Расхождения
между величиной какого-либо показателя,
найденного посредством статистического
наблюдения, и действительными его
размерами называются ошибками
наблюдения.В зависимости от
причин возникновения различают ошибки
регистрации и ошибки репрезентативности.
Ошибки
регистрациивозникают в результате
неправильного установления фактов или
ошибочной записи в процессе наблюдения
или опроса. Они бывают случайными или
систематическими. Случайные ошибки
регистрации могут быть допущены как
опрашиваемыми в их ответах, так и
регистраторами. Систематические ошибки
могут быть и преднамеренными, и
непреднамеренными. Преднамеренные –
сознательные, тенденциозные искажения
действительного положения дела.
Непреднамеренные вызываются различными
случайными причинами (небрежность,
невнимательность).
Ошибки
репрезентативности(представительности)
возникают в результате неполного
обследования и в случае, если обследуемая
совокупность недостаточно полно
воспроизводит генеральную совокупность.
Они могут быть случайными и систематическими.
Случайные ошибки репрезентативности
– это отклонения, возникающие при
несплошном наблюдении из-за того, что
совокупность отобранных единиц наблюдения
(выборка) неполно воспроизводит всю
совокупность в целом. Систематические
ошибки репрезентативности – это
отклонения, возникающие вследствие
нарушения принципов случайного отбора
единиц. Ошибки репрезентативности
органически присущи выборочному
наблюдению и возникают в силу того, что
выборочная совокупность не полностью
воспроизводит генеральную. Избежать
ошибок репрезентативности нельзя,
однако, пользуясь методами теории
вероятностей, основанными на использовании
предельных теорем закона больших чисел,
эти ошибки можно свести к минимальным
значениям, границы которых устанавливаются
с достаточно большой точностью.
Ошибки
выборки –разность между
характеристиками выборочной и генеральной
совокупности. Для среднего значения
ошибка будет определяться по формуле
![]()
(7.1)
где
![]()
Величина
![]() называетсяпредельной ошибкойвыборки.
называетсяпредельной ошибкойвыборки.
Предельная
ошибка выборки – величина случайная.
Исследованию закономерностей случайных
ошибок выборки посвящены предельные
теоремы закона больших чисел. Наиболее
полно эти закономерности раскрыты в
теоремах П. Л. Чебышева и А. М. Ляпунова.
Теорему П.
Л. Чебышева применительно к
рассматриваемому методу можно
сформулировать следующим образом: при
достаточно большом числе независимых
наблюдений можно с вероятностью, близкой
к единице (т. е. почти с достоверностью),
утверждать, что отклонение выборочной
средней от генеральной будет сколько
угодно малым. В теореме П. Л. Чебышева
доказано, что величина ошибки не должна
превышать![]() .
.
В свою очередь величина![]() ,
,
выражающая среднее квадратическое
отклонение выборочной средней от
генеральной средней, зависит от
колеблемости признака в генеральной
совокупности![]() и числа отобранных единицn. Эта
и числа отобранных единицn. Эта
зависимость выражается формулой
![]() ,
,
(7.2)
где
![]() зависит также от способа производства
зависит также от способа производства
выборки.
Величину
![]() =
=![]() называютсредней ошибкой выборки. В
называютсредней ошибкой выборки. В
этом выражении![]() – генеральная дисперсия,n– объем
– генеральная дисперсия,n– объем
выборочной совокупности.
Рассмотрим, как
влияет на величину средней ошибки число
отбираемых единиц n. Логически
нетрудно убедиться, что при отборе
большого числа единиц расхождения между
средними будут меньше, т. е. существует
обратная связь между средней ошибкой
выборки и числом отобранных единиц. При
этом здесь образуется не просто обратная
математическая зависимость, а такая
зависимость, которая показывает, что
квадрат расхождения между средними
обратно пропорционален числу отобранных
единиц.
Увеличение
колеблемости признака влечет за собой
увеличение среднего квадратического
отклонения, а следовательно, и ошибки.
Если предположить, что все единицы будут
иметь одинаковую величину признака, то
среднее квадратическое отклонение
станет равно нулю и ошибка выборки
также исчезнет. Тогда нет необходимости
применять выборку. Однако следует иметь
в виду, что величина колеблемости
признака в генеральной совокупности
неизвестна, поскольку неизвестны размеры
единиц в ней. Можно рассчитать лишь
колеблемость признака в выборочной
совокупности. Соотношение между
дисперсиями генеральной и выборочной
совокупности выражается формулой
![]()
Поскольку
величина
![]() при достаточно большихnблизка к
при достаточно большихnблизка к
единице, можно приближенно считать, что
выборочная дисперсия равна генеральной
дисперсии, т. е.![]()
Следовательно,
средняя ошибка выборки показывает,
какие возможны отклонения характеристик
выборочной совокупности от соответствующих
характеристик генеральной совокупности.
Однако о величине этой ошибки можно
судить с определенной вероятностью. На
величину вероятности указывает множитель
![]()
Теорема А.
М. Ляпунова. А. М. Ляпунов доказал,
что распределение выборочных средних
(следовательно, и их отклонений от
генеральной средней) при достаточно
большом числе независимых наблюдений
приближенно нормально при условии, что
генеральная совокупность обладает
конечной средней и ограниченной
дисперсией.
Математически
теорему Ляпуноваможно записать
так:
 (7.3)
(7.3)
где
![]() ,
,
(7.4)
где ![]() – математическая постоянная;
– математическая постоянная;
![]() –предельная ошибка выборки,которая дает возможность выяснить, в
–предельная ошибка выборки,которая дает возможность выяснить, в
каких пределах находится величина
генеральной средней.
Значения этого
интеграла для различных значений
коэффициента доверия tвычислены и
приводятся в специальных математических
таблицах. В частности, при:

Поскольку tуказывает на вероятность расхождения![]() ,
,
т. е. на вероятность того, на какую
величину генеральная средняя будет
отличаться от выборочной средней, то
это может быть прочитано так: с вероятностью
0,683 можно утверждать, что разность между
выборочной и генеральной средними не
превышает одной величины средней ошибки
выборки. Другими словами, в 68,3 % случаев
ошибка репрезентативности не выйдет
за пределы![]() С вероятностью 0,954 можно утверждать,
С вероятностью 0,954 можно утверждать,
что ошибка репрезентативности не
превышает![]() (т. е. в 95 % случаев). С вероятностью
(т. е. в 95 % случаев). С вероятностью
0,997, т. е. довольно близкой к единице,
можно ожидать, что разность между
выборочной и генеральной средней не
превзойдет трехкратной средней ошибки
выборки и т. д.
Логически связь
здесь выглядит довольно ясно: чем больше
пределы, в которых допускается
возможная ошибка, тем с большей
вероятностью судят о ее величине.
Зная выборочную
среднюю величину признака
![]() и предельную ошибку выборки
и предельную ошибку выборки![]() ,
,
можно определить границы (пределы),
в которых заключена генеральная
средняя
![]() (7.5)
(7.5)
1.
Собственно-случайная выборка–
этот способ ориентирован на выборку
единиц из генеральной совокупности без
всякого расчленения на части или группы.
При этом для соблюдения основного
принципа выборки – равной возможности
всем единицам генеральной совокупности
быть отобранным – используются схема
случайного извлечения единиц путем
жеребьевки (лотереи) или таблицы случайных
чисел. Возможен повторный и бесповторный
отбор единиц
Средняя ошибка
собственно-случайной выборки
представляет собой среднеквадратическое
отклонение возможных значений выборочной
средней от генеральной средней. Средние
ошибки выборки при собственно-случайном
методе отбора представлены в табл. 7.2.
Таблица 7.2
|
Средняя ошибка |
При отборе |
|
|
повторном |
бесповторном |
|
|
Для средней |
|
|
|
Для доли |
|
|

В таблице
использованы следующие обозначения:
![]() – дисперсия выборочной совокупности;
– дисперсия выборочной совокупности;
![]() – численность выборки;
– численность выборки;
![]() – численность генеральной совокупности;
– численность генеральной совокупности;
![]() – выборочная доля единиц, обладающих
– выборочная доля единиц, обладающих
изучаемым признаком;
![]() – число единиц, обладающих изучаемым
– число единиц, обладающих изучаемым
признаком;
![]() – численность выборки.
– численность выборки.
Для увеличения
точности вместо множителя
![]() следует
следует
брать множитель
![]() ,
,
но при большой численностиNразличие
между этими выражениями практического
значения не имеет.
Предельная
ошибка собственно-случайной выборки
![]() рассчитывается по формуле
рассчитывается по формуле
![]() ,
,
(7.6)
где t
– коэффициент доверия зависит от
значения вероятности.
Пример.При
обследовании ста образцов изделий,
отобранных из партии в случайном порядке,
20 оказалось нестандартными. С вероятностью
0,954 определите пределы, в которых
находится доля нестандартной продукции
в партии.
Решение.
Вычислим генеральную долю (Р):
![]() .
.
Доля нестандартной
продукции:
 .
.
Предельная
ошибка выборочной доли с вероятностью
0,954 рассчитывается по формуле (7.6) с
применением формулы табл. 7.2 для доли:

![]()
С вероятностью
0,954 можно утверждать, что доля нестандартной
продукции в партии товара находится в
пределах 12 % ≤ P≤ 28 %.
В практике
проектирования выборочного наблюдения
возникает потребность определения
численности выборки, которая необходима
для обеспечения определенной точности
расчета генеральных средних. Предельная
ошибка выборки и ее вероятность при
этом являются заданными. Из формулы
![]() и формул средних ошибок выборки
и формул средних ошибок выборки
устанавливается необходимая численность
выборки. Формулы для определения
численности выборки (n) зависят от
способа отбора. Расчет численности
выборки для собственно-случайной выборки
приведен в табл. 7.3.
Таблица 7.3
|
Предполагаемый |
Формулы |
|
|
для средней |
для доли |
|
|
Повторный |
|
|
|
Бесповторный |
|
|



2.
Механическая выборка– при этом
методе исходят из учета некоторых
особенностей расположения объектов в
генеральной совокупности, их упорядоченности
(по списку, номеру, алфавиту). Механическая
выборка осуществляется путем отбора
отдельных объектов генеральной
совокупности через определенный интервал
(каждый 10-й или 20-й). Интервал рассчитывается
по отношению![]() ,
,
гдеn– численность выборки,N–
численность генеральной совокупности.
Так, если из совокупности в 500 000 единиц
предполагается получить 2 %-ную выборку,
т. е. отобрать 10 000
единиц, то пропорция отбора составит![]() Отбор
Отбор
единиц осуществляется в соответствии
с установленной пропорцией через равные
интервалы. Если расположение объектов
в генеральной совокупности носит
случайный характер, то механическая
выборка по содержанию аналогична
случайному отбору. При механическом
отборе применяется только бесповторная
выборка [1, 5–10].
Средняя ошибка
и численность выборки при механическом
отборе подсчитывается по формулам
собственно-случайной выборки (см.
табл. 7.2 и 7.3).
3.
Типическая выборка, при котрой
генеральная совокупность делится по
некоторым существенным признакам на
типические группы; отбор единиц
производится из типических групп. При
этом способе отбора генеральная
совокупность расчленяется на однородные
в некотором отношении группы, которые
имеют свои характеристики, и вопрос
сводится к определению объема выборок
из каждой группы. Может бытьравномерная
выборка– при этом способе из каждой
типической группы отбирается одинаковое
число единиц![]() Такой подход оправдан лишь при равенстве
Такой подход оправдан лишь при равенстве
численностей исходных типических групп.
При типическом отборе, непропорциональном
объему групп, общее число отбираемых
единиц делится на число типических
групп, полученная величина дает
численность отбора из каждой типической
группы.
Более совершенной
формой отбора является пропорциональная
выборка. Пропорциональной называется
такая схема формирования выборочной
совокупности, когда численность выборок,
взятых из каждой типической группы в
генеральной совокупности, пропорциональна
численностям, дисперсиям (или комбинированно
и численностям, и дисперсиям). Условно
определяем численность выборки в 100
единиц и отбираем единицы из групп:
– пропорционально
численности их генеральной совокупности
(табл. 7.4). В таблице
обозначено:
Ni– численность типической группы;
dj
– доля (Ni/N);
N– численность
генеральной совокупности;
ni– численность выборки из типической
группы вычисляется:
![]() , (7.7)
, (7.7)
n – численность выборки из генеральной
совокупности.
Таблица
7.4
-
Группы
Ni
dj
ni
1
300
0,3
30
2
500
0,5
50
3
200
0,2
20
1000
1,0
100
–
пропорционально среднему квадратическому
отклонению(табл. 7.5).
здесь
i– среднее
квадратическое отклонение типических
групп;
ni
– численность выборки из типической
группы вычисляется по формуле

(7.8)
Таблица
7.5
-
Ni
i

ni
300
5
0,25
25
500
7
0,35
35
200
8
0,40
40
1000
20
1,0
100
–
комбинированно (табл. 7.6).
Численность
выборки вычисляется по формуле
![]() . (7.9)
. (7.9)
Таблица 7.6
-

i
iNi


300
5
1500
0,23
23
500
7
2100
0,53
53
200
8
1600
0.24
24
1000
20
6600
1,0
100
При проведении
типической выборки непосредственный
отбор из каждой группы проводится
методом случайного отбора.
Средние ошибки
выборки рассчитываются по формулам
табл. 7.7 в зависимости от способа отбора
из типических групп.
Таблица 7.7
|
Способ |
Повторный |
Бесповторный |
||
|
для |
для |
для |
для |
|
|
Непропорциональный |
|
|
|
|
|
Пропорциональный объему групп |
|
|
|
|
|
Пропорциональный |
|
|
|
|





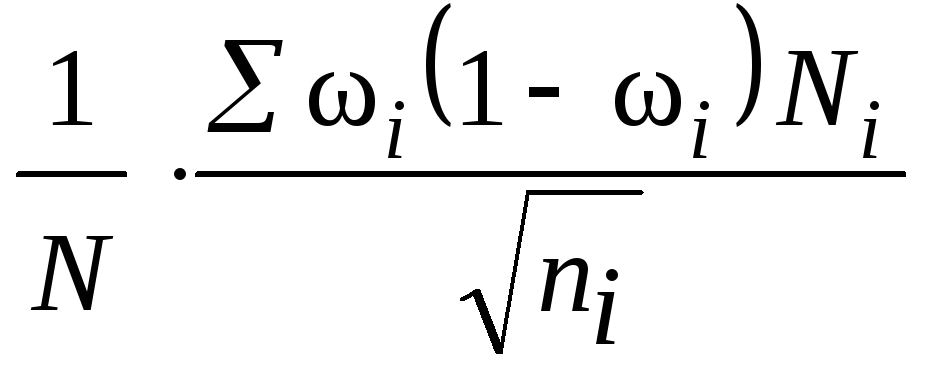


здесь
![]() – средняя из внутригрупповых дисперсий
– средняя из внутригрупповых дисперсий
типических групп;
![]() – доля единиц, обладающих изучаемым
– доля единиц, обладающих изучаемым
признаком;
![]() – средняя из внутригрупповых дисперсий
– средняя из внутригрупповых дисперсий
для доли;
![]() – среднее квадратическое отклонение
– среднее квадратическое отклонение
в выборке изi-й типической группы;
![]() – объем выборки из типической группы;
– объем выборки из типической группы;
![]() – общий объем выборки;
– общий объем выборки;
![]() –
–
объем типической группы;
![]() – объем генеральной совокупности.
– объем генеральной совокупности.
Численность
выборки из каждой типической группы
должна быть пропорциональна среднему
квадратическому отклонению в этой
группе
![]() .Расчет численности
.Расчет численности
![]() производится по формулам, приведенным
производится по формулам, приведенным
в табл. 7.8.
Таблица 7.8
|
Повторный |
Бесповторный |
|
|
Для определения |
|
|
|
Для определения |
|
|
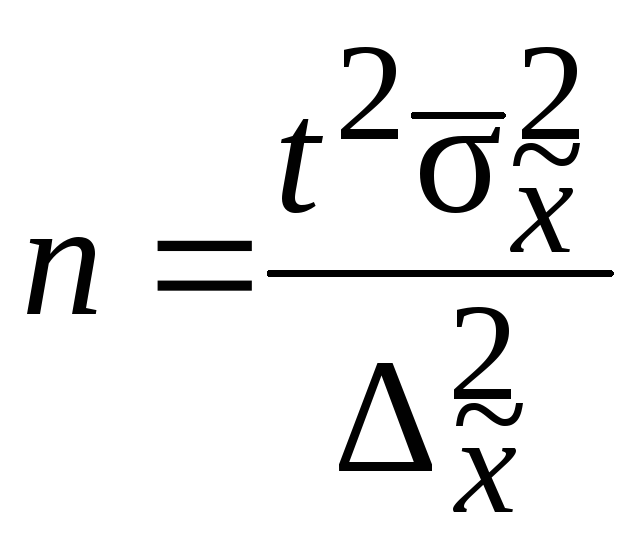

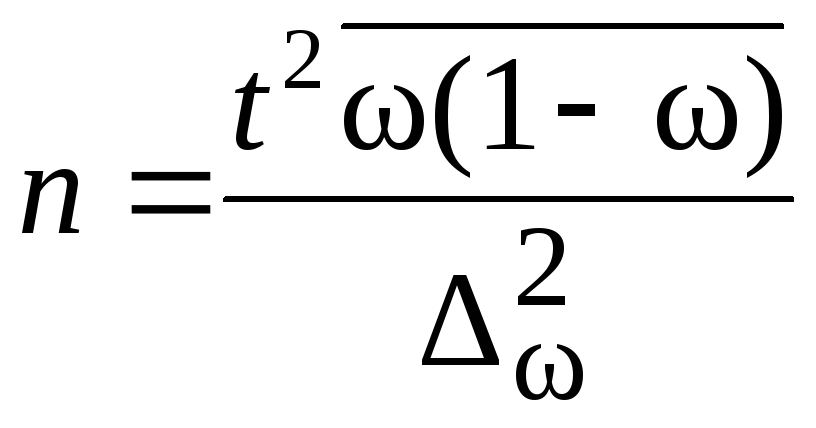

4. Серийная
выборка– удобена в тех случаях,
когда единицы совокупности объединены
в небольшие группы или серии. При серийной
выборке генеральную совокупность делят
на одинаковые по объему группы – серии.
В выборочную совокупность отбираются
серии. Сущность серийной выборки
заключается в случайном или механическом
отборе серий, внутри которых производится
сплошное обследование единиц. Средняя
ошибка серийной выборки с равновеликими
сериями зависит от величины только
межгрупповой дисперсии. Средние ошибки
сведены в табл. 7.9.
Таблица 7.9
|
Способ |
Формулы |
|
|
для |
для |
|
|
Повторный |
|
|
|
Бесповторный |
|
|


Здесь
R– число серий в генеральной
совокупности;
r – число
отобранных серий;
![]() – межсерийная (межгрупповая) дисперсия
– межсерийная (межгрупповая) дисперсия
средних;
![]() – межсерийная (межгрупповая) дисперсия
– межсерийная (межгрупповая) дисперсия
доли.
При серийном
отборе необходимую численность отбираемых
серий определяют так же, как и при
собственно-случайном методе отбора.
Расчет численности
серийной выборки производится по
формулам, приведенным в табл. 7.10.
Таблица 7.10
|
Повторный |
Бесповторный |
|
|
Для |
|
|
|
Для |
|
|
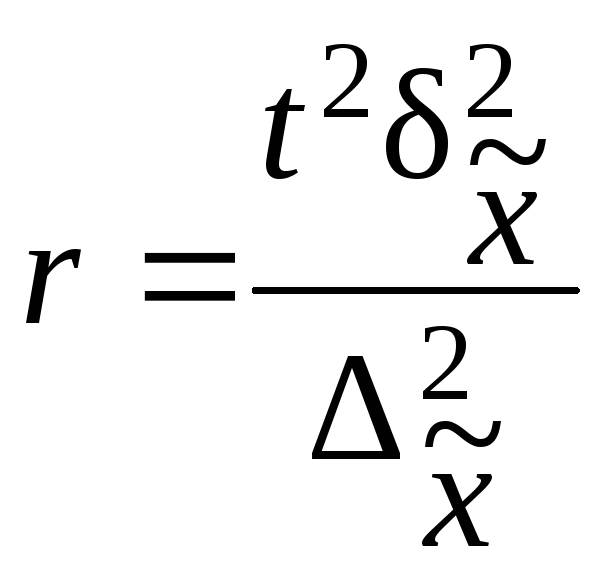

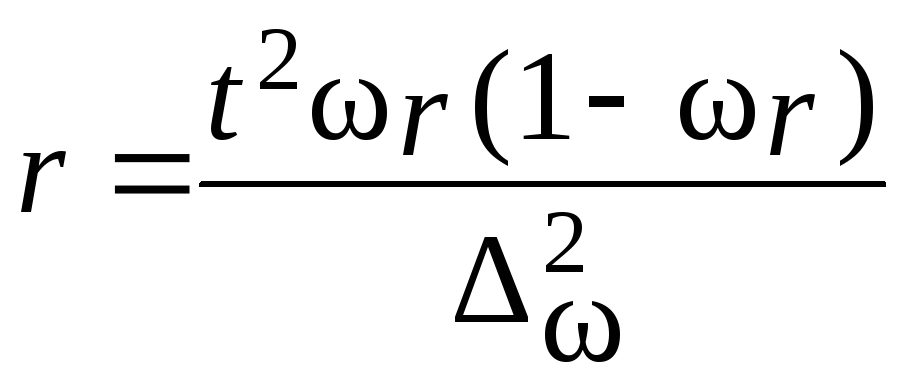

Пример.В
механическом цехе завода в десяти
бригадах работает 100 рабочих. В целях
изучения квалификации рабочих была
произведена 20 %-ная серийная бесповторная
выборка, в которую вошли две бригады.
Получено следующее распределение
обследованных рабочих по разрядам:
|
Рабочие |
Разряды рабочих |
Разряды рабочих |
Рабочие |
Разряды |
Разряды |
|
1 2 3 4 5 |
2 4 5 2 5 |
3 6 1 5 3 |
6 7 8 9 10 |
6 5 8 4 5 |
4 2 1 3 2 |
Необходимо
определить с вероятностью 0,997 пределы,
в которых находится средний разряд
рабочих механического цеха.
Решение.
Определим выборочные средние по
бригадам и общую среднюю как среднюю
взвешенную из групповых средних:

Определим
межсерийную дисперсию по формулам
(5.25):
![]()
Рассчитаем
среднюю ошибку выборки по формуле табл.
7.9:
![]()
Вычислим
предельную ошибку выборки с вероятностью
0,997:
![]()
С вероятностью
0,997 можно утверждать, что средний разряд
рабочих механического цеха находится
в пределах
![]()
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
From Wikipedia, the free encyclopedia
In statistics, sampling errors are incurred when the statistical characteristics of a population are estimated from a subset, or sample, of that population. It can produce biased results. Since the sample does not include all members of the population, statistics of the sample (often known as estimators), such as means and quartiles, generally differ from the statistics of the entire population (known as parameters). The difference between the sample statistic and population parameter is considered the sampling error.[1] For example, if one measures the height of a thousand individuals from a population of one million, the average height of the thousand is typically not the same as the average height of all one million people in the country.
Since sampling is almost always done to estimate population parameters that are unknown, by definition exact measurement of the sampling errors will not be possible; however they can often be estimated, either by general methods such as bootstrapping, or by specific methods incorporating some assumptions (or guesses) regarding the true population distribution and parameters thereof.
Description[edit]
Sampling Error[edit]
The sampling error is the error caused by observing a sample instead of the whole population.[1] The sampling error is the difference between a sample statistic used to estimate a population parameter and the actual but unknown value of the parameter.[2]
Effective Sampling[edit]
In statistics, a truly random sample means selecting individuals from a population with an equivalent probability; in other words, picking individuals from a group without bias. Failing to do this correctly will result in a sampling bias, which can dramatically increase the sample error in a systematic way. For example, attempting to measure the average height of the entire human population of the Earth, but measuring a sample only from one country, could result in a large over- or under-estimation. In reality, obtaining an unbiased sample can be difficult as many parameters (in this example, country, age, gender, and so on) may strongly bias the estimator and it must be ensured that none of these factors play a part in the selection process.
Even in a perfectly non-biased sample, the sample error will still exist due to the remaining statistical component; consider that measuring only two or three individuals and taking the average would produce a wildly varying result each time. The likely size of the sampling error can generally be reduced by taking a larger sample.[3]
Sample Size Determination[edit]
The cost of increasing a sample size may be prohibitive in reality. Since the sample error can often be estimated beforehand as a function of the sample size, various methods of sample size determination are used to weigh the predicted accuracy of an estimator against the predicted cost of taking a larger sample.
Bootstrapping and Standard Error[edit]
As discussed, a sample statistic, such as an average or percentage, will generally be subject to sample-to-sample variation.[1] By comparing many samples, or splitting a larger sample up into smaller ones (potentially with overlap), the spread of the resulting sample statistics can be used to estimate the standard error on the sample.
In Genetics[edit]
The term «sampling error» has also been used in a related but fundamentally different sense in the field of genetics; for example in the bottleneck effect or founder effect, when natural disasters or migrations dramatically reduce the size of a population, resulting in a smaller population that may or may not fairly represent the original one. This is a source of genetic drift, as certain alleles become more or less common), and has been referred to as «sampling error»,[4] despite not being an «error» in the statistical sense.
See also[edit]
- Margin of error
- Propagation of uncertainty
- Ratio estimator
- Sampling (statistics)
References[edit]
- ^ a b c Sarndal, Swenson, and Wretman (1992), Model Assisted Survey Sampling, Springer-Verlag, ISBN 0-387-40620-4
- ^ Burns, N.; Grove, S. K. (2009). The Practice of Nursing Research: Appraisal, Synthesis, and Generation of Evidence (6th ed.). St. Louis, MO: Saunders Elsevier. ISBN 978-1-4557-0736-2.
- ^ Scheuren, Fritz (2005). «What is a Margin of Error?». What is a Survey? (PDF). Washington, D.C.: American Statistical Association. Archived from the original (PDF) on 2013-03-12. Retrieved 2008-01-08.
- ^ Campbell, Neil A.; Reece, Jane B. (2002). Biology. Benjamin Cummings. pp. 450–451. ISBN 0-536-68045-0.
-
Ошибка выборки
2.1. Понятие и виды ошибок выборки
Поскольку изучаемая статистическая
совокупность состоит из единиц с
варьирующими признаками, то состав
выборочной совокупности может в той
или иной мере отличаться от состава
генеральной совокупности.
Расхождение
между характеристиками выборки и
генеральной совокупности составляет
ошибку
выборки.
Виды ошибок выборки
|
Ошибки выборки |
Систематические |
Случайные |
|
Ошибки регистрации |
Обусловлены |
Проявляются |
|
Ошибки репрезентативности |
Неправильный, |
Несмотря |
Основная
задача выборочного метода – изучение
случайных ошибок репрезентативности.
2.2. Средняя ошибка выборки
Случайная ошибка
репрезентативности зависит от следующих
фактов (при этом считается, что ошибок
регистрации нет):
-
Чем
больше численность выборки при прочих
равных условиях, тем меньше величина
ошибки выборки, т.е. ошибка выборки
обратно пропорциональна ее численности. -
Чем
меньше варьирование признака, тем
меньше ошибка выборки. Если признак
совсем не варьирует, а, следовательно,
величина дисперсии равна нулю, то ошибки
выборки не будет, т.к. любая единица
совокупности будет совершенно точно
характеризовать всю совокупность по
этому признаку. Таким образом, ошибка
выборки прямо пропорциональна величине
дисперсии.
В
математической статистике доказывается,
что величина средней ошибки случайной
повторной выборки может быть определена
по формуле
![]()
(6.1)
Однако
следует иметь в виду, что величина
дисперсии в генеральной совокупности
2
нам не известна, т.к. наблюдение выборочное.
Мы можем рассчитать лишь дисперсию в
выборочной совокупности S2.
Соотношение между дисперсиями генеральной
и выборочной совокупности выражается
формулой:
![]()
(6.2)
Если
n
велико, следовательно
![]()
Таким
образом, можно приблизительно считать,
что выборочная дисперсия равна генеральной
дисперсии.
2 =
S2
И формула средней ошибки повторной
выборки (6.1.) примет вид:
![]()
(6.3)
Но
здесь мы рассмотрели только ошибку
выборки для средней величины интересующего
признака. Существует также показатель
доли единиц с интересующим признаком.
Расчет ошибки этого показателя имеет
свои особенности.
Дисперсия
для показателя доли признака определяется
по формуле:
S2=(1-)
(6.4)
Тогда средняя ошибка повтора выборки
для показателя доли признака будет
равна:
![]()
(6.5)
Доказательство
формул (6.3) и (6.5) исходит из схемы повторной
выборки. Обычно же выборку организуют
бесповторным способом. Т.к. при бесповторном
отборе численность генеральной
совокупности N
в коде выборки сокращается, то в формулы
ошибки выборки включают дополнительный
множитель
![]() ,
,
и формулы
принимают вид:
![]()
(6.6)
![]()
(6.7)
Пример
1. Определим, на сколько отличаются
выборочные и генеральные показатели
по данным 10%-ной бесповторной выборки
успеваемости студентов.
|
Оценка, |
Число |
|
2 |
9 |
|
3 |
27 |
|
4 |
54 |
|
5 |
10 |
|
Итого |
100 |
Расчет ошибки бесповторной выборки для
средней величины:
![]()
n
= 100 N
= 1000
Найдем выборочную
дисперсию по формуле:
![]()
Здесь
не известна величина
![]() ,
,
которую можно найти как обычную среднюю
взвешенную величину:
![]()
![]()
Таким
образом,
![]()
Т.е.
можно сказать, что средний балл всех
студентов (![]() )
)
равен 3,650,07
Теперь
рассчитаем долю студентов в генеральной
совокупности, обучающихся на «4» и «5».
Найдем по выборке
долю студентов, получивших оценки «4»
и «5».
![]() (или
(или
64%)
Расчет
ошибки бесповторной выборки для доли
производится по формуле:
![]()
![]() (или
(или
4,5%)
Таким образом, доля студентов, обучающихся
на «4» и «5» по генеральной совокупности
(P) составляет
0,640,045 (или 64%4,5%).
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
What Is a Sampling Error?
A sampling error is a statistical error that occurs when an analyst does not select a sample that represents the entire population of data. As a result, the results found in the sample do not represent the results that would be obtained from the entire population.
Sampling is an analysis performed by selecting a number of observations from a larger population. The method of selection can produce both sampling errors and non-sampling errors.
Key Takeaways
- A sampling error occurs when the sample used in the study is not representative of the whole population.
- Sampling is an analysis performed by selecting a number of observations from a larger population.
- Even randomized samples will have some degree of sampling error because a sample is only an approximation of the population from which it is drawn.
- The prevalence of sampling errors can be reduced by increasing the sample size.
- In general, sampling errors can be placed into four categories: population-specific error, selection error, sample frame error, or non-response error.
Understanding Sampling Errors
A sampling error is a deviation in the sampled value versus the true population value. Sampling errors occur because the sample is not representative of the population or is biased in some way. Even randomized samples will have some degree of sampling error because a sample is only an approximation of the population from which it is drawn.
Calculating Sampling Error
The sampling error formula is used to calculate the overall sampling error in statistical analysis. The sampling error is calculated by dividing the standard deviation of the population by the square root of the size of the sample, and then multiplying the resultant with the Z-score value, which is based on the confidence interval.
Sampling Error
=
Z
×
σ
n
where:
Z
=
Z
score value based on the
confidence interval (approx
=
1.96
)
σ
=
Population standard deviation
n
=
Size of the sample
begin{aligned}&text{Sampling Error}=Ztimesfrac{sigma}{sqrt{n}}&textbf{where:}&Z=Ztext{ score value based on the}&qquad text{confidence interval (approx}=1.96)&sigma=text{Population standard deviation}&n=text{Size of the sample}end{aligned}
Sampling Error=Z×nσwhere:Z=Z score value based on the confidence interval (approx=1.96)σ=Population standard deviationn=Size of the sample
Types of Sampling Errors
There are different categories of sampling errors.
Population-Specific Error
A population-specific error occurs when a researcher doesn’t understand who to survey.
Selection Error
Selection error occurs when the survey is self-selected, or when only those participants who are interested in the survey respond to the questions. Researchers can attempt to overcome selection error by finding ways to encourage participation.
Sample Frame Error
A sample frame error occurs when a sample is selected from the wrong population data.
Non-response Error
A non-response error occurs when a useful response is not obtained from the surveys because researchers were unable to contact potential respondents (or potential respondents refused to respond).
Eliminating Sampling Errors
The prevalence of sampling errors can be reduced by increasing the sample size. As the sample size increases, the sample gets closer to the actual population, which decreases the potential for deviations from the actual population. Consider that the average of a sample of 10 varies more than the average of a sample of 100. Steps can also be taken to ensure that the sample adequately represents the entire population.
Researchers might attempt to reduce sampling errors by replicating their study. This could be accomplished by taking the same measurements repeatedly, using more than one subject or multiple groups, or by undertaking multiple studies.
Random sampling is an additional way to minimize the occurrence of sampling errors. Random sampling establishes a systematic approach to selecting a sample. For example, rather than choosing participants to be interviewed haphazardly, a researcher might choose those whose names appear first, 10th, 20th, 30th, 40th, and so on, on the list.
Examples of Sampling Errors
Assume that XYZ Company provides a subscription-based service that allows consumers to pay a monthly fee to stream videos and other types of programming via an Internet connection.
The firm wants to survey homeowners who watch at least 10 hours of programming via the Internet per week and that pay for an existing video streaming service. XYZ wants to determine what percentage of the population is interested in a lower-priced subscription service. If XYZ does not think carefully about the sampling process, several types of sampling errors may occur.
A population specification error would occur if XYZ Company does not understand the specific types of consumers who should be included in the sample. For example, if XYZ creates a population of people between the ages of 15 and 25 years old, many of those consumers do not make the purchasing decision about a video streaming service because they may not work full-time. On the other hand, if XYZ put together a sample of working adults who make purchase decisions, the consumers in this group may not watch 10 hours of video programming each week.
Selection error also causes distortions in the results of a sample. A common example is a survey that only relies on a small portion of people who immediately respond. If XYZ makes an effort to follow up with consumers who don’t initially respond, the results of the survey may change. Furthermore, if XYZ excludes consumers who don’t respond right away, the sample results may not reflect the preferences of the entire population.
Sampling Error vs. Non-sampling Error
There are different types of errors that can occur when gathering statistical data. Sampling errors are the seemingly random differences between the characteristics of a sample population and those of the general population. Sampling errors arise because sample sizes are inevitably limited. (It is impossible to sample an entire population in a survey or a census.)
A sampling error can result even when no mistakes of any kind are made; sampling errors occur because no sample will ever perfectly match the data in the universe from which the sample is taken.
Company XYZ will also want to avoid non-sampling errors. Non-sampling errors are errors that result during data collection and cause the data to differ from the true values. Non-sampling errors are caused by human error, such as a mistake made in the survey process.
If one group of consumers only watches five hours of video programming a week and is included in the survey, that decision is a non-sampling error. Asking questions that are biased is another type of error.
What Is Sampling Error vs. Sampling Bias?
In statistics, sampling means selecting the group that you will actually collect data from in your research.
Sampling bias is the expectation, which is known in advance, that a sample won’t be representative of the true population. For instance, if the sample ends up having proportionally more women or young people than the overall population.
Sampling errors are statistical errors that arise when a sample does not represent the whole population once analyses have been undertaken.
Why Is Sampling Error Important?
Being aware of the presence of sampling errors is important because it can be an indicator of the level of confidence that can be placed in the results. Sampling error is also important in the context of a discussion about how much research results can vary.
How Do You Find the Sampling Error?
In survey research, sampling errors occur because all samples are representative samples: a smaller group that stands in for the whole of your research population. It’s impossible to survey the entire group of people you’d like to reach.
It’s not usually possible to quantify the degree of sampling error in a study since it’s impossible to collect the relevant data from the entire population you are studying. This is why researchers collect representative samples (and representative samples are the reason why there are sampling errors).
What Is Sampling Error vs. Standard Error?
Sampling error is derived from the standard error (SE) by multiplying it by a Z-score value to produce a confidence interval.
The standard error is computed by dividing the standard deviation by the square root of the sample size.
The Bottom Line
Sampling error occurs when a sample drawn from a population deviates somewhat from that true population. Large sampling errors can lead to incorrect estimates or inferences made about the population based on statistical analysis of that sample.
In general, sampling errors can be placed into four categories: population-specific error, selection error, sample frame error, or non-response error. A population-specific error occurs when the researcher does not understand who they should survey. A selection error occurs when respondents self-select their participation in the study. (This results in only those that are interested in responding, which skews the results.) A sample frame error occurs when the wrong sub-population is used to select a sample. Finally, a non-response error occurs when potential respondents are not successfully contacted or refuse to respond.
What Is a Sampling Error?
A sampling error is a statistical error that occurs when an analyst does not select a sample that represents the entire population of data. As a result, the results found in the sample do not represent the results that would be obtained from the entire population.
Sampling is an analysis performed by selecting a number of observations from a larger population. The method of selection can produce both sampling errors and non-sampling errors.
Key Takeaways
- A sampling error occurs when the sample used in the study is not representative of the whole population.
- Sampling is an analysis performed by selecting a number of observations from a larger population.
- Even randomized samples will have some degree of sampling error because a sample is only an approximation of the population from which it is drawn.
- The prevalence of sampling errors can be reduced by increasing the sample size.
- In general, sampling errors can be placed into four categories: population-specific error, selection error, sample frame error, or non-response error.
Understanding Sampling Errors
A sampling error is a deviation in the sampled value versus the true population value. Sampling errors occur because the sample is not representative of the population or is biased in some way. Even randomized samples will have some degree of sampling error because a sample is only an approximation of the population from which it is drawn.
Calculating Sampling Error
The sampling error formula is used to calculate the overall sampling error in statistical analysis. The sampling error is calculated by dividing the standard deviation of the population by the square root of the size of the sample, and then multiplying the resultant with the Z-score value, which is based on the confidence interval.
Sampling Error
=
Z
×
σ
n
where:
Z
=
Z
score value based on the
confidence interval (approx
=
1.96
)
σ
=
Population standard deviation
n
=
Size of the sample
begin{aligned}&text{Sampling Error}=Ztimesfrac{sigma}{sqrt{n}}&textbf{where:}&Z=Ztext{ score value based on the}&qquad text{confidence interval (approx}=1.96)&sigma=text{Population standard deviation}&n=text{Size of the sample}end{aligned}
Sampling Error=Z×nσwhere:Z=Z score value based on the confidence interval (approx=1.96)σ=Population standard deviationn=Size of the sample
Types of Sampling Errors
There are different categories of sampling errors.
Population-Specific Error
A population-specific error occurs when a researcher doesn’t understand who to survey.
Selection Error
Selection error occurs when the survey is self-selected, or when only those participants who are interested in the survey respond to the questions. Researchers can attempt to overcome selection error by finding ways to encourage participation.
Sample Frame Error
A sample frame error occurs when a sample is selected from the wrong population data.
Non-response Error
A non-response error occurs when a useful response is not obtained from the surveys because researchers were unable to contact potential respondents (or potential respondents refused to respond).
Eliminating Sampling Errors
The prevalence of sampling errors can be reduced by increasing the sample size. As the sample size increases, the sample gets closer to the actual population, which decreases the potential for deviations from the actual population. Consider that the average of a sample of 10 varies more than the average of a sample of 100. Steps can also be taken to ensure that the sample adequately represents the entire population.
Researchers might attempt to reduce sampling errors by replicating their study. This could be accomplished by taking the same measurements repeatedly, using more than one subject or multiple groups, or by undertaking multiple studies.
Random sampling is an additional way to minimize the occurrence of sampling errors. Random sampling establishes a systematic approach to selecting a sample. For example, rather than choosing participants to be interviewed haphazardly, a researcher might choose those whose names appear first, 10th, 20th, 30th, 40th, and so on, on the list.
Examples of Sampling Errors
Assume that XYZ Company provides a subscription-based service that allows consumers to pay a monthly fee to stream videos and other types of programming via an Internet connection.
The firm wants to survey homeowners who watch at least 10 hours of programming via the Internet per week and that pay for an existing video streaming service. XYZ wants to determine what percentage of the population is interested in a lower-priced subscription service. If XYZ does not think carefully about the sampling process, several types of sampling errors may occur.
A population specification error would occur if XYZ Company does not understand the specific types of consumers who should be included in the sample. For example, if XYZ creates a population of people between the ages of 15 and 25 years old, many of those consumers do not make the purchasing decision about a video streaming service because they may not work full-time. On the other hand, if XYZ put together a sample of working adults who make purchase decisions, the consumers in this group may not watch 10 hours of video programming each week.
Selection error also causes distortions in the results of a sample. A common example is a survey that only relies on a small portion of people who immediately respond. If XYZ makes an effort to follow up with consumers who don’t initially respond, the results of the survey may change. Furthermore, if XYZ excludes consumers who don’t respond right away, the sample results may not reflect the preferences of the entire population.
Sampling Error vs. Non-sampling Error
There are different types of errors that can occur when gathering statistical data. Sampling errors are the seemingly random differences between the characteristics of a sample population and those of the general population. Sampling errors arise because sample sizes are inevitably limited. (It is impossible to sample an entire population in a survey or a census.)
A sampling error can result even when no mistakes of any kind are made; sampling errors occur because no sample will ever perfectly match the data in the universe from which the sample is taken.
Company XYZ will also want to avoid non-sampling errors. Non-sampling errors are errors that result during data collection and cause the data to differ from the true values. Non-sampling errors are caused by human error, such as a mistake made in the survey process.
If one group of consumers only watches five hours of video programming a week and is included in the survey, that decision is a non-sampling error. Asking questions that are biased is another type of error.
What Is Sampling Error vs. Sampling Bias?
In statistics, sampling means selecting the group that you will actually collect data from in your research.
Sampling bias is the expectation, which is known in advance, that a sample won’t be representative of the true population. For instance, if the sample ends up having proportionally more women or young people than the overall population.
Sampling errors are statistical errors that arise when a sample does not represent the whole population once analyses have been undertaken.
Why Is Sampling Error Important?
Being aware of the presence of sampling errors is important because it can be an indicator of the level of confidence that can be placed in the results. Sampling error is also important in the context of a discussion about how much research results can vary.
How Do You Find the Sampling Error?
In survey research, sampling errors occur because all samples are representative samples: a smaller group that stands in for the whole of your research population. It’s impossible to survey the entire group of people you’d like to reach.
It’s not usually possible to quantify the degree of sampling error in a study since it’s impossible to collect the relevant data from the entire population you are studying. This is why researchers collect representative samples (and representative samples are the reason why there are sampling errors).
What Is Sampling Error vs. Standard Error?
Sampling error is derived from the standard error (SE) by multiplying it by a Z-score value to produce a confidence interval.
The standard error is computed by dividing the standard deviation by the square root of the sample size.
The Bottom Line
Sampling error occurs when a sample drawn from a population deviates somewhat from that true population. Large sampling errors can lead to incorrect estimates or inferences made about the population based on statistical analysis of that sample.
In general, sampling errors can be placed into four categories: population-specific error, selection error, sample frame error, or non-response error. A population-specific error occurs when the researcher does not understand who they should survey. A selection error occurs when respondents self-select their participation in the study. (This results in only those that are interested in responding, which skews the results.) A sample frame error occurs when the wrong sub-population is used to select a sample. Finally, a non-response error occurs when potential respondents are not successfully contacted or refuse to respond.
From Wikipedia, the free encyclopedia
In statistics, sampling errors are incurred when the statistical characteristics of a population are estimated from a subset, or sample, of that population. Since the sample does not include all members of the population, statistics of the sample (often known as estimators), such as means and quartiles, generally differ from the statistics of the entire population (known as parameters). The difference between the sample statistic and population parameter is considered the sampling error.[1] For example, if one measures the height of a thousand individuals from a population of one million, the average height of the thousand is typically not the same as the average height of all one million people in the country.
Since sampling is almost always done to estimate population parameters that are unknown, by definition exact measurement of the sampling errors will not be possible; however they can often be estimated, either by general methods such as bootstrapping, or by specific methods incorporating some assumptions (or guesses) regarding the true population distribution and parameters thereof.
Description[edit]
Sampling Error[edit]
The sampling error is the error caused by observing a sample instead of the whole population.[1] The sampling error is the difference between a sample statistic used to estimate a population parameter and the actual but unknown value of the parameter.[2]
Effective Sampling[edit]
In statistics, a truly random sample means selecting individuals from a population with an equivalent probability; in other words, picking individuals from a group without bias. Failing to do this correctly will result in a sampling bias, which can dramatically increase the sample error in a systematic way. For example, attempting to measure the average height of the entire human population of the Earth, but measuring a sample only from one country, could result in a large over- or under-estimation. In reality, obtaining an unbiased sample can be difficult as many parameters (in this example, country, age, gender, and so on) may strongly bias the estimator and it must be ensured that none of these factors play a part in the selection process.
Even in a perfectly non-biased sample, the sample error will still exist due to the remaining statistical component; consider that measuring only two or three individuals and taking the average would produce a wildly varying result each time. The likely size of the sampling error can generally be reduced by taking a larger sample.[3]
Sample Size Determination[edit]
The cost of increasing a sample size may be prohibitive in reality. Since the sample error can often be estimated beforehand as a function of the sample size, various methods of sample size determination are used to weigh the predicted accuracy of an estimator against the predicted cost of taking a larger sample.
Bootstrapping and Standard Error[edit]
As discussed, a sample statistic, such as an average or percentage, will generally be subject to sample-to-sample variation.[1] By comparing many samples, or splitting a larger sample up into smaller ones (potentially with overlap), the spread of the resulting sample statistics can be used to estimate the standard error on the sample.
In Genetics[edit]
The term «sampling error» has also been used in a related but fundamentally different sense in the field of genetics; for example in the bottleneck effect or founder effect, when natural disasters or migrations dramatically reduce the size of a population, resulting in a smaller population that may or may not fairly represent the original one. This is a source of genetic drift, as certain alleles become more or less common), and has been referred to as «sampling error»,[4] despite not being an «error» in the statistical sense.
See also[edit]
- Margin of error
- Propagation of uncertainty
- Ratio estimator
- Sampling (statistics)
References[edit]
- ^ a b c Sarndal, Swenson, and Wretman (1992), Model Assisted Survey Sampling, Springer-Verlag, ISBN 0-387-40620-4
- ^ Burns, N.; Grove, S. K. (2009). The Practice of Nursing Research: Appraisal, Synthesis, and Generation of Evidence (6th ed.). St. Louis, MO: Saunders Elsevier. ISBN 978-1-4557-0736-2.
- ^ Scheuren, Fritz (2005). «What is a Margin of Error?». What is a Survey? (PDF). Washington, D.C.: American Statistical Association. Archived from the original (PDF) on 2013-03-12. Retrieved 2008-01-08.
- ^ Campbell, Neil A.; Reece, Jane B. (2002). Biology. Benjamin Cummings. pp. 450–451. ISBN 0-536-68045-0.
Как мы уже знаем, репрезентативность — свойство выборочной совокупности представлять характеристику генеральной. Если совпадения нет, говорят об ошибке репрезентативности — мере отклонения статистической структуры выборки от структуры соответствующей генеральной совокупности. Предположим, что средний ежемесячный семейный доход пенсионеров в генеральной совокупности составляет 2 тыс. руб., а в выборочной — 6 тыс. руб. Это означает, что социолог опрашивал только зажиточную часть пенсионеров, а в его исследование вкралась ошибка репрезентативности. Иными словами, ошибкой репрезентативности называется расхождение между двумя совокупностями — генеральной, на которую направлен теоретический интерес социолога и представление о свойствах которой он хочет получить в конечном итоге, и выборочной, на которую направлен практический интерес социолога, которая выступает одновременно как объект обследования и средство получения информации о генеральной совокупности.
Наряду с термином «ошибка репрезентативности» в отечественной литературе можно встретить другой — «ошибка выборки». Иногда они употребляются как синонимы, а иногда «ошибка выборки» используется вместо «ошибки репрезентативности» как количественно более точное понятие.
Ошибка выборки — отклонение средних характеристик выборочной совокупности от средних характеристик генеральной совокупности.
На практике ошибка выборки определяется путем сравнения известных характеристик генеральной совокупности с выборочными средними. В социологии при обследованиях взрослого населения чаще всего используют данные переписей населения, текущего статистического учета, результаты предшествующих опросов. В качестве контрольных параметров обычно применяются социально-демографические признаки. Сравнение средних генеральной и выборочной совокупностей, на основе этого определение ошибки выборки и ее уменьшение называется контролированием репрезентативности. Поскольку сравнение своих и чужих данных можно сделать по завершении исследования, такой способ контроля называется апостериорным, т.е. осуществляемым после опыта.
В опросах Института Дж. Гэллапа репрезентативность контролируется по имеющимся в национальных переписях данным о распределении населения по полу, возрасту, образованию, доходу, профессии, расовой принадлежности, месту проживания, величине населенного пункта. Всероссийский центр изучения общественного мнения (ВЦИОМ) использует для подобных целей такие показатели, как пол, возраст, образование, тип поселения, семейное положение, сфера занятости, должностной статус респондента, которые заимствуются в Государственном комитете по статистике РФ. В том и другом случае генеральная совокупность известна. Ошибку выборки невозможно установить, если неизвестны значения переменной в выборочной и генеральной совокупностях.
Специалисты ВЦИОМ обеспечивают при анализе данных тщательный ремонт выборки, чтобы минимизировать отклонения, возникшие на этапе полевых работ. Особенно сильные смещения наблюдаются по параметрам пола и возраста. Объясняется это тем, что женщины и люди с высшим образованием больше времени проводят дома и легче идут на контакт с интервьюером, т.е. являются легко достижимой группой по сравнению с мужчинами и людьми «необразованными»35.
Ошибка выборки обусловливается двумя факторами: методом формирования выборки и размером выборки.
Ошибки выборки подразделяются на два типа — случайные и систематические. Случайная ошибка — это вероятность того, что выборочная средняя выйдет (или не выйдет) за пределы заданного интервала. К случайным ошибкам относят статистические погрешности, присущие самому выборочному методу. Они уменьшаются при возрастании объема выборочной совокупности.
Второй тип ошибок выборки — систематические ошибки. Если социолог решил узнать мнение всех жителей города о проводимой местными органами власти социальной политике, а опросил только тех, у кого есть телефон, то возникает предумышленное смещение выборки в пользу зажиточных слоев, т.е. систематическая ошибка.
Таким образом, систематические ошибки — результат деятельности самого исследователя. Они наиболее опасны, поскольку приводят к довольно значительным смещениям результатов исследования. Систематические ошибки считаются страшнее случайных еще и потому, что они не поддаются контролю и измерению.
Они возникают, когда, например:
- выборка не соответствует задачам исследования (социолог решил изучить только работающих пенсионеров, а опросил всех подряд);
- налицо незнание характера генеральной совокупности (социолог думал, что 70% всех пенсионеров не работает, а оказалось, что не работает только 10%);
- отбираются только «выигрышные» элементы генеральной совокупности (например, только обеспеченные пенсионеры).
Внимание! В отличие от случайных ошибок систематические ошибки при возрастании объема выборки не уменьшаются.
Обобщив все случаи, когда происходят систематические ошибки, методисты составили их реестр. Они полагают, что источником неконтролируемых перекосов в распределении выборочных наблюдений могут быть следующие факторы:
- нарушены методические и методологические правила проведения социологического исследования;
- выбраны неадекватные способы формирования выборочной совокупности, методы сбора и расчета данных;
- произошла замена требуемых единиц наблюдения другими, более доступными;
- отмечен неполный охват выборочной совокупности (недополучение анкет, неполное их заполнение, труднодоступность единиц наблюдения).
Намеренные ошибки социолог допускает редко. Чаще ошибки возникают из-за того, что социологу плохо известна структура генеральной совокупности: распределение людей по возрасту, профессии, доходам и т.д.
Систематические ошибки легче предупредить (по сравнению со случайными), но их очень трудно устранить. Предупреждать систематические ошибки, точно предвидя их источники, лучше всего заранее — в самом начале исследования.
Вот некоторые способы избежать ошибок выборки:
- каждая единица генеральной совокупности должна иметь равную вероятность попасть в выборку;
- отбор желательно производить из однородных совокупностей;
- надо знать характеристики генеральной совокупности;
- при составлении выборочной совокупности надо учитывать случайные и систематические ошибки.
Если выборочная совокупность (или просто выборка) составлена правильно, то социолог получает надежные результаты, харастеризующие всю генеральную совокупность. Если она составлена неправильно, то ошибка, возникшая на этапе составления выборки, на каждом следующем этапе проведения социологического исследования приумножается и достигает в конечном счете такой величины, которая перевешивает ценность проведенного исследования. Говорят, что от такого исследования больше вреда, нежели пользы.
Подобные ошибки могут произойти только с выборочной совокупностыо. Чтобы избежать или уменьшить вероятность ошибки, самый простой способ — увеличивать размеры выборки (в идеале до объема генеральной: когда обе совокупности совпадут, ошибка выборки вообще исчезнет). Экономически такой метод невозможен. Остается другой путь — совершенствовать математические методы составления выборки. Они то и применяются на практике. Таков первый канал проникновения в социологию математики. Второй канал — математическая обработка данных.
Особенно важной проблема ошибок становится в маркетинговых исследованиях, где используются не очень большие выборки. Обычно они составляют несколько сотен, реже — тысячу респондентов. Здесь исходным пунктом расчета выборки выступает вопрос об определении размеров выборочной совокупности. Численность выборочной совокупности зависит от двух факторов:
- стоимости сбора информации,
- стремления к определенной степени статистической достоверности результатов, которую надеется получить исследователь.
Конечно, даже не искушенные в статистике и социологии люди интуитивно понимают, что чем больше размеры выборки, т.е. чем ближе они к размерам генеральной совокупности в целом, тем более надежны и достоверны полученные данные. Однако выше мы уже говорили о практической невозможности сплошных опросов в тех случаях, когда они проводятся на объектах, численность которых превышает десятки, сотни тысяч и даже миллионы. Понятно, что стоимость сбора информации (включающая оплату тиражирования инструментария, труда анкетеров, полевых менеджеров и операторов по компьютерному вводу) зависит от той суммы, которую готов выделить заказчик, и слабо зависит от исследователей. Что же касается второго фактора, то мы остановимся на нем чуть подробнее.
Итак, чем больше величина выборки, тем меньше возможная ошибка. Хотя необходимо отметить, что при желании увеличить точность вдвое вам придется увеличить выборку не в два, а в четыре раза. Например, чтобы сделать в два раза более точной оценку данных, полученных путем опроса 400 человек, вам потребуется опросить не 800, а 1600 человек. Впрочем, вряд ли маркетинговое исследование испытывает нужду в стопроцентной точности. Если пивовару необходимо узнать, какая часть потребителей пива предпочитает именно его марку, а не сорт его конкурента, — 60% или 40%, то на его планы никак не повлияет разница между 57%, 60 или 63%.
Ошибка выборки может зависеть не только от ее величины, но и от степени различий между отдельными единицами внутри генеральной совокупности, которую мы исследуем. Например, если нам нужно узнать, какое количество пива потребляется, то мы обнаружим, что внутри нашей генеральной совокупности нормы потребления у различных людей существенно различаются (гетерогенная генеральная совокупность). В другом случае мы будем изучать потребление хлеба и установим, что у разных людей оно различается гораздо менее существенно {гомогенная генеральная совокупность). Чем больше различия (или гетерогенность) внутри генеральной совокупности, тем больше величина возможной ошибки выборки. Указанная закономерность лишь подтверждает то, что нам подсказывает простой здравый смысл. Таким образом, как справедливо утверждает В. Ядов, «численность (объем) выборки зависит от уровня однородности или разнородности изучаемых объектов. Чем более они однородны, тем меньшая численность может обеспечить статистически достоверные выводы».
Определение объема выборки зависит также от уровня доверительного интервала допустимой статистической ошибки. Здесь имеются в виду так называемые случайные ошибки, которые связаны с природой любых статистических погрешностей. В.И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5%-ной ошибки:
Это означает,что если вы, опросив, предположим, 400 человек в районном городе, где численность взрослого платежеспособного населения составляет 100 тыс. человек, выявили, что 33% опрошенных покупателей предпочитают продукцию местного мясокомбината, то с 95%-ной вероятностью можете утверждать, что постоянными покупателями этой продукции являются 33+5% (т.е. от 28 до 38%) жителей этого города.
Можно также воспользоваться расчетами института Гэллапа для оценки соотношения размеров выборки и ошибки выборки.
Ошибка выборки – это распространенное явление в статистике и обработке данных, которое возникает в результате неправильного или непредставительного выбора элементов для анализа или исследования. Ошибка выборки может внести серьезные искажения в получаемые результаты и привести к неверным выводам.
Причины ошибки выборки могут быть разнообразными. Одной из основных причин является неправильное методологическое планирование исследования, включая непредставительность выборки, отсутствие случайного отбора или избирательность включения или исключения определенных элементов.
Способы исправления ошибки выборки включают в себя несколько подходов. Во-первых, можно увеличить объем выборки, чтобы уменьшить возможное влияние ошибки. Во-вторых, следует строго придерживаться правил случайного отбора, исключая возможность манипуляции в выборе элементов. Кроме того, необходимо учитывать различные факторы, которые могут влиять на получаемые результаты, и включать их в анализ.
Ошибка выборки – это серьезное явление, требующее внимательного исследования и постоянного контроля. Только правильное понимание причин и методов исправления ошибки позволит проводить достоверные и надежные исследования и получать точные результаты.
Содержание
- Что такое ошибка выборки?
- Определение и сущность
- Причины возникновения ошибки выборки
- Неправильное определение целевой аудитории
- Недостаточный объем выборки
- Неслучайная выборка
- Последствия ошибки выборки
- Неверные выводы и решения на основе ошибочной выборки
- Вопрос-ответ
- Что такое ошибка выборки?
- Какие причины могут быть у ошибки выборки?
- Как исправить ошибку выборки?
Что такое ошибка выборки?
Ошибка выборки – это один из типов ошибок, возникающих при проведении исследований или статистического анализа данных. Ошибка выборки происходит, когда результаты исследования или анализа основаны не на полной генеральной совокупности, а только на ее части – выборке.
Ошибку выборки можно объяснить следующим образом: вся генеральная совокупность – это некоторая группа людей, объектов или явлений, а выборка – это просто небольшая часть этой генеральной совокупности, которая выбирается для исследования. Идеальная выборка должна быть репрезентативной, то есть отражать все разнообразие и особенности генеральной совокупности, чтобы результаты исследования можно было обобщить на всю генеральную совокупность.
Ошибки выборки могут возникать по разным причинам. Наиболее распространенные причины – неправильная процедура выборки, недостаточный размер выборки, неучтение всех специфических характеристик генеральной совокупности при выборе выборки и другие.
Ошибка выборки может иметь серьезные последствия и сильно исказить результаты исследования или анализа данных. Поэтому очень важно проводить выборку и анализ данных с учетом всех необходимых требований и правил, чтобы минимизировать возможные ошибки и получить достоверные результаты.
Определение и сущность
Ошибка выборки является одной из наиболее распространенных проблем, с которой сталкиваются исследователи и аналитики при работе с данными. Она возникает, когда выборка (набор данных, используемый для анализа) не является репрезентативной для всей популяции (группы, класса объектов, которую мы хотим изучить).
Сущность ошибки выборки заключается в том, что полученные результаты и выводы, основанные на нерепрезентативной выборке, не могут быть обобщены на всю популяцию с высокой степенью уверенности и достоверности.
Ошибка выборки может возникнуть по разным причинам, таким как:
- Недостаточный размер выборки: выборка может быть слишком мала, чтобы достаточно точно представлять всю популяцию, что приводит к искажению результатов и неверным выводам.
- Неслучайная выборка: при использовании неслучайной выборки вместо случайной, можно получить искаженные результаты, так как возникает возможность систематического искажения данных в сторону определенного направления.
- Искажение выборки: при определенных условиях, таких как самоотбор или выбытие из выборки, данные могут стать неслучайными, что приведет к ошибочным результатам.
Для уменьшения ошибки выборки и обеспечения более точных и достоверных результатов необходимо применять соответствующие методы и стратегии выборки, анализировать и учитывать возможные источники искажений и принимать меры по их устранению. Только тогда мы сможем быть уверены в надежности и правильности полученных научных исследований и практических рекомендаций.
Причины возникновения ошибки выборки
Ошибка выборки – это ошибка, которая возникает при обработке данных в процессе выполнения выборки из базы данных. Она может быть вызвана разными причинами, и важно уметь их распознавать и исправлять.
Основными причинами возникновения ошибки выборки являются:
- Неправильный синтаксис запроса: ошибка может возникнуть, если запрос на выборку данных сформулирован некорректно, содержит синтаксические ошибки или несовместимые операторы. Например, неправильно указаны имена таблиц или полей, отсутствуют запятые или кавычки.
- Несуществующие данные или таблицы: возникает, когда в запросе указаны неправильные или несуществующие имена таблиц или полей. Убедитесь, что все используемые имена корректны и существуют в базе данных.
- Несоответствие типов данных: при выборке данных важно учитывать типы полей, с которыми работаете. Если тип данных, указанный в запросе, не соответствует типу данных в таблице, может возникнуть ошибка выборки.
- Проблемы с подключением к базе данных: ошибки выборки могут возникать из-за проблем с подключением к базе данных. Проверьте правильность настроек подключения, доступность сервера базы данных и наличие необходимых прав доступа.
- Дублирование данных: ошибка выборки может возникнуть, если в таблице есть дублирующиеся записи или если две или более записи имеют одинаковые значения ключевого поля.
Важно проводить тщательный анализ и отладку запросов на выборку данных, чтобы найти и исправить возможные ошибки. Также рекомендуется использовать средства и методы защиты от ошибок выборки, такие как проверка входных данных, использование подготовленных выражений и санитизация запросов.
Неправильное определение целевой аудитории
Ошибки выборки могут возникать по разным причинам. Одной из них является неправильное определение целевой аудитории.
При разработке маркетинговых стратегий и создании продуктов или услуг необходимо четко определить свою целевую аудиторию. Целевая аудитория — это группа людей, которым предназначен продукт или услуга, и к которой будет направлено все маркетинговое воздействие.
Однако, неправильное определение целевой аудитории может стать серьезной ошибкой, которая может привести к неэффективным результатам и потере ресурсов. Вот несколько примеров неправильного определения целевой аудитории:
- Неправильное определение демографических характеристик: Важно учитывать возраст, пол, доходы и другие критерии при определении целевой аудитории. Неправильная оценка этих характеристик может привести к неправильной ориентации маркетинговых усилий.
- Игнорирование психографических факторов: Кроме демографических характеристик, важно учитывать и психологический профиль вашей целевой аудитории. Игнорирование таких факторов может привести к тому, что ваш продукт или услуга не будут соответствовать потребностям и предпочтениям ваших клиентов.
- Недостаточное исследование рынка: Несмотря на то, что неправильное определение целевой аудитории может происходить из-за недооценки факторов, также существует опасность переоценки и неправильного понимания ваших потенциальных клиентов. Недостаточное исследование рынка может привести к неправильному определению целевой аудитории и, следовательно, к неправильному маркетинговому воздействию.
Чтобы избежать ошибок при определении целевой аудитории, рекомендуется провести тщательное исследование рынка, а также использовать различные методы сбора и анализа данных. Например, провести опросы, фокус-группы, анализировать поведенческие данные и т.д.
Недостаточный объем выборки
Недостаточный объем выборки является одной из наиболее распространенных причин ошибки выборки при проведении исследований. Эта ошибка возникает, когда выборка, которая используется для анализа, слишком мала, чтобы представлять всю популяцию.
Ошибки, связанные с недостаточным объемом выборки, могут иметь серьезные последствия и привести к искажению результатов исследования. Например, если выборка слишком мала, то она может не улавливать все значимые различия в популяции, что приведет к неправильным выводам.
Если выборка слишком мала, то результаты исследования не будут иметь статистической значимости и не смогут быть обобщены на всю популяцию. Кроме того, слишком маленькая выборка может привести к возникновению смещений, таких как смещение выборки или смещение в сторону особой подгруппы популяции.
Чтобы исправить недостаточный объем выборки, исследователи могут принять следующие меры:
- Увеличить размер выборки: чем больше выборка, тем более надежные будут результаты исследования. Однако увеличение объема выборки может быть связано с дополнительными затратами и усилиями.
- Использовать случайную выборку: случайная выборка помогает уменьшить возможные смещения и представляет популяцию более точно.
- Разбить популяцию на подгруппы: для увеличения достоверности результатов исследования, исследователи могут провести анализ в каждой подгруппе популяции отдельно. Это позволит получить более полную картину.
- Провести дополнительное исследование: если объем выборки все еще является проблемой, исследователи могут провести дополнительное исследование, чтобы увеличить общий объем данных и повысить достоверность результатов.
В целом, недостаточный объем выборки может привести к серьезным ошибкам и искажениям результатов исследования. Поэтому особое внимание следует уделять размеру выборки и применять стратегии, направленные на увеличение ее достоверности в соответствии с целями исследования.
Неслучайная выборка
Неслучайная выборка — это ошибка выборки, которая возникает в результате неправильного способа отбора выборки из генеральной совокупности или неправильного представления самих данных. Она может привести к некорректным или искаженным результатам и выводам и значительно исказить общую картину.
При неслучайной выборке может быть несколько причин:
- Смещение выборки: В результате смещения выборки отбираются определенные группы или характеристики, что исключает другие группы или характеристики. В итоге, полученная выборка не является представительной для всей генеральной совокупности.
- Выборочный метод: Применение определенного метода для отбора выборки может привести к неслучайной выборке. Например, использование удобных субъектов для исследования или отсутствие четкого алгоритма отбора.
- Отсутствие случайности: Если не было использовано случайное или рандомизированное отборочное процедура, то выборка может быть неслучайной.
Следующие стратегии могут быть использованы для исправления ошибки неслучайной выборки:
- Случайный отбор: Использование случайного отбора поможет устранить смещение и получить максимально представительную выборку.
- Проверка метода: Важно проверить метод отбора выборки на соответствие целям исследования и наличию систематических ошибок.
- Учет всех групп и характеристик: Необходимо обеспечить представительность всех групп и характеристик генеральной совокупности.
Исправление ошибки неслучайной выборки требует тщательного анализа данных, грамотного подхода к отбору выборки и строгого следования установленным методикам и принципам исследования и статистики.
Последствия ошибки выборки
Ошибка выборки – это ситуация, когда изучаемая выборка данных не является репрезентативной для всей генеральной совокупности. То есть, данные, полученные из выборки, не могут дать достоверную картину о всей группе или явлений, которые изучаются. Это может привести к ошибочным выводам и неверным решениям.
Последствия ошибки выборки могут быть крайне серьезными и затрагивать различные аспекты жизни и деятельности человека. Ниже приведены некоторые из них:
- Незначительность результата исследования: Если выборка нерепрезентативна, то результаты исследования могут быть несущественными и не иметь практической ценности. Например, исследование эффективности нового лекарства может показать положительные результаты на маленькой выборке пациентов, но когда оно будет применено на практике, оказаться неэффективным.
- Потеря ресурсов: Ошибочные выводы, основанные на нерепрезентативной выборке, могут привести к ненужным затратам – как времени, денег, так и других ресурсов. Например, компания может разработать новый продукт на основе исследования маленькой выборки, но когда продукт будет запущен на рынок, обнаружится его низкая востребованность.
- Неправильные решения: Ошибка выборки может привести к принятию неправильных решений в различных сферах – от бизнеса до политики. Например, политический кандидат может опираться на результаты исследования, проведенного на незначительной выборке, и базируясь на этом, строить свою предвыборную программу, которая может оказаться неэффективной или даже непопулярной среди избирателей.
Чтобы избежать последствий ошибки выборки, необходимо при исследованиях и аналитической работе тщательно подбирать выборку и стараться, чтобы она была максимально репрезентативной для интересующей нас генеральной совокупности. Также важно применять различные методы статистического анализа, которые помогут оценить достоверность полученных результатов.
Неверные выводы и решения на основе ошибочной выборки
Одной из основных проблем, связанных с ошибкой выборки, является возможность сделать неверные выводы и принять неправильные решения на основе полученных данных.
Когда проводится исследование или опрос, важно, чтобы выборка была репрезентативной, то есть достаточно представительной для всей генеральной совокупности. Если выборка содержит только определенную категорию людей или объектов, полученные результаты могут быть искажены и не могут быть обобщены на всю генеральную совокупность.
Например, если проводится исследование о вкусовых предпочтениях населения в отношении газированных напитков, а выборка включает только людей молодого возраста, это может привести к неверному выводу о предпочтениях всех возрастных групп.
Кроме того, ошибочная выборка может привести к неадекватным или неправильным решениям. Представим ситуацию, когда на основе опроса о вреде социальных сетей для здоровья была проведена кампания по запрету их использования. Однако, если выборка состояла только из людей старшего поколения, которые мало пользуются интернетом, такое решение может оказаться необоснованным и непродуманным.
Исправить ошибку выборки можно с помощью следующих методов:
- Увеличение выборки: Повышение размера выборки может помочь снизить вероятность ошибки выборки. Чем больше объектов в выборке, тем более репрезентативной она будет.
- Случайная выборка: Использование случайной выборки помогает уменьшить искусственные искажения и сделать выборку более репрезентативной.
- Стратифицированная выборка: Разделение генеральной совокупности на страты и проведение выборки в каждой страте помогает обеспечить более точные и репрезентативные результаты.
В целом, важно понимать, что ошибочная выборка может привести к неверным выводам и неправильным решениям. Поэтому необходимо проводить исследования и опросы с помощью корректных и надежных методов выборки, чтобы получить достоверные и репрезентативные данные.
Вопрос-ответ
Что такое ошибка выборки?
Ошибка выборки — это разница между реальными значениями в генеральной совокупности и значениями, полученными при проведении выборки. Она может возникнуть из-за случайной ошибки в процессе выборки или из-за систематической ошибки в методологии выборки.
Какие причины могут быть у ошибки выборки?
Ошибки выборки могут быть вызваны различными факторами. Например, неправильный выбор метода выборки, недостаточный размер выборки, отклонение от случайной выборки, неправильная оценка параметров генеральной совокупности, систематические ошибки в сборе данных и другие факторы.
Как исправить ошибку выборки?
Существует несколько способов исправить ошибку выборки. Во-первых, можно увеличить размер выборки, чтобы уменьшить случайную ошибку. Во-вторых, можно использовать более точные методы выборки, такие как стратифицированная выборка или кластеризованная выборка. Также можно заново оценить параметры генеральной совокупности и учесть систематические ошибки, если они имеются. Важно также проводить анализ результатов выборки, чтобы определить искажения и принять меры по их исправлению.
Как мы уже знаем, репрезентативность — свойство выборочной совокупности представлять характеристику генеральной. Если совпадения нет, говорят об ошибке репрезентативности — мере отклонения статистической структуры выборки от структуры соответствующей генеральной совокупности. Предположим, что средний ежемесячный семейный доход пенсионеров в генеральной совокупности составляет 2 тыс. руб., а в выборочной — 6 тыс. руб. Это означает, что социолог опрашивал только зажиточную часть пенсионеров, а в его исследование вкралась ошибка репрезентативности. Иными словами, ошибкой репрезентативности называется расхождение между двумя совокупностями — генеральной, на которую направлен теоретический интерес социолога и представление о свойствах которой он хочет получить в конечном итоге, и выборочной, на которую направлен практический интерес социолога, которая выступает одновременно как объект обследования и средство получения информации о генеральной совокупности.
Наряду с термином «ошибка репрезентативности» в отечественной литературе можно встретить другой — «ошибка выборки». Иногда они употребляются как синонимы, а иногда «ошибка выборки» используется вместо «ошибки репрезентативности» как количественно более точное понятие.
Ошибка выборки — отклонение средних характеристик выборочной совокупности от средних характеристик генеральной совокупности.
На практике ошибка выборки определяется путем сравнения известных характеристик генеральной совокупности с выборочными средними. В социологии при обследованиях взрослого населения чаще всего используют данные переписей населения, текущего статистического учета, результаты предшествующих опросов. В качестве контрольных параметров обычно применяются социально-демографические признаки. Сравнение средних генеральной и выборочной совокупностей, на основе этого определение ошибки выборки и ее уменьшение называется контролированием репрезентативности. Поскольку сравнение своих и чужих данных можно сделать по завершении исследования, такой способ контроля называется апостериорным, т.е. осуществляемым после опыта.
В опросах Института Дж. Гэллапа репрезентативность контролируется по имеющимся в национальных переписях данным о распределении населения по полу, возрасту, образованию, доходу, профессии, расовой принадлежности, месту проживания, величине населенного пункта. Всероссийский центр изучения общественного мнения (ВЦИОМ) использует для подобных целей такие показатели, как пол, возраст, образование, тип поселения, семейное положение, сфера занятости, должностной статус респондента, которые заимствуются в Государственном комитете по статистике РФ. В том и другом случае генеральная совокупность известна. Ошибку выборки невозможно установить, если неизвестны значения переменной в выборочной и генеральной совокупностях.
Специалисты ВЦИОМ обеспечивают при анализе данных тщательный ремонт выборки, чтобы минимизировать отклонения, возникшие на этапе полевых работ. Особенно сильные смещения наблюдаются по параметрам пола и возраста. Объясняется это тем, что женщины и люди с высшим образованием больше времени проводят дома и легче идут на контакт с интервьюером, т.е. являются легко достижимой группой по сравнению с мужчинами и людьми «необразованными»35.
Ошибка выборки обусловливается двумя факторами: методом формирования выборки и размером выборки.
Ошибки выборки подразделяются на два типа — случайные и систематические. Случайная ошибка — это вероятность того, что выборочная средняя выйдет (или не выйдет) за пределы заданного интервала. К случайным ошибкам относят статистические погрешности, присущие самому выборочному методу. Они уменьшаются при возрастании объема выборочной совокупности.
Второй тип ошибок выборки — систематические ошибки. Если социолог решил узнать мнение всех жителей города о проводимой местными органами власти социальной политике, а опросил только тех, у кого есть телефон, то возникает предумышленное смещение выборки в пользу зажиточных слоев, т.е. систематическая ошибка.
Таким образом, систематические ошибки — результат деятельности самого исследователя. Они наиболее опасны, поскольку приводят к довольно значительным смещениям результатов исследования. Систематические ошибки считаются страшнее случайных еще и потому, что они не поддаются контролю и измерению.
Они возникают, когда, например:
- выборка не соответствует задачам исследования (социолог решил изучить только работающих пенсионеров, а опросил всех подряд);
- налицо незнание характера генеральной совокупности (социолог думал, что 70% всех пенсионеров не работает, а оказалось, что не работает только 10%);
- отбираются только «выигрышные» элементы генеральной совокупности (например, только обеспеченные пенсионеры).
Внимание! В отличие от случайных ошибок систематические ошибки при возрастании объема выборки не уменьшаются.
Обобщив все случаи, когда происходят систематические ошибки, методисты составили их реестр. Они полагают, что источником неконтролируемых перекосов в распределении выборочных наблюдений могут быть следующие факторы:
- нарушены методические и методологические правила проведения социологического исследования;
- выбраны неадекватные способы формирования выборочной совокупности, методы сбора и расчета данных;
- произошла замена требуемых единиц наблюдения другими, более доступными;
- отмечен неполный охват выборочной совокупности (недополучение анкет, неполное их заполнение, труднодоступность единиц наблюдения).
Намеренные ошибки социолог допускает редко. Чаще ошибки возникают из-за того, что социологу плохо известна структура генеральной совокупности: распределение людей по возрасту, профессии, доходам и т.д.
Систематические ошибки легче предупредить (по сравнению со случайными), но их очень трудно устранить. Предупреждать систематические ошибки, точно предвидя их источники, лучше всего заранее — в самом начале исследования.
Вот некоторые способы избежать ошибок выборки:
- каждая единица генеральной совокупности должна иметь равную вероятность попасть в выборку;
- отбор желательно производить из однородных совокупностей;
- надо знать характеристики генеральной совокупности;
- при составлении выборочной совокупности надо учитывать случайные и систематические ошибки.
Если выборочная совокупность (или просто выборка) составлена правильно, то социолог получает надежные результаты, харастеризующие всю генеральную совокупность. Если она составлена неправильно, то ошибка, возникшая на этапе составления выборки, на каждом следующем этапе проведения социологического исследования приумножается и достигает в конечном счете такой величины, которая перевешивает ценность проведенного исследования. Говорят, что от такого исследования больше вреда, нежели пользы.
Подобные ошибки могут произойти только с выборочной совокупностыо. Чтобы избежать или уменьшить вероятность ошибки, самый простой способ — увеличивать размеры выборки (в идеале до объема генеральной: когда обе совокупности совпадут, ошибка выборки вообще исчезнет). Экономически такой метод невозможен. Остается другой путь — совершенствовать математические методы составления выборки. Они то и применяются на практике. Таков первый канал проникновения в социологию математики. Второй канал — математическая обработка данных.
Особенно важной проблема ошибок становится в маркетинговых исследованиях, где используются не очень большие выборки. Обычно они составляют несколько сотен, реже — тысячу респондентов. Здесь исходным пунктом расчета выборки выступает вопрос об определении размеров выборочной совокупности. Численность выборочной совокупности зависит от двух факторов:
- стоимости сбора информации,
- стремления к определенной степени статистической достоверности результатов, которую надеется получить исследователь.
Конечно, даже не искушенные в статистике и социологии люди интуитивно понимают, что чем больше размеры выборки, т.е. чем ближе они к размерам генеральной совокупности в целом, тем более надежны и достоверны полученные данные. Однако выше мы уже говорили о практической невозможности сплошных опросов в тех случаях, когда они проводятся на объектах, численность которых превышает десятки, сотни тысяч и даже миллионы. Понятно, что стоимость сбора информации (включающая оплату тиражирования инструментария, труда анкетеров, полевых менеджеров и операторов по компьютерному вводу) зависит от той суммы, которую готов выделить заказчик, и слабо зависит от исследователей. Что же касается второго фактора, то мы остановимся на нем чуть подробнее.
Итак, чем больше величина выборки, тем меньше возможная ошибка. Хотя необходимо отметить, что при желании увеличить точность вдвое вам придется увеличить выборку не в два, а в четыре раза. Например, чтобы сделать в два раза более точной оценку данных, полученных путем опроса 400 человек, вам потребуется опросить не 800, а 1600 человек. Впрочем, вряд ли маркетинговое исследование испытывает нужду в стопроцентной точности. Если пивовару необходимо узнать, какая часть потребителей пива предпочитает именно его марку, а не сорт его конкурента, — 60% или 40%, то на его планы никак не повлияет разница между 57%, 60 или 63%.
Ошибка выборки может зависеть не только от ее величины, но и от степени различий между отдельными единицами внутри генеральной совокупности, которую мы исследуем. Например, если нам нужно узнать, какое количество пива потребляется, то мы обнаружим, что внутри нашей генеральной совокупности нормы потребления у различных людей существенно различаются (гетерогенная генеральная совокупность). В другом случае мы будем изучать потребление хлеба и установим, что у разных людей оно различается гораздо менее существенно {гомогенная генеральная совокупность). Чем больше различия (или гетерогенность) внутри генеральной совокупности, тем больше величина возможной ошибки выборки. Указанная закономерность лишь подтверждает то, что нам подсказывает простой здравый смысл. Таким образом, как справедливо утверждает В. Ядов, «численность (объем) выборки зависит от уровня однородности или разнородности изучаемых объектов. Чем более они однородны, тем меньшая численность может обеспечить статистически достоверные выводы».
Определение объема выборки зависит также от уровня доверительного интервала допустимой статистической ошибки. Здесь имеются в виду так называемые случайные ошибки, которые связаны с природой любых статистических погрешностей. В.И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5%-ной ошибки:
Это означает,что если вы, опросив, предположим, 400 человек в районном городе, где численность взрослого платежеспособного населения составляет 100 тыс. человек, выявили, что 33% опрошенных покупателей предпочитают продукцию местного мясокомбината, то с 95%-ной вероятностью можете утверждать, что постоянными покупателями этой продукции являются 33+5% (т.е. от 28 до 38%) жителей этого города.
Можно также воспользоваться расчетами института Гэллапа для оценки соотношения размеров выборки и ошибки выборки.