From Wikipedia, the free encyclopedia

The standard error (SE)[1] of a statistic (usually an estimate of a parameter) is the standard deviation of its sampling distribution[2] or an estimate of that standard deviation. If the statistic is the sample mean, it is called the standard error of the mean (SEM).[1]
The sampling distribution of a mean is generated by repeated sampling from the same population and recording of the sample means obtained. This forms a distribution of different means, and this distribution has its own mean and variance. Mathematically, the variance of the sampling mean distribution obtained is equal to the variance of the population divided by the sample size. This is because as the sample size increases, sample means cluster more closely around the population mean.
Therefore, the relationship between the standard error of the mean and the standard deviation is such that, for a given sample size, the standard error of the mean equals the standard deviation divided by the square root of the sample size.[1] In other words, the standard error of the mean is a measure of the dispersion of sample means around the population mean.
In regression analysis, the term «standard error» refers either to the square root of the reduced chi-squared statistic or the standard error for a particular regression coefficient (as used in, say, confidence intervals).
Standard error of the sample mean[edit]
Exact value[edit]
Suppose a statistically independent sample of  observations
observations  is taken from a statistical population with a standard deviation of
is taken from a statistical population with a standard deviation of  . The mean value calculated from the sample,
. The mean value calculated from the sample,  , will have an associated standard error on the mean,
, will have an associated standard error on the mean,  , given by:[1]
, given by:[1]

Practically this tells us that when trying to estimate the value of a population mean, due to the factor  , reducing the error on the estimate by a factor of two requires acquiring four times as many observations in the sample; reducing it by a factor of ten requires a hundred times as many observations.
, reducing the error on the estimate by a factor of two requires acquiring four times as many observations in the sample; reducing it by a factor of ten requires a hundred times as many observations.
Estimate[edit]
The standard deviation of the population being sampled is seldom known. Therefore, the standard error of the mean is usually estimated by replacing with the sample standard deviation  instead:
instead:

As this is only an estimator for the true «standard error», it is common to see other notations here such as:

A common source of confusion occurs when failing to distinguish clearly between:
Accuracy of the estimator[edit]
When the sample size is small, using the standard deviation of the sample instead of the true standard deviation of the population will tend to systematically underestimate the population standard deviation, and therefore also the standard error. With n = 2, the underestimate is about 25%, but for n = 6, the underestimate is only 5%. Gurland and Tripathi (1971) provide a correction and equation for this effect.[3] Sokal and Rohlf (1981) give an equation of the correction factor for small samples of n < 20.[4] See unbiased estimation of standard deviation for further discussion.
Derivation[edit]
The standard error on the mean may be derived from the variance of a sum of independent random variables,[5] given the definition of variance and some simple properties thereof. If is a sample of independent observations from a population with mean and standard deviation , then we can define the total

which due to the Bienaymé formula, will have variance

where we’ve approximated the standard deviations, i.e., the uncertainties, of the measurements themselves with the best value for the standard deviation of the population. The mean of these measurements is simply given by

The variance of the mean is then

The standard error is, by definition, the standard deviation of which is simply the square root of the variance:

For correlated random variables the sample variance needs to be computed according to the Markov chain central limit theorem.
Independent and identically distributed random variables with random sample size[edit]
There are cases when a sample is taken without knowing, in advance, how many observations will be acceptable according to some criterion. In such cases, the sample size  is a random variable whose variation adds to the variation of
is a random variable whose variation adds to the variation of  such that,
such that,

[6]
which follows from the law of total variance.
If has a Poisson distribution, then  with estimator
with estimator  . Hence the estimator of
. Hence the estimator of  becomes
becomes  , leading the following formula for standard error:
, leading the following formula for standard error:

(since the standard deviation is the square root of the variance).
Student approximation when σ value is unknown[edit]
In many practical applications, the true value of σ is unknown. As a result, we need to use a distribution that takes into account that spread of possible σ’s.
When the true underlying distribution is known to be Gaussian, although with unknown σ, then the resulting estimated distribution follows the Student t-distribution. The standard error is the standard deviation of the Student t-distribution. T-distributions are slightly different from Gaussian, and vary depending on the size of the sample. Small samples are somewhat more likely to underestimate the population standard deviation and have a mean that differs from the true population mean, and the Student t-distribution accounts for the probability of these events with somewhat heavier tails compared to a Gaussian. To estimate the standard error of a Student t-distribution it is sufficient to use the sample standard deviation «s» instead of σ, and we could use this value to calculate confidence intervals.
Note: The Student’s probability distribution is approximated well by the Gaussian distribution when the sample size is over 100. For such samples one can use the latter distribution, which is much simpler.
Assumptions and usage[edit]
An example of how  is used is to make confidence intervals of the unknown population mean. If the sampling distribution is normally distributed, the sample mean, the standard error, and the quantiles of the normal distribution can be used to calculate confidence intervals for the true population mean. The following expressions can be used to calculate the upper and lower 95% confidence limits, where is equal to the sample mean, is equal to the standard error for the sample mean, and 1.96 is the approximate value of the 97.5 percentile point of the normal distribution:
is used is to make confidence intervals of the unknown population mean. If the sampling distribution is normally distributed, the sample mean, the standard error, and the quantiles of the normal distribution can be used to calculate confidence intervals for the true population mean. The following expressions can be used to calculate the upper and lower 95% confidence limits, where is equal to the sample mean, is equal to the standard error for the sample mean, and 1.96 is the approximate value of the 97.5 percentile point of the normal distribution:
In particular, the standard error of a sample statistic (such as sample mean) is the actual or estimated standard deviation of the sample mean in the process by which it was generated. In other words, it is the actual or estimated standard deviation of the sampling distribution of the sample statistic. The notation for standard error can be any one of SE, SEM (for standard error of measurement or mean), or SE.
Standard errors provide simple measures of uncertainty in a value and are often used because:
- in many cases, if the standard error of several individual quantities is known then the standard error of some function of the quantities can be easily calculated;
- when the probability distribution of the value is known, it can be used to calculate an exact confidence interval;
- when the probability distribution is unknown, Chebyshev’s or the Vysochanskiï–Petunin inequalities can be used to calculate a conservative confidence interval; and
- as the sample size tends to infinity the central limit theorem guarantees that the sampling distribution of the mean is asymptotically normal.
Standard error of mean versus standard deviation[edit]
In scientific and technical literature, experimental data are often summarized either using the mean and standard deviation of the sample data or the mean with the standard error. This often leads to confusion about their interchangeability. However, the mean and standard deviation are descriptive statistics, whereas the standard error of the mean is descriptive of the random sampling process. The standard deviation of the sample data is a description of the variation in measurements, while the standard error of the mean is a probabilistic statement about how the sample size will provide a better bound on estimates of the population mean, in light of the central limit theorem.[7]
Put simply, the standard error of the sample mean is an estimate of how far the sample mean is likely to be from the population mean, whereas the standard deviation of the sample is the degree to which individuals within the sample differ from the sample mean.[8] If the population standard deviation is finite, the standard error of the mean of the sample will tend to zero with increasing sample size, because the estimate of the population mean will improve, while the standard deviation of the sample will tend to approximate the population standard deviation as the sample size increases.
Extensions[edit]
Finite population correction (FPC)[edit]
The formula given above for the standard error assumes that the population is infinite. Nonetheless, it is often used for finite populations when people are interested in measuring the process that created the existing finite population (this is called an analytic study). Though the above formula is not exactly correct when the population is finite, the difference between the finite- and infinite-population versions will be small when sampling fraction is small (e.g. a small proportion of a finite population is studied). In this case people often do not correct for the finite population, essentially treating it as an «approximately infinite» population.
If one is interested in measuring an existing finite population that will not change over time, then it is necessary to adjust for the population size (called an enumerative study). When the sampling fraction (often termed f) is large (approximately at 5% or more) in an enumerative study, the estimate of the standard error must be corrected by multiplying by a »finite population correction» (a.k.a.: FPC):[9]
[10]

which, for large N:

to account for the added precision gained by sampling close to a larger percentage of the population. The effect of the FPC is that the error becomes zero when the sample size n is equal to the population size N.
This happens in survey methodology when sampling without replacement. If sampling with replacement, then FPC does not come into play.
Correction for correlation in the sample[edit]

If values of the measured quantity A are not statistically independent but have been obtained from known locations in parameter space x, an unbiased estimate of the true standard error of the mean (actually a correction on the standard deviation part) may be obtained by multiplying the calculated standard error of the sample by the factor f:

where the sample bias coefficient ρ is the widely used Prais–Winsten estimate of the autocorrelation-coefficient (a quantity between −1 and +1) for all sample point pairs. This approximate formula is for moderate to large sample sizes; the reference gives the exact formulas for any sample size, and can be applied to heavily autocorrelated time series like Wall Street stock quotes. Moreover, this formula works for positive and negative ρ alike.[11] See also unbiased estimation of standard deviation for more discussion.
See also[edit]
- Illustration of the central limit theorem
- Margin of error
- Probable error
- Standard error of the weighted mean
- Sample mean and sample covariance
- Standard error of the median
- Variance
- Variance of the mean and predicted responses
References[edit]
- ^ a b c d Altman, Douglas G; Bland, J Martin (2005-10-15). «Standard deviations and standard errors». BMJ: British Medical Journal. 331 (7521): 903. doi:10.1136/bmj.331.7521.903. ISSN 0959-8138. PMC 1255808. PMID 16223828.
- ^ Everitt, B. S. (2003). The Cambridge Dictionary of Statistics. Cambridge University Press. ISBN 978-0-521-81099-9.
- ^ Gurland, J; Tripathi RC (1971). «A simple approximation for unbiased estimation of the standard deviation». American Statistician. 25 (4): 30–32. doi:10.2307/2682923. JSTOR 2682923.
- ^ Sokal; Rohlf (1981). Biometry: Principles and Practice of Statistics in Biological Research (2nd ed.). p. 53. ISBN 978-0-7167-1254-1.
- ^ Hutchinson, T. P. (1993). Essentials of Statistical Methods, in 41 pages. Adelaide: Rumsby. ISBN 978-0-646-12621-0.
- ^ Cornell, J R; Benjamin, C A (1970). Probability, Statistics, and Decisions for Civil Engineers. NY: McGraw-Hill. pp. 178–179. ISBN 0486796094.
- ^ Barde, M. (2012). «What to use to express the variability of data: Standard deviation or standard error of mean?». Perspect. Clin. Res. 3 (3): 113–116. doi:10.4103/2229-3485.100662. PMC 3487226. PMID 23125963.
- ^ Wassertheil-Smoller, Sylvia (1995). Biostatistics and Epidemiology : A Primer for Health Professionals (Second ed.). New York: Springer. pp. 40–43. ISBN 0-387-94388-9.
- ^ Isserlis, L. (1918). «On the value of a mean as calculated from a sample». Journal of the Royal Statistical Society. 81 (1): 75–81. doi:10.2307/2340569. JSTOR 2340569. (Equation 1)
- ^ Bondy, Warren; Zlot, William (1976). «The Standard Error of the Mean and the Difference Between Means for Finite Populations». The American Statistician. 30 (2): 96–97. doi:10.1080/00031305.1976.10479149. JSTOR 2683803. (Equation 2)
- ^ Bence, James R. (1995). «Analysis of Short Time Series: Correcting for Autocorrelation». Ecology. 76 (2): 628–639. doi:10.2307/1941218. JSTOR 1941218.
From Wikipedia, the free encyclopedia
For a value that is sampled with an unbiased normally distributed error, the above depicts the proportion of samples that would fall between 0, 1, 2, and 3 standard deviations above and below the actual value.
The standard error (SE)[1] of a statistic (usually an estimate of a parameter) is the standard deviation of its sampling distribution[2] or an estimate of that standard deviation. If the statistic is the sample mean, it is called the standard error of the mean (SEM).[1]
The sampling distribution of a mean is generated by repeated sampling from the same population and recording of the sample means obtained. This forms a distribution of different means, and this distribution has its own mean and variance. Mathematically, the variance of the sampling mean distribution obtained is equal to the variance of the population divided by the sample size. This is because as the sample size increases, sample means cluster more closely around the population mean.
Therefore, the relationship between the standard error of the mean and the standard deviation is such that, for a given sample size, the standard error of the mean equals the standard deviation divided by the square root of the sample size.[1] In other words, the standard error of the mean is a measure of the dispersion of sample means around the population mean.
In regression analysis, the term «standard error» refers either to the square root of the reduced chi-squared statistic or the standard error for a particular regression coefficient (as used in, say, confidence intervals).
Standard error of the sample mean[edit]
Exact value[edit]
Suppose a statistically independent sample of observations is taken from a statistical population with a standard deviation of . The mean value calculated from the sample, , will have an associated standard error on the mean, , given by:[1]
 .
.

Practically this tells us that when trying to estimate the value of a population mean, due to the factor , reducing the error on the estimate by a factor of two requires acquiring four times as many observations in the sample; reducing it by a factor of ten requires a hundred times as many observations.
Estimate[edit]
The standard deviation of the population being sampled is seldom known. Therefore, the standard error of the mean is usually estimated by replacing with the sample standard deviation instead:
- .

As this is only an estimator for the true «standard error», it is common to see other notations here such as:
- or alternately .


A common source of confusion occurs when failing to distinguish clearly between:
Accuracy of the estimator[edit]
When the sample size is small, using the standard deviation of the sample instead of the true standard deviation of the population will tend to systematically underestimate the population standard deviation, and therefore also the standard error. With n = 2, the underestimate is about 25%, but for n = 6, the underestimate is only 5%. Gurland and Tripathi (1971) provide a correction and equation for this effect.[3] Sokal and Rohlf (1981) give an equation of the correction factor for small samples of n < 20.[4] See unbiased estimation of standard deviation for further discussion.
Derivation[edit]
The standard error on the mean may be derived from the variance of a sum of independent random variables,[5] given the definition of variance and some simple properties thereof. If are independent samples from a population with mean and standard deviation , then we can define the total
which due to the Bienaymé formula, will have variance

where we’ve approximated the standard deviations, i.e., the uncertainties, of the measurements themselves with the best value for the standard deviation of the population. The mean of these measurements is simply given by
- .

The variance of the mean is then
The standard error is, by definition, the standard deviation of which is simply the square root of the variance:
- .

For correlated random variables the sample variance needs to be computed according to the Markov chain central limit theorem.
Independent and identically distributed random variables with random sample size[edit]
There are cases when a sample is taken without knowing, in advance, how many observations will be acceptable according to some criterion. In such cases, the sample size is a random variable whose variation adds to the variation of such that,
- [6]
If has a Poisson distribution, then with estimator  . Hence the estimator of becomes , leading the following formula for standard error:
. Hence the estimator of becomes , leading the following formula for standard error:
(since the standard deviation is the square root of the variance)
Student approximation when σ value is unknown[edit]
In many practical applications, the true value of σ is unknown. As a result, we need to use a distribution that takes into account that spread of possible σ’s.
When the true underlying distribution is known to be Gaussian, although with unknown σ, then the resulting estimated distribution follows the Student t-distribution. The standard error is the standard deviation of the Student t-distribution. T-distributions are slightly different from Gaussian, and vary depending on the size of the sample. Small samples are somewhat more likely to underestimate the population standard deviation and have a mean that differs from the true population mean, and the Student t-distribution accounts for the probability of these events with somewhat heavier tails compared to a Gaussian. To estimate the standard error of a Student t-distribution it is sufficient to use the sample standard deviation «s» instead of σ, and we could use this value to calculate confidence intervals.
Note: The Student’s probability distribution is approximated well by the Gaussian distribution when the sample size is over 100. For such samples one can use the latter distribution, which is much simpler.
Assumptions and usage[edit]
An example of how is used is to make confidence intervals of the unknown population mean. If the sampling distribution is normally distributed, the sample mean, the standard error, and the quantiles of the normal distribution can be used to calculate confidence intervals for the true population mean. The following expressions can be used to calculate the upper and lower 95% confidence limits, where is equal to the sample mean, is equal to the standard error for the sample mean, and 1.96 is the approximate value of the 97.5 percentile point of the normal distribution:
- Upper 95% limit and
- Lower 95% limit


In particular, the standard error of a sample statistic (such as sample mean) is the actual or estimated standard deviation of the sample mean in the process by which it was generated. In other words, it is the actual or estimated standard deviation of the sampling distribution of the sample statistic. The notation for standard error can be any one of SE, SEM (for standard error of measurement or mean), or SE.
Standard errors provide simple measures of uncertainty in a value and are often used because:
- in many cases, if the standard error of several individual quantities is known then the standard error of some function of the quantities can be easily calculated;
- when the probability distribution of the value is known, it can be used to calculate an exact confidence interval;
- when the probability distribution is unknown, Chebyshev’s or the Vysochanskiï–Petunin inequalities can be used to calculate a conservative confidence interval; and
- as the sample size tends to infinity the central limit theorem guarantees that the sampling distribution of the mean is asymptotically normal.
Standard error of mean versus standard deviation[edit]
In scientific and technical literature, experimental data are often summarized either using the mean and standard deviation of the sample data or the mean with the standard error. This often leads to confusion about their interchangeability. However, the mean and standard deviation are descriptive statistics, whereas the standard error of the mean is descriptive of the random sampling process. The standard deviation of the sample data is a description of the variation in measurements, while the standard error of the mean is a probabilistic statement about how the sample size will provide a better bound on estimates of the population mean, in light of the central limit theorem.[7]
Put simply, the standard error of the sample mean is an estimate of how far the sample mean is likely to be from the population mean, whereas the standard deviation of the sample is the degree to which individuals within the sample differ from the sample mean.[8] If the population standard deviation is finite, the standard error of the mean of the sample will tend to zero with increasing sample size, because the estimate of the population mean will improve, while the standard deviation of the sample will tend to approximate the population standard deviation as the sample size increases.
Extensions[edit]
Finite population correction (FPC)[edit]
The formula given above for the standard error assumes that the population is infinite. Nonetheless, it is often used for finite populations when people are interested in measuring the process that created the existing finite population (this is called an analytic study). Though the above formula is not exactly correct when the population is finite, the difference between the finite- and infinite-population versions will be small when sampling fraction is small (e.g. a small proportion of a finite population is studied). In this case people often do not correct for the finite population, essentially treating it as an «approximately infinite» population.
If one is interested in measuring an existing finite population that will not change over time, then it is necessary to adjust for the population size (called an enumerative study). When the sampling fraction (often termed f) is large (approximately at 5% or more) in an enumerative study, the estimate of the standard error must be corrected by multiplying by a »finite population correction» (a.k.a.: FPC):[9]
[10]
which, for large N:
to account for the added precision gained by sampling close to a larger percentage of the population. The effect of the FPC is that the error becomes zero when the sample size n is equal to the population size N.
This happens in survey methodology when sampling without replacement. If sampling with replacement, then FPC does not come into play.
Correction for correlation in the sample[edit]
Expected error in the mean of A for a sample of n data points with sample bias coefficient ρ. The unbiased standard error plots as the ρ = 0 diagonal line with log-log slope −½.
If values of the measured quantity A are not statistically independent but have been obtained from known locations in parameter space x, an unbiased estimate of the true standard error of the mean (actually a correction on the standard deviation part) may be obtained by multiplying the calculated standard error of the sample by the factor f:
where the sample bias coefficient ρ is the widely used Prais–Winsten estimate of the autocorrelation-coefficient (a quantity between −1 and +1) for all sample point pairs. This approximate formula is for moderate to large sample sizes; the reference gives the exact formulas for any sample size, and can be applied to heavily autocorrelated time series like Wall Street stock quotes. Moreover, this formula works for positive and negative ρ alike.[11] See also unbiased estimation of standard deviation for more discussion.
See also[edit]
- Illustration of the central limit theorem
- Margin of error
- Probable error
- Standard error of the weighted mean
- Sample mean and sample covariance
- Standard error of the median
- Variance
- Variance of the mean and predicted responses
References[edit]
- ^ a b c d Altman, Douglas G; Bland, J Martin (2005-10-15). «Standard deviations and standard errors». BMJ: British Medical Journal. 331 (7521): 903. doi:10.1136/bmj.331.7521.903. ISSN 0959-8138. PMC 1255808. PMID 16223828.
- ^ Everitt, B. S. (2003). The Cambridge Dictionary of Statistics. CUP. ISBN 978-0-521-81099-9.
- ^ Gurland, J; Tripathi RC (1971). «A simple approximation for unbiased estimation of the standard deviation». American Statistician. 25 (4): 30–32. doi:10.2307/2682923. JSTOR 2682923.
- ^ Sokal; Rohlf (1981). Biometry: Principles and Practice of Statistics in Biological Research (2nd ed.). p. 53. ISBN 978-0-7167-1254-1.
- ^ Hutchinson, T. P. (1993). Essentials of Statistical Methods, in 41 pages. Adelaide: Rumsby. ISBN 978-0-646-12621-0.
- ^ Cornell, J R, and Benjamin, C A, Probability, Statistics, and Decisions for Civil Engineers, McGraw-Hill, NY, 1970, ISBN 0486796094, pp. 178–9.
- ^ Barde, M. (2012). «What to use to express the variability of data: Standard deviation or standard error of mean?». Perspect. Clin. Res. 3 (3): 113–116. doi:10.4103/2229-3485.100662. PMC 3487226. PMID 23125963.
- ^ Wassertheil-Smoller, Sylvia (1995). Biostatistics and Epidemiology : A Primer for Health Professionals (Second ed.). New York: Springer. pp. 40–43. ISBN 0-387-94388-9.
- ^ Isserlis, L. (1918). «On the value of a mean as calculated from a sample». Journal of the Royal Statistical Society. 81 (1): 75–81. doi:10.2307/2340569. JSTOR 2340569. (Equation 1)
- ^ Bondy, Warren; Zlot, William (1976). «The Standard Error of the Mean and the Difference Between Means for Finite Populations». The American Statistician. 30 (2): 96–97. doi:10.1080/00031305.1976.10479149. JSTOR 2683803. (Equation 2)
- ^ Bence, James R. (1995). «Analysis of Short Time Series: Correcting for Autocorrelation». Ecology. 76 (2): 628–639. doi:10.2307/1941218. JSTOR 1941218.
Стандартное отклонение и стандартная ошибка: в чем разница?
17 авг. 2022 г.
читать 2 мин
В статистике студенты часто путают два термина: стандартное отклонение и стандартная ошибка .
Стандартное отклонение измеряет, насколько разбросаны значения в наборе данных.
Стандартная ошибка — это стандартное отклонение среднего значения в повторных выборках из совокупности.
Давайте рассмотрим пример, чтобы ясно проиллюстрировать эту идею.
Пример: стандартное отклонение против стандартной ошибки
Предположим, мы измеряем вес 10 разных черепах.

Для этой выборки из 10 черепах мы можем вычислить среднее значение выборки и стандартное отклонение выборки:

Предположим, что стандартное отклонение оказалось равным 8,68. Это дает нам представление о том, насколько распределен вес этих черепах.
Но предположим, что мы собираем еще одну простую случайную выборку из 10 черепах и также проводим их измерения. Более чем вероятно, что эта выборка из 10 черепах будет иметь немного другое среднее значение и стандартное отклонение, даже если они взяты из одной и той же популяции:

Теперь, если мы представим, что мы берем повторные выборки из одной и той же совокупности и записываем выборочное среднее и выборочное стандартное отклонение для каждой выборки:

Теперь представьте, что мы наносим каждое среднее значение выборки на одну и ту же строку:

Стандартное отклонение этих средних значений известно как стандартная ошибка.

Формула для фактического расчета стандартной ошибки:
Стандартная ошибка = s/ √n
куда:
- s: стандартное отклонение выборки
- n: размер выборки
Какой смысл использовать стандартную ошибку?
Когда мы вычисляем среднее значение данной выборки, нас на самом деле интересует не среднее значение этой конкретной выборки, а скорее среднее значение большей совокупности, из которой взята выборка.
Однако мы используем выборки, потому что для них гораздо проще собирать данные, чем для всего населения. И, конечно же, среднее значение выборки будет варьироваться от выборки к выборке, поэтому мы используем стандартную ошибку среднего значения как способ измерить, насколько точна наша оценка среднего значения.
Вы заметите из формулы для расчета стандартной ошибки, что по мере увеличения размера выборки (n) стандартная ошибка уменьшается:
Стандартная ошибка = s/ √n
Это должно иметь смысл, поскольку большие размеры выборки уменьшают изменчивость и увеличивают вероятность того, что среднее значение нашей выборки ближе к фактическому среднему значению генеральной совокупности.
Когда использовать стандартное отклонение против стандартной ошибки
Если мы просто заинтересованы в измерении того, насколько разбросаны значения в наборе данных, мы можем использовать стандартное отклонение .
Однако, если мы заинтересованы в количественной оценке неопределенности оценки среднего значения, мы можем использовать стандартную ошибку среднего значения .
В зависимости от вашего конкретного сценария и того, чего вы пытаетесь достичь, вы можете использовать либо стандартное отклонение, либо стандартную ошибку.
Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы

Стандартная ошибка или, как часто называют, ошибка средней арифметической, является одним из важных статистических показателей. С помощью данного показателя можно определить неоднородность выборки. Он также довольно важен при прогнозировании. Давайте узнаем, какими способами можно рассчитать величину стандартной ошибки с помощью инструментов Microsoft Excel.
Расчет ошибки средней арифметической
Одним из показателей, которые характеризуют цельность и однородность выборки, является стандартная ошибка. Эта величина представляет собой корень квадратный из дисперсии. Сама дисперсия является средним квадратном от средней арифметической. Средняя арифметическая вычисляется делением суммарной величины объектов выборки на их общее количество.
В Экселе существуют два способа вычисления стандартной ошибки: используя набор функций и при помощи инструментов Пакета анализа. Давайте подробно рассмотрим каждый из этих вариантов.
Способ 1: расчет с помощью комбинации функций
Прежде всего, давайте составим алгоритм действий на конкретном примере по расчету ошибки средней арифметической, используя для этих целей комбинацию функций. Для выполнения задачи нам понадобятся операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ.
Для примера нами будет использована выборка из двенадцати чисел, представленных в таблице.

- Выделяем ячейку, в которой будет выводиться итоговое значение стандартной ошибки, и клацаем по иконке «Вставить функцию».
- Открывается Мастер функций. Производим перемещение в блок «Статистические». В представленном перечне наименований выбираем название «СТАНДОТКЛОН.В».
- Запускается окно аргументов вышеуказанного оператора. СТАНДОТКЛОН.В предназначен для оценивания стандартного отклонения при выборке. Данный оператор имеет следующий синтаксис:
=СТАНДОТКЛОН.В(число1;число2;…)«Число1» и последующие аргументы являются числовыми значениями или ссылками на ячейки и диапазоны листа, в которых они расположены. Всего может насчитываться до 255 аргументов этого типа. Обязательным является только первый аргумент.
Итак, устанавливаем курсор в поле «Число1». Далее, обязательно произведя зажим левой кнопки мыши, выделяем курсором весь диапазон выборки на листе. Координаты данного массива тут же отображаются в поле окна. После этого клацаем по кнопке «OK».
- В ячейку на листе выводится результат расчета оператора СТАНДОТКЛОН.В. Но это ещё не ошибка средней арифметической. Для того, чтобы получить искомое значение, нужно стандартное отклонение разделить на квадратный корень от количества элементов выборки. Для того, чтобы продолжить вычисления, выделяем ячейку, содержащую функцию СТАНДОТКЛОН.В. После этого устанавливаем курсор в строку формул и дописываем после уже существующего выражения знак деления (/). Вслед за этим клацаем по пиктограмме перевернутого вниз углом треугольника, которая располагается слева от строки формул. Открывается список недавно использованных функций. Если вы в нем найдете наименование оператора «КОРЕНЬ», то переходите по данному наименованию. В обратном случае жмите по пункту «Другие функции…».
- Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
- Открывается окно аргументов функции КОРЕНЬ. Единственной задачей данного оператора является вычисление квадратного корня из заданного числа. Его синтаксис предельно простой:
=КОРЕНЬ(число)Как видим, функция имеет всего один аргумент «Число». Он может быть представлен числовым значением, ссылкой на ячейку, в которой оно содержится или другой функцией, вычисляющей это число. Последний вариант как раз и будет представлен в нашем примере.
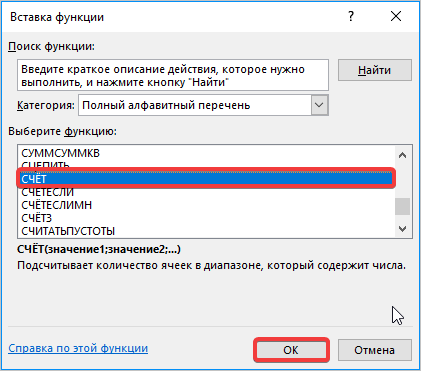
Устанавливаем курсор в поле «Число» и кликаем по знакомому нам треугольнику, который вызывает список последних использованных функций. Ищем в нем наименование «СЧЁТ». Если находим, то кликаем по нему. В обратном случае, опять же, переходим по наименованию «Другие функции…».
- В раскрывшемся окне Мастера функций производим перемещение в группу «Статистические». Там выделяем наименование «СЧЁТ» и выполняем клик по кнопке «OK».
- Запускается окно аргументов функции СЧЁТ. Указанный оператор предназначен для вычисления количества ячеек, которые заполнены числовыми значениями. В нашем случае он будет подсчитывать количество элементов выборки и сообщать результат «материнскому» оператору КОРЕНЬ. Синтаксис функции следующий:
=СЧЁТ(значение1;значение2;…)В качестве аргументов «Значение», которых может насчитываться до 255 штук, выступают ссылки на диапазоны ячеек. Ставим курсор в поле «Значение1», зажимаем левую кнопку мыши и выделяем весь диапазон выборки. После того, как его координаты отобразились в поле, жмем на кнопку «OK».
- После выполнения последнего действия будет не только рассчитано количество ячеек заполненных числами, но и вычислена ошибка средней арифметической, так как это был последний штрих в работе над данной формулой. Величина стандартной ошибки выведена в ту ячейку, где размещена сложная формула, общий вид которой в нашем случае следующий:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13))Результат вычисления ошибки средней арифметической составил 0,505793. Запомним это число и сравним с тем, которое получим при решении поставленной задачи следующим способом.










Но дело в том, что для малых выборок (до 30 единиц) для большей точности лучше применять немного измененную формулу. В ней величина стандартного отклонения делится не на квадратный корень от количества элементов выборки, а на квадратный корень от количества элементов выборки минус один. Таким образом, с учетом нюансов малой выборки наша формула приобретет следующий вид:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1)

Урок: Статистические функции в Экселе
Способ 2: применение инструмента «Описательная статистика»
Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Но чтобы воспользоваться данной возможностью, нужно сразу активировать «Пакет анализа», так как по умолчанию в Экселе он отключен.
- После того, как открыт документ с выборкой, переходим во вкладку «Файл».
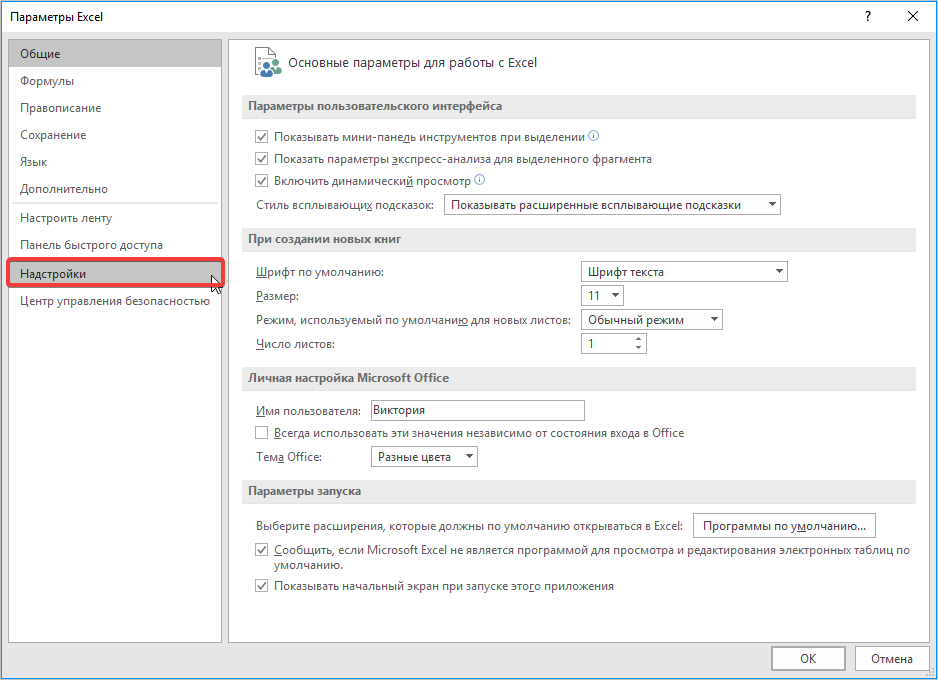
- Далее, воспользовавшись левым вертикальным меню, перемещаемся через его пункт в раздел «Параметры».
- Запускается окно параметров Эксель. В левой части данного окна размещено меню, через которое перемещаемся в подраздел «Надстройки».
- В самой нижней части появившегося окна расположено поле «Управление». Выставляем в нем параметр «Надстройки Excel» и жмем на кнопку «Перейти…» справа от него.
- Запускается окно надстроек с перечнем доступных скриптов. Отмечаем галочкой наименование «Пакет анализа» и щелкаем по кнопке «OK» в правой части окошка.
- После выполнения последнего действия на ленте появится новая группа инструментов, которая имеет наименование «Анализ». Чтобы перейти к ней, щелкаем по названию вкладки «Данные».
- После перехода жмем на кнопку «Анализ данных» в блоке инструментов «Анализ», который расположен в самом конце ленты.
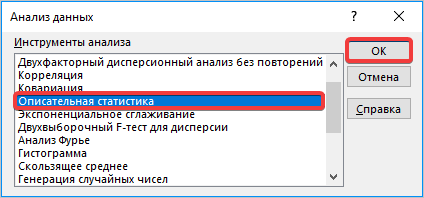
- Запускается окошко выбора инструмента анализа. Выделяем наименование «Описательная статистика» и жмем на кнопку «OK» справа.
- Запускается окно настроек инструмента комплексного статистического анализа «Описательная статистика».
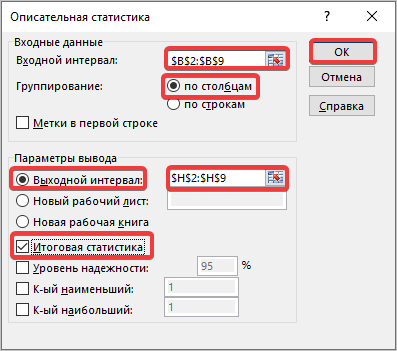
В поле «Входной интервал» необходимо указать диапазон ячеек таблицы, в которых находится анализируемая выборка. Вручную это делать неудобно, хотя и можно, поэтому ставим курсор в указанное поле и при зажатой левой кнопке мыши выделяем соответствующий массив данных на листе. Его координаты тут же отобразятся в поле окна.
В блоке «Группирование» оставляем настройки по умолчанию. То есть, переключатель должен стоять около пункта «По столбцам». Если это не так, то его следует переставить.
Галочку «Метки в первой строке» можно не устанавливать. Для решения нашего вопроса это не важно.
Далее переходим к блоку настроек «Параметры вывода». Здесь следует указать, куда именно будет выводиться результат расчета инструмента «Описательная статистика»:
- На новый лист;
- В новую книгу (другой файл);
- В указанный диапазон текущего листа.
Давайте выберем последний из этих вариантов. Для этого переставляем переключатель в позицию «Выходной интервал» и устанавливаем курсор в поле напротив данного параметра. После этого клацаем на листе по ячейке, которая станет верхним левым элементом массива вывода данных. Её координаты должны отобразиться в поле, в котором мы до этого устанавливали курсор.
Далее следует блок настроек определяющий, какие именно данные нужно вводить:
- Итоговая статистика;
- К-ый наибольший;
- К-ый наименьший;
- Уровень надежности.
Для определения стандартной ошибки обязательно нужно установить галочку около параметра «Итоговая статистика». Напротив остальных пунктов выставляем галочки на свое усмотрение. На решение нашей основной задачи это никак не повлияет.
После того, как все настройки в окне «Описательная статистика» установлены, щелкаем по кнопке «OK» в его правой части.
- После этого инструмент «Описательная статистика» выводит результаты обработки выборки на текущий лист. Как видим, это довольно много разноплановых статистических показателей, но среди них есть и нужный нам – «Стандартная ошибка». Он равен числу 0,505793. Это в точности тот же результат, который мы достигли путем применения сложной формулы при описании предыдущего способа.










Урок: Описательная статистика в Экселе
Как видим, в Экселе можно произвести расчет стандартной ошибки двумя способами: применив набор функций и воспользовавшись инструментом пакета анализа «Описательная статистика». Итоговый результат будет абсолютно одинаковый. Поэтому выбор метода зависит от удобства пользователя и поставленной конкретной задачи. Например, если ошибка средней арифметической является только одним из многих статистических показателей выборки, которые нужно рассчитать, то удобнее воспользоваться инструментом «Описательная статистика». Но если вам нужно вычислить исключительно этот показатель, то во избежание нагромождения лишних данных лучше прибегнуть к сложной формуле. В этом случае результат расчета уместится в одной ячейке листа.
Аннотация: Лекция посвящена основам анализа данных, рассмотрены основные характеристики описательной статистики, кратко изложена суть корреляционного и регрессионного анализа. Приведены примеры решения задач в Microsoft Excel.
В этой лекции мы рассмотрим некоторые аспекты статистического анализа данных, в частности, описательную статистику, корреляционный и регрессионный анализы. Статистический анализ включает большое разнообразие методов, даже для поверхностного знакомства с которыми объема одной лекции слишком мало. Цель данной лекции — дать самое общее представление о понятиях корреляции, регрессии, а также познакомиться с описательной статистикой. Примеры, рассмотренные в лекции, намеренно упрощены.
Существует большое разнообразие прикладных пакетов, реализующих широкий спектр статистических методов, их также называют универсальными пакетами или инструментальными наборами. О таких наборах мы подробно поговорим в последнем разделе курса. В Microsoft Excel также реализован широкий арсенал методов математической статистики, реализация примеров данной лекции продемонстрирована именно на этом программном обеспечении.
Следует заметить, что существует сложность использования статистических методов, так же как и статистического программного обеспечения, — для этого пользователю необходимы специальные знания.
Анализ данных в Microsoft Excel
Microsoft Excel имеет большое число статистических функций. Некоторые являются встроенными, некоторые доступны после установки пакета анализа. В данной лекции мы воспользуемся именно этим программным обеспечением.
Обращение к Пакету анализа. Средства, включенные в пакет анализа данных, доступны через команду Анализ данных меню Сервис. Если эта команда отсутствует в меню, в меню Сервис/Надстройки необходимо активировать пункт «Пакет анализа».
Далее мы рассмотрим некоторые инструменты, включенные в Пакет анализа.
Описательная статистика
Описательная статистика (Descriptive statistics ) — техника сбора и суммирования количественных данных, которая используется для превращения массы цифровых данных в форму, удобную для восприятия и обсуждения.
Цель описательной статистики — обобщить первичные результаты, полученные в результате наблюдений и экспериментов.
Пусть дан набор данных А, представленный в таблице 8.1.
Таблица
8.1.
Набор данных А
| x | y |
|---|---|
| 3 | 9 |
| 2 | 7 |
| 4 | 12 |
| 5 | 15 |
| 6 | 17 |
| 7 | 19 |
| 8 | 21 |
| 9 | 23,4 |
| 10 | 25,6 |
| 11 | 27,8 |
Выбрав в меню Сервис «Пакет анализа» и выбрав инструмент анализа «Описательная статистика», получаем одномерный статистический отчет, содержащий информацию о центральной тенденции и изменчивости или вариации входных данных.
В состав описательной статистики входят такие характеристики: среднее ; стандартная ошибка; медиана ; мода; стандартное отклонение ; дисперсия выборки; эксцесс ; асимметричность; интервал; минимум ; максимум; сумма; счет.
Отчет «Описательная статистика» для двух переменных их набора данных А приведен в таблице 8.2.
Таблица
8.2.
Описательная статистика для набора данных А
| x | y | |
|---|---|---|
| Среднее | 6,5 | 17,68 |
| Стандартная ошибка | 0,957427108 | 2,210922382 |
| Медиана | 6,5 | 18 |
| Стандартное отклонение | 3,027650354 | 6,991550456 |
| Дисперсия выборки | 9,166666667 | 48,88177778 |
| Эксцесс | -1,2 | -1,106006058 |
| Асимметричность | 0 | -0,128299221 |
| Интервал | 9 | 20,8 |
| Минимум | 2 | 7 |
| Максимум | 11 | 27,8 |
| Сумма | 65 | 176,8 |
| Счет | 10 | 10 |
| Наибольший (1) | 11 | 27,8 |
| Наименьший (1) | 2 | 7 |
| Уровень надежности (95,0%) | 2,16585224 | 5,001457714 |
Рассмотрим, что же представляют собой характеристики описательной статистики.
Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).

Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).

Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях:
What Is the Standard Error?
The standard error (SE) of a statistic is the approximate standard deviation of a statistical sample population.
The standard error is a statistical term that measures the accuracy with which a sample distribution represents a population by using standard deviation. In statistics, a sample mean deviates from the actual mean of a population; this deviation is the standard error of the mean.
Key Takeaways
- The standard error (SE) is the approximate standard deviation of a statistical sample population.
- The standard error describes the variation between the calculated mean of the population and one which is considered known, or accepted as accurate.
- The more data points involved in the calculations of the mean, the smaller the standard error tends to be.
Standard Error
Understanding Standard Error
The term «standard error» is used to refer to the standard deviation of various sample statistics, such as the mean or median. For example, the «standard error of the mean» refers to the standard deviation of the distribution of sample means taken from a population. The smaller the standard error, the more representative the sample will be of the overall population.
The relationship between the standard error and the standard deviation is such that, for a given sample size, the standard error equals the standard deviation divided by the square root of the sample size. The standard error is also inversely proportional to the sample size; the larger the sample size, the smaller the standard error because the statistic will approach the actual value.
The standard error is considered part of inferential statistics. It represents the standard deviation of the mean within a dataset. This serves as a measure of variation for random variables, providing a measurement for the spread. The smaller the spread, the more accurate the dataset.
Standard error and standard deviation are measures of variability, while central tendency measures include mean, median, etc.
Formula and Calculation of Standard Error
The standard error of an estimate can be calculated as the standard deviation divided by the square root of the sample size:
SE = σ / √n
where
- σ = the population standard deviation
- √n = the square root of the sample size
If the population standard deviation is not known, you can substitute the sample standard deviation, s, in the numerator to approximate the standard error.
Requirements for Standard Error
When a population is sampled, the mean, or average, is generally calculated. The standard error can include the variation between the calculated mean of the population and one which is considered known, or accepted as accurate. This helps compensate for any incidental inaccuracies related to the gathering of the sample.
In cases where multiple samples are collected, the mean of each sample may vary slightly from the others, creating a spread among the variables. This spread is most often measured as the standard error, accounting for the differences between the means across the datasets.
The more data points involved in the calculations of the mean, the smaller the standard error tends to be. When the standard error is small, the data is said to be more representative of the true mean. In cases where the standard error is large, the data may have some notable irregularities.
The standard deviation is a representation of the spread of each of the data points. The standard deviation is used to help determine the validity of the data based on the number of data points displayed at each level of standard deviation. Standard errors function more as a way to determine the accuracy of the sample or the accuracy of multiple samples by analyzing deviation within the means.
Standard Error vs. Standard Deviation
The standard error normalizes the standard deviation relative to the sample size used in an analysis. Standard deviation measures the amount of variance or dispersion of the data spread around the mean. The standard error can be thought of as the dispersion of the sample mean estimations around the true population mean. As the sample size becomes larger, the standard error will become smaller, indicating that the estimated sample mean value better approximates the population mean.
Example of Standard Error
Say that an analyst has looked at a random sample of 50 companies in the S&P 500 to understand the association between a stock’s P/E ratio and subsequent 12-month performance in the market. Assume that the resulting estimate is -0.20, indicating that for every 1.0 point in the P/E ratio, stocks return 0.2% poorer relative performance. In the sample of 50, the standard deviation was found to be 1.0.
The standard error is thus:
SE = 1.0/√50 = 1/7.07 = 0.141
Therefore, we would report the estimate as -0.20% ± 0.14, giving us a confidence interval of (-0.34 — -0.06). The true mean value of the association of the P/E on returns of the S&P 500 would therefore fall within that range with a high degree of probability.
Say now that we increase the sample of stocks to 100 and find that the estimate changes slightly from -0.20 to -0.25, and the standard deviation falls to 0.90. The new standard error would thus be:
SE = 0.90/√100 = 0.90/10 = 0.09.
The resulting confidence interval becomes -0.25 ± 0.09 = (-0.34 — -0.16), which is a tighter range of values.
What Is Meant by Standard Error?
Standard error is intuitively the standard deviation of the sampling distribution. In other words, it depicts how much disparity there is likely to be in a point estimate obtained from a sample relative to the true population mean.
What Is a Good Standard Error?
Standard error measures the amount of discrepancy that can be expected in a sample estimate compared to the true value in the population. Therefore, the smaller the standard error the better. In fact, a standard error of zero (or close to it) would indicate that the estimated value is exactly the true value.
How Do You Find the Standard Error?
The standard error takes the standard deviation and divides it by the square root of the sample size. Many statistical software packages automatically compute standard errors.
The Bottom Line
The standard error (SE) measures the dispersion of estimated values obtained from a sample around the true value to be found in the population. Statistical analysis and inference often involves drawing samples and running statistical tests to determine associations and correlations between variables. The standard error thus tells us with what degree of confidence we can expect the estimated value to approximate the population value.
Стандартная ошибка появляется при прогнозировании каких-либо данных или арифметических вычислениях, поэтому важно научиться находить этот параметр. В этой публикации разбираем, как найти и исправить стандартную ошибку путем использования инструментов Excel.
Расчет средней арифметической ошибки
В Microsoft Excel цельность и однородность выборки определяется при помощи стандартной ошибки. Стандартная ошибка — это квадратный корень из дисперсии. В приложении предусмотрено два варианта поиска стандартной ошибки: при помощи пакетного анализа и расширенных функций программы.
Чтобы найти значение средней арифметической, необходимо выполнить деление суммарной величины выборки на ее количество в электронной книге.
Расчет стандартной ошибки при помощи встроенных функций
Для того, чтобы правильно вычислять, необходимо изучить пошаговую инструкцию. В этом способе подбор результатов будет осуществляться с помощью комбинированных манипуляций.
- Для расчетов будем использовать таблицу с выборкой чисел. Кликаем на любой пустой ячейке на листе, где будет отображаться результат. Затем нажимаем кнопку «Вставить функцию.
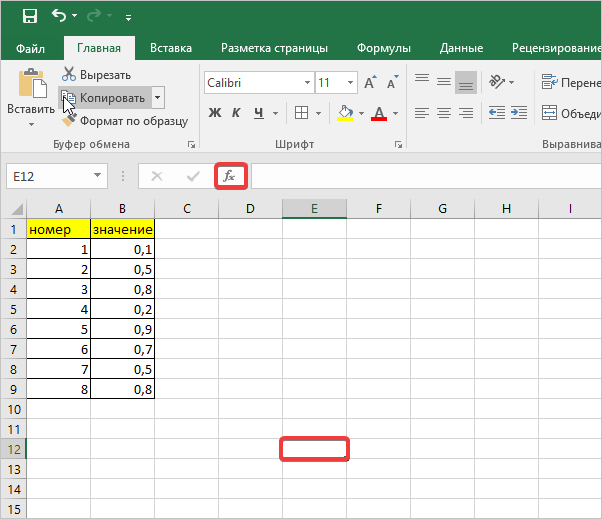
- Далее перед вами открывается диалоговое окно, в котором необходимо использовать «СТАНДОТКЛ.В», для этого в поле «Категория» необходимо выбрать «Полный алфавитный перечень». Затем нажмите кнопку «ОК».
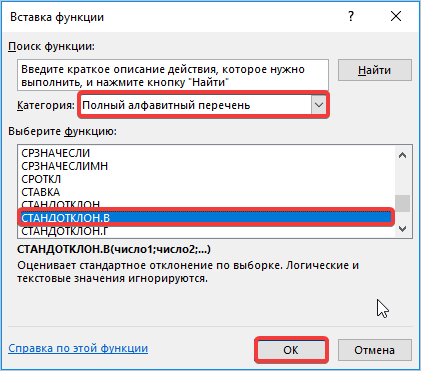
- В окне «Аргументы функции» кликаем в первом поле «Число 1», затем выполняем выделение мышью диапазона ячеек со значениями таблицы и нажимаем кнопку «ОК».
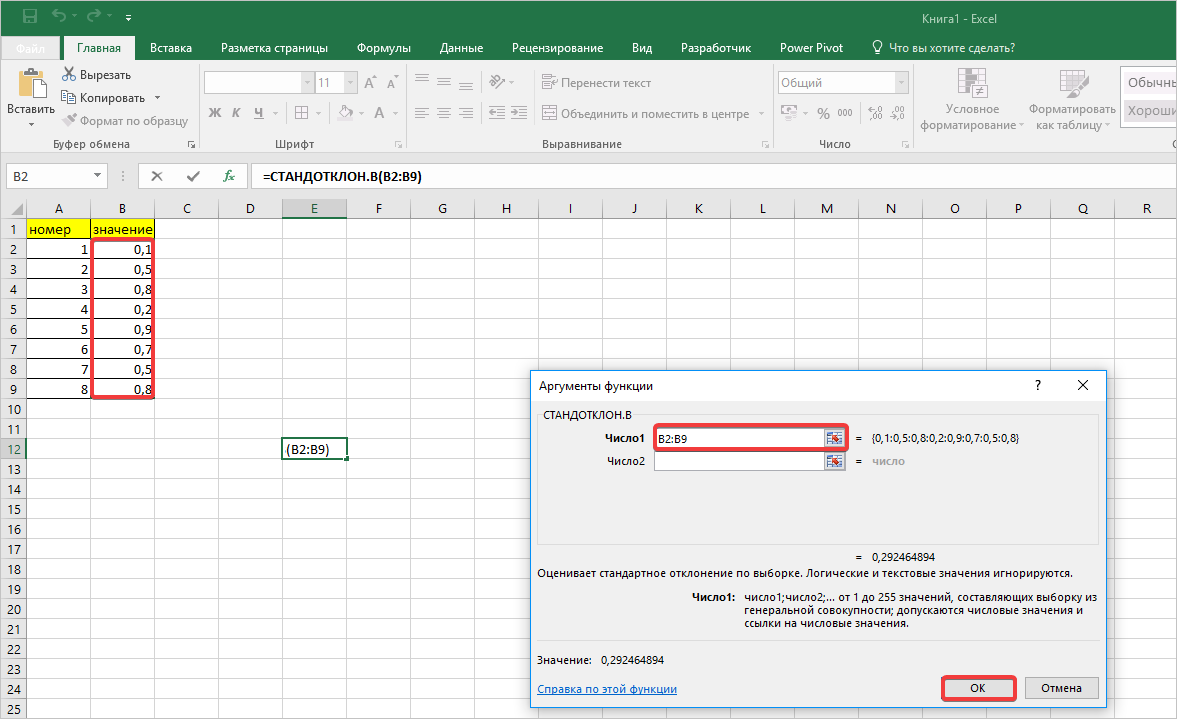
- Далее активируем ячейку с нашими значениями, переходим в строку формулы и ставим после значений наклонную линию. Переходим в поле наименования, кликаем на указывающий вниз флажок, где из списка выбираем «Другие функции».
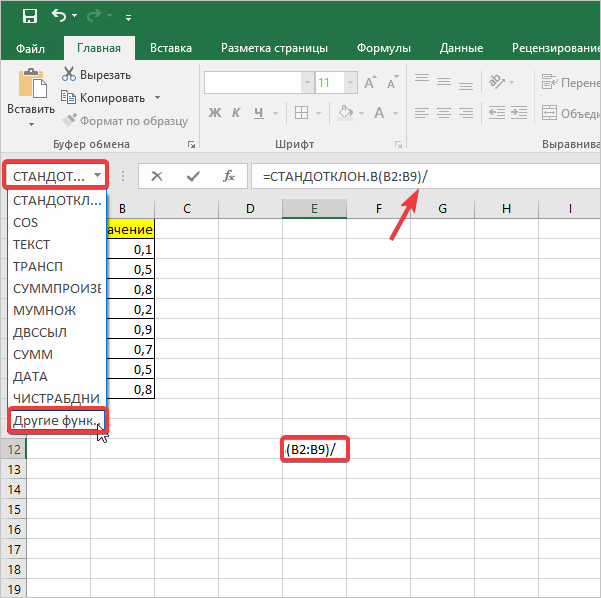
- Снова активируется окно с перечнем функций, в котором необходимо выбрать категорию «Математические», затем функцию «Корень». Далее нажмите кнопку «ОК».
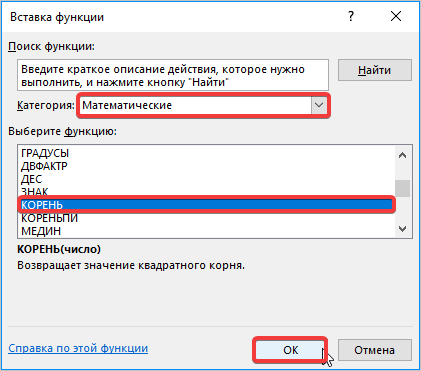
- Далее открывается окно, в котором необходимо заполнить поле с числом. Для этого переходим в поле «Имя», где спускаемся к пункту «Счет». Если его нет, ищите в дополнительных функциях.
После выполнения этих шагов, стандартная ошибка высчитывается автоматически, пользователю остается только сверить их и проверить значение на некорректное отображение.
Для малых и стандартных выборок необходимо использовать разные формулы. В первом случае (если находится до 30 значений), ее необходимо видоизменить.
Решение задачи с помощью опции «Описательная статистика»
Благодаря опции «Описательная статистика» удается выполнить вычисление по различным критериям. По этим правилам удается найти среднюю арифметическую ошибку. Для использования данного метода предварительно нужно запустить «Пакет анализа».
- Переходим во вкладку «Файл», где перемещаемся в пункт «Параметры». Далее нажимаем на запись «Надстройки».
- Открывается окошко, в нем в графе «Управление» должно быть прописано «Надстройки Excel», затем рядом нажимаем кнопку «Параметры».
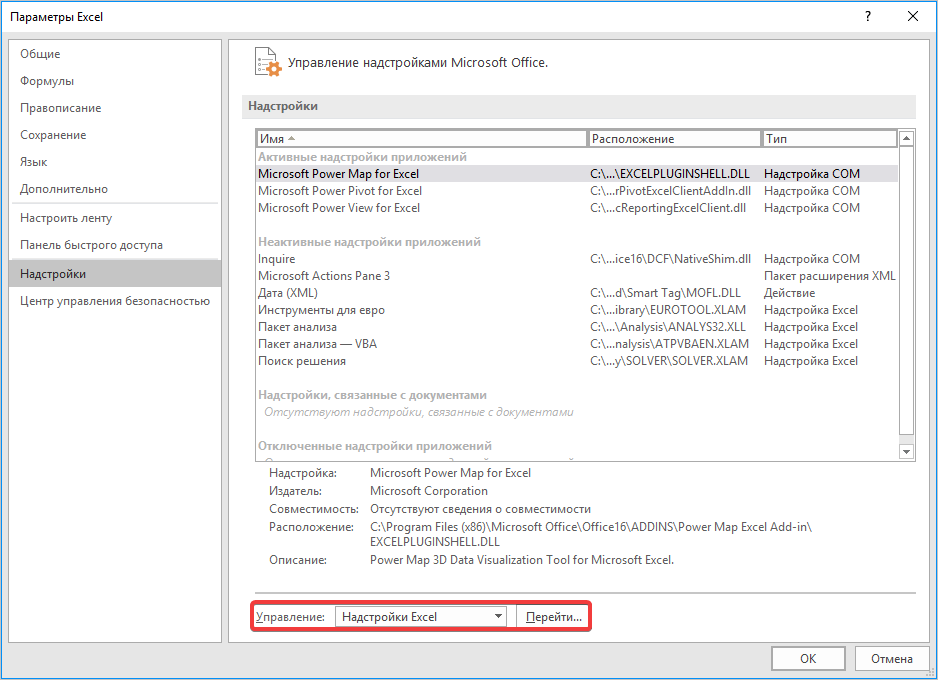
- В появившемся окне находим «Пакет анализа» и нажимаем кнопку «ОК».
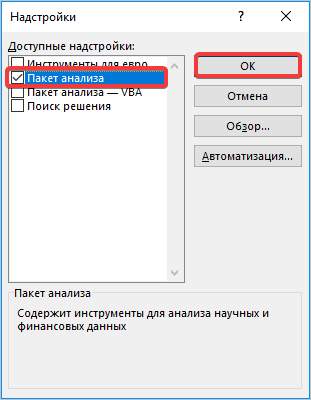
- Далее выбираем любую свободную ячейку, переходим во вкладку «Данные» и нажимаем «Анализ данных» в блоке «Анализ».

- Происходит запуск вспомогательного окошка, в котором необходимо выбрать из всех инструментов «Описательную статистику» и нажать кнопку «ОК».
- Открывается новый мастер значений. Здесь нужно вводить данные предельно внимательно. В поле «Входной интервал» вносим адрес диапазона ячеек с выборкой. Затем указываем параметр «Группирование» «По столбцам». Затем выбираем место для «выходного интервала», его должно быть столько же, сколько и «входного». Ставим галочку напротив «Итоговая статистика» и нажимаем кнопку «ОК».
В результате вычислений вы получаете небольшую таблицу, в которой указаны все данные с определенной стандартной ошибкой.

Стандартное отклонение оно определяется как абсолютная мера рассеивания ряда. Уточнить стандартное количество вариаций с каждой стороны от среднего. Это часто неверно истолковывается как стандартная ошибка, поскольку основывается на стандартном отклонении и размере выборки.
Стандартная ошибка Он используется для измерения статистической точности оценки. Он в основном используется в процессе проверки гипотез и интервал оценки.
Это две важные концепции статистики, которые широко используются в области исследований. Разница между стандартным отклонением и стандартной ошибкой основана на разнице между описанием данных и их выводом.
Сравнительный график
Основа для сравнения Стандартное отклонение Стандартная ошибка
| чувство | Стандартное отклонение подразумевает меру разброса множества значений его среднего значения. | Стандартная ошибка обозначает меру статистической точности оценки. |
| статистика | описательный | выведенный |
| меры | Сколько наблюдений отличаются друг от друга? | Насколько точный образец означает для истинной популяции. |
| распределение | Распределение наблюдения относительно нормальной кривой. | Распределение оценки относительно нормальной кривой. |
| формула | Квадратный корень дисперсии | Стандартное отклонение, деленное на квадратный корень размера выборки. |
| Увеличение размера выборки. | Дает более конкретную меру стандартного отклонения. | Уменьшает стандартную ошибку. |
Определение стандартного отклонения
Стандартное отклонение является мерой протяженности ряда или расстояния от нормы. В 1893 году Карл Пирсон ввел понятие стандартного отклонения, которое, возможно, является наиболее широко используемой мерой в научных исследованиях.
Это квадратный корень из средних квадратов отклонений от их среднего значения. Другими словами, для данного набора данных стандартное отклонение является среднеквадратичным отклонением среднего арифметического. Для всего населения это обозначено греческой буквой «sigma ()», а для выборки – латинской буквой «s».
Стандартное отклонение является мерой, которая количественно определяет степень разброса набора наблюдений. Чем дальше точки данных от среднего значения, тем больше отклонение в наборе данных, что означает, что точки данных распределены по более широкому диапазону значений и наоборот.
Определение стандартной ошибки
Возможно, вы заметили, что разные выборки одинакового размера, взятые из одной и той же популяции, будут давать разные статистические значения, то есть среднее значение выборки. Стандартная ошибка (SE) обеспечивает стандартное отклонение при различных значениях от среднего значения по выборке. Он используется для сравнения средних выборок во всех популяциях.
Таким образом, стандартная ошибка статистики является не чем иным, как стандартным отклонением ее выборочного распределения. Он играет большую роль в статистической гипотезе и тесте оценки интервалов. Дает представление о точности и достоверности оценки. Чем меньше стандартная ошибка, тем больше однородность теоретического распределения и наоборот.
- формула : Стандартная ошибка для выборочного среднего = / н Где стандартное отклонение населения
Ключевые различия между стандартным отклонением и стандартной ошибкой
Точки, перечисленные ниже, являются существенными, когда речь идет о разнице между стандартным отклонением:
- Стандартное отклонение – это мера, которая оценивает количество вариаций в наборе наблюдений. Стандартная ошибка измеряет точность оценки, то есть является мерой изменчивости теоретического распределения статистики.
- Стандартное отклонение является описательной статистикой, в то время как стандартная ошибка является логической статистикой.
- Стандартное отклонение показывает, насколько далеко отдельные значения от среднего значения. И наоборот, насколько близко выборка означает среднее значение для населения.
- Стандартное отклонение – это распределение наблюдений со ссылкой на нормальную кривую. В противоположность этому, стандартной ошибкой является распределение оценки со ссылкой на нормальную кривую.
- Стандартное отклонение определяется как квадратный корень из дисперсии. И наоборот, стандартная ошибка описывается как стандартное отклонение, деленное на квадратный корень размера выборки.
- Поскольку размер выборки увеличивается, это обеспечивает более конкретную меру стандартного отклонения. В отличие от стандартной ошибки, когда размер выборки увеличивается, стандартная ошибка имеет тенденцию уменьшаться.
заключение
В целом, стандартное отклонение считается одной из лучших мер дисперсии, которая измеряет дисперсию значений центрального значения. С другой стороны, стандартная ошибка в основном используется для проверки достоверности и точности оценки и, следовательно, чем меньше ошибка, тем выше ее надежность и точность.
Post Views: 86
Описательные статистики
Среднее арифметическое
Медиана
Мода
Среднее геометрическое
Взвешенное среднее
Размах (интервал изменения)
Размах, полученный из процентилей
Что такое процентили
Применение процентилей
Дисперсия
Cреднеквадратическое отклонение, стандартное отклонение выборки
Вариация в пределах субъектов и между субъектами
Пусть Х1, Х2 … Xn — выборка независимых случайных величин.
Упорядочим эти величины по возрастанию, иными словами, построим вариационный ряд:
Х(1) < Х(2) < … < X (n) , (*)
где Х(1) = min ( Х1, Х2 … Xn),
Х(n) = max ( Х1, Х2 … Xn).
Элементы вариационного ряда (*) называются порядковыми статистиками.
Величины d(i) = X(i+1) — X(i) называются спейсингами или расстояниями между порядковыми статистиками.
Размахом выборки называется величина
R = X(n) — X(1)
Иными словами, размах это расстояние между максимальным и минимальным членом вариационного ряда.
Выборочное среднее равно: ![]() = (Х1 + Х2 + … + Xn) / n
= (Х1 + Х2 + … + Xn) / n
Среднее арифметическое
Вероятно, большинство из вас использовало такую важную описательную статистику, как среднее.
Среднее — очень информативная мера «центрального положения» наблюдаемой переменной, особенно если сообщается ее доверительный интервал. Исследователю нужны такие статистики, которые позволяют сделать вывод относительно популяции в целом. Одной из таких статистик является среднее.
Доверительный интервал для среднего представляет интервал значений вокруг оценки, где с данным уровнем доверия, находится «истинное» (неизвестное) среднее популяции.
Например, если среднее выборки равно 23, а нижняя и верхняя границы доверительного интервала с уровнем p=.95 равны 19 и 27 соответственно, то можно заключить, что с вероятностью 95% интервал с границами 19 и 27 накрывает среднее популяции.
Если вы установите больший уровень доверия, то интервал станет шире, поэтому возрастает вероятность, с которой он «накрывает» неизвестное среднее популяции, и наоборот.
Хорошо известно, например, что чем «неопределенней» прогноз погоды (т.е. шире доверительный интервал), тем вероятнее он будет верным. Заметим, что ширина доверительного интервала зависит от объема или размера выборки, а также от разброса (изменчивости) данных. Увеличение размера выборки делает оценку среднего более надежной. Увеличение разброса наблюдаемых значений уменьшает надежность оценки.
Вычисление доверительных интервалов основывается на предположении нормальности наблюдаемых величин. Если это предположение не выполнено, то оценка может оказаться плохой, особенно для малых выборок.
При увеличении объема выборки, скажем, до 100 или более, качество оценки улучшается и без предположения нормальности выборки.
Довольно трудно «ощутить» числовые измерения, пока данные не будут содержательно обобщены. Диаграмма часто полезна в качестве отправной точки. Мы можем также сжать информацию, используя важные характеристики данных. В частности, если бы мы знали, из чего состоит представленная величина, или если бы мы знали, насколько широко рассеяны наблюдения, то мы бы смогли сформировать образ этих данных.
Среднее арифметическое, которое очень часто называют просто «среднее», получают путем сложения всех значений и деления этой суммы на число значений в наборе.
Это можно показать с помощью алгебраической формулы. Набор n наблюдений переменной X можно изобразить как X1, X2, X3, …, Xn. Например, за X можно обозначить рост индивидуума (см), X1 обозначит рост 1-го индивидуума, а Xi — рост i-го индивидуума. Формула для определения среднего арифметического наблюдений ![]() (произносится «икс с чертой»):
(произносится «икс с чертой»):
![]() = (Х1 + Х2 + … + Xn) / n
= (Х1 + Х2 + … + Xn) / n
Можно сократить это выражение:

где ![]() (греческая буква «сигма») означает «суммирование», а индексы внизу и вверху этой буквы означают, что суммирование производится от i = 1 до i = n. Это выражение часто сокращают еще больше:
(греческая буква «сигма») означает «суммирование», а индексы внизу и вверху этой буквы означают, что суммирование производится от i = 1 до i = n. Это выражение часто сокращают еще больше:
![]() или
или ![]()
Медиана
Если упорядочить данные по величине, начиная с самой маленькой величины и заканчивая самой большой, то медиана также будет характеристикой усреднения в упорядоченном наборе данных.
Медиана делит ряд упорядоченных значений пополам с равным числом этих значений как выше, так и ниже ее (левее и правее медианы на числовой оси).
Вычислить медиану легко, если число наблюдений n нечетное. Это будет наблюдение номер (n + 1)/2 в нашем упорядоченном наборе данных.
Например, если n = 11, то медиана — это (11 + 1)/2, т. е. 6-е наблюдение в упорядоченном наборе данных.
Если n четное, то, строго говоря, медианы нет. Однако обычно мы вычисляем ее как среднее арифметическое двух соседних средних наблюдений в упорядоченном наборе данных (т. е. наблюдений номер (n/2) и (n/2 + 1)).
Так, например, если n = 20, то медиана — это среднее арифметическое наблюдений номер 20/2 = 10 и (20/2 + 1) = 11 в упорядоченном наборе данных.
Мода
Мода — это значение, которое встречается наиболее часто в наборе данных; если данные непрерывные, то мы обычно группируем их и вычисляем модальную группу.
Некоторые наборы данных не имеют моды, потому что каждое значение встречается только 1 раз. Иногда бывает более одной моды; это происходит тогда, когда 2 значения или больше встречаются одинаковое число раз и встречаемость каждого из этих значений больше, чем любого другого значения.
Как обобщающую характеристику моду используют редко.
Среднее геометрическое
При несимметричном распределении данных среднее арифметическое не будет обобщающим показателем распределения.
Если данные скошены вправо, то можно создать более симметричное распределение, если взять логарифм (по основанию 10 или по основанию е) каждого значения переменной в наборе данных. Среднее арифметическое значений этих логарифмов — характеристика распределения для преобразованных данных.
Чтобы получить меру с теми же единицами измерения, что и первоначальные наблюдения, нужно осуществить обратное преобразование — потенцирование (т. е. взять антилогарифм) средней логарифмированных данных; мы называем такую величину среднее геометрическое.
Если распределение данных логарифма приблизительно симметричное, то среднее геометрическое подобно медиане и меньше, чем среднее необработанных данных.
Взвешенное среднее
Взвешенное среднее используют тогда, когда некоторые значения интересующей нас переменной x более важны, чем другие. Мы присоединяем вес wi к каждому из значений xi в нашей выборке для того, чтобы учесть эту важность.
Если значения x1, x2 … xn имеют соответствующий вес w1, w2 … wn, то взвешенное арифметическое среднее выглядит следующим образом:

Например, предположим, что мы заинтересованы в определении средней продолжительности госпитализации в каком-либо районе и знаем средний реабилитационный период больных в каждой больнице. Учитываем количество информации, в первом приближении принимая за вес каждого наблюдения число больных в больнице.
Взвешенное среднее и среднее арифметическое идентичны, если каждый вес равен единице.
Размах (интервал изменения)
Размах — это разность между максимальным и минимальным значениями переменной в наборе данных; этими двумя величинами обозначают их разность. Обратите внимание, что размах вводит в заблуждение, если одно из значений есть выброс (см. раздел 3).
Размах, полученный из процентилей
Что такое процентили
Предположим, что мы расположим наши данные упорядоченно от самой маленькой величины переменной X и до самой большой величины. Величина X, до которой расположен 1% наблюдений (и выше которой расположены 99% наблюдений), называется первым процентилем.
Величина X, до которой находится 2% наблюдений, называется 2-м процентилем, и т. д.
Величины X, которые делят упорядоченный набор значений на 10 равных групп, т. е. 10-й, 20-й, 30-й,…, 90 и процентили, называются децилями. Величины X, которые делят упорядоченный набор значений на 4 равные группы, т.е. 25-й, 50-й и 75-й процентили, называются квартилями. 50-й процентиль — это медиана.
Применение процентилей
Мы можем добиться такой формы описания рассеяния, на которую не повлияет выброс (аномальное значение), исключая экстремальные величины и определяя размах остающихся наблюдений.
Межквартильный размах — это разница между 1-м и 3-м квартилями, т.е. между 25-м и 75-м процентилями. В него входят центральные 50% наблюдений в упорядоченном наборе, где 25% наблюдений находятся ниже центральной точки и 25% — выше.
Интердецильный размах содержит в себе центральные 80% наблюдений, т. е. те наблюдения, которые располагаются между 10-м и 90-м процентилями.
Мы часто используем размах, который содержит 95% наблюдений, т.е. он исключает 2,5% наблюдений снизу и 2,5% сверху. Указание такого интервала актуально, например, для осуществления диагностики болезни. Такой интервал называется референтный интервал, референтный размах или нормальный размах.
Дисперсия
Один из способов измерения рассеяния данных заключается в том, чтобы определить степень отклонения каждого наблюдения от средней арифметической. Очевидно, что чем больше отклонение, тем больше изменчивость, вариабельность наблюдений.
Однако мы не можем использовать среднее этих отклонений как меру рассеяния, потому что положительные отклонения компенсируют отрицательные отклонения (их сумма равна нулю). Чтобы решить эту проблему, мы возводим в квадрат каждое отклонение и находим среднее возведенных в квадрат отклонений; эта величина называется вариацией, или дисперсией.
Возьмем n наблюдений x1, x2, х3, …, xn, среднее которых равняется ![]() .
.
Вычисляем дисперсию:
![]()
В случае, если мы имеем дело не с генеральной совокупностью, а с выборкой, то вычисляется выборочная дисперсия:
![]()
Теоретически можно показать, что получится более точная дисперсия по выборке, если разделить не на n, а на (n-1).
Единицы измерения (размерность) вариации — это квадрат единиц измерения первоначальных наблюдений.
Например, если измерения производятся в килограммах, то единица измерения вариации будет килограмм в квадрате.
Среднеквадратическое отклонение, стандартное отклонение выборки
Среднеквадратическое отклонение — это положительный квадратный корень из дисперсии.
Стандартное отклонение выборки — корень из выборочной дисперсии:

Мы можем представить себе стандартное отклонение как своего рода среднее отклонение наблюдений от среднего. Оно вычисляется в тех же единицах (размерностях), что и исходные данные.
Если разделить стандартное отклонение на среднее арифметическое и выразить результат в процентах, получится коэффициент вариации.
Он является мерой рассеяния, не зависит от единиц измерения (безразмерный), но имеет некоторые теоретические неудобства и поэтому не очень одобряется статистиками.
Вариация в пределах субъектов и между субъектами
Если провести повторные измерения непрерывной переменной у исследуемого объекта, то можно увидеть ее изменения (внутрисубъектные изменения). Это можно объяснить тем, что объект не всегда может дать точные и те же самые ответы, и/или ошибкой, погрешностью измерения. Однако при измерениях у одного объекта вариация обычно меньше, чем вариация единичного измерения в группе (межсубъектные изменения).
Например, вместимость легкого 17-летнего мальчика составляет от 3,60 до 3,87 л, когда измерения повторяются не менее 10 раз; если провести однократное измерение у 10 мальчиков того же возраста, то объем будет между 2,98 и 4,33 л. Эти концепции важны в плане исследования.
Связанные определения:
Выборочное среднее, среднее значение выборки
Выброс
Дисперсия (рассеяние, разброс)
Дисперсия выборки (выборочная дисперсия)
Коэффициент вариации
Максимум
Математическое ожидание дискретной случайной величины
Математическое ожидание непрерывной случайной величины
Медиана
Меры дисперсии, меры разброса
Минимум
Мода
Описательные статистики
Описательный анализ
Параметры рассеяния
Параметры центральной тенденции
Среднее значение
Среднеквадратичное отклонение популяции
Стандартная ошибка среднего
Стандартное отклонение
В начало
Содержание портала
Стандартное отклонение и стандартная ошибка: в чем разница?
17 авг. 2022 г.
читать 2 мин
В статистике студенты часто путают два термина: стандартное отклонение и стандартная ошибка .
Стандартное отклонение измеряет, насколько разбросаны значения в наборе данных.
Стандартная ошибка — это стандартное отклонение среднего значения в повторных выборках из совокупности.
Давайте рассмотрим пример, чтобы ясно проиллюстрировать эту идею.
Пример: стандартное отклонение против стандартной ошибки
Предположим, мы измеряем вес 10 разных черепах.
Для этой выборки из 10 черепах мы можем вычислить среднее значение выборки и стандартное отклонение выборки:
Предположим, что стандартное отклонение оказалось равным 8,68. Это дает нам представление о том, насколько распределен вес этих черепах.
Но предположим, что мы собираем еще одну простую случайную выборку из 10 черепах и также проводим их измерения. Более чем вероятно, что эта выборка из 10 черепах будет иметь немного другое среднее значение и стандартное отклонение, даже если они взяты из одной и той же популяции:
Теперь, если мы представим, что мы берем повторные выборки из одной и той же совокупности и записываем выборочное среднее и выборочное стандартное отклонение для каждой выборки:
Теперь представьте, что мы наносим каждое среднее значение выборки на одну и ту же строку:
Стандартное отклонение этих средних значений известно как стандартная ошибка.
Формула для фактического расчета стандартной ошибки:
Стандартная ошибка = s/ √n
куда:
- s: стандартное отклонение выборки
- n: размер выборки
Какой смысл использовать стандартную ошибку?
Когда мы вычисляем среднее значение данной выборки, нас на самом деле интересует не среднее значение этой конкретной выборки, а скорее среднее значение большей совокупности, из которой взята выборка.
Однако мы используем выборки, потому что для них гораздо проще собирать данные, чем для всего населения. И, конечно же, среднее значение выборки будет варьироваться от выборки к выборке, поэтому мы используем стандартную ошибку среднего значения как способ измерить, насколько точна наша оценка среднего значения.
Вы заметите из формулы для расчета стандартной ошибки, что по мере увеличения размера выборки (n) стандартная ошибка уменьшается:
Стандартная ошибка = s/ √n
Это должно иметь смысл, поскольку большие размеры выборки уменьшают изменчивость и увеличивают вероятность того, что среднее значение нашей выборки ближе к фактическому среднему значению генеральной совокупности.
Когда использовать стандартное отклонение против стандартной ошибки
Если мы просто заинтересованы в измерении того, насколько разбросаны значения в наборе данных, мы можем использовать стандартное отклонение .
Однако, если мы заинтересованы в количественной оценке неопределенности оценки среднего значения, мы можем использовать стандартную ошибку среднего значения .
В зависимости от вашего конкретного сценария и того, чего вы пытаетесь достичь, вы можете использовать либо стандартное отклонение, либо стандартную ошибку.
Стандартное отклонение (SD), измеряет количество изменчивости или дисперсии, из отдельных значений данных, к среднему значению, в то время как стандартная ошибка среднего (SEM) мер, как далеко образец среднее (среднее) данных, вероятно, будет от истинного среднего значения населения. SEM всегда меньше SD.
Ключевые выводы
- Стандартное отклонение (SD) измеряет разброс набора данных относительно его среднего значения.
- Стандартная ошибка среднего (SEM) измеряет, насколько вероятно расхождение между средним значением выборки по сравнению со средним значением генеральной совокупности.
- SEM берет SD и делит его на квадратный корень из размера выборки.
SEM против SD
Стандартное отклонение и стандартная ошибка используются во всех типах статистических исследований, включая исследования в области финансов, медицины, биологии, инженерии, психологии и т. Д. В этих исследованиях стандартное отклонение (SD) и расчетная стандартная ошибка среднего (SEM) ) используются для представления характеристик данных выборки и объяснения результатов статистического анализа. Однако некоторые исследователи иногда путают SD и SEM. Таким исследователям следует помнить, что расчеты SD и SEM включают разные статистические выводы, каждый из которых имеет свое значение. SD – это разброс отдельных значений данных.
Другими словами, SD указывает, насколько точно среднее значение представляет данные выборки. Однако значение SEM включает статистический вывод, основанный на распределении выборки. SEM – это стандартное отклонение теоретического распределения выборочных средних (выборочное распределение).
Расчет стандартного отклонения

Формула SD требует нескольких шагов:
- Во-первых, возьмите квадрат разницы между каждой точкой данных и средним значением выборки, найдя сумму этих значений.
- Затем разделите эту сумму на размер выборки минус один, который представляет собой дисперсию.
- Наконец, извлеките квадратный корень из дисперсии, чтобы получить стандартное отклонение.
Стандартная ошибка среднего
SEM рассчитывается путем деления стандартного отклонения на квадратный корень из размера выборки.
Стандартная ошибка дает точность выборочного среднего путем измерения изменчивости выборочного среднего от образца к образцу. SEM описывает, насколько точное среднее значение выборки является оценкой истинного среднего значения совокупности. По мере увеличения размера выборки данных SEM уменьшается по сравнению с SD; следовательно, по мере увеличения размера выборки среднее значение выборки оценивает истинное среднее значение генеральной совокупности с большей точностью. Напротив, увеличение размера выборки не обязательно делает SD больше или меньше, это просто становится более точной оценкой SD населения.
Стандартная ошибка и стандартное отклонение в финансах
В финансах стандартная ошибка средней дневной доходности актива измеряет точность выборочного среднего как оценки долгосрочной (постоянной) средней дневной доходности актива.
С другой стороны, стандартное отклонение доходности измеряет отклонения индивидуальных доходов от среднего значения. Таким образом, SD является мерой волатильности и может использоваться в качестве меры риска для инвестиций. Активы с более высокими ежедневными движениями цен имеют более высокое SD, чем активы с меньшими ежедневными движениями. Предполагая нормальное распределение, около 68% дневных изменений цен находятся в пределах одного стандартного отклонения от среднего, при этом около 95% дневных изменений цен находятся в пределах двух стандартных значений среднего.
Вступление
стандарт D (SD) а также S tandard Е rror (SE) по-видимому, аналогичные терминологии; однако они концептуально настолько разнообразны, что они используются почти взаимозаменяемо в статистической литературе. Каждому термину обычно предшествует символ плюс-минус (+/-), который указывает на то, что они определяют симметричное значение или представляют диапазон значений. Неизменно оба выражения появляются со средним (средним) набором измеренных значений.
Интересно, что SE не имеет ничего общего со стандартами, с ошибками или с сообщением научных данных.
Подробный взгляд на происхождение и объяснение SD и SE покажет, почему профессиональные статистики и те, кто использует это сдержанно, оба склонны ошибаться.
Стандартное отклонение (SD)
SD является описательный статистика, описывающая распространение распределения. Как метрика, это полезно, когда данные обычно распределяются. Однако это менее полезно, когда данные сильно искажены или бимодальны, потому что они не очень хорошо описывают форму распределения. Как правило, мы используем SD при представлении характеристик образца, поскольку мы намерены описывать насколько данные изменяются по среднему значению. Другая полезная статистика для описания распространения данных — это межквартильный диапазон, 25-й и 75-й процентили и диапазон данных.
Рисунок 1. SD является мерой распространения данных. Когда данные являются образцом из нормально распределенного распределения, тогда ожидается, что две трети данных будут находиться в пределах 1 стандартного отклонения среднего значения.
Разница заключается в описательный статистика также, и она определяется как квадрат стандартного отклонения. Обычно это не сообщается при описании результатов, но это более математически приемлемая формула (a.k.a. сумма квадратов отклонений) и играет роль в вычислении статистики.
Например, если у нас есть две статистики п & Q с известными отклонениями вар (П) & вар (Q) , то дисперсия суммы Р + Q равна сумме дисперсий: вар (P) + вар (Q) , Теперь очевидно, почему статистикам нравится говорить об отклонениях.
Но стандартные отклонения имеют важное значение для распространения, особенно когда данные обычно распределяются: среднее значение интервала +/- 1 SD можно ожидать захвата 2/3 образца, а среднее значение интервала + — 2 SD можно ожидать захвата 95% образца.
SD дает представление о том, насколько индивидуальные ответы на вопрос меняются или «отклоняются» от среднего. SD рассказывает исследователю, насколько распространены ответы: сосредоточены ли они вокруг среднего или разбросаны по всему миру? Все ваши респонденты оценили ваш продукт в середине шкалы, или кто-то одобрил его, а некоторые отклонили его?
Рассмотрим эксперимент, в котором респондентам предлагается оценивать продукт по ряду атрибутов по 5-балльной шкале. Среднее значение для группы из десяти респондентов (обозначаемое «A» через «J» ниже) для «хорошей стоимости за деньги» составляло 3,2 с SD 0,4, а среднее значение для «надежности продукта» составляло 3,4 с SD 2,1.
На первый взгляд (смотря только на средства), казалось бы, надежность была оценена выше стоимости. Но более высокий SD для надежности может указывать (как показано ниже в распределении), что ответы были очень поляризованы, где большинство респондентов не имели проблем с надежностью (с оценкой атрибута «5»), но меньший, но важный сегмент респондентов, проблема надежности и оценили атрибут «1». Однако, глядя на среднее значение, он говорит только часть истории, однако чаще всего это то, на что ориентируются исследователи. Распределение ответов важно учитывать, и SD обеспечивает ценную описательную меру этого.
| ответчик | Хорошая ценность для денег | Надежность продукта |
| 3 | 1 | |
| В | 3 | 1 |
| С | 3 | 1 |
| D | 3 | 1 |
| Е | 4 | 5 |
| F | 4 | 5 |
| г | 3 | 5 |
| ЧАС | 3 | 5 |
| я | 3 | 5 |
| J | 3 | 5 |
| Имею в виду | 3.2 | 3.4 |
| Std. Девиация | 0.4 | 2.1 |
Первый опрос: респонденты оценивают продукт по пятибалльной шкале
Два очень разных распределения ответов на 5-балльную рейтинговую шкалу могут дать одно и то же значение. Рассмотрим следующий пример, показывающий значения ответа для двух разных оценок.
В первом примере (Рейтинг «A») SD равен нулю, потому что ВСЕ ответы были точно средним значением. Индивидуальные ответы не отклонялись от среднего.
В рейтинге «B», хотя среднее значение группы одинаково (3.0) в качестве первого распределения, стандартное отклонение выше. Стандартное отклонение 1.15 показывает, что индивидуальные ответы в среднем * были чуть более 1 балла от среднего.
| ответчик | Рейтинг «A» | Рейтинг «B» |
| 3 | 1 | |
| В | 3 | 2 |
| С | 3 | 2 |
| D | 3 | 3 |
| Е | 3 | 3 |
| F | 3 | 3 |
| г | 3 | 3 |
| ЧАС | 3 | 4 |
| я | 3 | 4 |
| J | 3 | 5 |
| Имею в виду | 3.0 | 3.0 |
| Std. Девиация | 0.00 | 1.15 |
Второй опрос: респонденты оценивают продукт по пятибалльной шкале
Другой способ взглянуть на SD — это построить распределение как гистограмму ответов. Распределение с низким SD будет отображаться как высокая узкая форма, в то время как большая SD будет обозначаться более широкой формой.
SD обычно не указывает «правильно или неправильно» или «лучше или хуже» — более низкая SD не обязательно более желательна. Он используется исключительно как описательная статистика. Он описывает распределение по отношению к среднему.
T echnical disclaimer, относящийся к SD
Думая о том, что SD как «отклонение» — это отличный способ концептуально понять его смысл. Тем не менее, он фактически не рассчитывается как среднее (если бы это было так, мы бы назвали это «отклонениями»). Вместо этого он «стандартизирован» — несколько сложный метод вычисления значения с использованием суммы квадратов.
Для практических целей вычисление не имеет значения. Большинство программ табуляции, электронных таблиц или других инструментов управления данными будут вычислять SD для вас. Более важно понять, что передает статистика.
Стандартная ошибка
Стандартная ошибка — это выведенный статистика, которая используется при сравнении выборочных средств (средних) по группам населения. Это мера точность от среднего значения выборки. Среднее значение выборки — это статистическая информация, полученная из данных, имеющих базовое распределение. Мы не можем визуализировать его так же, как и данные, поскольку мы выполнили один эксперимент и имеем только одно значение. Статистическая теория говорит нам о том, что среднее значение выборки (для большого, более выбранного образца и в нескольких условиях регулярности) приблизительно нормально распределено. Стандартное отклонение этого нормального распределения — это то, что мы называем стандартной ошибкой.

Фигура 2. Распределение в нижней части распределяет данные, тогда как распределение сверху — это теоретическое распределение среднего значения выборки. SD 20 является мерой распространения данных, тогда как SE of 5 является мерой неопределенности вокруг среднего значения выборки.
Когда мы хотим сравнить средства исходов от эксперимента с двумя образцами Лечения A против лечения B, нам нужно оценить, насколько точно мы измерили средства.
На самом деле нас интересует, насколько точно мы измерили разницу между этими двумя средствами. Мы называем эту меру стандартной ошибкой разности. Вы не можете быть удивлены, узнав, что стандартная ошибка разницы в средствах выборки является функцией стандартных ошибок средств:

Теперь, когда вы поняли, что стандартная ошибка среднего (SE) и стандартное отклонение распределения (SD) — это два разных зверя, вам может быть интересно, как они запутались в первую очередь. Хотя они принципиально отличаются друг от друга, они имеют математическую форму:

, где n — количество точек данных.
Обратите внимание, что стандартная ошибка зависит от двух компонентов: стандартного отклонения выборки и размера выборки N , Это делает интуитивный смысл: чем больше стандартное отклонение выборки, тем менее точным может быть наша оценка истинного среднего.
Кроме того, большой размер выборки, чем больше информации мы имеем о населении, тем точнее мы можем оценить истинное значение.
SE является показателем надежности среднего значения. Небольшой SE является показателем того, что среднее значение выборки является более точным отражением фактического значения популяции. Более большой размер выборки обычно приводит к меньшему SE (тогда как SD не зависит напрямую от размера выборки).
Большинство исследовательских исследований включает в себя выборку из населения. Затем мы делаем выводы о популяции из результатов, полученных из этого образца. Если был сделан второй образец, результаты, вероятно, были бы точно совпадают с первым образцом. Если среднее значение для атрибута рейтинга составляло 3,2 для одного образца, это может быть 3,4 для второго образца того же размера. Если бы мы собирали бесконечное количество выборок (равного размера) из нашей популяции, мы могли бы отображать наблюдаемые средства как распределение. Затем мы могли бы вычислить среднее значение всех наших образцов. Это означало бы равное истинное значение популяции. Мы также можем рассчитать SD распределения средств выборки. SD этого распределения средств выборки является SE каждого отдельного образца.
Таким образом, мы имеем самое значительное наблюдение: SE является SD среднего значения.
| Образец | Имею в виду |
| первый | 3.2 |
| второй | 3.4 |
| третий | 3.3 |
| четвёртая | 3.2 |
| пятые | 3.1 |
| …. | …. |
| …. | …. |
| …. | …. |
| …. | …. |
| …. | …. |
| Имею в виду | 3.3 |
| Std. Девиация | 0.13 |
Таблица, иллюстрирующая взаимосвязь между SD и SE
Теперь ясно, что если SD этого распределения помогает нам понять, насколько далека среднее значение выборки от истинной совокупности, то мы можем использовать это, чтобы понять, насколько точна какая-либо индивидуальная выборка по отношению к истинному среднему значению. В этом суть SE.
На самом деле, мы набрали только один образец из нашего населения, но мы можем использовать этот результат для оценки надежности нашего наблюдаемого образца.
На самом деле, SE говорит нам, что мы можем быть на 95% уверены, что наше наблюдаемое среднее значение выборки плюс или минус примерно 2 (на самом деле 1,96). Стандартные ошибки от населения.
В приведенной ниже таблице показано распределение ответов от нашей первой (и единственной) выборки, используемой для наших исследований. SE 0,13, будучи относительно небольшим, дает нам указание на то, что наше среднее значение относительно близко к истинному среднему для нашей общей популяции. Предел погрешности (с доверием 95%) для нашего среднего значения (примерно) в два раза превышает это значение (+/- 0,26), сообщая нам, что истинное среднее значение, скорее всего, составляет от 2,94 до 3,46.
| ответчик | Рейтинг |
| 3 | |
| В | 3 |
| С | 3 |
| D | 3 |
| Е | 4 |
| F | 4 |
| г | 3 |
| ЧАС | 3 |
| я | 3 |
| J | 3 |
| Имею в виду | 3.2 |
| Std. заблуждаться | 0.13 |
Резюме
Многие исследователи не понимают различия между стандартным отклонением и стандартной ошибкой, хотя они обычно включаются в анализ данных. Хотя фактические расчеты для стандартного отклонения и стандартной ошибки выглядят очень схожими, они представляют собой две очень разные, но взаимодополняющие меры. SD рассказывает нам о форме нашего распределения, насколько близки значения отдельных данных от среднего значения. SE рассказывает нам, насколько близка наша выборка к истинному средству общей популяции.Вместе они помогают обеспечить более полную картину, чем может сказать нам только одно значащее.
Аннотация: Лекция посвящена основам анализа данных, рассмотрены основные характеристики описательной статистики, кратко изложена суть корреляционного и регрессионного анализа. Приведены примеры решения задач в Microsoft Excel.
В этой лекции мы рассмотрим некоторые аспекты статистического анализа данных, в частности, описательную статистику, корреляционный и регрессионный анализы. Статистический анализ включает большое разнообразие методов, даже для поверхностного знакомства с которыми объема одной лекции слишком мало. Цель данной лекции — дать самое общее представление о понятиях корреляции, регрессии, а также познакомиться с описательной статистикой. Примеры, рассмотренные в лекции, намеренно упрощены.
Существует большое разнообразие прикладных пакетов, реализующих широкий спектр статистических методов, их также называют универсальными пакетами или инструментальными наборами. О таких наборах мы подробно поговорим в последнем разделе курса. В Microsoft Excel также реализован широкий арсенал методов математической статистики, реализация примеров данной лекции продемонстрирована именно на этом программном обеспечении.
Следует заметить, что существует сложность использования статистических методов, так же как и статистического программного обеспечения, — для этого пользователю необходимы специальные знания.
Анализ данных в Microsoft Excel
Microsoft Excel имеет большое число статистических функций. Некоторые являются встроенными, некоторые доступны после установки пакета анализа. В данной лекции мы воспользуемся именно этим программным обеспечением.
Обращение к Пакету анализа. Средства, включенные в пакет анализа данных, доступны через команду Анализ данных меню Сервис. Если эта команда отсутствует в меню, в меню Сервис/Надстройки необходимо активировать пункт «Пакет анализа».
Далее мы рассмотрим некоторые инструменты, включенные в Пакет анализа.
Описательная статистика
Описательная статистика (Descriptive statistics ) — техника сбора и суммирования количественных данных, которая используется для превращения массы цифровых данных в форму, удобную для восприятия и обсуждения.
Цель описательной статистики — обобщить первичные результаты, полученные в результате наблюдений и экспериментов.
Пусть дан набор данных А, представленный в таблице 8.1.
| x | y |
|---|---|
| 3 | 9 |
| 2 | 7 |
| 4 | 12 |
| 5 | 15 |
| 6 | 17 |
| 7 | 19 |
| 8 | 21 |
| 9 | 23,4 |
| 10 | 25,6 |
| 11 | 27,8 |
Выбрав в меню Сервис «Пакет анализа» и выбрав инструмент анализа «Описательная статистика», получаем одномерный статистический отчет, содержащий информацию о центральной тенденции и изменчивости или вариации входных данных.
В состав описательной статистики входят такие характеристики: среднее ; стандартная ошибка; медиана ; мода; стандартное отклонение ; дисперсия выборки; эксцесс ; асимметричность; интервал; минимум ; максимум; сумма; счет.
Отчет «Описательная статистика» для двух переменных их набора данных А приведен в таблице 8.2.
| x | y | |
|---|---|---|
| Среднее | 6,5 | 17,68 |
| Стандартная ошибка | 0,957427108 | 2,210922382 |
| Медиана | 6,5 | 18 |
| Стандартное отклонение | 3,027650354 | 6,991550456 |
| Дисперсия выборки | 9,166666667 | 48,88177778 |
| Эксцесс | -1,2 | -1,106006058 |
| Асимметричность | 0 | -0,128299221 |
| Интервал | 9 | 20,8 |
| Минимум | 2 | 7 |
| Максимум | 11 | 27,8 |
| Сумма | 65 | 176,8 |
| Счет | 10 | 10 |
| Наибольший (1) | 11 | 27,8 |
| Наименьший (1) | 2 | 7 |
| Уровень надежности (95,0%) | 2,16585224 | 5,001457714 |
Рассмотрим, что же представляют собой характеристики описательной статистики.