Время на прочтение
20 мин
Количество просмотров 4.5K
Мы школа онлайн-образования, которая уже три года делает курсы по Data Science и разработке. Одна из наших целей — собрать коммьюнити классных специалистов и делиться крутыми и неочевидными знаниями. Так был рождён Симулятор ML — место, в котором начинающие и опытные специалисты решают задачи разной сложности, разрабатывают проекты в командах, осваивают новые инструменты, развивают продуктовое мышление и постоянно растут в профессии.
А, как это свойственно коммьюнити, горящему идеей, студенты и авторы хотят делиться своими инсайтами и открытиями, которые дадут свежий взгляд на устоявшиеся практики. Сегодня хотим поделиться статьей автора Симулятора ML Богдана Печёнкина о том, как лучше использовать анализ ошибок для разработки ML систем.
Введение
Всем привет! Меня зовут Богдан Печёнкин. Я Senior ML Engineer в компании BrandsGoDigital и больше всего известен как автор Симулятора ML.
Мой первый пост на Хабре посвящался 10 первым ошибкам в карьере ML-инженера, что тесно связано с сегодняшней темой. Анализируя свои и чужие ошибки, Я пришёл к выводу, что один из самых недооценённых этапов в построении ML систем — это, как ни странно, анализ ошибок. Он даёт глубокое понимание не только наших моделей, но и данных и метрик, с которыми мы работаем. Сегодня Я хочу поделиться с вами тем, почему анализ ошибок так важен, каким образом его проводить и как он может помочь вам в дизайне и разработке более надёжных и эффективных ML продуктов.
Данная статья написана по мотивам главы «Error Analysis» из книги «Machine Learning System Design with end-2-end examples», которую Я писал вместе с Валерой Бабушкиным и Арсением Кравченко, авторами книги.
Certainly, coming up with new ideas is important.
But even more important, to understand the results.
— Ilya Sutskever, сооснователь OpenAI
Что такое анализ ошибок?
Каждая модель машинного обучения несовершенна и имеет свои границы применимости: на одних данных она работает лучше, на других хуже, а где-то — совсем плохо.
All models are wrong, but some are useful.
– George Box, британский статистик
Определяя, как ведёт себя текущая модель в каждом отдельном кейсе, «в какую сторону» ошибается, мы получаем неоценимые подсказки, какие новые признаки нам нужны, какие преобразования целевой переменной попробовать, каких данных нам не хватает и так далее. Таким образом, анализ ошибок — это важнейший этап построения модели перед проведением A/B экспериментов, её тестированием в боевых условиях.
Но почему нам мало обычной кросс-валидации?
Когда мы считаем метрику на отложенной выборке, мы, по сути, агрегируем ошибки со всех объектов в одно число. Если у нас кросс-валидация вместо отложенной выборки и несколько метрик вместо одной, мы всё ещё агрегируем разного рода ошибки со всех объектов в некую «среднюю температуру по больнице».
Например, считаем MAE, WAPE, wQL в регрессии, или LogLoss в классификации.
Aгрегированная метрика не показывает, как ошибка распределяется по разным объектам, какое у неё распределение, а тем более — что нужно поменять в собранной ML системе, чтобы скорректировать ошибку (какие у метрики «драйверы роста»?).
Метрики сообщают нам, что стало либо «хуже», либо «лучше», но подсказок, что делать дальше, из-за чего результат именно такой и что надо менять в ML системе, они не дадут.
Анализ ошибок — процесс прямо противоположный подсчёту метрики: агрегированную метрику мы разбиваем на компоненты — и анализируем их в совокупности. Это даёт нам полную картину: где и как система проявляет себя и какие встречаются паттерны в разных сегментах объектов отложенной выборки.

Мне нравится проводить параллель с алгоритмом back-propagation: мы пробрасываем градиент ошибки от самых последних слоёв нейросети к самым первым, соответствующим образом обновляя каждый компонент сети. Анализ ошибок — это ровно такое же «взятие градиента метрики», но на этот раз для всего ML пайлпайна.

План рассказа
-
Введение в остатки и псевдоостатки
-
Определение понятий «остатков» и «псевдоостатков» в контексте регрессии и классификации.
-
Визуальный и статистический анализ остатков
-
Методы визуализации распределения остатков.
-
Применение статистических тестов для оценки смещения, гетероскедастичности и нормальности остатков.
-
Что такое fairness и его роль при принятии решения о деплое модели.
-
Анализ кейсов работы модели
-
Разбор наилучших, наихудших и крайних сценариев работы модели.
-
Моделирование ошибок с помощью Adversarial Validation
-
Анализ ошибок в нестандартных задачах машинного обучения
-
Как проводится анализ ошибок в других областях машинного обучения, отличных от стандартных регрессии и классификации.
Остатки и псевдоостатки
Остатки (residuals)
Что формально мы имеем в виду, говоря «ошибки»? Введём понятие «остатков».
Остатки регрессии представляют собой разницу между фактическим значением целевой переменной и предсказанным значением:
residuals = y_true – y_pred
Остаток — это буквально «то, что осталось недопредсказанным», часть значения таргета, которую модель не смогла объяснить с учётом имеющихся признаков.

Псевдоостатки в классификации
Что может служить остатками в бинарной классификации? Да, мы можем также смотреть на разницу между предсказанной вероятностью (скажем, 0.42) и метками класса 0 и 1. Мы уже упорядочим объекты по размеру их ошибки, но будет ли это самым информативным способом их анализа? Более естественно оперировать слагаемыми LogLoss, поскольку так мы учитываем ещё и вклад каждой ошибки в общую метрику, её вес.
Если агрегированный лосс представляется как:
∑ y log(p) + (1−y) log(1−p)
То слагаемые (y log(p) + (1−y) log(1−p)) представляют собой псевдоостатки. Так мы не просто считаем недопредсказанную часть целевой переменной, но ещё и «взвешиваем» объекты пропорционально их влиянию на метрику.

Псевдоостатки в общем случае
Если задуматься, большинство метрик, которые мы используем в машинном обучении (и абсолютно все лоссы) — представляют собой усреднение ошибок по каждому объекту, посчитанных тем или иным образом (вспомните, какие есть исключения из правила?).
-
Mean Squared Error (MSE):
∑ (y_true — y_pred)2 → sign(y_true – y_pred) * (y_true – y_pred)2 -
Mean Absolute Error (MAE):
∑ |y_true — y_pred| → y_true – y_pred
-
Mean Absolute Percentage Error (MAPE):
∑ |y_true — y_pred| / y_true → 1 – y_pred / y_true
Часто возникает путаница между остатками и псевдоостатками, особенно у начинающих специалистов на первых собеседованиях, когда разговор заходит о том, на что обучаются деревья в градиентном бустинге и почему он, собственно, градиентный.
Правильный ответ: каждое дерево ансамбля обучается на градиент функции потерь, или, иначе говоря, на градиент псевдоостатков.
Визуализация остатков
Распределение остатков
Допустим, мы рассчитали остатки. Основываясь на них, какие выводы мы можем сделать? (Примечание: здесь и далее будем использовать термины «остатки», «псевдоостатки» и «ошибки» как взаимозаменяемые).
Для начала мы анализируем их в совокупности — смотрим на их распределение. Распределение остатков позволяет нам «проверить на прочность» наши базовые предположения (assumptions) относительно данных, модели и других компонентов системы.
К примеру, вот наш коллега обучил модель прогноза спроса, визуализировал распределение остатков.
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure()
sns.histplot(residuals, kde=True)
plt.title('Distribution of Residuals')
plt.xlabel('Residuals')
plt.ylabel('Frequency')
plt.show()И увидел один из графиков ниже:

Какие выводы сделал бы наш коллега, посмотрев на эти три картинки?
-
Остатки распределены практически нормально (как мы и хотели):
✓ assumptions are met! -
Распределение нормальное, но с большим хвостом влево (недопредсказания):
✗ assumptions are not met! -
Распределение не нормальное и имеет две моды:
✗ assumptions are not met!
Какие шаги по улучшению модели он бы предпринял дальше?
-
В первом случае, наш коллега, вероятно, оставил бы модель без изменений, однако для полной уверенности перешёл бы к статистическим тестам и проверке скедастичности.
-
Здесь наш коллега возможно бы использовал логарифмирование таргета перед квантильной регрессией, чтобы минимизировать влияние больших значений.
-
В этом случае, возможно, стоит перейти к более сложным методам, таким как бустинг, чтобы уловить пропущенные моделью паттерны.
Обычно мы предполагаем, что остатки, если они в точности не подчиняются нормальному распределению, как минимум должны быть унимодальными и с центром вокруг нуля (не иметь выраженного сдвига: перепредсказания или недопредсказания). Кроме того, мы стремимся избегать ситуаций, когда остатки имеют сильно вытянутые хвосты, что обычно указывает на наличие существенных выбросов.
Ясно, что мы не хотим проверять эти свойства каждый раз вручную, изучая графики распределений глазами. Автоматизировать проверку остатков помогут статистические тесты, которые можно запускать после каждого запуска обучающего пайплайна. Так, в случае возникновения проблем (например, отвалился источник данных, либо новая версия модели оказалась выраженно хуже предыдущей).
Статистические гипотезы
Свойства распределения можно формулировать в виде статистических гипотез. Так, чтобы оценить наличие или отсутствие смещения (bias), мы сравниваем среднее у распределения остатков с нулём, используя t-тест для одной выборки. Тест учтёт их разброс и отвергнет гипотезу о несмещённости остатков, только если наблюдаемое смещение выходит за рамки погрешности.
Подобным образом, мы можем оценить нормальность распределения, используя критерий Колмогорова-Смирнова. Очевидно, здесь глаз человека даже менее надёжен, чем стат. тест, сравнивающий «отклонение» от нормального распределения численно.
На выходе статистического критерия мы получаем p-value — вероятность встретить наблюдаемое значение статистики или более экстремальное при условии, что нулевая гипотеза верна.
-
В случае смещения нулевая гипотеза: остатки не имеют смещения.
-
В случае нормальности нулевая гипотеза: остатки распределены нормально.
Для принятия решения мы руководствуемся уровнем значимости α (например, 5%) или, иначе, уровнем ошибки I рода. Уровень значимости сообщает, начиная с какой степени «невероятности» нулевой гипотезы мы её отвергнем.
Гетероскедастичность
Ещё два свойства распределения, которые мы можем оценивать, — гомоскедастичность и гетероскедастичность. Гомоскедастичность (homo + scedasticity) — буквально «одинаковый разброс». Соответственно, гетероскедастичность (hetero + scedasticity) — «разный разброс».
")
кейсы 2-3: гетероскедастичное (с разным паттерном)
О чём речь в случае остатков? Мы хотим знать, насколько сильно дисперсия остатков варьируется для разных значений целевой переменной. Наблюдаем ли мы, что на малых значениях остатки маленькие, а с ростом таргета они растут (или наоборот)? Наблюдаем ли мы, что на малых и больших значениях таргета (на краях) остатки имеют больший разброс, чем в середине (в основной массе распределения таргетов)? Или остатки везде однородные?
Обратите внимание, что скедастичность остатков (и псевдоостатков) может кардинально отличаться при переходе от одной метрики к другой (например, от разностей таргетов и предиктов — к квадратам разностей), поскольку каждая метрика по-своему взвешивает разные ошибки в зависимости от их знака и величины.
Для гомоскедастичности существует несколько статистических тестов:
-
Bartlett’s test
-
Levene’s test
-
Fligner-Killeen’s test
Все они доступны в пакете scipy.stats. Это семейство тестов называют ANOVA-тестами (ANalysis Of VAriance). Каждый них принимает на вход набор подвыборок и оценивает, насколько валидно предположение, что каждая из подвыборок имеет одну и ту же дисперсию.
Для нас подвыборками будут служить бины из остатков, разбитых по мере увеличения таргета. Например, бьём таргет на 5 бинов по пороговым квантилям: 0.2, 0.4, 0.6, 0.8.

Diagnostic Plots
Diagnostic Plots представляют собой ещё один метод для анализа распределения остатков в дополнение к статистическим тестам. Это набор специфических визуализаций остатков и предсказаний целевой переменной в разных разрезах.
Чаще всего эти визуализации используются в линейных моделях для проверки их основных предположений: несмещённости, нормальности и гомоскедастичности.
1. Residuals vs. Fitted
На этом графике мы визуализируем остатки против предсказанных значений целевой переменной. Он позволяет понять характер смещения: распределено ли оно равномерно по всем предсказаниям (тогда наблюдаем прямую линию, см. левый график внизу), либо имеет значимую неравномерность (например, на втором графике ниже — остатки на очень больших и очень маленьких прогнозах резко отрицательные).
")
2. Normal Q-Q Plot
Q-Q Plot — это способ визуализации отклонения от заданного распределения. Для его отрисовки мы визуализируем, какие теоретические квантили были бы у нашей выборки (остатков), будь она взята из предполагаемого распределения, и какие квантили на самом деле, поэтому график называется Q-Q (Quantile-Quantile) Plot.
Чем больше реальные значения отклоняются от прямой линии, тем менее вероятно, что выборка взята из этого распределения. Частным случаем служит Normal Q-Q Plot, где мы сравниваем выборку с нормальным распределением (ещё один способ оценить, распределены ли остатки нормально — и, если нет, в каких конкретно значениях).
")
3. Scale-Location Plot
Scale-Location Plot помогает в оценке скедастичности распределения (гетероскедастичности либо гомоскедастичности, с которыми мы уже успели познакомиться). Для его отрисовки мы берём предсказания против корня модуля стандартизированных остатков.
Если распределение одинаково для всех предсказаний (иметь одного масштаба отклонение), то остатки считаются гомоскедастичными относительно предсказанного значения. Если мы видим растущий или убывающий тренд, другую неоднородность — значит, присутствует гетероскедастичность.
")
4. Cook’s Distance Plot
Cook’s Distance является мерой влияния каждого отдельного наблюдения на модель в целом. Она помогает выявить наиболее влиятельные объекты в данных, что может быть полезно при проверке модели на наличие аномалий или выбросов, которые могут сильно искажать её предсказания.
Для построения Cook’s Distance Plot визуализируются предсказанные значения против расстояния Кука. В каждой точке графика расстояние Кука представляет собой сумму отклонений предсказаний, полученных при удалении данного наблюдения, к предсказаниям, полученным на всем наборе данных.
Таким образом, если какие-то наблюдения имеют высокое значение расстояния Кука, это означает, что удаление этих точек может значительно изменить модель, поэтому они могут считаться влиятельными.
")
Diagnostic Plots
Эти четыре типа графиков часто используются вместе для полного визуального анализа остатков и проверки предположений модели. Они помогают понять, хорошо ли модель работает, есть ли какие-либо систематические ошибки, а также позволяют определить возможные проблемы с распределением остатков и наличием выбросов.

Существуют готовые пакеты отрисовки всех четырёх графиков. Например, в языке программирования R они входят в стандартную библиотеку и доступны вызовом функции plot на уже обученной линейной модели.
Fairness
Когда мы улучшаем модель, мы не хотим, чтобы метрика росла на одних сегментах пользователей и падала на других (даже если в среднем она оказывается выше). Бенефиты от прироста метрики легко могут быть перечёркнуты негативным User Experience «пострадавшей» группы пользователей — и за счёт совсем других метрик.
Чтобы этого избежать, мы должны смотреть не только на то, выросла ли метрика или упала, но и на то, как она размазана по всем объектам (например, по всем пользователям или по всем товарам). Для этого вводят концепт Fairness (в переводе с английского, «справедливость»).
Идеализированный пример:
Два ML инженера разрабатывали улучшение бейзлайн-модели. Оба из них получили сокращение MAE (Mean Absolute Error) на 20%. Как их рассудить? Чью модель выкатывать на A/B тест? Первая модель дала небольшой равномерный прирост для всех объектов. Вторая модель сильно сократила ошибку на половине объектов и немного увеличила на другой половиние.

Как мы видим из примера, одного и того же улучшения метрики можно добиться разными способами. Мы предпочтём скорее, чтобы метрика везде выросла понемногу, нежели чтобы где-то она сильно выроста, а где-то просела. Поэтому даже если суммарная метрика выросла, этого ещё не достаточно, чтобы принять решение, что новая модель лучше и её нужно катить в прод!
Аналогично можно представить, что неравномерный прирост (unfair uplift) был получен по ключевой онлайн-метрике и во время A/B теста (эксперимента на реальных пользователях), что также может послужить сигналом, что данную модель не стоит раскатывать на остальном трафике.
Gini Index
В экономике для количественной оценки «справедливости» распределения часто используют Gini-индекс, особенно при анализе распределения доходов населения определённой страны.
Gini-индекс варьируется от 0 до 1, где 0 обозначает идеальное равенство (т. е. все значения равны), а 1 обозначает максимальное неравенство (одно значение максимально, все остальные минимальны). Чем выше индекс Gini, тем более несправедливым считается распределение.

То же касается и распределения ошибок. Встретить случай, когда малое число объектов вносит львиную долю вклада в ошибку, для нас нежелательно. Почти во всех случаях для нас предпочтительнее «размазать» ошибку по разным объектам (или, скажем, для некой группы особых объектов построить отдельную модель), чем встретить явный перекос.
Достичь полностью равномерного распределения ошибок невозможно, и к этому нет смысла стремиться как к самоцели, так же как и к равномерному распределению доходов. Однако, кроме точности предсказания, оценивать, что Gini Index не снижаеся более чем на X%, — это полезно. Здесь нам главное избегать вырожденных случаев.
Кроме того, мы можем добавить и более простые эвристики, которые в лоб считают, на какой доле объектов мы увеличили качество, на какой просадили (по разнице знаков остатков).
Best Case / Worse Case / Corner Case
Изучив остатки в их совокупности и проанализировав их верхнеуровневые свойства, мы спускаемся на один уровень ниже. А именно начинаем искать в них паттерны. Так мы понимаем, «в какую сторону» нужно корректировать модель или остальные компоненты пайплайна обучения, когда что-то сломалось.
Best Case & Worst Case
Зная остатки, можно проанализировать поведение модели в лучших и худших сценариях. Для этого мы выводим топ-20, топ-50, топ-100 объектов по величине остатков и ищем в них общие паттерны.
-
Например, если мы прогнозируем число заказов в приложении доставки и видим, что наша модель систематически недооценивает спрос на веганскую и вегетарианскую еду, а также на блюда, которые попадали под промоакции. Мы пришли к выводу, что в качестве признаков нужно добавить «тип кухни» и, кроме того, подключить источник данных, содержащий «промо календарь».
-
Другой случай: мы попробовали построить модель прогноза на Трансформерах, распределение её остатков принципиально отличается от текущей модели в проде. Метрика лучше. Мы хотим с нуля проанализировать, на каких блюдах и на каких пользователях прогноз спроса точнее всего. Где пролегает текущая «граница применимости» текущей модели, чтобы раскатить её в первую очередь на той части данных, где она чувствует себя лучше всего. Для этого мы выводим топ-1000, топ-5000, топ-10,000 объектов с наименьшей ошибкой.
Одним из наилучших методов является автоматическое сохранение объектов с наибольшими ошибками (debug samples) в качестве артефактов при каждом запуске обучения. Благодаря этому мы сможем быстро и легко заметить общие паттерны (сходу получаем багаж идей для улучшения пайплайна) и в будущем проследить, как менялся характер ошибки по мере выкатки новых улучшений и добавления новых признаков.

Corner Case Analysis
В то время как анализ лучших и худших случаев направлен на выявление общих паттернов на основе остатков, corner case analysis фокусируется на том, какие остатки характерны для объектов с конкретными особенностями.

-
Так, если у остатков разный разброс на разных по масштабу таргетах (например, мы предсказываем выручку и наибольший вклад делают ошибки в предсказании наименьших значений выручки, близких к нулю), тогда нам стоит вывести группу объектов с наименьшими таргетами, посмотреть на их остатки.
-
Аналогично, нам может быть любопытно, какие ошибки в районах или ресторанах, которые недавно подключены к нашему сервису (так называемся «проблема холодного старта»: например, как заполнять пропуски в товарах, для которых нет достаточной истории продаж?).
-
Или какие ошибки на пользователях из определённого сегмента, например, присоединившиеся в наш сервис после того, как увидели рекламу на маркетплейсе KarpovExpress; или какие ошибки предсказания у самых популярных ресторанов и блюд. Во всех этих случаях нам нужно отфильтровать нужную подвыборку данных и проанализировать её остатки в изоляции.

Случай из жизни: когда мы строили сервис динамического ценообразования в одном крупном маркетплейсе, то столкнулись с забавной проблемой, которую удалось оперативно решить благодаря анализу ошибок.
Наша система работала по следующему принципу: ML-модель учится предсказывать спрос для товаро-дня с учётом множества факторов, среди которых есть факторы цены и их производные (скидки, наценки, разницы с ценами конкурентов и т.д.). Для дальнейшего использования модели, мы подставляли разные цены (досчитывая зависимые от цены факторы) и оценивали спрос для каждого прайс-поинта.
Например, -10%, -9%, -8%, …, +9%, +10% от последней наценки.
Чтобы понять, делает ли обученная модель осмысленные предсказания, мы смотрим на графики кривой эластичности по каждому товару. Если не вдаваться в детали, эластичность – это и есть зависимость спроса от цены, которую мы получаем подставляя цены и делая прогноз для новой точки.

Ожидаемое поведение: чем выше цена, тем ниже спрос, и наоборот. Эластичные товары имеют “более крутую” кривую: малейшее увеличение цены ведёт к сильному спаду спроса, и наоборот. Неэластичные имеют более “плоскую” зависимость: мы можем наглеть в цене, а спрос – не сильно упадёт (значит, заработаем больше денег).
 – аналог товарооборота (выручки) для e-commerce. Для нашего сервиса он играет роль «спроса».")
Однако, начав анализ первых графиков эластичности, мы обнаружили вот какую картину:

Как вы понимаете, это вообще вышло за рамки нашего ожидания. Из-за чего так произошло? Есть ли у вас догадки?
Дело в том, что в качестве модели прогноза у нас был CatBoost и обучался он на большом числе товаров. Как мы знаем, градиентный бустинг (начиная с LightGBM) делает квантизацию всех признаков перед обучением (разбивая на бины +- одинаковых размеров), таким образом, с десятков уникальных значений по каждому признаку мы переходим, например, к 256 или 512 значениям. Это обеспечивает ускорение обучения за счёт потери части сигнала в признаках.

Таким образом, даже несмотря на то, что цена и признаки на основе цены выходили в топ по важности, тем не менее, модель была физически «нечувствительна» к малым вариациям цены, на которых мы затем её хотели применять.
Решение: повысить гранулярность квантизации (скажем, до 4096 или 8192). В результате мы получили графики с уже осмысленным «гладким» возрастанием спроса по мере уменьшением цены.
Моделируем ошибку
Но вернёмся к worst-case анализу.
Допустим, мы выделили группу объектов, на которых модель показала наихудшие результаты. Как нам это знание использовать для определения «градиента» ML системы, поиска наискорейшего шага её улучшения? Смотреть на ошибки, конечно, можно и вручную, особенно когда признаков мало, а объектов выделено немного. Но что если того и того становится слишком много?
Наверняка, есть пути автоматизировать и этот процесс, ведь мы инженеры…
И такой приём действительно есть: Что, если использовать одну модель машинного обучения для предсказания ошибок другой модели машинного обучения?

Adversarial Validation
Adversarial Validation — приём, который мы сегодня применим для выделения паттернов в ошибках. Он происходит от соревнований по машинному обучению на Kaggle. В соревнованиях участники стремятся улучшить качество своих моделей, используя наиболее умные и сложные методы. Часто они сталкиваются с проблемой, когда их модели хорошо работают на обучающем наборе данных, но плохо на отложенной выборке (тестовом наборе данных, целевые переменные, для которых надо предсказать).
Почему так происходит?
-
Первая возможная причина: модели могут переобучаться на обучающем наборе данных (особенно если не предусмотреть надёжную валидацию, на основе которой мы не просто смотрим, подросла ли метрика или нет, но и учитываем чувствительность выбранной схемы.
-
Вторая возможная причина: и от этого куда труднее спастись — тестовый набор данных может существенно отличаться от обучающего набора данных. Именно это называется «расхождением распределений».

Чтобы оценить, насколько два распределения похожи или не похожи (и в каких признаках именно), мы можем обучить отдельную модель-классификатор. Все объекты обучающей выборки примут класс 0, а все объекты тестовой — класс 1.
Если разница между выборками несущественна (например, ROC-AUC ≈ 0.5), это означает, что распределения обучающего и тестового набора данных схожи.
Если между выборками большая разница (например, ROC-AUC > 0.6), тогда выборки уже различимы, мы можем из обучающей выборки выделить самые похожие на тест объекты и использовать их как отложенную валидационную выборку.
Именно это и называется Adversarial Validation.
Граница применимости модели
Если задуматься, этот подход можно применить к любым двум выборкам, чтобы выявить между ними отличия. Более того, поняв, что две группы объектов различимы, мы можем заглянуть в Feature Importance модели (а выбор подходящей модели для анализа ошибок — отдельный разговор) и узнать, в каких именно признаках различие между выборками себя выдаёт.
Как Adversarial Validation «завести» для анализа ошибок? Какие две выборки у нас есть?
-
Отбираем топ ошибок модели (например, топ-1000 или топ-10%). Это наши worst-cases.
-
Присваиваем им класс 1, а всем остальным («здоровым») объектам — класс 0.
Наши выборки: «хорошо прогнозируемые» и «плохо прогнозируемые». -
Строим вспомогательную модель-классификатор, которая пытается предсказать, является ли объект «плохо прогнозируемым». Эта модель будет использовать признаки объектов (возможно даже куда больший набор, чем тот, на основе которого мы обучаем основную модель), чтобы понять, чем так отличаются «плохие объекты».
-
Если модель классифицирует «хорошо прогнозируемые» и «плохо прогнозируемые» объекты с достаточной точностью (ROC-AUC > 0.6), то это говорит о том, что ошибка модели зависит от значений некоторых признаков.
-
Анализируем важность признаков в этой модели (например, по SHAP-values), чтобы определить, какие признаки сильнее всего влияют на ошибки основной модели.
Это подскажет, паттерны в каких признаках сейчас основная модель не понимает чаще всего. Это направляет вектор нашего поиска новых признаков (и их трансформаций), обогащения датасета и, возможно, модификацией loss-функции или процесса предобработки целевых переменных.
Анализ ошибок за пределами регрессии и классификации
Анализ ошибок не ограничивается простыми задачами классификации или регрессии и столь же активно используется в других областях машинного обучения. Давайте посмотрим шире не то, что может играть роль остатков в других доменах.
1. Сегментация изображений (Image Segmentation). В области компьютерного зрения задача сегментации изображений заключается в выделении определенных областей или объектов на изображении, соответствующих определённым классам. «Остатками» здесь является разница предсказанной маски сегментации (контура объекта) и истинной. С помощью наложения масок или использование цветовых карт, мы можем быстро определить области изображения, где модель допускает ошибки (например, плохо отделяет мелкие детали, волосы или ошибочно выделяет зеркальное отражение).
, ошибочно не выделенные регионы изображения, — и False Positives (FP), ошибочно выделенные.")
С другой стороны, мы можем оперировать не пикселями, а самими картинками: просматривать топ-N изображений с самой большой ошибкой после обучения и анализировать, есть ли в них какой-либо паттерн. Так, например, модель может некорректно работать на картинках с тёмным освещением, с зеркалами, с большим количеством объектов или на специфическом фоне. Обнаруженные закономерности подсказывают, каких данных (на какие паттерны) нужно добавить в выборку больше, либо как нужно модифицировать loss-функцию (чтобы модель была внимательнее на границах масок сегментации).
2. Генерация звука (Voice Cloning). В задачах генерации аудио, таких как генерация голоса или Text-to-Speech (TTS), важным элементом анализа ошибок является использование Attention Plots. Они показывают, на какие части исходного текста модель обращала особое внимание при генерации каждого отдельного звука. Это позволяет выявить неправильные соответствия и улучшить качество генерации.
Кроме того, существует подход Guided Attention, который дополнительно штрафует модель за отклонение от линейного отображения позиции символа в позицию звука. Как мы помним, анализ ошибок служит в том числе и для проверки на прочность наших предположений о модели (model assumptions).

3. Рекомендательные и поисковые движки. Ещё пример — рекомендательные системы. Вместо предсказанной одной цифры, как в классификации и регрессии, мы имеем рейтинг объектов, которые мы порекомендовали бы пользователю. Существует несколько метрик, сравнивающих гипотетическую выдачу и то, что пользователь реально кликал/покупал/смотрел.
Одна из таких метрик — NDCG. Несмотря на отличный от регрессии и классификации формат «предсказаний», эта метрика усредняет качество рекомендации по всем объектам. Значит, ничего не мешает посмотреть на best/worst/corner кейсы по аналогии с регрессией и классификацией: узнать, какие запросы наша система «понимает» хуже всего; как ведёт себя на пользователях с длинной и короткой историей запросов (или просмотров); нет ли очевидных проблем, например, зацикливания на том, что пользователь уже покупал или смотрел?
Вывод
Как мы увидели, анализ ошибок играет ключевую роль в процессе создания и оптимизации ML системы. Это не просто этап «для галочки» перед деплоем, который можно пропустить. Напротив, анализ ошибок стоит в самом начале итеративного цикла улучшения и усложнения модели.
Когда мы создали baseline с минимальным датасетом, анализ ошибок позволяет нам определить её сильные и слабые стороны, а также выявить моменты, которые требуют оптимизации (что далеко не всегда требует сразу заводить бустинги или BERTы). Этот анализ даёт нам понимание о том, какие улучшения модели следует внести в следующем цикле. Так, на каждой итерации, мы заменяем модель на более сложную, добавляем новые факторы в датасет, анализируем ошибки и сравниваем их с ошибками предыдущей версии.
Этот цикл дотошного анализа текущих результатов для определения вектора следующего наискорейшего шага в улучшении ML системы – и, непосредственно, внесения изменений в пайплайн — вот, из чего состоит реальная работа ML инженера на практике.
Анализ ошибок — это лишь часть задач инженера по машинному обучению. Кроме анализа ошибок в повседневной работе мы разрабатываем метрики, собираем датасеты, обучаем сами модели, деплоим и тестируем ML-сервисы, проводим A/B-тесты и много чего ещё, порой выходящего за рамки теоретического понимания, как работают модели машинного обучения.
Для математики популярная поговорка «умные люди учатся на чужих ошибках» практически не работает, так как ошибка в большинстве случаев является необходимой и полезной, ведь она позволяет определить пробелы в знаниях школьника и своевременно их устранить. Главное – правильно относится к ошибке и ее правильно ее использовать.
Тем более обидно получать глупые ошибки, которые вызваны невнимательностью обучающихся, пропусками переменных, случайными потерями знаков, скобок и другими различными ляпами.
Для того чтобы снизить вероятность ошибок, необходимо использовать различные методики предупреждения типичных ошибок, что будет в итоге способствовать повышению уровня математической подготовки школьников.
Разбор, анализ и проработка ошибок и неточностей, допущенных при выполнении задания
Организация работы обучающихся, направленной на анализ и исправление допущенных недочетов называется работой над ошибками. Ее основной целью является разбор, анализ и проработка ошибок и неточностей, допущенных при выполнении задания. Правильно организованная работа обучающихся обеспечивает:
-
дифференцированный подход к обучению;
-
является профилактикой будущих ошибок;
-
позволяет своевременно ликвидировать пробелы в знаниях и навыках детей;
-
формирует умение систематизировать и обобщать, закреплять полученные знания.
Грамотный, творческий подход учителя к организации работы над ошибками создает условия для развития адекватного отношения обучающегося к ошибкам, умение работать с ними.
Можно говорить о том, что, после проведения работы над ошибками итоговая оценка отражает действительный уровень усвоения знаний и умений обучающихся. Существует практика, когда некоторые учителя практикуют выставление оценок за каждую проведенную работу. При этом, часто бывает, что после работы над ошибками, отметка за проверяемую работу повышается (как правило на один бал).
Обычно, работа над ошибками проводится в классе, под руководством учителя, но может проводиться и дома, возможно, под контролем родителей. Если учитель считает возможным дать выполнение работы над ошибками в качестве домашнего задания, он должен убедиться, что все обучающиеся знают и помнят основной алгоритм действий по выполнению работы. Целесообразно, каждому ребенку выдать памятку с порядком выполнения действий. Кроме этого, необходимо предварительно, на уроке провести общий анализ допущенных ошибок.
В классе, работу над ошибками проводят, как правило, после контрольных, самостоятельных или творческих работ. Работе над ошибками может быть посвящен, как весь урок, так и его часть. Это зависит от характера и количества видов ошибок, от уровня самостоятельности обучающихся и т.п. По усмотрению учителя возможны: фронтальная, групповая, парная, индивидуальная работа.
Основные этапы и формы организации работы над ошибками на уроке
При работе на уроке выделяют несколько основных этапов:
-
консультация;
-
коррекция знаний и умений;
-
диагностика результатов;
-
оценочная деятельность.
По усмотрению учителя возможны: фронтальная, групповая, индивидуальная работа.
Рассмотрим несколько вариантов проведения работы над ошибками
В начале урока, после проведения общего анализа проверенной работы, учитель просит поднять руку тех обучающихся, которые допустили ошибки при выполнении первого задания. К доске приглашается один из обучающихся, который будет выполнять и комментировать аналогичное задание у доски. Обучающийся определяется либо по его желанию, либо по решению учителя. Остальные обучающиеся выполняют работу у себя в тетрадях. Затем все самостоятельно решают задание проверочной работы. Таким образом, дети прорешивая аналогичное задание, прорабатывают ошибки, допущенные не только ими самими, но и остальными обучающимися. Такой подход целесообразен, когда в данном задании большинство обучающихся допустили ошибки.
Следующая форма работы используется, когда один, или несколько обучающихся допустили ошибки в задании, которое большинство обучающихся выполнили правильно. При данной форме организации урока один обучающийся выполняет работу над своими ошибками у доски, остальные обучающиеся исправляют свои недочеты в тетрадях или выполняют индивидуальные задания. С одной стороны, этот метод позволяет экономить время, затрачиваемое на данную деятельность, с другой — учитель не может контролировать деятельность других детей. Для исправления возникшей ситуации, нужно обеспечить каждому обучающемуся возможность обратиться к учителю за помощью, за консультацией.
Бывают ситуации, когда часть обучающихся выполнила проверочную работу на «отлично», т.е. возникает необходимость организовать деятельность этих обучающихся, и, одновременно организовать выполнение работы над ошибками остальными обучающимися. В этом случае, есть несколько вариантов организации работы на уроке.
Во-первых, «отличникам» можно предложить выполнение индивидуальных заданий повышенного или углубленного уровней, творческие задания, работу по подготовке, например, информационного сообщения к следующему уроку. С остальными обучающимися проводится работа над ошибками.
Во-вторых, обучающихся, показавших высокий уровень усвоения учебного материала, можно привлечь к консультированию других детей. В этом случае возможна организация групповой и (или) парной работы.
Имеют место случаи, когда педагог, в целях экономии времени, выделяет только типичные ошибки, допущенные обучающимися при выполнении проверочной работы, и на уроке проводят работу только таким видом ошибок. В этом случае работа организовывается фронтально, анализ и исправление типичных ошибок и недочетов выполняет весь класс вместе. При этом у доски работают обучающиеся по желанию, по очереди или по решению учителя, в зависимости от того, кто какие ошибки допустил.
Алгоритм действий по выполнению работы над ошибками
Алгоритм действий по проведению работы над ошибками определяется учителем самостоятельно, исходя из особенностей класса, общего уровня обученности и т.д.
Например, алгоритм действий обучающегося может выглядеть следующим образом:
- просмотреть всю работу, обратить внимание на исправления учителя;
- найти ошибку, выписать задание, в котором она допущена, проанализировать причину ее возникновения:
-
ошибка в вычислении – перерешать;
-
ошибка в применении формулы (правила, закона) — вспомнить нужную формулу (правило, закон) по данной теме, применить при решении;
-
ошибка в построении рисунка – повторить материал в учебнике и выполнить рисунок правильно;
- решить аналогичное задание
Памятка-помощник
В практике работы некоторых учителей встречается использование памяток, которые изготавливаются педагогом и раздаются каждому обучающемуся. Памятки могут быть индивидуальными. Работа с памятками выполняется под контролем педагога.
В памятке пронумерованы и записаны основные группы ошибок в виде:
Тема «….».
Примеры.
- …
Если учитель планирует проводить работу над ошибками, с использованием памяток, то при проверке работы на полях тетради, напротив задания, в котором допущена ошибка, ставится номер, соответствующего задания в памятке. Это не только облегчает работу обучающихся, но и совершенствует систему обучения. Обучающийся неоднократно обращается к данной памятке, что способствует лучшему запоминанию учебного материала.
Проверка и подведение итогов работы над ошибками
В конце работы над ошибками необходимо провести проверку. Существует несколько форм ее организации.
-
самопроверка;
-
парная работа;
-
групповая работа, когда «сильные» обучающиеся выступают в роли консультантов;
-
фронтальная работа со всем классом.
Во всех случаях, необходимо обеспечить возможность каждому обучающемуся консультирования и помощи учителя, если возникают трудности.
В конце работы над ошибками, как и в конце любого урока, необходимо провести рефлексию. Дети анализируют свои ошибки, отмечают, как изменились собственные умения, отмечают моменты, которые остались не понятны, говорят о том, что вызвало трудности и высказывают свои предложения.
Следует отметить, что проведение работы над ошибками является обязательным и систематическим действием после каждой контрольной и проверочной работы. При этом необходимо обращать внимание и прорабатывать все ошибки, допущенные обучающимися, тщательно проводить отбор задач и примеров для отработки знаний и умений, для закрепления пройденного материала.
Превентивная деятельность учителя по предупреждению ошибок
Большая часть ошибок, допускаемых обучающимися, не связана с отсутствием или наличием знаний, хотя, конечно, доведение до уровня автоматизма ряда вычислительных операций позволяет существенно снизить вероятность появления ошибок. Однако при этом необходимо, чтобы обучающийся все равно руководствовался нужными правилами и постоянно сохранял концентрацию внимания.
Знание определенных правил нужно и для того, чтобы обучающийся мог проверить правильность решения и дать его обоснование. В тоже время многие школьники воспринимают курс алгебры в качестве набора правил, которые абсолютно не связаны между собой, поэтому они заучиваются исключительно для решения какой-то конкретной задачи, а по истечению незначительного промежутка времени просто забываются. В этой связи требуется организовывать процесс обучения правилам с использованием приемов, которые активизируют рефлексивную деятельность школьников по предупреждению и исправлению ошибок, возникающих при формальном усвоении правил.
Если процесс поиска и исправления ошибок сделать максимально поучительным для обучающихся, то анализ ошибок может стать эффективным средством для развития познавательного интереса к математике.
Наиболее распространенными ошибками являются:
-
незнание или непонимание правил, формул и определений;
-
неправильное применение формул или неумение правильно применять определения и правила;
-
совершение вычислительных ошибок;
-
невнимательное чтение условий задачи;
-
отказ от использования свойств фигур при решении геометрических задач;
-
неправильное раскрытие скобок;
-
совершение логических ошибок при решении текстовых задач;
-
применение формул сокращенного умножения.
К основным причинам совершения ошибок по математике относят:
-
пропуски уроков, в результате чего появляются пробелы в знаниях;
-
поверхностное изучение нового материала;
-
повышенная усталость, вызванная чрезмерной нагрузкой или недостаточным сном, в результате чего понижается скорость мышления и снижается уровень внимания;
-
неаккуратный почерк, из-за чего учитель часто не понимает, что написал обучающийся;
-
скорость работы. При этом на появление ошибок влияет как высокая скорость работы, из-за которой обучающийся просто не стремиться вникнуть в суть задания, так и медленная. В последнем случае замедленная скорость мыслительных операций не позволяет обучающемуся в полной мере контролировать себя, а из-за «зависания» нужная информация просто удаляется из «оперативной памяти»;
-
полное либо кратковременное переключение внимания с одной деятельности на другую;
-
низкая мотивация, в результате которой теряется внимание и появляются ошибки.
Объяснение и предупреждение ошибок
Для предупреждения ошибок и сведения их к минимуму используются следующие профилактические мероприятия и действия:
-
постоянный разбор наиболее распространенных ошибок в классе;
-
предлагаемые обучающимся письменные задания должны быть максимально удобны для восприятия, то есть грамотно сформулированными и понятными;
-
подбор заданий и упражнений, которые будут вызывать у детей интерес и повышенное внимание;
-
учитель должен при объяснении нового материала стараться предугадать возможные ошибки обучающихся и разработать систему заданий, которые позволят правильно усвоить новые понятия;
-
использование правил удобных для запоминания и исключающих двойную их трактовку.
Кроме того, учитель математики должен помнить, что систематическое и планомерное повторение является основным инструментом для ликвидации пробелов знаний.
Также рекомендуется при объяснении нового материала активно применять определения и теоремы, которые изучались ранее. Так, при изучении темы «Теоремы сложения» целесообразно организовать повторение ряда теоретических вопросов:
-
Изменение тригонометрических функций при возрастании и убывании аргумента.
-
Четные и нечетные функции.
-
Таблицы значений тригонометрических функций.
-
Знаки тригонометрических функций.
Дополнительно выполняются следующие задания:
-
Необходимо определить четность и нечестность тригонометрических функций:
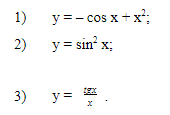
-
Найдите область определения функции y = x2 – 6x + 10.
-
Определите, при каких значениях x, функции y = sin x и y = cos x принимают одинаковые значения?
Перед тем как приступить к изучению темы «Первообразная и интеграл», следует повторить все формулы дифференцирования. После этого обучающиеся выполняют самостоятельную работу (время решения – 10-15 минут), во время которой школьникам предлагаются карточки-задания, где «опущены» один-два компонента из формулы дифференцирования, а также приведены две функции, производные которых необходимо найти.
Затем проводиться проверка работы и анализ совершенных ошибок, что необходимо для выявления пробелов в знаниях и проведения работы по их устранению.
Список литературы:
- Азиев И.К. Индивидуальные задания для устранения ошибок. // Журнал «Математика в школе» – 1993 г. – №5, с. 9.
- Амонашвили Ш.А. Воспитательная и образовательная функции оценки обучения школьников: Экспериментальное педагогическое исследование. – М.: Педагогика, 1984. – 296 с.
- Бабанский Ю.К. Педагогика. М.: Просвещение, 1983.
- Волович И.Б. Наука обучать: Технология преподавания математики. – М.: LINKA-PRESS. 1995. – 280 с.
- Груденов Я.И. Совершенствование методики работы учителя математики: Кн. для учителя. – М.: Просвещение, 1990. – 224 с.
- Груденов Я.И. Психолого-дидактические основы методике обучения математики. – газета «Математика», 1987 г. с. 91-96.
- Гуцанович С.А. Дидактические основы математического развития учащихся: Монография. – Минск: БГПУ им. М. Танка, 1999. – 301 с.
- Давыдов В. В. Проблемы развивающего обучения. Опыт теоретического и экспериментального исследования / В. В. Давыдов. – М.: Педагогика, 1986. – 239 с.
- Далингер В.А. Методика реализации внутрипредметных связей при обучении математике: Кн. для учителя. – М.: Просвещение, 1991. – 80 с.
- Далингер В.А. Обучение учащихся доказательству теорем: Учебное пособие. – Омск: Омский пед. ин-т, 1990. – 127 с.
- Действующие учебники и учебные пособия по математике для средней школы.
- Журналы «Математика в школе» за 1970-1990 гг.
- Колягин Ю.М. Задачи в обучении математике: Математические задачи как средство обучения и развития учащихся: в 2ч. – М.: Просвещение, 1977. – ч.2. – 144 с.
- Колягин Ю.М. Задачи в обучении математике: Обучение математике через задачи и обучение решению задач: в 2ч. – М.: Просвещение, 1977. – ч.2. – 144 с.
- Метельский Н.В. Дидактика математики. – Минск: Изд-во БГУ, 1982–254с.
- Методика преподавания математики в средней школе: Общая методика: учеб. пособие; сост. Р. С. Черкасов, А. А. Столяр. – М.: Просвещение, 1985. – 336 с.
- Новик И.А. Формирование методической культуры учителя математики в педвузе. – Мн.: БГПУ им. М. Танка, 2002. – 193 с.
- Новик, И. А. Практикум по методике преподавания математики / И. А. Новик. – Минск: Выш. шк., 1984. – 175 с.
- Оганесян В.А. Принципы отбора основного содержания обучения математике в средней школе. – Ереван: Луис, 1984. – 215 с.
- Рогановский, Н. М. Методика преподавания математики в средней школе: учеб. пособие / Н. М. Рогановский. – Минск: Выш. шк., 1990. – 267 с.
- Селевко, Г. К. Современные образовательные технологии: учеб. пособие / Г. К. Селевко. – М.: Народное образование, 1998. – 256 с.
- Столяр, А. А. Педагогика математики: учеб. пособие / А. А. Столяр. – Минск: Выш. шк., 1986. – 414 с.
- Темербекова, А. А. Методика преподавания математики: учеб. пособие / А. А. Темербекова. – М.: ВЛАДОС, 2003. – 176 с.
- Фридман, Л. М. Психолого-педагогические основы обучения математике в школе / Л. М. Фридман. – М.: Просвещение, 1983. – 160 с.
- Шнейдерман М.В. Анализ ошибок и затруднений учащихся V классов // Журнал «Математика в школе» – 1999 г. – №6, с. 21.
- Эрдниев, П. М. Обучение математике в школе. Укрупнение дидактических единиц / П. М. Эрдниев, Б. Л. Эрдниев. – М.: Столетие, 1996. – 320 с.
- Якиманская И.С. Личностно-ориентированное обучение в современной школе – М., 1996. – 347 с.
- Якиманская И.С. Психологические основы математического образования. – М.: Acadiia, 2004.
- Ярский А.С. Что делать с ошибками // Журнал «Математика в школе» – 1998 г. – №2, с. 8-14.

Сергеева А. А. учитель английского языка
Анализ и разбор типичных ошибок ОГЭ 2022

Типичные ошибки
- Общие ошибки
- Незнание формата, критериев оценки;
- Невнимательное прочтение инструкций в бланках;
- Невнимательное прочтение инструкций к заданиям;
- Неправильное распределение времени на экзаменах.
- Ошибки организационного и психологического плана
- Неправильно заносят ответы в бланк ответов (добавляют лишние символы или заносят информацию в неправильные позиции бланка)
- Забывают заполнить позиции бланка
- По одной позиции пишут 2 ответа
- Пропускают клеточки при заполнении бланков
- Пишут неразборчиво, машина не распознает ответы
5 ОБИДНЫХ ОШИБОК, НА КОТОРЫХ УЧАЩИЕСЯ ПОТЕРЯЛИ БАЛЛЫ

Употребляют слова в неправильной форме
- В основном это касается глаголов, но попадаются существительные, числительные и местоимения. Например: предлагается числительное one , в предложении оно должно стать порядковым first . Школьники употребляют все что угодно: от once (однажды) до third (третий).

Не так согласовывают времена
- Встречается много ошибок на применение страдательного залога, перфектных времен, будущего времени в прошедшем. Например: «Он спросил, когда я приду домой». Если на уроке все понимают, что идет отработка будущего в прошедшем, то на экзамене это требуется понять из контекста.

Некорректно строят слова
- Часто ученики ошибаются в словообразовании. Например, они знают суффикс -able и используют слово changeable (непостоянный, переменчивый) вместо flexible (гибкий, уступчивый). Или допускают орфографические ошибки в суффиксах и приставках. Например, в словах с -ful ( beautiful , successful ) пишут две буквы « l ».

Не понимают задание
- Самое трудное в разделе «Чтение» — это задание, в котором нужно выбрать из трех вариантов ответа: высказывание соответствует тексту, высказывание не соответствует тексту или же в тексте об этом ничего не сказано ( true, false, not stated ). Школьники путают false и not stated . Дети рассуждают так: «Если я не нашел информации об этом в тексте, значит, это неверно».

Переводят с ошибками
- Иногда школьники попадаются на «ложных друзей переводчика» или просто на устоявшиеся «неполные» переводы. Типичная ситуация, когда слово holidays они воспринимают как «каникулы», а не как «праздники», и на вопрос «How do you celebrate your favorite holidays?» отвечают неверно.

Типичные ошибки обучающихся, допускаемые в разделе «Чтение».
- Что встретилось наиболее часто?
- Невнимательное прочтение инструкции к заданию и, соответственно, неправильное занесение ответов в бланк ответов (например, экзаменуемые заносят в бланк лишние символы или заносят ответ в неправильные позиции бланка).
- Попытка дать ответ на тестовое задание, основываясь на значении отдельного слова.
- Неправильное определение ключевых слов, соответствующих теме текста.
- Попытка найти в тексте лексику, использованную в вопросе без подбора синонимов или синонимичных выражений к словам из текста.
- Выбор ответа в задании на основании только грамматической формы или только на лексическом наполнении фразы.
![Примеры типичных ошибок: Неправильно произносят звуки [s], [θ], [ð], Замена звуков друг другом, неправильное произношение [f], [v], [w] Оглушение звонких согласных в конце слова – например, plays [z], reads [z], Одинаковое произношение долгих и кратких гласных [ɑː] – [ʌ], [iː] – [ɪ]; [ɔː] – [ɒ]; [u:] – [u], [ɔː] и [ɜː], Неиспользование «связующего r».](https://fsd.multiurok.ru/html/2022/10/21/s_6352b39cd0343/img9.jpg)
Примеры типичных ошибок:
- Неправильно произносят звуки [s], [θ], [ð],
- Замена звуков друг другом, неправильное произношение [f], [v], [w]
- Оглушение звонких согласных в конце слова – например, plays [z], reads [z],
- Одинаковое произношение долгих и кратких гласных [ɑː] – [ʌ], [iː] – [ɪ]; [ɔː] – [ɒ]; [u:] – [u], [ɔː] и [ɜː],
- Неиспользование «связующего r».

При выполнении заданий раздела «Чтение» следует обращать внимание на следующие аспекты:
— Следует приучать учащихся внимательно читать инструкцию к выполнению задания и извлекать из неё максимум информации.
— Для овладения определенной стратегией чтения и контроля определенного блока умений целесообразно использовать определенные типы и жанры аутентичных текстов;
— Необходимо развивать языковую догадку учащихся.
— Следует приучать учащихся не стремиться понять каждое слово в тексте.

При выполнении заданий раздела «Чтение» следует обращать внимание на следующие аспекты:
— Следует учить учащихся находить ключевые слова в тексте, необходимые для понимания основного содержания, и обращать их внимание на то, что даже если они не точно знают значение слов, от которых не зависит понимание основного содержания, это не повлияет на результат выполнения задания.
— Если по заданию требуется понять тему или основную идею микротекста, учащийся должен быть приучен внимательней читать первое и последнее предложения, где обычно заключена тема или идея.

Типичные ошибки обучающихся, допускаемые в разделе «Аудирование»
- 1. При выполнении задания на установление соответствия некоторые экзаменуемые:
- невнимательно читают инструкцию к заданию и соответственно неправильно заносят ответы в бланк ответов;
- неверно определяют ключевые слова, соответствующие основной мысли высказывания в микротекстах;
- осуществляют соответствие, исходя из выбранного из контекста слова, а не на основе общего понимания услышанных микротекстов.

Типичные ошибки обучающихся, допускаемые в разделе «Аудирование»
- 2. В задании с выбором ответа:
- выбирают ответ без опоры на текст, исходя из собственных представлений и общих знаний;
- исходят не из содержания текста, а из своего социального опыта, в то время как в тексте данной информации нет;
- · экзаменуемые не соотносят ключевые слова в вопросах и в аудиотекстах.

При выполнении заданий раздела «Аудирование» следует обращать внимание на следующие аспекты:
— следует обращать внимание обучающихся на то, что внимательное прочтение инструкции позволяет извлечь из неё всю полезную информацию;
- следует ставить задачу выделять при прослушивании аудиотекстов ключевые слова в заданиях и подбирать соответствующие синонимы;
— следует обращать внимание учащихся на то, что выбор ответа в заданиях на полное понимание прослушанного должен быть основан только на той информации, которая звучит в тексте, а не на том, что о ней думают или знают по предложенному вопросу.

Типичные ошибки обучающихся, допускаемые в разделе «Грамматика и лексика «
- Невнимание к контексту, и, как следствие, неправильное использование видовременных форм и форм страдательного залога
- Незнание форм неправильных глаголов
- Подмена причастием I причастием II и наоборот
- Неправильное употребление неличных форм глагола
- Образование от опорных слов однокоренных слов не той части речи, которая требуется по контексту
- Заполнения пропуска опорным словом без изменения его
- Употребление несуществующих слов
- Использование неправильного отрицательного префикса
- Неправильное написание слов
- Неумение правильно подобрать слова из ряда предложенных
- Незнание устойчивых выражений, идиом и фразовых глаголов

Что вызвало наибольшие трудности в этом разделе?
- Наибольшую трудность для учащихся представляет форма страдательного залога в Past и Present Indefinite. Типичной ошибкой также является использование активной формы Past и Present Indefinite вместо пассивной формы (asked вместо was asked; invited вместо was invited).
- Встречается также ошибочное употребление вместо Past и Present Indefinite Passive форм глаголов в Present или Past Perfect Active, Past или Present Progressive Active. Есть ошибки, вызванные незнанием того, как образуется форма Past Indefinite Passive, когда учащиеся вместо 3-ей формы глагола употребляли 2-ую (was wrote вместо was written).

Трудности возникли и с этим
- Другая разновидность ошибок при образовании Past и Present Indefinite Passive связана с неправильным употреблением формы вспомогательного глагола to be (are printed вместо is printed). Эта же ошибка встречается в использовании глагола to be для образования видовременных форм группы Progressive и даже в простейшем случае его использования в качестве глагола-связки в составном именном сказуемом.
- Использование неличных форм глагола (given, giving) вместо соответствующих личных форм активного и страдательного залогов говорит о том, что некоторые тестируемые не видят структуры предложения, в соответствии с которой в пропуск после подлежащего должна быть вписана соответствующая форма сказуемого.

С чем связано наибольшее количество ошибок?
- Наибольшее количество ошибок связано с использованием вместо Present Perfect – Present и Past Indefinite. По-видимому, это обусловлено незнанием случаев употребления соответствующих видовременных форм и недостаточной сформированностью навыков их употребления.
- Некоторые ошибки обусловлены неправильным выбором формы вспомогательного глагола (has grown вместо have grown и наоборот) из-за неумения согласовать подлежащее со сказуемым.
- В отношении употребления неличных форм глагола большое количество ошибок было допущено экзаменуемыми в употреблении причастий. Эти ошибки состоят в употреблении вместо необходимой формы причастия I (taking) причастия II (taken) и наоборот, а также в употреблении вместо причастия II (taken) личных форм глагола (took) или слов, образованных от опорного с помощью суффиксов (takeness), часто не существующих в языке.

Кроме того, учащиеся допускают типичные словообразовательные ошибки:
- — наибольшую трудность представляет употребление суффиксов -er, -ly, -ness, -ency, -ion, -ation, -able, -ive, а также префиксов dis- и in-;
- — образование от опорных слов однокоренных слов не той части речи, которая требуется по контексту (вместо protection – protective, proteced или protectly);
- — заполнение пропуска опорным словом без изменения его;
- — употребление несуществующих слов (difficultness вместо difficulty, scientifics вместо scientists);
- — вместо заполнения пропуска словом с отрицательным префиксом, употребление или опорного слова без изменения, или слова, образованного с помощью суффикса (honestly, honesty вместо dishonest);
- — использование не того отрицательного префикса, который употребляется с указанным корнем (unhonest, inhonest);
- — неправильное написание слов (valueable, importent).

При выполнении заданий раздела «Грамматика и лексика» следует обращать внимание на следующие аспекты:
— Для ознакомления и тренировки в употреблении видовременных форм глагола использовать связные тексты, которые помогают понять характер обозначенных в нем действий и время, к которому эти действия относятся.
— При обучении временам глагола обращать больше внимания на те случаи употребления времен, когда в предложении не употреблено наречие времени, а использование соответствующей видовременной формы глагола обусловлено контекстом.
— Использовать при обучении достаточное количество тренировочных заданий, в которых сопоставляются разные возможные формы вспомогательного глагола и при выполнении которых учащиеся в нужной мере закрепляют навык употребления подходящей формы глагола в зависимости от подлежащего в предложении.

При выполнении заданий раздела «Грамматика и лексика» следует обращать внимание на следующие аспекты:
— Особое внимание уделять формам глагола to be и to have как вспомогательным глаголам.
— При обучении словообразованию английского языка уделять особое вниманию использованию суффиксов –ic, -ful, -ly, , -able, -ion, -tion, -al, -er, — ity, -ive, вызвавших наибольшее число затруднений у выпускников .
— Использовать для отработки грамматических навыков задания, в которых употребление соответствующей видовременной формы глагола осуществляется с учетом правила согласования времен.
— Обращать внимание учащихся на структуру и смысл предложений и соблюдение порядка слов, соответствующих построению предложений в английском языке.

При выполнении заданий раздела «Грамматика и лексика» следует обращать внимание на следующие аспекты:
— При обучении грамматическим формам требовать от учащихся правильного написания слов, т. к. неправильное написание лексических единиц в разделе «Грамматика и лексика» приводит к тому, что тестируемый получает за тестовый вопрос 0.
— При обучении лексике уделять внимание вопросам сочетаемости лексических единиц.
— Показывать, как грамматическая конструкция влияет на выбор лексической единицы, учить видеть связь между лексикой и грамматикой. —

Типичные ошибки при выполнении заданий в разделе «Письмо»
- учащиеся допустили следующие ошибки:
- — не определили стиль письма (официальный, неофициальный) в зависимости от адресата и вида задания. Не смогли придерживаться выбранного стиля на протяжении всего задания
- — неполное и/или неточное выполнение задания.
- — невнимательно прочли инструкции к заданию, не сумели извлечь из инструкции максимум информации.
- — не соблюли требований по объёму, указанному в тестовом задании. Имеет место недостаточный объем письменного высказывания, как и значительное превышение заданного объема, которые привели к снижению баллов.

При выполнении заданий раздела «Письмо» следует обращать внимание на следующие аспекты:
— Необходимо научить учащихся внимательно читать инструкцию к заданию, извлекать из нее максимум информации, видеть коммуникативную задачу и формальные ограничения (рекомендуемое время выполнения, требуемый объем).
— Формировать у учащихся умение писать различные виды письменных продуктов с учетом специфики коммуникативной задачи определенного типа и вытекающие из этой коммуникативной задачи особенности каждого вида, в частности, стиль (официальный, неофициальный).

При выполнении заданий раздела «Письмо» следует обращать внимание на следующие аспекты:
— Формировать умение делить текст на абзацы, которые отражают логическую и содержательную структуру текста, использовать средствам логической связи текста, как внутри предложений, так и между предложениями.
- — Совершенствовать умение учащихся планировать, анализировать и редактировать свое письменное высказывание.

Спасибо за внимание!
Ошибаться, конечно же, неприятно. Однако ошибки — это главный источник нашего жизненного опыта. Каждая из них делает нас немного мудрее, помогает лучше понять окружающий мир и самих себя, помогает вывести на новый уровень наши навыки и личные качества.
Проблема в том, что у большинства людей «обучение на своих ошибках» происходит спонтанно и неосознанно. В результате многие совершенные ошибки ничего не добавляют в копилку их личного опыта: они воспринимаются исключительно как источник страданий, а потому очень часто повторяются снова и снова.
Сегодня мы поговорим об одной простой, но очень мощной технике саморазвития, которая называется «Работа над ошибками». Она помогает учиться на своих ошибках более сознательно, извлекать из них максимум опыта и почти сразу менять свою жизнь к лучшему.
Дневник «Работа над ошибками»
Для использования этой техники вам потребуется завести специальный дневник, который будет называться «Работа над ошибками». Это может быть бумажная тетрадь, текстовый файл на компьютере или электронная таблица.
Обратите внимание на следующее:
1. Дневник должен быть по-настоящему тайным. Не показывайте его никому, даже друзьям и близким. Еще лучше, если никто вообще не будет знать о его существовании. Дело в том, что вам придется записывать в него довольно неприятные факты о себе. И если вы знаете, что эти записи кто-то будет читать, то невольно начнете все цензурировать и приукрашать, из-за чего эффективность техники упадет в разы.
Храните дневник там, где на него никто не сможет натолкнуться даже случайно. Если вы делайте записи в файл, уберите его в какую-нибудь неприметную папку и закройте паролем.
2. Работа с дневником должна быть регулярной. Лучше всего заполнять его вечером, пока свежи воспоминания, но можно это делать и по утрам (в этом случае вы будете разбирать вчерашний день). Также можно работать с дневником один раз в неделю, например, по воскресеньям. Имейте в виду: чем больший период времени вы рассматриваете, тем больше событий ускользает от вашего взора.
Дневник может быть как обычным текстом, так и таблицей — это дело вкуса.
Если вы решили работать с электронной таблицей, закрепите в ней верхнюю строку и установите в свойствах ячеек «перенос текста». Саму таблицу размечаем следующим образом:

Если вы решили работать с обычным текстом, вам не нужно ничего размечать: просто по очереди записывайте все этапы.
Итак, приступим. Анализ ошибок в дневнике состоит из 5 этапов:
Этап 1. Вспомнить и записать ошибки
На этом этапе мы выписываем все ошибки, которые совершили за день или за неделю. Ошибками будут считаться не только наши явные промахи, но и любые неприятные события.
Дело в том, что каждое такое событие — это всегда в какой-то степени следствие наших поступков. Если же мы воспринимаем неприятности как сугубо внешние явления, мы словно говорим себе, что не контролируем ситуацию. А поверив в это, мы становимся пассивными жертвами обстоятельств и уже ничего не можем изменить.
Безусловно, бывают такие ситуации, когда от нас действительно ничего не зависит. Но очень часто это не так.
Предположим, что сегодня на нас накричал начальник. Он хам, псих и самодур? Очень может быть. Но была ли у нас возможность предотвратить конфликт? Наверняка да. Например:
- Мы могли сдать ему этот злосчастный отчет еще вчера.
- Мы могли вежливо, но твердо поставить его на место (хамство вообще терпеть не стоит).
- Мы могли найти работу с нормальным руководителем и т. д.
Если же мы снимаем с себя ответственность за эту ситуацию, мы отказываемся от активной жизненной позиции и начинаем пассивно плыть по течению.
Итак, записываем ошибки. Для этого мысленно «прокрутите» в голове весь прошедший день (или неделю) и попробуйте вспомнить следующее:
1. Какие явные промахи вы совершили?
2. Какие дела не удалось сделать? Какие планы сорвались?
3. Какие неприятности с вами произошли?
4. Из-за чего у вас портилось настроение?
5. С кем возникали конфликты и недопонимания?
Вот такой примерно список у вас может получиться:

Здесь, кстати, удобно пользоваться методом пяти пальцев, о котором мы как-то уже писали. Суть его в том, чтобы перебирать прошедшие события по жизненным сферам: мысли, знания, эмоции, общение, здоровье и т. д.
Также полезно делать пометки в течение всего дня или недели. Формулировать сами ошибки не надо: просто запишите в блокнот или на диктофон пару слов, которые помогут вам вспомнить о событии. Например: «автобус», «продавец в магазине», «удалил файл», «забыл ключи» и т. д.
После того как вы записали все ошибки, посидите еще 2–3 минуты, прежде чем двигаться дальше. Часто в эти минуты в голову приходят всякие неприметные события, о которых мы сразу не вспомнили.
Этап 2. Выявить причины ошибок
Теперь мы должны найти причину каждой записанной ошибки. Этот этап поможет нам выявить свои «слабые места» и понять, что конкретно нужно исправить. Подумайте: почему произошло то, что произошло?
Вот что примерно должно у вас получиться:

При анализе причин важно придерживаться принципа «Mea culpa» (в переводе с латыни — «моя вина»). Иными словами, мы должны в первую очередь искать причину произошедшего в своих действиях. Еще раз: мы можем что-то изменить лишь тогда, когда берем на себя ответственность за то, что произошло.
Даже если у неприятного события есть явные внешние причины, подумайте: могли ли вы его предотвратить? Могли ли вы к нему как-то подготовиться? Если да, то именно это и следует записать как причину.
Например, мы пошли в лес за грибами, попали под дождь и до нитки промокли. Дождь, естественно, случился сам по себе и на это мы повлиять никак не могли. Однако мы могли перед выходом из дома посмотреть прогноз погоды или взять с собой плащ-дождевик.
У некоторых событий может быть несколько причин — это нормально. В этом случае можно записать их все или же выбрать из них только самую главную.
Этап 3. Исправление ошибок
На этом этапе мы выясним: а нельзя ли эти ошибки хоть как-нибудь исправить? Подумайте:
- Можно ли изменить то, что произошло?
- Если нельзя, то можно ли минимизировать или компенсировать последствия этих ошибок?
Каждая ошибка — это всегда какой-то ущерб, нанесенный нашей жизни, нашим планам и нашему душевному равновесию. И в идеале было бы здорово этот ущерб если не ликвидировать, то хотя бы чуть-чуть «сгладить».
Вот как это может выглядеть:

Увы, но многие ошибки в нашей жизни исправлению не подлежат. И если эта графа часто будет оставаться у вас пустой, не переживайте: так и должно быть. Просто переходите к следующему этапу.
Этап 4. Меры профилактики
Теперь самое главное: мы должны понять, как не допустить повторения этих ошибок. На данном этапе нужно для каждой ошибки придумать свои меры профилактики. Обычно это либо правила, которые следует соблюдать, либо задачи, которые следует выполнить. Например:

Этот этап — «сердце» нашей техники. Каждая такое правило и каждая задача — это то, что помогает нам изменить свою жизнь к лучшему. Даже если сами изменения выглядят совсем небольшими, со временем они будут накапливаться и давать потрясающий результат.
Как разрабатывать меры профилактики? В первую очередь нужно смотреть в раздел «Причины»: именно там обычно и скрыт «корень проблем». Если мы устраняем причину ошибки, то исчезает и сама ошибка.
Например, я проспал на работу. У этой неприятности есть две причины: я поздно лег спать, а утром не услышал будильник на смартфоне. Теперь у меня появятся одно новое правило и одна регулярная задача:
- Ложиться спать не позднее 23–00.
- Устанавливать на смартфоне сразу два будильника с интервалом в 5 минут.
Как вы уже поняли, для одной ошибки может быть создано сразу несколько правил и задач.
Этап 5. Внедрение улучшений
Недостаточно просто придумать правила: еще нужно сделать так, чтобы эти правила сразу же начали работать и менять жизнь к лучшему. Если не внедрять их специально, они будут мертвым грузом «пылиться» в нашем дневнике. Высока вероятность, что вскоре мы о них забудем и снова допустим уже проработанные ошибки.
Поэтому на последнем этапе нужно определить: с помощью какого инструмента мы будем внедрять эти правила? Вот как это выглядит:

Рассмотрим эти инструменты чуть более подробно.
1. Разовая задача. Это задача, которую нужно выполнить всего один раз, чтобы предотвратить дальнейшее повторение ошибки или проблемы. Например, если у нас есть проблема «тормозит компьютер», нам достаточно «купить дополнительный блок ОЗУ на 16 Гб».
Задачу записываем в органайзер (если у вас его еще нет, то обязательно заведите) на тот день, когда ее удобно будет выполнить.

2. Регулярная задача. Это задача, которую нам нужно периодически повторять: каждое день, каждую субботу, каждый месяц и т. д. Например, если мы по дороге с работы постоянно забываем купить продукты, нам потребуется создать регулярную задачу-напоминание «Не нужно ли зайти в магазин?».

То же самое: создаем в органайзере новую задачу (можно привязать ее к конкретному времени) и настраиваем ее повторение. Подробнее о том, как работать с такими задачами, вы можете прочитать в нашей статье «Повторяющиеся задачи».
3. Рабочий чек-лист. Чек-листы — это очень удобный инструмент для организации любых повторяющихся процессов. Сюда относятся тренировки и занятия спортом, мероприятия по уборке, уход за питомцами, проверки, аудиты, создания типовых продуктов и т. д. Если вы регулярно пользуетесь чек-листами, вам будет легче предотвращать ошибки: допустив какой-нибудь промах, просто добавьте в чек-лист новый пункт для его профилактики.

О создании рабочих чек-листов у нас была отдельная статья.
4. Трекер привычек. Некоторые правила потребуют от нас выработки новых привычек или изменения старых. Для этой цели в тайм-менеджменте используется несколько инструментов, из которых самым популярным является трекер привычек:

Работает он очень просто: каждую привычку, которую нам нужно выработать или изменить, мы добавляем в трекер и отслеживаем ее соблюдение.
5. Личный кодекс. Это еще один очень мощный инструмент саморазвития, о котором следует как-нибудь рассказать отдельно. Он представляет собой свод персональных правил и принципов на все случаи жизни: от общения с людьми, до ухода за домом.
Для создания кодекса можно использовать блокнот, общую тетрадь или текстовый файл.

В кодексе может быть несколько разделов. Например:
- Главные правила;
- Мои моральные принципы;
- Общение с людьми;
- Бизнес;
- Клиенты;
- Здоровье;
- Автомобиль и т. п.
Чтобы кодекс работал, его нужно регулярно и вдумчиво перечитывать. В этом случае правила будут «впитываться» и становиться неотъемлемой частью нашей личности.
Теперь, когда мы разобрались с инструментами, можно подобрать для каждого правила подходящий способ внедрения. Обратите внимание: после этого вам нужно сразу же разложить все задачи и правила по «своим местам»: в органайзер, в трекер привычек и т. д. В противном случае о них можно очень быстро забыть.
Заключение
Алгоритм только на первый взгляд кажется большим и громоздким, но на практике он не отнимает много времени. Обычно «работа над ошибками» занимает не более 10–15 минут в день.
Если у вас совсем мало времени, попробуйте выполнять эту технику один раз в неделю. Также можно использовать ее упрощенный вариант: записывать не все ошибки, а только 3 самых значительных.
Наиболее частая проблема с дневником — это повторение ошибок. То есть, мы анализируем ошибку, внедряем профилактические меры, а она все равно повторяется. Здесь есть два варианта:
Вариант 1. Неправильно установлены причины. Подумайте, что еще может вызывать эту ошибку? Что вы могли упустить?
Лайфхак. У ошибки может быть много причин. Но есть и одна универсальная причина: мы совершаем ошибку потому, что у нас есть возможность ее совершать. И чтобы ошибка исчезла, достаточно устранить эту возможность.
Например, мы отвлекаемся на социальные сети во время работы. Как сделать, чтобы это стало невозможным? Тут много вариантов: выйти из всех аккаунтов, использовать другой профиль браузера или даже отключать интернет.
Вариант 2. Неправильно выбраны меры профилактики или способы их внедрения. Здесь, к сожалению, нет универсальных решений: вам придется немного поэкспериментировать.
Лайфхак. Лучше всего работают простые «механические» методы, которые не требуют размышлений и самоконтроля.
Например, ежедневно по дороге с работы мы заходим в кондитерский магазин и покупаем пирожные, набирая лишний вес и лишние комплексы. Мы, конечно же, можем здесь использовать и трекер привычек, и личный кодекс. Но гораздо проще и эффективней будет изменить свой обычный маршрут с работы.
Еще одна частая ситуация с дневником — это отсутствие серьезных поводов для записи. В этом случае, если есть настроение, можно совершить «экскурсию в прошлое» и поразмышлять над старыми ошибками. Однако вполне допустимо просто наградить себя «выходным» за удачный день.
Поделиться:
Типы
ошибок: лексическая (недопустимые
символы)
синтаксическая
(в синтаксическом анализаторе)
семантическая
(происходит на этапе семантического
анализа; пример – несоответствие типа
операнда конкретной операции)
логическая
(возникает во время выполнения; пример
— зацикливание)
Обработчик
ошибок должен:
Точно
определить место и тип ошибки,быстро
восстановиться после ошибки для
продолжения анализа
эффективно
работать при анализе корректных программ
Выделяют
несколько стратегий действия после
обнаружения ошибок:
режим
паники транслятор
пропускает символы из входной строки
до обнаружения символа из синхронизирующего
множества Недостатки:Пропускаемое
множество символов может быть очень
большим, Появление цепной реакции,
позднее проявление ошибки
уровень
фразы Недостатки:Для
каждого случая необходимо писать свою
процедуру ошибок
продукции
ошибок Добавляется
ошибочная ситуация, тогда синтаксический
анализатор обнаруживает ошибку,
локализует ее, восстанавливается и
работает дальше.
Недостатки:Описывает
только ограниченные и ранее известные
типы ошибок
глобальная
коррекция необходимо
минимально видоизменить программу,
чтобы она преобразовалась в синтаксически
корректную Недостатки:Сложность
реализации
20 Семантика языка, методы описания и анализа.
-
Фаза
контроля типов -
Идентификация.
Работа с таблицами -
Идентификация.
Работа с типами -
Причины
использования промежуточных языков в
компиляторах -
Различные
формы представления промежуточных
языков (ПЯ) в компиляторах:-
Атрибутивные
деревья разбора -
Прямая
и обратная польские записи -
Триады/тетрады
-
RTL
-
На
этапе семантического анализа можно:
Проверить
соответствие типов
Проверить
управление (различных переходов)
Проверить
единственность (чтобы один раз объявлялась
переменная или функция)
Проверить
имена (чтобы имя встречалось определенное
количество раз)
Сравнение
может быть статическим
(на этапе трансляции) и динамическим
(во время выполнения).
Приведение
типов
Расширяющее
(short
-> long)
Сужающее
(long
-> short)
Формализм
атрибутных грамматик оказался очень
удобным средством для описания семантики
языков программирования
21 Понятие атрибутивные грамматики
входит
в раздел синтаксически управляемые
грамматики.
Для
каждого символа грамматики вводится
атрибут val
Вместе
с правилами грамматики записываются
семантические правила, которые вычисляют
значение этих атрибутов.Процесс
построения дерева разбора, а затем
вычисления атрибутов (нетерминал к
терминалу) и называется синтаксически
управляемой трансляцией
Атрибутивная
грамматика содержит:Синтаксические
правила. Для каждого элемента грамматики
– множество атрибутов.Для каждого
правила – множество семантических
правил
Атрибуты
бывают:Синтезируемые.Наследуемые
Семантическая
часть правила состоит из локальных
объявлений и семантических действий.
В качестве семантических действий
допускаются как атрибутные присваивания,
так и составные операторы.
Метка
в семантической части правила привязывает
выполнение оператора к обходу дерева
разбора сверху-вниз слева направо.
Конструкция i : оператор означает,
что оператор должен быть выполнен сразу
после обхода i-й компоненты правой части.
Конструкция i E : оператор
означает, что оператор должен быть
выполнен, только если порождение i-й
компоненты правой части пусто. Конструкция
i A : оператор означает, что
оператор должен быть выполнен после
разбора каждого повторения i-й компоненты
правой части (имеется в виду конструкция
повторения).