Ошибка прогнозирования: виды, формулы, примеры

Ошибка прогнозирования — это такая величина, которая показывает, как сильно прогнозное значение отклонилось от фактического. Она используется для расчета точности прогнозирования, что в свою очередь помогает нам оценивать как точно и корректно мы сформировали прогноз. В данной статье я расскажу про основные процентные «ошибки прогнозирования» с кратким описанием и формулой для расчета. А в конце статьи я приведу общий пример расчётов в Excel. Напомню, что в своих расчетах я в основном использую ошибку WAPE или MAD-Mean Ratio, о которой подробно я рассказал в статье про точность прогнозирования, здесь она также будет упомянута.
В каждой формуле буквой Ф обозначено фактическое значение, а буквой П — прогнозное. Каждая ошибка прогнозирования (кроме последней!), может использоваться для нахождения общей точности прогнозирования некоторого списка позиций, по типу того, что изображен ниже (либо для любого другого подобной детализации):
Алгоритм для нахождения любой из ошибок прогнозирования для такого списка примерно одинаковый: сначала находим ошибку прогнозирования по одной позиции, а затем рассчитываем общую. Итак, основные ошибки прогнозирования!
MPE — Mean Percent Error
MPE — средняя процентная ошибка прогнозирования. Основная проблема данной ошибки заключается в том, что в нестабильном числовом ряду с большими выбросами любое незначительное колебание факта или прогноза может значительно поменять показатель ошибки и, как следствие, точности прогнозирования. Помимо этого, ошибка является несимметричной: одинаковые отклонения в плюс и в минус по-разному влияют на показатель ошибки.

- Для каждой позиции рассчитывается ошибка прогноза (из факта вычитается прогноз) — Error
- Для каждой позиции рассчитывается процентная ошибка прогноза (ошибка прогноза делится на фактический показатель) — Percent Error
- Находится среднее арифметическое всех процентных ошибок прогноза (процентные ошибки суммируются и делятся на количество) — Mean Percent Error
MAPE — Mean Absolute Percent Error
MAPE — средняя абсолютная процентная ошибка прогнозирования. Основная проблема данной ошибки такая же, как и у MPE — нестабильность.

- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта по модулю) — Absolute Error
- Для каждой позиции рассчитывается абсолютная процентная ошибка прогноза (абсолютная ошибка прогноза делится на фактический показатель) — Absolute Percent Error
- Находится среднее арифметическое всех абсолютных процентных ошибок прогноза (абсолютные процентные ошибки суммируются и делятся на количество) — Mean Absolute Percent Error
Вместо среднего арифметического всех абсолютных процентных ошибок прогноза можно использовать медиану числового ряда (MdAPE — Median Absolute Percent Error), она наиболее устойчива к выбросам.
WMAPE / MAD-Mean Ratio / WAPE — Weighted Absolute Percent Error
WAPE — взвешенная абсолютная процентная ошибка прогнозирования. Одна из «лучших ошибок» для расчета точности прогнозирования. Часто называется как MAD-Mean Ratio, то есть отношение MAD (Mean Absolute Deviation — среднее абсолютное отклонение/ошибка) к Mean (среднее арифметическое). После упрощения дроби получается искомая формула WAPE, которая очень проста в понимании:

- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта, по модулю) — Absolute Error
- Находится сумма всех фактов по всем позициям (общий фактический объем)
- Сумма всех абсолютных ошибок делится на сумму всех фактов — WAPE
Данная ошибка прогнозирования является симметричной и наименее чувствительна к искажениям числового ряда.
Рекомендуется к использованию при расчете точности прогнозирования. Более подробно читать здесь.
RMSE (as %) / nRMSE — Root Mean Square Error
RMSE — среднеквадратичная ошибка прогнозирования. Примерно такая же проблема, как и в MPE и MAPE: так как каждое отклонение возводится в квадрат, любое небольшое отклонение может значительно повлиять на показатель ошибки. Стоит отметить, что существует также ошибка MSE, из которой RMSE как раз и получается путем извлечения корня. Но так как MSE дает расчетные единицы измерения в квадрате, то использовать данную ошибку будет немного неправильно.

- Для каждой позиции рассчитывается квадрат отклонений (разница между фактом и прогнозом, возведенная в квадрат) — Square Error
- Затем рассчитывается среднее арифметическое (сумма квадратов отклонений, деленное на количество) — MSE — Mean Square Error
- Извлекаем корень из полученного результат — RMSE
- Для перевода в процентную или в «нормализованную» среднеквадратичную ошибку необходимо:
- Разделить на разницу между максимальным и минимальным значением показателей
- Разделить на разницу между третьим и первым квартилем значений показателей
- Разделить на среднее арифметическое значений показателей (наиболее часто встречающийся вариант)
MASE — Mean Absolute Scaled Error
MASE — средняя абсолютная масштабированная ошибка прогнозирования. Согласно Википедии, является очень хорошим вариантом для расчета точности, так как сама ошибка не зависит от масштабов данных и является симметричной: то есть положительные и отрицательные отклонения от факта рассматриваются в равной степени.
Важно! Если предыдущие ошибки прогнозирования мы могли использовать для нахождения точности прогнозирования некого списка номенклатур, где каждой из которых соответствует фактическое и прогнозное значение (как было в примере в начале статьи), то данная ошибка для этого не предназначена: MASE используется для расчета точности прогнозирования одной единственной позиции, основываясь на предыдущих показателях факта и прогноза, и чем больше этих показателей, тем более точно мы сможем рассчитать показатель точности. Вероятно, из-за этого ошибка не получила широкого распространения.
Здесь данная формула представлена исключительно для ознакомления и не рекомендуется к использованию.
Суть формулы заключается в нахождении среднего арифметического всех масштабированных ошибок, что при упрощении даст нам следующую конечную формулу:

Также, хочу отметить, что существует ошибка RMMSE (Root Mean Square Scaled Error — Среднеквадратичная масштабированная ошибка), которая примерно похожа на MASE, с теми же преимуществами и недостатками.
Это основные ошибки прогнозирования, которые могут использоваться для расчета точности прогнозирования. Но не все! Их очень много и, возможно, чуть позже я добавлю еще немного информации о некоторых из них. А примеры расчетов уже описанных ошибок прогнозирования будут выложены через некоторое время, пока что я подготавливаю пример, ожидайте.
Об авторе

HeinzBr
Автор статей и создатель сайта SHTEM.RU
 Рост точности прогноза — это точка роста оборотных средств при неизменном объеме. Чем меньше ошибка прогноза, тем меньше денег необходимо на обслуживание модели прогноза.
Рост точности прогноза — это точка роста оборотных средств при неизменном объеме. Чем меньше ошибка прогноза, тем меньше денег необходимо на обслуживание модели прогноза.
Дополнительные оборотные средства за счет повышения точности прогноза мы получим, если будем использовать модель прогнозирования, которая дает наименьшую среднюю абсолютную ошибку прогноза.
В данной статье мы рассмотрим:
- Как рассчитать среднюю абсолютную ошибку прогноза и выбрать модель, которая дает наименьшую ошибку;
- Сравним модели и оценим, сколько оборотных средств мы можем сохранить за год, если будем использовать модель, которая дает минимальную ошибку прогноза.
По ходу статьи мы разберем
- Что такое ошибка прогноза;
- Как рассчитывается среднее абсолютное отклонение;
и рассчитаем:
- Прогноз с помощью модели «Скользящей средней к 4-м месяцам с аддитивной сезонностью»;
- Прогноз с помощью модели «Логарифмический тренд с сезонностью»;
- Ошибку прогноза для каждой модели;
- Среднее абсолютное отклонение и для каждой модели.
А также сравним модели, опираясь на среднее абсолютное отклонение и оценим экономию оборотных средств за счет использования более точной модели прогнозирования.
Скачайте файл с примером
Что такое ошибка прогноза?
Ошибкой прогноза продаж является разность между фактическими продажами и прогнозом продаж.
Чем меньше ошибка прогноза, тем более точные решения мы приминаем в закупках, производстве, планировании … а следовательно более эффективно распределяем оборотные средства и повышаем оборачиваемость товаров.
Существует несколько методов оценки ошибок. Большинство этих методов состоит в усреднении некоторых функций от разностей между действительными значениями и их прогнозами.
Ошибку прогноза (et) для каждого момента времени во временном ряду мы можем вычистить по формуле:
et = Yt — Y^t ,
где
- Yt — действительное значение временного ряда в момент t — в наших примерах объем продаж,
- Y^t — прогноз значения Yt — в наших примерах прогноз объема продаж.
Ошибка MAD — среднее абсолютное отклонение
Среднее абсолютное отклонение (MAD) измеряет точность прогноза, усредняя величины ошибок прогноза (абсолютные значения каждой ошибки). Чаще всего MAD используют, когда ошибку прогноза необходимо измерить в тех же единицах, что и исходные значения временного ряда.
Формула вычисления ошибки:
![]()
- Yt — действительное значение временного ряда в момент t,
- Y^t — прогноз значения Yt,
- n — номера периодов
Среднее абсолютное отклонение — средняя ошибка (разность между фактом продаж и прогнозом продаж) по модулю.
Рассчитаем прогноз и оценим следующие модели:
- Скользящей средней к 4-м месяцам с аддитивной сезонностью;
- Логарифмический тренд с сезонностью.
Скачайте файл с примером
Для оценки ошибки модели «Скользящей средней к 4-м месяцам с аддитивной сезонностью» рассчитаем:
- Скользящую среднюю к 4-м месяцам;
- Разность между значениями ряда и средними значениями к 4-м месяцам (пункт 1);
- Усредним разность ряда и средней для каждого месяца получим сезонность в абсолютной величание — аддитивную сезонность;
- Продлим значения ряда с помощью скользящей средней к 4-м месяцам и скорректируем её аддитивной сезонностью;
- Модель прогноза для каждого момента времени t;
- Ошибку прогноза;
- Среднее абсолютное отклонение.
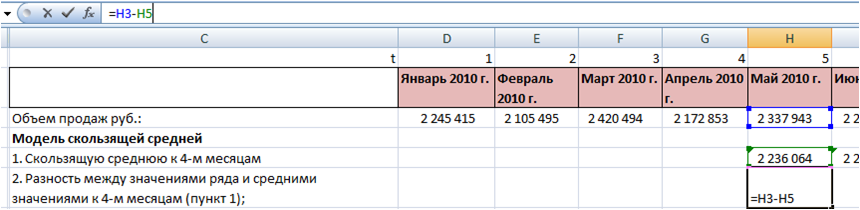
1. Скользящую среднюю к 4-м месяцам для каждого момента времени во временном ряду начиная с 5-го периода:

2. Разность между значениями ряда и средними значениями к 4-м месяцам для каждого момента времени t (пункт 1):
3. Усредним разность ряда и средней для каждого месяца получим сезонность в абсолютной величание — аддитивную сезонность.
Для этого вначале выделим номера месяцев с помощью функции Excel =месяц(дата). Для этого проверяем являются ли наши даты «январь 2010 г.», датой, если нет, то переводим в дату и используя функцию Excel =месяц(дата), получаем номера месяцев:
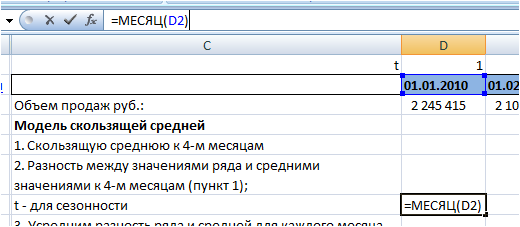
Получаем ряд с пронумерованными месяцами:

Далее усредняем отклонения ряда от средней для каждого месяца, получаем 12 значений аддитивной сезонности.
Для этого используем формулы Excel:
СУММЕСЛИ($D$7:$AY$7 (диапазон с номерами месяцев);D7 (номер месяца, для которого мы рассчитываем сезонность);$D$6:$AY$6 (разность между рядом и средней))
СЧЁТЕСЛИ($D$7:$AY$7(диапазон с номерами месяцев);D7(номер месяца, для которого мы рассчитываем сезонность))
Обязательно фиксируем ссылки на диапазоны с «Номерами месяцев» и «разность между рядом и средней». Подробнее об этом в статье » Как зафиксировать ссылку в Excel»
Подробнее о формулах Excel СУММЕСЛИ и СЧЁТЕСЛИ читайте с статье «Формулы Excel «СУММЕСЛИ» и «СЧЕТЕСЛИ» при расчете сезонности»
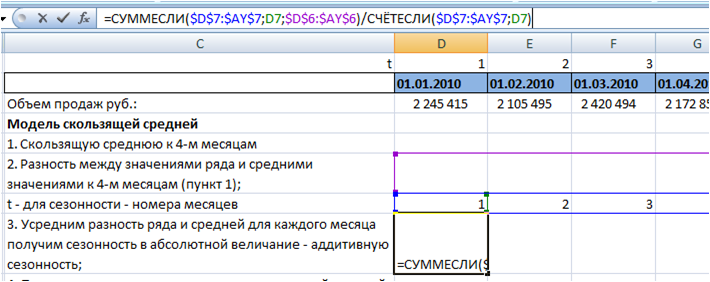
Протянули формулу на 12 месяцев, получили аддитивную сезонность для каждого месяца:

4. Продлим значения ряда с помощью скользящей средней к 4-м месяцам и скорректируем её аддитивной сезонностью.

Скорректируем скользящую рассчитанной аддитивной сезонностью.
Для этого к прогнозному среднему прибавим аддитивную сезонность. Сезонность для каждого месяца подтянем с помощью функции Excel ГПР.
Подробнее об этом читайте с статье «ГПР в Excel на примере скользящей средней».
Прогноз = средние продажи за последние 4 месяца + сезонность:
=СРЗНАЧ(AV4:AY4(средние продажи за 4 последних месяца))+ГПР(AZ3 (искомый номер месяца);$D$8:$O$9 (зафиксированная ссылка на таблицу с сезонностью);2 (номер строки);0)
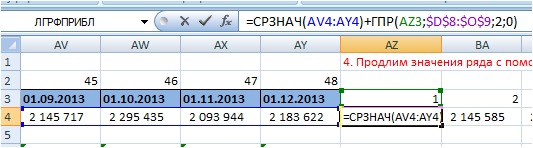
5. Рассчитаем модель прогноза для каждого момента времени t.
К скользящей средней прибавим аддитивную сезонность начиная с 5 периода:
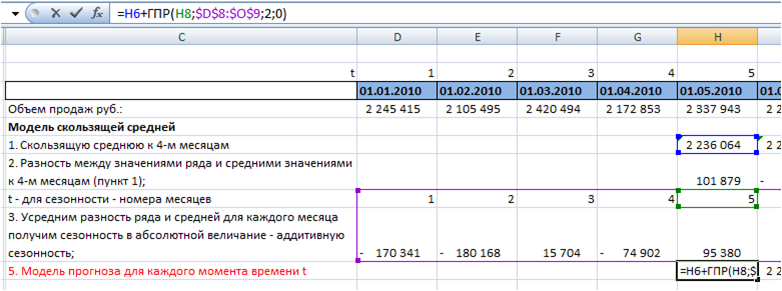
6. Рассчитаем значение ошибки для каждого месяца.
Для этого из объема продаж вычтем значение прогнозной модели:
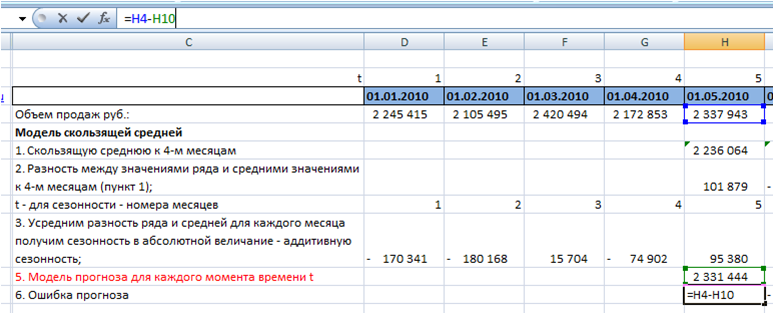
7. Определим среднее абсолютное отклонение.
Для каждого момента времени t рассчитаем ошибку по модулю с помощью формулы Excel =ABS(H11 (ссылка на ошибку)):
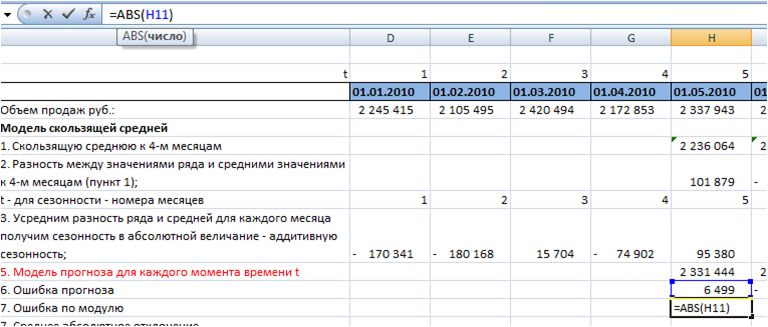
Среднее абсолютное отклонение равно средней ошибке по модулю:
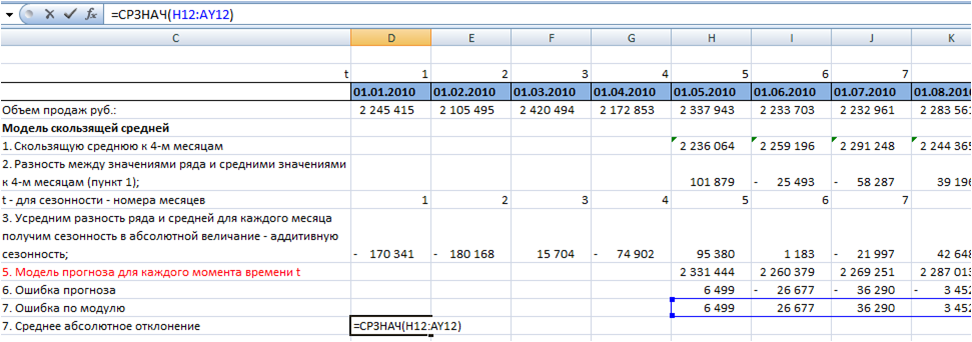
Среднее абсолютное отклонение для модели скользящей средней к 4-м месяцам с аддитивной сезонностью у нас равно 55 475
Теперь рассчитаем прогноз с помощью «Логарифмического тренда с сезонностью».
- Выделим логарифмический тренд;
- Рассчитаем сезонность;
- Рассчитаем значение модели;
- Рассчитаем ошибку прогноза и Среднее абсолютное отклонение.
Скачайте файл с примером
1. Выделим логарифмический тренд.
О всех возможных способах выделения логарифмического тренда в Excel вы можете узнать в нашей статье «5 способов расчета логарифмического тренда в Excel. + О логарифмическом тренде и его применении».
Рассчитаем значения тренда с помощью функции =ПРЕДСКАЗ(LN(D2(номер периода));$D$4:$AY$4 (зафиксированная ссылка на диапазон с объемами продаж);LN($D$2:$AY$2 (зафиксированная ссылка на диапазон с номерами периодов)))
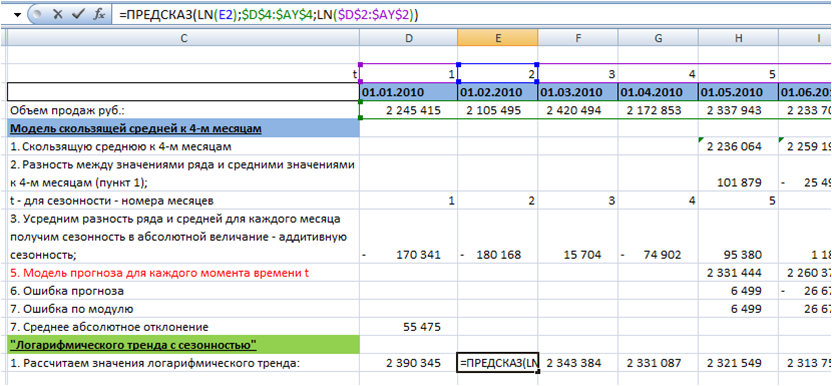
2. Рассчитываем отклонения объемов продаж от тренда (объем продаж делим на значения тренда):
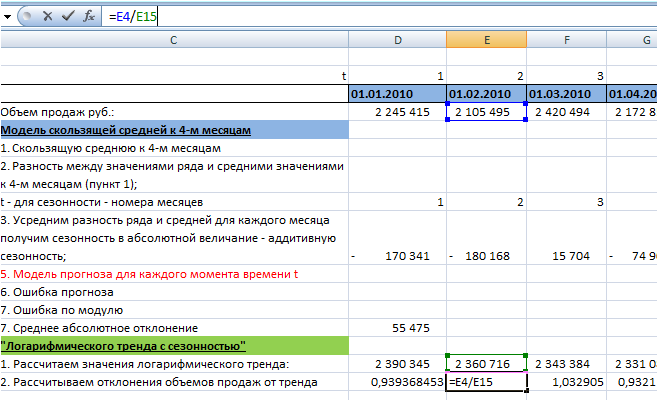
3. Определяем сезонность с помощью формул Excel =СУММЕСЛИ() и =СЧЁТЕСЛИ()
Подробнее о формулах Excel СУММЕСЛИ и СЧЁТЕСЛИ читайте с статье «Формулы Excel «СУММЕСЛИ» и «СЧЕТЕСЛИ» при расчете сезонности»:
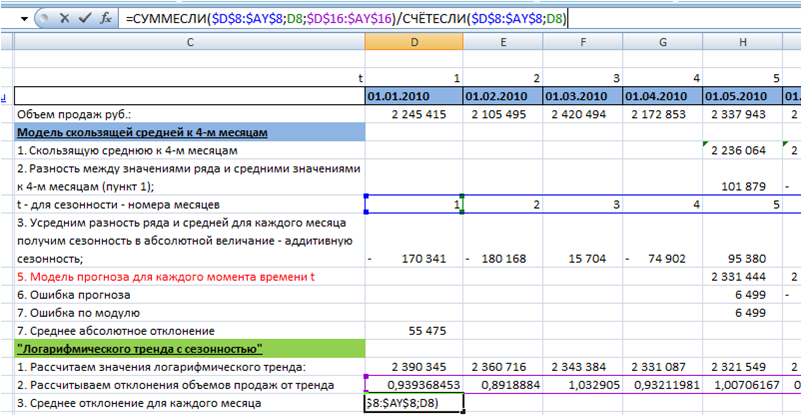
Т.к. полученная сезонность в среднем равна 1, то нормирующий коэффициент вводить не нужно, и среднее отклонение у нас будет равно сезонности по месяцам.
4. Определим значения модели прогноза для каждого момента времени t, для этого значения тренда умножим на сезонность. Сезонность подтянем с помощью функции ГПР (см. статью «Функция ГПР в Excel»):
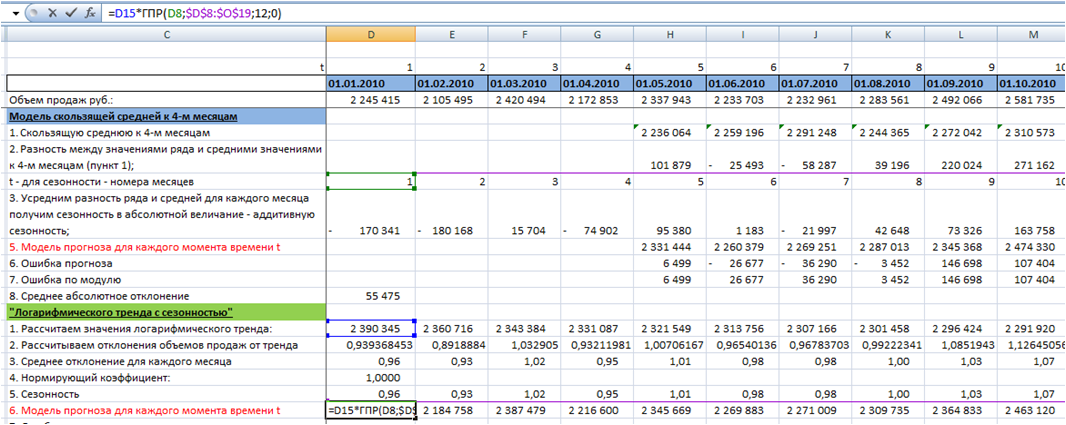
5. Определим ошибку прогноза для каждого момента времени t. Для этого из объема продаж вычтем значение модели прогноза для каждого момента времени t:
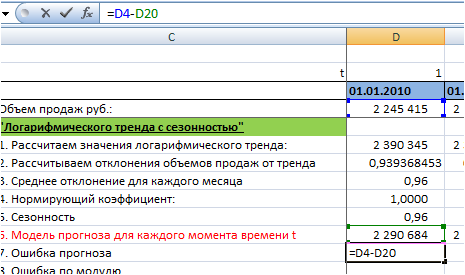
6. Рассчитаем ошибку по модулю с помощью функции =ABS(D21″ссылка на ошибку»):
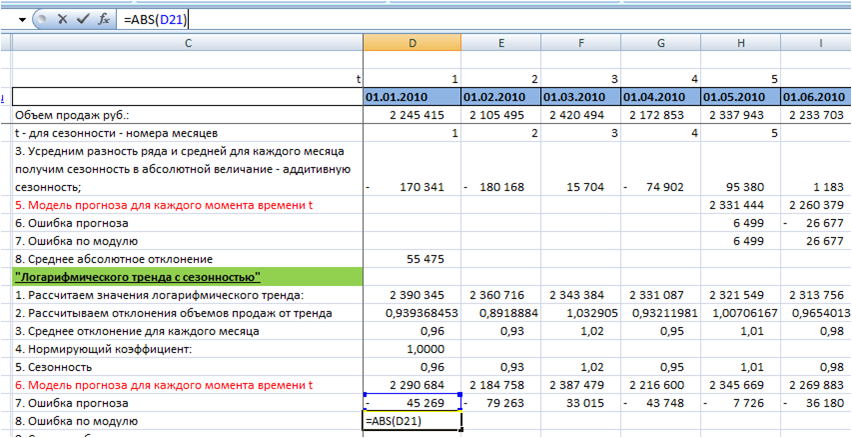
7. Получим среднее абсолютное отклонение по модулю — среднее значение ошибки по модулю:
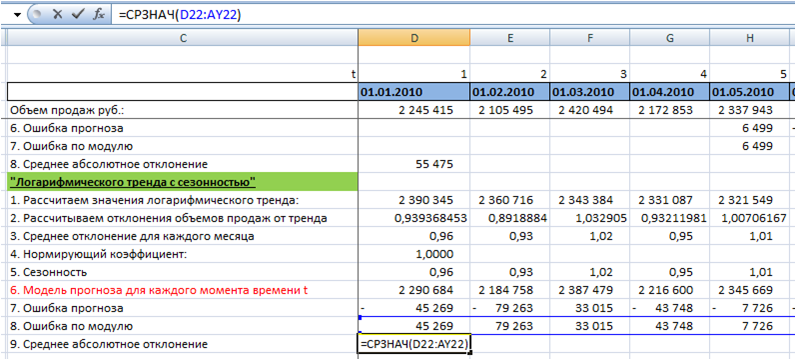
Среднее абсолютное отклонение для модели «Логарифмического тренда с сезонностью» у нас равно 70 412
Оценим эффективность использования в рамках года одной модели относительно другой.
Среднее абсолютное отклонение для модели
- «Логарифмического тренда с сезонностью» = 70 412 руб.
- «Скользящей средней к 4-м месяцам с аддитивной сезонностью» = 55 475 руб.
Итак модель скользящей средней делает более точный прогноз по сравнение с логарифмическим трендом для этого ряда в месяц на 14 937 руб. = 70 412 руб. — 55 475 руб.
В результате для нас это означает экономию оборотных средств на 14 937 руб. в месяц на обслуживание модели и 179 242 руб. в год, т.е. 14 937 руб. в месяц = 14 937 руб. * 12 месяцев =179 242 руб.
Т.е. в год мы получаем дополнительные оборотные средства в размере 179 242 руб.
Вот так вот за счет оценки точности прогноза и использования модели, которая дает меньшую ошибку прогноза, вы получаете дополнительные оборотные средства — 179 242 руб. в год.
Скачайте файл с примером
Коллеги, эти 2 модели я выбрал наугад, давайте теперь оценим модель, которую автоматически подберет Forecast4AC PRO. И оценим, какой эффект в год нам это даст.
В настройках программы во вкладке «Доп. возможности» ставим галочку «MAD — Среднее абсолютное отклонение» и отключаем модели экспоненциального сглаживания (т.к. они дают ошибку для данного ряда больше чем скользящая средняя и трендовые модели):
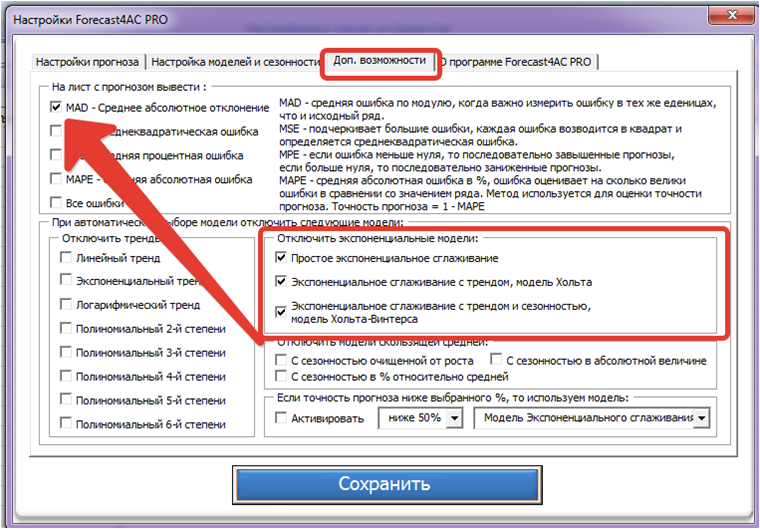
Сохраняем и рассчитываем прогноз с помощью Forecast4AC PRO с автоматическим выбором модели.
Автоматически программа выбрала модель Средняя за 2 предыдущих периода + Сезонность относительно средней в абсолютной величине (т.е. аддитивная сезонность). Среднее абсолютное отклонение для этой модели у нас получилось равным 39 882 руб.
|
Экономия оборотных средств модели Forecast4AC PRO относительно модели скользящей к 4-м месяцам в год руб.: |
187 115 руб. |
|
Экономия оборотных средств модели Forecast4AC PRO относительно модели Логарифмический тренд с сезонностью в год руб.: |
366 357 руб. |
Оцените точность моделей прогнозирования, которые вы используете сейчас, рассчитайте проноз с помощью Forecast4AC PRO и оцените сумму оборотных средств, которую вы можете сэкономить за счет использования нашей программы.
Точных вам прогнозов!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:

- Novo Forecast Lite — автоматический расчет прогноза в Excel.
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Зарегистрируйтесь и скачайте решения
Статья полезная? Поделитесь с друзьями
В этой статье я поделюсь методикой измерения точности прогноза продаж, которая применяется во многих западных компаниях и позволяет достаточно объективно оценить качество прогнозирования. В частности, данные показатели используются компанией Reckitt Benckiser, в которой я имел честь работать почти 6 лет.
Очевидно, что повышение точности прогнозирования и уменьшение ошибки прогноза улучшают многие бизнес-показатели цепи поставок, начиная от сервиса клиентов и уровня запасов, заканчивая более стабильной работой производства и более предсказуемой закупочной деятельностью. Это особенно актуально в условиях кризиса, когда эффективность становится, пожалуй, основным конкурентным преимуществом.
Именно поэтому описанные ниже показатели можно использовать как KPI функции Demand Planning так и KPI сотрудников, которые отвечают за подготовку прогноза продаж.
Так что же такое MAD, Bias и MAPE?
Bias (англ. – смещение) демонстрирует на сколько и в какую сторону прогноз продаж отклоняется от фактической потребности. Этот индикатор показывает, был ли прогноз оптимистичным или пессимистичным. То есть, отрицательное значение Bias говорит о том, что прогноз был завышен (реальная потребность оказалась ниже), и, наоборот, положительное значение о том, что прогноз был занижен. Цифровое значение показателя определяет величину отклонения (смещения).
MAD (Mean Absolute Deviation) – среднее абсолютное отклонение
MAD = ∑ |Et| / n, где:
|Et| — ошибка прогноза продаж за определенный период времени t
n – количество периодов оценки
Это показатель можно также выразить в процентах:
MAPE (Mean Absolute Percentage Error)
MARE = ∑ |Et| / At /n * 100% , где:
|Et| — ошибка прогноза продаж за период времени t
n – количество периодов оценки
At – фактическая потребность за период времени t
Пример расчета MAD:
|
Месяц |
Фактические продажи |
Прогноз |
Абсолютная ошибка |
|
1 |
310 |
290 |
20 |
|
2 |
300 |
310 |
10 |
|
3 |
290 |
300 |
10 |
|
4 |
260 |
280 |
20 |
|
5 |
275 |
280 |
5 |
|
65 |
MAD = 65/5 = 13
Пример расчета MAD, BIAS и MAPE.
|
Период |
Факт |
Прогноз |
Е |
|E| |
|E| / A |
|
1 |
4650 |
4800 |
-150 |
150 |
0,0323 |
|
2 |
4900 |
4700 |
200 |
200 |
0,0408 |
|
3 |
5100 |
5000 |
100 |
100 |
0,0196 |
|
4 |
4200 |
5000 |
-800 |
800 |
0,1905 |
|
5 |
4500 |
4400 |
100 |
100 |
0,0222 |
|
6 |
3900 |
4200 |
-300 |
300 |
0,0769 |
|
7 |
3300 |
3800 |
-500 |
500 |
0,1515 |
|
8 |
3600 |
3600 |
0 |
0 |
0,0000 |
|
9 |
3900 |
3800 |
100 |
100 |
0,0256 |
|
10 |
4100 |
4000 |
100 |
100 |
0,0244 |
|
42150 |
43300 |
-1150 |
2350 |
0,5839 |
|
|
BIAS = |
-115 |
||||
|
MAD = |
235 |
||||
|
MAPE = |
5,84% |
||||
Эти показатели можно использовать также и по группе SKU, чтобы оценить точность прогноза продаж группы за период времени. В таком случае, мы берем один период времени, например, месяц и считаем MAD и BIAS для каждого SKU:
|
SKU |
Факт |
Прогноз |
Е |
|E| |
|E| / A |
|
SKU 1 |
3000 |
3200 |
-200 |
200 |
0,0667 |
|
SKU 2 |
2900 |
3000 |
-100 |
100 |
0,0345 |
|
SKU 3 |
3400 |
3000 |
400 |
400 |
0,1176 |
|
SKU 4 |
3600 |
3400 |
200 |
200 |
0,0556 |
|
SKU 5 |
3500 |
3500 |
0 |
0 |
0,0000 |
|
300 |
900 |
0,2744 |
|||
|
BIAS = |
60 |
||||
|
MAD = |
180 |
||||
|
MAPE = |
5,49% |
||||
Еще одним наглядным показателем для измерения точности прогноза является непосредственно Forecast Accuracy, который показывает, насколько, собственно, прогноз оказался точным:
FA = (1 – |E|/A)*100%
|
SKU |
Продажи |
Прогноз |
Е |
|E| |
|E| / A |
FA |
|
SKU 1 |
3000 |
3200 |
-200 |
200 |
0,067 |
93,3% |
|
SKU 2 |
2900 |
3000 |
-100 |
100 |
0,034 |
96,6% |
|
SKU 3 |
3400 |
3000 |
400 |
400 |
0,118 |
88,2% |
|
SKU 4 |
3600 |
3400 |
200 |
200 |
0,056 |
94,4% |
|
SKU 5 |
3500 |
3500 |
0 |
0 |
0,000 |
100,0% |
|
16400 |
900 |
0,055 |
94,5% |
Показатели точности измерения прогноза продаж MAD, BIAS, MAPE и FA необходимо измерять на регулярной основе и рассматривать в рамках S&OP (Sales and Operations) процесса.
Измерение и обсуждение описанных выше показателей позволяет значительно улучшить уровень коммуникации между продажами и производством. Рекомендую всем, кто этого ещё не сделал, брать на вооружение.
Тарас Пархомчук.
Методы оценки качества прогноза
Время на прочтение
3 мин
Количество просмотров 30K
Часто при составлении любого прогноза — забывают про способы оценки его результатов. Потому как часто бывает, прогноз есть, а сравнение его с фактом отсутствует. Еще больше ошибок случается, когда существуют две (или больше) модели и не всегда очевидно — какая из них лучше, точнее. Как правило одной цифрой (R2) сложно обойтись. Как если бы вам сказали — этот парень ходит в синей футболке. И вам сразу все стало про него ясно )
В статьях о методах прогнозирования при оценке полученной модели я постоянно использовал такие аббревиатуры или обозначения.
- R2
- MSE
- MAPE
- MAD
- Bias
Попробую объяснить, что я имел в виду.
Остатки
Итак, по порядку. Основная величина, через которую оценивается точность прогноза это остатки (иногда: ошибки, error, e). В общем виде это разность между спрогнозированными значениями и исходными данными (либо фактическими значениями). Естественно, что чем больше остатки тем сильнее мы ошиблись. Для вычисления сравнительных коэффициентов остатки преобразуют: либо берут по модулю, либо возводят в квадрат (см. таблицу, колонки 4,5,6). В сыром виде почти не используют, так как сумма отрицательных и положительных остатков может свести суммарную ошибку в ноль. А это глупо, сами понимаете.
Суровые MSE и R2
Когда нам требуется подогнать кривую под наши данные, то точность этой подгонки будет оцениваться программой по среднеквадратической ошибке (mean squared error, MSE). Рассчитывается по незамысловатой формуле
![]()
где n-количество наблюдений.
Соотвественно, программа, рассчитывая кривую подгонки, стремится минимизировать этот коэффициент. Квадраты остатков в числителе взяты именно по той причине, чтобы плюсы и минусы не взаимоуничтожились. Физического смысла MSE не имеет, но чем ближе к нулю, тем модель лучше.
Вторая абстрактная величина это R2 — коэффициент детерминации. Характеризует степень сходства исходных данных и предсказанных. В отличии от MSE не зависит от единиц измерения данных, поэтому поддается сравнению. Рассчитывается коэффициент по следующей формуле:
![]()
где Var(Y) — дисперсия исходных данных.
Безусловно коэффициент детерминации — важный критерий выбора модели. И если модель плохо коррелирует с исходными данными, она вряд ли будет иметь высокую предсказательную силу.

MAPE и MAD для сравнения моделей
Статистические методы оценки моделей вроде MSE и R2, к сожалению, трудно интерпретировать, поэтому светлые головы придумали облегченные, но удобные для сравнения коэффициенты.
Среднее абсолютное отклонение (mean absolute deviation, MAD) определяется как частное от суммы остатков по модулю к числу наблюдений. То есть, средний остаток по модулю. Удобно? Вроде да, а вроде и не очень. В моем примере MAD=43. Выраженный в абсолютных единицах MAD показывает насколько единиц в среднем будет ошибаться прогноз.
MAPE призван придать модели еще более наглядный смысл. Расшифровывается выражение как средняя абсолютная ошибка в процентах (mean percentage absolute error, MAPE).
![]()
где Y — значение исходного ряда.
Выражается MAPE в процентах, и в моем случае означает, что в модель может ошибаться в среднем на 16%. Что, согласитесь, вполне допустимо.
Наконец, последняя абсолютно синтетическая величина — это Bias, или просто смещение. Дело в том, что в реальном мире отклонения в одну сторону зачастую гораздо болезненнее, чем в другую. К примеру, при условно неограниченных складских помещениях, важнее учитывать скачки реального спроса вверх от спрогнозированных значений. Поэтому случаи, где остатки положительные относятся к общему числу наблюдений. В моем случае 44% спрогнозированных значений оказались ниже исходных. И можно пожертвовать другими критериями оценки, чтобы минимизировать этот Bias.
Можете попробовать это сами в ![]() Excel и
Excel и ![]() Numbers
Numbers
Интересно узнать — какие методы оценки качества прогнозирования вы используете в своей работе?
Подробности на блоге
Для анализа результатов расчета прогноза, в продолжение ряда вы можете рассчитать следующие ошибки:
- MAPE – средняя абсолютная ошибка в % . Ошибка оценивает на сколько велики ошибки в сравнении со значением ряда и с ошибками в соседних рядах.
Подробнее читайте в статье на нашем сайте: http://4analytics.ru/metodi-analiza/mape-%E2%80%93-srednyaya-absolyutnaya-oshibka-praktika-primeneniya.html - MRPE – средняя относительная ошибка в %, оценивает на сколько велика дельта между фактом и прогнозом. Чем ближе к 100%, тем больше ошибка, чем ближе к нулю, тем ошибка меньше.
- MSE – средняя квадратическая ошибка, подчеркивает большие ошибки за счет возведения каждой ошибки в квадрат.
Подробнее читайте в статье на нашем сайте:
http://4analytics.ru/metodi-analiza/mse-%E2%80%93-srednekvadraticheskaya-oshibka-v-excel.html - MPE – средняя процентная ошибка – показывает завышен или занижен прогноз относительно факта. Если ошибка меньше нулю, то прогноз последовательно завышен, если ошибка больше нуля, то прогноз последовательно занижен.
Подробнее читайте в статье на нашем сайте:
http://4analytics.ru/metodi-analiza/mpe-%E2%80%93-srednyaya-procentnaya-oshibka-v-excel.html - MAD – среднее абсолютное отклонение. Используется, когда важно измерить ошибку в тех же единицах, что и исходный ряд.
Подробнее читайте в статье на нашем сайте:
http://4analytics.ru/planirovanie-i-prognozirovanie-praktika/dopolnitelnie-oborotnie-sredstva-za-schet-povisheniya-tochnosti-prognoza.html - A MAPE – ошибка, которая показывает отклонение средних значений ряда к средним значениям модели прогноза. Имеет значение при неравномерном перераспределении значений ряда по периодам.
- S MAPE – ошибка, которая показывает отклонение суммы значения ряда к сумме значений модели прогноза. Имеет значение при неравномерном перераспределении значений ряда по периодам.
А также 2 показателя «Точность прогноза»:
- Точность прогноза = 1 – МАРЕ
- Точность прогноза 2 = 1 – MRPE
Для расчета ошибок одновременно с прогнозом, нажимаем кнопку «Расчет ошибок» в меню «FORECAST»

В открывшемся окне выбираем нужные для расчета ошибки:
Теперь при расчете прогноза, в продолжение ряда, программа автоматически сделает расчет отмеченных Вами ошибок:
