Efficient Standard Errors in Item Response Theory Models for Short Tests
Lianne Ippel et al.
Educ Psychol Meas.
2020 Jun.
Free PMC article
Abstract
In dichotomous item response theory (IRT) framework, the asymptotic standard error (ASE) is the most common statistic to evaluate the precision of various ability estimators. Easy-to-use ASE formulas are readily available; however, the accuracy of some of these formulas was recently questioned and new ASE formulas were derived from a general asymptotic theory framework. Furthermore, exact standard errors were suggested to better evaluate the precision of ability estimators, especially with short tests for which the asymptotic framework is invalid. Unfortunately, the accuracy of exact standard errors was assessed so far only in a very limiting setting. The purpose of this article is to perform a global comparison of exact versus (classical and new formulations of) asymptotic standard errors, for a wide range of usual IRT ability estimators, IRT models, and with short tests. Results indicate that exact standard errors globally outperform the ASE versions in terms of reduced bias and root mean square error, while the new ASE formulas are also globally less biased than their classical counterparts. Further discussion about the usefulness and practical computation of exact standard errors are outlined.
Keywords:
ability estimation; asymptotic standard error; exact standard error; item response theory.
© The Author(s) 2019.
Conflict of interest statement
Declaration of Conflicting Interests: The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Figures
Simulation results of maximum likelihood (ML) for the one-parameter logistic (1PL) model, averaged over 1,000 test takers per ability level, and 1,000 tests. Simulation results of weighted likelihood (WL) for the oe-parameter logistic (1PL) model, averaged over 1,000 test takers per ability level, and 1,000 tests. Simulation results of Bayes modal (BM) for the one-parameter logistic (1PL) model, averaged over 1,000 test takers per ability level, and 1,000 tests. Simulation results of robust estimator (ROB) for the one-parameter logistic (1PL) and two-aarameter logistic (2PL) models, averaged over 1,000 test takers per ability level, and 1,000 tests.
Figure 1.

Figure 2.

Figure 3.

Figure 4.
Similar articles
-
Efficient Standard Error Formulas of Ability Estimators with Dichotomous Item Response Models.
Magis D.
Magis D.
Psychometrika. 2016 Mar;81(1):184-200. doi: 10.1007/s11336-015-9443-3. Epub 2015 Feb 18.
Psychometrika. 2016.PMID: 25691364
-
On the asymptotic standard error of a class of robust estimators of ability in dichotomous item response models.
Magis D.
Magis D.
Br J Math Stat Psychol. 2014 Nov;67(3):430-50. doi: 10.1111/bmsp.12027. Epub 2013 Sep 10.
Br J Math Stat Psychol. 2014.PMID: 24016181
-
Asymptotic Variance of Linking Coefficient Estimators for Polytomous IRT Models.
Andersson B.
Andersson B.
Appl Psychol Meas. 2018 May;42(3):192-205. doi: 10.1177/0146621617721249. Epub 2017 Aug 24.
Appl Psychol Meas. 2018.PMID: 29881121
Free PMC article. -
A primer on classical test theory and item response theory for assessments in medical education.
De Champlain AF.
De Champlain AF.
Med Educ. 2010 Jan;44(1):109-17. doi: 10.1111/j.1365-2923.2009.03425.x.
Med Educ. 2010.PMID: 20078762
Review.
-
The value of item response theory in clinical assessment: a review.
Thomas ML.
Thomas ML.
Assessment. 2011 Sep;18(3):291-307. doi: 10.1177/1073191110374797. Epub 2010 Jul 19.
Assessment. 2011.PMID: 20644081
Review.
Cited by
-
Estimating and Using Block Information in the Thurstonian IRT Model.
Frick S.
Frick S.
Psychometrika. 2023 Aug 28. doi: 10.1007/s11336-023-09931-8. Online ahead of print.
Psychometrika. 2023.PMID: 37640828
References
-
-
Baker F. B., Kim S.-H. (2004). Item response theory: Parameter estimation techniques (2nd ed.). New York, NY: Marcel Dekker.
-
-
-
Birnbaum A. (1969). Statistical theory for logistic mental test models with a prior distribution of ability. Journal of Mathematical Psychology, 6, 258-276.
-
-
-
Bock R. D., Mislevy R. J. (1982). Adaptive EAP estimation of ability in a microcomputer environment. Applied Psychological Measurement, 6, 431-444.
-
-
-
Breslow N. E., Clayton D. G. (1993). Approximate inference in generalized linear mixed models. Journal of the American Statistical Association, 88(421), 9-25.
-
-
-
De Boeck P., Wilson M. (2004). Explanatory item response models: A generalized linear and nonlinear approach. New York, NY: Springer.
-
LinkOut — more resources
-
Full Text Sources
- Atypon
- Europe PubMed Central
- PubMed Central

Добавил:
Upload
Опубликованный материал нарушает ваши авторские права? Сообщите нам.
Вуз:
Предмет:
Файл:
Скачиваний:
265
Добавлен:
14.05.2015
Размер:
9.84 Mб
Скачать
![]()
Глава 2. Взаимосвязь переменных
Что такое «первый прогноз» при модальном прогнозе? Это мо дальное значение предсказываемой переменной, обозначим его как Л, а процент, который соответствует значению А, — как Рг А. При таком обозначении ошибка при первом прогнозе будет Pt = 1 -РгА.
При втором прогнозе мы анализируем по очереди каждую строку таблицы и выбираем в каждой строке модальную частоту. Пусть модаль ное значение в каждой строке будет А., а соответствующий процент — Рг А .. Соответственно ошибка при предсказании значения в г’-й строке составит Р = 1 — Рг А.. Таким образом, ошибка при втором прогнозе будет средней ошибкой предсказания по каждой из строк таблицы:
(2.5)
Формула коэффициента, фиксирующего улучшение прогноза теременной, значение которой располагаются по столбцам таблицы, выглядит следующим образом:
(2.6)
У обсуждаемого коэффициента есть одна особенность, отличаю щая его от коэффициента %2. В вычислении Хь строки и столбцы уча ствуют не симметрично. Разумеется, таблицу можно повернуть на 90% и с точки зрения содержащейся в таблице информации от этой операции ничего не изменится. При таком повороте не изменятся значения коэффициентов %2 и коэффициентов, основанных на %2. Однако значение коэффициента Хь изменится. Это связано с тем, что в модели коэффициента Хь мы предсказываем значение одной пере менной на основании значений другой и переменные включены в модель не симметрично. Фактически одна переменная рассматрива ется как причина, а другая как следствие.
В этой связи наряду с переменной Хь, которая фиксирует пред сказание переменной, расположенной по колонкам таблицы, суще ствует и переменная Ха, которая отражает улучшение предсказания
2.3. Коэффициенты связи для номинальных переменных
переменной, расположенной по строкам на основании переменной, расположенной по столбцам. Наконец, когда мы не можем четко ска зать, какая из переменных может рассматриваться как причина, а ка кая как следствие, существует так называемая Xs , т.е. «лямбда сим метричная», представляющая полусумму Хаи Ху
Поскольку коэффициенты X, так же как и %2 — статистические меры, то в их отношении встает задача оценки уровня значимости. Действительно, если для некоторой таблицы был получен коэффици ент, скажем, Хь = 0,1, можем ли мы утверждать, что некоторая связь между переменными действительно есть, и это значение не есть про сто статистическая случайность. Другими словами, требуется прове рить статистическую гипотезу Хь = 0 на основании полученного вы борочного значения Хь = 0,1.
Логика проверки данной статистической гипотезы совершенно аналогична логике проверки гипотезы о равенстве нулю коэффици ента X2. Нам требуется знание теоретического распределения коэф фициента X, которое покажет нам, насколько вероятно то или иное значение коэффициента X. При вычислении коэффициентов А, в па кете SPSS в команде Crosstabs одновременно проводится вычисление уровней значимости а этих коэффициентов. Если коэффициент X ра вен, скажем, значению Х0, уровень значимости этого значения опре деляется так: а = Р (X > Х0) при условии, что в генеральной совокуп ности X = 0.
Достоинством коэффициентов X является то, что в отличие от коэффициента %2 либо производных от него само значение Ха и Хь имеет непосредственный смысл — это улучшение вероятности пра вильного предсказания. Иначе говоря, если для некоторой таблицы *j ~ 0,2, это означает, что мы можем предсказывать модальное значе ние переменной, располагающейся по колонкам, зная совместное рас пределение двух переменных на 20% точнее по сравнению с ситуаци- еи, когда мы не знаем этого распределения.
Однако это значение весьма условно. Действительно, коэффи циенты X являются статистическими мерами и потому точное полу ченное значение коэффициента бессмысленно. Ведь мы можем повто-
Глава 2. Взаимосвязь переменных
рить опрос для другой выборки (с соблюдением той же процедуры ее построения) и тем не менее почти наверняка получим другое значение коэффициента X, поскольку будут опрашиваться другие респонденты. Следовательно, гораздо важнее получить не точечное значение коэф фициентов X, а доверительный интервал.
При вычислении коэффициентов X командой Crosstabs наряду с точечными значениями вычисляются также и величины стандартных ошибок. Стандартные ошибки позволяют построить доверительные интервалы с задаваемыми уровнями значимости. В табл. 2.6 приве ден фрагмент таблицы, выдаваемой командой Crosstabs, в которой вычислены коэффициенты X, соответствующие стандартные ошибки и уровни значимости для проверки гипотезы о равенстве нулю этих коэффициентов для данных табл. 2.1.
|
Таблица 2.6. |
Значения коэффициентов X и связанных |
|||||
|
с ними статистических показателей |
||||||
|
для данных табл. 2.1 |
||||||
|
X |
Value |
Asymp. Std. |
Ap |
Approx. |
||
|
Error» |
prox. T4 |
Sig. |
||||
|
Symmetric |
0,017 |
0,018 |
0,942 |
0,346 |
||
|
«Как бы вы оценили в настоя |
0,032 |
0,033 |
0,947 |
0,344 |
||
|
щее время материальное поло |
||||||
|
жение вашей семьи?» |
||||||
|
Dependent |
||||||
|
«Как бы вы оценили в целом |
0,001 |
0,010 |
0,103 |
0,918 |
||
|
политическую обстановку |
||||||
|
в России?» |
||||||
|
Dependent |
||||||
Таблица 2.6 содержит одновременно все три коэффициента X — X (строка Symmetric), Xa (следующая за Symmetric строка) и Хь (по следняя строка). В колонке Value расположены значения соответствую щих коэффициентов, а в последней колонке {Approx. Sig.) -— уровни значимости для проверки гипотез о равенстве нулю этих коэффици-
2.3. Коэффициенты связи для номинальных переменных
ентов. Находящееся в этой колонке значение имеет смысл сравнить с заранее выбранным уровнем значимости, снова обозначим его а (в статистике чаще всего используется а = 0,05). Если наше значение больше а, гипотезу следует принять, если меньше — отвергнуть.
Из табл. 2.6 видно, что при уровне значимости а = 0,05 следует принять гипотезу о равенстве нулю всех трех коэффициентов — A.s , X , Хь (так как все значения в колонке Approx. Sig. превосходят 0,05).
. Таблица 2.6 содержит еще две колонки, одна из которых—Asymp. Std. Error (асимптотическая стандартная ошибка) дает нам информа цию, необходимую для построения доверительных интервалов. Напомним, что 68%-й доверительный интервал дает Х± (одна стан дартная ошибка); 95%-й доверительный интервал — Х± (две стан дартные ошибки).
Графа Approx. T — вспомогательная, и обозначает отношение значения коэффициента Хк величине его стандартной ошибки. Отме тим, что данный показатель Т широко распространен в разных разде лах статистики. Фактически он показывает, как соотносится изме ренное значение с ошибкой измерения и характеризует то, насколько мы можем доверять полученным коэффициентам. Поясним смысл это го показателя на примере. Предположим, что мы взвешиваем спичку на обычных бытовых весах и получаем, что спичка весит 2 г. Однако точность наших весов составляет ± 10 г. В данном примере показа тель Т = 0,2 и едва ли мы будем всерьез относиться к полученному значению веса спички. Таким образом, чем больше значение Т, тем выше качество полученного измерения.
Из приведенных формул коэффициентов X следует, что у них есть очень существенный недостаток — в том случае, когда все мо дальные частоты лежат в одной колонке либо в одной строке табли цы, соответствующие коэффициенты всегда обращаются в нуль. Та ким образом, равенство нулю коэффициентов ХМЩ Xt— это необходи мое, но не достаточное условие для независимости переменных, об разующих таблицу.
Последнее свойство весьма неудобно. Действительно, хотелось бы иметь коэффициенты, которые обладают естественным свойством —

Глава 2. Взаимосвязь переменных
равенство нулю всегда говорит о независимости. Этим качеством об ладают коэффициенты, также основанные на прогнозе, но в которых прогнозируется не модальная частота, а весь спектр частот. Это коэф фициенты т (тау) Гудмена — Краскэла.
Общая идея оценки качества прогноза для коэффициентов т записывается выражением (2.4), так же как и для коэффициентов X, однако сам прогноз строится иначе. Рассмотрим это подробнее.
Из табл. 2.2 следует, что переменная ql2 «Как бы вы оценили в целом политическую обстановку в России?» имеет следующее одно мерное распределение (табл. 2.7). Случайным образом отберем 2407 респондентов и, базируясь на приведенном одномерном распределе нии, попытаемся угадать ответы каждого на вопрос ql2. Возьмем 43 респондента и скажем, что они отметили в этом вопросе града цию «1». Поскольку вероятность выбора первой градации составляет 1,8%, количество людей, у которых мы правильно угадаем первый вариант ответа, составляет 43 х 0,018 = 0,774. Аналогичным образом поступим со всеми 2407 респондентами (последняя колонка табл. 2.6).
|
Таблица 2.7. |
Одномерное частотное распределение |
||||
|
переменной ql2 и результаты предсказания |
|||||
|
этого распределения |
|||||
|
1 |
N |
% |
Количество правильно |
||
|
предсказанных ответов |
|||||
|
Благополучная, спокойная |
43 |
1,8 |
0,774 |
||
|
Напряженная |
692 |
28,7 |
198,604 |
||
|
Критическая, взрывоопасная |
1429 |
59,4 |
848,826 |
||
|
Затрудняюсь ответить |
243 |
10,1 |
24,543 |
||
|
N |
2407 |
100 |
1072,747 |
||
Таблица 2.7 показывает, что из 2407 отобранных респондентов, используя предлагаемую модель предсказания, мы сумели правильно предсказать выбор у 1072,747 респондентов. Таким образом, общее ка чество такого прогноза, который базируется только на знании одномер ного распределения переменной ql2, составляет 1072,747 / 2407 = 44,57%.
66
2.4. Коэффициенты связи для порядковых данных
Далее строим модель предсказания, базируясь уже на данных таб лицы двумерного распределения переменных qlO и ql2, т.е. будем использовать для предсказания значений ql2 значения перемен ной qlO. В табл. 2.8 приведен расчет такого предсказания для первой строки таблицы совместного распределения.
|
Таблица 2.8. |
Таблица расчетов коэффициента |
||||||
|
пропорционального предсказания |
|||||||
|
Как бы вы оценили |
Как бы вы оценили в целом |
Все |
|||||
|
в настоящее время |
политическую обстановку в России? |
го |
|||||
|
материальное |
|||||||
|
благопо |
напря |
критичес |
затруд |
||||
|
положение вашей |
лучная, |
женная |
кая, |
няюсь |
|||
|
семьи? |
спокойная |
взрыво |
ответить |
||||
|
опасная |
|||||||
|
Хорошее, |
N |
12 |
48 |
47 |
17 |
124 |
|
|
очень |
% |
9,7 |
38,7 |
37,9 |
13,7 |
100,0 |
|
|
хорошее |
Количество |
1,164 |
18,576 |
17,813 |
2,329 |
39,882 |
|
|
респондентов |
|||||||
|
с правильным |
|||||||
|
прогнозом |
|||||||
2.4
Коэффициенты связи для порядковых данных
В предыдущих рассуждениях о таблицах сопряженности и коэффици ентах связи не делалось никаких ограничений либо допущений в отношении уровня измерения тех переменных, которые образуют таб лицу. Не использовалась и информация о порядке следования града ций в переменных. Очевидно, что если мы поменяем местами града-
67

Глава 2. Взаимосвязь переменных
ции переменных, это никоим образом не скажется на значении коэф фициентов х2, Крамера, Хкх.
Это является естественным для переменных, измеренных на но минальном уровне. Действительно, номера, которые присваиваются градациям в таких переменных, имеют абсолютно условный смысл. Так, совершенно не имеет значения, присвоен ли в вопросе «Ваш пол» мужчинам код 1, 2 или 28. Главное, чтобы код, присвоенный мужчинам, отличался от кода, присвоенного женщинам.
По этой причине то, что коэффициенты связи никак не реагиру ют на наш произвол в присвоении определенным градациям тех или иных числовых кодов, является вполне правильным для случая, когда исходные данные получены по номинальным шкалам.
Однако эти рассуждения становятся неверными, когда речь захо дит о переменных, измеренных на порядковом уровне. Для такого рода переменных порядок расположения градаций уже существен, посколь ку он фиксирует степень выраженности измеряемого свойства. Изме рение взаимосвязи в таблицах, построенных с использованием по рядковых переменных, вполне возможно и нередко делается с исполь зованием коэффициентов %2, Крамера, X и т. Но эти коэффициенты не используют данные о порядке следования градаций и, следова тельно, лишают нас возможности использовать всю содержащуюся в переменных информацию. Для того чтобы устранить этот недоста ток, наряду с перечисленными коэффициентами, для порядковых пе ременных используют и другие меры связи — коэффициенты ранго вой корреляции.
Для демонстрации принципов работы коэффициентов ранго вой корреляции рассмотрим пример (табл. 2.9). Таблица должна от ветить на вопрос о том, насколько взаимосвязаны оценка человеком своего материального положения и оценка удовлетворенности жиз нью в целом.
Коэффициенты %2 и Крамера, вычисленные для этой таблицы, показывают, что с большой вероятностью можно утверждать о нали чии взаимосвязи между двумя рассматриваемыми показателями, по скольку значимость обоих коэффициентов весьма высока (а > 0,001)-
68
2.4. Коэффициенты связи для порядковых данных
Однако эти коэффициенты не дают ответа на важный вопрос: воз растает или падает удовлетворенность жизнью в целом с ростом удов летворенности материальным положением? На интуитивном уровне представляется, что удовлетворенность жизнью должна возрастать с ростом удовлетворенности материальным положением, но коэффици енты не дают возможности это зафиксировать либо хотя бы проверить направление взаимосвязи.
Таблица 2.9. Таблица сопряженности с использованием порядковых переменных
|
В какой мере вас |
Как бы вы оценили в настоящее время |
Все |
||||
|
устраивает жизнь, |
материальное положение вашей семьи? |
го |
||||
|
которую вы ведете? |
||||||
|
очень |
хоро |
сред |
пло |
очень |
||
|
хорошее |
шее |
нее |
хое |
плохое |
||
|
Вполне устраивает |
5 |
39 |
109 |
8 |
3 |
164 |
|
По большей части |
3 |
35 |
284 |
15 |
5 |
342 |
|
устраивает |
||||||
|
Отчасти устраивает, |
0 |
31 |
649 |
201 |
14 |
895 |
|
отчасти нет |
||||||
|
По большей части |
1 |
3 |
200 |
340 |
55 |
599 |
|
не устраивает |
||||||
|
Совершенно |
1 |
1 |
49 |
185 |
118 |
354 |
|
не устраивает |
||||||
|
Всего |
10 |
109 |
1291 |
749 |
195 |
2354 |
В настоящее время социологи используют коэффициенты ран говой корреляции — р Спирмена, т Кендэла, у Гудмена — Краскэла. Рассмотрим правила вычисления коэффициента у Гудмена — Краскэ ла как самого простого и часто используемого при анализе социоло гических данных.
На первом шаге вычисления коэффициента у фиксируют коли чество респондентов, у которых значение первой переменной не мень- ше значений второй переменной. Например, в табл. 2.9 у пяти респон дентов значения обоих переменных равны 1, у 35 респондентов — Равны 2 и т.д.
69

Глава 2. Взаимосвязь переменных
Таблица 2.10. Схема определения показателя S для вычисления коэффициента у
Шаг!
|
В какой мере вас |
Как бы вы оценили в настоящее время |
Все |
||||||
|
устраивает жизнь, |
материальное положение вашей семьи? |
го |
||||||
|
которую вы ведете? |
||||||||
|
очень |
хоро |
сред |
пло |
очень |
||||
|
хорошее |
шее |
нее |
хое |
плохое |
||||
|
Вполне устраивает |
5 |
39 |
109 |
8 |
3 |
164 |
||
|
По большей части |
3 |
35 |
284 |
15 |
5 |
342 |
||
|
устраивает |
||||||||
|
Отчасти устраивает, |
31 |
649 |
201 |
14 |
895 |
|||
|
отчасти нет |
||||||||
|
По большей части |
1 |
3 |
200 |
340 |
55 |
599 |
||
|
не устраивает |
||||||||
|
Совершенно |
1 |
1 |
49 |
185 |
118 |
354 |
||
|
не устраивает |
||||||||
|
Всего |
10 |
109 |
1291 |
749 |
195 |
2354 |
||
|
Шаг 2 |
||||||||
|
В какой мере вас |
Как бы вы оценили в настоящее время |
Все |
||||||
|
устраивает жизнь, |
материальное положение вашей семьи? |
го |
||||||
|
которую вы ведете? |
||||||||
|
очень |
хоро |
сред |
пло |
очень |
||||
|
хорошее |
шее |
нее |
хое |
плохое |
||||
|
Вполне устраивает |
5 |
39 |
109 |
8 |
3 |
164 |
||
|
По большей части |
3 |
35 |
284 |
15 |
5 |
342 |
||
|
устраивает |
||||||||
|
Отчасти устраивает, |
31 |
649 |
201 |
14 |
895 |
|||
|
отчасти нет |
||||||||
|
По большей части |
1 |
3 |
200 |
340 |
55 |
599 |
||
|
не устраивает |
||||||||
|
Совершенно |
1 |
1 |
49 |
185 |
118 |
354 |
||
|
не устраивает |
||||||||
|
Всего |
10 |
109 |
1291 |
749 |
195 |
2354 |
||
|
70 |
2.4. Коэффициенты связи для порядковых данных
Ц1агЗ
|
В какой мере вас |
Как бы вы оценили в настоящее время |
Все |
||||||||||||||||
|
устраивает жизнь, |
материальное положение вашей семьи? |
го |
||||||||||||||||
|
которую вы ведете? |
||||||||||||||||||
|
очень |
хоро |
сред |
пло |
очень |
||||||||||||||
|
хорошее |
шее |
нее |
хое |
плохое |
||||||||||||||
|
Вполне устраивает |
5 |
39 |
109 |
8 |
3 |
164 |
||||||||||||
|
По большей части |
3 |
35 |
284 |
15 |
5 |
342 |
||||||||||||
|
устраивает |
||||||||||||||||||
|
Отчасти устраивает, |
31 |
649 |
201 |
14 |
895 |
|||||||||||||
|
отчасти нет |
||||||||||||||||||
|
По большей части |
1 |
3 |
200 |
340 |
55 |
599 |
||||||||||||
|
не устраивает |
||||||||||||||||||
|
Совершенно |
1 |
1 |
49 |
185 |
118 |
354 |
||||||||||||
|
не устраивает |
||||||||||||||||||
|
Всего |
10 |
109 |
1291 |
749 |
195 |
2354 |
||||||||||||
|
Шаг 4 |
||||||||||||||||||
|
В какой мере вас |
Как бы вы оценили в настоящее время |
Все |
||||||||||||||||
|
устраивает жизнь, |
материальное положение вашей семьи? |
го |
||||||||||||||||
|
которую вы ведете? |
||||||||||||||||||
|
очень |
хоро |
сред |
пло |
очень |
||||||||||||||
|
хорошее |
шее |
нее |
хое |
плохое |
||||||||||||||
|
Вполне устраивает |
5 |
39 |
109 |
8 |
3 |
164 |
||||||||||||
|
По большей части |
3 |
35 |
284 |
15 |
5 |
342 |
||||||||||||
|
устраивает |
||||||||||||||||||
|
Отчасти устраивает, |
31 |
649 |
201 |
14 |
895 |
|||||||||||||
|
отчасти нет |
||||||||||||||||||
|
По большей части |
1 |
3 |
200 |
340 |
55 |
599 |
||||||||||||
|
не устраивает |
||||||||||||||||||
|
Совершенно |
1 |
1 |
49 |
185 |
118 |
354 |
||||||||||||
|
не устраивает |
||||||||||||||||||
|
Всего |
10 |
109 |
1291 |
749 |
195 |
2354 |
||||||||||||
В табл. 2.10 представлена схема вычисления показателя S— ко личества пар, в которых значение первой переменной не меньше зна чений второй переменной:
71

Глава 2. Взаимосвязь переменных
Шаг!
|
В какой мере вас |
Как бы вы оценили в настоящее время |
Все |
||||||||||
|
устраивает жизнь, |
материальное положение вашей семьи? |
го |
||||||||||
|
которую вы ведете? |
||||||||||||
|
очень |
хоро |
сред |
пло |
очень |
||||||||
|
хорошее |
шее |
нее |
хое |
плохое |
||||||||
|
Вполне устраивает |
5 |
39 |
109 |
8 |
3 |
164 |
||||||
|
По большей части |
3 |
35 |
284 |
15 |
5 |
342 |
||||||
|
устраивает |
||||||||||||
|
Отчасти устраивает, |
31 |
649 |
201 |
14 |
895 |
|||||||
|
отчасти нет |
||||||||||||
|
По большей части |
1 |
3 |
200 |
340 |
55 |
599 |
||||||
|
не устраивает |
||||||||||||
|
Совершенно |
1 |
1 |
49 |
185 |
118 |
354 |
||||||
|
не устраивает |
||||||||||||
|
Всего |
10 |
109 |
1291 |
749 |
195 |
2354 | |
||||||
|
Шаг 2 |
||||||||||||
|
В какой мере вас |
Как бы вы оценили в настоящее время |
Все |
||||||||||
|
устраивает жизнь, |
материальное положение вашей семьи? |
го |
||||||||||
|
которую вы ведете? |
||||||||||||
|
очень |
хоро |
сред |
пло |
очень |
||||||||
|
хорошее |
шее |
нее |
хое |
плохое |
||||||||
|
Вполне устраивает |
5 |
39 |
109 |
8 |
3 |
164 |
||||||
|
По большей части |
3 |
35 |
284 |
15 |
5 |
342 |
||||||
|
устраивает |
||||||||||||
|
Отчасти устраивает, |
31 |
649 |
201 |
14 |
895 |
|||||||
|
отчасти нет |
||||||||||||
|
По большей части |
1 |
200 |
340 |
55 |
599 |
|||||||
|
не устраивает |
||||||||||||
|
Совершенно |
1 |
1 |
49 |
185 |
118 |
354 |
||||||
|
не устраивает |
||||||||||||
|
Всего |
10 |
109 |
1291 |
749 |
195 |
2354 |
||||||
|
72 |
||||||||||||
2.4. Коэффициенты связи для порядковых данных
ШагЗ
|
В какой мере вас |
Как бы вы оценили в настоящее время |
Все |
|||||
|
устраивает жизнь, |
материальное положение вашей семьи? |
го |
|||||
|
которую вы ведете? |
|||||||
|
очень |
хоро |
сред |
пло |
очень |
|||
|
хорошее |
шее |
нее |
хое |
плохое |
|||
|
Вполне устраивает |
5 |
39 |
109 |
8 |
3 |
164 |
|
|
По большей части |
3 |
35 |
284 |
15 |
5 |
342 |
|
|
устраивает |
|||||||
|
Отчасти устраивает, |
31 |
649 |
201 |
14 |
895 |
||
|
отчасти нет |
|||||||
|
По большей части |
1 |
3 |
200 |
340 |
55 |
599 |
|
|
не устраивает |
|||||||
|
Совершенно |
1 |
1 |
49 |
185 |
118 |
354 |
|
|
не устраивает |
|||||||
|
Всего |
10 |
109 |
1291 |
749 |
195 |
2354 |
|
|
Шаг 4 |
|||||||
|
В какой мере вас |
Как бы вы оценили в настоящее время |
Все |
|||||
|
устраивает жизнь, |
материальное положение вашей семьи? |
го |
|||||
|
которую вы ведете? |
|||||||
|
очень |
хоро |
сред |
пло |
очень |
|||
|
хорошее |
шее |
нее |
хое |
плохое |
|||
|
Вполне устраивает |
5 |
39 |
109 |
8 |
3 |
164 |
|
|
По большей части |
3 |
35 |
284 |
15 |
5 |
342 |
|
|
устраивает |
|||||||
|
Отчасти устраивает, |
31 |
649 |
201 |
14 |
895 |
||
|
отчасти нет |
|||||||
|
По большей части |
1 |
3 |
200 |
340 |
55 |
599 |
|
|
не устраивает |
|||||||
|
Совершенно |
1 |
1 |
49 |
185 |
118 |
354 |
|
|
не устраивает |
|||||||
|
Всего |
10 |
109 |
1291 |
749 |
195 |
2354 |
|
В табл. 2.11 представлена схема вычисления показателя D — количества пар, в которых значение первой переменной не меньше значений второй переменной.
73

Глава 2. Взаимосвязь переменных
D = 3 х (3 + 1 + 1 + 35 + 31 + 3 + 1 + 284 + 649 + 200 + 49 + 15 + + 201 +340+ 185)+ 15 х (1 + 1 + 31+3 + 1+649 + 200 + 49) + + 649 х (1 + 1 + 3 + 1) + 3 х 1 = 23 916.
Имея значения SKD, МОЖНО непосредственно рассчитать коэф фициент у по формуле
(2.7)
Для табл. 2.9 значение у равно 0,763. О чем говорит такое значе ние коэффициента, и, более того, как вообще интерпретируются ран говые коэффициенты связи?
В целом ранговые коэффициенты связи характеризуют ситуа цию, когда, сопоставляя двух случайно отобранных респондентов, у которых измеряются две порядковые переменные А и В, мы можем сказать, что если у первого респондента значение переменной А боль ше, чем у второго респондента, то у него будет больше и значение по переменной В. Количество пар респондентов, у которых это правило выполняется, и есть построенный показатель S. Количество пар рес пондентов, для которых действует обратное правило, т.е. таких пар, у которых переменная А у первого респондента имеет значение больше, чем у второго, а переменная В — меньше, фиксируется показателем D. Таким образом, коэффициент у фиксирует то, каких пар больше.
Из формулы (2.7) следует, что коэффициент у может изменяться в интервале от-1 до +1. Коэффициент равен +1 в случае, когда пока затель D равен нулю, т.е. в ситуации, когда для всех респондентов верно, что если переменная А = г, а переменная В =j, всегда i > j. Соответственно у равна — 1 , когда в той же ситуации переменных А и В всегда t <j.
Что означает ситуация, когда одна пара переменных, скажем, А] и А , имеет более высокое (по абсолютной величине) значение коэф фициента у, чем пара переменных 5, и 52? Это означает, что для пере менных А и А2 вероятность правильного порядка значений перемен ных выше, чем для переменных 5, и Вг Под правильным порядком мы понимаем порядок, при котором если А = i, а В =j, то всегда i >j,
2.4. Коэффициенты связи для порядковых данных
или i <j- Вообще, коэффициент у имеет прямую вероятностную ин терпретацию — это разность между вероятностями правильного и неправильного порядка для пары случайно извлеченных из выборки наблюдений4. Именно так следует понимать силу связи, которая фик сируется ранговыми коэффициентами корреляции.
Как на практике определить, насколько велико полученное зна чение коэффициента у, можно ли сказать, что если в одном исследо вании коэффициент у = 0,5, а в другом — у = 0,6, то во втором иссле довании имеет место более тесная связь между анализируемыми по казателями? Поскольку для коэффициента у известно теоретическое распределение, то пакет SPSS одновременно со значением коэффи циента вычисляет также и значение стандартной ошибки. Благодаря этому возможно построение доверительного интервала для коэффи циента у. В табл. 2.12 приведены результаты, которые выводит ко манда Crosstabs при запросе на вычисление коэффициента у для дан ных, приведенных в табл. 2.9.
|
Таблица 2.12. |
Результаты вычисления коэффициента |
||||
|
ранговой корреляции у для данных табл. 2.8 |
|||||
|
Value |
Asymp. Std. |
Ар- |
Approx. |
||
|
Error |
prox. T |
Sig. |
|||
|
Gamma |
0,763 |
0,015 |
37,143 |
0,000 |
|
Основываясь на данных табл. 2.12, можно сказать, что с вероят ностью 95% значение коэффициента у для генеральной совокупности будет находиться в интервале (0,763 ± 0,03). С помощью числа в ко лонке Approx. Sig. (приблизительная значимость) можно оценить спра ведливость гипотезы Н: «Величина коэффициента ранговой корреля ции у для анализируемых переменных в генеральной совокупности равна нулю». В табл. 2.12 мы получили, что Approx. Sig = 0,000. Это означает,
4 См.: Аптон Г. Анализ таблиц сопряженности. М.: Финансы и статистика, 1982.
С 37.

Глава 2. Взаимосвязь переменных
что для соответствующего уровня значимости а имеет место неравен ств: а < 0,001. Гипотезу Н0 следует отвергнуть, поскольку эта величи на намного меньше общепринятого для отвержения гипотезы уровня значимости 0,05.
Если необходимо решить задачу сравнения коэффициентов у, вы численных для двух разных социальных совокупностей, необходимо:
•определить доверительные интервалы для обоих коэффици
ентов;
•посмотреть, пересекаются ли эти доверительные интервалы. Если они не пересекаются, то мы, с соответствующей доверительной вероятностью, можем утверждать, что эти коэффициенты различны.
Отличие ранговых коэффициентов корреляции от коэффициен тов связи, основанных на %2 либо на модели предсказания, состоит в том, что фиксируют не только наличие либо отсутствие связи, но и, в случае наличия связи, ее направление. Это, несомненно, является до стоинством данных коэффициентов, но в определенных случаях мо жет являться и их недостатком. Дело в том, что ранговые коэффици енты корреляции фиксируют только однонаправленность, монотон ность формы зависимости (см. рис. 2.6). Например, для всех изобра женных на рис. 2.6 зависимостей имеем значение коэффициента у, равное +1 или — 1 , несмотря на то что сами формы зависимости суще ственно разные.
Что произойдет, если зависимость между переменными не име ет однонаправленной связи, как, например, зависимости, изображен ные на рис. 2.7? Оказывается, что в ситуации такого рода форм зави симостей ранговые коэффициенты связи оказываются неэффектив ными. Действительно, если может оказаться, что для части рес пондентов, например тех, кто имеет малые значения переменной х (рис. 2.7, график 1), значение рангового коэффициента связи будет отрицательное, а для тех респондентов, которые имеют большие зна чения переменной х, значение рангового коэффициента будет поло жительное, то общее значение рангового коэффициента может ока заться равным нулю. И это при том, что, как показывает график, связь между переменными явно есть.
2.4. Коэффициенты связи для порядковых данных
Рис. 2.6. Примеры монотонных зависимостей между переменными
Рис. 2.7. Примеры немонотонных зависимостей между переменными
Таким образом, тот факт, что значение рангового коэффициента корреляции равно нулю, говорит не об отсутствии связи, а лишь об отсутствии монотонной связи.

Глава 2. Взаимосвязь переменных
Если при изучении взаимосвязи двух порядковых переменных мы получили нулевое значение коэффициента ранговой корреляции, встает вопрос о том, как можно проверить, с какой из ситуаций мы имеем дело: между переменными вообще нет зависимости, или нет монотонной зависимости? Ответ достаточно прост: следует посчи тать, скажем, коэффициент %2. Если этот коэффициент покажет на личие связи при нулевом значении коэффициента у, очевидно, что мы имеем дело с наличием немонотонной связи между переменными.
2.5
Коэффициент корреляции Пирсона
В том случае, когда обе анализируемые переменные измерены по мет рическим шкалам (интервальным либо абсолютным) появляется допол нительная возможность измерения степени взаимосвязи между этими переменными —- это коэффициент корреляции Пирсона. Формула для вычисления этого коэффициента корреляции достаточно проста:
(2.8)
где х и у — средние значения переменных х и у соответственно; Sx и S — стандартные отклонения переменных х и у; N — количество наблюдений.
Из формулы (2.8) следует, что коэффициент г фиксирует сте пень того, насколько переменные х и у одновременно отклоняются от средних значений. Таким образом, в отличие от ранговых коэффи циентов корреляции, которые замеряют монотонный характер связи между переменными, коэффициент корреляции Пирсона учитывает более узкий характер монотонности — линейность. Когда между пе ременными есть строгая линейная зависимость, значение коэффици ента корреляции Пирсона будет равно +1 в случае положительной
2.5. Коэффициент корреляции Пирсона
связи и -1 в случае отрицательной связи. Так, для графика 2 рис. 2.6 коэффициент корреляции равен +1, а для графика 4 1. В ситуа ции, когда связь не соответствует линейной, коэффициент корреля ции отличается от единицы даже в случае жесткой функциональной связи между переменными. Для графика 1 рис. 2.6 коэффициент
|
корреляции равен 0,975, а для графика 4 |
0,833. |
|
На практике, когда анализируется зависимость между социологи ческими переменными, мы имеем дело не с функциональными зависи мостями. На рис. 2.8 показана диаграмма рассеяния для реальных дан ных, полученных в ходе социологического изучения зависимости меж ду размером семьи и величиной среднедушевого дохода семьи.
Расположение точек на рис. 2.8 показывает, что едва ли суще ствует какая-то строгая функция, которая позволит построить кри вую, проходящую через все точки реальных данных.
Среднедушевой доход, тыс. руб.
20-
15 —
10-
о
Число членов семьи
Рис. 2.8. Диаграмма рассеяния для 30 респондентов по переменным «Среднедушевой доход» и «Число членов семьи»
Коэффициент корреляции Пирсона отражает определенную пря мую, которая в некотором смысле наилучшим образом фиксирует за-

Глава 2. Взаимосвязь переменных
висимость между двумя переменными5. Для данных, представленных на рис. 2.8, коэффициент корреляции Пирсона равен -0,11. Отрица тельное значение коэффициента означает, что с ростом размера семьи среднедушевой доход уменьшается. Величина коэффициента 0,11 по казывает степень того, насколько реальные данные близки к линей ной зависимости (прямой).
Когда мы рассматриваем совместное поведение двух метрических переменных, то целью социологического анализа является установле ние взаимосвязи, зависимости между этими переменными. При исполь зовании для решения этой задачи коэффициента корреляции Пирсона следует помнить, что нулевое значение этого коэффициента, строго говоря, свидетельствует только об отсутствии линейной зависимости. Это, в свою очередь, может свидетельствовать и об отсутствии вообще какой-либо зависимости, и о том, что зависимость есть, но она носит нелинейный характер. Установить с помощью данного коэффициента, с какой из этих ситуаций мы имеем дело в конкретном случае, нельзя.
После вычисления коэффициента Пирсона для данных социоло гического опроса, как и в случае ранговых коэффициентов корреля ции, возникают две взаимосвязанные статистические задачи:
•является ли полученная величина коэффициента статистичес ки значимой;
•каков доверительный интервал для полученного значения. Команда Crosstabs, в случае запроса на вычисление коэффици
ента корреляции Пирсона, выводит таблицу, которая позволяет ре шить обе задачи (табл. 2.13).
Колонка Asymp. Std. Error (стандартная ошибка) позволяет по строить доверительный интервал для полученного значения г. Послед няя колонка табл. 2.13 содержит оценку значимости гипотезы #0 , ко торая формулируется следующим образом: «Для двух анализируемых переменных коэффициент корреляции Пирсона равен нулю». В нашем примере (табл. 2.12), если снова взять уровень значимости 5%, гипотезу следует принять.
5 Прямая в данном случае вычисляется по методу наименьших квадратов — см. главу 4 «Модели регрессионного анализа».
80
2.6. Вычисление коэффициентов связи в команде Crosstabs
Таблица 2.13. Формат выдачи результатов вычисления коэффициента корреляции Пирсона командой Crosstabs
|
Value |
Asymp. Std. Error |
Approx. T |
Approx. Sig. |
|
|
Pearson’s R |
-0,109 |
0,173 |
-0,580 |
0,567 |
|
N of Valid Cases |
30 |
|||
2.6
Вычисление коэффициентов связи в команде Crosstabs
Главное меню команды Crosstabs в нижней части имеет клавишу Statistics… (см. рис. 2.2). На рис. 2.9 показано меню, которое вызыва ется нажатием этой клавиши.
В меню Statistics можно выбрать любое количество необходимых коэффициентов связи. Отметим, что выбор коэффициента А, приведет к вычислению всех трех коэффициентов X , Хь, и Я. , а также двух коэффициентов т. Выбор же вычисления коэффициента корреляции Пирсона приводит также и к вычислению рангового коэффициента корреляции Спирмена.
Рис. 2.9. Меню Statistics команды Crosstabs
81
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Симметричные и несимметричные меры связи.
Симметричность мер связи (симметричная форма) проявляется в том, неважно какую переменную брать в качестве зависимой, так как вероятности предсказания одной переменной по другой, и наоборот, равны.
Содержательный смысл зависимости и независимости переменных для Гутмана.
Лямбда (Lambda). Данная мера связи оценивает, насколько одна переменная позволяет предсказывать другую переменную. Лямбда строится на основе разности суммы максимальных значений по строкам/столбцам () и максимальных маргинальных значений().
Схема расчета и интерпретация значения Гутмана.
Логика коэффициента, фиксирующего улучшение предсказания значений одной переменной на основании значений другой переменной весьма проста. Если назвать прогноз на основе значений только одной переменной первым прогнозом, а прогноз на основе двух переменных —вторым прогнозом, предлагаемые коэффициенты называются коэффициентами, основанными на модели прогноза:
Это так называемый прогноз модального значения. Коэффициенты для такого прогноза называются λ, их предложил Л. Гутман в 1941 г.
Что такое «первый прогноз» при модальном прогнозе? Это модальное значение предсказываемой переменной обозначим его как А, а проценту который соответствует значению А, — как Рr A. При таком обозначении ошибка при первом прогнозе будет Р1 =1—Рr А.
При втором прогнозе мы анализируем по очереди каждую строку таблицы и выбираем в каждой строке модальную частоту. Пусть модальное значение в каждой строке будет Аi, а соответствующий процент — Pr Аi. Соответственно ошибка при предсказании значения в i-й строке составит Р2i = 1 — Рr Аi. Таким образом, ошибка при втором прогнозе будет средней ошибкой предсказания по каждой из строк таблицы:
Формула коэффициента, фиксирующего улучшение прогноза переменной значение которой располагаются по столбцам таблицы, выглядит следующим образом:
У обсуждаемого коэффициента есть одна особенность, отличающая его ОТ коэффициента c2. В вычислении λb строки и столбцы участвуют не симметрично. Разумеется, таблицу можно повернуть на 90% и с точки зрения содержащейся в таблице информации от этой операции ничего не изменится. При таком повороте не изменятся значения коэффициентов c2 и коэффициентов, основанных на c2. Однако значение коэффициента λb изменится. Это связано с тем, что в модели коэффициента λb мы предсказываем значение одной переменной на основании значений другой и переменные включены в модель не симметрично. Фактически одна переменная рассматривается как причина, а другая как следствие.
В этой связи наряду с переменной λb, которая фиксирует предсказание переменной, расположенной по колонкам таблицы, существует и переменная λа, которая отражает улучшение предсказания переменной, расположенной по строкам на основании переменной, расположенной по столбцам. Наконец, когда мы не можем четко сказать, какая из переменных может рассматриваться как причина, а какая как следствие, существует так называемая λsym, т.е. «лямбда симметричная», представляющая полусумму λа и λb.
Поскольку коэффициенты λ, так же как и c2 — статистические меры, то в их отношении встает задача оценки уровня значимости. Действительной, если для некоторой таблицы был получен коэффициент, скажем, λb = 0,1, можем ли мы ‚утверждать, что некоторая связь между переменными действительно есть, и это значение не есть просто статистическая случайность. Другими словами, требуется проверить статистическую гипотезу λb=0 на основании полученного выборочного значения λb=0,1
Логика проверки данной статистической гипотезы совершенно аналогична логике проверки гипотезы о равенстве нулю коэффициента c2. Нам требуется знание теоретического распределения коэффициента λ, которое покажет нам, насколько вероятно то или иное значение коэффициента λ. При вычислении коэффициентов λ в пакете SPSS в команде Crosstabs одновременно проводится вычисление уровней значимости этих коэффициентов. Если коэффициент λ равен, скажем, значению λ0 уровень значимости этого значения определяется так: = Р(λ ≥λ0) при условии, что в генеральной совокупности λ=0.
Достоинством коэффициентов λ является то, что в отличие от коэффициента c2 либо производных от него само значение λа и λb имеет непосредственный смысл — это улучшение вероятности правильного предсказания. Иначе говоря, если для некоторой таблицы λb = 0,2, это означает, что мы можем предсказывать модальное значение переменной, располагающейся по колонкам, зная совместное распределение двух переменных на 20% точнее по сравнению с ситуацией, когда мы не знаем этого распределения.
Однако это значение весьма условно. Действительно коэффициенты λ являются статистическими мерами и потому точное полученное значение коэффициента бессмысленно. Ведь мы можем повторить опрос для другой выборки (с соблюдением той же процедуры ее построения) и тем не менее почти наверняка получим другое значение коэффициента λ, поскольку будут опрашиваться другие респонденты. Следовательно, гораздо важнее получить не точечное значение коэффициентов λ, а доверительный интервал.
При вычислении коэффициентов λ командой Crosstabs наряду с точечными значениями вычисляются также и величины стандартных ошибок. Стандартные ошибки позволяют построить доверительные интервалы с задаваемыми уровнями значимости. В табл. 2.6 приведен фрагмент таблицы, выдаваемой командой Crosstabs, в которой вычислены коэффициенты λ, соответствующие стандартные ошибки и уровни значимости для проверки гипотезы о равенстве нулю этих коэффициентов для данных табл. 2.1.
Таблица 2.6 содержит одновременно все три коэффициента λ — λsym (строка Symmetric)‚ λа (cследующая за Symmеtгiс строка) и λb (последняя строка). В колонке Value расположены значения соответствующих коэффициентов, а в последней колонке (Approx. Sig.) — уровни значимости для проверки гипотез о равенстве нулю этих коэффициентов. Находящееся в этой колонке значение имеет смысл сравнить с заранее выбранным уровнем значимости, снова обозначим его (в статистике чаще всего используется = 0,05). Если наше значение больше , гипотезу следует принять, если меньше — отвергнуть.
Из табл. 2.6 видно, что при уровне значимости =0,05 следует принять гипотезу о равенстве нулю всех трех коэффициентов — λsym, λа, λb (так как все значения в колонке Approx. sig. превосходят 0,05).
•Таблица 2.6 содержит еще две колонки, одна из которых —Asymp. std. Error (асимптотическая стандартная ошибка) дает нам информацию, необходимую для построения доверительных интервалов. Напомним, что 68%-й доверительный интервал дает λ± (одна стандартная ошибка); 95%-й доверительный интервал — λ± (две стандартные ошибки).
Графа Арргох. Т — вспомогательная, и обозначает отношение значення коэффициента λ к величине его стандартной ошибки. Отметим, что данный показатель Т широко распространен в разных разделах статистики. Фактически он показывает, как соотносится измеренное значение с ошибкой измерения и характеризует то, насколько мы можем доверять полученным коэффициентам. Поясним смысл этого показателя на примере. Предположим, что мы взвешиваем спичку на обычных бытовых весах и получаем, что спичка весит 2 г. Однако точность наших весов составляет ± 10 г. В данном примере показатель Т = 0,2 и едва ли мы будем всерьез относиться к полученному значению веса спички. Таким образом, чем больше значение Т, тем выше качество полученного измерения.
Из приведенных формул коэффициентов λ, следует, что у них есть очень существенный недостаток — в том случае, когда все модальные частоты лежат в одной колонке либо в одной строке таблицы, соответствующие коэффициенты всегда обращаются в нуль. Таким образом, равенство нулю коэффициентов λа и λb — это необходимое, но не достаточное условие для независимости переменных, образующих таблицу.
Последнее свойство весьма неудобно. Действительно, хотелось бы иметь коэффициенты, которые обладают естественным свойством — равенство нулю всегда говорит о независимости. Этим качеством обладают коэффициенты, также основанные на прогнозе, но в которых прогнозируется не модальная частота, а весь спектр частот. Это коэффициенты τ (тау) Гудмена — Краскэла.
Эти меры связи изменяются от 0 до 1. При этом 0 означает, что независимая переменная не помогает предсказывать значение зависимой переменной, а 1 — что знание о независимой переменной полностью определяет категории зависимой переменной. При вычислении этих мер можно объявить зависимой каждую из двух переменных.
Где F im – наибольшее значение в i строке таблицы. F om – наибольшее значение по столбцам. У коэффициента на рис. 3.8. есть одна особенность отличающая его от коэффициент Хи – квадрат. В вычислении Лямбда b строки и столбцы участвуют не симметрично . Разумеется, таблицу можно повернуть на 90% и с точки зрения содержащейся в таблице информации от этой операции ничего не изменится. Однако значение Лямбда изменится. Это связано с тем, что в модели коэффициента Лямбда мы предсказываем значение одной переменной на основании значений другой и переменные включены в модель не симметрично.
В этой связи наряду с переменной Лямбда b, которая фиксирует предсказания переменной, расположенной по колонкам таблицы, существует и переменная Лямбда а, которая отражает улучшение предсказания переменной, расположенной по строкам на основании переменной, расположенной по столбцам. Наконец, когда мы не можем предсказать какая из пременных причина, а что следствие, тогда существует «Лямбда симметричная» — полусумма лямбд а и б.
Недостатки Гутмана.
Существенный недостаток Лямбды – в том случае, когда все максимальные частоты лежат в одной колонке либо в одной строке таблицы, сооответствующие коэффициенты всегда обращаются в нуль. Таким образом, равенство нулю коэффициентов лямбды – необходимое, но недостаточное условие для независимости переменных, образующих таблицу.
Другие направленные меры связи. Уровень значимости, значение и доверительный интервал для значения.
Еще направленными мерами связи являются:
Тay Гудмена и Краскала (Goodman and Kruskal tau). Данный коэффициент является одним из вариантов критерия лямбда; он также показывает, какую переменную надо взять за зависимую, чтобы сократилась вероятность ошибки.
Общая идея оценки качества прогноза для коэффициентов τ записывается выражением (2.4), так же как и для коэффициентов λ, однако сам прогноз строится иначе. Рассмотрим это подробнее.
Из табл. 2.2 следует, что переменная q12 «Как бы вы оценили в целом политическую обстановку в России?» имеет следующее одномерное распределение (табл. 2.7). Случайным образом отберем 2407 респондентов и, базируясь на приведенном одномерном распределении, попытаемся угадать ответы каждого на вопрос q12. Возьмем 43 респондента и скажем, что они отметили в этом вопросе градацию «1». Поскольку вероятность выбора первой градации составляет 1,8%, количество людей, у которых мы правильно угадаем первый вариант ответа, составляет 43*0,018 = 0,774. Аналогичным образом поступим со всеми 2407 респондентами (последняя колонка табл. 2.6)
Таблица 2.7 показывает что из 2407 отобранных респондентов используя предлагаемую модель предсказания, мы сумели правильно предсказать выбор у 1072,747 респондентов. Таким образом, общее качество такого прогноза, который базируется только на знании одномерного распределения переменной q12, составляет 1072,747/2407 = 44,57%
Далее строим модель предсказания, базируясь уже на данных таблицы двумерного распределения переменных ql0 и q12, т.е. будем использовать для предсказания значений q12 значения переменной ql0. В табл. 2.8 приведен расчет такого предсказания для первой строки таблицы совместного распределения.
Коэффициент неопределенности (Uncertainty Coefficient). Коэффициент неопределенности показывает степень не точности предсказания. Чем больше данный коэффициент, тем точнее предсказание.
Меры связанности для переменных с номинальной шкалой
Коэффициент корреляции нельзя применять в качестве характеристики зависимости между переменными, если эти переменные принадлежат к номинальной шкале и имеют более двух категорий, потому что между их кодировками невозможно установить порядкового отношения и, следовательно, они не могут быть расположены в определенном, рационально объяснимом порядке.
Наилучшим средством для анализа таких зависимостей считается представленный в разделе 11.3.1 тест хи-квадрат, после которого при необходимости можно провести анализ наблюдаемых и ожидаемых частот, а также нормированных остатков. Этот анализ был описан в разделе 8.7.2.
Тем не менее и в этом случае также производились попытки разработать критерии количественной оценки степени связанности двух переменных, поставленных во взаимное соответствие. Эти критерии показывают степень взаимной зависимости или независимости двух переменных, принадлежащих к с номинальной шкале, причем значение
0 соответствует полной независимости переменных, а 1 — их максимальной зависимости. Меры связанности не могут иметь отрицательных значений, так как при отсутствии порядкового отношения нельзя дать ответа на вопрос о направлении зависимости.
В опросе членов городской организации одной из политических партий среди прочего выяснялось их занятие и определялось, выполняет ли респондент какую-либо партийную функцию. Выдержка из ответов респондентов-мужчин содержится в файле partei.sav.
-
Загрузите файл partei.sav и создайте таблицу сопряженности с переменной funk в
строках и переменной beruf в столбцах. -
Задайте вывод ожидаемых частот, стандартизованных остатков, процентов по столбцам и критерия хи-квадрат.
Занятие * Партийная работа Crosstabulation (Таблица сопряженности)
|
|
|
|||||
| Наемный работник |
|
Предпри-ниматель |
||||
|
|
|
|
13 |
|
|
|
|
|
12,4 |
|
|
|
||
|
|
59,1% |
|
|
|
||
|
|
,2 |
|
|
|||
|
|
|
9 |
|
|
|
|
|
|
9,6 |
|
|
|
||
|
|
40,9% |
|
|
|
||
|
|
-,2 |
|
|
|||
|
|
|
22 |
|
|
|
|
|
|
22,0 |
|
|
|
||
|
|
100,0% |
|
|
|
Chi-Square Tests
|
Value |
df |
Asymp. Sig. (2-sided) |
|
|
Pearson Chi-Square (Критерий хи-квадрат по Пирсону) |
15,01 7 (a) |
2 |
,001 |
|
Likelihood Ratio (Отношение правдоподобия) |
16,421 |
2 |
,000 |
|
Li near-by-Li near Association (Зависимость линейный-линейный) |
4,420 |
1 |
,036 |
|
N of Valid Cases |
64 |
а. и cells (,0%) have expected count less than 5. The minimum expected count is 11,50. (0 ячеек (,0%) имеют ожидаемую частоту менее 5. Минимальная ожидаемая частота 7,88.)
Результат получился максимально значимым: участие в партийной работе весьма характерно для государственных служащих, а для предпринимателей — совсем не характерно, тогда как наемные работники находятся посредине. Теперь зададим (кнопкой Statistics…) вывод всех мер связанности для переменных, принадлежащих к номинальной шкале (флажки в группе Nominal).
Directional Measures (Направленные меры)
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
||
|
|
|
|
|
|
||
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
a. Not assuming the null hypothesis (Нулевая гипотеза не принимается).
b. Using the asymptotic standard error assuming the null hypothesis (Используется асимптотическая
стандартная ошибка с принятием нулевой гипотезы).
с. Based on chi-square approximation (На основе аппроксимации по распределению хи-квадрат).
d. Likelihood ratio chi-square probability (Степень правдоподобия при распределении вероятности
по закону хи-квадрат).
Symmetric Measures (Симметричные меры)
|
Value |
Approx. Sig. |
||
|
Nominal by Nominal (Номинальный-номинальный) |
Phi (Фи) |
,484 |
,001 |
|
Cramer’s V (V Крамера) |
,484 |
,001 |
|
|
Contingency Coefficient (Коэффициент сопряженности признаков) |
,436 |
,001 |
|
|
N of Valid Cases |
64 |
a. Not assuming the null hypothesis (Нулевая гипотеза не принимается).
b. Using the asymptotic standard error assuming the null hypothesis (Используется асимптотическая
стандартная ошибка с принятием нулевой гипотезы).
Коэффициент сопряженности признаков (Пирсона)
Его величина всегда находится в пределах от 0 до 1 и вычисляется (как и значения критериев Фишера (<р) и Крамера (V)) с использованием значения критерия хи-квадрат:
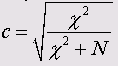
Здесь N — общая сумма частот в таблице сопряженности. Так как
N всегда больше нуля, коэффициент сопряженности признаков никогда не достигает единицы. Максимальное значение зависит от количества строк и столбцов таблицы сопряженности и в таблице размером 3*2 составляет (как в данном примере) 0,762. По этой причине коэффициенты сопряженности признаков для двух таблиц с разным количеством полей несопоставимы.
Критерий Фишера (<р)
Этот коэффициент можно использовать только для таблиц 2*2, так как в других случаях он может превысить значение 1:
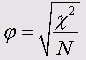
Критерий Крамера (V)
Этот критерий представляет собой модификацию критерия Фишера и для любых таблиц сопряженности он дает значение в пределах от 0 до 1, включая 1:
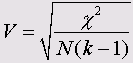
Здесь k — наименьшее из количеств строк и столбцов.
Три названных критерия основаны на использовании критерия хи-квадрат. Они различными способами нормируют его значение по отношению к размеру выборки. Так, если формуле для V Крамера положить k = 2, то значения (р и V Крамера совпадут. Определение значимости основано на значении критерия хи-квадрат.
При оценке полученных значений мер связанности, находящихся в нашем примере в промежутке между 0,4 и 0,5, следует учесть, что значение 1 достигается очень редко или вообще никогда. Другие меры связанности (Я, т Гудмена-Крускала и коэффициент неопределенности) определяются на основе так называемой концепции пропорционального сокращения ошибки. При определении этих критериев одна переменная рассматривается как зависимая; по этой причине данные критерии называются «направленными мерами».
Лямбда
В данном примере вопрос о партийной работе можно рассматривать как зависимую переменную, определяемую родом занятий. Если для какого-то отдельно взятого человека надо сделать предположение о том, выполняет ли он партийную работу или нет, то, естественно, делается наиболее вероятное предположение, соответствующее наиболее часто даваемому ответу — в данном случае, предположение о том, что опрашиваемый занимается партийной работой. Такой ответ дают 56,3% респондентов; однако в 43,7% наблюдений наше предположение будет неверным.
Вероятность предположения можно повысить, если учитывать другую переменную — род занятий. Для наемных работников, как и для государственных служащих, можно достаточно уверенно прогнозировать участие в партийной работе, причем этот прогноз окажется неверным для 9 наемных работников и для 2 государственных служащих. В то же время для предпринимателей можно с большими основаниями предположить, что они не занимаются партийной работой, и ошибиться в 7 наблюдениях. Таким образом, для общего числа 64 опрашиваемых мы получаем 9 + 2 + 7=18 наблюдений, или 28,1 %, в которых прогноз будет неверен. Легко видеть, что первоначальная вероятность ошибки 43,7% значительно сократилась.
На основе этих двух вероятностей можно вычислить относительное сокращение
ошибки, которое и называется лямбда:
Лямбда=(Ошибка при первом прогнозе — Ошибка при втором прогнозе)/Ошибка при первом
В нашем примере:
Лямбда =( 43,7% — 28.1%)/43,7% = ,357
Если ошибка при втором прогнозе сокращается до 0, лямбда будет равна 1. Если ошибки при первом и при втором прогнозе одинаковы, лямбда = 0. В этом случае вторая переменная никак не помогает в уточнении предсказания значения первой (зависимой переменной); то есть выбранные две переменные совершенно не зависят друг от
друга.
Так как ваш быстрый, но совершенно не умеющий соображать компьютер не знает, какую переменную следует считать зависимой, SPSS вычисляет оба значения Я, поочередно рассматривая каждую из переменных как зависимую. В случае, если выясняется, что ни одну из выбранных переменных нельзя объявить зависимой, выводится среднее двух этих значений с обозначением «лямбда
-симметричная».
Тау (т) Гудмена-Крускала
Это вариант меры связанности , который SPSS всегда вычисляет совместно с ней. При определении этой меры количество правильных предсказаний определяется по-иному: наблюдаемые частоты взвешиваются с учетом своих процентов и складываются. Для первого прогноза это дает:
36 * 56,3% + 28 * 43,8% =32,53
Согласно этому выражению, из 64 респондентов неверное предположение сделано для 31,47, что составляет 49,17%.
С учетом второй переменной количество верных предположений (второй прогноз)
составляет:
13 * 59,1 % + 16 * 88,9 % + 7 * 29,2 % + 9 * 40,9 % + 2 * 11,1 % + 17 * 70,8 % =
39,89
Итак, при втором прогнозе сделано 24,11 неверных прогнозов из 64, что составляет 37,67%. Тогда сокращение ошибки равно
(49.17 %-37.67%)/49,17 %=0,235
Это значение выводится под названием «тау Гудмена-Крускала». И в этом случае SPSS выдает второе значение т, рассматривая вторую переменную, как зависимую.
Коэффициент неопределенности
Это еще один вариант критерия лямбда, при определении которого имеется в виду не ошибочное предсказание, а «неопределенность», то есть степень неточности предсказаний. Эта неопределенность вычисляется по достаточно сложным формулам, которые мы опускаем. Коэффициент неопределенности также принимает значения в диапазоне от 0 до 1. Значение 1 говорит о том, что одну переменную можно точно предсказать по значениям другой.