Нейронные сети обучаются с помощью тех или иных модификаций градиентного спуска, а чтобы применять его, нужно уметь эффективно вычислять градиенты функции потерь по всем обучающим параметрам. Казалось бы, для какого-нибудь запутанного вычислительного графа это может быть очень сложной задачей, но на помощь спешит метод обратного распространения ошибки.
Открытие метода обратного распространения ошибки стало одним из наиболее значимых событий в области искусственного интеллекта. В актуальном виде он был предложен в 1986 году Дэвидом Э. Румельхартом, Джеффри Э. Хинтоном и Рональдом Дж. Вильямсом и независимо и одновременно красноярскими математиками С. И. Барцевым и В. А. Охониным. С тех пор для нахождения градиентов параметров нейронной сети используется метод вычисления производной сложной функции, и оценка градиентов параметров сети стала хоть сложной инженерной задачей, но уже не искусством. Несмотря на простоту используемого математического аппарата, появление этого метода привело к значительному скачку в развитии искусственных нейронных сетей.
Суть метода можно записать одной формулой, тривиально следующей из формулы производной сложной функции: если $f(x) = g_m(g_{m-1}(\ldots (g_1(x)) \ldots))$, то $\frac{\partial f}{\partial x} = \frac{\partial g_m}{\partial g_{m-1}}\frac{\partial g_{m-1}}{\partial g_{m-2}}\ldots \frac{\partial g_2}{\partial g_1}\frac{\partial g_1}{\partial x}$. Уже сейчас мы видим, что градиенты можно вычислять последовательно, в ходе одного обратного прохода, начиная с $\frac{\partial g_m}{\partial g_{m-1}}$ и умножая каждый раз на частные производные предыдущего слоя.
Backpropagation в одномерном случае
В одномерном случае всё выглядит особенно просто. Пусть $w_0$ — переменная, по которой мы хотим продифференцировать, причём сложная функция имеет вид
$$f(w_0) = g_m(g_{m-1}(\ldots g_1(w_0)\ldots)),$$
где все $g_i$ скалярные. Тогда
$$f'(w_0) = g_m'(g_{m-1}(\ldots g_1(w_0)\ldots))\cdot g’_{m-1}(g_{m-2}(\ldots g_1(w_0)\ldots))\cdot\ldots \cdot g’_1(w_0)$$
Суть этой формулы такова. Если мы уже совершили forward pass, то есть уже знаем
$$g_1(w_0), g_2(g_1(w_0)),\ldots,g_{m-1}(\ldots g_1(w_0)\ldots),$$
то мы действуем следующим образом:
-
берём производную $g_m$ в точке $g_{m-1}(\ldots g_1(w_0)\ldots)$;
-
умножаем на производную $g_{m-1}$ в точке $g_{m-2}(\ldots g_1(w_0)\ldots)$;
-
и так далее, пока не дойдём до производной $g_1$ в точке $w_0$.
Проиллюстрируем это на картинке, расписав по шагам дифференцирование по весам $w_i$ функции потерь логистической регрессии на одном объекте (то есть для батча размера 1):

Собирая все множители вместе, получаем:
$$\frac{\partial f}{\partial w_0} = (-y)\cdot e^{-y(w_0 + w_1x_1 + w_2x_2)}\cdot\frac{-1}{1 + e^{-y(w_0 + w_1x_1 + w_2x_2)}}$$
$$\frac{\partial f}{\partial w_1} = x_1\cdot(-y)\cdot e^{-y(w_0 + w_1x_1 + w_2x_2)}\cdot\frac{-1}{1 + e^{-y(w_0 + w_1x_1 + w_2x_2)}}$$
$$\frac{\partial f}{\partial w_2} = x_2\cdot(-y)\cdot e^{-y(w_0 + w_1x_1 + w_2x_2)}\cdot\frac{-1}{1 + e^{-y(w_0 + w_1x_1 + w_2x_2)}}$$
Таким образом, мы видим, что сперва совершается forward pass для вычисления всех промежуточных значений (и да, все промежуточные представления нужно будет хранить в памяти), а потом запускается backward pass, на котором в один проход вычисляются все градиенты.
Почему же нельзя просто пойти и начать везде вычислять производные?
В главе, посвящённой матричным дифференцированиям, мы поднимаем вопрос о том, что вычислять частные производные по отдельности — это зло, лучше пользоваться матричными вычислениями. Но есть и ещё одна причина: даже и с матричной производной в принципе не всегда хочется иметь дело. Рассмотрим простой пример. Допустим, что $X^r$ и $X^{r+1}$ — два последовательных промежуточных представления $N\times M$ и $N\times K$, связанных функцией $X^{r+1} = f^{r+1}(X^r)$. Предположим, что мы как-то посчитали производную $\frac{\partial\mathcal{L}}{\partial X^{r+1}_{ij}}$ функции потерь $\mathcal{L}$, тогда
$$\frac{\partial\mathcal{L}}{\partial X^{r}_{st}} = \sum_{i,j}\frac{\partial f^{r+1}_{ij}}{\partial X^{r}_{st}}\frac{\partial\mathcal{L}}{\partial X^{r+1}_{ij}}$$
И мы видим, что, хотя оба градиента $\frac{\partial\mathcal{L}}{\partial X_{ij}^{r+1}}$ и $\frac{\partial\mathcal{L}}{\partial X_{st}^{r}}$ являются просто матрицами, в ходе вычислений возникает «четырёхмерный кубик» $\frac{\partial f_{ij}^{r+1}}{\partial X_{st}^{r}}$, даже хранить который весьма болезненно: уж больно много памяти он требует ($N^2MK$ по сравнению с безобидными $NM + NK$, требуемыми для хранения градиентов). Поэтому хочется промежуточные производные $\frac{\partial f^{r+1}}{\partial X^{r}}$ рассматривать не как вычисляемые объекты $\frac{\partial f_{ij}^{r+1}}{\partial X_{st}^{r}}$, а как преобразования, которые превращают $\frac{\partial\mathcal{L}}{\partial X_{ij}^{r+1}}$ в $\frac{\partial\mathcal{L}}{\partial X_{st}^{r}}$. Целью следующих глав будет именно это: понять, как преобразуется градиент в ходе error backpropagation при переходе через тот или иной слой.
Вы спросите себя: надо ли мне сейчас пойти и прочитать главу учебника про матричное дифференцирование?
Встречный вопрос. Найдите производную функции по вектору $x$:
$$f(x) = x^TAx,\ A\in Mat_{n}{\mathbb{R}}\text{ — матрица размера }n\times n$$
А как всё поменяется, если $A$ тоже зависит от $x$? Чему равен градиент функции, если $A$ является скаляром? Если вы готовы прямо сейчас взять ручку и бумагу и посчитать всё, то вам, вероятно, не надо читать про матричные дифференцирования. Но мы советуем всё-таки заглянуть в эту главу, если обозначения, которые мы будем дальше использовать, покажутся вам непонятными: единой нотации для матричных дифференцирований человечество пока, увы, не изобрело, и переводить с одной на другую не всегда легко.
Мы же сразу перейдём к интересующей нас вещи: к вычислению градиентов сложных функций.
Градиент сложной функции
Напомним, что формула производной сложной функции выглядит следующим образом:
$$\left[D_{x_0} (\color{#5002A7}{u} \circ \color{#4CB9C0}{v}) \right](h) = \color{#5002A7}{\left[D_{v(x_0)} u \right]} \left( \color{#4CB9C0}{\left[D_{x_0} v\right]} (h)\right)$$
Теперь разберёмся с градиентами. Пусть $f(x) = g(h(x))$ – скалярная функция. Тогда
$$\left[D_{x_0} f \right] (x-x_0) = \langle\nabla_{x_0} f, x-x_0\rangle.$$
С другой стороны,
$$\left[D_{h(x_0)} g \right] \left(\left[D_{x_0}h \right] (x-x_0)\right) = \langle\nabla_{h_{x_0}} g, \left[D_{x_0} h\right] (x-x_0)\rangle = \langle\left[D_{x_0} h\right]^* \nabla_{h(x_0)} g, x-x_0\rangle.$$
То есть $\color{#FFC100}{\nabla_{x_0} f} = \color{#348FEA}{\left[D_{x_0} h \right]}^* \color{#FFC100}{\nabla_{h(x_0)}}g$ — применение сопряжённого к $D_{x_0} h$ линейного отображения к вектору $\nabla_{h(x_0)} g$.
Эта формула — сердце механизма обратного распространения ошибки. Она говорит следующее: если мы каким-то образом получили градиент функции потерь по переменным из некоторого промежуточного представления $X^k$ нейронной сети и при этом знаем, как преобразуется градиент при проходе через слой $f^k$ между $X^{k-1}$ и $X^k$ (то есть как выглядит сопряжённое к дифференциалу слоя между ними отображение), то мы сразу же находим градиент и по переменным из $X^{k-1}$:

Таким образом слой за слоем мы посчитаем градиенты по всем $X^i$ вплоть до самых первых слоёв.
Далее мы разберёмся, как именно преобразуются градиенты при переходе через некоторые распространённые слои.
Градиенты для типичных слоёв
Рассмотрим несколько важных примеров.
Примеры
-
$f(x) = u(v(x))$, где $x$ — вектор, а $v(x)$ – поэлементное применение $v$:
$$v\begin{pmatrix}
x_1 \\
\vdots\\
x_N
\end{pmatrix}
= \begin{pmatrix}
v(x_1)\\
\vdots\\
v(x_N)
\end{pmatrix}$$Тогда, как мы знаем,
$$\left[D_{x_0} f\right] (h) = \langle\nabla_{x_0} f, h\rangle = \left[\nabla_{x_0} f\right]^T h.$$
Следовательно,
$$
\left[D_{v(x_0)} u\right] \left( \left[ D_{x_0} v\right] (h)\right) = \left[\nabla_{v(x_0)} u\right]^T \left(v'(x_0) \odot h\right) =\\
$$$$
= \sum\limits_i \left[\nabla_{v(x_0)} u\right]_i v'(x_{0i})h_i
= \langle\left[\nabla_{v(x_0)} u\right] \odot v'(x_0), h\rangle.
,$$где $\odot$ означает поэлементное перемножение. Окончательно получаем
$$\color{#348FEA}{\nabla_{x_0} f = \left[\nabla_{v(x_0)}u\right] \odot v'(x_0) = v'(x_0) \odot \left[\nabla_{v(x_0)} u\right]}$$
Отметим, что если $x$ и $h(x)$ — это просто векторы, то мы могли бы вычислять всё и по формуле $\frac{\partial f}{\partial x_i} = \sum_j\big(\frac{\partial z_j}{\partial x_i}\big)\cdot\big(\frac{\partial h}{\partial z_j}\big)$. В этом случае матрица $\big(\frac{\partial z_j}{\partial x_i}\big)$ была бы диагональной (так как $z_j$ зависит только от $x_j$: ведь $h$ берётся поэлементно), и матричное умножение приводило бы к тому же результату. Однако если $x$ и $h(x)$ — матрицы, то $\big(\frac{\partial z_j}{\partial x_i}\big)$ представлялась бы уже «четырёхмерным кубиком», и работать с ним было бы ужасно неудобно.
-
$f(X) = g(XW)$, где $X$ и $W$ — матрицы. Как мы знаем,
$$\left[D_{X_0} f \right] (X-X_0) = \text{tr}, \left(\left[\nabla_{X_0} f\right]^T (X-X_0)\right).$$
Тогда
$$
\left[ D_{X_0W} g \right] \left(\left[D_{X_0} \left( \ast W\right)\right] (H)\right) =
\left[ D_{X_0W} g \right] \left(HW\right)=\\
$$ $$
= \text{tr}\, \left( \left[\nabla_{X_0W} g \right]^T \cdot (H) W \right) =\\
$$ $$
=
\text{tr} \, \left(W \left[\nabla_{X_0W} (g) \right]^T \cdot (H)\right) = \text{tr} \, \left( \left[\left[\nabla_{X_0W} g\right] W^T\right]^T (H)\right)
$$Здесь через $\ast W$ мы обозначили отображение $Y \hookrightarrow YW$, а в предпоследнем переходе использовалось следующее свойство следа:
$$
\text{tr} , (A B C) = \text{tr} , (C A B),
$$где $A, B, C$ — произвольные матрицы подходящих размеров (то есть допускающие перемножение в обоих приведённых порядках). Следовательно, получаем
$$\color{#348FEA}{\nabla_{X_0} f = \left[\nabla_{X_0W} (g) \right] \cdot W^T}$$
-
$f(W) = g(XW)$, где $W$ и $X$ — матрицы. Для приращения $H = W — W_0$ имеем
$$
\left[D_{W_0} f \right] (H) = \text{tr} , \left( \left[\nabla_{W_0} f \right]^T (H)\right)
$$Тогда
$$
\left[D_{XW_0} g \right] \left( \left[D_{W_0} \left(X \ast\right) \right] (H)\right) = \left[D_{XW_0} g \right] \left( XH \right) = \
$$ $$
= \text{tr} , \left( \left[\nabla_{XW_0} g \right]^T \cdot X (H)\right) =
\text{tr}, \left(\left[X^T \left[\nabla_{XW_0} g \right] \right]^T (H)\right)
$$Здесь через $X \ast$ обозначено отображение $Y \hookrightarrow XY$. Значит,
$$\color{#348FEA}{\nabla_{X_0} f = X^T \cdot \left[\nabla_{XW_0} (g)\right]}$$
-
$f(X) = g(softmax(X))$, где $X$ — матрица $N\times K$, а $softmax$ — функция, которая вычисляется построчно, причём для каждой строки $x$
$$softmax(x) = \left(\frac{e^{x_1}}{\sum_te^{x_t}},\ldots,\frac{e^{x_K}}{\sum_te^{x_t}}\right)$$
В этом примере нам будет удобно воспользоваться формализмом с частными производными. Сначала вычислим $\frac{\partial s_l}{\partial x_j}$ для одной строки $x$, где через $s_l$ мы для краткости обозначим $softmax(x)_l = \frac{e^{x_l}} {\sum_te^{x_t}}$. Нетрудно проверить, что
$$\frac{\partial s_l}{\partial x_j} = \begin{cases}
s_j(1 — s_j),\ & j = l,\
-s_ls_j,\ & j\ne l
\end{cases}$$Так как softmax вычисляется независимо от каждой строчки, то
$$\frac{\partial s_{rl}}{\partial x_{ij}} = \begin{cases}
s_{ij}(1 — s_{ij}),\ & r=i, j = l,\
-s_{il}s_{ij},\ & r = i, j\ne l,\
0,\ & r\ne i
\end{cases},$$где через $s_{rl}$ мы обозначили для краткости $softmax(X)_{rl}$.
Теперь пусть $\nabla_{rl} = \nabla g = \frac{\partial\mathcal{L}}{\partial s_{rl}}$ (пришедший со следующего слоя, уже известный градиент). Тогда
$$\frac{\partial\mathcal{L}}{\partial x_{ij}} = \sum_{r,l}\frac{\partial s_{rl}}{\partial x_{ij}} \nabla_{rl}$$
Так как $\frac{\partial s_{rl}}{\partial x_{ij}} = 0$ при $r\ne i$, мы можем убрать суммирование по $r$:
$$\ldots = \sum_{l}\frac{\partial s_{il}}{\partial x_{ij}} \nabla_{il} = -s_{i1}s_{ij}\nabla_{i1} — \ldots + s_{ij}(1 — s_{ij})\nabla_{ij}-\ldots — s_{iK}s_{ij}\nabla_{iK} =$$
$$= -s_{ij}\sum_t s_{it}\nabla_{it} + s_{ij}\nabla_{ij}$$
Таким образом, если мы хотим продифференцировать $f$ в какой-то конкретной точке $X_0$, то, смешивая математические обозначения с нотацией Python, мы можем записать:
$$\begin{multline*}
\color{#348FEA}{\nabla_{X_0}f =}\\
\color{#348FEA}{= -softmax(X_0) \odot \text{sum}\left(
softmax(X_0)\odot\nabla_{softmax(X_0)}g, \text{ axis = 1}
\right) +}\\
\color{#348FEA}{softmax(X_0)\odot \nabla_{softmax(X_0)}g}
\end{multline*}
$$
Backpropagation в общем виде
Подытожим предыдущее обсуждение, описав алгоритм error backpropagation (алгоритм обратного распространения ошибки). Допустим, у нас есть текущие значения весов $W^i_0$ и мы хотим совершить шаг SGD по мини-батчу $X$. Мы должны сделать следующее:
- Совершить forward pass, вычислив и запомнив все промежуточные представления $X = X^0, X^1, \ldots, X^m = \widehat{y}$.
- Вычислить все градиенты с помощью backward pass.
- С помощью полученных градиентов совершить шаг SGD.
Проиллюстрируем алгоритм на примере двуслойной нейронной сети со скалярным output’ом. Для простоты опустим свободные члены в линейных слоях.
 Обучаемые параметры – матрицы $U$ и $W$. Как найти градиенты по ним в точке $U_0, W_0$?
Обучаемые параметры – матрицы $U$ и $W$. Как найти градиенты по ним в точке $U_0, W_0$?
$$\nabla_{W_0}\mathcal{L} = \nabla_{W_0}{\left({\vphantom{\frac12}\mathcal{L}\circ h\circ\left[W\mapsto g(XU_0)W\right]}\right)}=$$
$$=g(XU_0)^T\nabla_{g(XU_0)W_0}(\mathcal{L}\circ h) = \underbrace{g(XU_0)^T}_{k\times N}\cdot
\left[\vphantom{\frac12}\underbrace{h’\left(\vphantom{\int_0^1}g(XU_0)W_0\right)}_{N\times 1}\odot
\underbrace{\nabla_{h\left(\vphantom{\int_0^1}g(XU_0)W_0\right)}\mathcal{L}}_{N\times 1}\right]$$
Итого матрица $k\times 1$, как и $W_0$
$$\nabla_{U_0}\mathcal{L} = \nabla_{U_0}\left(\vphantom{\frac12}
\mathcal{L}\circ h\circ\left[Y\mapsto YW_0\right]\circ g\circ\left[ U\mapsto XU\right]
\right)=$$
$$=X^T\cdot\nabla_{XU^0}\left(\vphantom{\frac12}\mathcal{L}\circ h\circ [Y\mapsto YW_0]\circ g\right) =$$
$$=X^T\cdot\left(\vphantom{\frac12}g'(XU_0)\odot
\nabla_{g(XU_0)}\left[\vphantom{\in_0^1}\mathcal{L}\circ h\circ[Y\mapsto YW_0\right]
\right)$$
$$=\ldots = \underset{D\times N}{X^T}\cdot\left(\vphantom{\frac12}
\underbrace{g'(XU_0)}_{N\times K}\odot
\underbrace{\left[\vphantom{\int_0^1}\left(
\underbrace{h’\left(\vphantom{\int_0^1}g(XU_0)W_0\right)}_{N\times1}\odot\underbrace{\nabla_{h(\vphantom{\int_0^1}g\left(XU_0\right)W_0)}\mathcal{L}}_{N\times 1}
\right)\cdot \underbrace{W^T}_{1\times K}\right]}_{N\times K}
\right)$$
Итого $D\times K$, как и $U_0$
Схематически это можно представить следующим образом:

Backpropagation для двуслойной нейронной сети
Подробнее о предыдущих вычисленияхЕсли вы не уследили за вычислениями в предыдущем примере, давайте более подробно разберём его чуть более конкретную версию (для $g = h = \sigma$).
Рассмотрим двуслойную нейронную сеть для классификации. Мы уже встречали ее ранее при рассмотрении линейно неразделимой выборки. Предсказания получаются следующим образом:
$$
\widehat{y} = \sigma(X^1 W^2) = \sigma\Big(\big(\sigma(X^0 W^1 )\big) W^2 \Big).
$$
Пусть $W^1_0$ и $W^2_0$ — текущее приближение матриц весов. Мы хотим совершить шаг по градиенту функции потерь, и для этого мы должны вычислить её градиенты по $W^1$ и $W^2$ в точке $(W^1_0, W^2_0)$.
Прежде всего мы совершаем forward pass, в ходе которого мы должны запомнить все промежуточные представления: $X^1 = X^0 W^1_0$, $X^2 = \sigma(X^0 W^1_0)$, $X^3 = \sigma(X^0 W^1_0) W^2_0$, $X^4 = \sigma(\sigma(X^0 W^1_0) W^2_0) = \widehat{y}$. Они понадобятся нам дальше.
Для полученных предсказаний вычисляется значение функции потерь:
$$
l = \mathcal{L}(y, \widehat{y}) = y \log(\widehat{y}) + (1-y) \log(1-\widehat{y}).
$$
Дальше мы шаг за шагом будем находить производные по переменным из всё более глубоких слоёв.
-
Градиент $\mathcal{L}$ по предсказаниям имеет вид
$$
\nabla_{\widehat{y}}l = \frac{y}{\widehat{y}} — \frac{1 — y}{1 — \widehat{y}} = \frac{y — \widehat{y}}{\widehat{y} (1 — \widehat{y})},
$$где, напомним, $ \widehat{y} = \sigma(X^3) = \sigma\Big(\big(\sigma(X^0 W^1_0 )\big) W^2_0 \Big)$ (обратите внимание на то, что $W^1_0$ и $W^2_0$ тут именно те, из которых мы делаем градиентный шаг).
-
Следующий слой — поэлементное взятие $\sigma$. Как мы помним, при переходе через него градиент поэлементно умножается на производную $\sigma$, в которую подставлено предыдущее промежуточное представление:
$$
\nabla_{X^3}l = \sigma'(X^3)\odot\nabla_{\widehat{y}}l = \sigma(X^3)\left( 1 — \sigma(X^3) \right) \odot \frac{y — \widehat{y}}{\widehat{y} (1 — \widehat{y})} =
$$$$
= \sigma(X^3)\left( 1 — \sigma(X^3) \right) \odot \frac{y — \sigma(X^3)}{\sigma(X^3) (1 — \sigma(X^3))} =
y — \sigma(X^3)
$$ -
Следующий слой — умножение на $W^2_0$. В этот момент мы найдём градиент как по $W^2$, так и по $X^2$. При переходе через умножение на матрицу градиент, как мы помним, умножается с той же стороны на транспонированную матрицу, а значит:
$$
\color{blue}{\nabla_{W^2_0}l} = (X^2)^T\cdot \nabla_{X^3}l = (X^2)^T\cdot(y — \sigma(X^3)) =
$$$$
= \color{blue}{\left( \sigma(X^0W^1_0) \right)^T \cdot (y — \sigma(\sigma(X^0W^1_0)W^2_0))}
$$Аналогичным образом
$$
\nabla_{X^2}l = \nabla_{X^3}l\cdot (W^2_0)^T = (y — \sigma(X^3))\cdot (W^2_0)^T =
$$$$
= (y — \sigma(X^2W_0^2))\cdot (W^2_0)^T
$$ -
Следующий слой — снова взятие $\sigma$.
$$
\nabla_{X^1}l = \sigma'(X^1)\odot\nabla_{X^2}l = \sigma(X^1)\left( 1 — \sigma(X^1) \right) \odot \left( (y — \sigma(X^2W_0^2))\cdot (W^2_0)^T \right) =
$$$$
= \sigma(X^1)\left( 1 — \sigma(X^1) \right) \odot\left( (y — \sigma(\sigma(X^1)W_0^2))\cdot (W^2_0)^T \right)
$$ -
Наконец, последний слой — это умножение $X^0$ на $W^1_0$. Тут мы дифференцируем только по $W^1$:
$$
\color{blue}{\nabla_{W^1_0}l} = (X^0)^T\cdot \nabla_{X^1}l = (X^0)^T\cdot \big( \sigma(X^1) \left( 1 — \sigma(X^1) \right) \odot (y — \sigma(\sigma(X^1)W_0^2))\cdot (W^2_0)^T\big) =
$$$$
= \color{blue}{(X^0)^T\cdot\big(\sigma(X^0W^1_0)\left( 1 — \sigma(X^0W^1_0) \right) \odot (y — \sigma(\sigma(X^0W^1_0)W_0^2))\cdot (W^2_0)^T\big) }
$$
Итоговые формулы для градиентов получились страшноватыми, но они были получены друг из друга итеративно с помощью очень простых операций: матричного и поэлементного умножения, в которые порой подставлялись значения заранее вычисленных промежуточных представлений.
Автоматизация и autograd
Итак, чтобы нейросеть обучалась, достаточно для любого слоя $f^k: X^{k-1}\mapsto X^k$ с параметрами $W^k$ уметь:
- превращать $\nabla_{X^k_0}\mathcal{L}$ в $\nabla_{X^{k-1}_0}\mathcal{L}$ (градиент по выходу в градиент по входу);
- считать градиент по его параметрам $\nabla_{W^k_0}\mathcal{L}$.
При этом слою совершенно не надо знать, что происходит вокруг. То есть слой действительно может быть запрограммирован как отдельная сущность, умеющая внутри себя делать forward pass и backward pass, после чего слои механически, как кубики в конструкторе, собираются в большую сеть, которая сможет работать как одно целое.
Более того, во многих случаях авторы библиотек для глубинного обучения уже о вас позаботились и создали средства для автоматического дифференцирования выражений (autograd). Поэтому, программируя нейросеть, вы почти всегда можете думать только о forward-проходе, прямом преобразовании данных, предоставив библиотеке дифференцировать всё самостоятельно. Это делает код нейросетей весьма понятным и выразительным (да, в реальности он тоже бывает большим и страшным, но сравните на досуге код какой-нибудь разухабистой нейросети и код градиентного бустинга на решающих деревьях и почувствуйте разницу).
Но это лишь начало
Метод обратного распространения ошибки позволяет удобно посчитать градиенты, но дальше с ними что-то надо делать, и старый добрый SGD едва ли справится с обучением современной сетки. Так что же делать? О некоторых приёмах мы расскажем в следующей главе.
Обратное распространение ошибки — это способ обучения нейронной сети. Цели обратного распространения просты: отрегулировать каждый вес пропорционально тому, насколько он способствует общей ошибке. Если мы будем итеративно уменьшать ошибку каждого веса, в конце концов у нас будет ряд весов, которые дают хорошие прогнозы.
Обновление правила цепочки
Прямое распространение можно рассматривать как длинный ряд вложенных уравнений. Если вы так думаете о прямом распространении, то обратное распространение — это просто приложение правила цепочки (дифференцирования сложной функции) для поиска производных потерь по любой переменной во вложенном уравнении. С учётом функции прямого распространения:
f(x)=A(B(C(x)))
A, B, и C — функции активации на различных слоях. Пользуясь правилом цепочки, мы легко вычисляем производную f(x) по x:
f′(x)=f′(A)⋅A′(B)⋅B′(C)⋅C′(x)
Что насчёт производной относительно B? Чтобы найти производную по B, вы можете сделать вид, что B (C(x)) является константой, заменить ее переменной-заполнителем B, и продолжить поиск производной по B стандартно.
f′(B)=f′(A)⋅A′(B)
Этот простой метод распространяется на любую переменную внутри функции, и позволяет нам в точности определить влияние каждой переменной на общий результат.
Применение правила цепочки
Давайте используем правило цепочки для вычисления производной потерь по любому весу в сети. Правило цепочки поможет нам определить, какой вклад каждый вес вносит в нашу общую ошибку и направление обновления каждого веса, чтобы уменьшить ошибку. Вот уравнения, которые нужны, чтобы сделать прогноз и рассчитать общую ошибку или потерю:
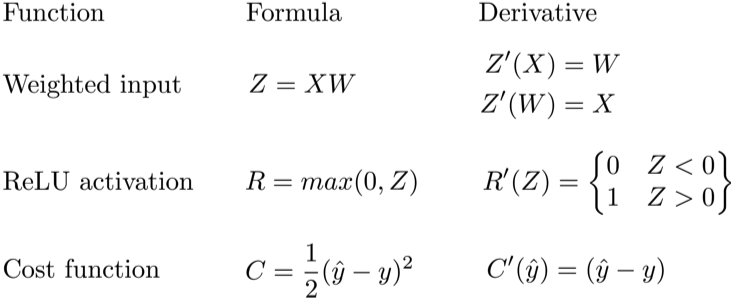
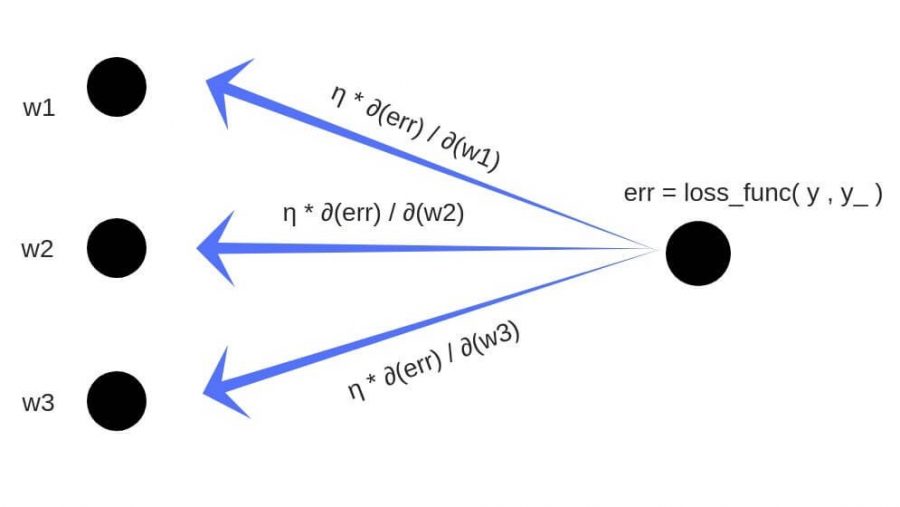
Учитывая сеть, состоящую из одного нейрона, общая потеря нейросети может быть рассчитана как:
Cost=C(R(Z(XW)))
Используя правило цепочки, мы легко можем найти производную потери относительно веса W.
C′(W)=C′(R)⋅R′(Z)⋅Z′(W)=(y^−y)⋅R′(Z)⋅X
Теперь, когда у нас есть уравнение для вычисления производной потери по любому весу, давайте обратимся к примеру с нейронной сетью:
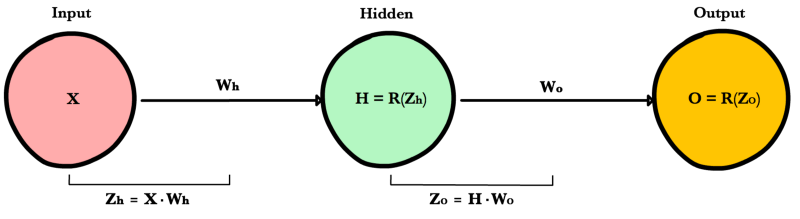
Какова производная от потери по Wo?
C′(WO)=C′(y^)⋅y^′(ZO)⋅Z′O(WO)=(y^−y)⋅R′(ZO)⋅H
А что насчет Wh? Чтобы узнать это, мы просто продолжаем возвращаться в нашу функцию, рекурсивно применяя правило цепочки, пока не доберемся до функции, которая имеет элемент Wh.
C′(Wh)=C′(y^)⋅O′(Zo)⋅Z′o(H)⋅H′(Zh)⋅Z′h(Wh)=(y^−y)⋅R′(Zo)⋅Wo⋅R′(Zh)⋅X
И просто забавы ради, что, если в нашей сети было бы 10 скрытых слоев. Что такое производная потери для первого веса w1?
C(w1)=(dC/dy^)⋅(dy^/dZ11)⋅(dZ11/dH10)⋅(dH10/dZ10)⋅(dZ10/dH9)⋅(dH9/dZ9)⋅(dZ9/dH8)⋅(dH8/dZ8)⋅(dZ8/dH7)⋅(dH7/dZ7)⋅(dZ7/dH6)⋅(dH6/dZ6)⋅(dZ6/dH5)⋅(dH5/dZ5)⋅(dZ5/dH4)⋅(dH4/dZ4)⋅(dZ4/dH3)⋅(dH3/dZ3)⋅(dZ3/dH2)⋅(dH2/dZ2)⋅(dZ2/dH1)⋅(dH1/dZ1)⋅(dZ1/dW1)
Заметили закономерность? Количество вычислений, необходимых для расчёта производных потерь, увеличивается по мере углубления нашей сети. Также обратите внимание на избыточность в наших расчетах производных. Производная потерь каждого слоя добавляет два новых элемента к элементам, которые уже были вычислены слоями над ним. Что, если бы был какой-то способ сохранить нашу работу и избежать этих повторяющихся вычислений?
Сохранение работы с мемоизацией
Мемоизация — это термин в информатике, имеющий простое значение: не пересчитывать одно и то же снова и снова. В мемоизации мы сохраняем ранее вычисленные результаты, чтобы избежать пересчета одной и той же функции. Это удобно для ускорения рекурсивных функций, одной из которых является обратное распространение. Обратите внимание на закономерность в уравнениях производных приведённых ниже.
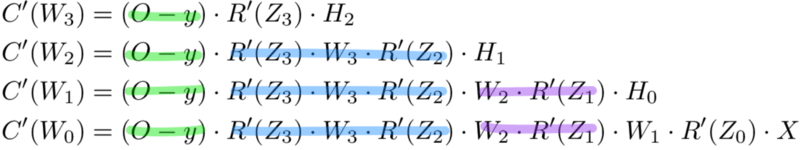
Каждый из этих слоев пересчитывает одни и те же производные! Вместо того, чтобы выписывать длинные уравнения производных для каждого веса, можно использовать мемоизацию, чтобы сохранить нашу работу, так как мы возвращаем ошибку через сеть. Для этого мы определяем 3 уравнения (ниже), которые вместе выражают в краткой форме все вычисления, необходимые для обратного распространения. Математика та же, но уравнения дают хорошее сокращение, которое мы можем использовать, чтобы отслеживать те вычисления, которые мы уже выполнили, и сохранять нашу работу по мере продвижения назад по сети.
Для начала мы вычисляем ошибку выходного слоя и передаем результат на скрытый слой перед ним. После вычисления ошибки скрытого слоя мы передаем ее значение обратно на предыдущий скрытый слой. И так далее и тому подобное. Возвращаясь назад по сети, мы применяем 3-ю формулу на каждом слое, чтобы вычислить производную потерь по весам этого слоя. Эта производная говорит нам, в каком направлении регулировать наши веса, чтобы уменьшить общие потери.
Примечание: термин ошибка слоя относится к производной потерь по входу в слой. Он отвечает на вопрос: как изменяется выход функции потерь при изменении входа в этот слой?
Ошибка выходного слоя
Для расчета ошибки выходного слоя необходимо найти производную потерь по входу выходному слою, Zo. Это отвечает на вопрос: как веса последнего слоя влияют на общую ошибку в сети? Тогда производная такова:
C′(Zo)=(y^−y)⋅R′(Zo)
Чтобы упростить запись, практикующие МО обычно заменяют последовательность (y^−y)∗R'(Zo) термином Eo. Итак, наша формула для ошибки выходного слоя равна:
Eo=(y^−y)⋅R′(Zo)
Ошибка скрытого слоя
Для вычисления ошибки скрытого слоя нужно найти производную потерь по входу скрытого слоя, Zh.
C′(Zh)=(y^−y)⋅R′(Zo)⋅Wo⋅R′(Zh)
Далее мы можем поменять местами элемент Eo выше, чтобы избежать дублирования и создать новое упрощенное уравнение для ошибки скрытого слоя:
Eh=Eo⋅Wo⋅R′(Zh)
Эта формула лежит в основе обратного распространения. Мы вычисляем ошибку текущего слоя и передаем взвешенную ошибку обратно на предыдущий слой, продолжая процесс, пока не достигнем нашего первого скрытого слоя. Попутно мы обновляем веса, используя производную потерь по каждому весу.
Производная потерь по любому весу
Вернемся к нашей формуле для производной потерь по весу выходного слоя Wo.
C′(WO)=(y^−y)⋅R′(ZO)⋅H
Мы знаем, что можем заменить первую часть уравнением для ошибки выходного слоя Eh. H представляет собой активацию скрытого слоя.
C′(Wo)=Eo⋅H
Таким образом, чтобы найти производную потерь по любому весу в нашей сети, мы просто умножаем ошибку соответствующего слоя на его вход (выход предыдущего слоя).
C′(w)=CurrentLayerError⋅CurrentLayerInput
Примечание: вход относится к активации с предыдущего слоя, а не к взвешенному входу, Z.
Подводя итог
Вот последние 3 уравнения, которые вместе образуют основу обратного распространения.
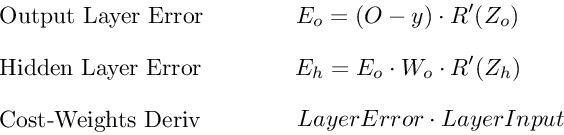
Вот процесс, визуализированный с использованием нашего примера нейронной сети выше:
Обратное распространение: пример кода
def relu_prime(z): if z > 0: return 1 return 0 def cost(yHat, y): return 0.5 * (yHat - y)**2 def cost_prime(yHat, y): return yHat - y def backprop(x, y, Wh, Wo, lr): yHat = feed_forward(x, Wh, Wo) # Layer Error Eo = (yHat - y) * relu_prime(Zo) Eh = Eo * Wo * relu_prime(Zh) # Cost derivative for weights dWo = Eo * H dWh = Eh * x # Update weights Wh -= lr * dWh Wo -= lr * dWo
Время на прочтение
5 мин
Количество просмотров 83K
В первой части были рассмотрены: структура, топология, функции активации и обучающее множество. В этой части попробую объяснить как происходит обучение сверточной нейронной сети.
Обучение сверточной нейронной сети
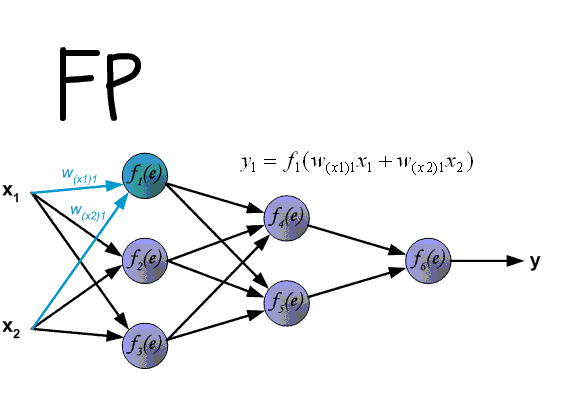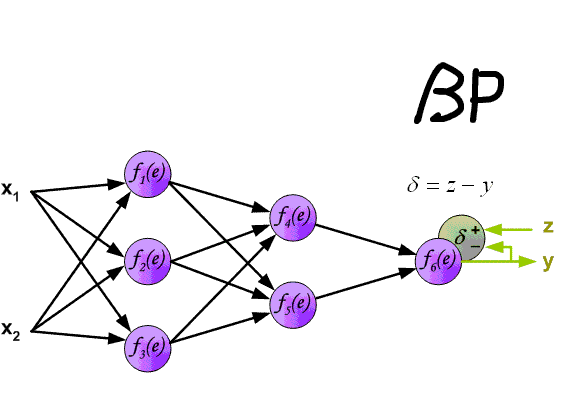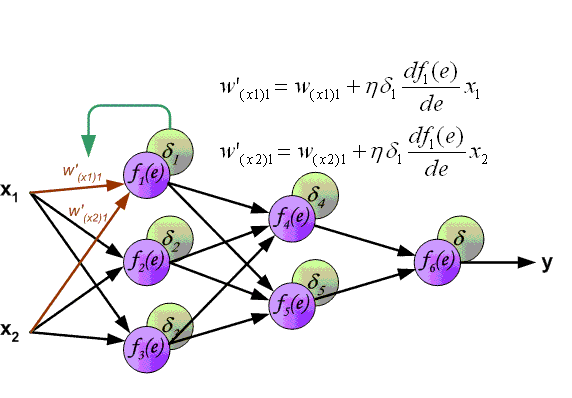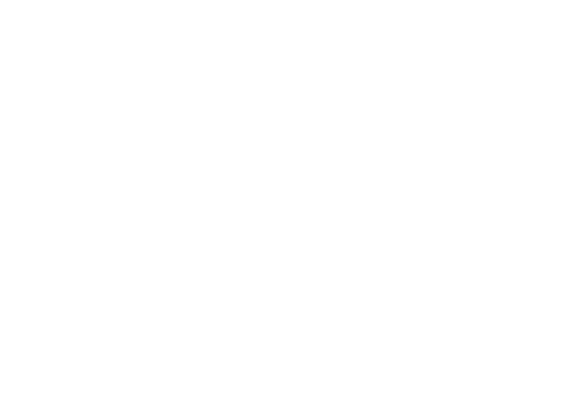
На начальном этапе нейронная сеть является необученной (ненастроенной). В общем смысле под обучением понимают последовательное предъявление образа на вход нейросети, из обучающего набора, затем полученный ответ сравнивается с желаемым выходом, в нашем случае это 1 – образ представляет лицо, минус 1 – образ представляет фон (не лицо), полученная разница между ожидаемым ответом и полученным является результат функции ошибки (дельта ошибки). Затем эту дельту ошибки необходимо распространить на все связанные нейроны сети.
Таким образом обучение нейронной сети сводится к минимизации функции ошибки, путем корректировки весовых коэффициентов синаптических связей между нейронами. Под функцией ошибки понимается разность между полученным ответом и желаемым. Например, на вход был подан образ лица, предположим, что выход нейросети был 0.73, а желаемый результат 1 (т.к. образ лица), получим, что ошибка сети является разницей, то есть 0.27. Затем веса выходного слоя нейронов корректируются в соответствии с ошибкой. Для нейронов выходного слоя известны их фактические и желаемые значения выходов. Поэтому настройка весов связей для таких нейронов является относительно простой. Однако для нейронов предыдущих слоев настройка не столь очевидна. Долгое время не было известно алгоритма распространения ошибки по скрытым слоям.
Алгоритм обратного распространения ошибки
Для обучения описанной нейронной сети был использован алгоритм обратного распространения ошибки (backpropagation). Этот метод обучения многослойной нейронной сети называется обобщенным дельта-правилом. Метод был предложен в 1986 г. Румельхартом, Макклеландом и Вильямсом. Это ознаменовало возрождение интереса к нейронным сетям, который стал угасать в начале 70-х годов. Данный алгоритм является первым и основным практически применимым для обучения многослойных нейронных сетей.
Для выходного слоя корректировка весов интуитивна понятна, но для скрытых слоев долгое время не было известно алгоритма. Веса скрытого нейрона должны изменяться прямо пропорционально ошибке тех нейронов, с которыми данный нейрон связан. Вот почему обратное распространение этих ошибок через сеть позволяет корректно настраивать веса связей между всеми слоями. В этом случае величина функции ошибки уменьшается и сеть обучается.
Основные соотношения метода обратного распространения ошибки получены при следующих обозначениях:

Величина ошибки определяется по формуле 2.8 среднеквадратичная ошибка:

Неактивированное состояние каждого нейрона j для образа p записывается в виде взвешенной суммы по формуле 2.9:

Выход каждого нейрона j является значением активационной функции
 , которая переводит нейрон в активированное состояние. В качестве функции активации может использоваться любая непрерывно дифференцируемая монотонная функция. Активированное состояние нейрона вычисляется по формуле 2.10:
, которая переводит нейрон в активированное состояние. В качестве функции активации может использоваться любая непрерывно дифференцируемая монотонная функция. Активированное состояние нейрона вычисляется по формуле 2.10:

В качестве метода минимизации ошибки используется метод градиентного спуска, суть этого метода сводится к поиску минимума (или максимума) функции за счет движения вдоль вектора градиента. Для поиска минимума движение должно быть осуществляться в направлении антиградиента. Метод градиентного спуска в соответствии с рисунком 2.7.

Градиент функции потери представляет из себя вектор частных производных, вычисляющийся по формуле 2.11:
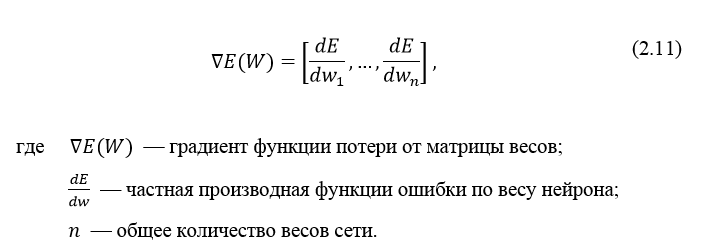
Производную функции ошибки по конкретному образу можно записать по правилу цепочки, формула 2.12:

Ошибка нейрона  обычно записывается в виде символа δ (дельта). Для выходного слоя ошибка определена в явном виде, если взять производную от формулы 2.8, то получим t минус y, то есть разницу между желаемым и полученным выходом. Но как рассчитать ошибку для скрытых слоев? Для решения этой задачи, как раз и был придуман алгоритм обратного распространения ошибки. Суть его заключается в последовательном вычислении ошибок скрытых слоев с помощью значений ошибки выходного слоя, т.е. значения ошибки распространяются по сети в обратном направлении от выхода к входу.
обычно записывается в виде символа δ (дельта). Для выходного слоя ошибка определена в явном виде, если взять производную от формулы 2.8, то получим t минус y, то есть разницу между желаемым и полученным выходом. Но как рассчитать ошибку для скрытых слоев? Для решения этой задачи, как раз и был придуман алгоритм обратного распространения ошибки. Суть его заключается в последовательном вычислении ошибок скрытых слоев с помощью значений ошибки выходного слоя, т.е. значения ошибки распространяются по сети в обратном направлении от выхода к входу.
Ошибка δ для скрытого слоя рассчитывается по формуле 2.13:

Алгоритм распространения ошибки сводится к следующим этапам:
- прямое распространение сигнала по сети, вычисления состояния нейронов;
- вычисление значения ошибки δ для выходного слоя;
- обратное распространение: последовательно от конца к началу для всех скрытых слоев вычисляем δ по формуле 2.13;
- обновление весов сети на вычисленную ранее δ ошибки.
Алгоритм обратного распространения ошибки в многослойном персептроне продемонстрирован ниже:
До этого момента были рассмотрены случаи распространения ошибки по слоям персептрона, то есть по выходному и скрытому, но помимо них, в сверточной нейросети имеются подвыборочный и сверточный.
Расчет ошибки на подвыборочном слое
Расчет ошибки на подвыборочном слое представляется в нескольких вариантах. Первый случай, когда подвыборочный слой находится перед полносвязным, тогда он имеет нейроны и связи такого же типа, как в полносвязном слое, соответственно вычисление δ ошибки ничем не отличается от вычисления δ скрытого слоя. Второй случай, когда подвыборочный слой находится перед сверточным, вычисление δ происходит путем обратной свертки. Для понимания обратно свертки, необходимо сперва понять обычную свертку и то, что скользящее окно по карте признаков (во время прямого распространения сигнала) можно интерпретировать, как обычный скрытый слой со связями между нейронами, но главное отличие — это то, что эти связи разделяемы, то есть одна связь с конкретным значением веса может быть у нескольких пар нейронов, а не только одной. Интерпретация операции свертки в привычном многослойном виде в соответствии с рисунком 2.8.
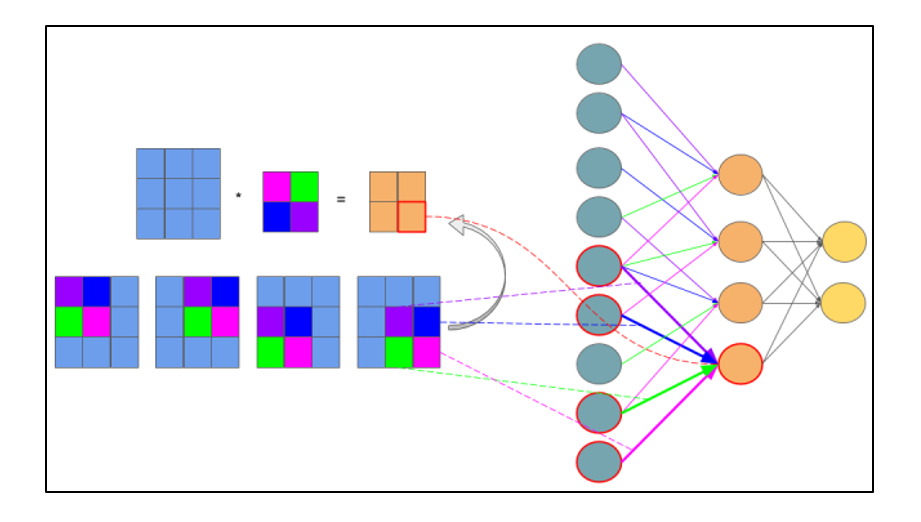
Рисунок 2.8 — Интерпретация операции свертки в многослойный вид, где связи с одинаковым цветом имеют один и тот же вес. Синим цветом обозначена подвыборочная карта, разноцветным – синаптическое ядро, оранжевым – получившаяся свертка
Теперь, когда операция свертки представлена в привычном многослойном виде, можно интуитивно понять, что вычисление дельт происходит таким же образом, как и в скрытом слое полносвязной сети. Соответственно имея вычисленные ранее дельты сверточного слоя можно вычислить дельты подвыборочного, в соответствии с рисунком 2.9.
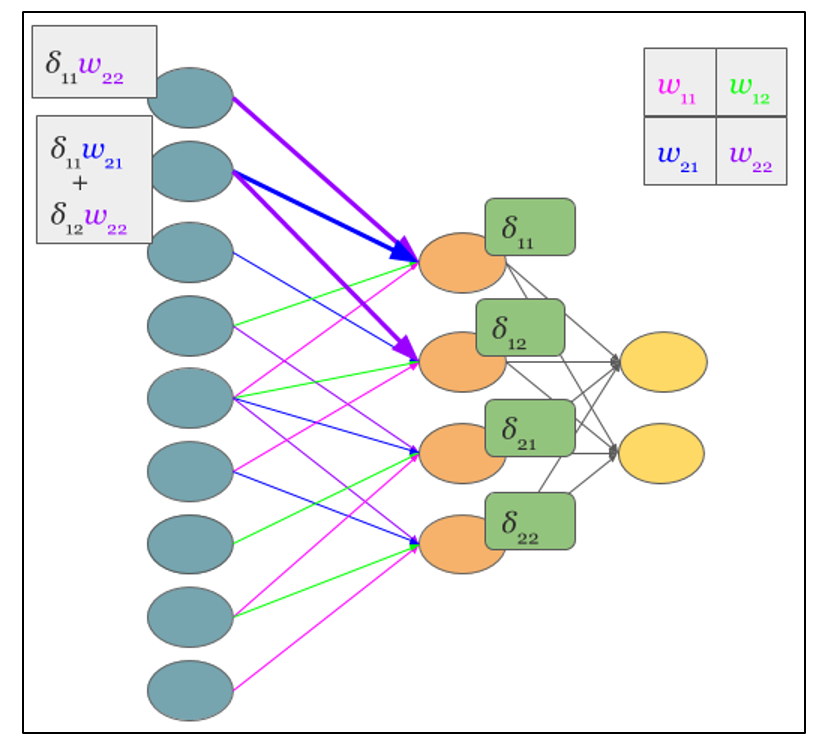
Рисунок 2.9 — Вычисление δ подвыборочного слоя за счет δ сверточного слоя и ядра
Обратная свертка – это тот же самый способ вычисления дельт, только немного хитрым способом, заключающийся в повороте ядра на 180 градусов и скользящем процессе сканирования сверточной карты дельт с измененными краевыми эффектами. Простыми словами, нам необходимо взять ядро сверточной карты (следующего за подвыборочным слоем) повернуть его на 180 градусов и сделать обычную свертку по вычисленным ранее дельтам сверточной карты, но так чтобы окно сканирования выходило за пределы карты. Результат операции обратной свертки в соответствии с рисунком 2.10, цикл прохода обратной свертки в соответствии с рисунком 2.11.

Рисунок 2.10 — Результат операции обратной свертки
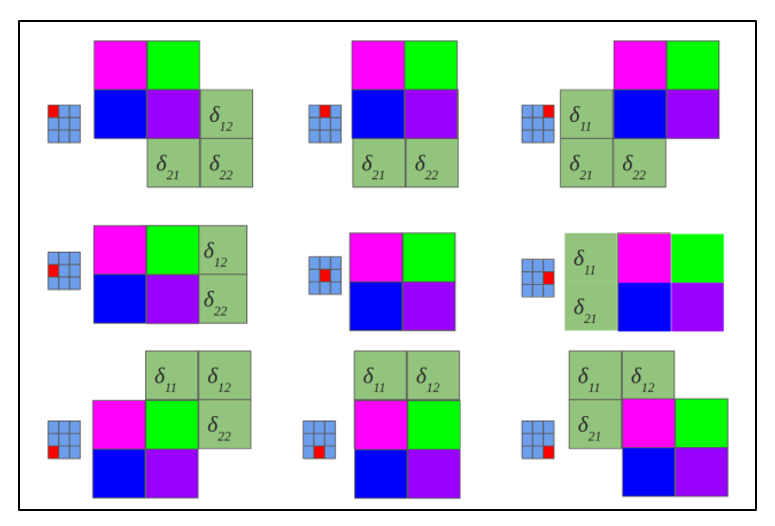
Рисунок 2.11 — Повернутое ядро на 180 градусов сканирует сверточную карту
Расчет ошибки на сверточном слое
Обычно впередиидущий слой после сверточного это подвыборочный, соответственно наша задача вычислить дельты текущего слоя (сверточного) за счет знаний о дельтах подвыборочного слоя. На самом деле дельта ошибка не вычисляется, а копируется. При прямом распространении сигнала нейроны подвыборочного слоя формировались за счет неперекрывающегося окна сканирования по сверточному слою, в процессе которого выбирались нейроны с максимальным значением, при обратном распространении, мы возвращаем дельту ошибки тому ранее выбранному максимальному нейрону, остальные же получают нулевую дельту ошибки.
Заключение
Представив операцию свертки в привычном многослойном виде (рисунок 2.8), можно интуитивно понять, что вычисление дельт происходит таким же образом, как и в скрытом слое полносвязной сети.
Источники
Алгоритм обратного распространения ошибки для сверточной нейронной сети
Обратное распространение ошибки в сверточных слоях
раз и два
Обратное распространение ошибки в персептроне
Еще можно почитать в РГБ диссертацию Макаренко: АЛГОРИТМЫ И ПРОГРАММНАЯ СИСТЕМА КЛАССИФИКАЦИИ
Время на прочтение
19 мин
Количество просмотров 287K
Тема нейронных сетей была уже ни раз освещена на хабре, однако сегодня я бы хотел познакомить читателей с алгоритмом обучения многослойной нейронной сети методом обратного распространения ошибки и привести реализацию данного метода.
Сразу хочу оговориться, что не являюсь экспертом в области нейронных сетей, поэтому жду от читателей конструктивной критики, замечаний и дополнений.
Теоретическая часть
Данный материал предполагает знакомство с основами нейронных сетей, однако я считаю возможным ввести читателя в курс темы без излишних мытарств по теории нейронных сетей. Итак, для тех, кто впервые слышит словосочетание «нейронная сеть», предлагаю воспринимать нейронную сеть в качестве взвешенного направленного графа, узлы ( нейроны ) которого расположены слоями. Кроме того, узел одного слоя имеет связи со всеми узлами предыдущего слоя. В нашем случае у такого графа будут иметься входной и выходной слои, узлы которых выполняют роль входов и
выходов соответственно. Каждый узел ( нейрон ) обладает активационной функцией — функцией, ответственной за вычисление сигнала на выходе узла ( нейрона ). Также существует понятие смещения, представляющего из себя узел, на выходе которого всегда появляется единица. В данной статье мы будем рассматривать процесс обучения нейронной сети, предполагающий наличие «учителя», то есть процесс обучения, при котором обучение происходит путем предоставления сети последовательности обучающих примеров с правильными откликами.
Как и в случае с большинством нейронных сетей, наша цель состоит в обучении сети таким образом, чтобы достичь баланса между способностью сети давать верный отклик на входные данные, использовавшиеся в процессе обучения ( запоминания ), и способностью выдавать правильные результаты в ответ на входные данные, схожие, но неидентичные тем, что были использованы при обучении ( принцип обобщения). Обучение сети методом обратного распространения ошибки включает в себя три этапа: подачу на вход данных, с последующим распространением данных в направлении выходов, вычисление и обратное распространение соответствующей ошибки и корректировку весов. После обучения предполагается лишь подача на вход сети данных и распространение их в направлении выходов. При этом, если обучение сети может являться довольно длительным процессом, то непосредственное вычисление результатов обученной сетью происходит очень быстро. Кроме того, существуют многочисленные вариации метода обратного распространения ошибки, разработанные с целью увеличения скорости протекания
процесса обучения.
Также стоит отметить, что однослойная нейронная сеть существенно ограничена в том, обучению каким шаблонам входных данных она подлежит, в то время, как многослойная сеть ( с одним или более скрытым слоем ) не имеет такого недостатка. Далее будет дано описание стандартной нейронной сети с обратным распространением ошибки.
Архитектура
На рисунке 1 показана многослойная нейронная сеть с одним слоем скрытых нейронов ( элементы Z ).
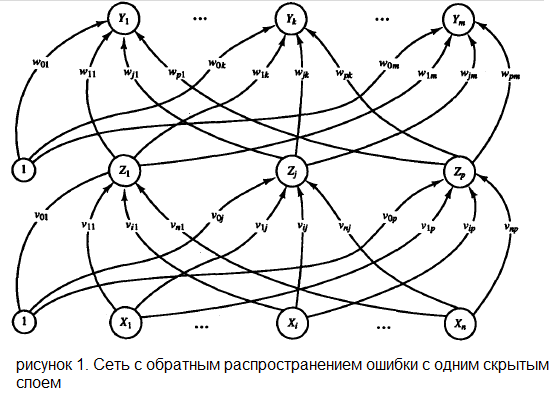
Нейроны, представляющие собой выходы сети ( обозначены  ), и скрытые нейроны могут иметь смещение( как показано на изображении ). Смещение, соответствующий выходу
), и скрытые нейроны могут иметь смещение( как показано на изображении ). Смещение, соответствующий выходу  обозначен
обозначен , скрытому элементу
, скрытому элементу  —
— 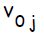 . Эти смещения служат в качестве весов на связях, исходящих от нейронов, на выходе которых всегда появляется 1 ( на рисунке 1 они показаны, но обычно явно не отображаются, подразумеваясь). Кроме того, на рисунке 1 стрелками показано перемещение информации в ходе фазы распространения данных от входов к выходам. В процессе обучения сигналы распространяются в обратном направлении.
. Эти смещения служат в качестве весов на связях, исходящих от нейронов, на выходе которых всегда появляется 1 ( на рисунке 1 они показаны, но обычно явно не отображаются, подразумеваясь). Кроме того, на рисунке 1 стрелками показано перемещение информации в ходе фазы распространения данных от входов к выходам. В процессе обучения сигналы распространяются в обратном направлении.
Описание алгоритма
Алгоритм, представленный далее, применим к нейронной сети с одним скрытым слоем, что является допустимой и адекватной ситуацией для большинства приложений. Как уже было сказано ранее, обучение сети включает в себя три стадии: подача на входы сети обучающих данных, обратное распространение ошибки и корректировка весов. В ходе первого этапа каждый входной нейрон  получает сигнал и широковещательно транслирует его каждому из скрытых нейронов
получает сигнал и широковещательно транслирует его каждому из скрытых нейронов  . Каждый скрытый нейрон затем вычисляет результат его активационной функции ( сетевой функции ) и рассылает свой сигнал
. Каждый скрытый нейрон затем вычисляет результат его активационной функции ( сетевой функции ) и рассылает свой сигнал  всем выходным нейронам. Каждый выходной нейрон , в свою очередь, вычисляет результат своей активационной функции
всем выходным нейронам. Каждый выходной нейрон , в свою очередь, вычисляет результат своей активационной функции  , который представляет собой ничто иное, как выходной сигнал данного нейрона для соответствующих входных данных. В процессе обучения, каждый нейрон на выходе сети сравнивает вычисленное значение с предоставленным учителем
, который представляет собой ничто иное, как выходной сигнал данного нейрона для соответствующих входных данных. В процессе обучения, каждый нейрон на выходе сети сравнивает вычисленное значение с предоставленным учителем  ( целевым значением ), определяя соответствующее значение ошибки для данного входного шаблона. На основании этой ошибки вычисляется
( целевым значением ), определяя соответствующее значение ошибки для данного входного шаблона. На основании этой ошибки вычисляется  .
.  используется при распространении ошибки от до всех элементов сети предыдущего слоя ( скрытых нейронов, связанных с ), а также позже при изменении весов связей между выходными нейронами и скрытыми. Аналогичным образом вычисляется
используется при распространении ошибки от до всех элементов сети предыдущего слоя ( скрытых нейронов, связанных с ), а также позже при изменении весов связей между выходными нейронами и скрытыми. Аналогичным образом вычисляется 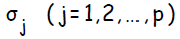 для каждого скрытого нейрона . Несмотря на то, что распространять ошибку до входного слоя необходимости нет,
для каждого скрытого нейрона . Несмотря на то, что распространять ошибку до входного слоя необходимости нет, 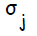 используется для изменения весов связей между нейронами скрытого слоя и входными нейронами. После того как все
используется для изменения весов связей между нейронами скрытого слоя и входными нейронами. После того как все 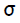 были определены, происходит одновременная корректировка весов всех связей.
были определены, происходит одновременная корректировка весов всех связей.
Обозначения:
В алгоритме обучения сети используются следующие обозначения:
 Входной вектор обучающих данных
Входной вектор обучающих данных 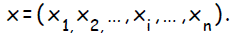
 Вектор целевых выходных значений, предоставляемых учителем
Вектор целевых выходных значений, предоставляемых учителем
Составляющая корректировки весов связей 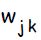 , соответствующая ошибке выходного нейрона ; также, информация об ошибке нейрона , которая распространяется тем нейронам скрытого слоя, которые связаны с .
, соответствующая ошибке выходного нейрона ; также, информация об ошибке нейрона , которая распространяется тем нейронам скрытого слоя, которые связаны с .
Составляющая корректировки весов связей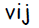 , соответствующая распространяемой от выходного слоя к скрытому нейрону информации об ошибке.
, соответствующая распространяемой от выходного слоя к скрытому нейрону информации об ошибке.
 Скорость обучения.
Скорость обучения.
 Нейрон на входе с индексом i. Для входных нейронов входной и выходной сигналы одинаковы — .
Нейрон на входе с индексом i. Для входных нейронов входной и выходной сигналы одинаковы — .
Смещение скрытого нейрона j.
Скрытый нейрон j; Суммарное значение подаваемое на вход скрытого элемента обозначается 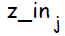 :
: 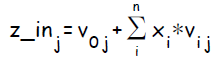
Сигнал на выходе ( результат применения к активационной функции ) обозначается : 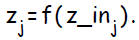
Смещение нейрона на выходе.
Нейрон на выходе под индексом k; Суммарное значение подаваемое на вход выходного элемента обозначается 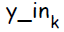 :
:  . Сигнал на выходе ( результат применения к активационной функции ) обозначается :
. Сигнал на выходе ( результат применения к активационной функции ) обозначается :
Функция активации
Функция активация в алгоритме обратного распространения ошибки должна обладать несколькими важными характеристиками: непрерывностью, дифференцируемостью и являться монотонно неубывающей. Более того, ради эффективности вычислений, желательно, чтобы ее производная легко находилась. Зачастую, активационная функция также является функцией с насыщением. Одной из наиболее часто используемых активационных функций является бинарная сигмоидальная функция с областью значений в ( 0, 1 ) и определенная как:


Другой широко распространенной активационной функцией является биполярный сигмоид с областью значений ( -1, 1 ) и определенный как:
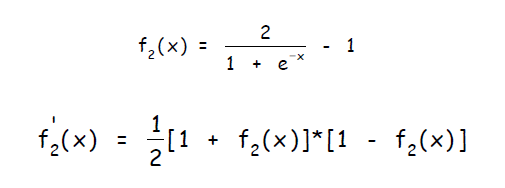
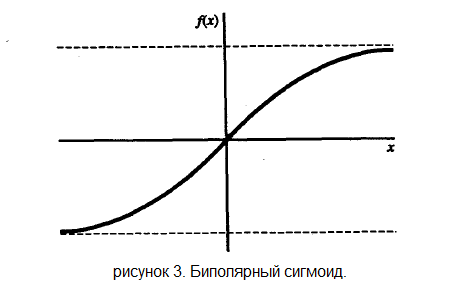
Алгоритм обучения
Алгоритм обучения выглядит следующим образом:
Шаг 0.
Инициализация весов ( веса всех связей инициализируются случайными небольшими значениями ).
Шаг 1.
До тех пор пока условие прекращения работы алгоритма неверно, выполняются шаги 2 — 9.
Шаг 2.
Для каждой пары { данные, целевое значение } выполняются шаги 3 — 8.
Распространение данных от входов к выходам:
Шаг 3.
Каждый входной нейрон 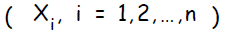 отправляет полученный сигнал всем нейронам в следующем слое ( скрытом ).
отправляет полученный сигнал всем нейронам в следующем слое ( скрытом ).
Шаг 4.
Каждый скрытый нейрон  суммирует взвешенные входящие сигналы: и применяет активационную функцию: После чего посылает результат всем элементам следующего слоя ( выходного ).
суммирует взвешенные входящие сигналы: и применяет активационную функцию: После чего посылает результат всем элементам следующего слоя ( выходного ).
Шаг 5.
Каждый выходной нейрон  суммирует взвешенные входящие сигналы: и применяет активационную функцию, вычисляя выходной сигнал:
суммирует взвешенные входящие сигналы: и применяет активационную функцию, вычисляя выходной сигнал: 
Обратное распространение ошибки:
Шаг 6.
Каждый выходной нейрон получает целевое значение — то выходное значение, которое является правильным для данного входного сигнала, и вычисляет ошибку:  , так же вычисляет величину, на которую изменится вес связи :
, так же вычисляет величину, на которую изменится вес связи :  . Помимо этого, вычисляет величину корректировки смещения:
. Помимо этого, вычисляет величину корректировки смещения:  и посылает нейронам в предыдущем слое.
и посылает нейронам в предыдущем слое.
Шаг 7.
Каждый скрытый нейрон суммирует входящие ошибки ( от нейронов в последующем слое )  и вычисляет величину ошибки, умножая полученное значение на производную активационной функции:
и вычисляет величину ошибки, умножая полученное значение на производную активационной функции: 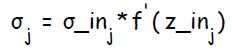 , так же вычисляет величину, на которую изменится вес связи :
, так же вычисляет величину, на которую изменится вес связи :  . Помимо этого, вычисляет величину корректировки смещения:
. Помимо этого, вычисляет величину корректировки смещения: 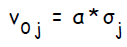
Шаг 8. Изменение весов.
Каждый выходной нейрон изменяет веса своих связей с элементом смещения и скрытыми нейронами: 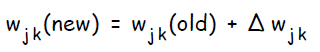
Каждый скрытый нейрон изменяет веса своих связей с элементом смещения и выходными нейронами: 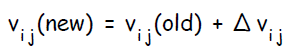
Шаг 9.
Проверка условия прекращения работы алгоритма.
Условием прекращения работы алгоритма может быть как достижение суммарной квадратичной ошибкой результата на выходе сети предустановленного заранее минимума в ходе процесса обучения, так и выполнения определенного количества итераций алгоритма. В основе алгоритма лежит метод под названием градиентный спуск. В зависимости от знака, градиент функции ( в данном случае значение функции — это ошибка, а параметры — это веса связей в сети ) дает направление, в котором значения функции возрастают (или убывают) наиболее стремительно.
Выбор первоначальных весов и смещения
Случайная инициализация. Выбор начальных весов окажет влияние на то, сумеет ли сеть достичь глобального ( или только локального) минимума ошибки, и насколько быстро этот процесс будет происходить. Изменение весов между двумя нейронами связано с производной активационной функции нейрона из последующего слоя и активационной функции нейрона слоя предыдущего. В связи с этим, важно избегать выбора таких начальных весов, которые обнулят активационную функцию или ее производную. Также начальные веса не должны быть слишком большими ( или входные сигнал для каждого скрытого или выходного нейрона скорее всего попадут в регион очень малых значений сигмоида ( регион насыщения ) ). С другой стороны, если начальные веса будут слишком маленькими, то входной сигнал на скрытые или выходные нейроны будет близок к нулю, что также приведет к очень низкой скорости обучения. Стандартная процедура инициализации весов состоит в присвоении им случайных значений в интервале ( -0,5; 0,5). Значения могут быть как положительными, так и отрицательными, так как конечные веса, получающиеся после обучения сети, могут быть обоих знаков. Инициализация Nguyen – Widrow. Представленная далее простая модификация стандартной процедуру инициализации способствует более быстрому обучению: Веса связей скрытых и выходных нейронов, а также смещение выходного слоя инициализируются также, как и в стандартной процедуре — случайными значениями из интервала ( -0,5; 0,5).
Введем обозначения:
 количество входных нейронов
количество входных нейронов
 количество скрытых нейронов
количество скрытых нейронов
 фактор масштабирования:
фактор масштабирования:
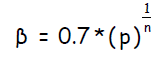
Процедура состоит из следующих простых шагов:
Для каждого скрытого нейрона :
инициализировать его вектор весов ( связей с входными нейронами ):
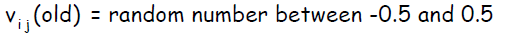
вычислить 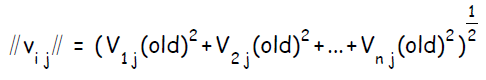
переинициализировать веса: 
задать значение смещения: 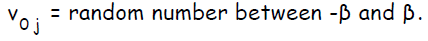
Практическая часть
Начну с реализации концепции нейрона. Было решено представить нейроны входного слоя базовым классом, а скрытые и выходные как декораторы базового класса. Кроме того, нейрон хранит в себе информацию об исходящих и входящих связях, а также каждый нейрон композиционно имеет в своем составе активационную функцию.
Интерфейс нейрона
/**
* Neuron base class.
* Represents a basic element of neural network, node in the net's graph.
* There are several possibilities for creation an object of type Neuron, different constructors suites for
* different situations.
*/
template <typename T>
class Neuron
{
public:
/**
* A default Neuron constructor.
* - Description: Creates a Neuron; general purposes.
* - Purpose: Creates a Neuron, linked to nothing, with a Linear network function.
* - Prerequisites: None.
*/
Neuron( ) : mNetFunc( new Linear ), mSumOfCharges( 0.0 ) { };
/**
* A Neuron constructor based on NetworkFunction.
* - Description: Creates a Neuron; mostly designed to create an output kind of neurons.
* @param inNetFunc - a network function which is producing neuron's output signal;
* - Purpose: Creates a Neuron, linked to nothing, with a specific network function.
* - Prerequisites: The existence of NetworkFunction object.
*/
Neuron( NetworkFunction * inNetFunc ) : mNetFunc( inNetFunc ), mSumOfCharges( 0.0 ){ };
Neuron( std::vector<NeuralLink<T > *>& inLinksToNeurons, NetworkFunction * inNetFunc ) :
mNetFunc( inNetFunc ),
mLinksToNeurons(inLinksToNeurons),
mSumOfCharges(0.0){ };
/**
* A Neuron constructor based on layer of Neurons.
* - Description: Creates a Neuron; mostly designed to create an input and hidden kinds of neurons.
* @param inNeuronsLinkTo - a vector of pointers to Neurons which is representing a layer;
* @param inNetFunc - a network function which is producing neuron's output signal;
* - Purpose: Creates a Neuron, linked to every Neuron in provided layer.
* - Prerequisites: The existence of std::vector<Neuron *> and NetworkFunction.
*/
Neuron( std::vector<Neuron *>& inNeuronsLinkTo, NetworkFunction * inNetFunc );
virtual ~Neuron( );
virtual std::vector<NeuralLink<T > *>& GetLinksToNeurons( ){ return mLinksToNeurons; };
virtual NeuralLink<T> * at( const int& inIndexOfNeuralLink ) { return mLinksToNeurons[ inIndexOfNeuralLink ]; };
virtual void SetLinkToNeuron( NeuralLink<T> * inNeuralLink ){ mLinksToNeurons.push_back( inNeuralLink ); };
virtual void Input( double inInputData ){ mSumOfCharges += inInputData; };
virtual double Fire( );
virtual int GetNumOfLinks( ) { return mLinksToNeurons.size( ); };
virtual double GetSumOfCharges( );
virtual void ResetSumOfCharges( ){ mSumOfCharges = 0.0; };
virtual double Process( ) { return mNetFunc->Process( mSumOfCharges ); };
virtual double Process( double inArg ){ return mNetFunc->Process( inArg ); };
virtual double Derivative( ){ return mNetFunc->Derivative( mSumOfCharges ); };
virtual void SetInputLink( NeuralLink<T> * inLink ){ mInputLinks.push_back( inLink ); };
virtual std::vector<NeuralLink<T > *>& GetInputLink( ){ return mInputLinks; };
virtual double PerformTrainingProcess( double inTarget );
virtual void PerformWeightsUpdating( );
virtual void ShowNeuronState( );
protected:
NetworkFunction * mNetFunc;
std::vector<NeuralLink<T > *> mInputLinks;
std::vector<NeuralLink<T > *> mLinksToNeurons;
double mSumOfCharges;
};
template <typename T>
class OutputLayerNeuronDecorator : public Neuron<T>
{
public:
OutputLayerNeuronDecorator( Neuron<T> * inNeuron ){ mOutputCharge = 0; mNeuron = inNeuron; };
virtual ~OutputLayerNeuronDecorator( );
virtual std::vector<NeuralLink<T > *>& GetLinksToNeurons( ){ return mNeuron->GetLinksToNeurons( ) ;};
virtual NeuralLink<T> * at( const int& inIndexOfNeuralLink ){ return ( mNeuron->at( inIndexOfNeuralLink ) ) ;};
virtual void SetLinkToNeuron( NeuralLink<T> * inNeuralLink ){ mNeuron->SetLinkToNeuron( inNeuralLink ); };
virtual double GetSumOfCharges( ) { return mNeuron->GetSumOfCharges( ); };
virtual void ResetSumOfCharges( ){ mNeuron->ResetSumOfCharges( ); };
virtual void Input( double inInputData ){ mNeuron->Input( inInputData ); };
virtual double Fire( );
virtual int GetNumOfLinks( ) { return mNeuron->GetNumOfLinks( ); };
virtual double Process( ) { return mNeuron->Process( ); };
virtual double Process( double inArg ){ return mNeuron->Process( inArg ); };
virtual double Derivative( ) { return mNeuron->Derivative( ); };
virtual void SetInputLink( NeuralLink<T> * inLink ){ mNeuron->SetInputLink( inLink ); };
virtual std::vector<NeuralLink<T > *>& GetInputLink( ) { return mNeuron->GetInputLink( ); };
virtual double PerformTrainingProcess( double inTarget );
virtual void PerformWeightsUpdating( );
virtual void ShowNeuronState( ) { mNeuron->ShowNeuronState( ); };
protected:
double mOutputCharge;
Neuron<T> * mNeuron;
};
template <typename T>
class HiddenLayerNeuronDecorator : public Neuron<T>
{
public:
HiddenLayerNeuronDecorator( Neuron<T> * inNeuron ) { mNeuron = inNeuron; };
virtual ~HiddenLayerNeuronDecorator( );
virtual std::vector<NeuralLink<T > *>& GetLinksToNeurons( ){ return mNeuron->GetLinksToNeurons( ); };
virtual void SetLinkToNeuron( NeuralLink<T> * inNeuralLink ){ mNeuron->SetLinkToNeuron( inNeuralLink ); };
virtual double GetSumOfCharges( ){ return mNeuron->GetSumOfCharges( ) ;};
virtual void ResetSumOfCharges( ){mNeuron->ResetSumOfCharges( ); };
virtual void Input( double inInputData ){ mNeuron->Input( inInputData ); };
virtual double Fire( );
virtual int GetNumOfLinks( ){ return mNeuron->GetNumOfLinks( ); };
virtual NeuralLink<T> * ( const int& inIndexOfNeuralLink ){ return ( mNeuron->at( inIndexOfNeuralLink) ); };
virtual double Process( ){ return mNeuron->Process( ); };
virtual double Process( double inArg ){ return mNeuron->Process( inArg ); };
virtual double Derivative( ){ return mNeuron->Derivative( ); };
virtual void SetInputLink( NeuralLink<T> * inLink ){ mNeuron->SetInputLink( inLink ); };
virtual std::vector<NeuralLink<T > *>& GetInputLink( ){ return mNeuron->GetInputLink( ); };
virtual double PerformTrainingProcess( double inTarget );
virtual void PerformWeightsUpdating( );
virtual void ShowNeuronState( ){ mNeuron->ShowNeuronState( ); };
protected:
Neuron<T> * mNeuron;
};
Интерфейс нейронных связей представлен ниже, каждая связь хранит вес и указатель на нейрон:
Интерфейс нейронной связи
template <typename T>
class Neuron;
template <typename T>
class NeuralLink
{
public:
NeuralLink( ) : mWeightToNeuron( 0.0 ),
mNeuronLinkedTo( 0 ),
mWeightCorrectionTerm( 0 ),
mErrorInformationTerm( 0 ),
mLastTranslatedSignal( 0 ){ };
NeuralLink( Neuron<T> * inNeuronLinkedTo, double inWeightToNeuron = 0.0 ) :
mWeightToNeuron( inWeightToNeuron ),
mNeuronLinkedTo( inNeuronLinkedTo ),
mWeightCorrectionTerm( 0 ),
mErrorInformationTerm( 0 ),
mLastTranslatedSignal( 0 ){ };
void SetWeight( const double& inWeight ){ mWeightToNeuron = inWeight; };
const double& GetWeight( ){ return mWeightToNeuron; };
void SetNeuronLinkedTo( Neuron<T> * inNeuronLinkedTo ){ mNeuronLinkedTo = inNeuronLinkedTo; };
Neuron<T> * GetNeuronLinkedTo( ){ return mNeuronLinkedTo; };
void SetWeightCorrectionTerm( double inWeightCorrectionTerm ){ mWeightCorrectionTerm = inWeightCorrectionTerm; };
double GetWeightCorrectionTerm( ){ return mWeightCorrectionTerm; };
void UpdateWeight( ){ mWeightToNeuron = mWeightToNeuron + mWeightCorrectionTerm; };
double GetErrorInFormationTerm( ){ return mErrorInformationTerm; };
void SetErrorInFormationTerm( double inEITerm ){ mErrorInformationTerm = inEITerm; };
void SetLastTranslatedSignal( double inLastTranslatedSignal ){ mLastTranslatedSignal = inLastTranslatedSignal; };
double GetLastTranslatedSignal( ){ return mLastTranslatedSignal; };
protected:
double mWeightToNeuron;
Neuron<T> * mNeuronLinkedTo;
double mWeightCorrectionTerm;
double mErrorInformationTerm;
double mLastTranslatedSignal;
};
Каждая активационная функция наследует от абстрактного класса, реализуя саму функцию и производную:
Интерфейс активационной функции
class NetworkFunction {
public:
NetworkFunction(){};
virtual ~NetworkFunction(){};
virtual double Process( double inParam ) = 0;
virtual double Derivative( double inParam ) = 0;
};
class Linear : public NetworkFunction {
public:
Linear(){};
virtual ~Linear(){};
virtual double Process( double inParam ){ return inParam; };
virtual double Derivative( double inParam ){ return 0; };
};
class Sigmoid : public NetworkFunction {
public:
Sigmoid(){};
virtual ~Sigmoid(){};
virtual double Process( double inParam ){ return ( 1 / ( 1 + exp( -inParam ) ) ); };
virtual double Derivative( double inParam ){ return ( this->Process(inParam)*(1 - this->Process(inParam)) );};
};
class BipolarSigmoid : public NetworkFunction {
public:
BipolarSigmoid(){};
virtual ~BipolarSigmoid(){};
virtual double Process( double inParam ){ return ( 2 / ( 1 + exp( -inParam ) ) - 1 ) ;};
virtual double Derivative( double inParam ){ return ( 0.5 * ( 1 + this->Process( inParam ) ) * ( 1 - this->Process( inParam ) ) ); };
};
За производство нейронов ответственна нейронная фабрика:
Интерфейс нейронной фабрики
template <typename T>
class NeuronFactory
{
public:
NeuronFactory(){};
virtual ~NeuronFactory(){};
virtual Neuron<T> * CreateInputNeuron( std::vector<Neuron<T > *>& inNeuronsLinkTo, NetworkFunction * inNetFunc ) = 0;
virtual Neuron<T> * CreateOutputNeuron( NetworkFunction * inNetFunc ) = 0;
virtual Neuron<T> * CreateHiddenNeuron( std::vector<Neuron<T > *>& inNeuronsLinkTo, NetworkFunction * inNetFunc ) = 0;
};
template <typename T>
class PerceptronNeuronFactory : public NeuronFactory<T>
{
public:
PerceptronNeuronFactory(){};
virtual ~PerceptronNeuronFactory(){};
virtual Neuron<T> * CreateInputNeuron( std::vector<Neuron<T > *>& inNeuronsLinkTo, NetworkFunction * inNetFunc ){ return new Neuron<T>( inNeuronsLinkTo, inNetFunc ); };
virtual Neuron<T> * CreateOutputNeuron( NetworkFunction * inNetFunc ){ return new OutputLayerNeuronDecorator<T>( new Neuron<T>( inNetFunc ) ); };
virtual Neuron<T> * CreateHiddenNeuron( std::vector<Neuron<T > *>& inNeuronsLinkTo, NetworkFunction * inNetFunc ){ return new HiddenLayerNeuronDecorator<T>( new Neuron<T>( inNeuronsLinkTo, inNetFunc ) ); };
};
Сама нейронная сеть хранит указатели на нейроны, организованные
слоями ( вообще, указатели на нейроны хранятся в векторах, которые
нужно заменить на объекты-слои ), включает в себя абстрактную
фабрику нейронов, а также алгоритм обучения сети.
Интерфейс нейронной сети
template <typename T>
class TrainAlgorithm;
/**
* Neural network class.
* An object of that type represents a neural network of several types:
* - Single layer perceptron;
* - Multiple layers perceptron.
*
* There are several training algorithms available as well:
* - Perceptron;
* - Backpropagation.
*
* How to use this class:
* To be able to use neural network , you have to create an instance of that class, specifying
* a number of input neurons, output neurons, number of hidden layers and amount of neurons in hidden layers.
* You can also specify a type of neural network, by passing a string with a name of neural network, otherwise
* MultiLayerPerceptron will be used. ( A training algorithm can be changed via public calls);
*
* Once the neural network was created, all u have to do is to set the biggest MSE required to achieve during
* the training phase ( or u can skip this step, then mMinMSE will be set to 0.01 ),
* train the network by providing a training data with target results.
* Afterwards u can obtain the net response by feeding the net with data;
*
*/
template <typename T>
class NeuralNetwork
{
public:
/**
* A Neural Network constructor.
* - Description: A template constructor. T is a data type, all the nodes will operate with. Create a neural network by providing it with:
* @param inInputs - an integer argument - number of input neurons of newly created neural network;
* @param inOutputs- an integer argument - number of output neurons of newly created neural network;
* @param inNumOfHiddenLayers - an integer argument - number of hidden layers of newly created neural network, default is 0;
* @param inNumOfNeuronsInHiddenLayers - an integer argument - number of neurons in hidden layers of newly created neural network ( note that every hidden layer has the same amount of neurons), default is 0;
* @param inTypeOfNeuralNetwork - a const char * argument - a type of neural network, we are going to create. The values may be:
* <UL>
* <LI>MultiLayerPerceptron;</LI>
* <LI>Default is MultiLayerPerceptron.</LI>
* </UL>
* - Purpose: Creates a neural network for solving some interesting problems.
* - Prerequisites: The template parameter has to be picked based on your input data.
*
*/
NeuralNetwork( const int& inInputs,
const int& inOutputs,
const int& inNumOfHiddenLayers = 0,
const int& inNumOfNeuronsInHiddenLayers = 0,
const char * inTypeOfNeuralNetwork = "MultiLayerPerceptron"
);
~NeuralNetwork( );
/**
* Public method Train.
* - Description: Method for training the network.
* - Purpose: Trains a network, so the weights on the links adjusted in the way to be able to solve problem.
* - Prerequisites:
* @param inData - a vector of vectors with data to train with;
* @param inTarget - a vector of vectors with target data;
* - the number of data samples and target samples has to be equal;
* - the data and targets has to be in the appropriate order u want the network to learn.
*/
bool Train( const std::vector<std::vector<T > >& inData,
const std::vector<std::vector<T > >& inTarget );
/**
* Public method GetNetResponse.
* - Description: Method for actually get response from net by feeding it with data.
* - Purpose: By calling this method u make the network evaluate the response for u.
* - Prerequisites:
* @param inData - a vector data to feed with.
*/
std::vector<int> GetNetResponse( const std::vector<T>& inData );
/**
* Public method SetAlgorithm.
* - Description: Setter for algorithm of training the net.
* - Purpose: Can be used for dynamic change of training algorithm.
* - Prerequisites:
* @param inTrainingAlgorithm - an existence of already created object of type TrainAlgorithm.
*/
void SetAlgorithm( TrainAlgorithm<T> * inTrainingAlgorithm ) { mTrainingAlgoritm = inTrainingAlgorithm; };
/**
* Public method SetNeuronFactory.
* - Description: Setter for the factory, which is making neurons for the net.
* - Purpose: Can be used for dynamic change of neuron factory.
* - Prerequisites:
* @param inNeuronFactory - an existence of already created object of type NeuronFactory.
*/
void SetNeuronFactory( NeuronFactory<T> * inNeuronFactory ) { mNeuronFactory = inNeuronFactory; };
/**
* Public method ShowNetworkState.
* - Description: Prints current state to the standard output: weight of every link.
* - Purpose: Can be used for monitoring the weights change during training of the net.
* - Prerequisites: None.
*/
void ShowNetworkState( );
/**
* Public method GetMinMSE.
* - Description: Returns the biggest MSE required to achieve during the training phase.
* - Purpose: Can be used for getting the biggest MSE required to achieve during the training phase.
* - Prerequisites: None.
*/
const double& GetMinMSE( ){ return mMinMSE; };
/**
* Public method SetMinMSE.
* - Description: Setter for the biggest MSE required to achieve during the training phase.
* - Purpose: Can be used for setting the biggest MSE required to achieve during the training phase.
* - Prerequisites:
* @param inMinMse - double value, the biggest MSE required to achieve during the training phase.
*/
void SetMinMSE( const double& inMinMse ){ mMinMSE = inMinMse; };
/**
* Friend class.
*/
friend class Hebb<T>;
/**
* Friend class.
*/
friend class Backpropagation<T>;
protected:
/**
* Protected method GetLayer.
* - Description: Getter for the layer by index of that layer.
* - Purpose: Can be used by inner implementation for getting access to neural network's layers.
* - Prerequisites:
* @param inInd - an integer index of layer.
*/
std::vector<Neuron<T > *>& GetLayer( const int& inInd ){ return mLayers[inInd]; };
/**
* Protected method size.
* - Description: Returns the number of layers in the network.
* - Purpose: Can be used by inner implementation for getting number of layers in the network.
* - Prerequisites: None.
*/
unsigned int size( ){ return mLayers.size( ); };
/**
* Protected method GetNumOfOutputs.
* - Description: Returns the number of units in the output layer.
* - Purpose: Can be used by inner implementation for getting number of units in the output layer.
* - Prerequisites: None.
*/
std::vector<Neuron<T > *>& GetOutputLayer( ){ return mLayers[mLayers.size( )-1]; };
/**
* Protected method GetInputLayer.
* - Description: Returns the input layer.
* - Purpose: Can be used by inner implementation for getting the input layer.
* - Prerequisites: None.
*/
std::vector<Neuron<T > *>& GetInputLayer( ){ return mLayers[0]; };
/**
* Protected method GetBiasLayer.
* - Description: Returns the vector of Biases.
* - Purpose: Can be used by inner implementation for getting vector of Biases.
* - Prerequisites: None.
*/
std::vector<Neuron<T > *>& GetBiasLayer( ) { return mBiasLayer; };
/**
* Protected method UpdateWeights.
* - Description: Updates the weights of every link between the neurons.
* - Purpose: Can be used by inner implementation for updating the weights of links between the neurons.
* - Prerequisites: None, but only makes sense, when its called during the training phase.
*/
void UpdateWeights( );
/**
* Protected method ResetCharges.
* - Description: Resets the neuron's data received during iteration of net training.
* - Purpose: Can be used by inner implementation for reset the neuron's data between iterations.
* - Prerequisites: None, but only makes sense, when its called during the training phase.
*/
void ResetCharges( );
/**
* Protected method AddMSE.
* - Description: Changes MSE during the training phase.
* - Purpose: Can be used by inner implementation for changing MSE during the training phase.
* - Prerequisites:
* @param inInd - a double amount of MSE to be add.
*/
void AddMSE( double inPortion ){ mMeanSquaredError += inPortion; };
/**
* Protected method GetMSE.
* - Description: Getter for MSE value.
* - Purpose: Can be used by inner implementation for getting access to the MSE value.
* - Prerequisites: None.
*/
double GetMSE( ){ return mMeanSquaredError; };
/**
* Protected method ResetMSE.
* - Description: Resets MSE value.
* - Purpose: Can be used by inner implementation for resetting MSE value.
* - Prerequisites: None.
*/
void ResetMSE( ) { mMeanSquaredError = 0; };
NeuronFactory<T> * mNeuronFactory; /*!< Member, which is responsible for creating neurons @see SetNeuronFactory */
TrainAlgorithm<T> * mTrainingAlgoritm; /*!< Member, which is responsible for the way the network will trained @see SetAlgorithm */
std::vector<std::vector<Neuron<T > *> > mLayers; /*!< Inner representation of neural networks */
std::vector<Neuron<T > *> mBiasLayer; /*!< Container for biases */
unsigned int mInputs, mOutputs, mHidden; /*!< Number of inputs, outputs and hidden units */
double mMeanSquaredError; /*!< Mean Squared Error which is changing every iteration of the training*/
double mMinMSE; /*!< The biggest Mean Squared Error required for training to stop*/
};
И, наконец, сам интерфейс класса, ответственного за обучение сети:
Интерфейс алгоритма обучения
template <typename T>
class NeuralNetwork;
template <typename T>
class TrainAlgorithm
{
public:
virtual ~TrainAlgorithm(){};
virtual double Train(const std::vector<T>& inData, const std::vector<T>& inTarget) = 0;
virtual void WeightsInitialization() = 0;
protected:
};
template <typename T>
class Hebb : public TrainAlgorithm<T>
{
public:
Hebb(NeuralNetwork<T> * inNeuralNetwork) : mNeuralNetwork(inNeuralNetwork){};
virtual ~Hebb(){};
virtual double Train(const std::vector<T>& inData, const std::vector<T>& inTarget);
virtual void WeightsInitialization();
protected:
NeuralNetwork<T> * mNeuralNetwork;
};
template <typename T>
class Backpropagation : public TrainAlgorithm<T>
{
public:
Backpropagation(NeuralNetwork<T> * inNeuralNetwork);
virtual ~Backpropagation(){};
virtual double Train(const std::vector<T>& inData, const std::vector<T>& inTarget);
virtual void WeightsInitialization();
protected:
void NguyenWidrowWeightsInitialization();
void CommonInitialization();
NeuralNetwork<T> * mNeuralNetwork;
};
Весь код доступен на github: Sovietmade/NeuralNetworks
В качестве заключения, хотелось бы отметить, что тема нейронных сетей на данный момент не разработана полностью, вновь и вновь мы видим на страницах хабра упоминания о новых достижениях ученых в области нейронных сетей, новых удивительных разработках. С моей стороны,
эта статья была первым шагом освоения интереснейшей технологии, и я надеюсь для кого — то она окажется небесполезной.
Использованная литература:
Алгоритм обучения нейронной сети был взят из изумительной книги:
Laurene V. Fausett “Fundamentals of Neural Networks: Architectures, Algorithms And Applications”.

Что это? Бихевиоризм – направление в психологии, объясняющее действия человека с точки зрения поведенческих триггеров и окружения, которое влияет на поведение. Изначально концепция создавалась на изучении повадок животных.

Для чего? Классический бихевиоризм в чистом виде как направление психологии изжил себя. Его дополнили другие заключения ученых, давшие новые названия ответвлениям теории. Какая бы версия ни рассматривалась, сегодня каждый может многое почерпнуть из бихевиоризма.
В статье рассказывается:
- Суть бихевиоризма
- Основные положения, сильные и слабые стороны бихевиоризма
- Классическое направление бихевиоризма Дж. Уотсона
- Бихевиоризм в интерпретации Э. Торндайка
- Бихевиоризм Б. Скиннера
- Когнитивный бихевиоризм Э. Толмена
- Чему может научить бихевиоризм
-

Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.Бесплатно от Geekbrains
Суть бихевиоризма
Это название получило одно из направлений в психологии, изучающее поведение человека. Изначально предметом бихевиоризма было исследование поведения животных в рамках биологии, но потом к этому добавился социальный аспект. Термин имеет английские корни и происходит от слова behavior – «поведение».
Психологи-бихевиористы выбрали для изучения самую простую универсальную схему, которая прекрасно объясняет наше поведение. В нее входят два компонента – стимул и реакция. Другими словами, большое значение отводится механическому влиянию внешней среды, благодаря которому мы совершаем различные действия.
Если, к примеру, будет поставлена задача выяснить, почему господин X или госпожа Y поступили именно так, а не по-другому, то сначала надо самым подробным образом описать поведение этих людей, затем найти в их окружении стимул, который заставил так себя вести, и после этого установить связь между стимулом и реакцией на него у господина X и госпожи Y.

Схема достаточно проста, но ее применение подразумевает знания психологии, социологии, философии. И если начинался бихевиоризм как физиологическое учение, где простейшие связи выглядели как «видишь пищу – выделяется слюна», то в отношении человека все схемы стали гораздо сложнее.
Основные положения, сильные и слабые стороны бихевиоризма
Сегодня бихевиоризм в психологии – это отдельное фундаментальное направление, в котором можно выделить несколько основных положений. Мы дадим их в краткой форме, а тем, кто захочет глубже погрузиться в тему, советуем изучить работы Торндайка, Уотсона и других авторов:
- предметом бихевиоризма является изучение поведения человека и животных;
- изучение лучше всего проводить методом наблюдения;
- все существование человека, как в психическом, так и в физиологическом плане, определяется его поступками;
- действия человека и животных обоснованы их двигательными реакциями на внешние раздражающие факторы – стимулы;
- если известно, что это за раздражитель, то можно с большой точностью предопределить и ответную реакцию;
- отсюда главная цель бихевиоризма – предсказать возможное поведение особи;
- при использовании схемы «стимул – реакция» ответные действия людей и животных можно предопределить и держать под контролем;
- реакции индивида могут быть наследственными (безусловные рефлексы) или приобретенными (условные рефлексы);
- привычное поведение человека является следствием обучения, в процессе которого успешные реакции повторяются много раз и в результате запоминаются, превращаясь в автоматические и легко воспроизводимые;
- выработка условных рефлексов формирует навыки;
- к навыкам относятся мышление и речь;
- не растерять приобретенные навыки помогает механизм памяти;
- развитие психических реакций происходит в течение всей жизни;
- на процесс развития психических реакций влияет окружающая среда – условия жизни, близкие люди и т.д.;
- проявление эмоций – это своеобразная реакция на поступающие извне положительные и отрицательные стимулы.

Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда

Подборка 50+ бесплатных нейросетей для упрощения работы и увеличения заработка
Только проверенные нейросети с доступом из России и свободным использованием
ТОП-100 площадок для поиска работы от GeekBrains
Список проверенных ресурсов реальных вакансий с доходом от 210 000 ₽
Уже скачали 22616 ![]()
Из этих тезисов становится ясно, почему идеи нового направления в психологии оказали такое заметное влияние и на сообщество ученых, и на обывателей. Передовое учение поначалу окружал искренний энтузиазм, но ничего не бывает в науке только хорошего или только плохого. Любое научное движение имеет свои плюсы и минусы. Есть они и у бихевиоризма:
- Для своего времени бихевиоризм стал передовым методом, направленным на изучение поведения. Это понятно, поскольку до его появления наука занималась изучением одного лишь сознания, не учитывая влияние на него объективной реальности. Но и со своей стороны бихевиористы тоже подошли к решению проблемы однобоко, не рассматривая сознание вовсе.
- Приверженцы учения изучали поведенческие функции человека и животных только с помощью метода наблюдения. В результате они полностью игнорировали не только сознание, но и психические, и физиологические процессы, внешние проявления которых были недоступны наблюдениям.
- Из теории бихевиоризма следовало, что ученый может направлять поведение индивида в соответствии со своими нуждами и задачами. Но такой подход к изучению получился безжизненным, поведение объекта объяснялось набором самых элементарных реакций. Сама личность человека не имела для ученых никакого значения.
- Поэтому все практические изыскания бихевиористов базировались на лабораторном эксперименте. В их работу входили также опыты не только над животными, но и над людьми. Особых различий между поведением людей, зверей и птиц они не установили.
- Последователи бихевиоризма определили механизм выработки навыков у человека без учета мотивации и психического фактора – а ведь именно они служат основой его функционирования. К тому же они совершенно не учитывали влияние социального фактора.
Эти существенные с точки зрения современной психологии недостатки довели некогда прогрессивное научное направление до такого состояния, что оно не поддавалось уже никакой критике. Но с подведением итогов мы пока повременим. Чтобы представить полную картину учения, следует познакомиться с направлениями, возникшими на основе классического бихевиоризма, а также с наиболее известными их последователями.
Классическое направление бихевиоризма Дж. Уотсона
Основателем бихевиоризма считается американский психолог Джон Уотсон. Своими исследованиями он пытался поднять психологию до уровня естественных наук, чтобы при ее изучении можно было пользоваться объективными методами.
В своих работах Уотсон выделял методы классического научения, когда организм объединяет различные стимулы. Например, если звук колокольчика является условным раздражителем, то выделение слюны у собаки в ответ на этот звук – условный рефлекс. При таком виде научения результатом становятся непроизвольные, автоматические действия.
Организм и человека, и животного умеет приспосабливаться к окружающему миру, используя для этого врожденные и приобретенные навыки поведения. По Уотсону все психические действия воспринимались как поведение. Другими словами, поведение – это объединение реакций организма на стимулы, по принципу «стимул – реакция». Джон Уотсон был уверен, что, если подобрать правильный стимул, то можно сформировать в индивиде нужные навыки и качества.


Читайте также
Когда русский физиолог И.П. Павлов открыл и описал классические условные рефлексы, он и не предполагал, что его исследования лягут в основу бихевиоризма. Уотсон внимательно изучил работы Павлова и пришел к выводу, что наблюдение за поведением индивида сводится к описанию стимулов (S) и реакций (R). Хотя сам Павлов считал данный вывод ошибочным и утверждал, что его просто не так поняли.
Чтобы доказать правильность бихевиористической теории, Джон Уотсон и Розали Рейнер решили поставить эксперимент, который вошел в историю науки как «маленький Альберт».
Для своих экспериментов Уотсон и Рейнер выбрали нормально развитого 11-месячного малыша Альберта. Сначала, они проверили реакцию Альберта на то, что он видел у них в руках – белую крысу, маску, горящую бумагу и хлопковую пряжу. Ни один из предметов не вызвал страха у ребенка.

Затем они решили сформировать реакцию страха. В тот момент, когда Альберту давали поиграть с белой крысой, один из экспериментаторов сильно бил молотком по металлическому листу, но так, чтобы малыш его не видел. Альберта громкий звук удара каждый раз пугал. В дальнейшем ребенок стал бояться и белой крысы, хотя звука в момент ее появления могло и не быть. В результате у маленького Альберта закрепился условный рефлекс страха на крысу.
Скачать
файл
Через пять дней эксперимент продолжили. На другие предметы у Альберта не было никакой реакции, а вот крысы он продолжал бояться. Тогда исследователи решили проверить, не перешла ли его реакция страха на других животных или на схожие по внешнему виду предметы. Им удалось выяснить, что малыша действительно пугают животные и предметы, не имеющие отношения к крысе, например, кролик (сильно), собака (слабо).
Бихевиоризм в интерпретации Э. Торндайка
Эдвард Торндайк – выдающийся американский психолог. Он разработал теорию научения, стал автором научных трудов – «Интеллект животных», «Основы обучения» и др. Последователем бихевиоризма Торндайк себя не считал, хотя многие его законы и исследования как раз говорят об обратном.
Под руководством своего наставника У. Джеймса, еще в Гарварде, Э. Торндайк начал проводить опыты над животными. В подвале дома Джеймса он занимался тем, что обучал цыплят находить выход из лабиринта. Поскольку в университете для подобных опытов места не было, то именно этот подвал можно считать первой в мире экспериментальной лабораторией по зоопсихологии и изучению бихевиоризма.
Он продолжил свои эксперименты в Колумбии, где изучал закономерности привыкания организма к необычным условиям, когда тот умеет вести себя только так, чтобы справиться с этими условиями не может. Торндайк изобрел специальные «проблемные ящики» – устройства различной степени сложности. Животное, попавшее в такой ящик, должно было справиться с препятствиями, найти выход и решить проблему.
В основном экспериментаторы работали с кошками, но были разработаны такие же ящики и для собак, и для обезьян. Животное могло выйти из ящика и получить лакомство только в том случае, если производило нужное действие – нажимало на пружину, дергало за веревку и т.п. По результатам исследований строились графики, названные «кривыми научения». Целью этой научной работы было изучение двигательных реакций животных.
Эксперимент показал однотипность поведения животных. Сначала их движения носили беспорядочный характер – они бросались на стенки ящика, кусали его, царапали, пока случайно одно из движений не попадало в цель. Последующие опыты показали, что число хаотичных движений уменьшалось, животное все быстрее находило выход, пока не начинало делать это без ошибок. Данный вид обучения получил название метода «проб и ошибок».
Затем Торндайк занялся изучением того, как связи, лежащие в основе научения, зависят от поощрения и наказания. Результаты этой научной работы позволили сформулировать основные законы научения.
- Закон повторяемости (упражнения) — чем чаще повторяется связь между стимулом и реакцией, тем быстрее и прочнее она закрепляется в сознании.
- Закон эффекта — в одной и той же повторяющейся ситуации при прочих равных условиях более прочные связи возникают у реакции, вызвавшей чувство удовлетворения. Другими словами, связи будут устанавливаться успешнее, если при реагировании на стимул выдается угощение.
- Закон готовности — новые связи образуются в том случае, если субъект к этому готов.
- Закон ассоциативного сдвига — если одновременно появляются два раздражителя, один из которых вызывает положительную реакцию, то со временем и на другой появится точно такая же реакция. Получается, что нейтральный по своему значению стимул, который сознание объединило по ассоциации со значимым, тоже начинает вызывать нужную реакцию.
На основе проведенных экспериментов Торндайк вывел концепцию «распространения эффекта». Это означает, что субъект готов усвоить новую информацию из областей, смежных с уже изученными. Психолог также заметил ситуации, в которых одно уже освоенное действие может помешать обучению другому («проактивное торможение»), а научение новому виду деятельности может уничтожить то, что было выучено ранее («ретроактивное торможение»).
Так работает память. Какой-то изученный материал может быть забыт не только по истечении длительного периода времени, но и в связи с влиянием на сознание индивида иных видов деятельности.
Бихевиоризм Б. Скиннера
Бернес Скиннер, известный американский психолог и писатель, продолжил развитие бихевиоризма, используя идеи Дж. Уотсона, разработавшего теорию оперантного научения.
Он называл организм человека «черным ящиком», в котором лежат эмоции, мотивы, влечения – все то, что по мнению ученого нельзя объективно измерить. Следовательно, их не надо включать в перечень объектов эмпирического наблюдения. А вот поведение Скиннер активно измерял.
При этом он считал, что поведение человека направляет или стимулирует не его личность (потребности, мысли, чувства), а какие-то внешние силы (окружающая среда). По Скиннеру изучение личности связано с определением характера взаимоотношений между поведением индивида и результатами этих поступков, которые в дальнейшем оказывают на него влияние. Такой подход нацелен на прогнозирование и контроль наблюдаемого поведения.
Б. Скиннера, как и Дж. Уотсона в свое время, очень интересовало явление научения. Он взял за основу эффект, открытый Э. Торндайком, и сформулировал свою концепцию оперантного научения.
Только до 25.09
Скачай подборку материалов, чтобы гарантированно найти работу в IT за 14 дней
Список документов:

ТОП-100 площадок для поиска работы от GeekBrains
20 профессий 2023 года, с доходом от 150 000 рублей
Чек-лист «Как успешно пройти собеседование»
Чтобы получить файл, укажите e-mail:
Введите e-mail, чтобы получить доступ к документам
Подтвердите, что вы не робот,
указав номер телефона:
Введите телефон, чтобы получить доступ к документам

Уже скачали 52300
Оперантное научение в бихевиоризме – это метод обучения, включающий в себя систему поощрений и наказаний, призванную укрепить или сократить приобретенный тип поведения. При этом научаемый индивид связывает свое дальнейшее поведение с результатом этих действий. Метод направлен на закрепление поведения, которое контролирует индивид.
К примеру, человек хочет, чтобы собака выполняла определенную команду. Когда она это делает, то получает награду в виде похвалы, ласки или лакомства. Если собака команду не выполнила, то поощрение ей не достается. В результате собака улавливает связь между определенным поведением и получением награды, а последующие тренировки эту связь укрепляют.
Точно так же собаку можно отучить грызть обувь. Только в этом случае за каждое нарушение пса надо наказывать (например, отругать). Получился наглядный пример метода «кнута и пряника».

Скиннер спроектировал специальное устройство, получившее впоследствии название «ящик Скиннера», в которое он сажал голодных животных или птиц (крыс, голубей). Ящик был абсолютно пуст, только на дне был смонтирован выступающий рычаг, под которым стояла небольшая емкость. Крыса, оказавшись внутри, начинала изучать пространство, в какой-то момент натыкалась на рычаг и нажимала его.
После того, как крыса начнет с определенной периодичностью нажимать на рычаг, исследователь подключает к устройству кассету с пищей, установленную снаружи. Как только крыса давит на рычаг, в емкость под ним падает небольшой кусочек. Крыса лакомится и вскоре снова давит на дно ящика. Поскольку после каждого нажатия в тарелку падает еда, это заставляет крысу увеличить частоту своих действий. После отсоединения кассеты пища перестает появляться после давления на рычаг, и число нажатий будет постепенно уменьшаться.
Скиннер определил экспериментально, что выученная реакция при отсутствии подкрепления угасает точно так же, как и классически обусловленная реакция. В ходе исследования можно установить дополнительный критерий – подавать пищу только тогда, когда крыса нажимает на рычаг при включенной лампочке. Таким образом у крысы вырабатывается условная реакция при избирательном подкреплении. В данном случае свет – это контролирующий реакцию стимул.
Кроме всего прочего Скиннер вывел положения о двух видах поведения: респондентном и оперантном.
- Респондентное поведение — это определенная реакция, вызванная хорошо знакомым стимулом. При этом стимул всегда предшествует реакции. Например, сужение зрачка при ярком свете, движение колена при ударе по нему молоточком, дрожь при низкой температуре воздуха.
- Оперантное поведение — это любые приобретенные реакции без характерного стимула. Поведение, выработанное оперантным научением, зависит от тех событий, которые наступают после реакции. Или, другими словами, за поведением идет следствие, и составляющие этого следствия влияют на желание индивида вести себя также в дальнейшем.
Примеры оперантной реакции (операнты) – катание на роликах, игра на гитаре, написание собственного имени. Они контролируются результатами соответствующего поведения.
Когнитивный бихевиоризм Э. Толмена
Эдвард Толмен известен как американский психолог, представитель необихевиоризма, автор концепции «когнитивных карт», разработавший когнитивный бихевиоризм.
Он не принял открытый Э. Торндайком закон эффекта, утверждая, что вознаграждения (поощрения) практически не влияют на научение, и предложил свою когнитивную теорию. По убеждению Э. Толмена только постоянное выполнение одного и того же действия укрепляет возникающие связи между окружающей средой и предположениями организма.
Ученый выдвинул идею, что поведение следует рассматривать как функцию пяти основных независимых переменных: стимулы окружающей среды, психологические побуждения, наследственность, предшествующее обучение и возраст.
Толмен считал, что бихевиористская модель S-R является неполной – формула поведения должна выглядеть так: стимул (независимая переменная) — организм (промежуточные переменные) — реакция (зависимая переменная), т.е. S-O-R.
К промежуточным переменным относится все, что связано с организмом (О) и способно сформировать реакцию поведения на конкретное раздражение. Получается, что среднее звено состоит из психических моментов, за которыми нельзя вести прямое наблюдение (например, ощущения, знания, ожидания и т.п.). В качестве примера можно взять чувство голода, которое экспериментатор не в состоянии разглядеть у подопытного объекта. Но в то же время голод объективно связан с переменными, участвующими в эксперименте, например, с промежутком времени, в течение которого индивид был лишен пищи.
Толмен проводил опыты над крысами, запуская их в лабиринт, чтобы они самостоятельно нашли выход. Результаты исследования позволили сделать главный вывод: достоверно установлено, что при тщательно контролируемом и наблюдаемом поведении животных управляют им совсем не те раздражители, которые в данный момент применяются к крысам, а особые внутренние механизмы.
На поведение животных оказывают влияние своего рода ожидания, гипотезы, познавательные (когнитивные) «карты». Это субъективная картина с пространственными координатами, возникающая у конкретной особи, благодаря которой она воспринимает отдельные локальные объекты. Эти «карты» животное генерирует само, чтобы ориентироваться в лабиринте, знать, куда и как ему надо двигаться, чтобы выбраться из ловушки.
Положение о том, что психические картины, возникающие в мозгу, могут служить регулятором действия, подтверждено гештальт теорией. С учетом данного положения Толмен разработал собственную теорию, которую назвали когнитивным бихевиоризмом.
Чему может научить бихевиоризм
Несмотря на серьезную критику, некоторые положения и направления бихевиоризма не утратили своей актуальности и сегодня.
Сильное воздействие окружающей среды на человека
Бихевиоризму уже больше 100 лет, но этот принцип продолжает оставаться одним из основных в психологии. Все наши страхи, переживания, комплексы по мнению психологов кроются во внешних причинах.
По мнению одного из известных бихевиористов, Бернеса Фредерика Скиннера, большинство наших действий зависит от реакции на них окружающей среды. Человек запоминает, как на его поведение отреагировали окружающие, и в дальнейшем корректирует свои поступки с учетом предполагаемых последствий. Люди быстро усваивают, как надо себя вести, чтобы добиться положительного результата и по возможности избежать отрицательного. Если хотите сохранить собственное лицо, постоянно анализируйте свои действия: действительно ли вы поступили так по своему желанию, или на вас повлияли какие-то внешние факторы.
Влияние на поведение людей
Последователи социального бихевиоризма практически отрицали роль личности в поведении человека, приписывая ведущую роль внешнему воздействию. Они заявляли, например, что из ребенка, помещенного в полностью контролируемую среду, можно вырастить кого угодно. И считали, что его способности, склонности и желания не будут при этом иметь почти никакого значения.
Сегодня понятно, что это серьезное заблуждение. К примеру, воспитанники детского дома растут примерно в одних и тех же социальных условиях, но в результате становятся разными людьми с собственным характером.

Но какое-то зерно истины в идеях бихевиоризма все же есть. Возьмем рекламу. Маркетологи способны с помощью ее многократного повторения сформировать у потребителей желание приобрести этот продукт. А ведь это наглядный пример схемы «стимул – реакция», только немного усложненный: в рекламном ролике многократно звучит призыв купить товар, и у вас начинает появляться мысль о том, что он вам действительно необходим. Так что прежде, чем что-нибудь приобрести, подумайте – а не навеяно ли это решение слишком назойливой рекламой.
Борьба с причиной психологической проблемы, а не с ее последствиями
Когнитивисты фокусируют свое внимание на поиске источника проблем, а не на исправлении последствий. Именно этот принцип лег в основу когнитивно-поведенческой терапии, которая помогает человеку отказаться от определенных привычек, изменить образ действий и мыслей таким образом, чтобы избежать негативных психологических эффектов. К примеру, слишком эмоционально реагировать на поведение окружающих.
Поощрение эффективнее, чем наказание
Награда укрепляет определенное поведение, а наказание отталкивает от него. Именно так организована работа системы школьных оценок.

Читайте также
Но по мнению бихевиористов все не так просто. Скиннер утверждал, что роль пряника важнее, чем кнута. Ученый придерживался той точки зрения, что поощрение является лучшим стимулом для человека, в то время как наказание не отталкивает от плохих поступков, а только заставляет искать другие пути для их совершения. Например, обманывать. Так что, если хотите сформировать у себя или у кого-то другого хорошие привычки и свести к минимуму плохие, то чаще говорите похвальные слова.
Человек – существо очень сложное, изучение его самого и его жизни требует времени и множества усилий. Идеи психологического бихевиоризма помогли этому процессу лишь отчасти.
Подведем итоги бихевиористских исследований: выработка частичного понимания человеком своего и чужого поведения, открытие возможности создания условий, которые способны подвигнуть к выполнению определенных действий. Но при этом и поведение отдельного человека влияет на его окружение, вызывая собой конкретную реакцию людей.