Систематические корректирующие коды. Линейно групповой код
Время на прочтение
6 мин
Количество просмотров 8.6K
В данной публикации будет рассматриваться линейно групповой код, как один из представителей систематических корректирующих кодов и предложена его реализация на C++.
Что из себя представляет корректирующий код. Корректирующий код – это код направленный на обнаружение и исправление ошибок. А систематические коды — Это коды, в которых контрольные и информационные разряды размещаются по определенной системе. Одним из таких примеров может служить Код Хэмминга или собственно линейно групповые коды.
Линейно групповой код состоит из информационных бит и контрольных. Например, для исходной комбинации в 4 символа, линейно групповой код будет выглядеть вот так:
|1100|110|Где первые 4 символа это наша исходная комбинация, а последние 3 символа это контрольные биты.
Общая длина линейно группового кода составляет 7 символов. Если число бит исходной комбинации нам известно, то чтобы вычислить число проверочных бит, необходимо воспользоваться формулой:

Где n — это число информационных бит, то есть длина исходной комбинации, и log по основанию 2. И общая длина N кода будет вычисляться по формуле:

Допустим исходная комбинация будет составлять 10 бит.


d всегда округляется в
большую сторону
, и d=4.
И полная длина кода будет составлять
14
бит.
Разобравшись с длиной кода, нам необходимо составить производящую и проверочную матрицу.
Производящая матрица, размерностью N на n, где N — это длина линейно группового кода, а n — это длина информационной части линейно группового кода. По факту производящая матрица представляет из себя две матрицы: единичную размерностью m на m, и матрицу контрольных бит размерностью d на n. Если единичная матрица составляется путём расставления единиц по главной диагонали, то составление «контрольной» части матрицы имеет некоторые правила. Проще объяснить на примере. Мы возьмем уже известную нам комбинацию из 10 информационных битов, но добавим коду избыточность, и добавим ему 5-ый контрольный бит. Матрица будет иметь размерность 15 на 10.
1 0 0 0 0 0 0 0 0 0 1 1 1 1 1
0 1 0 0 0 0 0 0 0 0 1 1 1 1 0
0 0 1 0 0 0 0 0 0 0 1 1 1 0 1
0 0 0 1 0 0 0 0 0 0 1 1 0 1 1
0 0 0 0 1 0 0 0 0 0 1 0 1 1 1
0 0 0 0 0 1 0 0 0 0 0 1 1 1 1
0 0 0 0 0 0 1 0 0 0 1 1 1 0 0
0 0 0 0 0 0 0 1 0 0 1 1 0 0 1
0 0 0 0 0 0 0 0 1 0 1 0 0 1 1
0 0 0 0 0 0 0 0 0 1 0 1 0 1 1«Контрольная» часть составляется по схеме уменьшения двоичного числа и соблюдения минимального кодового расстояния между строками: в нашем случае это 11111, 11110, 11101…
Минимальное кодовое расстояние для комбинации будет вычисляться по формуле:
Wp=r+s
Где r – это ранг обнаруживаемой ошибки, а s – ранг исправляемой ошибки.
В нашем случае ранг исправляемой и обнаруживаемой ошибки 1.
Также необходимо составить проверочную матрицу. Она составляется путём транспонирования «контрольной» части и после неё добавляется единичная матрица размерности d на d.
1 1 1 1 1 0 1 1 1 0 1 0 0 0 0
1 1 1 1 0 1 1 1 0 1 0 1 0 0 0
1 1 1 0 1 1 1 0 0 0 0 0 1 0 0
1 1 0 1 1 1 0 0 1 1 0 0 0 1 0
1 0 1 1 1 1 0 1 1 1 0 0 0 0 1Составив матрицы, мы уже можем написать линейно групповой код, путём суммирования строк производящей матрицы под номерами ненулевых бит исходного сообщения.
Рассмотрим этот этап на примере исходного сообщения 1001101010.
Линейно групповой код: 100110101011100
Сразу обозначим, что контрольные разряды в ЛГК определяются по правилам чётности суммы соответствующих индексов, в нашем случае, эти суммы составляют: 5,3,3,4,4. Следовательно, контрольная часть кода выглядит: 11100.
В результате мы составили линейно групповой код. Однако, как уже говорилось ранее, линейно групповой код имеет исправляющую способность, в нашем случае, он способен обнаружить и исправить одиночную ошибку.
Допустим, наш код был отправлен с ошибкой в 6-ом разряде. Для определения ошибок в коде служит, уже ранее составленная проверочная матрица
Для того, чтобы определить, в каком конкретно разряде произошла ошибка, нам необходимо узнать «синдром ошибки». Синдром ошибки вычисляется методом проверок по ненулевым позициям проверочной матрицы на чётность. В нашем случае этих проверок пять, и мы проводим наше полученное сообщение через все эти проверки.





Получив двоичное число, мы сверяем его со столбцами проверочной матрицы. Как только находим соответствующий «синдром», определяем его индекс, и выполняем инверсию бита по полученному индексу.
В нашем случае синдром равен: 01111, что соответствует 6-му разряду в ЛГК. Мы инвертируем бит и получаем корректный линейно групповой код.
Декодирование скорректированного ЛГК происходит путём простого удаления контрольных бит. После удаления контрольных разрядов ЛГК мы получаем исходную комбинацию, которая была отправлена на кодировку.
В заключение можно сказать, что такие корректирующие коды как линейно групповые коды, Код Хэмминга уже достаточно устарели, и в своей эффективности однозначно уступят своим современным альтернативам. Однако они вполне справляются с задачей познакомиться с процессом кодирования двоичных кодов и методом исправления ошибок в результате воздействия помех на канал связи.
Реализация работы с ЛГК на C++:
#include <iostream>
#include <vector>
#include <string>
#include <cstdlib>
#include <ctime>
#include <algorithm>
#include <iterator>
#include <cctype>
#include <cmath>
using namespace std;
int main()
{
setlocale(LC_ALL, "Russian");
cout<<"Производящая матрица:"<<endl;
int matr [10][15]={{1,0,0,0,0,0,0,0,0,0,1,1,1,1,1},{0,1,0,0,0,0,0,0,0,0,1,1,1,1,0},{0,0,1,0,0,0,0,0,0,0,1,1,1,0,1},{0,0,0,1,0,0,0,0,0,0,1,1,0,1,1},{0,0,0,0,1,0,0,0,0,0,1,0,1,1,1},
{0,0,0,0,0,1,0,0,0,0,0,1,1,1,1},{0,0,0,0,0,0,1,0,0,0,1,1,1,0,0},{0,0,0,0,0,0,0,1,0,0,1,1,0,0,1},{0,0,0,0,0,0,0,0,1,0,1,0,0,1,1},{0,0,0,0,0,0,0,0,0,1,0,1,0,1,1}};
for(int i=0;i<10;i++)
{
for(int j=0;j<15;j++)
{
cout<<matr[i][j]<<' ';
}
cout<<endl;
}
cout<<"Проверочная матрица:"<<endl;
int matr_2 [5][15]={{1,1,1,1,1,0,1,1,1,0,1,0,0,0,0},{1,1,1,1,0,1,1,1,0,1,0,1,0,0,0},{1,1,1,0,1,1,1,0,0,0,0,0,1,0,0},{1,1,0,1,1,1,0,0,1,1,0,0,0,1,0},{1,0,1,1,1,1,0,1,1,1,0,0,0,0,1}};
for(int i=0;i<5;i++)
{
for(int j=0;j<15;j++)
{
cout<<matr_2[i][j]<<' ';
}
cout<<endl;
}
cout<<"Введите комбинацию: "<<endl;
string str;
bool flag=false;
while(flag!=true)
{
cin>>str;
if(str.size()!=10)
{
cout<<"Недопустимая размерность строки!"<<endl;
flag=false;
}
else
flag=true;
}
vector <int> arr;
for(int i=0;i<str.size();i++)
{
if(str[i]=='1')
arr.push_back(1);
else if(str[i]=='0')
arr.push_back(0);
}
cout<<"Ваша комбинация: ";
for(int i=0;i<arr.size();i++)
cout<<arr[i];
cout<<endl;
vector <int> S;
vector <vector<int>> R;
for(int i=0;i<10;i++)
{
if(arr[i]==1)
{
vector <int> T;
for(int j=0;j<15;j++)
{
T.push_back(matr[i][j]);
}
R.push_back(T);
}
}
cout<<endl;
cout<<"Суммиирвоание строк для построения группового кода: "<<endl;
for(vector <vector<int>>::iterator it=R.begin();it!=R.end();it++)
{
copy((*it).begin(),(*it).end(),ostream_iterator<int>(cout,"\t"));
cout<<"\n";
}
cout<<endl;
vector <int> P;
for(int i=0; i<15;i++)
{
int PT=0;
for(int j=0; j<R.size();j++)
{
PT+=R[j][i];
}
P.push_back(PT);
}
for(int i=10; i<15;i++)
{
if(P[i]%2==0)
P[i]=0;
else if(P[i]%2!=0)
P[i]=1;
}
cout<<endl<<"Групповой линейный код: "<<endl;
for(int i=0; i<P.size();i++)
{
cout<<P[i]<<' ';
}
int rand_i;
rand_i=5;
cout<<endl<<"В сообщении сгенерирована ошибка: ";
if(P[rand_i]==0)
P[rand_i]=1;
else if(P[rand_i]==1)
P[rand_i]=0;
for(int i=0; i<P.size();i++)
{
cout<<P[i]<<' ';
}
int S1, S2, S3, S4, S5;
//Проверки на чётность
S1=P[0]+P[1]+P[2]+P[3]+P[4]+P[6]+P[7]+P[8]+P[10];
S2=P[0]+P[1]+P[2]+P[3]+P[5]+P[6]+P[7]+P[9]+P[11];
S3=P[0]+P[1]+P[2]+P[4]+P[5]+P[6]+P[12];
S4=P[0]+P[1]+P[3]+P[4]+P[5]+P[8]+P[9]+P[13];
S5=P[0]+P[2]+P[3]+P[4]+P[5]+P[7]+P[8]+P[9]+P[14];
//Составление синдрома
if(S1%2==0)
{
S1=0;
}
else if(S1%2!=0)
{
S1=1;
}
if(S2%2==0)
{
S2=0;
}
else if(S2%2!=0)
{
S2=1;
}
if(S3%2==0)
{
S3=0;
}
else if(S3%2!=0)
{
S3=1;
}
if(S4%2==0)
{
S4=0;
}
else if(S4%2!=0)
{
S4=1;
}
if(S5%2==0)
{
S5=0;
}
else if(S5%2!=0)
{
S5=1;
}
cout<<endl<<"Синдром ошибки: "<<S1<<S2<<S3<<S4<<S5<<endl;
int mas_s[5]={S1,S2,S3,S4,S5};
int index_j=0;
bool flag_s=false;
for(int i=0;i<15;i++)
{
if((matr_2[0][i]==mas_s[0])&&(matr_2[1][i]==mas_s[1])&&(matr_2[2][i]==mas_s[2])&&(matr_2[3][i]==mas_s[3])&&(matr_2[4][i]==mas_s[4]))
{
index_j=i;
}
}
cout<<endl<<"Разряд ошибки: "<<index_j+1<<endl;
if(P[index_j]==0)
P[index_j]=1;
else if(P[index_j]==1)
P[index_j]=0;
cout<<"Исправленный код: ";
for(int i=0; i<P.size();i++)
{
cout<<P[i]<<' ';
}
cout<<endl;
P.erase(P.begin()+14);
P.erase(P.begin()+13);
P.erase(P.begin()+12);
P.erase(P.begin()+11);
P.erase(P.begin()+10);
cout<<"Исходный код: ";
for(int i=0; i<P.size();i++)
{
cout<<P[i]<<' ';
}
cout<<endl;
return 0;
}Источники:
1. StudFiles – файловый архив студентов [Электронный ресурс] studfiles.net/preview/4514583/page:2/.
2. Задачник по теории информации и кодированию [Текст] / В.П. Цымбал. – Изд. объед. «Вища школа», 1976. – 276 с.
3. Тенников, Ф.Е. Теоретические основы информационной техники / Ф.Е. Тенников. – М.: Энергия, 1971. – 424 с.
Коды с обобщенными
проверками на четность
Все
систематические коды являются разделимыми.
Их принято иногда называть (n,k)-кодами,
где n—
общее число разрядов в кодовой комбинации,
k—
число информационных разрядов. Число
контрольных разрядов в кодовой комбинации,
следовательно, равно n—k.
Точных
аналитических выражений, связывающих
корректирующие свойства кода с его
параметрами, не существует. Получены
лишь асимптотические выражения,
называемые границами, для кодового
расстояния.
Наиболее важными
и полезными границами для кодового
расстояния являются граница Хэмминга,
граница Плоткина и граница Варшамова
— Гилберта.
Граница Хэмминга,
выражаемая обычно следующим образом,

, (3.19)
указывает
на наибольшее число кодовых комбинаций,
возможных при данных n
и числе обнаруживаемых и исправляемых
ошибок.
Граница
Плоткина также является верхней границей
для кодового расстояния при данных n
и k
и может выражаться следующим образом
![]()
. (3.20)
Выражение
(3.20) удобно для получения максимально
возможного d
при заданных n
и k,
но не очень удобно для получения
максимального k
при данных d
и n,
в связи с чем другая форма границы
Плоткина выглядит следующим образом
![]()
. (3.21)
Граница
Хэмминга обычно близка к оптимальной
для высокоскоростных кодов (т.е. для
больших значений k/n),
а граница Плоткина — для низкоскоростных
кодов.
Согласно границе
Варшамова — Гилберта, выражаемой как
![]()
,
(3.22)
существует
(n,k)-код
с кодовым расстоянием, не меньшим d,
и с числом проверок на четность, не
превышающим n—k.
Таким образом, граница Варшамова-Гилберта
является границей существования и дает
нижнюю оценку для кодового расстояния
«наилучшего» кода.
Приведем
пример использования этих границ.
Предположим, что требуется найти код
длиной n=63
с кодовым расстоянием d=5
и наибольшим возможным значением k.
Примером такого кода является (63,51)-код
БЧХ. Для оценки того, насколько хорошим
является этот код, используем границы
Хэмминга и Варшамова-Гилберта. Из (3.19)
следует, что 20172n—k
, откуда n—k
11.
Граница Варшамова-Гилберта (3.22)
«утверждает», что 39774>2n—k
, откуда n-k
16.
Таким образом, из границы Хэмминга
следует, что не существует кодов,
обеспечивающих заданные параметры, с
n—k<11,
а граница Варшамова-Гилберта гарантирует
существование таких кодов с n—k16.
Отсюда можно сделать вывод, что код
(63,51) является «хорошим» и дальнейшие
поиски могут привести лишь к незначительному
улучшению.
Для
кодов с d=3
для определения требуемого числа
контрольных разрядов можно найти более
простое выражение, воспользовавшись
следующими рассуждениями. При передаче
кодовой комбинации может быть искажен
любой из n
разрядов комбинации или комбинация
принята без искажений. Следовательно,
всего может быть n+1
вариантов исхода. Использование
контрольных разрядов должно обеспечить
возможность различения всех n+1
вариантов. С помощью n—k
разрядов можно описать 2n—k
событий, следовательно, должно выполняться
условие
![]()
или
![]()
(3.23)
Рассматриваемые
(n,k)-коды
называются групповыми. Своим названием
они обязаны тому, что множество кодовых
комбинаций вместе с нулевой кодовой
комбинацией, снабженное операцией
посимвольного сложения по модулю два,
образуют математическую структуру,
называемую группой. Основные свойства
группы:
-
замкнутость
— т.е. сумма по модулю два двух элементов
группы всегда лежит в группе; -
ассоциативность
— т.е. (ab)c=a(bc); -
наличие
единичного элемента — для двоичных
кодов это нулевая комбинация; -
каждый
элемент группы обладает обратным, для
которого а+(-а)=0,
для двоичных кодов каждая кодовая
комбинация совпадает со своей обратной.
Каждая
кодовая комбинация группового кода
разбивается на две части. Первая часть
содержит k
информационных
символов и всегда совпадает с передаваемой
информационной последовательностью.
Каждый из n—k
символов второй части вычисляется как
линейная комбинация фиксированного
подмножества информационных символов.
Согласно данным ранее определениям,
эти коды можно назвать также систематическими
и линейными. Символы второй части,
представляющие собой контрольные
разряды, называются символами обобщенных
проверок на четность.
Значения
контрольных разрядов в каждой кодовой
комбинации определяются в результате
сложения по модулю два тех или иных
информационных разрядов этой комбинации.
Особенностью группового кода является
постоянство набора информационных
разрядов, определяющего данный контрольный
разряд.
Другими
словами, для данного группового кода
имеется единый алгоритм образования
значений контрольных разрядов по
значениям информационных разрядов,
определяемый т.н. проверочными уравнениями.
Пусть
кодовая комбинация двоичного группового
кода имеет n
разрядов: unun-1un-2
. . . u1.
Положим, что среди этих n
разрядов символы ur,
ul,
us
— контрольные. Число проверочных уравнений
определяется числом контрольных
символов:

(3.24)
В
этих уравнениях коэффициенты
![]()
принимают значения 1 или 0 в зависимости
от того, используется или нет соответственно
для определения значения i-го
контрольного разряда j-й
информационный разряд.
С
помощью этих уравнений могут быть
составлены все Np=2k
разрешенных или рабочих комбинаций
кода путем записи информационных
разрядов каждой комбинации и вычисления
значений контрольных разрядов по
уравнениям (3.24) для каждой комбинации
информационных разрядов. Таким образом,
тот или иной код может быть задан таблицей
информационных кодовых комбинаций и
системой проверочных уравнений.
Однако
свойство линейности групповых кодов
обеспечивает возможность более компактной
записи кода. Из свойств групповых кодов
вытекает, что все множество кодовых
комбинаций данного кода можно получить
путем суммирования по модулю два в
различных сочетаниях образующих кодовых
комбинаций или базисных векторов.
Удобно
в качестве образующих выбрать комбинации,
которые содержать лишь по одной единице
в информационных разрядах. Следовательно,
число таких комбинаций равно k
— числу информационных разрядов. Если
к тому же упорядочить разряды, расположив
слева направо сначала информационные
разряды, начиная со старшего, а затем
контрольные разряды, и записать
упорядоченные таким образом комбинации
одна под другой, то получим матрицу,
содержащую n
столбцов и k
строк, которая называется образующей
матрицей систематического (n,k)-кода
и обозначается Gn,k.
Пример.3.7.
Построить образующую матрицу (7,4)-кода,
имеющего следующие проверочные уравнения

Решение.
Сначала целесообразно построить полную
таблицу кода в соответствии с
проверочными уравнениями.
|
a4 |
a3 |
a2 |
a1 |
b3 |
b2 |
b1 |
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
0 |
0 |
0 |
1 |
1 |
0 |
1 |
|
0 |
0 |
1 |
0 |
1 |
1 |
1 |
|
0 |
0 |
1 |
1 |
0 |
1 |
0 |
|
0 |
1 |
0 |
0 |
1 |
1 |
0 |
|
0 |
1 |
0 |
1 |
0 |
1 |
1 |
|
0 |
1 |
1 |
0 |
0 |
0 |
1 |
|
0 |
1 |
1 |
1 |
1 |
0 |
0 |
|
1 |
0 |
0 |
0 |
0 |
1 |
1 |
|
1 |
0 |
0 |
1 |
1 |
1 |
0 |
|
1 |
0 |
1 |
0 |
1 |
0 |
0 |
|
1 |
0 |
1 |
1 |
0 |
0 |
1 |
|
1 |
1 |
0 |
0 |
1 |
0 |
1 |
|
1 |
1 |
0 |
1 |
0 |
0 |
0 |
|
1 |
1 |
1 |
0 |
0 |
1 |
0 |
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
Выберем
образующие кодовые комбинации (выделены
жирным шрифтом) и запишем их в виде
образующей матрицы
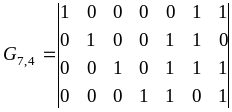
.
При
наличии образующей матрицы можно найти
все остальные кодовые комбинации кода
без использования полной таблицы кода.
Например, требуется найти кодовую
комбинацию для информационной комбинации
1101. Для этого нужно суммировать по модулю
2 три соответствующих строки образующей
матрицы:
1000011
0100110
0001101
1101000,
после чего можно
сопоставить результат с полной таблицей
кода.
Анализ
вида образующей матрицы приводит к
выводу, что она состоит из двух матриц
— единичной
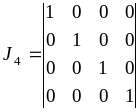
и
дополняющей
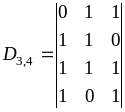
.
Обобщая
рассмотренный пример на любой
систематический групповой блоковый
(n,k)-код
можно записать для него образующую
матрицу
![]()
(3.25)
Единичная
матрица является образующей для
равномерного примитивного кода, поскольку
с ее помощью могут быть построены все
2k-1
ненулевых комбинаций этого кода путем
суммирования по модулю два ее строк в
различных сочетаниях.
Дополняющая
матрица, если не заданы проверочные
уравнения, может быть получена путем
подбора k
различных
комбинаций, содержащих n—k
разрядов. Эти комбинации должны
удовлетворять следующим условиям :
1)
количество единиц в комбинации должно
быть не менее d-1,
2)
сумма по модулю два любых двух комбинаций
должна содержать не менее d-2
единиц.
Пример.3.8.
Построить
образующую матрицу систематического
кода (7,4) с
d=3.
Решение.
Начать построение целесообразно с
нахождения дополняющей матрицы
![]()
.
В данном
случае n=7,
k=4,
n—k=3,
т.е.D3,4..
Следовательно, надо подобрать трехразрядные
комбинации, каждая из которых содержит
по d-1=3-1=2
единицы.
Поскольку
таких комбинаций всего три, а их требуется
k=4,
то в качестве
четвертой выберем, не нарушая первого
условия, комбинацию, содержащую три
единицы. Тогда дополняющая матрица
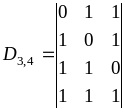
и
образующая матрица

,(3.26)
из которой может
быть найдена система проверочных
уравнений

(3.27)
Сравнивая
примеры 3.7 и 3.8 можно сделать вывод: для
каждой образующей матрицы Gn,k
существует своя единственная система
проверочных уравнений и, наоборот,
поскольку то и другое является описанием
одного и того же кода.
В
качестве еще одной равноправной формы
описания систематического (n,k)-кода
служит т.н. проверочная матрица,
обозначаемая обычно Hn,n—k.
При построении проверочной матрицы к
единичной квадратной матрице Jn—k
слева приписывают матрицу, содержащую
k
столбцов и n—k
строк, причем каждая ее строка формируется
из соответствующего столбца дополняющей
матрицы, т.е. приписываемая матрица
представляет собой транспонированную
дополняющую матрицу
![]()
. (3.28)
Пример.3.9.
Для кода из
примера 3.8- построить проверочную
матрицу.
Решение.
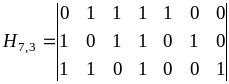
. (3.29)
Проверочная
матрица позволяет выбрать алгоритм
кодирования и декодирования, исходя из
того, что единицы в каждой ее строке
соответствуют тем символам кодовой
комбинации, сумма которых по модулю два
должна быть равна 0. Так, из матрицы
(3.29) можно получить следующие уравнения
проверок:

(3.30)
Естественно,
что (3.27) и (3.30) полностью совпадают с той
лишь разницей, что операции по (3.27)
выполняются при кодировании для получения
значений контрольных разрядов в каждой
кодовой комбинации, а операции по (3.30)
выполняются при декодировании для
обнаружения и исправления ошибок.
Из
анализа (3.30) видно, что a1
входит во все три уравнения, а2
— в первое и второе, а3
— в первое и третье, а4
— во второе и третье. Следовательно,
искажение любого аi
нарушит вполне определенные уравнения,
т.е. сумма по модулю два в них будет рана
не нулю, а единице. По тому, какие именно
уравнения нарушены, можно определить,
в каком разряде произошла ошибка, и
восстановить его истинное значение.
Таким
образом, результаты проверок дают
кодовую комбинацию вида
![]()
,
которую называют контрольной
последовательностью или, чаще, синдромом.
При
![]()
считается, что кодовая комбинация
принята верно или произошла не
обнаруживаемая ошибка. Если
![]()
,
считается, что комбинация принята
неверно, т.е. имеет место обнаружение
ошибки. Если (n,k)-код
используется только для обнаружения
ошибок, то в теории кодирования
доказывается, что при любой вероятности
ошибочного приема кодового символа
р1/2
найдется код, для которого вероятность
необнаруженной ошибки будет меньше
вполне определенного значения
![]()
.
Такие коды называются кодами равномерно
обнаруживающими ошибки.
Для
исправления ошибок каждому ненулевому
синдрому может быть сопоставлен
исправляющий вектор Ej
, сумма по
модулю два которого с принятой кодовой
комбинацией образует переданную
комбинацию. Пусть, например, передается
кодовая комбинация из примера 3.8
![]()
,
а принимается
![]()
.
При
выполнении проверок на приеме в
соответствии с системой (3.30) получается
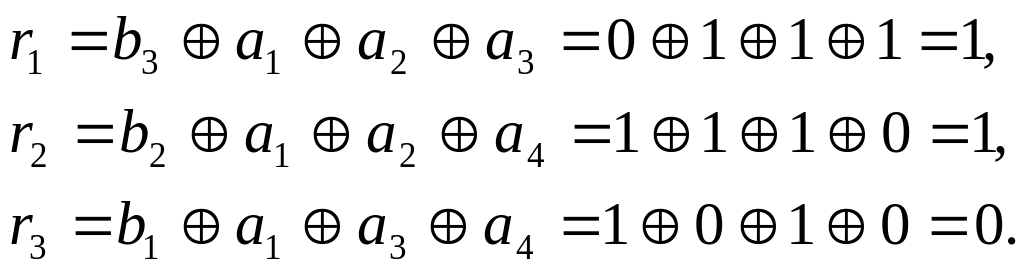
т.е.
синдром R=110,
нарушены первое и второе уравнения, в
которые входит а2,
следовательно, ошибка в разряде а2
и тогда исправляющий вектор Е=0010000,
а исправленная кодовая комбинация
![]()
.
Пользуясь
этим примером, обратим внимание на
третью стоку образующей матрицы (3.26). В
части этой строки, соответствующей
единичной матрице, единица расположена
на месте разряда, в котором произошла
ошибка, а получившийся синдром R
равен части этой же строки, входящей в
дополняющую матрицу.
Обобщая,
можно сказать, что при ошибке в разряде
а4
синдром будет 011, при ошибке в разряде
а3
— 101, при ошибке в разряде а1
— 111.
То
же самое следует из проверочной матрицы
этого кода (3.29), где первый столбец —
синдром при ошибке в разряде а4
и т.д.
На
основании любого из приведенных ранее
описаний группового систематического
кода (системы проверочных уравнений,
образующей матрицы, проверочной матрицы)
могут быть синтезированы функциональные
схемы кодера и декодера такого кода.
Так, кодер (рис.
3.9) для кода из примера 3.8 должен содержать
|
|
|
Рис. 3.9. Кодер |

параллельный
регистр, предназначенный для приема от
источника и временного хранения четырех
информационных разрядов, совокупность
из трех трехвходовых сумматоров по
модулю два, предназначенных для
формирования значений контрольных
разрядов, и параллельный семиразрядный
регистр для промежуточного хранения
сформированной кодовой комбинации,
которая далее может быть последовательно
передана в линию связи. Соединение
входов сумматоров по модулю два с
выходами первого регистра выполняются
в соответствии с системой проверочных
уравнений.
Сложность
схемы декодера для такого кода будет
зависеть от того, используется ли данный
код в режиме обнаружения ошибки или в
режиме исправления ошибки.
Для
режима исправления ошибки в составе
декодера (рис. 3.10) должны присутствовать
следующие функциональные узлы:
— регистр для
временного хранения принятой кодовой
комбинации;
— устройство
вычисления синдрома;
— дешифратор
синдрома;
— устройство
исправления ошибки;
—
регистр для хранения исправленной
информационной части комбинации.
Устройство
вычисления синдрома представляет собой
совокупность из трех сумматоров по
модулю два, каждый из которых имеет по
четыре входа, которые соединяются с
выходами первого регистра в соответствии
с системой проверочных уравнений, а
выходы подключены к входам дешифратора
синдрома. Дешифратор синдрома осуществляет
преобразование синдрома в исправляющий
вектор. Устройство исправления ошибок
может быть реализовано в виде совокупности
из четырех сумматоров по модулю два,
каждый из которых имеет по два входа.
Первые входы сумматоров соединяются с
выходами информационных разрядов
первого регистра, а вторые входы
подключаются к соответствующим выходам
дешифратора синдрома, а выходы соединены
с соответствующими входами второго
регистра.
|
|
|
Рис. 3.10. Декодер |

Декодер,
работающий в режиме обнаружения ошибок,
проще, поскольку в нем отсутствует
устройство исправления ошибок, а
дешифратор синдрома может быть заменен
одной схемой выявления ненулевого
синдрома (рис. 3.11).
|
|
|
Рис. |
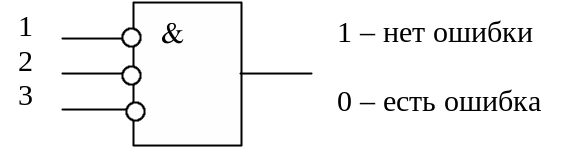
Рассмотренный
алгоритм декодирования блоковых
групповых линейных систематических
(n,
k)-
кодов, называемый иногда синдромным,
относится к классу алгебраических
методов декодирования, в основе которых
лежит решение системы уравнений, задающих
расположение и значение ошибки.
Для
декодирования этих кодов могут
использоваться и неалгебраические
методы, использующие простые структурные
понятия теории кодирования, которые
позволяют найти комбинации ошибок более
прямым путем. Одним из таких алгоритмов
является декодирование по максимуму
правдоподобия.
Этот
метод основывается на том предположении,
что если все кодовые комбинации передаются
по двоичному симметричному каналу с
равной вероятностью, то наилучшим
решением при приеме является такое, при
котором переданной считается кодовая
комбинация, отличающаяся от принятой
в наименьшем числе разрядов.
В связи с этим
алгоритм максимального правдоподобия
реализуется в виде следующей
последовательности действий:
1)
принятая кодовая комбинация Y
суммируется по модулю два последовательно
со всеми кодовыми комбинациями кода Xi
, в результате каждого суммирования
вычисляются векторы ошибок ei
= Y+Xi;
2)
подсчитывается число di
единиц в каждом из векторов ошибки ei;
3)
та из Xi,
для которой di
минимально, считается переданной кодовой
комбинацией.
Для
некоторых систематических (n,k)-кодов
неравенство (3.23)
превращается в
строгое равенство
![]()
. (3.31)
Для
таких кодов можно записать
![]()
и, поскольку
![]()
,
то
![]()
.
(n,k)-коды
вида
![]()
называются кодами Хэмминга.
Образующая
матрица кода Хэмминга (7,4) приведена
ранее (3.26). Образующие матрицы кодов
больших размерностей строятся аналогично.
Уравнение (3.31) имеет целочисленные
решения при k=0,1,4,11,26,57,120,
. . , что дает соответствующие коды
Хэмминга (3,1), (7,4), (15,11), (31,26), (63,57), (127,120),.
. . . Коды Хэмминга относятся к немногим
известным совершенным кодам.
С
учетом данных ранее определений кодового
пространства и кодового расстояния
представим некоторый код в виде сфер с
центрами во всех разрешенных кодовых
комбинациях. Все сферы имеют одинаковый
целочисленный радиус. Будем увеличивать
его, оставляя целочисленным, до тех пор,
пока сферы не соприкоснутся. Значение
этого радиуса равно числу исправляемых
кодом ошибок. Этот радиус называется
радиусом сферической упаковки кода.
Теперь
позволим этому радиусу увеличиваться
до тех пор, пока каждая точка кодового
пространства не окажется внутри хотя
бы одной сферы. Такой радиус называется
радиусом покрытия кода. Радиус упаковки
и радиус покрытия кода могут совпадать.
Код,
для которого сферы некоторого одинакового
радиуса вокруг кодовых слов, не
пересекаясь, покрывают все кодовое
пространство, называются совершенными.
Совершенный код удовлетворяет границе
Хэмминга с равенством. Код Хэмминга,
имеющий длину
![]()
,
является совершенным.
Код,
у которого сферы радиуса t
вокруг каждого кодового слова не
пересекаются и все кодовые слова, не
лежащие внутри какой-либо из этих сфер,
находятся на расстоянии t+1
хотя бы от одного кодового слова,
называется квазисовершенным.
Квазисовершенные коды встречаются
чаще, чем совершенные. Если для заданных
n
и k
существует квазисовершенный и не
существует совершенного кода, то для
этих n
и k
не существует кода с большим, чем у
квазисовершенного, кодовым расстоянием.
Систематические
коды, в том числе и код Хэмминга, допускают
различные преобразования, которые,
порождая новые коды, тем не менее, не
выводят их из класса линейных групповых
кодов.
К
числу наиболее часто используемых
преобразований кодов относят укорочение
и расширение кодов.
Укорочение
кода состоит
в уменьшении длины кодовых комбинаций
путем удаления лишних информационных
разрядов. Если код задан порождающей
матрицей, то это приводит к уменьшению
обоих размеров порождающей матрицы на
одно и то же число. Так, например, как
упоминалось ранее, коды Хэмминга с d=3
могут быть построены с вполне определенным
сочетанием n
и k.
Как поступить в том случае, если требуется
код Хэмминга с d=3,
для передачи информации достаточно
k=8,
а на длину кодовой комбинации наложено
ограничение n<15.
Для выполнения этих требований можно
выбрать код Хэмминга (15,11) и прибегнуть
к его укорочению. Укорочение производится
за счет удаления требуемого числа лишних
информационных разрядов, обычно это
первые слева разряды. В образующей
матрице кода (15,11) полагаются равными
нулю столько столбцов слева, сколько
разрядов надо удалить, после чего
вычеркиваются нулевые столбцы и строки
с полностью нулевыми строками единичной
матрицы. Относительно проверочной
матрицы операция укорочения выражается
в удалении соответствующего количества
первых слева столбцов, так как число
строк проверочной матрицы, равное числу
контрольных разрядов, остается неизменным
при укорочении. Для приведенных значений
k=8
и n<15
из кода (15,11) нужно удалить три лишних
информационных разряда, в результате
чего получится укороченный код (12,8),
который также называется кодом Хэмминга.
Расширение
кода состоит
в увеличении длины кодовых комбинаций
за счет введения новых контрольных
разрядов, что приводит к увеличению
большего размера порождающей матрицы,
и, естественно, к увеличению d,
т.е. повышению корректирующих способностей.
В качестве примера можно привести
расширенный код Хэмминга (8,4) с d=4.
Этот код образуется путем добавления
к каждой кодовой комбинации кода Хэмминга
(7,4) еще одного контрольного разряда,
значение которого определяется как
сумма по модулю два всех остальных
разрядов кодовой комбинации, т.е. общая
проверка на четность всей кодовой
комбинации. При декодировании комбинаций
этого кода возможны следующие варианты:
1) ошибок нет. Это показывает как общая
проверка на четность, так и равенство
нулю синдрома. 2) одиночная ошибка. Общая
проверка на четность указывает на
наличие ошибки, а по синдрому находится
номер искаженного разряда и ошибка в
нем исправляется. Нулевой синдром в
этом случае указывает на наличие ошибки
в дополнительном разряде, т.о. имеет
место режим исправления ошибок. 3) две
ошибки. Общая проверка на четность
указывает на отсутствие ошибок, ненулевой
синдром – на их наличие, причем значение
синдрома указывает на разряд, в котором
якобы произошла ошибка, однако в этом
случае ее не следует исправлять, а лишь
констатировать наличие двух ошибок,
т.о. реализуется режим обнаружения
ошибок.
Рассмотренные
преобразования (укорочение и расширение)
можно использовать для модификации
известных кодов, чтобы сделать их
подходящими для каких-либо конкретных
приложений, а также для получения новых
классов хороших кодов.
Контрольные
вопросы к
лекции 14
14-1.
Почему коды с обобщенными проверками
на четность называются групповыми?
14-2. Что связывают
проверочные уравнения группового кода?
14-3. Чем определяется
количество проверочных уравнений того
или иного группового кода?
14-4.
Какие кодовые комбинации выбираются в
качестве базисных при построении
образующей матрицы группового кода?
14-5.
Как строится образующая матрица
(n,k)-кода?
14-6.
Как с помощью образующей матрицы можно
найти любую разрешенную комбинацию
(n,k)-кода?
14-7.
Из каких подматриц состоит образующая
матрица (n,k)-кода?
14-8.
Как может быть построена образующая
матрица (n,k)-кода,
если не задана система проверочных
уравнений?
14-9.
Как может быть построена проверочная
матрица (n,k)-кода?
14-10. Что называется
синдромом ошибки?
14-11.
Какое значение синдрома указывает на
наличие ошибки в принятой кодовой
комбинации?
14-12. Что называется
исправляющим вектором?
14-13.
Из каких функциональных узлов состоит
кодер (n,k)-кода?
14-14.
Чем определяется количество сумматоров
по модулю два в составе кодера (n,k)-кода?
14-15.
Чем определяется количество входов у
сумматоров по модулю два в составе
кодера (n,k)-кода?
14-16.
Из каких функциональных узлов состоит
синдромный декодер (n,k)-кода?
14-17.
Что представляет собой устройство
вычисления синдрома в составе синдромного
декодера (n,k)-кода?
14-18.
Чем определяется количество входов у
сумматоров по модулю два в составе
устройства вычисления синдрома?
14-19.
Какую функцию реализует дешифратор
синдрома в составе синдромного декодера
(n,k)-кода?
14-20.
Как реализуется устройство исправления
ошибок в составе синдромного декодера
(n,k)-кода?
14-21.
Как реализуется устройство обнаружения
ошибок в составе синдромного декодера
(n,k)-кода?
14-22. Как реализуется
декодер максимального правдоподобия?
14-23.
Какие (n,k)-коды
называются кодами Хэмминга?
14-24. Что называется
радиусом сферической упаковки кода?
14-25. Что называется
радиусом покрытия кода?
14-26. Какие коды
называются совершенными?
14-27. Какие коды
называются квазисовершенными?
14-28. Как выполняется
укорочение кода?
14-29. Как выполняется
расширение кода?
14-30. Для чего
выполняется расширение кода?
Лекция 15
Полиномиальные
коды
Полиномиальные
коды
В
предыдущем разделе кодовые комбинации
(n,k)-кода
представлялись в виде набора символов
(а0,
а1,
. . .аn-1)
длиной n.
Другой способ представления того же
кодового слова состоит в том, чтобы
элементы а0,
а1,
. . .аn-1
считать коэффициентами полинома n-1
степени от некоторой фиктивной или
формальной переменной x,
т.е.
![]()
.
Используя
это обозначение, можно определить
полиномиальный код, как множество всех
полиномов степени, не большей n-1,
содержащих в качестве сомножителя
некоторый фиксированный полином g(x).
Полином g(x)
называется порождающим
полиномом кода.
Для
того чтобы иметь возможность умножать
кодовые полиномы, разлагать их на
множители и производить другие операции,
необходимо потребовать, чтобы все
коэффициенты полинома были элементами
некоторого конечного алгебраического
поля. Конечное поле, называемое также
полем Галуа и обозначаемое GF(q)
– это конечное множество, состоящее из
q
элементов, в котором определены правила
для выполнения арифметических операций.
Основное отличие их от обычных
арифметических операций состоит в том,
что в конечном поле все операции
производятся над конечным числом
элементов, в связи с чем все конечные
поля обладают следующими свойствами:
1.
Существуют две операции, используемые
для комбинирования элементов — умножение
и сложение.
2. Результатом
сложения или умножения двух элементов
является третий элемент, лежащий в том
же поле.
3.
Поле всегда содержит мультипликативную
единицу, обозначаемую 1, и аддитивную
единицу, обозначаемую 0, так, что а*1=а
и а+0=а
для любого элемента а поля.
4.
Для любого элемента а
поля существует обратный элемент по
сложению (-а),
такой, что а
+ (-а)=0 и
обратный элемент по умножению а-1
(при а0),
такой, что а*
а-1=1.
Существование этих элементов позволяет
использовать обычные обозначения для
вычитания и деления.
5.
Выполняются обычные правила ассоциативности,
коммутативности и дистрибутивности.
Конечные
поля существуют не при любом числе
элементов q,
а только в том случае, если число элементов
q
является простым числом или степенью
простого числа. В первом случае поле
называется простым, во втором –
расширенным. Для каждого допустимого
q
существует ровно одно поле. Другими
словами, правила сложения и умножения,
удовлетворяющие всем указанным
требованиям можно задать только одним
способом. Если q
– простое
число, то элементами поля являются числа
0, 1, . . . , q-1,
а сложение и умножение являются сложением
и умножением по модулю q.
С
учетом сказанного о полиномиальном
представлении кодовых комбинаций и
операций над ними для двоичного случая,
т.е. над полем GF(2),
эти операции выполняются следующим
образом.
1.
Кодовая комбинация 100101 может быть
представлена в виде полинома
f(x)=1*x5+0*x4+0*x3+1*x2+0*x1+1*x0b
= x5+x2+1.
2.
Сложение таких полиномов осуществляется
следующим образом. Пусть, например, f1
= x7+x4+x3+x+1,
а f2
= x5+x4+x2+x
, тогда f3=f1+f2
= x7+x5+x3+x2+1.
в двоичном виде 10011011
00110110 = 10101101.
3.
Умножение полиномов. Пусть, например,
f1
= x3+x2+1
и f2
= x+1,
тогда f3=f1*f2
= x4+x3+x+x3+x2+1
= x4+x2+x+1.
В двоичном виде (1101)*(11)=(01101)
(11010) = 10111. Циклический сдвиг некоторого
полинома, а он, напоминаю, форма
представления кодовой комбинации,
соответствует простому умножению этого
полинома на x.
4.
Деление полиномов. Пусть, например, f3
= x4+x2+x+1,
а f2
= x+1,
тогда f1=
f3/f2
= x3+x2+1,
что можно продемонстрировать, выполняя
деление полиномов столбиком или делая
то же самое в двоичном виде.
При
некоторых значениях n
полиномиальные коды обладают свойством
цикличности и называются циклическими.
Свойство цикличности состоит в том, что
если кодовая комбинация аn,
аn-1,
. . . , а1
является разрешенной кодовой комбинацией
данного кода, то и кодовая комбинация,
аn-1,
. . . , а1,
аn,
получаемая из нее путем циклического
сдвига, тоже будет разрешенной кодовой
комбинацией данного кода. Сдвиг обычно
осуществляется справа налево, причем
крайний левый символ переносится в
конец комбинации. Число возможных
циклических (n,k)-
кодов значительно меньше числа различных
групповых (n,k)-
кодов.
При
использовании циклических кодов процесс
кодирования, так же, как и в рассмотренных
(n,k)-
кодах, сводится к определению значений
n—k
контрольных разрядов на основании
известных значений k
информационных разрядов для каждой
кодовой комбинации.
При
полиномиальном представлении этот
процесс осуществляется следующим
образом. Полином f(x),
отображающий комбинацию безизбыточного
двоичного кода умножается на xn—k.
Это приводит к увеличению длины кодовой
комбинации на n—k
разрядов, которые и используются в
качестве контрольных. Далее произведение
f(x)*
xn—k
делится на некоторый полином g(x),
названный ранее образующим, и остаток
от этого деления r(x)
суммируется с произведением f(x)*
xn—k.
Полученная кодовая комбинация описывается
полиномом
![]()
,
(3.32)
который
без остатка делится на образующий
полином g(x).
Сказанное является
важным свойством циклических кодов,
используемым при декодировании для
обнаружения или исправления ошибок
Пример 3.10.
Пусть n=7,
k=4,
g(x)=x3+x2+1.
Найти кодовую
комбинацию s(x),
если ее
информационная часть описывается
полиномом f(x)=x3+x+1.
Решение:
n—k=7-4=3,
тогда f(x)*
xn—k
= (x3+x+1)x3
= x6+x4+x3.
![]()
с
остатком
r(x)=x2.
Таким образом,
искомая кодовая комбинация
= x6+x4+x3+x2
или в двоичном
виде 1011100, где левые четыре разряда
представляют собой информационные
разряды, соответствующие полиному
f(x)=x3+x+1,
а остальные
три разряда – контрольные, соответствующие
полиному
r(x)=x2.
Таким образом,
выявлено первое свойство образующего
полинома g(x),
состоящее в том, что все разрешенные
комбинации данного кода делятся на него
без остатка. Он позволяет выбрать из
большого числа комбинаций только те,
которые удовлетворяют заданному закону
построения кода, т.е. разрешенные. Именно
поэтому полином g(x)
и называется образующим.
Степень l
образующего
полинома g(x)
не может быть меньше требуемого
числа контрольных разрядов n-k.
Для упрощения обычно полагают l=n—k.
Но не любой полином этой степени может
выступать в качестве образующего
полинома циклического кода. В качестве
таковых могут использоваться только
так называемые неприводимые
полиномы. Полином называется приводимым,
если он может быть представлен в виде
произведения полиномов низших степеней,
в противном случае полином называется
неприводимым. Другими словами, неприводимый
полином делится без остатка только на
самого себя и на единицу. Неприводимые
полиномы играют роль, сходную с простыми
числами в теории чисел. Из нескольких
неприводимых полиномов данной степени
в качестве образующего полинома следует
выбирать самый короткий, однако число
ненулевых членов g(x)
не должно быть меньше требуемого кодового
расстояния кода.
Циклические
коды являются подклассом рассмотренных
ранее групповых систематических
(n,k)-кодов.
Следовательно, кроме полиномиального
описания, они могут быть описаны с
помощью образующей и проверочной матриц.
Образующая
матрица циклического кода может быть
построена методом, аналогичным
рассмотренному ранее.
Пример
3.11. Построить
образующую матрицу циклического кода
(7,4) с образующим полиномом g(x)=x3+x+1.
Решение.
Запишем базовые
информационные комбинации:
|
0001 |
0010 |
0100 |
1000 |
Представим их в
виде полиномов:
|
1 |
x |
x2 |
x3 |
Умножим на xn—k=x3
|
x3 |
x4 |
x5 |
x6 |
Поделим
каждый из них на образующий полином и
зафиксируем остаток:
|
Частное |
Остаток |
||
|
|
1 |
|
011 |
|
|
|
|
110 |
|
|
|
|
111 |
|
|
|
101 |
Тогда
образующая матрица этого кода может
быть представлена следующим образом

или в общем виде
![]()
.
Существует
другой способ построения образующей
матрицы, базирующийся на основной
особенности циклического (n,k)-кода.
Первая строка образующей матрицы
формируется путем приписывания слева
к представленному двоичным кодом
образующему полиному k-1
нулей. Каждая следующая строка образуется
циклическим сдвигом предыдущей строки
на один разряд влево. Для того же
образующего полинома g(x)=x3+x+1
образующая
матрица, построенная таким способом,
будет выглядеть следующим образом
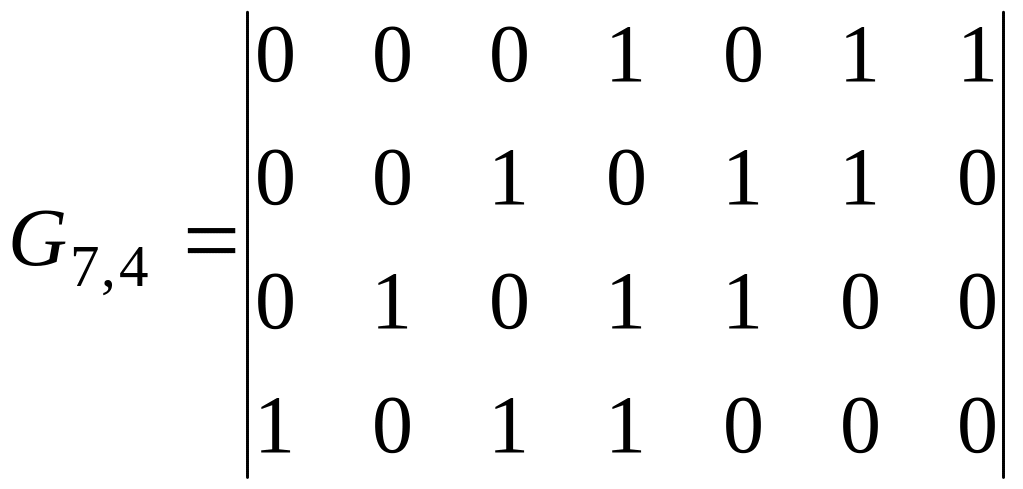
.
Рассмотренный
метод проще, но получающаяся матрица
менее удобна для использования. Такой
вид образующей матрицы в отличие от
предыдущего называется неканоническим.
Переход
от неканонической формы образующей
матрицы к канонической осуществляется
на основании того, что циклический код,
будучи подклассом рассмотренных ранее
групповых систематических (n,k)-кодов,
является групповым и линейным и,
следовательно, обладает свойством
замкнутости.
Метод
получения канонической формы проверочной
матрицы циклического кода аналогичен
рассмотренному ранее общему для групповых
кодов методу, т.е.
![]()
.
Тогда
для рассматриваемого циклического кода
с образующим полиномом g(x)=x3+x+1
проверочная матрица будет выглядеть
следующим образом
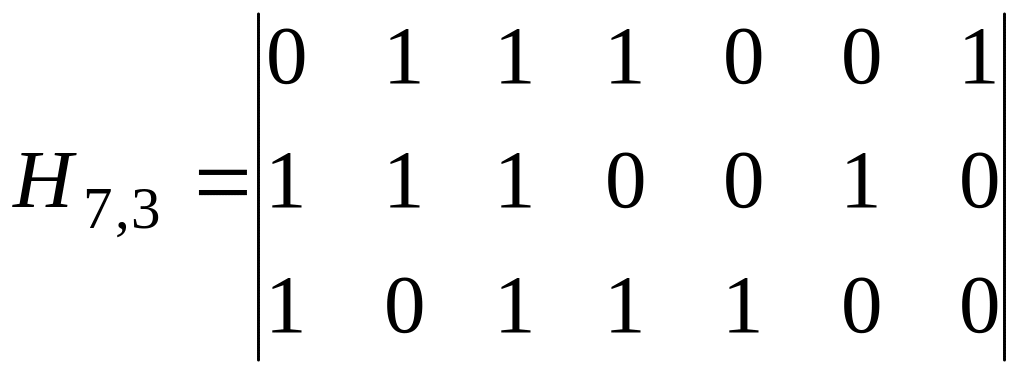
.
Идея
обнаружения ошибок в кодовой комбинации
циклического кода основана на
сформулированном ранее утверждении,
что при отсутствии ошибок принятая
кодовая комбинация совпадает с переданной
![]()
,
т.е. без остатка делится на образующий
полином g(x).
При
наличии ошибок переданная комбинация
![]()
преобразуется в
![]()
,
где
![]()
— полином ошибок, содержащий столько
членов и на тех позициях, в которых не
совпадают элементы переданной и принятой
комбинаций.
Следовательно,
при делении
![]()
на g(x)
получим
![]()
.
При наличии
однократной ошибки в каком-либо
информационном разряде полиномы ошибок
имеют вид:
|
1 |
x |
x2 |
x3 |
Деление
этих полиномов на образующий уже было
выполнено ранее. С этих позиций можно
по-другому взглянуть на содержимое
образующей матрицы. Если строки единичной
подматрицы рассматривать как полиномы
ошибок, то соответствующие строки
дополняющей подматрицы представляют
собой остатки, указывающие на ошибку в
разряде, указываемом полиномом ошибки.
Таким образом, остаток от деления
полинома принятой кодовой комбинации
на образующий полином играет роль
синдрома, что свидетельствует о
возможности применения к циклическим
кодам метода синдромного декодирования.
Возможность
матричного описания циклических кодов
указывает на то, что кодеры и декодеры
циклических кодов могут быть построены
на основе этого писания методами,
рассмотренными ранее.
Из
полиномиального описания циклических
кодов следует, что процессы кодирования
и декодирования этих кодов представляют
собой операции деления полиномов. Для
аппаратной реализации операции деления
полиномов используются циклические
регистры сдвига, т.е. последовательные
регистры с обратной связью, в цепи
которой устанавливаются сумматоры по
модулю два.
Один
из методов построения кодера циклического
кода на основе упомянутых регистров
можно описать следующим образом:
1.
Число разрядов регистра, т.е. число
триггеров, выбирается равным числу
проверочных разрядов n—k,
т.е. равным степени образующего полинома.
2.
Число двухвходовых сумматоров по модулю
два берется на единицу меньше числа
членов образующего полинома.
3.
Триггеры регистра нумеруются слева
направо от 1 до n—k.
4.
Сумматоры по модулю два располагаются
после тех триггеров, номера которых
совпадают со степенями ненулевых членов
образующего полинома.
5.
Выходы предыдущих триггеров соединяются
с входами последующих через сумматоры
по модулю два там, где они есть, или
непосредственно, там, где их нет.
6.
На второй вход сумматора по модулю два,
первый вход которого соединен с выходом
последнего триггера с номером n—k,
подаются в последовательном коде
информационные разряды, т.е. этот вход
является входом кодера. Выход этого
сумматора соединяется с входом первого
триггера и вторыми входами всех остальных
сумматоров по модулю два.
После
того, как все k
информационных
разрядов последовательно поступят в
кодер, одновременно будучи выданными
в линию, в триггерах регистра будет
сформирован остаток, состоящий из n—k
контрольных символов, которые должны
быть переданы вслед за информационными.
Для управления этим процессом в структуру
кодера необходимо ввести три ключа К1,
К2, К3. Ключи К1 и К2 необходимы для того,
чтобы коммутировать выход кодера либо
с входом кодера при передаче k
информационных разрядов, либо с выходом
регистра при передаче n—k
контрольных разрядов. Чтобы эти уже
сформированные разряды выдвигались из
регистра без искажений, необходимо
разорвать цепь обратной связи, для чего
и служит ключ К3.
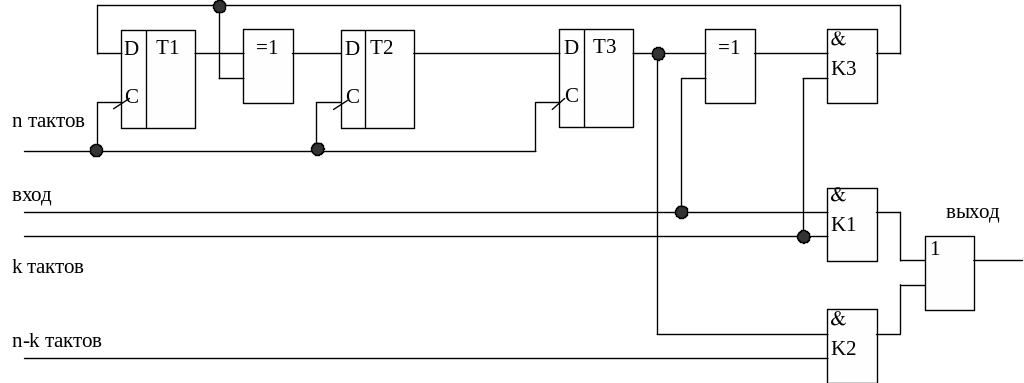
С
учетом всего сказанного построим
структуру кодера (рис. 3.12) циклического
кода (7,4) с образующим полиномом
g(x)=x3+x+1.
|
|
|
Рис. 3.12. Кодер |
Иногда
более удобной оказывается другая
реализация кодера с использованием не
(n—k)-разрядного,
а k-разрядного
регистра сдвига с обратной связью на
основе сумматоров по модулю два, который
описывается не образующим, а т.н.
проверочным полиномом h(x),
получаемым в соответствии с выражением
![]()
.
Для рассмотренного ранее кода проверочный
полином
![]()
.
Построенная
в соответствии с этим полиномом структура
кодера приведена на рис. 3.13.
|
|
|
Рис. 3.13. Кодер |
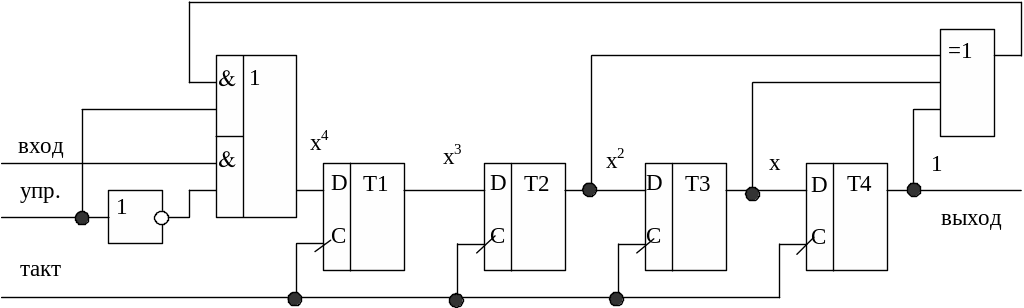
Работа
кодера начинается с того, что в регистр
с отключенной обратной связью (0 на входе
управления) заносятся четыре информационных
символа (старший разряд в Т4). Затем
обратная связь включается (1 на входе
управления) и регистр сдвигается семь
раз. Первые четыре символа, поступающие
с выхода кодера, являются информационными,
следующие за ними три символа –
контрольными.
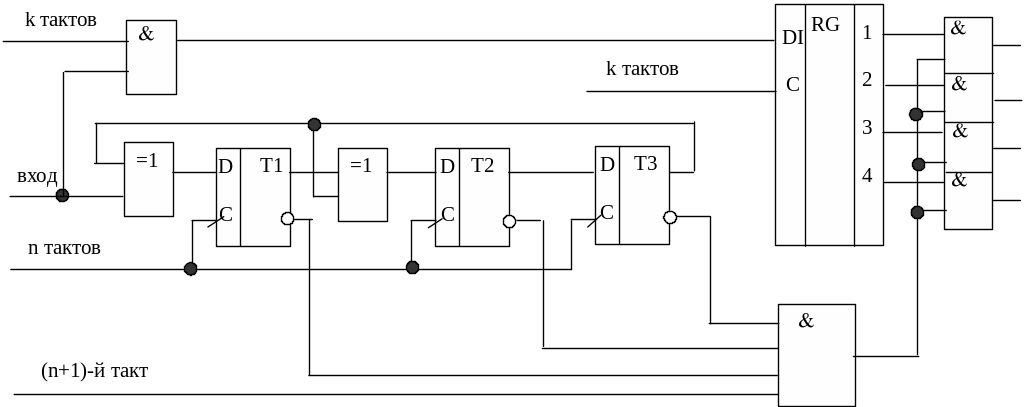
Декодер
циклического кода в соответствии с
изложенным ранее принципом декодирования
содержит устройство деления полинома
принятой кодовой комбинации на образующий
полином. Это устройство реализуется
так же, как и в кодере с помощью циклического
регистра сдвига с сумматорами по модулю
два, расставленными между триггерами
регистра в соответствии с образующим
полиномом. Отличие декодера состоит в
том, что цепь обратной связи берется не
с выхода последнего сумматора, а с выхода
последнего триггера регистра. Кроме
того, в состав декодера необходимо
ввести буферный регистр для хранения
информационных разрядов и дешифратор
остатка (синдрома).
Дешифратор
остатка может быть реализован по-разному
в зависимости от того, в каком режиме
используется данный код: только для
обнаружения ошибок или для исправления
ошибок.
В
первом случае дешифратор остатка только
выявляет, равен остаток нулю или не
равен. В последнем случае вырабатывается
сигнал о наличии ошибки в принятой
комбинации и запрещается передача
хранящихся в буферном регистре
информационных разрядов для дальнейшей
обработки. С учетом этого структуру
такого декодера можно представить
следующим образом (рис. 3.14).
|
|
|
Рис. 3.14. Декодер |
|
Для |
|
|
Рис. |

Циклические
коды, будучи подклассом линейных
групповых кодов, так же как и рассмотренные
ранее коды, могут быть подвергнуты в
зависимости от требований системы, в
которой они используются простым
преобразованиям, среди которых ранее
упоминались расширение кода и укорочение
кода. В некоторых случаях преобразования
может получиться код, в котором циклический
сдвиг его кодовой комбинации не всегда
приводит к другой разрешенной кодовой
комбинации. Такие коды называются
псевдоциклическими.
Для
увеличения кодового расстояния
циклического кода может быть использовано
преобразование расширения кода,
выполняемое за счет введения дополнительных
контрольных разрядов. Одним из простейших
способов расширения кода является
введение одного контрольного разряда
общей проверки на четность. В результате,
например, циклический код (7,4) с образующим
полиномом
![]()
превратиться в циклический код (8,4) с
образующим полиномом
![]()
,
поскольку полином (x+1)
является образующим для циклического
кода с одним контрольным разрядом,
способным обнаруживать все ошибки
нечетной кратности. Отсюда (попутно)
можно сделать вывод о том, что код с
проверкой на четность является циклическим
кодом с образующим полиномом (x+1).
Полученный расширенный код с d=4
будет обладать такими же корректирующими
свойствами, что и аналогичный расширенный
код Хэмминга. Можно сделать обобщение,
состоящее в том, что для любого кода с
нечетным кодовым расстоянием введение
общей проверки на четность увеличивает
кодовое расстояние на 1.
Если
далее над этим кодом выполнить операцию
укорочения, состоящую в удалении одного
информационного разряда, то получится
код (7,3) с d=4
и проверочной матрицей
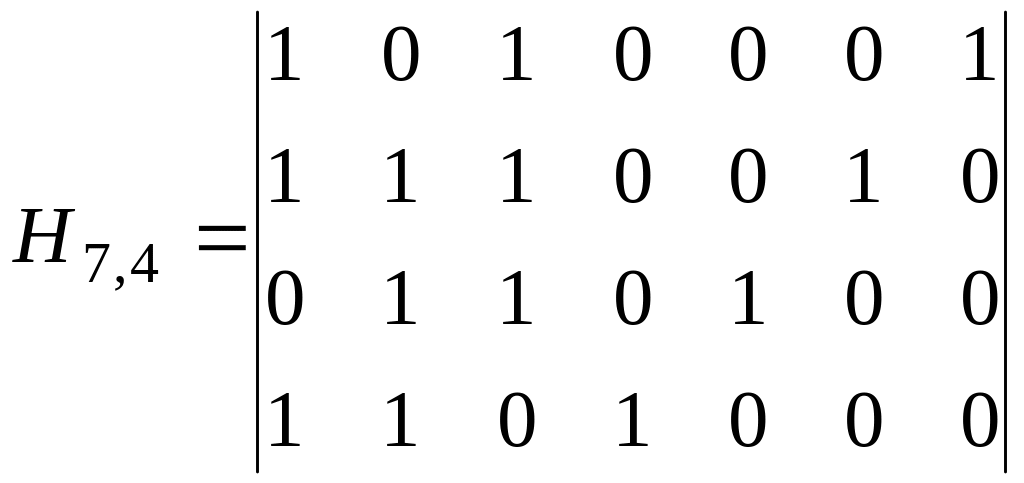
.
Этот
код приведен здесь, во-первых, в качестве
примера выполнения простых операций
по преобразованию кодов, а во-вторых,
для того, что с его помощью проще всего
продемонстрировать еще один метод
декодирования, отличающийся от
рассмотренного ранее синдромного
метода, и называемый методом мажоритарного
декодирования.
Метод
мажоритарного декодирования применим
тогда, когда систему общих контрольных
проверок удается за счет использования
различных линейных комбинаций из
уравнений, входящих в нее, изменить так,
что для каждого символа aj
может быть построена система уравнений:
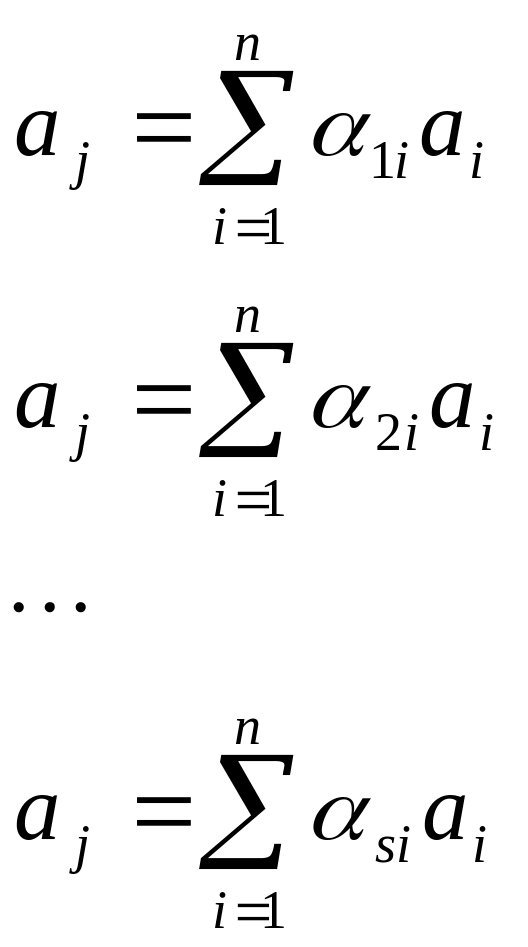
,
называемая
системой раздельных контрольных проверок
и обладающая тем свойством, что в правую
часть каждого уравнения входят символы,
отличные от aj
и всякий такой символ входит не более
чем в одно уравнение. Такая система
проверок называется ортогональной.
Если
число уравнений, входящих в каждую
ортогональную систему, не меньше s,
то путем голосования по большинству
могут быть исправлены любые
![]()
ошибок. В самом деле, ошибка в одном
символе влияет в силу ортогональности
не более чем на одну проверку, следовательно,
среди значений символа aj,
которые получены из всех s
проверок, неправильными могут оказаться
не более t,
т.е. не более половины уравнений. Тогда,
сравнивая значения правых частей
проверок, а также значение самого символа
aj,
можно по большинству значений определить
верное значение этого символа. Если при
нечетном s
![]()
имеет место равенство голосов, то ошибка
обнаруживается, но не исправляется.
Случай,
когда число s
проверок в каждой ортогональной системе
на единицу меньше кодового расстояния
s=d-1
является в известном смысле идеальным.
В этом случае голосование позволяет
полностью реализовать корректирующие
свойства кода. Код, для каждого символа
которого существует система из d-1
ортогональных проверок, называется
полностью ортогонализируемым.
Именно
к таким кодам относится код (7,3), проверочная
матрица которого получена ранее в
результате последовательных операций
расширения и укорочения циклического
кода. Пользуясь ею
,
можно записать систему проверочных
уравнений
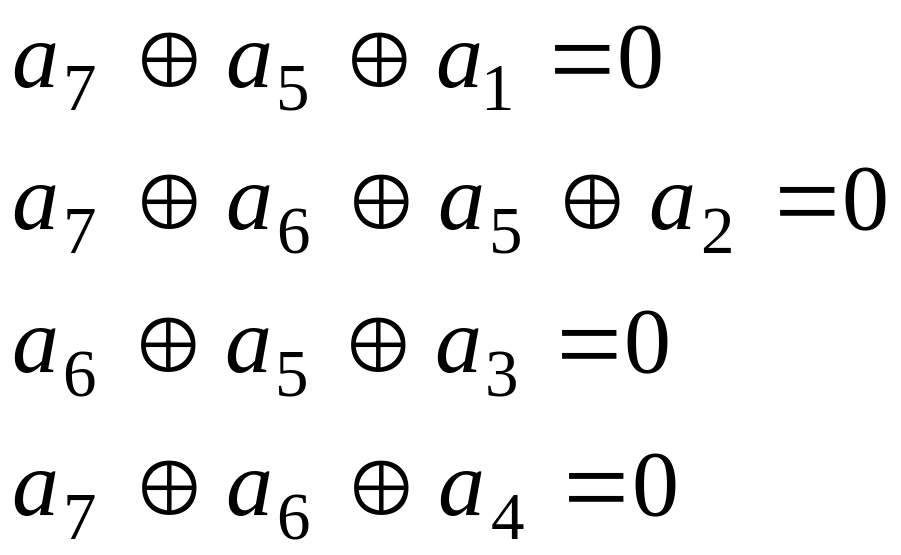
.
Суммируя
по модулю два второе и третье уравнения
и разрешая полученные три уравнения
относительно а7,
получаем систему
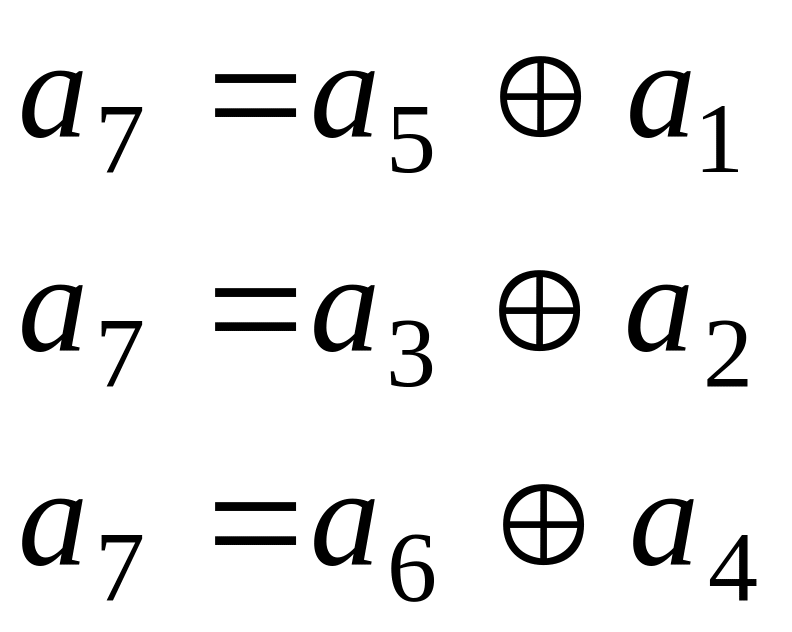
,
отвечающую
сформулированным ранее условиям
ортогональности.
Такие
ортогональные системы могут быть
достаточно просто в силу свойства
цикличности составлены для всех символов
кодовой комбинации, т.е. уравнения
циклически сдвигаются в индексах с
выполнением операции по модулю n.
Анализируя
указанным выше способом каждый символ
принятой кодовой комбинации можно
правильно восстановить посланную
кодовую комбинацию, если произошло не
более одной ошибки, или обнаружит двойную
ошибку. Тем самым полностью реализуются
корректирующие способности этого кода,
поскольку его кодовое расстояние d=4.
Метод
мажоритарного декодирования отличается
простотой технической реализации
особенно в случае двоичных циклических
кодов. Наряду с регистром сдвига для
приема кодовой комбинации и совокупностью
сумматоров по модулю два, которые
реализуют ортогональную систему
проверок, декодер должен содержать
мажоритарный элемент. Для рассматриваемого
примера функция мажоритарного элемента
описывается таблицей истинности,
приведенной ниже.
|
1 |
2 |
3 |
М |
|
0 |
0 |
0 |
0 |
|
0 |
0 |
1 |
0 |
|
0 |
1 |
0 |
0 |
|
0 |
1 |
1 |
1 |
|
1 |
0 |
0 |
0 |
|
1 |
0 |
1 |
1 |
|
1 |
1 |
0 |
1 |
|
1 |
1 |
1 |
1 |
7.1. Классификация корректирующих кодов
7.2. Принципы помехоустойчивого кодирования
7.3. Систематические коды
7.4. Код с четным числом единиц. Инверсионный код
7.5. Коды Хэмминга
7.6. Циклические коды
7.7. Коды с постоянным весом
7.8. Непрерывные коды
7.1. Классификация корректирующих кодов
В каналах с помехами эффективным средством повышения достоверности передачи сообщений является помехоустойчивое кодирование. Оно основано на применении специальных кодов, которые корректируют ошибки, вызванные действием помех. Код называется корректирующим, если он позволяет обнаруживать или обнаруживать и исправлять ошибки при приеме сообщений. Код, посредством которого только обнаруживаются ошибки, носит название обнаруживающего кода. Исправление ошибки при таком кодировании обычно производится путем повторения искаженных сообщений. Запрос о повторении передается по каналу обратной связи. Код, исправляющий обнаруженные ошибки, называется исправляющим, кодом. В этом случае фиксируется не только сам факт наличия ошибок, но и устанавливается, какие кодовые символы приняты ошибочно, что позволяет их исправить без повторной передачи. Известны также коды, в которых исправляется только часть обнаруженных ошибок, а остальные ошибочные комбинации передаются повторно.
Для того чтобы «од обладал корректирующими способностями, в кодовой последовательности должны содержаться дополнительные (избыточные) символы, предназначенные для корректирования ошибок. Чем больше избыточность кода, тем выше его корректирующая способность.
Помехоустойчивые коды могут быть построены с любым основанием. Ниже рассматриваются только двоичные коды, теория которых разработана наиболее полно.
В настоящее время известно большое количество корректирующих кодов, отличающихся как принципами построения, так и основными характеристиками. Рассмотрим их простейшую классификацию, дающую представление об основных группах, к которым принадлежит большая часть известных кодов [12]. На рис. 7.1 показана схема, поясняющая классификацию, проведенную по способам построения корректирующих кодов.
Все известные в настоящее время коды могут быть разделены
на две большие группы: блочные и непрерывные. Блочные коды характеризуются тем, что последовательность передаваемых символов разделена на блоки операции кодирования и декодирования в каждом блоке производятся отдельно. Отличительной особенностью непрерывных кодов является то, что первичная последовательность символов, несущих информацию, непрерывно преобразуется по определенному закону в другую последовательность, содержащую избыточное число символов. Здесь процессы кодирования и декодирования не требуют деления кодовых символов на блоки.
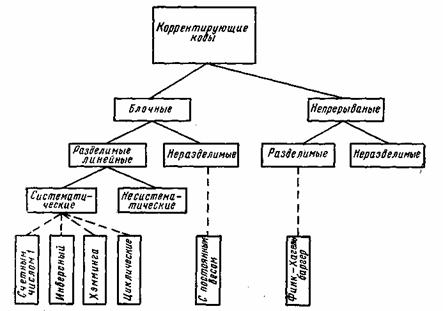
Рис. 7.1. Классификация корректирующих кодов
Разновидностями как блочных, так и непрерывных кодов являются разделимые и неразделимые коды. В разделимых кодах всегда можно выделить информационные символы, содержащие передаваемую информацию, и контрольные (проверочные) символы, которые являются избыточными и служат ‘исключительно для коррекции ошибок. В неразделимых кодах такое разделение символов провести невозможно.
Наиболее многочисленный класс разделимых кодов составляют линейные коды. Основная их особенность состоит в том, что контрольные символы образуются как линейные комбинации информационных символов.
В свою очередь, линейные коды могут быть |разбиты на два подкласса: систематические и несистематические. Все двоичные систематические коды являются групповыми. Последние характеризуются принадлежностью кодовых комбинаций к группе, обладающей тем свойством, что сумма по модулю два любой пары комбинаций снова дает комбинацию, принадлежащую этой группе. Линейные коды, которые не могут быть отнесены к подклассу систематических, называются несистематическими. Вертикальными прямоугольниками на схеме рис. 7.1 представлены некоторые конкретные коды, описанные в последующих параграфах.
7.2. Принципы помехоустойчивого кодирования
В теории помехоустойчивого кодирования важным является вопрос об использовании избыточности для корректирования возникающих при передаче ошибок. Здесь удобно рассмотреть блочные моды, в которых всегда имеется возможность выделить отдельные кодовые комбинации. Напомним, что для равномерных кодов, которые в дальнейшем только и будут изучаться, число возможных комбинаций равно M=2n, где п — значность кода. В обычном некорректирующем коде без избыточности, например в коде Бодо, число комбинаций М выбирается равным числу сообщений алфавита источника М0и все комбинации используются для передачи информации. Корректирующие коды строятся так, чтобы число комбинаций М превышало число сообщений источника М0. Однако в.этом случае лишь М0комбинаций из общего числа используется для передачи информации. Эти комбинации называются разрешенными, а остальные М—М0комбинаций носят название запрещенных. На приемном конце в декодирующем устройстве известно, какие комбинации являются разрешенными и какие запрещенными. Поэтому если переданная разрешенная комбинация в результате ошибки преобразуется в некоторую запрещенную комбинацию, то такая ошибка будет обнаружена, а при определенных условиях исправлена. Естественно, что ошибки, приводящие к образованию другой разрешенной комбинации, не обнаруживаются.
Различие между комбинациями равномерного кода принято характеризовать расстоянием, равным числу символов, которыми отличаются комбинации одна от другой. Расстояние d![]() между двумя комбинациями
между двумя комбинациями ![]() и
и ![]() определяется количеством единиц в сумме этих комбинаций по модулю два. Например,
определяется количеством единиц в сумме этих комбинаций по модулю два. Например,
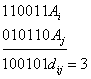
Для любого кода d![]()
![]() . Минимальное расстояние между разрешенными комбинациями ,в данном коде называется кодовым расстоянием d.
. Минимальное расстояние между разрешенными комбинациями ,в данном коде называется кодовым расстоянием d.
Расстояние между комбинациями ![]() и
и ![]() условно обозначено на рис. 7.2а, где показаны промежуточные комбинации, отличающиеся друг от друга одним символом. B общем случае некоторая пара разрешенных комбинаций
условно обозначено на рис. 7.2а, где показаны промежуточные комбинации, отличающиеся друг от друга одним символом. B общем случае некоторая пара разрешенных комбинаций ![]() и
и ![]() , разделенных кодовым расстоянием d, изображается на прямой рис. 7.2б, где точками указаны запрещенные комбинации. Для того чтобы в результате ошибки комбинация
, разделенных кодовым расстоянием d, изображается на прямой рис. 7.2б, где точками указаны запрещенные комбинации. Для того чтобы в результате ошибки комбинация ![]() преобразовалась в другую разрешенную комбинацию
преобразовалась в другую разрешенную комбинацию ![]() , должно исказиться d символов.
, должно исказиться d символов.
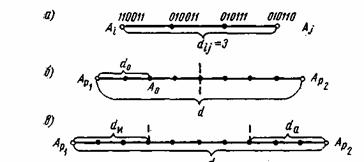
Рис. 7.2. Геометрическое представление разрешенных и запрещенных кодовых комбинаций
При искажении меньшего числа символов комбинация ![]() перейдет в запрещенную комбинацию и ошибка будет обнаружена. Отсюда следует, что ошибка всегда обнаруживается, если ее кратность, т. е. число искаженных символов в кодовой комбинации,
перейдет в запрещенную комбинацию и ошибка будет обнаружена. Отсюда следует, что ошибка всегда обнаруживается, если ее кратность, т. е. число искаженных символов в кодовой комбинации,
![]() (7.1)
(7.1)
Если g>d, то некоторые ошибки также обнаруживаются. Однако полной гарантии обнаружения ошибок здесь нет, так как ошибочная комбинация ib этом случае может совпасть с какой-либо разрешенной комбинацией. Минимальное кодовое расстояние, при котором обнаруживаются любые одиночные ошибки, d=2.
Процедура исправления ошибок в процессе декодирования сводится к определению переданной комбинации по известной принятой. Расстояние между переданной разрешенной комбинацией и принятой запрещенной комбинацией d0 равно кратности ошибок g. Если ошибки в символах комбинации происходят независимо относительно друг друга, то вероятность искажения некоторых g символов в n-значной комбинации будет равна:
![]() (7.2)
(7.2)
где ![]() — вероятность искажения одного символа. Так как обычно
— вероятность искажения одного символа. Так как обычно ![]() <<1, то вероятность многократных ошибок уменьшается с увеличением их кратности, при этом более вероятны меньшие расстояния d0. В этих условиях исправление ошибок может производиться по следующему правилу. Если принята запрещенная комбинация, то считается переданной ближайшая разрешенная комбинация. Например, пусть образовалась запрещенная комбинация
<<1, то вероятность многократных ошибок уменьшается с увеличением их кратности, при этом более вероятны меньшие расстояния d0. В этих условиях исправление ошибок может производиться по следующему правилу. Если принята запрещенная комбинация, то считается переданной ближайшая разрешенная комбинация. Например, пусть образовалась запрещенная комбинация ![]() (см.рис.7.2б), тогда принимается решение, что была передана комбинация
(см.рис.7.2б), тогда принимается решение, что была передана комбинация ![]() . Это .правило декодирования для указанного распределения ошибок является оптимальным, так как оно обеспечивает исправление максимального числа ошибок. Напомним, что аналогичное правило используется в теории потенциальной помехоустойчивости при оптимальном приеме дискретных сигналов, когда решение сводится к выбору того переданного сигнала, который ib наименьшей степени отличается от принятого. Нетрудно определить, что при таком правиле декодирования будут исправлены все ошибки кратности
. Это .правило декодирования для указанного распределения ошибок является оптимальным, так как оно обеспечивает исправление максимального числа ошибок. Напомним, что аналогичное правило используется в теории потенциальной помехоустойчивости при оптимальном приеме дискретных сигналов, когда решение сводится к выбору того переданного сигнала, который ib наименьшей степени отличается от принятого. Нетрудно определить, что при таком правиле декодирования будут исправлены все ошибки кратности
![]() (7.3)
(7.3)
Минимальное значение d, при котором еще возможно исправление любых одиночных ошибок, равно 3.
Возможно также построение таких кодов, в которых часть ошибок исправляется, а часть только обнаруживается. Так, в соответствии с рис. 7.2в ошибки кратности ![]() исправляются, а ошибки, кратность которых лежит в пределах
исправляются, а ошибки, кратность которых лежит в пределах ![]() только обнаруживаются. Что касается ошибок, кратность которых сосредоточена в пределах
только обнаруживаются. Что касается ошибок, кратность которых сосредоточена в пределах ![]() , то они обнаруживаются, однако при их исправлении принимается ошибочное решение — считается переданной комбинация А
, то они обнаруживаются, однако при их исправлении принимается ошибочное решение — считается переданной комбинация А![]() вместо A
вместо A![]() или наоборот.
или наоборот.
Существуют двоичные системы связи, в которых решающее устройство выдает, кроме обычных символов 0 и 1, еще так называемый символ стирания ![]() . Этот символ соответствует приему сомнительных сигналов, когда затруднительно принять определенное решение в отношении того, какой из символов 0 или 1 был передан. Принятый символ в этом случае стирается. Однако при использовании корректирующего кода возможно восстановление стертых символов. Если в кодовой комбинации число символов
. Этот символ соответствует приему сомнительных сигналов, когда затруднительно принять определенное решение в отношении того, какой из символов 0 или 1 был передан. Принятый символ в этом случае стирается. Однако при использовании корректирующего кода возможно восстановление стертых символов. Если в кодовой комбинации число символов ![]() оказалось равным gc, причем
оказалось равным gc, причем
![]() (7.4)
(7.4)
а остальные символы приняты без ошибок, то такая комбинация полностью восстанавливается. Действительно, для восстановления всех символов ![]() необходимо перебрать всевозможные сочетания из gc символов типа 0 и 1. Естественно, что все эти сочетания, за исключением одного, будут неверными. Но так как в неправильных сочетаниях кратность ошибок
необходимо перебрать всевозможные сочетания из gc символов типа 0 и 1. Естественно, что все эти сочетания, за исключением одного, будут неверными. Но так как в неправильных сочетаниях кратность ошибок ![]() , то согласно неравенству (7.1) такие ошибки обнаруживаются. Другими словами, в этом случае неправильно восстановленные сочетания из gc символов совместно с правильно принятыми символами образуют запрещенные комбинации и только одно- сочетание стертых символов даст разрешенную комбинацию, которую и следует считать как правильно восстановленную.
, то согласно неравенству (7.1) такие ошибки обнаруживаются. Другими словами, в этом случае неправильно восстановленные сочетания из gc символов совместно с правильно принятыми символами образуют запрещенные комбинации и только одно- сочетание стертых символов даст разрешенную комбинацию, которую и следует считать как правильно восстановленную.
Если ![]() , то при восстановлении окажется несколько разрешенных комбинаций, что не позволит принять однозначное решение.
, то при восстановлении окажется несколько разрешенных комбинаций, что не позволит принять однозначное решение.
Таким образом, при фиксированном кодовом расстоянии максимально возможная кратность корректируемых ошибок достигается в кодах, которые обнаруживают ошибки или .восстанавливают стертые символы. Исправление ошибок представляет собой более трудную задачу, практическое решение которой сопряжено с усложнением кодирующих и декодирующих устройств. Поэтому исправляющие «оды обычно используются для корректирования ошибок малой кратности.
Корректирующая способность кода возрастает с увеличением d. При фиксированном числе разрешенных комбинаций М![]() увеличение d возможно лишь за счет роста количества запрещенных комбинаций:
увеличение d возможно лишь за счет роста количества запрещенных комбинаций:
![]() (7.5)
(7.5)
что, в свою очередь, требует избыточного числа символов r=n—k, где k — количество символов в комбинации кода без избыточности. Можно ввести понятие избыточности кода и количественно определить ее по аналогии с (6.12) как
![]() (7.6)
(7.6)
При независимых ошибках вероятность определенного сочетания g ошибочных символов в n-значной кодовой комбинации выражается ф-лой ((7.2), а количество всевозможных сочетаний g ошибочных символов в комбинации зависит от ее длины и определяется известной формулой числа сочетаний
![]()
Отсюда полная вероятность ошибки кратности g, учитывающая все сочетания ошибочных символов, равняется:
![]() (7.7)
(7.7)
Используя (7.7), можно записать формулы, определяющие вероятность отсутствия ошибок в кодовой комбинации, т. е. вероятность правильного приема
![]()
и вероятность правильного корректирования ошибок
![]()
Здесь суммирование ‘Производится по всем значениям кратности ошибок g, которые обнаруживаются и исправляются. Таким образом, вероятность некорректируемых ошибок равна:
![]() (7.8)
(7.8)
Анализ ф-лы (7.8) показывает, что при малой величине Р0и сравнительно небольших значениях п наиболее вероятны ошибки малой кратности, которые и необходимо корректировать в первую очередь.
Вероятность Р![]() , избыточность
, избыточность ![]() и число символов n являются основными характеристиками корректирующего кода, определяющими, насколько удается повысить помехоустойчивость передачи дискретных сообщений и какой ценой это достигается.
и число символов n являются основными характеристиками корректирующего кода, определяющими, насколько удается повысить помехоустойчивость передачи дискретных сообщений и какой ценой это достигается.
Общая задача, которая ставится при создании кода, заключается, в достижении наименьших значений Р![]() и
и ![]() . Целесообразность применения того или иного кода зависит также от сложности кодирующих и декодирующих устройств, которая, в свою очередь, зависит от п. Во многих практических случаях эта сторона вопроса является решающей. Часто, например, используются коды с большой избыточностью, но обладающие простыми правилами кодирования и декодирования.
. Целесообразность применения того или иного кода зависит также от сложности кодирующих и декодирующих устройств, которая, в свою очередь, зависит от п. Во многих практических случаях эта сторона вопроса является решающей. Часто, например, используются коды с большой избыточностью, но обладающие простыми правилами кодирования и декодирования.
В соответствии с общим принципом корректирования ошибок, основанным на использовании разрешенных и запрещенных комбинаций, необходимо сравнивать принятую комбинацию со всеми комбинациями данного кода. В результате М сопоставлений и принимается решение о переданной комбинации. Этот способ декодирования логически является наиболее простым, однако он требует сложных устройств, так как в них должны запоминаться все М комбинаций кода. Поэтому на практике чаще всего используются коды, которые позволяют с помощью ограниченного числа преобразований принятых кодовых символов извлечь из них всю информацию о корректируемых ошибках. Изучению таких кодов и посвящены последующие разделы.
7.3. Систематические коды
Изучение конкретных способов помехоустойчивого кодирования начнем с систематических кодов, которые в соответствии с классификацией (рис. 7.1) относятся к блочным разделимым кодам, т. е. к кодам, где операции кодирования осуществляются независимо в пределах каждой комбинации, состоящей из информационных и контрольных символов.
Остановимся кратко на общих принципах построения систематических кодов. Если обозначить информационные символы буквами с, а контрольные — буквами е, то любую кодовую комбинацию, содержащую k информационных и r контрольных символов, можно представить последовательностью:![]() , где с и е в двоичном коде принимают значения 0 или 1.
, где с и е в двоичном коде принимают значения 0 или 1.
Процесс кодирования на передающем конце сводится к образованию контрольных символов, которые выражаются в виде линейной функции информационных символов:
![]()
![]() (7.9)
(7.9)
Здесь ![]() — коэффициенты, равные 0 или 1, а
— коэффициенты, равные 0 или 1, а ![]() и
и ![]() — знаки суммирования по модулю два. Значения
— знаки суммирования по модулю два. Значения ![]()
![]() выбираются по определенным правилам, установленным для данного вида кода. Иными словами, символы е представляют собой суммы по модулю два информационных символов в различных сочетаниях. Процедура декодирования принятых комбинаций может осуществляться различными» методами. Один из них, так называемый метод контрольных чисел, состоит в следующем. Из информационных символов принятой кодовой комбинации
выбираются по определенным правилам, установленным для данного вида кода. Иными словами, символы е представляют собой суммы по модулю два информационных символов в различных сочетаниях. Процедура декодирования принятых комбинаций может осуществляться различными» методами. Один из них, так называемый метод контрольных чисел, состоит в следующем. Из информационных символов принятой кодовой комбинации ![]()
![]()
![]() образуется по правилу (7.9) вторая группа контрольных символов
образуется по правилу (7.9) вторая группа контрольных символов ![]()
![]()
Затем производится сравнение обеих групп контрольных символов путем их суммирования по модулю два:
![]()
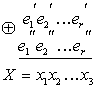 (7.10)
(7.10)
Полученное число X называется контрольным числом или синдромом. С его помощью можно обнаружить или исправить часть ошибок. Если ошибки в принятой комбинации отсутствуют, то все суммы![]()
![]() , а следовательно, и контрольное число X будут равны .нулю. При появлении ошибок некоторые значения х могут оказаться равным 1. В этом случае
, а следовательно, и контрольное число X будут равны .нулю. При появлении ошибок некоторые значения х могут оказаться равным 1. В этом случае ![]() , что и позволяет обнаружить ошибки. Таким образом, контрольное число Х определяется путем r проверок на четность.
, что и позволяет обнаружить ошибки. Таким образом, контрольное число Х определяется путем r проверок на четность.
Для исправления ошибок знание одного факта их возникновения является недостаточным. Необходимо указать номер ошибочно принятых символов. С этой целью каждому сочетанию исправляемых ошибок в комбинации присваивается одно из контрольных чисел, что позволяет по известному контрольному числу определить место положения ошибок и исправить их.
Контрольное число X записывается в двоичной системе, поэтому общее количество различных контрольных чисел, отличающихся от нуля, равно![]()
![]() . Очевидно, это количество должно быть не меньше числа различных сочетаний ошибочных символов, подлежащих исправлению. Например, если код предназначен для исправления одиночных ошибок, то число различных вариантов таких ошибок равно
. Очевидно, это количество должно быть не меньше числа различных сочетаний ошибочных символов, подлежащих исправлению. Например, если код предназначен для исправления одиночных ошибок, то число различных вариантов таких ошибок равно ![]() . В этом случае должно выполняться условие
. В этом случае должно выполняться условие
![]() (7.11)
(7.11)
Формула (7.11) позволяет при заданном количестве информационных символов k определить необходимое число контрольных символов r, с помощью которых исправляются все одиночные ошибки.
7.4. Код с чётным числом единиц. Инверсионный код
Рассмотрим некоторые простейшие систематические коды, применяемые только для обнаружения ошибок. Одним из кодов подобного типа является код с четным числом единиц. Каждая комбинация этого кода содержит, помимо информационных символов, один контрольный символ, выбираемый равным 0 или 1 так, чтобы сумма единиц в комбинации всегда была четной. Примером могут служить пятизначные комбинации кода Бодо, к которым добавляется шестой контрольный символ: 10101,1 и 01100,0. Правило вычисления контрольного символа можно выразить на
основании (7.9) в следующей форме: ![]() . Отсюда вытекает, что для любой комбинации сумма всех символов по модулю два будет равна нулю (
. Отсюда вытекает, что для любой комбинации сумма всех символов по модулю два будет равна нулю (![]() — суммирование по модулю):
— суммирование по модулю):
![]() (7.12)
(7.12)
Это позволяет в декодирующем устройстве сравнительно просто производить обнаружение ошибок путем проверки на четность. Нарушение четности имеет место при появлении однократных, трехкратных и в общем, случае ошибок нечетной кратности, что и дает возможность их обнаружить. Появление четных ошибок не изменяет четности суммы (7.12), поэтому такие ошибки не обнаруживаются. На основании ,(7.8) вероятность необнаруженной ошибки равна:
![]()
![]()
К достоинствам кода следует отнести простоту кодирующих и декодирующих устройств, а также малую .избыточность ![]() , однако последнее определяет и его основной недостаток — сравнительно низкую корректирующую способность.
, однако последнее определяет и его основной недостаток — сравнительно низкую корректирующую способность.
Значительно лучшими корректирующими способностями обладает инверсный код, который также применяется только для обнаружения ошибок. С принципом построения такого кода удобно ознакомиться на примере двух комбинаций: 11000, 11000 и 01101, 10010. В каждой комбинации символы до запятой являются информационными, а последующие — контрольными. Если количество единиц в информационных символах четное, т. е. сумма этих
символов
![]() (7.13)
(7.13)
равна нулю, то контрольные символы представляют собой простое повторение информационных. В противном случае, когда число единиц нечетное и сумма (7.13) равна 1, контрольные символы получаются из информационных посредством инвертирования, т. е. путем замены всех 0 на 1, а 1 на 0. Математическая форма записи образования контрольных символов имеет вид ![]() . При декодировании происходит сравнение принятых информационных и контрольных символов. Если сумма единиц в принятых информационных символах четная, т. е.
. При декодировании происходит сравнение принятых информационных и контрольных символов. Если сумма единиц в принятых информационных символах четная, т. е. ![]() , то соответствующие друг другу информационные и контрольные символы суммируются по модулю два. В противном случае, когда c‘
, то соответствующие друг другу информационные и контрольные символы суммируются по модулю два. В противном случае, когда c‘![]() =1, происходит такое же суммирование, но с инвертированными контрольными символами. Другими словами, в соответствии с (7.10) производится r проверок на четность:
=1, происходит такое же суммирование, но с инвертированными контрольными символами. Другими словами, в соответствии с (7.10) производится r проверок на четность: ![]() . Ошибка обнаруживается, если хотя бы одна проверка на четность дает 1.
. Ошибка обнаруживается, если хотя бы одна проверка на четность дает 1.
Анализ показывает, что при ![]() наименьшая кратность необнаруживаемой ошибки g=4. Причем не обнаруживаются только те ошибки четвертой кратности, которые искажают одинаковые номера информационных и контрольных символов. Например, если передана комбинация 10100, 10100, а принята 10111, 10111, то такая четырехкратная ошибка обнаружена не будет, так как здесь все значения
наименьшая кратность необнаруживаемой ошибки g=4. Причем не обнаруживаются только те ошибки четвертой кратности, которые искажают одинаковые номера информационных и контрольных символов. Например, если передана комбинация 10100, 10100, а принята 10111, 10111, то такая четырехкратная ошибка обнаружена не будет, так как здесь все значения ![]() равны 0. Вероятность необнаружения ошибок четвертой кратности определяется выражением
равны 0. Вероятность необнаружения ошибок четвертой кратности определяется выражением
![]()
Для g>4 вероятность необнаруженных ошибок еще меньше. Поэтому при достаточно малых вероятностях ошибочных символов ро можно полагать, что полная вероятность необнаруженных ошибок ![]()
Инверсный код обладает высокой обнаруживающей способностью, однако она достигается ценой сравнительно большой избыточности, которая, как нетрудно определить, составляет величину ![]() =0,5.
=0,5.
7.5. Коды Хэмминга
К этому типу кодов обычно относят систематические коды с расстоянием d=3, которые позволяют исправить все одиночные ошибки (7.3).
Рассмотрим построение семизначного кода Хэмминга, каждая комбинация которого содержит четыре информационных и триконтрольных символа. Такой код, условно обозначаемый (7.4), удовлетворяет неравенству (7.11) и имеет избыточность ![]()
Если информационные символы с занимают в комбинация первые четыре места, то последующие три контрольных символа образуются по общему правилу (7.9) как суммы:
![]() (7.14)
(7.14)
Декодирование осуществляется путем трех проверок на четность (7.10):
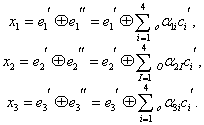 (7.15)
(7.15)
Так как х равно 0 или 1, то всего может быть восемь контрольных чисел Х=х1х2х3: 000, 100, 010, 001, 011, 101, 110 и 111. Первое из них имеет место в случае правильного приема, а остальные семь появляются при наличии искажений и должны использоваться для определения местоположения одиночной ошибки в семизначной комбинации. Выясним, каким образом устанавливается взаимосвязь между контрольными числами я искаженными символами. Если искажен один из контрольных символов: ![]() или
или ![]() , то, как следует из (7.15), контрольное число примет соответственно одно из трех значений: 100, 010 или 001. Остальные четыре контрольных числа используются для выявления ошибок в информационных символах.
, то, как следует из (7.15), контрольное число примет соответственно одно из трех значений: 100, 010 или 001. Остальные четыре контрольных числа используются для выявления ошибок в информационных символах.
Таблица 7.1

Порядок присвоения контрольных чисел ошибочным информационным символам может устанавливаться любой, например, как показано в табл. 7.1. Нетрудно показать, что этому распределению контрольных чисел соответствуют коэффициенты ![]() , приведенные в табл. 7.2.
, приведенные в табл. 7.2.
Таблица 7.2
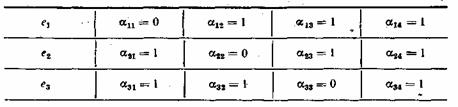
Если подставить коэффициенты ![]() в выражение (7.15), то получим:
в выражение (7.15), то получим:
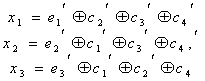 (7.16)
(7.16)
При искажении одного из информационных символов становятся равными единице те суммы х, в которые входит этот символ. Легко проверить, что получающееся в этом случае контрольное число![]() согласуется с табл. 7.1.Нетрудно заметить, что первые четыре контрольные числа табл. 7.1 совпадают со столбцами табл. 7.2. Это свойство дает возможность при выбранном распределении контрольных чисел составить таблицу коэффициентов
согласуется с табл. 7.1.Нетрудно заметить, что первые четыре контрольные числа табл. 7.1 совпадают со столбцами табл. 7.2. Это свойство дает возможность при выбранном распределении контрольных чисел составить таблицу коэффициентов ![]() . Таким образом, при одиночной ошибке можно вычислить контрольное число, позволяющее по табл. 7.1 определить тот символ кодовой комбинации, который претерпел искажения. Исправление искаженного символа двоичной системы состоит в простой замене 0 на 1 или 1 на 0. B качестве примера рассмотрим передачу комбинации, в которой информационными символами являются
. Таким образом, при одиночной ошибке можно вычислить контрольное число, позволяющее по табл. 7.1 определить тот символ кодовой комбинации, который претерпел искажения. Исправление искаженного символа двоичной системы состоит в простой замене 0 на 1 или 1 на 0. B качестве примера рассмотрим передачу комбинации, в которой информационными символами являются ![]() , Используя ф-лу (7.14) и табл. 7.2, вычислим контрольные символы:
, Используя ф-лу (7.14) и табл. 7.2, вычислим контрольные символы:
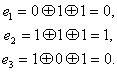
Передаваемая комбинация при этом будет ![]() . Предположим, что принята комбинация — 1001, 010 (искажен символ
. Предположим, что принята комбинация — 1001, 010 (искажен символ ![]() ). Подставляя соответствующие значения в (7.16), получим:
). Подставляя соответствующие значения в (7.16), получим:
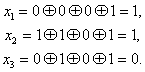
Вычисленное таким образом контрольное число ![]() 110 позволяет согласно табл. 7.1 исправить ошибку в символе.
110 позволяет согласно табл. 7.1 исправить ошибку в символе.
Здесь был рассмотрен простейший способ построения и декодирования кодовых комбинаций, в которых первые места отводились информационным символам, а соответствие между контрольными числами и ошибками определялось таблице. Вместе с тем существует более изящный метод отыскания одиночных ошибок, предложенный впервые самим Хэммингом. При этом методе код строится так, что контрольное число в двоичной системе счисления сразу указывает номер искаженного символа. Правда, в этом случае контрольные символы необходимо располагать среди информационных, что усложняет процесс кодирования. Для кода (7.4) символы в комбинации должны размещаться в следующем порядке: ![]() , а контрольное число вычисляться по формулам:
, а контрольное число вычисляться по формулам:
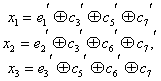 (7.17)
(7.17)
Так, если произошла ошибка в информационном символе с’5 то контрольное число ![]() , что соответствует числу 5 в двоичной системе.
, что соответствует числу 5 в двоичной системе.
В заключение отметим, что в коде (7.4) при появлении многократных ошибок контрольное число также может отличаться от нуля. Однако декодирование в этом случае будет проведено неправильно, так как оно рассчитано на исправление лишь одиночных ошибок.
7.6. Циклические коды
Важное место среди систематических кодов занимают циклические коды. Свойство цикличности состоит в том, что циклическая перестановка всех символов кодовой комбинации ![]() дает другую комбинацию
дает другую комбинацию ![]() также принадлежащую этому коду. При такой перестановке символы кодовой комбинации перемещаются слева направо на одну позицию, причем крайний правый символ переносится на место крайнего левого символа. Например,
также принадлежащую этому коду. При такой перестановке символы кодовой комбинации перемещаются слева направо на одну позицию, причем крайний правый символ переносится на место крайнего левого символа. Например, ![]()
![]()
![]()
![]() .
.
Комбинации циклического кода, выражаемые двоичными числами, для удобства преобразований обычно определяют в виде полиномов, коэффициенты которых равны 0 или 1. Примером этому может служить следующая запись:
![]()
Помимо цикличности, кодовые комбинации обладают другим важным свойством. Если их представить в виде полиномов, то все они делятся без остатка на так называемый порождающий полином G(z) степени ![]() , где k—значность первичного кода без избыточности, а п-значность циклического кода
, где k—значность первичного кода без избыточности, а п-значность циклического кода
Построение комбинаций циклических кодов возможно путем умножения комбинации первичного кода A*(z) ,на порождающий полином G(z):
A(z)=A*(z)G(z).
Умножение производится по модулю zn и в данном случае сводится к умножению по обычным правилам с приведением подобных членов по модулю два.
В полученной таким способом комбинации A(z) в явном виде не содержатся информационные символы, однако они всегда могут быть выделены в результате обратной операции: деления A(z) на G(z).
Другой способ кодирования, позволяющий представить кодовую комбинацию в виде информационных и контрольных символов, заключается в следующем. К комбинации первичного кода дописывается справа г нулей, что эквивалентно повышению полинома A*(z) на ,г разрядов, т. е. умножению его на гг. Затем произведение zrA*(z) делится на порождающий полином. B общем случае результат деления состоит из целого числа Q(z) и остатка R(z). Отсюда
![]()
Вычисленный остаток К(г) я используется для образования комбинации циклического кода в виде суммы
A(z)=zrA*(z)@R(z).
Так как сложение и вычитание по модулю два дают один и тот же результат, то нетрудно заметить, что A(z) = Q(z)G(z), т. е. полученная комбинация удовлетворяет требованию делимости на порождающий полином. Степень полинома R{z) не превышает r—1, поэтому он замещает нули в комбинации z![]() A*(z).
A*(z).
Для примера рассмотрим циклический код c n = 7, k=4, r=3 и G(z)=z3-z+1=1011. Необходимо закодировать комбинацию A*(z)=z*+1 = 1001. Тогда z![]() A*(z)=z
A*(z)=z![]() +z
+z![]() = 1001000. Для определения остатка делим z3A*(z) на G(z):
= 1001000. Для определения остатка делим z3A*(z) на G(z):
Окончательно получаем
В А(z) высшие четыре разряда занимают информационные символы, а остальные при — контрольные.
Контрольные символы в циклическом коде могут быть вычислены по общим ф-лам (7.9), однако здесь определение коэффициентов ![]() затрудняется необходимостью выполнять требования делимости А(z) на порождающий полином G(z).
затрудняется необходимостью выполнять требования делимости А(z) на порождающий полином G(z).
Процедура декодирования принятых комбинаций также основана на использовании полиномов G(z). Если ошибок в процессе передачи не было, то деление принятой комбинации A(z) на G(z) дает целое число. При наличии корректируемых ошибок в результате деления образуется остаток, который и позволяет обнаружить или исправить ошибки.
Кодирующие и декодирующие устройства циклических кодов в большинстве случаев обладают сравнительной простотой, что следует считать одним из основных их преимуществ. Другим важным достоинством этих кодов является их способность корректировать пачки ошибок, возникающие в реальных каналах, где действуют импульсные и сосредоточенные помехи или наблюдаются замирания сигнала.
В теории кодирования весом кодовых комбинаций принято называть .количество единиц, которое они содержат. Если все комбинации кода имеют одинаковый вес, то такой код называется кодом с постоянным весом. Коды с постоянным весом относятся к классу блочных неразделимых кодов, так как здесь не представляется возможным выделить информационные и контрольные символы. Из кодов этого типа наибольшее распространение получил обнаруживающий семизначный код 3/4, каждая разрешенная комбинация которого имеет три единицы и четыре нуля. Известен также код 2/5. Примером комбинаций кода 3/4 могут служить следующие семизначные последовательности: 1011000, 0101010, 0001110 и т. д.
Декодирование принятых комбинаций сводится к определению их веса. Если он отличается от заданного, то комбинация принята с ошибкой. Этот код обнаруживает все ошибки нечетной краткости и часть ошибок четной кратности. Не обнаруживаются только так называемые ошибки смещения, сохраняющие неизменным вес комбинации. Ошибки смещения характеризуются тем, что число искаженных единиц всегда равно числу искаженных нулей. Можно показать, что вероятность необнаруженной ошибки для кода 3/4 равна:
![]() при
при ![]() (7.18)
(7.18)
В этом коде из общего числа комбинаций М = 27=128 разрешенными являются лишь ![]() , поэтому в соответствии с (7.6) коэффициент избыточности
, поэтому в соответствии с (7.6) коэффициент избыточности
![]()
Код 3/4 находит применение при частотной манипуляции в каналах с селективными замираниями, где вероятность ошибок смещения невелика.
7.8. Непрерывные коды
Из непрерывных кодов, исправляющих ошибки, наиболее известны коды Финка—Хагельбаргера, в которых контрольные символы образуются путем линейной операции над двумя или более информационными символами. Принцип построения этих кодов рассмотрим на примере простейшего цепного кода. Контрольные символы в цепном коде формируются путем суммирования двух информационных символов, расположенных один относительно другого на определенном расстоянии:
![]() ;
;![]() (7.19)
(7.19)
Расстояние между информационными символами l=k—i определяет основные свойства кода и называется шагом сложения. Число контрольных символов при таком способе кодирования равно числу информационных символов, поэтому избыточность кода ![]() =0,5. Процесс образования последовательности контрольных символов показан на рис.7. символы разметаются между информационными символами с задержкой на два шага сложения.
=0,5. Процесс образования последовательности контрольных символов показан на рис.7. символы разметаются между информационными символами с задержкой на два шага сложения.
Рис. 7.3. Образование и размещение контрольных символов в цепном коде Финка—Хагельбаргера
При декодировании из принятых информационных символов по тому же правилу (7.19) формируется вспомогательная последовательность контрольных символов е», которая сравнивается с принятой последовательностью контрольных символов е’ (рис. 7.36). Если произошла ошибка в информационном символе, например, c‘k, то это вызовет искажения сразу двух символов e«k и e«km, что и обнаружится в результате их сравнения с ![]() и e‘km. Отсюда по общему индексу k легко определить и исправить ошибочно принятый информационный символ с’
и e‘km. Отсюда по общему индексу k легко определить и исправить ошибочно принятый информационный символ с’![]() Ошибка в принятом контрольном символе, например, e‘k приводит к несовпадению контрольных последовательностей лишь в одном месте. Исправление такой ошибки не требуется.
Ошибка в принятом контрольном символе, например, e‘k приводит к несовпадению контрольных последовательностей лишь в одном месте. Исправление такой ошибки не требуется.
Важное преимущество непрерывных кодов состоит в их способности исправлять не только одиночные ошибки, но я группы (пакеты) ошибок. Если задержка контрольных символов выбрана равной 2l, то можно показать, что максимальная длина исправляемого пакета ошибок также равна 2l при интервале между пакетами не менее 6l+1. Таким образом, возможность исправления длинных пакетов связана с увеличением шага сложения, а следовательно, и с усложнением кодирующих и декодирующих устройств.
Вопросы для повторения
1. Как могут быть классифицированы корректирующие коды?
2. Каким образом исправляются ошибки в кодах, которые только их обнаруживают?
3. В чем состоят основные принципы корректирования ошибок?
4. Дайте определение кодового расстояния.
5. При каких условиях код может обнаруживать или исправлять ошибки?
6. Как используется корректирующий код в системах со стиранием?
7. Какие характеристики определяют корректирующие способности кода?
8. Как осуществляется построение кодовых комбинаций в систематических кодах?
9. На чем основан принцип корректирования ошибок с использованием контрольного числа?
10. Объясните метод построения кода с четным числом единиц.
11. Как осуществляется процедура кодирования в семизначном коде Хэмминга?
12. Почему семизначный код 3/4 не обнаруживает ошибки смещения?
13. Каким образом производится непрерывное кодирование?
14. От чего зависит длина пакета исправляемых ошибок в коде Финка—Хагельбаргера?
Совершенные и квазисовершенные коды
Групповой  -код, исправляющий все ошибки веса, не большего
-код, исправляющий все ошибки веса, не большего  , и
, и
никаких других, называется совершенным.
Свойства совершенного кода21 :
- Для совершенного
 -кода, исправляющего все ошибки веса,
-кода, исправляющего все ошибки веса,
не большего, выполняется соотношение . Верно и обратное утверждение; - Совершенный код, исправляющий все ошибки веса, не большего , в столбцах таблицы декодирования содержит все слова, отстоящие
от кодовых на расстоянии, не большем. Верно и обратное
утверждение; -
Таблица декодирования совершенного кода, исправляющего все ошибки
в не более чем позициях, имеет в качестве лидеров все строки,
содержащие не более единиц. Верно и обратное утверждение.
 . Верно и обратное утверждение;
. Верно и обратное утверждение;Совершенный код — это лучший код, обеспечивающий максимум минимального
расстояния между кодовыми словами при минимуме длины кодовых слов.
Совершенный код легко декодировать: каждому полученному
слову однозначно ставится в соответствие ближайшее кодовое. Чисел  ,
, 
и  , удовлетворяющих условию
, удовлетворяющих условию
совершенности кода очень мало. Но и при подобранных , и
совершенный код можно построить только в исключительных случаях.
Если , и не удовлетворяют
условию совершенности, то лучший групповой код, который им соответствует называется квазисовершенным, если
он исправляет все ошибки кратности, не большей , и некоторые
ошибки кратности  . Квазисовершенных кодов также очень мало.
. Квазисовершенных кодов также очень мало.
Двоичный блочный -код называется оптимальным,
если он минимизирует вероятность ошибочного декодирования.
Совершенный или квазисовершенный код — оптимален. Общий способ
построения оптимальных кодов пока неизвестен.
Для любого целого положительного числа 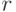 существует
существует
совершенный -код, исправляющий одну ошибку, называемый кодом Хэмминга
(Hamming), в котором  и
и 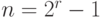 .
.
Действительно,  .
.
Порядок построения кода Хэмминга следующий:
- Выбираем целое положительное число . Сообщения будут
словами длины, а кодовые слова — длины ; - В каждом кодовом слове
бит с индексами-степенями двойки —
являются контрольными, остальные — в естественном порядке — битами сообщения.
Например, если, то биты —
контрольные, а — из исходного сообщения; - Строится матрица из строк и столбцов. В -ой строке стоят цифры двоичного представления числа . Матрицы для r=2, 3 и 4 таковы:
- Записывается система уравнений , где —
матрица из предыдущего пункта. Система состоит из уравнений. Например,
для:
- Чтобы закодировать сообщение , берутся в качестве , не равно степени двойки, соответствующие биты сообщения и
отыскиваются, используя полученную систему уравнений, те, для которых — степень двойки. В каждое уравнение входит только одно , . В выписанной системе входит в 1-е уравнение, — во
второе и — в
третье. В рассмотренном примере сообщение будет
закодировано кодовым словом.

 —
— , то биты
, то биты  —
— — из исходного сообщения;
— из исходного сообщения; строк и
строк и 
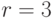 :
:

 , берутся в качестве
, берутся в качестве  ,
,  не равно степени двойки, соответствующие биты сообщения и
не равно степени двойки, соответствующие биты сообщения и . В выписанной системе
. В выписанной системе 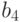 входит в 1-е уравнение,
входит в 1-е уравнение, 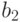 — во
— во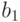 — в
— в будет
будетДекодирование кода Хэмминга проходит по следующей схеме. Пусть принято
слово  , где
, где  — переданное кодовое слово, а
— переданное кодовое слово, а  — строка ошибок. Так как
— строка ошибок. Так как  , то
, то  . Если результат нулевой,
. Если результат нулевой,
как происходит при правильной передаче, считается, что ошибок не было. Если строка ошибок имеет
единицу в  -й позиции, то результатом произведения
-й позиции, то результатом произведения  будет -я строка
будет -я строка
матрицы  или двоичное представление числа . В этом
или двоичное представление числа . В этом
случае следует изменить символ в -й позиции слова , считая
позиции слева, с единицы.
Пример.  —код Хэмминга имеет в качестве одного из кодовых
—код Хэмминга имеет в качестве одного из кодовых
слов  . Матрица
. Матрица  приведена на шаге 3
приведена на шаге 3
хода построения кода Хэмминга. Ясно,
что . Добавим к строку ошибок  . Тогда
. Тогда  и
и  , т.е. ошибка находится в третьей позиции. Если
, т.е. ошибка находится в третьей позиции. Если  , то
, то  и позиция ошибки —
и позиция ошибки —  и т.п.
и т.п.
Если ошибка допущена в более чем в одной позиции, то декодирование даст
неверный результат.
Код Хэмминга — это групповой код.
Это следует из того, что —код Хэмминга можно
получить матричным кодированием, при помощи  -матрицы, в которой столбцы с
-матрицы, в которой столбцы с
номерами не степенями 2 образуют единичную подматрицу. Остальные столбцы соответствуют
уравнениям шага 4 построения кода Хэмминга, т.е. 1-му столбцу
соответствует уравнение для вычисления 1-го контрольного разряда, 2-му —
для 2-го, 4-му — для 4-го и т.д. Такая матрица будет при кодировании
копировать биты сообщения в позиции не степени 2 кода и заполнять другие
позиции кода согласно схеме кодирования Хэмминга.
Пример. Кодирующая матрица для —кода Хэмминга —

Ее столбцы с номерами 3, 5, 6 и 7 образуют единичную подматрицу. Столбцы с
номерами 1, 2 и 4 соответствуют уравнениям для вычисления контрольных бит,
например, уравнению  соответствует столбец 1101,
соответствует столбец 1101,
т.е. для вычисления первого контрольного разряда берутся 1, 2 и 4 биты исходного
сообщения или биты 3, 5 и 7 кода.
К -коду Хэмминга можно добавить проверку четности.
Получится  -код с наименьшим весом ненулевого кодового слова 4,
-код с наименьшим весом ненулевого кодового слова 4,
способный исправлять одну и обнаруживать две ошибки.
Коды Хэмминга накладывают ограничения на длину слов сообщения: эта длина
может быть только числами вида  : 1, 4, 11, 26, 57,
: 1, 4, 11, 26, 57,  Но в реальных системах информация передается байтам или машинными словами, т.е.
Но в реальных системах информация передается байтам или машинными словами, т.е.
порциями по 8, 16, 32 или 64 бита, что делает использование совершенных
кодов не всегда подходящим. Поэтому в таких случаях часто используются
квазисовершенные коды.
Квазисовершенные -коды, исправляющие одну ошибку,
строятся следующим образом. Выбирается минимальное так, чтобы

Каждое кодовое слово такого кода будет содержать 
контрольных разрядов. Из предыдущих соотношений следует, что

Каждому из разрядов присваивается слева-направо номер от 1 до . Для заданного слова сообщения составляются контрольных сумм  по модулю 2 значений специально выбранных разрядов кодового слова,
по модулю 2 значений специально выбранных разрядов кодового слова,
которые помещаются в позиции-степени 2 в нем: для 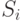
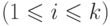
выбираются разряды, содержащие биты исходного сообщения, двоичные
числа-номера которых имеют в -м разряде единицу. Для суммы 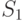 это будут, например, разряды 3, 5, 7 и т.д., для суммы
это будут, например, разряды 3, 5, 7 и т.д., для суммы  — 3, 6,
— 3, 6,
7 и т.д. Таким образом, для слова сообщения 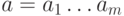 будет
будет
построено кодовое слово  . Обозначим
. Обозначим  сумму по модулю 2 разрядов полученного слова, соответствующих контрольной сумме
сумму по модулю 2 разрядов полученного слова, соответствующих контрольной сумме
и самой этой контрольной суммы. Если  , то
, то
считается, что передача прошла без ошибок. В случае одинарной ошибки  будет равно двоичному числу-номеру сбойного бита. В случае ошибки, кратности
будет равно двоичному числу-номеру сбойного бита. В случае ошибки, кратности
большей 1, когда  , ее можно обнаружить.
, ее можно обнаружить.
Подобная схема декодирования не позволяет исправлять некоторые двойные ошибки, чего можно
было бы достичь, используя схему декодирования с лидерами, но последняя
значительно сложнее в реализации и дает незначительное улучшение качества
кода.
Пример построения кодового слова квазисовершенного  -кода,
-кода,
исправляющего все однократные ошибки, для сообщения 100011010.

Искомое кодовое слово имеет вид  . Далее нужно
. Далее нужно
вычислить контрольные суммы.

Таким образом, искомый код — 0011000111010. Если в процессе передачи этого
кода будет испорчен его пятый бит, то приемник получит код 0011100111010.
Для его декодирования опять вычисляются контрольные суммы:

Приемник преобразует изменением пятого бита полученное
сообщение в отправленное передатчиком, из которого затем отбрасыванием
контрольных разрядов восстанавливает исходное сообщение.
Совершенный код Хэмминга также можно строить по рассмотренной схеме,
т.к. для него  .
.
Для исправление одинарной ошибки к 8-разрядному коду
достаточно приписать 4 разряда (  ), к 16-разрядному
), к 16-разрядному
— 5, к 32-разрядному — 6, к 64-разрядному — 7.
Упражнение 41
Может ли  -код, минимальное расстояние между кодовыми словами
-код, минимальное расстояние между кодовыми словами
которого 5, быть совершенным?
Упражнение 42
Построить кодовые слова квазисовершенного -кода,
исправляющего однократные ошибки, для тех сообщений, которые соответствуют числам
55, 200 и декодировать слова 1000001000001, 1100010111100,
полученные по каналу связи, использующему этот код.
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
In computing, telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding[1][2][3] is a technique used for controlling errors in data transmission over unreliable or noisy communication channels.
The central idea is that the sender encodes the message in a redundant way, most often by using an error correction code or error correcting code (ECC).[4][5] The redundancy allows the receiver not only to detect errors that may occur anywhere in the message, but often to correct a limited number of errors. Therefore a reverse channel to request re-transmission may not be needed. The cost is a fixed, higher forward channel bandwidth.
The American mathematician Richard Hamming pioneered this field in the 1940s and invented the first error-correcting code in 1950: the Hamming (7,4) code.[5]
FEC can be applied in situations where re-transmissions are costly or impossible, such as one-way communication links or when transmitting to multiple receivers in multicast.
Long-latency connections also benefit; in the case of a satellite orbiting Uranus, retransmission due to errors can create a delay of five hours. FEC is widely used in modems and in cellular networks, as well.
FEC processing in a receiver may be applied to a digital bit stream or in the demodulation of a digitally modulated carrier. For the latter, FEC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many FEC decoders can also generate a bit-error rate (BER) signal which can be used as feedback to fine-tune the analog receiving electronics.
FEC information is added to mass storage (magnetic, optical and solid state/flash based) devices to enable recovery of corrupted data, and is used as ECC computer memory on systems that require special provisions for reliability.
The maximum proportion of errors or missing bits that can be corrected is determined by the design of the ECC, so different forward error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon can be used to compute the maximum achievable communication bandwidth for a given maximum acceptable error probability. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. However, the proof is not constructive, and hence gives no insight of how to build a capacity achieving code. After years of research, some advanced FEC systems like polar code[3] come very close to the theoretical maximum given by the Shannon channel capacity under the hypothesis of an infinite length frame.
Method[edit]
ECC is accomplished by adding redundancy to the transmitted information using an algorithm. A redundant bit may be a complicated function of many original information bits. The original information may or may not appear literally in the encoded output; codes that include the unmodified input in the output are systematic, while those that do not are non-systematic.
A simplistic example of ECC is to transmit each data bit 3 times, which is known as a (3,1) repetition code. Through a noisy channel, a receiver might see 8 versions of the output, see table below.
| Triplet received | Interpreted as |
|---|---|
| 000 | 0 (error-free) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (error-free) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
This allows an error in any one of the three samples to be corrected by «majority vote», or «democratic voting». The correcting ability of this ECC is:
- Up to 1 bit of triplet in error, or
- up to 2 bits of triplet omitted (cases not shown in table).
Though simple to implement and widely used, this triple modular redundancy is a relatively inefficient ECC. Better ECC codes typically examine the last several tens or even the last several hundreds of previously received bits to determine how to decode the current small handful of bits (typically in groups of 2 to 8 bits).
Averaging noise to reduce errors[edit]
ECC could be said to work by «averaging noise»; since each data bit affects many transmitted symbols, the corruption of some symbols by noise usually allows the original user data to be extracted from the other, uncorrupted received symbols that also depend on the same user data.
- Because of this «risk-pooling» effect, digital communication systems that use ECC tend to work well above a certain minimum signal-to-noise ratio and not at all below it.
- This all-or-nothing tendency – the cliff effect – becomes more pronounced as stronger codes are used that more closely approach the theoretical Shannon limit.
- Interleaving ECC coded data can reduce the all or nothing properties of transmitted ECC codes when the channel errors tend to occur in bursts. However, this method has limits; it is best used on narrowband data.
Most telecommunication systems use a fixed channel code designed to tolerate the expected worst-case bit error rate, and then fail to work at all if the bit error rate is ever worse.
However, some systems adapt to the given channel error conditions: some instances of hybrid automatic repeat-request use a fixed ECC method as long as the ECC can handle the error rate, then switch to ARQ when the error rate gets too high;
adaptive modulation and coding uses a variety of ECC rates, adding more error-correction bits per packet when there are higher error rates in the channel, or taking them out when they are not needed.
Types of ECC[edit]

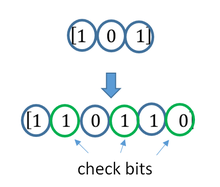
The two main categories of ECC codes are block codes and convolutional codes.
- Block codes work on fixed-size blocks (packets) of bits or symbols of predetermined size. Practical block codes can generally be hard-decoded in polynomial time to their block length.
- Convolutional codes work on bit or symbol streams of arbitrary length. They are most often soft decoded with the Viterbi algorithm, though other algorithms are sometimes used. Viterbi decoding allows asymptotically optimal decoding efficiency with increasing constraint length of the convolutional code, but at the expense of exponentially increasing complexity. A convolutional code that is terminated is also a ‘block code’ in that it encodes a block of input data, but the block size of a convolutional code is generally arbitrary, while block codes have a fixed size dictated by their algebraic characteristics. Types of termination for convolutional codes include «tail-biting» and «bit-flushing».
There are many types of block codes; Reed–Solomon coding is noteworthy for its widespread use in compact discs, DVDs, and hard disk drives. Other examples of classical block codes include Golay, BCH, Multidimensional parity, and Hamming codes.
Hamming ECC is commonly used to correct NAND flash memory errors.[6]
This provides single-bit error correction and 2-bit error detection.
Hamming codes are only suitable for more reliable single-level cell (SLC) NAND.
Denser multi-level cell (MLC) NAND may use multi-bit correcting ECC such as BCH or Reed–Solomon.[7][8] NOR Flash typically does not use any error correction.[7]
Classical block codes are usually decoded using hard-decision algorithms,[9] which means that for every input and output signal a hard decision is made whether it corresponds to a one or a zero bit. In contrast, convolutional codes are typically decoded using soft-decision algorithms like the Viterbi, MAP or BCJR algorithms, which process (discretized) analog signals, and which allow for much higher error-correction performance than hard-decision decoding.
Nearly all classical block codes apply the algebraic properties of finite fields. Hence classical block codes are often referred to as algebraic codes.
In contrast to classical block codes that often specify an error-detecting or error-correcting ability, many modern block codes such as LDPC codes lack such guarantees. Instead, modern codes are evaluated in terms of their bit error rates.
Most forward error correction codes correct only bit-flips, but not bit-insertions or bit-deletions.
In this setting, the Hamming distance is the appropriate way to measure the bit error rate.
A few forward error correction codes are designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.
The Levenshtein distance is a more appropriate way to measure the bit error rate when using such codes.
[10]
Code-rate and the tradeoff between reliability and data rate[edit]
The fundamental principle of ECC is to add redundant bits in order to help the decoder to find out the true message that was encoded by the transmitter. The code-rate of a given ECC system is defined as the ratio between the number of information bits and the total number of bits (i.e., information plus redundancy bits) in a given communication package. The code-rate is hence a real number. A low code-rate close to zero implies a strong code that uses many redundant bits to achieve a good performance, while a large code-rate close to 1 implies a weak code.
The redundant bits that protect the information have to be transferred using the same communication resources that they are trying to protect. This causes a fundamental tradeoff between reliability and data rate.[11] In one extreme, a strong code (with low code-rate) can induce an important increase in the receiver SNR (signal-to-noise-ratio) decreasing the bit error rate, at the cost of reducing the effective data rate. On the other extreme, not using any ECC (i.e., a code-rate equal to 1) uses the full channel for information transfer purposes, at the cost of leaving the bits without any additional protection.
One interesting question is the following: how efficient in terms of information transfer can an ECC be that has a negligible decoding error rate? This question was answered by Claude Shannon with his second theorem, which says that the channel capacity is the maximum bit rate achievable by any ECC whose error rate tends to zero:[12] His proof relies on Gaussian random coding, which is not suitable to real-world applications. The upper bound given by Shannon’s work inspired a long journey in designing ECCs that can come close to the ultimate performance boundary. Various codes today can attain almost the Shannon limit. However, capacity achieving ECCs are usually extremely complex to implement.
The most popular ECCs have a trade-off between performance and computational complexity. Usually, their parameters give a range of possible code rates, which can be optimized depending on the scenario. Usually, this optimization is done in order to achieve a low decoding error probability while minimizing the impact to the data rate. Another criterion for optimizing the code rate is to balance low error rate and retransmissions number in order to the energy cost of the communication.[13]
Concatenated ECC codes for improved performance[edit]
Classical (algebraic) block codes and convolutional codes are frequently combined in concatenated coding schemes in which a short constraint-length Viterbi-decoded convolutional code does most of the work and a block code (usually Reed–Solomon) with larger symbol size and block length «mops up» any errors made by the convolutional decoder. Single pass decoding with this family of error correction codes can yield very low error rates, but for long range transmission conditions (like deep space) iterative decoding is recommended.
Concatenated codes have been standard practice in satellite and deep space communications since Voyager 2 first used the technique in its 1986 encounter with Uranus. The Galileo craft used iterative concatenated codes to compensate for the very high error rate conditions caused by having a failed antenna.
Low-density parity-check (LDPC)[edit]
Low-density parity-check (LDPC) codes are a class of highly efficient linear block
codes made from many single parity check (SPC) codes. They can provide performance very close to the channel capacity (the theoretical maximum) using an iterated soft-decision decoding approach, at linear time complexity in terms of their block length. Practical implementations rely heavily on decoding the constituent SPC codes in parallel.
LDPC codes were first introduced by Robert G. Gallager in his PhD thesis in 1960,
but due to the computational effort in implementing encoder and decoder and the introduction of Reed–Solomon codes,
they were mostly ignored until the 1990s.
LDPC codes are now used in many recent high-speed communication standards, such as DVB-S2 (Digital Video Broadcasting – Satellite – Second Generation), WiMAX (IEEE 802.16e standard for microwave communications), High-Speed Wireless LAN (IEEE 802.11n),[14] 10GBase-T Ethernet (802.3an) and G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable). Other LDPC codes are standardized for wireless communication standards within 3GPP MBMS (see fountain codes).
Turbo codes[edit]
Turbo coding is an iterated soft-decoding scheme that combines two or more relatively simple convolutional codes and an interleaver to produce a block code that can perform to within a fraction of a decibel of the Shannon limit. Predating LDPC codes in terms of practical application, they now provide similar performance.
One of the earliest commercial applications of turbo coding was the CDMA2000 1x (TIA IS-2000) digital cellular technology developed by Qualcomm and sold by Verizon Wireless, Sprint, and other carriers. It is also used for the evolution of CDMA2000 1x specifically for Internet access, 1xEV-DO (TIA IS-856). Like 1x, EV-DO was developed by Qualcomm, and is sold by Verizon Wireless, Sprint, and other carriers (Verizon’s marketing name for 1xEV-DO is Broadband Access, Sprint’s consumer and business marketing names for 1xEV-DO are Power Vision and Mobile Broadband, respectively).
Local decoding and testing of codes[edit]
Sometimes it is only necessary to decode single bits of the message, or to check whether a given signal is a codeword, and do so without looking at the entire signal. This can make sense in a streaming setting, where codewords are too large to be classically decoded fast enough and where only a few bits of the message are of interest for now. Also such codes have become an important tool in computational complexity theory, e.g., for the design of probabilistically checkable proofs.
Locally decodable codes are error-correcting codes for which single bits of the message can be probabilistically recovered by only looking at a small (say constant) number of positions of a codeword, even after the codeword has been corrupted at some constant fraction of positions. Locally testable codes are error-correcting codes for which it can be checked probabilistically whether a signal is close to a codeword by only looking at a small number of positions of the signal.
Interleaving[edit]
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.

Interleaving is frequently used in digital communication and storage systems to improve the performance of forward error correcting codes. Many communication channels are not memoryless: errors typically occur in bursts rather than independently. If the number of errors within a code word exceeds the error-correcting code’s capability, it fails to recover the original code word. Interleaving alleviates this problem by shuffling source symbols across several code words, thereby creating a more uniform distribution of errors.[15] Therefore, interleaving is widely used for burst error-correction.
The analysis of modern iterated codes, like turbo codes and LDPC codes, typically assumes an independent distribution of errors.[16] Systems using LDPC codes therefore typically employ additional interleaving across the symbols within a code word.[17]
For turbo codes, an interleaver is an integral component and its proper design is crucial for good performance.[15][18] The iterative decoding algorithm works best when there are not short cycles in the factor graph that represents the decoder; the interleaver is chosen to avoid short cycles.
Interleaver designs include:
- rectangular (or uniform) interleavers (similar to the method using skip factors described above)
- convolutional interleavers
- random interleavers (where the interleaver is a known random permutation)
- S-random interleaver (where the interleaver is a known random permutation with the constraint that no input symbols within distance S appear within a distance of S in the output).[19]
- a contention-free quadratic permutation polynomial (QPP).[20] An example of use is in the 3GPP Long Term Evolution mobile telecommunication standard.[21]
In multi-carrier communication systems, interleaving across carriers may be employed to provide frequency diversity, e.g., to mitigate frequency-selective fading or narrowband interference.[22]
Example[edit]
Transmission without interleaving:
Error-free message: aaaabbbbccccddddeeeeffffgggg Transmission with a burst error: aaaabbbbccc____deeeeffffgggg
Here, each group of the same letter represents a 4-bit one-bit error-correcting codeword. The codeword cccc is altered in one bit and can be corrected, but the codeword dddd is altered in three bits, so either it cannot be decoded at all or it might be decoded incorrectly.
With interleaving:
Error-free code words: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Transmission with a burst error: abcdefgabcd____bcdefgabcdefg Received code words after deinterleaving: aa_abbbbccccdddde_eef_ffg_gg
In each of the codewords «aaaa», «eeee», «ffff», and «gggg», only one bit is altered, so one-bit error-correcting code will decode everything correctly.
Transmission without interleaving:
Original transmitted sentence: ThisIsAnExampleOfInterleaving Received sentence with a burst error: ThisIs______pleOfInterleaving
The term «AnExample» ends up mostly unintelligible and difficult to correct.
With interleaving:
Transmitted sentence: ThisIsAnExampleOfInterleaving... Error-free transmission: TIEpfeaghsxlIrv.iAaenli.snmOten. Received sentence with a burst error: TIEpfe______Irv.iAaenli.snmOten. Received sentence after deinterleaving: T_isI_AnE_amp_eOfInterle_vin_...
No word is completely lost and the missing letters can be recovered with minimal guesswork.
Disadvantages of interleaving[edit]
Use of interleaving techniques increases total delay. This is because the entire interleaved block must be received before the packets can be decoded.[23] Also interleavers hide the structure of errors; without an interleaver, more advanced decoding algorithms can take advantage of the error structure and achieve more reliable communication than a simpler decoder combined with an interleaver[citation needed]. An example of such an algorithm is based on neural network[24] structures.
Software for error-correcting codes[edit]
Simulating the behaviour of error-correcting codes (ECCs) in software is a common practice to design, validate and improve ECCs. The upcoming wireless 5G standard raises a new range of applications for the software ECCs: the Cloud Radio Access Networks (C-RAN) in a Software-defined radio (SDR) context. The idea is to directly use software ECCs in the communications. For instance in the 5G, the software ECCs could be located in the cloud and the antennas connected to this computing resources: improving this way the flexibility of the communication network and eventually increasing the energy efficiency of the system.
In this context, there are various available Open-source software listed below (non exhaustive).
- AFF3CT(A Fast Forward Error Correction Toolbox): a full communication chain in C++ (many supported codes like Turbo, LDPC, Polar codes, etc.), very fast and specialized on channel coding (can be used as a program for simulations or as a library for the SDR).
- IT++: a C++ library of classes and functions for linear algebra, numerical optimization, signal processing, communications, and statistics.
- OpenAir: implementation (in C) of the 3GPP specifications concerning the Evolved Packet Core Networks.
List of error-correcting codes[edit]
| Distance | Code |
|---|---|
| 2 (single-error detecting) | Parity |
| 3 (single-error correcting) | Triple modular redundancy |
| 3 (single-error correcting) | perfect Hamming such as Hamming(7,4) |
| 4 (SECDED) | Extended Hamming |
| 5 (double-error correcting) | |
| 6 (double-error correct-/triple error detect) | Nordstrom-Robinson code |
| 7 (three-error correcting) | perfect binary Golay code |
| 8 (TECFED) | extended binary Golay code |
- AN codes
- Algebraic geometry code
- BCH code, which can be designed to correct any arbitrary number of errors per code block.
- Barker code used for radar, telemetry, ultra sound, Wifi, DSSS mobile phone networks, GPS etc.
- Berger code
- Constant-weight code
- Convolutional code
- Expander codes
- Group codes
- Golay codes, of which the Binary Golay code is of practical interest
- Goppa code, used in the McEliece cryptosystem
- Hadamard code
- Hagelbarger code
- Hamming code
- Latin square based code for non-white noise (prevalent for example in broadband over powerlines)
- Lexicographic code
- Linear Network Coding, a type of erasure correcting code across networks instead of point-to-point links
- Long code
- Low-density parity-check code, also known as Gallager code, as the archetype for sparse graph codes
- LT code, which is a near-optimal rateless erasure correcting code (Fountain code)
- m of n codes
- Nordstrom-Robinson code, used in Geometry and Group Theory[25]
- Online code, a near-optimal rateless erasure correcting code
- Polar code (coding theory)
- Raptor code, a near-optimal rateless erasure correcting code
- Reed–Solomon error correction
- Reed–Muller code
- Repeat-accumulate code
- Repetition codes, such as Triple modular redundancy
- Spinal code, a rateless, nonlinear code based on pseudo-random hash functions[26]
- Tornado code, a near-optimal erasure correcting code, and the precursor to Fountain codes
- Turbo code
- Walsh–Hadamard code
- Cyclic redundancy checks (CRCs) can correct 1-bit errors for messages at most bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters


See also[edit]
- Code rate
- Erasure codes
- Soft-decision decoder
- Burst error-correcting code
- Error detection and correction
- Error-correcting codes with feedback
- Linear code
- Quantum error correction
References[edit]
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
How Forward Error-Correcting Codes Work]
- ^ a b Maunder, Robert (2016). «Overview of Channel Coding».
- ^ Glover, Neal; Dudley, Trent (1990). Practical Error Correction Design For Engineers (Revision 1.1, 2nd ed.). CO, USA: Cirrus Logic. ISBN 0-927239-00-0.
- ^ a b Hamming, Richard Wesley (April 1950). «Error Detecting and Error Correcting Codes». Bell System Technical Journal. USA: AT&T. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. S2CID 61141773.
- ^ «Hamming codes for NAND flash memory devices» Archived 21 August 2016 at the Wayback Machine. EE Times-Asia. Apparently based on «Micron Technical Note TN-29-08: Hamming Codes for NAND Flash Memory Devices». 2005. Both say: «The Hamming algorithm is an industry-accepted method for error detection and correction in many SLC NAND flash-based applications.»
- ^ a b «What Types of ECC Should Be Used on Flash Memory?» (Application note). Spansion. 2011.
Both Reed–Solomon algorithm and BCH algorithm are common ECC choices for MLC NAND flash. … Hamming based block codes are the most commonly used ECC for SLC…. both Reed–Solomon and BCH are able to handle multiple errors and are widely used on MLC flash.
- ^ Jim Cooke (August 2007). «The Inconvenient Truths of NAND Flash Memory» (PDF). p. 28.
For SLC, a code with a correction threshold of 1 is sufficient. t=4 required … for MLC.
- ^ Baldi, M.; Chiaraluce, F. (2008). «A Simple Scheme for Belief Propagation Decoding of BCH and RS Codes in Multimedia Transmissions». International Journal of Digital Multimedia Broadcasting. 2008: 1–12. doi:10.1155/2008/957846.
- ^ Shah, Gaurav; Molina, Andres; Blaze, Matt (2006). «Keyboards and covert channels». USENIX. Retrieved 20 December 2018.
- ^ Tse, David; Viswanath, Pramod (2005), Fundamentals of Wireless Communication, Cambridge University Press, UK
- ^ Shannon, C. E. (1948). «A mathematical theory of communication» (PDF). Bell System Technical Journal. 27 (3–4): 379–423 & 623–656. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:11858/00-001M-0000-002C-4314-2.
- ^ Rosas, F.; Brante, G.; Souza, R. D.; Oberli, C. (2014). «Optimizing the code rate for achieving energy-efficient wireless communications». Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC). pp. 775–780. doi:10.1109/WCNC.2014.6952166. ISBN 978-1-4799-3083-8.
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009» Archived 3 February 2013 at the Wayback Machine, IEEE, 29 October 2009, accessed 21 March 2011.
- ^ a b Vucetic, B.; Yuan, J. (2000). Turbo codes: principles and applications. Springer Verlag. ISBN 978-0-7923-7868-6.
- ^ Luby, Michael; Mitzenmacher, M.; Shokrollahi, A.; Spielman, D.; Stemann, V. (1997). «Practical Loss-Resilient Codes». Proc. 29th Annual Association for Computing Machinery (ACM) Symposium on Theory of Computation.
- ^ «Digital Video Broadcast (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other satellite broadband applications (DVB-S2)». En 302 307. ETSI (V1.2.1). April 2009.
- ^ Andrews, K. S.; Divsalar, D.; Dolinar, S.; Hamkins, J.; Jones, C. R.; Pollara, F. (November 2007). «The Development of Turbo and LDPC Codes for Deep-Space Applications». Proceedings of the IEEE. 95 (11): 2142–2156. doi:10.1109/JPROC.2007.905132. S2CID 9289140.
- ^ Dolinar, S.; Divsalar, D. (15 August 1995). «Weight Distributions for Turbo Codes Using Random and Nonrandom Permutations». TDA Progress Report. 122: 42–122. Bibcode:1995TDAPR.122…56D. CiteSeerX 10.1.1.105.6640.
- ^ Takeshita, Oscar (2006). «Permutation Polynomial Interleavers: An Algebraic-Geometric Perspective». IEEE Transactions on Information Theory. 53 (6): 2116–2132. arXiv:cs/0601048. Bibcode:2006cs……..1048T. doi:10.1109/TIT.2007.896870. S2CID 660.
- ^ 3GPP TS 36.212, version 8.8.0, page 14
- ^ «Digital Video Broadcast (DVB); Frame structure, channel coding and modulation for a second generation digital terrestrial television broadcasting system (DVB-T2)». En 302 755. ETSI (V1.1.1). September 2009.
- ^ Techie (3 June 2010). «Explaining Interleaving». W3 Techie Blog. Retrieved 3 June 2010.
- ^ Krastanov, Stefan; Jiang, Liang (8 September 2017). «Deep Neural Network Probabilistic Decoder for Stabilizer Codes». Scientific Reports. 7 (1): 11003. arXiv:1705.09334. Bibcode:2017NatSR…711003K. doi:10.1038/s41598-017-11266-1. PMC 5591216. PMID 28887480.
- ^ Nordstrom, A.W.; Robinson, J.P. (1967), «An optimum nonlinear code», Information and Control, 11 (5–6): 613–616, doi:10.1016/S0019-9958(67)90835-2
- ^ Perry, Jonathan; Balakrishnan, Hari; Shah, Devavrat (2011). «Rateless Spinal Codes». Proceedings of the 10th ACM Workshop on Hot Topics in Networks. pp. 1–6. doi:10.1145/2070562.2070568. hdl:1721.1/79676. ISBN 9781450310598.
Further reading[edit]
- MacWilliams, Florence Jessiem; Sloane, Neil James Alexander (2007) [1977]. Written at AT&T Shannon Labs, Florham Park, New Jersey, USA. The Theory of Error-Correcting Codes. North-Holland Mathematical Library. Vol. 16 (digital print of 12th impression, 1st ed.). Amsterdam / London / New York / Tokyo: North-Holland / Elsevier BV. ISBN 978-0-444-85193-2. LCCN 76-41296. (xxii+762+6 pages)
- Clark, Jr., George C.; Cain, J. Bibb (1981). Error-Correction Coding for Digital Communications. New York, USA: Plenum Press. ISBN 0-306-40615-2.
- Arazi, Benjamin (1987). Swetman, Herb (ed.). A Commonsense Approach to the Theory of Error Correcting Codes. MIT Press Series in Computer Systems. Vol. 10 (1 ed.). Cambridge, Massachusetts, USA / London, UK: Massachusetts Institute of Technology. ISBN 0-262-01098-4. LCCN 87-21889. (x+2+208+4 pages)
- Wicker, Stephen B. (1995). Error Control Systems for Digital Communication and Storage. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-200809-2.
- Wilson, Stephen G. (1996). Digital Modulation and Coding. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-210071-1.
- «Error Correction Code in Single Level Cell NAND Flash memories» 2007-02-16
- «Error Correction Code in NAND Flash memories» 2004-11-29
- Observations on Errors, Corrections, & Trust of Dependent Systems, by James Hamilton, 2012-02-26
- Sphere Packings, Lattices and Groups, By J. H. Conway, Neil James Alexander Sloane, Springer Science & Business Media, 2013-03-09 – Mathematics – 682 pages.
External links[edit]
- Morelos-Zaragoza, Robert (2004). «The Correcting Codes (ECC) Page». Retrieved 5 March 2006.
- lpdec: library for LP decoding and related things (Python)