Между
признаками выборочной совокупности и
признаками генеральной совокупности,
как правило, существует некоторое
расхождение, которое называется ошибкой
статистического наблюдения. При массовом
наблюдении ошибки неизбежны, но возникают
они в результате действия различных
причин. Величина возможной ошибки
выборочного признака происходит из-за
ошибок регистрации и ошибок
репрезентативности. Ошибки регистрации,
или технические ошибки, связаны с
недостаточной квалификацией наблюдателей,
неточностью подсчетов, несовершенством
приборов и т. п.
Под
ошибкой
репрезентативности
(представительства) понимают расхождение
между выборочной характеристикой и
предполагаемой характеристикой
генеральной совокупности. Ошибки
репрезентативности бывают случайными
и систематическими. Систематические
ошибки связаны с нарушением установленных
правил отбора. Случайные
ошибки объясняются недостаточно
равномерным представлением в выборочной
совокупности различных категорий
единиц генеральной совокупности.
В
результате первой причины выборка
легко может оказаться смещенной, так
как при отборе каждой единицы допускается
ошибка, всегда направленная в одну и
ту же сторону. Эта ошибка получила
название ошибки
смещения.
Ее размер может превышать величину
случайной ошибки. Особенность ошибки
смещения состоит в том, что, являясь
постоянной частью ошибки репрезентативности,
она увеличивается с увеличением объема
выборки. Случайная же ошибка с увеличением
объема выборки уменьшается. Кроме того,
величину случайной ошибки можно
определить, тогда как размер ошибки
смещения практически определить очень
сложно, а иногда и невозможно, поэтому
важно знать причины, вызывающие ошибку
смещения, и предусмотреть мероприятия
по ее устранению.
Ошибки
смещения бывают преднамеренные и
непреднамеренные. Причиной возникновения
преднамеренной
ошибки
является тенденциозный подход к выбору
единиц из генеральной совокупности.
Чтобы не допустить появление такой
ошибки, необходимо соблюдать принцип
случайности отбора единиц.
Непреднамеренные
ошибки
могут возникать на стадии подготовки
выборочного наблюдения, формирования
выборочной совокупности и анализа ее
данных. Чтобы не допустить появление
таких ошибок, необходима хорошая основа
выборки, т. е. та генеральная
совокупность, из которой предполагается
производить отбор, например список
единиц отбора. Основа выборки должна
быть достоверной, полной и соответствовать
цели исследования, а единицы отбора и
их характеристики должны соответствовать
действительному их состоянию на момент
подготовки выборочного наблюдения.
Нередки случаи, когда в отношении
некоторых единиц, попавших в выборку,
трудно собрать сведения из-за их
отсутствия на момент наблюдения,
нежелания дать сведения и т. п. В
таких случаях эти единицы приходится
заменять другими. Необходимо следить,
чтобы замена осуществлялась равноценными
единицами.
Случайная
ошибка
выборки возникает в результате случайных
различий между единицами, попавшими в
выборку, и единицами генеральной
совокупности, т. е. она связана со
случайным отбором. Теоретическим
обоснованием появления случайных
ошибок выборки является теория
вероятностей и ее предельные теоремы.
Сущность
предельных
теорем
состоит в том, что в массовых явлениях
совокупное влияние различных случайных
причин на формирование закономерностей
и обобщающих характеристик будет сколь
угодно малой величиной или практически
не зависит от случая. Так как случайная
ошибка выборки возникает в результате
случайных различий между единицами
выборочной и генеральной совокупностей,
то при достаточно большом объеме выборки
она будет сколь угодно мала.
Предельные
теоремы теории вероятностей позволяют
определять размер случайных ошибок
выборки. Различают среднюю (стандартную)
и предельную ошибку выборки. Под средней
(стандартной) ошибкой
выборки понимают такое расхождение
между средней выборочной и генеральной
совокупностями (~ —), которое не превышает
±.
Предельной
ошибкой
выборки принято считать максимально
возможное расхождение (~ —), т. е.
максимум ошибки при заданной вероятности
ее появления.
В
математической теории выборочного
метода сравниваются средние характеристики
признаков выборочной и генеральной
совокупностей и доказывается, что с
увеличением объема выборки вероятность
появления больших ошибок и пределы
максимально возможной ошибки уменьшаются.
Чем больше обследуется единиц, тем
меньше будет величина расхождений
выборочных и генеральных характеристик.
На основании теоремы, доказанной П.Л.
Чебышевым, величину стандартной ошибки
простой случайной выборки при достаточно
большом объеме выборки (n)
можно определить по формуле

– стандартная
ошибка.
Из
этой формулы средней (стандартной)
ошибки простой случайной выборки видно,
что величина зависит от изменчивости
признака в генеральной совокупности
(чем больше вариация признака, тем
больше ошибка выборки) и от объема
выборки n
(чем больше обследуется единиц, тем
меньше будет величина расхождений
выборочных и генеральных характеристик).
Академик
A.M. Ляпунов доказал, что вероятность
появления случайной ошибки выборки
при достаточно большом ее объеме
подчиняется закону нормального
распределения. Эта вероятность
определяется по формуле

В
математической статистике употребляют
коэффициент доверия t, значения функции
F(t)
табулированы при разных его значениях,
при этом получают соответствующие
уровни доверительной вероятности
(табл. 6.1).
Таблица
6.1
Коэффициент
доверия t и соответствующие уровни
доверительной вероятности
![]()
Коэффициент
доверия позволяет вычислить предельную
ошибку выборки,

т. е.
предельная ошибка выборки равна
t-кратному числу средних ошибок выборки.
Таким
образом, величина предельной ошибки
выборки может быть установлена с
определенной вероятностью. Как видно
из последней графы табл. 6.1, вероятность
появления ошибки равной или большей
утроенной средней ошибки выборки,
т. е.
![]()
крайне
мала и равна 0,003(1–0,997). Такие маловероятные
события считаются практически
невозможными, а потому величину
![]()
можно
принять за предел возможной ошибки
выборки.
Выборочное
наблюдение дает возможность определить
среднюю арифметическую выборочной
совокупности и величину предельной
ошибки этой средней, которая показывает
(с определенной вероятностью), насколько
выборочная величина может отличаться
от генеральной средней в большую или
меньшую сторону. Тогда величина
генеральной средней будет представлена
интервальной оценкой, для которой
нижняя граница будет равна

Интервал,
в который с данной степенью вероятности
будет заключена неизвестная величина
оцениваемого параметра, называют
доверительным,
а вероятность Р
– доверительной вероятностью.
Чаще всего доверительную вероятность
принимают равной 0,95 или 0,99, тогда
коэффициент доверия t
равен соответственно 1,96 и 2,58. Это
означает, что доверительный интервал
с заданной вероятностью заключает в
себе генеральную среднюю.
Наряду
с абсолютной величиной предельной
ошибки выборки рассчитывается и
относительная
ошибка
выборки, которая определяется как
процентное отношение предельной ошибки
выборки к соответствующей характеристике
выборочной совокупности:

Чем
больше величина предельной ошибки
выборки, тем больше величина доверительного
интервала и тем, следовательно, ниже
точность оценки. Средняя (стандартная)
ошибка выборки зависит от объема выборки
и степени вариации признака в генеральной
совокупности.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
12.04.2015613.89 Кб24pr.doc
- #
- #
- #
- #
7.4. Влияние вида выборки на величину ошибки выборки
Как указывалось в п. 7.2, при проведении выборочного наблюдения используются различные способы формирования выборочной совокупности: случайный отбор — повторный или бесповторный, механический, серийный, типический. Вид выборки влияет на величину ошибки выборки. При бесповторном отборе формула средней ошибки выборки дополняется множителем

который корректирует величину ошибки выборки и в связи с изменением состава совокупности и вероятности попадания единиц в выборку. В серийной выборке дисперсия определяется как колеблемость между сериями:
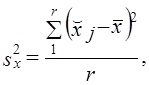 (7.14)
(7.14)
где x̌j — среднее значение признака х в у-й серии;
х̅ — среднее значение в целом по выборке;
r — число отобранных серий.
Формула (7.14) предполагает равенство серий по числу единиц, если это условие не выполняется, то в числитель выражения (7.14) вводится вес — число единиц в j-й серии, fj; тогда в знаменателе указывается не r, а 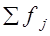 . Межсерийная дисперсия представляет часть общей дисперсии признака х, и потому ее использование направлено на уменьшение ошибки выборки. Однако значение г намного меньше п, так как число отобранных гнезд намного меньше числа единиц наблюдения. Этот фактор увеличивает ошибку выборки. Его действие более значительно, нежели понижающее влияние межсерийной дисперсии — в результате ошибка серийной выборки в среднем больше ошибки выборки при отборе единицами.
. Межсерийная дисперсия представляет часть общей дисперсии признака х, и потому ее использование направлено на уменьшение ошибки выборки. Однако значение г намного меньше п, так как число отобранных гнезд намного меньше числа единиц наблюдения. Этот фактор увеличивает ошибку выборки. Его действие более значительно, нежели понижающее влияние межсерийной дисперсии — в результате ошибка серийной выборки в среднем больше ошибки выборки при отборе единицами.
При типическом отборе (стратифицированная или районированная выборка) дисперсия рассчитывается как средняя из внутрирайонных дисперсий:
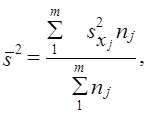 (7.15′)
(7.15′)
где s2ji — выборочная дисперсия признака х в j-м районе;
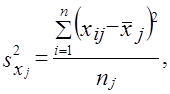
где пj — объем выборки в j-м районе;
т — число районов.
Очевидно, что по правилу сложения дисперсий величина s2 меньше, чем величина общей дисперсии.
Величина ошибки районированной выборки меньше величины ошибки простой (нерайонированной выборки).
Часто используется сочетание районированного отбора с отбором сериями. Такой вид выборки обеспечивает преимущества в организации выборки и уменьшение ошибки выборки. Дисперсия такой выборки представляет среднюю из межсерийных дисперсий для каждого j-го района:
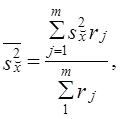 (7.16)
(7.16)
где s2x̌j — межсерийная дисперсия в j-м районе;
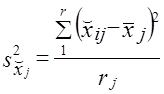 ,
,
х̌ij — средняя в i-й серии j-го района;
х̅j — средняя ву-м районе;
r— число серий, отобранных в j-м районе;
т — число районов.
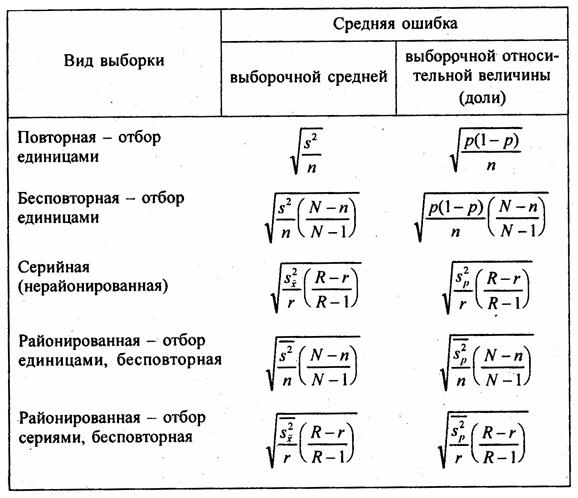
Табл. 7.2 содержит формулы средней ошибки выборки для выборочной средней и выборочной относительной величины для разных видов выборки. В приведенных формулах требуют пояснения выражения дисперсий выборочной относительной величины.
При нерайонированной серийной выборке
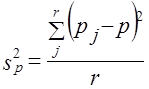 ,
,
где рj — доля единиц определенной категории в у-й серии;
р — доля единиц этой категории в выборке.
Таблица 7.2
Формулы средней ошибки выборочной средней и выборочной относительной величины
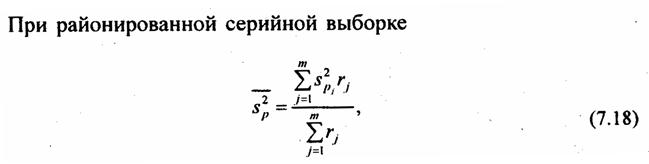

Рассмотрим на примере влияние вида выборки на величину ошибки выборки. Исходные данные представлены в табл. 7.3.
Таблица 7.3
Показатели 60 предприятий легкой промышленности Санкт-Петербурга (по данным статистической отчетности за I полугодие 1995 г.)
|
№ пп |
Форма Собственнос-ти |
Оборачиваемость запасов, х1 |
Коэффициент покрытия, х2 |
№ пп |
Форма собственности |
Оборачиваемость запасов, х1 |
Коэффициент покрытия, х2 |
|
1 |
государственная |
5,65 |
0,22 |
31 |
Частная |
1,23 |
1,18 |
|
2 |
« |
2,86 |
0,35 |
32 |
« |
0,82 |
1,59 |
|
3 |
« |
1,61 |
1,06 |
33 |
« |
2,83 |
0,74 |
|
4 |
« |
3,99 |
1,01 |
34 |
« |
1,83 |
1,52 |
|
5 |
« |
2,17 |
8,88 |
35 |
« |
2,26 |
2,43 |
|
6 |
« |
1,52 |
1,06 |
36 |
« |
2,33 |
3,28 |
|
7 |
« |
0,40 |
0,99 |
37 |
« |
2,35 |
1,13 |
|
8 |
« |
2,18 |
1,07 |
38 |
« |
1,68 |
0,89 |
|
9 |
« |
1,36 |
4,62 |
39 |
« |
2,00 |
1,67 |
|
10 |
« |
3,69 |
1,40 |
40 |
« |
2,64 |
1,48 |
|
11 |
частная |
0,45 |
1,34 |
41 |
« |
2,75 |
1,51 |
|
12 |
« |
1,0 |
1,16 |
42 |
« |
3,29 |
5,96 |
|
13 |
« |
2,05 |
2,00 |
43 |
« |
1,6 |
1,38 |
|
14 |
« |
2,36 |
1,43 |
44 |
« |
1,90 |
2,39 |
|
15 |
« |
4,90 |
1,76 |
45 |
« |
3,27 |
3,62 |
|
16 |
« |
3,12 |
1,26 |
46 |
« |
3,49 |
0,46 |
|
17 |
« |
1,36 |
1,89 |
47 |
« |
2,92 |
1,26 |
|
18 |
« |
1,56 |
12,36 |
48 |
смешання |
3,22 |
0,78 |
|
19 |
« |
4,84 |
1,23 |
49 |
« |
2,61 |
1,67 |
|
20 |
« |
1,23 |
3,26 |
50 |
« |
5,17 |
0,95 |
|
21 |
« |
0,81 |
2,22 |
51 |
« |
8,63 |
0,96 |
|
22 |
« |
0,7 |
1,16 |
52 |
« |
1,06 |
2,51 |
|
23 |
« |
0,87 |
1,21 |
53 |
« |
2,13 |
3,49 |
|
24 |
« |
0,20 |
1,45 |
54 |
« |
2,03 |
1,22 |
|
25 |
« |
1,71 |
4,04 |
55 |
« |
1,82 |
2,92 |
|
26 |
« |
1,83 |
2,07 |
56 |
« |
3,12 |
1,54 |
|
27 |
« |
1,32 |
0,69 |
57 |
« |
0,77 |
0,97 |
|
28 |
« |
1,95 |
1,97 |
58 |
« |
4,15 |
0,93 |
|
29 |
« |
1,46 |
1,31 |
59 |
« |
3,62 |
1,34 |
|
30 |
« |
2,96 |
5,32 |
60 |
« |
3,89 |
3,51 |
Предприятия легкой промышленности примем за генеральную совокупность. Ее характеристики:
численность N = 60;
генеральные средние: μ1 = 2,40 число оборотов;
μ2 = 1,424;
генеральные дисперсии: σ21 = 2,24;
σ22 = 4,38;
средние квадратические σ1 = 1,49 оборотов;
отклонения: σ2 = 2,09.
Остановимся на смысле характеристик предприятий: оборачиваемость запасов рассчитывается делением продолжительности периода (полгода) на среднюю продолжительность одного периода оборота запасов. Очевидно, чем скорее оборачиваются запасы, тем выше их отдача. Коэффициент покрытия рассчитывается как отношение суммы всех источников покрытия запасов к стоимости запасов. Если значение этого показателя меньше единицы, то текущее финансовое состояние предприятия рассматривается как неустойчивое. В нашем примере вариация этого признака примерно в 2 раза превосходит вариацию предприятий по уровню оборачиваемости запасов: ν2 = 147%, ν1 = 62%.
Произведем 30%-ную выборку. Объем выборки составит п = 20 предприятий. При формировании выборки методом механического отбора каждое третье предприятие попадет в выборку. Отбор начинаем с полушага отбора, т. е. первым предприятием, попавшим в выборку, является второе по списку. Средние по выборке равны:
оборачиваемость запасов x̅1 =2,16 оборотов, коэффициент покрытия x̅2=2,01.
Средняя ошибка выборочной средней оборачиваемости запасов
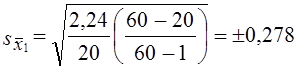 оборотов.
оборотов.
Средняя ошибка выборочного среднего коэффициента покрытия
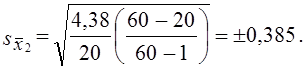
С вероятностью 0,954 можно утверждать, что средняя оборачиваемость запасов на предприятиях легкой промышленности не ниже
x̅1 — 2sx1 = 2,16 — 0,55 = 1,61 оборотов и не выше x̅1+2sx1 = 2,16 + 0,55 = 2,71 оборотов.
Действительно генеральная средняя (μ1 = 2,40) попадает в этот интервал.
Фактическая ошибка репрезентативности
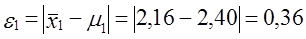 оборотов.
оборотов.
Эта величина меньше предельной ошибки выборки, гарантированной с принятой доверительной вероятностью, 0,36 < 0,55. Следовательно, выборка репрезентативна по этому признаку.
Вычислим предельную ошибку выборки коэффициента покрытия и определим доверительный интервал для этой характеристики. Его нижняя граница с той же вероятностью
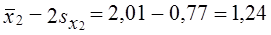 ;
;
верхняя граница:
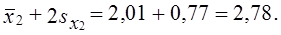
Генеральная средняя (μ2 = 1,424) так же попадает в доверительный интервал.
Фактическая ошибка репрезентативности составляет:
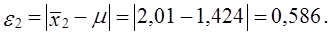
Эта величина меньше предельной ошибки выборки (0,77), что дает основание считать выборку репрезентативной и по этому признаку.
В генеральной совокупности доля единиц с неустойчивым финансовым положением (х2 < 1) составила 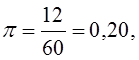 в выборке
в выборке 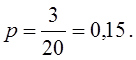
Доверительный интервал для оценки доли таких предприятий в генеральной совокупности составляет с вероятностью 0,954:
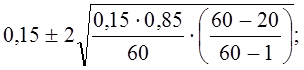
0,15 ± 0,076,
т. е. таких предприятий должно быть не меньше 7,4% и не больше 22,6%. Фактически их оказалось 20% от общего числа предприятии, т. е. выборка дает репрезентативный результат и по этому показателю.
Выполненная выборка формировалась как простая бесповторная механическая. Однако, наверняка статистик будет стремиться учесть структуру генеральной совокупности, поэтому более естественной была бы выборка, учитывающая выделение предприятий разных форм собственности. Тогда выборка должна быть районированной.
Рассмотрим пример. Генеральная совокупность состоит из 11 государственных предприятий, 36 частных, 13 смешанных. В выборке эти пропорции соблюдаются следующим образом: отобраны по 4 предприятия государственных и смешанных и 12 — частных:
|
Предприятия |
Генеральные характеристики |
Выборочные характеристики |
||
|
средние |
доли |
средние |
доли |
|
|
Государственные |
μ1 = 2.35 |
π1 = 0,27 |
х̅1 = 1,92 |
Р1 = 0,25 |
|
Частные |
μ1 =2,11 |
π2 = 0,11 |
х̅1 = 1,79 |
Р2=0,08 |
|
Смешанные |
μ1 =3,25 |
π3 = 0,38 |
х̅1 =3,51 |
Рз — 0,25 |
Средняя из внутрирайонных дисперсий, рассчитанных по каждой группе предприятий в генеральной совокупности:
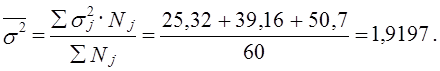
Эта величина меньше общей дисперсии без учета районирования (σ2 = 2,24). Следовательно, и величина ошибки выборки при районированном отборе будет меньше:
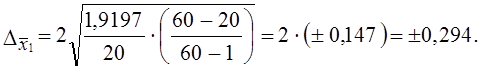
Итак, с вероятностью 0,954 генеральная средняя оборачиваемости запасов находится в интервале 2,16 ± 0,294; 1,866 £ μ £ 2,454.
Чтобы понять, насколько целесообразно в том или ином случае применение районированного отбора, можно воспользоваться корреляционным отношением ц. Согласно правилу сложения дисперсий средняя из внутригрупповых дисперсий может быть представлена как

где h2 — квадрат корреляционного отношения, равный б2:s2.
Следовательно, применение районированной (типической) выборки изменяет предельную ошибку на 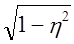 . В нашем примере для первой переменной (оборачиваемость) имеем:
. В нашем примере для первой переменной (оборачиваемость) имеем:
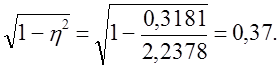
Сопоставим полученный результат с изменением предельной ошибки выборки: 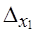 (без учета районирования) =0,55;
(без учета районирования) =0,55;
∆x (при районировании) = 0,294, т. е. ошибка уменьшилась примерно вполовину.
Корреляционное отношение используется и при корректировке величины
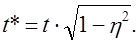 (7.18′)
(7.18′)
Тогда при вероятности 0,954 и t = 2; t*=2 — Ö0̅,8̅6̅ = 1,85, т. е. вместо t = 2 достаточно взять t = 1,85.
Многие выборки формируются как многоступенчатые. Ошибка многоступенчатой выборки может быть представлена как
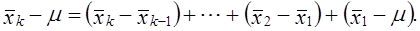
Она складывается из ошибок отдельных ступеней. Поэтому практически используется не больше 2-3 ступеней отбора.
Средняя ошибка выборки при двухступенчатом отборе рассчитывается по формуле
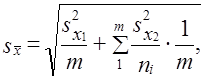
где sx1 2 — дисперсия признака х по совокупности «крупных» единиц;
sx22 — дисперсия признака х в каждой из отобранных «крупных» единиц;
пi — число отобранных единиц наблюдения в <-й «крупной» единице;
т — число отобранных «крупных» единиц.
Таким образом, применение многоступенчатой выборки улучшает организацию выборки, но увеличивает ее ошибку.
Кроме рассмотренных, применяется многофазовая выборка, когда одни сведения собираются на основе изучения всех единиц выборки, а другие — только на основании изучения некоторых из этих единиц, отобранных так, что они составляют подвыборки из единиц первоначальной выборки.
При периодическом повторении выборочных обследований с целью изучения динамики явлений применяются либо независимые выборки — через определенные промежутки времени отбор каждый раз производится независимо от предыдущих выборок; либо фиксированные выборки — в этом случае повторные обследования проводятся по одной и той же выборке. В связи с тем, что в фиксированной выборке могут происходить изменения (прежде всего за счет выбытия единиц) практикуют периодическую адаптацию фиксированной выборки происходящим изменениям. Чаще для целей изучения динамики используется промежуточный вариант — ротационная выборка (частичное замещение). При этом нужно следовать определенному плану замещения, например, каждый раз замещать четверть выборки, тогда каждая первоначальная единица останется в выборке в четырех следующих друг за другом обследованиях.
Названные виды выборок ориентированы на отбор конкретных материальных явлений. Кроме них следует назвать как особый вид выборки метод моментных наблюдений.Сущность метода моментных наблюдений состоит в периодической фиксации состояний .наблюдаемых единиц в отобранные моменты времени. Расчет объема такой выборки дает количество моментов. Этот вид выборочного наблюдения применяется при изучении использования производственного оборудования, либо рабочего времени (см. п. 7.13).
7.5. Задачи, решаемые при применении выборочного метода
При применении выборочного наблюдения возникают три основные задачи:
• определение объема выборки, необходимого для получения требуемой точности результатов с заданной вероятностью;
• определение возможного предела ошибки репрезентативности, гарантированного с заданной вероятностью, и сравнение его с величиной допустимой погрешности.
• определение вероятности того, что Ошибка выборки не превысит допустимой погрешности.
Все эти задачи решаются на основе теоремы Чебышева, согласно которой Р {[ х — μ | < e } ³ 1 — h, когда п — достаточно большое число; e и h — сколь угодно малые положительные числа. Это соотношение, как было показано в п. 7.3, может быть выражено через формулу предельной ошибки выборки ∆x = tsx или ∆p = ts. Решение указанных задач зависит от того, какие величины в формуле предельной ошибки заданы, а какие нужно найти.
Объем выборки рассчитывается на стадии проектирования выборочного обследования. Так как
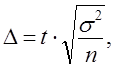
то
 , (7.20)
, (7.20)
где ∆ — допустимая погрешность,, которая задается исследователем исходя из требуемой точности результатов проектируемой выборки;
t — табличная величина, соответствующая заданной доверительной вероятности F(t), с которой будут гарантированы оценки генеральной совокупности по данным выборочного обследования;
σ2 — генеральная дисперсия.
Последняя величина, как правило, неизвестна. Используются какие-либо ее оценки: результаты прошлых обследований той же совокупности, если ее структура и условия развития достаточно стабильны, или же зная примерную величину средней, находят дисперсию из соотношения 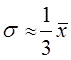 ;
;
если известны xmax и хmin, то можно определить среднее квадратическое отклонение в соответствии с правилом «трех сигм»
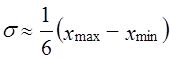 ,
,
так как в нормальном распределении в размахе вариации «укладывается» 6σ(±3σ). Если распределение заведомо асимметричное, то
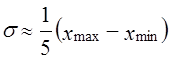 .
.
Для относительной величины принимают максимальную величину дисперсии σ2max = 0,5∙0,5 = 0,25.
При расчете п не следует гнаться за большими значениями t и малыми значениями ∆, так как это приведет к увеличению объема выборки, а следовательно, к увеличению затрат средств, труда и времени, вовсе не являющемуся необходимым.
Формула (7.20) не учитывает бесповторности отбора и дает максимальную величину выборки, которую можно скорректировать «на бесповторность». Так как
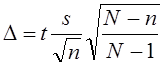 ,
,
то на основе (7.20) получаем выражение скорректированного объема выборки (п):
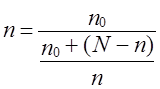 , (7.21)
, (7.21)
где
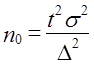 .
.
При больших размерах генеральной совокупности скорректированный Объем выборки незначительно отличается от n0.
Например, для изучения структуры и стоимости покупок в универмаге из 10 000 покупателей следует отобрать определенное число человек, которое бы обеспечивало с вероятностью 0,95 определение средней стоимости покупок с точностью не менее 2 тыс. руб. Дисперсию примем по прошлому обследованию равной 625.
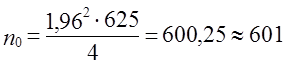 человек;
человек;
тогда скорректированная численность
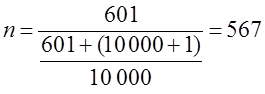 человек (≈ 570 человек).
человек (≈ 570 человек).
При проектировании районированной выборки рассчитанный объем выборки распределяют пропорционально численности районов (пропорциональный отбор):
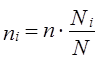 , (7.22)
, (7.22)
где пi — объем выборки для i-го района;
Ni — объем i-го района в генеральной совокупности;
п — общий объем выборки;
N — общий объем генеральной совокупности.
При различиях в однородности выделенных районов лучшие результаты дает распределение запланированного объема выборки между районами не только с учетом их объема, но и с учетом дисперсии признака (оптимальный отбор). В этом случае объем выборки в i-м районе определяется как
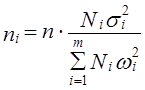 , (7.23)
, (7.23)
где σ2i — дисперсия признака х в i-м районе.
При любом виде проектируемой выборки расчет объема выборки начинают по формуле повторного отбора (7.20). Если в результате расчета п доля отбора превысит 5%, проводят второй вариант расчета по формуле бесповторного отбора, либо по формуле (7.21), либо как
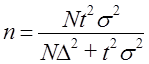 .
.
Если доля отбора меньше 5%, к формуле бесповторного отбора не переходят, так как это не скажется существенно на величине п.
Выборка должна быть такой, чтобы выборочные показатели по всем основным характеристикам были репрезентативны. Поэтому численность выборки рассчитывают многократно исходя из допустимых ошибок разных показателей, значения которых в генеральной совокупности известны.
Например, при выборочном учете детей школьного возраста требуется определить число семей, которые надо обследовать. При этом надо учесть: а) число детей в возрасте 6-7 лет, б) число детей в возрасте 6-15 лет; в) число детей в возрасте 16-17 лет;
г) среднедушевой доход (например, для решения вопроса о строительстве базы отдыха).
Так как репрезентируемые признаки могут иметь разную размерность, то допустимая погрешность для каждого их них задается в виде относительной величины (∆ : х̅) (например, планируется, что в определении среднего размера семьи ошибка должна быть не больше 2%, в определении дохода — не больше 3% и т.д.). В этом случае вместо дисперсии в формуле (7.20) берется квадрат коэффициента вариации.
Вычислив значение п, на основе каждой из характеристик получаем разные объемы выборки: 1200; 300; 700; 100. Обследовать необходимо 1200 семей, т.е. из рассчитанных численностей берется максимальная. При резких различиях необходимых объемов выборки для разных вопросов программы проводится многофазный отбор. В рассмотренном примере среднедушевой доход достаточно учитывать в одной из каждых 12 семей, попавших в выборку.
Многофазный отбор, как правило, довольно сложно организовать, может быть нарушен принцип случайности отбора. Поэтому для обеспечения репрезентативности оказывается выгоднее затратить больше средств на учет большего числа единиц совокупности. Многофазный отбор целесообразно применять, если соотношение между рассчитанными объемами выборки по крайней мере 1:6.
Поскольку расчет необходимой численности выборки основан не на точных, а на предположительных данных о колеблемости в совокупности, следует соблюдать следующие рекомендации: абсолютную величину п округлять только вверх; долю отбора округлять только вниз, т.е. из предосторожности планировать несколько больший объем выборки, чем показывают расчеты.
Объем многоступенчатой выборки рекомендуется увеличить не менее чем на 10% от рассчитанной численности, поскольку, как было показано в предыдущем параграфе, многоступенчатость отбора увеличивает ошибку выборки.
После проведения выборки рассчитывают возможные ошибки . выборочных показателей (ошибки репрезентативности), которые используются для оценки результатов выборки и для получения характеристик генеральной совокупности.
Пример. На электроламповом заводе взято для проверки 100 ламп. Средняя продолжительность их горения оказалась 1420 ч со средним квадратическим отклонением 61,03 ч. Поскольку приемщика продукции интересует качество всей партии (50 тыс. электроламп), оценивают точность полученной средней. Средняя возможная ошибка вычисленной выборочной средней
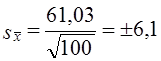 ч.
ч.
С вероятностью 0,954 предел возможной ошибки
∆х = 2∙6,1 = ± 12,2 ч.
С вероятностью 0,954 можно утверждать, что средняя продолжительность горения 1 электролампы во всей партии будет находиться в пределах от 1408 до 1432 ч; 46 электроламп из 1000 могут иметь срок горения, выходящий за эти пределы.
Приемщика продукции интересуют отклонения от вычисленных пределов только в сторону сокращения продолжительности горения. Меньше чем 1408 ч могут гореть 23 лампы из 1000. На основании этого приемщик продукции решает вопрос о годности всей партии электроламп.
Решение вопроса может быть уточнено: определим, у какой доли ламп срок службы окажется меньше установленного лимита. Для потребителя продукции таким лимитом являются 1410 ч, продукция с меньшим сроком горения неприемлема.
При контрольной проверке 100 ламп 100 ламп горели менее 1410 ч, их удельный вес р = 0,1, или 10%. Средняя возможная ошибка этой доли
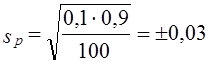 , или ± 3%.
, или ± 3%.
С вероятностью 0,954 предел ошибки доли Д^ = 2 • 0,03 = ± 0,06, или ±6%. Следовательно, во всей партии можно ожидать от 4 до 16% некачественных электроламп.
Чаще всего делают заключение об удовлетворительности выборки, сопоставляя получившиеся пределы ошибок выборочных показателей с величинами допустимых погрешностей. Может получиться, что предел ошибки, рассчитанный с заданной вероятностью, окажется выше допустимого размера погрешности. В этих случаях определяют вероятность того, что ошибка выборки не превзойдет допускаемую погрешность. Решение этой задачи и заключается в отыскании Fft) на основе формулы предела ошибки выборки:
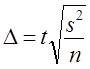 ,
,
где ∆ — допустимый размер погрешности оцениваемого показателя;
s2 — дисперсия показателя, рассчитанная по данным выборочного наблюдения;
п — объем проведенной выборки.
Продолжим пример с оценкой качества электроламп. Если при приемке партии электроламп ставится условие, что минимальный срок горения электроламп 1410 ч, то, учитывая среднюю продолжительность горения по выборке (х= 1420 ч), допустимая погрешность равна 10 ч: 1410 — 1420 = — 10 ч.
Как было установлено выше, с вероятностью 0,954 предел возможной ошибки выборочной средней составил 12,2 ч, что превосходит допустимую погрешность. Является ли это основанием для браковки всей партии? Для ответа на этот вопрос определяют вероятность риска при приемке продукции:
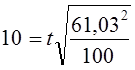 , отсюда t= 1,64.
, отсюда t= 1,64.
Соответствующая доверительная вероятность 0,899 (см. приложение, табл. 1). Вероятность того, что средний срок горения лампы меньше 1410 ч, равна:
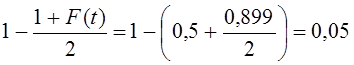
Следовательно, из 100 ламп 5 могут гореть менее 1410 ч — риск появления некачественной продукции достаточно высок.
Аналогично можно определить вероятность того, что предел ошибки доли не превысит допускаемую погрешность доли.
Оценки надежности выборочных показателей, как показано на примере, позволяют принять обоснованные решения в отношении генеральной совокупности.
7.6. Распространение данных выборочного наблюдения на генеральную совокупность
Конечной целью выборочного наблюдения является характеристика генеральной совокупности на основе данных, полученных по выборке. При этом исходят из того, что все средние и относительные показатели, полученные по выборке, являются несмещенными и эффективными характеристиками генеральной совокупности.
Выборочные средние и относительные величины распространяются на генеральную совокупность обязательно с учетом предела их возможной ошибки. Приводится выборочный показатель со справкой о пределах ошибки с указанием доверительной вероятности: x̅ ± ∆x, p ± ∆p. Или же указывают границы значений генеральной характеристики с определенной вероятностью F(t):
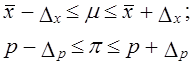
Последняя форма записи является основной.
Иногда требуется указать только один (верхний или нижний) предел характеристики генеральной совокупности. При испытании качества продукции часто нас не интересуют положительные ошибки выборки (качество фактически выше, чем получилось по выборке), беспокоит нижний предел, как в примере, рассмотренном в предыдущем параграфе. В некоторых случаях, напротив, интерес вызывают верхние границы оцениваемых показателей, например при анализе расхода материалов. Так что при характеристике генеральной совокупности всегда указывают неблагоприятный предел.
На основе выборки могут быть получены и значения объемных показателей, т. е. подсчетов для генеральной совокупности. Такой расчет осуществляется двумя способами: путем прямого расчета и способом коэффициентов. Прямой расчет заключается в том, что выборочная средняя или доля умножается на объем генеральной совокупности:
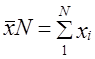 .
.
Так как средняя величина имеет ошибку репрезентативности ± А д то можно считать, что итоговый подсчет в генеральной совокупности находится в пределах
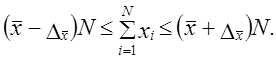 (7.24)
(7.24)
Итоговый подсчет по генеральной совокупности можно получить на основе итогового подсчета по выборке, разделив его на долю отбора единиц совокупности
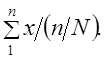
Прежде чем проводить расчет объемных показателей для генеральной совокупности, нужно убедиться, что структура выборки соответствует структуре генеральной совокупности. При наличии значительных смещений в структуре выборки в долях отдельных групп (0,03 и выше) следует применить метод перевзвешивания, г. в. рассчитывать генеральную среднюю на основе выборочных средних по группам и удельного веса этих групп в генеральной совокупности:
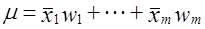 ,
,
где wi = NiN.
При способе коэффициентов также используются не только выборочные данные, но и сведения о генеральной совокупности.
Этот способ основан на связи признаков друг с другом. Например, в результате выборочного обследования семей города получены размер среднедушевого дохода (х̅), средний доход семьи (у̅) и среднее число человек в семье (z̅). Так что x̅ = y̅ / z̅.
Зная численность населения города, требуется рассчитать общую величину денежного дохода населения. Очевидно, это можно сделать, умножив душевой доход на общее число жителей в городе: x̅N. Общий доход можно получить, суммируя доход отдельных семей; численность населения можно получить, суммируя данные о числе членов семей. Тогда
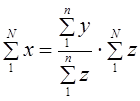 .
.
Средний душевой расход 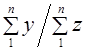 представляет собой коэффициент, подсчитанный по выборке, который связывает две характеристики. Этот коэффициент рассчитывается как отношение двух итоговых подсчетов по выборке:
представляет собой коэффициент, подсчитанный по выборке, который связывает две характеристики. Этот коэффициент рассчитывается как отношение двух итоговых подсчетов по выборке:
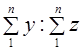 .
.
Следовательно,
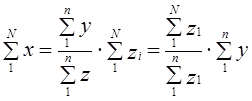 .
.
Последний сомножитель не что иное, как обратная величина доли отбора, рассчитанной по значениям признака z.
Итак, итоговый подсчет по генеральной совокупности может быть получен делением соответствующего итогового подсчета по выборке на долю отбора. При прямом расчете берется доля отбора единиц совокупности, при способе коэффициентов — доля отбора по значению какого-либо признака.
Эффективность способа коэффициентов по сравнению с методом прямого расчета зависит от того, насколько тесно связаны между собой признаки, лежащие в основе расчета коэффициента, т.е. признак, по которому подсчитывается итог, и признак, по которому определяется доля отбора. Эффект проявляется, если коэффициент корреляции между ними больше 0,8.
Способ коэффициентов используется для корректировки данных сплошного наблюдения. Например, перепись скота дала сведения, что поголовье свиней в районе составляет 10 000, в том числе в тех хозяйствах, которые потом были охвачены контрольным обходом, сплошное наблюдение показало число свиней 1100. Контрольный обход дал уточненную цифру: не 1100, а 1107 свиней. Тогда поправочный коэффициент
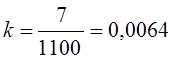 .
.
Отсюда скорректированная численность поголовья свиней во всем районе
N =N¢+∆N; ∆N = kN¢ = ∙10 000 = 64.
N = 10 000 + 64 = 10 064 голов.
Таблицы интеграла вероятностей используются для выборок большого объема из бесконечно большой генеральной совокупности. Но уже при п < \ 00 получается несоответствие между табличными данными и вероятностью предела; при п < 100 погрешность становится значительной. Несоответствие вызывается главным образом характером распределения единиц генеральной совокупности. При большом объеме выборки особенность распределения в генеральной совокупности не имеет значения, так как распределение отклонений выборочного показателя от генеральной характеристики при большой выборке всегда оказывается нормальным.
В выборках небольшого объема п £ 30 характер распределения генеральной совокупности сказывается на распределении ошибок выборки. Поэтому для расчета ошибки выборки при небольшом объеме наблюдения (уже менее 100 единиц) отбор должен проводиться из совокупности, имеющей нормальное распределение.
Теория малых выборок разработана английским статистиком В. Госсетом (писавшим под псевдонимом Стьюдент) в начале XX в. В 1908 г. им построено специальное распределение, которое позволяет и при малых выборках соотносить t и доверительную вероятность F(t). При п > 100 таблицы распределения Стьюдента дают те же результаты, что и таблицы интеграла вероятностей Лапласа, при 30 £ п £ 100 различия незначительны. Поэтому практически к малым выборкам относят выборки объемом менее 30 единиц (безусловно, большой считается выборка с объемом более 100 единиц).
Использование малых выборок в ряде случаев обусловлено характером обследуемой совокупности. Так, в селекционной работе «чистого» опыта легче добиться на небольшом числе делянок. Производственный и экономический эксперимент, связанный с экономическими затратами, также проводится на небольшом числе испытаний.
Как уже отмечалось, в случае малой выборки только для нормально распределенной генеральной совокупности могут быть рассчитаны и доверительные вероятности, и доверительные пределы генеральной средней.
Плотность вероятностей распределения Стьюдента описывается функцией
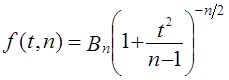 , (7.25)
, (7.25)
где t — текущая переменная;
п — объем выборки;
В — величина, зависящая лишь от п.
Распределение Стьюдента имеет только один параметр: d.f. —число степеней свободы (иногда обозначается k).
Это распределение, как и нормальное, симметрично относительно точки t = 0, но оно более пологое. При увеличении объема выборки, а следовательно, и числа степеней свободы распределение Стьюдента быстро приближается к нормальному. Число степеней свободы равно числу тех индивидуальных значений признаков, которыми нужно располагать для определения искомой характеристики.
Так, для расчета дисперсии должна быть известна средняя величина. Поэтому при расчете дисперсии d.f. = п — 1
Таблицы распределения Стьюдента публикуются в двух вариантах:
1) аналогично таблицам интеграла вероятностей приводятся значения t и соответствующие вероятности F(t) при разном числе степеней свободы;
2) значения t приводятся для наиболее употребимых доверительных вероятностей 0,90; 0,95 и 0,99 или для 1 — 0,9 = 0,1, 1 — 0,95 = = 0,05 и 1 — 0,99 == 0,01 при разном числе степеней свободы. Такого рода таблица приведена в приложении (табл. 2), а также значение t-критерия Стьюдента при уровне значимости 0,10; 0,05; 0,01.
При малых выборках расчет средней возможной ошибки основан на выборочных дисперсиях, поэтому
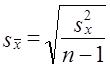 .
.
Приведенная формула используется для определения предела возможной ошибки выборочного показателя:
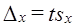 .
.
Порядок расчетов тот же, что и при больших выборках.
Пример. Для изучения интенсивности труда было организовано наблюдение за 10 отобранными рабочими. Доля работавших все время оказалась равной 0,40, дисперсия 0,4∙0,6 = 0,24. По табл. 2 приложения находим для F(t) = 0,95 и d.f. = n — 1 = 9, t = 2,26. Рассчитаем среднюю ошибку выборки доли работавших все время:
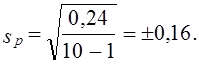
Тогда предельная ошибка выборки ∆p = 2,26∙0,16 = ± 0,36. Таким образом, с вероятностью 0,95 доля рабочих, работавших без простоев, в данном цехе предприятия находится в пределах
39,64% £ π £ 40,36%
или
39,6% £ π £ 40,4%.
Если бы мы использовали для расчета доверительных границ генерального параметра таблицу интеграла вероятностей, то t было бы равно 1,96 и ∆p — ± 0,31, т. е. доверительный интервал был бы несколько уже.
Малые выборки широко используются для решения задач, связанных с испытанием статистических гипотез, особенно гипотез о средних величинах.
1.1. Ошибки
выборочного наблюдения
Средняя
ошибка выборки показывает, как генеральная средняя отклоняется в среднем от выборочной средней в ту или другую сторону. Формула
расчета средней ошибки выборки определяется видом исследуемого признака единиц
совокупности (количественный или альтернативный) и
способом отбора (бесповторный или повторный).
·
Если отбор повторный, а признак количественный
средняя ошибка выборки определяется по формуле
![]() , где
, где ![]() — дисперсия признака в выборочной совокупности
— дисперсия признака в выборочной совокупности
n- число единиц
в выборке
·
Если отбор бесповторный, а признак
количественный
 , где N—
, где N—
число единиц в генеральной совокупности
·
Если отбор повторный, а признак альтернативный
 , где w-выборочная
, где w-выборочная
доля
·
Если отбор бесповторный, а признак
альтернативный

Предельная ошибка выборки— показывающая с определенной степенью вероятности
отклонения средней от выборочной средней.
Предельная ошибка выборки
![]() , где параметр t зависит
, где параметр t зависит
от вероятности
Некоторые значения параметра t приведены
в таблице:
|
Вероятность, p |
0.95 |
0.954 |
0.9876 |
0.9907 |
0.9973 |
0.9999 |
|
Параметр t |
1.96 |
2.0 |
2.5 |
2.6 |
3.0 |
4.0 |
·
Если отбор повторный, а признак количественный
средняя ошибка выборки определяется по формуле
![]() , где
, где ![]() — дисперсия признака в выборочной совокупности
— дисперсия признака в выборочной совокупности
n- число единиц
в выборке
·
Если отбор бесповторный, а признак
количественный
 , где N—
, где N—
число единиц в генеральной совокупности
·
Если отбор повторный, а признак альтернативный
 , где w-выборочная
, где w-выборочная
доля
·
Если отбор бесповторный, а признак
альтернативный

Доверительный интервал для генеральной средней
![]()
Доверительный интервал для
генеральной доли
![]()
Пример расчета доверительного
интервала:
При выборочном обследовании 5% продукции по методу случайного
бесповторного отбора получены данные о содержании сахара в образцах:
|
Сахарность, % |
Число |
|
16-17 17-18 18-19 19-20 20-21 |
10 158 154 50 28 |
|
На основании этих данных вычислите:
1. Средний процент сахаристости.
2. Дисперсию и среднее квадратическое
отклонение.
3. С вероятностью 0.954 возможные пределы среднего значения
сахаристости продукции для всей партии.
4. С вероятностью 0.997 возможный процент продукции высшего
сорта по всей партии, если известно, что из 400 проб, попавших в выборку , 80
ед. отнесены к продукции высшего сорта.
Решение.
1.
Средний процент сахаристости найдем по формуле средней взвешенной
![]() , где xi–
, где xi–
середина i-го интервала
![]() =18,32 %
=18,32 %
2.
Дисперсия
![]()
![]()
![]() =336,49
=336,49
D(X)=336.49–
18.322=0.8676
Среднее квадратическое отклонение
![]() =0,93%
=0,93%
5. Предельная ошибка для
среднего процента сахаристости
![]()
для вероятности 0,954 параметр t=2.0
![]()
Доверительный интервал для среднего значения процента
сахаристости
![]()
![]()
![]()
С вероятностью 0,954 можно утверждать, что в генеральной
совокупности средний процент сахаристости лежит в пределах от 18,23% до 18,41%.
5. Доля продукции высшего сорта в выборочной совокупности
![]()
Предельная ошибка для
доли продукции высшего сорта
![]()
для вероятности 0,997 параметр t=3.0
![]()
Доверительный интервал для доли продукции высшего сорта
![]()
![]()
![]()
С вероятностью 0,997 можно утверждать, что в генеральной
совокупности доля продукции высшего сорта лежит в пределах от 14,0% до 26,0%.