Стандартная ошибка
Стандартная ошибка — это стандартное отклонение выборочного распределения статистики. Этот термин также может использоваться для оценки (хорошего предположения) этого стандартного отклонения, взятого из выборки всей группы.
Среднее значение некоторой части группы (называемой выборкой) является обычным способом оценки среднего значения для всей группы. Часто бывает слишком сложно или стоит слишком много денег, чтобы измерить всю группу. Но если измерить другую выборку, то ее среднее значение будет немного отличаться от первой выборки. Стандартная ошибка среднего — это способ узнать, насколько близка средняя по выборке к средней по всей группе. Это способ узнать, насколько вы можете быть уверены в среднем значении по выборке.
В реальных измерениях истинное значение стандартного отклонения среднего для всей группы обычно неизвестно. Поэтому термин стандартная ошибка часто используется для обозначения близкого к истинному значению для всей группы. Чем больше измерений в выборке, тем ближе к истинному значению для всей группы.
![]()
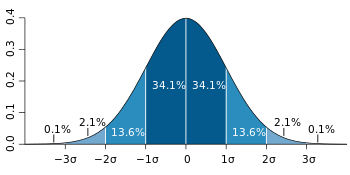
Для значения, отобранного с несмещенной нормально распределенной ошибкой, выше показана доля выборок, которые будут находиться в пределах 0, 1, 2 и 3 стандартных отклонений выше и ниже фактического значения.
Как найти стандартную ошибку среднего значения
Один из способов найти стандартную ошибку среднего — это множество выборок. Сначала находят среднее значение для каждой выборки. Затем находят среднее и стандартное отклонение этих средних по выборкам. Стандартное отклонение для всех средних по выборке и есть стандартная ошибка среднего. Это может быть большой объем работы. Иногда иметь большое количество образцов слишком сложно или стоит слишком много денег.
Другой способ найти стандартную ошибку среднего — использовать уравнение, для которого нужна только одна выборка. Стандартная ошибка среднего обычно оценивается по стандартному отклонению для выборки из всей группы (стандартное отклонение выборки), деленному на квадратный корень из размера выборки.
S E x ¯ = s n {\displaystyle SE_{\bar {x}}\ ={\frac {s}{\sqrt {n}}}} 
где
s — стандартное отклонение выборки (т.е. выборочная оценка стандартного отклонения популяции), и
n — количество измерений в выборке.
Насколько большой должна быть выборка, чтобы оценка стандартной ошибки среднего была близка к фактической стандартной ошибке среднего для всей группы? В выборке должно быть не менее шести измерений. Тогда стандартная ошибка среднего для выборки будет находиться в пределах 5% от стандартной ошибки среднего, если бы измерялась вся группа.
Исправления для некоторых случаев
Существует еще одно уравнение, которое можно использовать, если количество измерений составляет 5% или более от всей группы:
Существуют специальные уравнения, которые необходимо использовать, если образец имеет менее 20 измерений.
Иногда выборка поступает из одного места, хотя вся группа может быть рассредоточена. Кроме того, иногда выборка может быть сделана за короткий промежуток времени, когда вся группа охватывает более длительный период. В этом случае числа в выборке не являются независимыми. Тогда используются специальные уравнения, чтобы попытаться исправить это.
Полезность
Практический результат: Можно быть более уверенным в среднем значении, если провести больше измерений в выборке. Тогда стандартная ошибка среднего значения будет меньше, поскольку стандартное отклонение делится на большее число. Однако, чтобы сделать неопределенность (стандартную ошибку среднего) среднего значения в два раза меньше, размер выборки (n) должен быть в четыре раза больше. Это происходит потому, что стандартное отклонение делится на квадратный корень из размера выборки. Чтобы сделать неопределенность на одну десятую больше, размер выборки (n) должен быть в сто раз больше!
Стандартные ошибки легко вычисляются и часто используются, потому что:
- Если известна стандартная ошибка нескольких отдельных величин, то во многих случаях можно легко рассчитать стандартную ошибку некоторой функции этих величин;
- Если вероятностное распределение значения известно, его можно использовать для расчета хорошего приближения к точному доверительному интервалу; и
- Если распределение вероятности неизвестно, для оценки доверительного интервала можно использовать другие уравнения
- Когда размер выборки становится очень большим, принцип центральной предельной теоремы показывает, что числа в выборке очень похожи на числа во всей группе (они имеют нормальное распределение).
Относительная стандартная ошибка
Относительная стандартная ошибка (RSE) — это стандартная ошибка, деленная на среднее значение. Это число меньше единицы. Умножение его на 100% дает его в процентах от среднего значения. Это помогает показать, является ли неопределенность важной или нет. Например, рассмотрим два исследования доходов домохозяйств, в результате которых среднее значение по выборке составляет $50 000. Если стандартная ошибка одного опроса составляет $10 000, а другого — $5 000, то относительные стандартные ошибки равны 20% и 10% соответственно. Опрос с меньшей относительной стандартной ошибкой лучше, потому что он имеет более точное измерение (неопределенность меньше).
На самом деле, люди, которым необходимо знать средние значения, часто решают, насколько мала должна быть неопределенность, прежде чем они решат использовать информацию. Например, Национальный центр статистики здравоохранения США не сообщает среднее значение, если относительная стандартная ошибка превышает 30%. NCHS также требует не менее 30 наблюдений для того, чтобы оценка была представлена в отчете. []
Пример
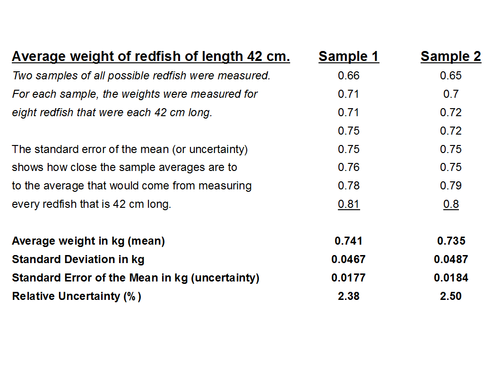
Например, в воде Мексиканского залива водится много красной рыбы. Чтобы узнать, сколько в среднем весит красноперка длиной 42 см, невозможно измерить всех красноперок длиной 42 см. Вместо этого можно измерить некоторых из них. Рыба, которую измеряют, называется образцом. В таблице показан вес двух образцов красноперки длиной 42 см. Средний (средний) вес первого образца составляет 0,741 кг. Средний (средний) вес второго образца — 0,735 кг, что немного отличается от первого образца. Каждое из этих средних значений немного отличается от среднего значения, которое было бы получено при измерении каждой красной рыбы длиной 42 см (что в любом случае невозможно).
Неопределенность среднего значения можно использовать для того, чтобы узнать, насколько близки средние значения выборок к среднему значению, которое было бы получено в результате измерения всей группы. Неопределенность среднего оценивается как стандартное отклонение для выборки, деленное на квадратный корень из числа выборок минус один. Из таблицы видно, что неопределенности в средних для двух выборок очень близки друг к другу. Кроме того, относительная неопределенность — это неопределенность среднего значения, деленная на среднее значение, умноженное на 100%. Относительная неопределенность в данном примере составляет 2,38% и 2,50% для двух образцов.
Зная неопределенность среднего, можно узнать, насколько близко выборочное среднее к среднему, которое было бы получено в результате измерения всей группы. Среднее по всей группе находится между а) средним по выборке плюс неопределенность в среднем и б) средним по выборке минус неопределенность в среднем. В данном примере средний вес всей красноперки длиной 42 см в Мексиканском заливе, как ожидается, составит 0,723-0,759 кг по первой выборке и 0,717-0,753 по второй выборке.
![]()
.jpg)
![]()
Пример красной рыбы (также известной как красный барабан, Sciaenops ocellatus), используемой в примере.
Вопросы и ответы
В: Что такое стандартная ошибка?
О: Стандартная ошибка — это стандартное отклонение выборочного распределения статистики.
В: Можно ли использовать термин стандартная ошибка для оценки стандартного отклонения?
О: Да, термин стандартная ошибка может быть использован для оценки (хорошего предположения) этого стандартного отклонения, взятого из выборки всей группы.
В: Как можно оценить среднее значение для всей группы?
О: Среднее значение некоторой части группы (называемой выборкой) — это обычный способ оценки среднего значения для всей группы.
В: Почему трудно измерить всю группу?
О: Часто бывает слишком трудно или слишком дорого измерить всю группу.
В: Что такое стандартная ошибка среднего, и что она определяет?
О: Стандартная ошибка среднего — это способ узнать, насколько близко среднее значение выборки к среднему значению всей группы. Это способ узнать, насколько можно быть уверенным в среднем значении по выборке.
В: Известно ли обычно истинное значение стандартного отклонения среднего при реальных измерениях?
О: Нет, истинное значение стандартного отклонения среднего для всей группы обычно не известно в реальных измерениях.
В: Как количество измерений в выборке влияет на точность оценки?
О: Чем больше измерений в выборке, тем ближе предположение будет к истинному значению для всей группы.
In statistics, a relative standard error (RSE) is equal to the standard error of a survey estimate divided by the survey estimate and then multiplied by 100. The number is multiplied by 100 so it can be expressed as a percentage. The RSE does not necessarily represent any new information beyond the standard error, but it might be a superior method of presenting statistical confidence.
Relative Standard Error vs. Standard Error
Standard error measures how much a survey estimate is likely to deviate from the actual population. It is expressed as a number. By contrast, relative standard error (RSE) is the standard error expressed as a fraction of the estimate and is usually displayed as a percentage. Estimates with an RSE of 25% or greater are subject to high sampling error and should be used with caution.
Survey Estimate and Standard Error
Surveys and standard errors are crucial parts of probability theory and statistics. Statisticians use standard errors to construct confidence intervals from their surveyed data. The reliability of these estimates can also be assessed in terms of a confidence interval. Confidence intervals are important for determining the validity of empirical tests and research.
A confidence interval is a type of interval estimate, computed from the statistics of the observed data, that might contain the true value of an unknown population parameter. Confidence intervals represent the range in which the population value is likely to lie. They are constructed using the estimate of the population value and its associated standard error. For example, there is approximately a 95% chance (i.e. 19 chances in 20) that the population value lies within two standard errors of the estimates, so the 95% confidence interval is equal to the estimate plus or minus two standard errors.
In layman’s terms, the standard error of a data sample is a measurement of the likely difference between the sample and the entire population. For example, a study involving 10,000 cigarette-smoking adults may generate slightly different statistical results than if every possible cigarette-smoking adult was surveyed.
Smaller sample errors are indicative of more reliable results. The central limit theorem in inferential statistics suggests that large samples tend to have approximately normal distributions and low sample errors.
Standard Deviation and Standard Error
The standard deviation of a data set is used to express the concentration of survey results. Less variety in the data results in a lower standard deviation. More variety is likely to result in a higher standard deviation.
The standard error is sometimes confused with the standard deviation. The standard error actually refers to the standard deviation of the mean. Standard deviation refers to the variability inside any given sample, while a standard error is the variability of the sampling distribution itself.
Relative Standard Error
The standard error is an absolute gauge between the sample survey and the total population. The relative standard error shows if the standard error is large relative to the results; large relative standard errors suggest the results are not significant. The formula for relative standard error is:
Relative Standard Error
=
Standard Error
Estimate
×
1
0
0
where:
Standard Error
=
standard deviation of the mean sample
Estimate
=
mean of the sample
\begin{aligned} &\text{Relative Standard Error} = \frac { \text{Standard Error} }{ \text{Estimate} } \times 100 \\ &\textbf{where:} \\ &\text{Standard Error} = \text{standard deviation of the mean sample} \\ &\text{Estimate} = \text{mean of the sample} \\ \end{aligned}
Relative Standard Error=EstimateStandard Error×100where:Standard Error=standard deviation of the mean sampleEstimate=mean of the sample
a:
В статистике относительная стандартная ошибка или RSE равна стандартной ошибке оценки опроса, деленной на оценку опроса, а затем умножается на 100. Число умножается на 100 так его можно выразить в процентах. RSE не обязательно представляет какую-либо новую информацию за пределами стандартной ошибки, но это может быть превосходный метод представления статистической достоверности.
Оценка и стандартная ошибка
Обследования и стандартные ошибки являются важными частями теории вероятностей и статистики. Статистики используют стандартные ошибки для построения доверительных интервалов из своих опрошенных данных. Доверительные интервалы важны для определения действительности эмпирических тестов и исследований.
В условиях непрофессионала стандартная ошибка выборки данных — это измерение вероятной разницы между выборкой и всей совокупностью. Например, исследование с участием 10 000 взрослых, курящих сигареты, может генерировать несколько иные статистические результаты, чем если бы были опрошены все возможные взрослые курильщики сигарет.
Меньшие ошибки выборки свидетельствуют о более надежных результатах. Центральная предельная теорема в статистических выводах показывает, что большие образцы имеют тенденцию иметь приблизительно нормальные распределения и низкие ошибки выборки.
Стандартное отклонение и стандартная ошибка
Стандартное отклонение набора данных используется для выражения концентрации результатов опроса. Меньшее разнообразие данных приводит к более низкому стандартным отклонениям. Больше разнообразия, вероятно, приведет к более высокому стандартным отклонениям.
Стандартная ошибка иногда путается со стандартным отклонением. Стандартная ошибка на самом деле относится к стандартным отклонениям среднего значения. Стандартное отклонение относится к изменчивости внутри любого данного образца, в то время как стандартная ошибка — это изменчивость самого распределения выборки.
Относительная стандартная ошибка
Стандартная ошибка — это абсолютная величина между выборочным обследованием и общей численностью населения. Относительная стандартная ошибка показывает, является ли стандартная ошибка большой по сравнению с результатами; большие относительные стандартные ошибки предполагают, что результаты не значительны. Формула относительной стандартной ошибки (стандартная ошибка / оценка) x 100.
В статистике относительная стандартная ошибка (RSE) равна стандартной ошибке оценки обследования, деленной на оценку обследования, а затем умноженной на 100. Число умножается на 100, чтобы его можно было выразить в процентах. RSE не обязательно представляет какую-либо новую информацию, выходящую за рамки стандартной ошибки, но это может быть лучшим методом представления статистической достоверности.
Относительная стандартная ошибка против стандартной ошибки
Стандартная ошибка определяет, насколько оценка обследования может отличаться от фактической совокупности.Он выражается числом.Напротив, относительная стандартная ошибка (RSE) — это стандартная ошибка, выраженная как часть оценки и обычно отображается в процентах.Оценки с RSE 25% или более подвержены большой ошибке выборки и должны использоваться с осторожностью.
Оценка опроса и стандартная ошибка
Опросы и стандартные ошибки — важнейшие части теории вероятностей и статистики. Статистики используют стандартные ошибки для построения доверительных интервалов на основе своих обследованных данных. Достоверность этих оценок также можно оценить с помощью доверительного интервала. Доверительные интервалы важны для определения достоверности эмпирических тестов и исследований.
Доверительный интервал — это тип интервальной оценки, вычисляемой на основе статистики наблюдаемых данных, которая может содержать истинное значение неизвестного параметра совокупности.Доверительные интервалы представляют собой диапазон, в котором, вероятно, находится значение генеральной совокупности.Они построены с использованием оценки значения генеральной совокупности и связанной с ней стандартной ошибки.Например, вероятность того, что значение генеральной совокупности находится в пределах двух стандартных ошибок оценок, составляет приблизительно 95% (т.е. 19 из 20), поэтому 95% доверительный интервал равен оценке плюс или минус две стандартные ошибки.
С точки зрения непрофессионала, стандартная ошибка выборки данных — это измерение вероятной разницы между выборкой и всей совокупностью. Например, исследование с участием 10 000 взрослых, курящих сигареты, может дать несколько иные статистические результаты, чем при опросе всех возможных курящих сигареты взрослых.
Меньшие ошибки выборки указывают на более надежные результаты. Центральная предельная теорема в умозаключениях статистиков показывает, что большие выборки, как правило, имеют приблизительно нормальное распределение и низкие ошибки выборки.
Стандартное отклонение и стандартная ошибка
Стандартное отклонение набора данных используется для выражения концентрации результатов обследования. Меньшее разнообразие данных приводит к более низкому стандартному отклонению. Чем больше разнообразия, тем выше стандартное отклонение.
Стандартную ошибку иногда путают со стандартным отклонением. Стандартная ошибка фактически относится к стандартному отклонению среднего значения. Стандартное отклонение относится к изменчивости внутри любой данной выборки, тогда как стандартная ошибка — это изменчивость самого распределения выборки.
Относительная стандартная ошибка
Стандартная ошибка — это абсолютная мера между выборочным обследованием и генеральной совокупностью. Относительная стандартная ошибка показывает, велика ли стандартная ошибка по сравнению с результатами; большие относительные стандартные ошибки предполагают, что результаты незначительны. Формула относительной стандартной ошибки:


Содержание
- Относительная стандартная ошибка против стандартной ошибки
- Оценка опроса и стандартная ошибка
- Стандартное отклонение и стандартная ошибка
- Относительная стандартная ошибка
В статистике относительная стандартная ошибка (RSE) равна стандартной ошибке оценки обследования, деленной на оценку обследования, а затем умноженной на 100. Число умножается на 100, чтобы его можно было выразить в процентах. RSE не обязательно представляет какую-либо новую информацию, выходящую за рамки стандартной ошибки, но это может быть лучшим методом представления статистической достоверности.
Относительная стандартная ошибка против стандартной ошибки
Стандартная ошибка измеряет, насколько оценка обследования может отличаться от фактической совокупности. Выражается в виде числа. Напротив, относительная стандартная ошибка (RSE) — это стандартная ошибка, выраженная как часть оценки и обычно отображается в процентах. Оценки с RSE 25% или более подвержены большой ошибке выборки и должны использоваться с осторожностью.
Оценка опроса и стандартная ошибка
Опросы и стандартные ошибки — важнейшие части теории вероятностей и статистики. Статистики используют стандартные ошибки для построения доверительных интервалов на основе полученных данных. Достоверность этих оценок также можно оценить с помощью доверительного интервала. Доверительные интервалы важны для определения достоверности эмпирических тестов и исследований.
Доверительный интервал — это тип интервальной оценки, вычисляемой на основе статистики наблюдаемых данных, которая может содержать истинное значение неизвестного параметра совокупности. Доверительные интервалы представляют собой диапазон, в котором, вероятно, находится значение генеральной совокупности. Они построены с использованием оценки значения генеральной совокупности и связанной с ней стандартной ошибки. Например, вероятность того, что значение генеральной совокупности находится в пределах двух стандартных ошибок оценок, составляет примерно 95% (то есть 19 из 20), поэтому 95% доверительный интервал равен оценке плюс или минус две стандартные ошибки.
С точки зрения непрофессионала, стандартная ошибка выборки данных — это измерение вероятной разницы между выборкой и всей совокупностью. Например, исследование с участием 10 000 взрослых, курящих сигареты, может дать несколько иные статистические результаты, чем при опросе всех возможных курящих сигареты взрослых.
Меньшие ошибки выборки указывают на более надежные результаты. Центральная предельная теорема в выводной статистике предполагает, что большие выборки обычно имеют приблизительно нормальное распределение и низкие ошибки выборки.
Стандартное отклонение и стандартная ошибка
Стандартное отклонение набора данных используется для выражения концентрации результатов обследования. Меньшее разнообразие данных приводит к более низкому стандартному отклонению. Чем больше разнообразия, тем выше стандартное отклонение.
Стандартную ошибку иногда путают со стандартным отклонением. Стандартная ошибка фактически относится к стандартному отклонению среднего значения. Стандартное отклонение относится к изменчивости внутри любой данной выборки, в то время как стандартная ошибка — это изменчивость самого распределения выборки.
Относительная стандартная ошибка
Стандартная ошибка — это абсолютная мера между выборочным обследованием и генеральной совокупностью. Относительная стандартная ошибка показывает, велика ли стандартная ошибка по сравнению с результатами; большие относительные стандартные ошибки предполагают, что результаты незначительны. Формула относительной стандартной ошибки:
Относительная стандартная ошибка = оценка Стандартная ошибка × 100, где: стандартная ошибка = стандартное отклонение среднего значения выборки Оценка = среднее значение выборки