Cправка — Search Console
Войти
Справка Google
- Справочный центр
- Сообщество
- Search Console
- Политика конфиденциальности
- Условия предоставления услуг
- Отправить отзыв
Тема отзыва
Информация в текущем разделе Справочного центра
Общие впечатления о Справочном центре Google
- Справочный центр
- Сообщество
Search Console
Подробный SEO-гайд по Отчёту об индексировании Google Search Console. Разберёмся, как проверить индексацию сайта с его помощью, как «читать» статусы URL, какие ошибки можно обнаружить и как их исправить.
Перевод с сайта onely.com.
В Отчёте вы можете получить данные о сканировании и индексации всех URL-адресов, которые Google смог обнаружить на вашем сайте. Он поможет отследить, добавлен ли сайт в индекс, и проинформирует о технических проблемах со сканированием и индексацией.
Но перед тем, как говорить об Отчёте, вспомним все этапы индексации страницы в Google.
Как проходит индексация в Google
Чтобы страница ранжировалась в поиске и показывалась пользователям, она должна быть обнаружена, просканирована и проиндексирована.
Обнаружение
Перед тем, как просканировать страницу, Google должен её обнаружить. Он может сделать это несколькими способами.
Наиболее распространённые — с помощью внутренних или внешних ссылок или через карту сайта (файл Sitemap.xml).
Сканирование
Суть сканирования состоит и том, что поисковые системы изучают страницу и анализируют её содержимое.
Главный аспект в этом вопросе — краулинговый бюджет, который представляет собой лимит времени и ресурсов, который поисковая система готова «потратить» на сканирование вашего сайта.
Что такое «краулинговый бюджет, как его проверить и оптимизировать
Индексация
В процессе индексации Google оценивает качество страницы и добавляет её в индекс — базу данных, где собраны все страницы, о которых «знает» Google.
В этот этап включается и рендеринг, который помогает Google видеть макет и содержимое страницы. Собранная информация даёт поисковой системе понимание, как показывать страницу в результатах поиска.
Даже если Google нашёл и просканировал страницу, это не означает, что она обязательно будет проиндексирована.
Но главное, что вы должны понять и запомнить: нет необходимости в том, чтобы абсолютно все страницы вашего сайты были проиндексированы. Вместо этого убедитесь, что в индекс включены все важные и полезные для пользователей страницы с качественным контентом.
Некоторые страницы могут содержать контент низкого качества или быть дублями. Если поисковые системы их увидят, это может негативно отразится на всём сайте.
Поэтому важно в процессе создания стратегии индексации решить, какие страницы должны и не должны быть проиндексированы.
Ранжирование
Только проиндексированные страницы могут появиться в результатах поиска и ранжироваться.
Google определяет, как ранжировать страницу, основываясь на множестве факторов, таких как количество и качество ссылок, скорость страницы, удобство мобильной версии, релевантность контента и др.
Теперь перейдём к Отчёту.
Как пользоваться Отчётом об индексировании в Google Search Console
Чтобы просмотреть Отчёт, авторизуйтесь в своём аккаунте Google Search Console. Затем в меню слева выберите «Покрытие» в секции «Индекс»:
Перед вами Отчёт. Отметив галочками любой из статусов или все сразу, вы сможете выбрать то, что хотите визуализировать на графике:
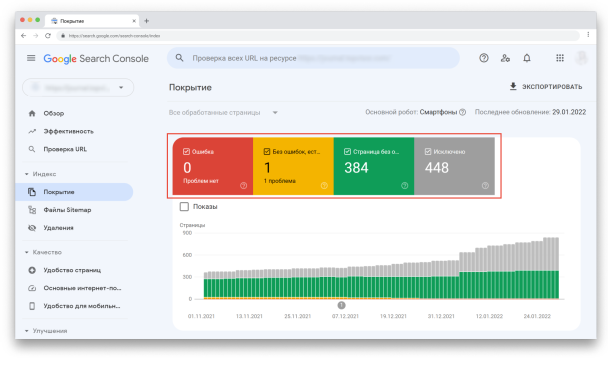
Вы увидите четыре статуса URL-адресов:
- Ошибка — критическая проблема сканирования или индексации.
- Без ошибок, есть предупреждения — URL-адреса проиндексированы, но содержат некоторые некритичные ошибки.
- Страница без ошибок — страницы проиндексированы корректно.
- Исключено — страницы, которые не были проиндексированы из-за проблем (это самый важный раздел, на котором нужно сфокусироваться).
Фильтры «Все обработанные страницы» vs «Все отправленные страницы»
В верхнем углу вы можете отфильтровать, какие страницы хотите видеть:
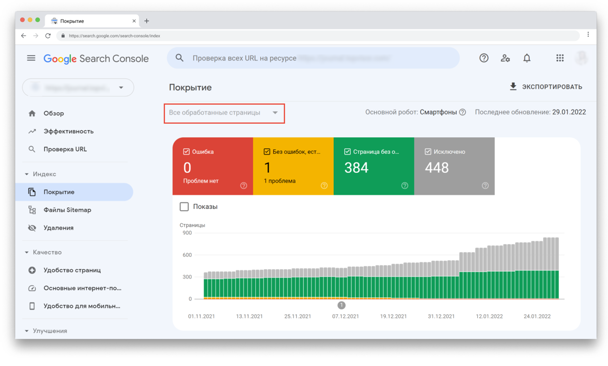
«Все обработанные страницы» показываются по умолчанию. В этот фильтр включены все URL-адреса, которые Google смог обнаружить любым способом.
Фильтр «Все отправленные страницы» включает только URL-адреса, добавленные с помощью файла Sitemap.
В чём разница?
Первый обычно включает в себя больше URL-адресов и многие из них попадают в секцию «Исключено». Это происходит потому, что карта сайта включает только индексируемые URL, в то время как сайты обычно содержат множество страниц, которые не должны быть проиндексированы.
Как пример — URL с параметрами на сайтах eCommerce. Googlebot может найти их разными способами, но не в карте сайта.
Так что когда открываете Отчёт, убедитесь, что смотрите нужные данные.
Проверка статусов URL
Чтобы увидеть подробную информацию о проблемах, обнаруженных для каждого статуса, посмотрите «Сведения» под графиком:
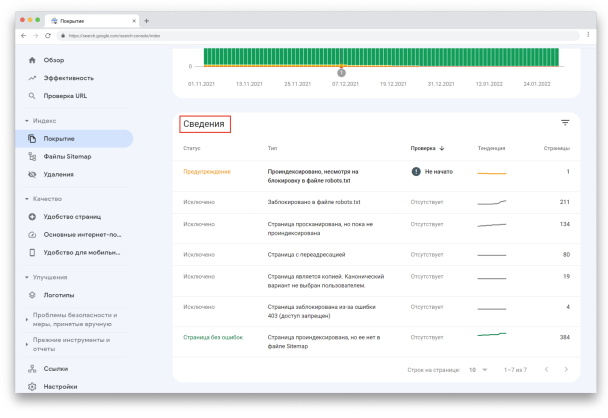
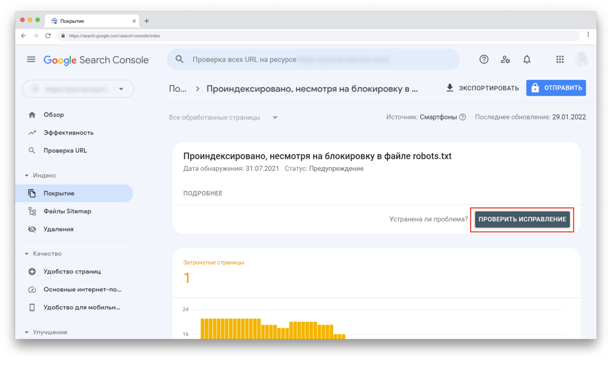
Тут показан статус, тип проблемы и количество затронутых страниц. Обратите внимание на столбец «Проверка» — после исправления ошибки, вы можете попросить Google проверить URL повторно.
Например, если кликнуть на первую строку со статусом «Предупреждение», то вверху появится кнопка «Проверить исправление»:
Вы также можете увидеть динамику каждого статуса: увеличилось, уменьшилось или осталось на том же уровне количество URL-адресов в этом статусе.
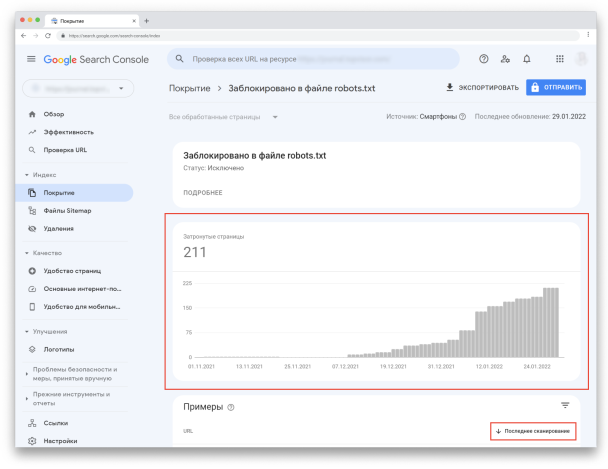
Если в «Сведениях» кликнуть на любой статус, вы увидите количество адресов, связанных с ним. Кроме того, вы сможете посмотреть, когда каждая страница была просканирована (но помните, что эта информация может быть неактуальна из-за задержек в обновлении отчётов).
Что учесть при использовании отчёта
- Всегда проверяйте, смотрите ли вы отчёт по всем обработанным или по всем отправленным страницам. Разница может быть очень существенной.
- Отчёт может показывать изменения с задержкой. После публикации контента подождите несколько дней, пока страницы просканируются и проиндексируются.
- Google пришлёт уведомления на электронную почту, если увидит какие-то критичные проблемы с сайтом.
- Стремитесь к индексации канонической версии страницы, которую вы хотите показывать пользователям и поисковым ботам.
- В процессе развития сайта, на нём будет появляться больше контента, так что ожидайте увеличения количества проиндексированных страниц в Отчёте.
Как часто смотреть Отчёт
Обычно достаточно делать это раз в месяц.
Но если вы внесли значимые изменения на сайте, например, изменили макет страницы, структуру URL или сделали перенос сайта, мониторьте Отчёт чаще, чтобы вовремя поймать негативное влияние изменений.
Рекомендую делать это хотя бы раз в неделю и обращать особое внимание на статус «Исключено».
Дополнительно: инструмент проверки URL
В Search Console есть ещё один инструмент, который даст ценную информацию о сканировании и индексации страниц вашего сайта — Инструмент проверки URL.
Он находится в самом верху страницы в GSC:
Просто вставьте URL, который вы хотите проверить, в эту строку и увидите данные по нему. Например:
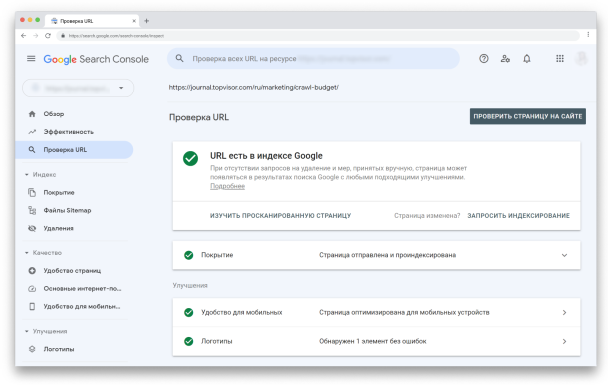
Инструментом можно пользоваться для того, чтобы:
- проверить статус индексирования URL, и обнаружить возможные проблемы;
- узнать, индексируется ли URL;
- просмотреть проиндексированную версию URL;
- запросить индексацию, например, если страница изменилась;
- посмотреть загруженные ресурсы, например, такие как JavaScript;
- посмотреть, какие улучшения доступны для URL, например, реализация структурированных данных или удобство для мобильных.
Если в Отчёте об индексировании обнаружены какие-то проблемы со страницами, используйте Инструмент, чтобы тщательнее проверить их и понять, что именно нужно исправить.
Статус «Ошибка»
Под этим статусом собраны URL, которые не были проиндексированы из-за ошибок.
Если вы видите проблему с пометкой «Отправлено», то это может касаться только URL, которые были отправлены через карту сайту. Убедитесь, что в карте сайте содержатся только те страницы, которые вы действительно хотите проиндексировать.
Ошибка сервера (5xx)
Эта проблема говорит об ошибке сервера со статусом 5xx, например, 502 Bad Gateway или 503 Service Unavailable.
Советую регулярно проверять этот раздел и следить, нет ли у Googlebot проблем с индексацией страниц из-за ошибки сервера.
Что делать. Нужно связаться с вашим хостинг-провайдером, чтобы исправить эту проблему или проверить, не вызваны ли эти ошибки недавними обновлениями и изменениями на сайте.
Как исправить ошибки сервера — рекомендации Google
Ошибка переадресации
Редиректы перенаправляют поисковых ботов и пользователей со старого URL на новый. Обычно они применяются, если старый адрес изменился или страницы больше не существует.
Ошибки переадресации могут указывать на такие проблемы:
- цепочка редиректов слишком длинная;
- обнаружен циклический редирект — страницы переадресуют друг на друга;
- редирект настроен на страницу, URL которой превышает максимальную длину;
- в цепочке редиректов найден пустой или ошибочный URL.
Что делать. Проверьте и исправьте редиректы каждой затронутой страницы.
Доступ к отправленному URL заблокирован в файле robots.txt
Эти страницы есть в файле Sitemap, но заблокированы в файле robots.txt.
Robots.txt — это файл, который содержит инструкции для поисковых роботов о том, как сканировать ваш сайт. Чтобы URL был проиндексирован, Google нужно для начала его просканировать.
Что делать. Если вы видите такую ошибку, перейдите в файл robots.txt и проверьте настройку директив. Убедитесь, что страницы не закрыты через noindex.
Страница, связанная с отправленным URL, содержит тег noindex
По аналогии с предыдущей ошибкой, эта страница была отправлена на индексацию, но она содержит директиву noindex в метатеге или в заголовке ответа HTTP.
Что делать. Если страница должна быть проиндексирована, уберите noindex.
Отправленный URL возвращает ложную ошибку 404
Ложная ошибка 404 означает, что страница возвращает статус 200 OK, но её содержимое может указывать на ошибку. Например, страница пустая или содержит слишком мало контента.
Что делать. Проверьте страницы с ошибками и посмотрите, есть ли возможность изменить контент или настроить редирект.
Отправленный URL возвращает ошибку 401 (неавторизованный запрос)
Ошибка 401 Unauthorized означает, что запрос не может быть обработан, потому что необходимо залогиниться под правильными user ID и паролем.
Что делать. Googlebot не может индексировать страницы, скрытые за логинами. Или уберите необходимость авторизации или подтвердите авторизацию Googlebot, чтобы он мог получить доступ к странице.
Отправленный URL не найден (ошибка 404)
Ошибка 404 говорит о том, что запрашиваемая страница не найдена, потому что была изменена или удалена. Такие страницы есть на каждом сайте и наличие их в малом количестве обычно ни на что не влияет. Но если пользователи будут находить такие страницы, это может отразиться негативно.
Что делать. Если вы увидели эту проблему в отчёте, перейдите на затронутые страницы и проверьте, можете ли вы исправить ошибку. Например, настроить 301-й редирект на рабочую страницу.
Дополнительно убедитесь, что файл Sitemap не содержит URL, которые возвращают какой-либо другой код состояния HTTP кроме 200 OK.
При отправке URL произошла ошибка 403
Код состояния 403 Forbidden означает, что сервер понимает запрос, но отказывается авторизовывать его.
Что делать. Можно либо предоставить доступ анонимным пользователям, чтобы робот Googlebot мог получить доступ к URL, либо, если это невозможно, удалить URL из карты сайта.
URL заблокирован из-за ошибки 4xx (ошибка клиента)
Страница может быть непроиндексирована из-за других ошибок 4xx, которые не описаны выше.
Что делать. Чтобы понять, о какой именно ошибке речь, используйте Инструмент проверки URL. Если устранить ошибку невозможно, уберите URL из карты сайта.
Статус «Без ошибок, есть предупреждения»
URL без ошибок, но с предупреждениями, были проиндексированы, но могут требовать вашего внимания. Тут обычно случается две проблемы.
Проиндексировано, несмотря на блокировку в файле robots.txt
Обычно эти страницы не должны быть проиндексированы, но скорее всего Google нашёл ссылки, указывающие на них, и посчитал их важными.
Что делать. Проверьте эти страницы. Если они всё же должны быть проиндексированы, то обновите файл robots.txt, чтобы Google получил к ним доступ. Если не должны — поищите ссылки, которые на них указывают. Если вы хотите, чтобы URL были просканированы, но не проиндексированы, добавьте директиву noindex.
Страница проиндексирована без контента
URL проиндексированы, но Google не смог прочитать их контент. Это может быть из-за таких проблем:
- Клоакинг — маскировка контента, когда Googlebot и пользователи видят разный контент.
- Страница пустая.
- Google не может отобразить страницу.
- Страница в формате, который Google не может проиндексировать.
Зайдите на эти страницы сами и проверьте, виден ли на них контент. Также проверьте их через Инструмент проверки URL и посмотрите, как их видит Googlebot. После того, как устраните ошибки, или если не обнаружите каких-либо проблем, вы можете запросить у Google повторное индексирование.
Статус «Страница без ошибок»
Здесь показываются страницы, которые корректно проиндексированы. Но на эту часть Отчёта всё равно нужно обращать внимание, чтобы сюда не попали страницы, которые не должны были оказаться в индексе. Тут тоже есть два статуса.
Страница была отправлена в Google и проиндексирована
Это значит, что страницы отправлена через Sitemap и Google её проиндексировал.
Страница проиндексирована, но её нет в файле Sitemap
Это значит, что страница проиндексирована даже несмотря на то, что её нет в Sitemap. Посмотрите, как Google нашёл эту страницу, через Инструмент проверки URL.
Чаще всего страницы в этом статусе — это страницы пагинации, что нормально, учитывая, что их и не должно быть в Sitemap. Посмотрите список этих URL, вдруг какие-то из них стоит добавить в карту сайта.
Статус «Исключено»
В этом статусе находятся страницы, которые не были проиндексированы. В большинстве случаев это вызвано теми же проблемами, которые мы обсуждали выше. Единственное различие в том, что Google не считает, что исключение этих страниц вызвано какой-либо ошибкой.
Вы можете обнаружить, что многие URL здесь исключены по разумным причинам. Но регулярный просмотр Отчёта поможет убедиться, что не исключены важные страницы.
Индексирование страницы запрещено тегом noindex
Что делать. Тут то же самое — если страница и не должна быть проиндексирована, то всё в порядке. Если должна — удалите noindex.
Индексирование страницы запрещено с помощью инструмента удаления страниц
У Google есть Инструмент удаления страниц. Как правило с его помощью Google удаляет страницы из индекса не навсегда. Через 90 дней они снова могут быть проиндексированы.
Что делать. Если вы хотите заблокировать страницу насовсем, вы можете удалить её, настроит редирект, внедрить авторизацию или закрыть от индексации с помощью тега noindex.
Заблокировано в файле robots.txt
У Google есть Инструмент проверки файла robots.txt, где вы можете в этом убедиться.
Что делать. Если эти страницы и не должны быть в индексе, то всё в порядке. Если должны — обновите файл robots.txt.
Помните, что блокировка в robots.txt — не стопроцентный вариант закрыть страницу от индексации. Google может проиндексировать её, например, если найдёт ссылку на другой странице. Чтобы страница точно не была проиндексирована, используйте директиву noindex.
Подробнее о блокировке индексирования при помощи директивы noindex
Страница не проиндексирована вследствие ошибки 401 (неавторизованный запрос)
Обычно это происходит на страницах, защищённых паролем.
Что делать. Если они и не должны быть проиндексированы, то ничего делать не нужно. Если вы не хотите, чтобы Google обнаруживал эти страницы, уберите существующие внутренние и внешние ссылки на них.
Страница просканирована, но пока не проиндексирована
Это значит, что страница «ждёт» решения. Для этого может быть несколько причин. Например, с URL нет проблем и вскоре он будет проиндексирован.
Но чаще всего Google не будет торопиться с индексацией, если контент недостаточно качественный или выглядит похожим на остальные страницы сайта.
В этом случае он поставит её в очередь с низким приоритетом и сфокусируется на индексации более важных страниц. Google говорит, что отправлять такие страницы на переиндексацию не нужно.
Что делать. Для начала убедитесь, что это не ошибка. Проверьте, действительно ли URL не проиндексирован, в Инструменте проверки URL или через инструмент «Индексация» в Анализе сайта в Топвизоре. Они показывают более свежие данные, чем Отчёт.
Как исправить ошибку, когда страница просканирована, но не проиндексирована (на английском)
Обнаружена, не проиндексирована
Это значит, что Google увидел страницу, например, в карте сайта, но ещё не просканировал её. В скором времени страница может быть просканирована.
Иногда эта проблема возникает из-за проблем с краулинговым бюджетом. Google может посчитать сайт некачественным, потому что ему не хватает производительности или на нём слишком мало контента.
Что такое краулинговый бюджет и как его оптимизировать
Возможно, Google не нашёл каких-либо ссылок на эту страницу или нашёл страницы с большим ссылочным весом и посчитал их более приоритетными для сканирования.
Если на сайте есть более качественные и важные страницы, Google может игнорировать менее важные страницы месяцами или даже никогда их не просканировать.
Вариант страницы с тегом canonical
Эти URL — дубли канонической страницы, отмеченные правильным тегом, который указывает на основную страницу.
Что делать. Ничего, вы всё сделали правильно.
Страница является копией, канонический вариант не выбран пользователем
Это значит, что Google не считает эти страницы каноническими. Посмотрите через Инструмент проверки URL какую страницу он считает канонической.
Что делать. Выберите страницу, которая по вашему мнению является канонической, и разметьте дубли с помощью rel=”canonical”.
Страница является копией, канонические версии страницы, выбранные Google и пользователем, не совпадают
Вы выбрали каноническую страницу, но Google решил по-другому. Возможно, страница, которую вы выбрали, не имеет столько внутреннего ссылочного веса, как неканоническая.
Что делать. В этом случае может помочь объединение URL повторяющихся страниц.
Как правильно настроить внутренние ссылки на сайте
Не найдено (404)
URL нет в Sitemap, но Google всё равно его обнаружил. Возможно, это произошло с помощью ссылки на другом сайте или ранее страница существовала и была удалена.
Что делать. Если вы и не хотели, чтобы Google индексировал страницу, то ничего делать не нужно. Другой вариант — поставить 301-й редирект на работающую страницу.
Страница с переадресацией
Эта страница редиректит на другую страницу, поэтому не была проиндексирована. Обычно, такие страницы не требуют внимания.
Что делать. Эти страницы и не должны быть проиндексированы, так что делать ничего не нужно.
Для постоянного редиректа убедитесь, что вы настроили перенаправление на ближайшую альтернативную страницу, а не на Главную. Редирект страницы с 404 ошибкой на Главную может определять её как soft 404.
@JohnMu what does Google do when a site redirects all its 404s to the homepage? Seeing more and more sites do this and it’s such an anti-pattern.
— Joost de Valk (@jdevalk) January 7, 2019
Yeah, it’s not a great practice (confuses users), and we mostly treat them as 404s anyway (they’re soft-404s), so there’s no upside. It’s not critically broken/bad, but additional complexity for no good reason — make a better 404 page instead.
— ? John ? (@JohnMu) January 8, 2019
Ложная ошибка 404
Обычно это страницы, на которых пользователь видит сообщение «не найдено», но которые не сопровождаются кодом ошибки 404.
Что делать. Для исправления проблемы вы можете:
- Добавить или улучшить контент таких страниц.
- Настроить 301-й редирект на ближайшую альтернативную страницу.
- Настроить сервер, чтобы он возвращал правильный код ошибки 404 или 410.
Страница является копией, отправленный URL не выбран в качестве канонического
Эти страницы есть в Sitemap, но для них не выбрана каноническая страница. Google считает их дублями и канонизировал их другими страницами, которые определил самостоятельно.
Что делать. Выберите и добавьте канонические страницы для этих URL.
Страница заблокирована из-за ошибки 403 (доступ запрещён)
Что делать. Если Google не может получить доступ к URL, лучше закрыть их от индексации с помощью метатега noindex или файла robots.txt.
URL заблокирован из-за ошибки 4xx (ошибка клиента)
Сервер столкнулся с ошибкой 4xx, которая не описана выше.
Гайд по ошибкам 4xx и способы их устранения (на английском)
Попробуйте исправить ошибки или оставьте страницы как есть.
Ключевые выводы
- Проверяя данные в Отчёте помните, что не все страницы сайта должны быть просканированы и проиндексированы.
- Закрыть от индексации некоторые страницы может быть так же важно, как и следить за тем, чтобы нужные страницы сайта индексировались корректно.
- Отчёт об индексировании показывает как критичные ошибки, так и неважные, которые не обязательно требуют действий с вашей стороны.
- Регулярно проверяйте Отчёт, но только для того, чтобы убедиться, что всё идёт по плану. Исправляйте только те ошибки, которые не соответствуют вашей стратегии индексации.
Не так страшен чёрт, как его малюют
– русская пословица
Иногда довольно сложно понять, что от тебя хотят поисковые системы, что именно они понимают под значением «страницы низкого качества»? Порой смотришь на страницу и откровенно не понимаешь, почему же её невзлюбил Яндекс или Google. В этой статье мы рассмотрим страницы, которые ПС удаляют из поиска, считая недостаточно качественными.
- Что такое «низкокачественные страницы»
- Как найти проблемные страницы на своём сайте
- Типы низкокачественных страниц
- Влияние страниц низкого качества на ранжирование всего сайта
- И, главное, что делать с такими страницами
Страницы низкого качества в понимании поисковых систем
В блоге Яндекса Елена Першина даёт следующее определение страницы низкого качества: «Под понятием некачественная страница мы понимаем страницы, вероятность показа которых в поиске практически нулевая. По понятным причинам мы не рассказываем способы определения таких страниц, но это чёткий сигнал, что если вы хотите видеть эту страницу в поиске, то со страницей нужно что-то делать».
Внесём немного корректив в слова представителя Яндекса: так как алгоритмы иногда дают сбой, причём в пользу сайтов, страница может занимать ТОП, а потом бесследно пропасть из выдачи.
То есть, страницы низкого качества – это документы, которые не имеют ценности, не несут новую и полезную информацию, не дают релевантный ответ на вопрос пользователя, с точки зрения поисковых систем.
Как обнаружить удалённые низкокачественные страницы
Яндекс.Вебмастер
Проще всего найти исключённые страницы, воспользовавшись инструментом Яндекс.Вебмастер.
Переходим в раздел «Индексирование» – «Страницы в поиске».
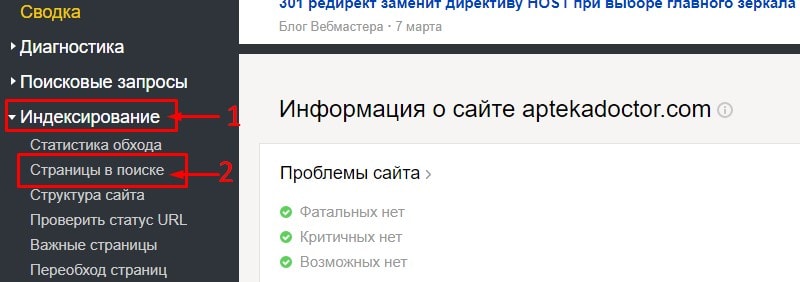
Переходим на вкладку «Исключённые страницы» – выбираем статус «Недостаточно качественная».
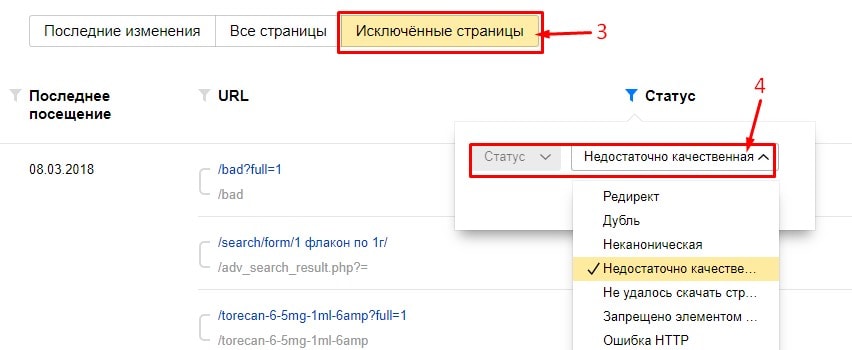
Можно, не переходя с «Последних изменений», выбрать статус «Удалено: Недостаточно качественная».
Google Search Console
В отличие от Яндекса, Google не предоставляет информацию о том, какие страницы были удалены из поиска из-за качества. Даже в новой бета-версии Google Search Console, к сожалению, эта функция отсутствует.
Единственным сигналом от Google сейчас можно считать «Отправленный URL возвращает ложную ошибку 404». В таких случаях нужно проанализировать страницы, убедиться, что они существуют, а не удалены (и просто ответ сервера некорректен). Подробнее о мягкой 404 можно прочесть в нашем блоге.
Итак:
- Переходим в новую версию Google Search Console.
- В боковом меню находим «Статус» – «Индексирование отправленных URL».
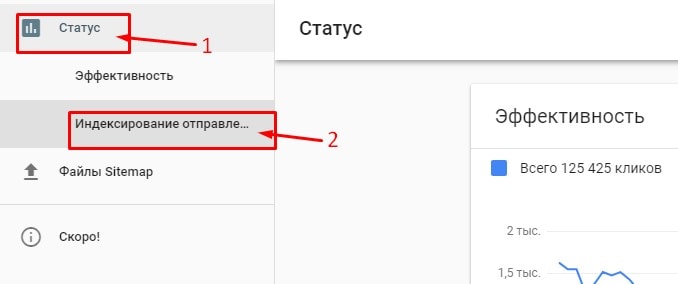
- Выбираем строку «Отправленный URL возвращает ложную ошибку 404».
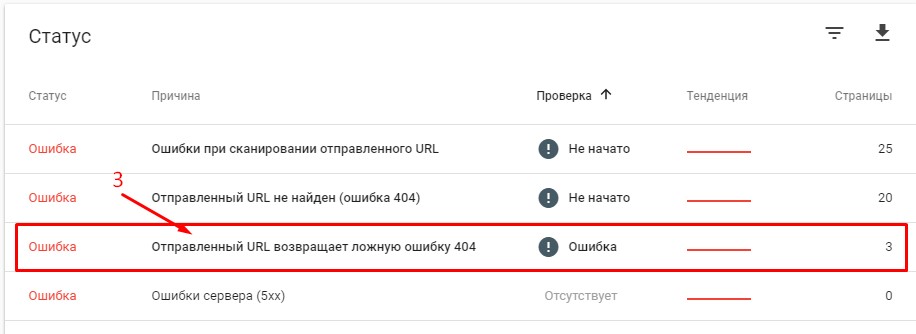
- Анализируем исключённые страницы.
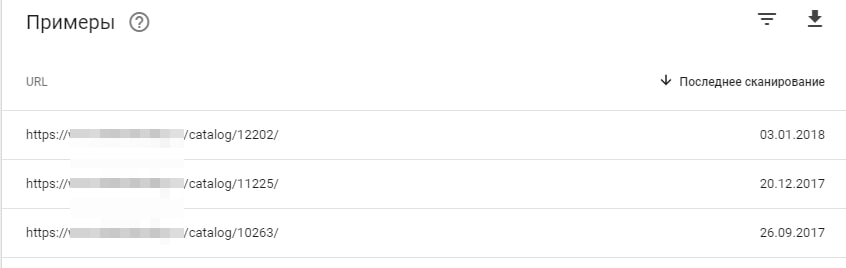
Причины удаления страниц
Проанализировав большое количество различных сайтов и выявив закономерность у страниц, удалённых по причине низкого качества, мы пришли к следующим выводам:
1) Алгоритм Яндекса недоскональный: вместо того, чтобы отнести страницу в удалённые, например, по причине дублирования, он исключает её как низкокачественную.
2) Страницы низкого качества чаще встречаются на коммерческих сайтах – интернет-магазинах и агрегаторах, чем на информационных (за счёт автоматической генерации).
Типология удалённых страниц низкого качества
1. «Жертвы» некорректной работы алгоритма
К этой категории мы отнесём страницы, которые должны были быть удалены по другим причинам.
1.1. Дубли страниц
К страницам низкого качества довольно часто попадают дубликаты страниц.
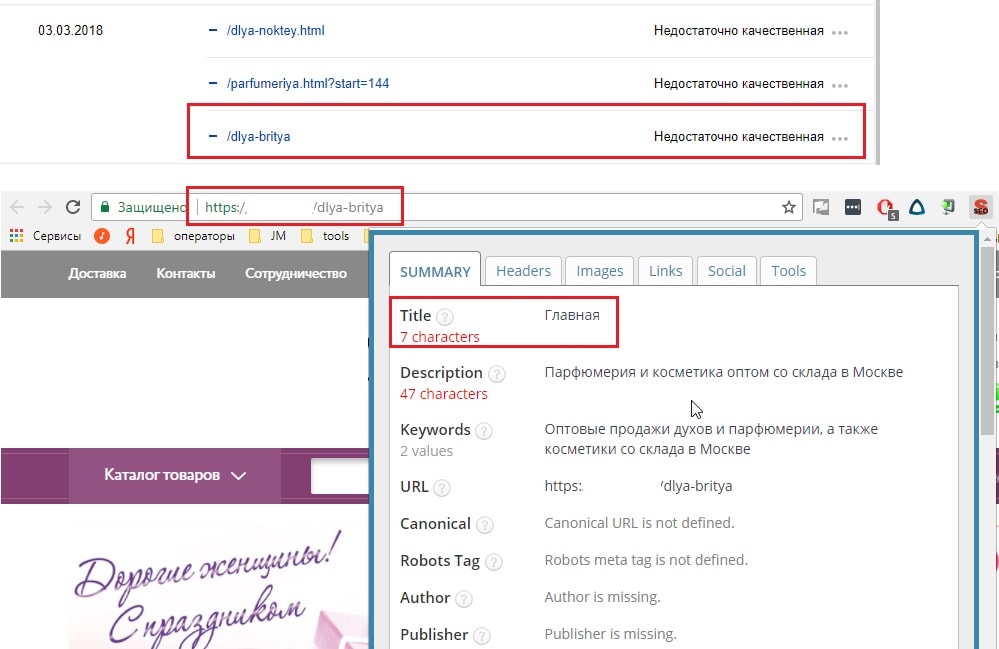
Такие страницы довольно легко определить, если кроме URL ничего не уникализированно.
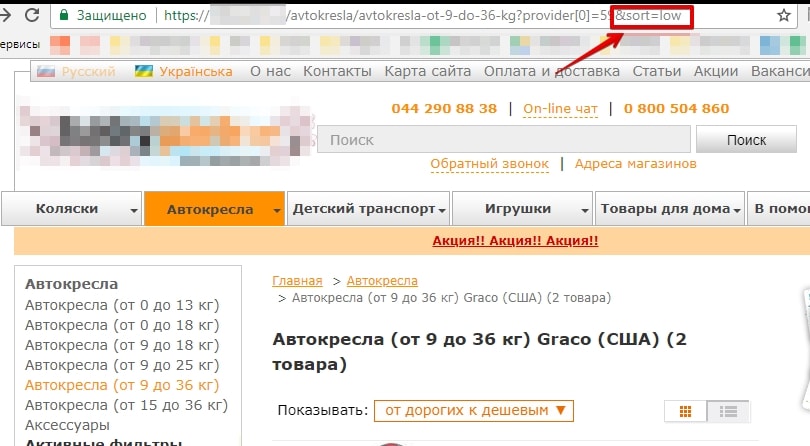
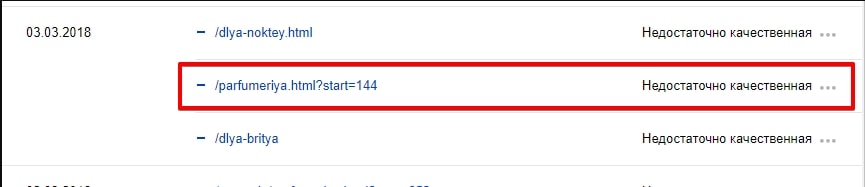
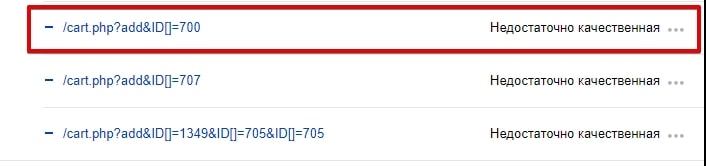
1.2. Страницы сортировки, пагинации и GET-параметры
Чаще Яндекс исключает такие страницы, как дубли, но, как показано на примере ниже, они могут быть удалены и по другой причине.
Страницы сортировки:
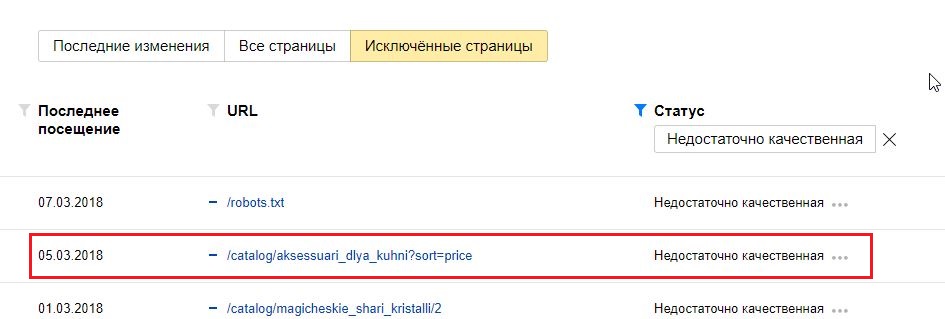
Страницы пагинации:
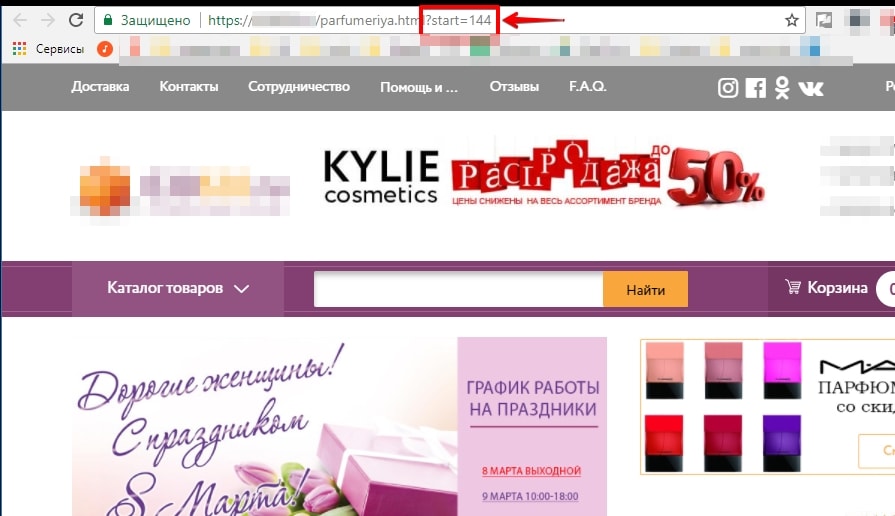
GET-параметры:
В этом примере GET-параметры определяют регион пользователя.


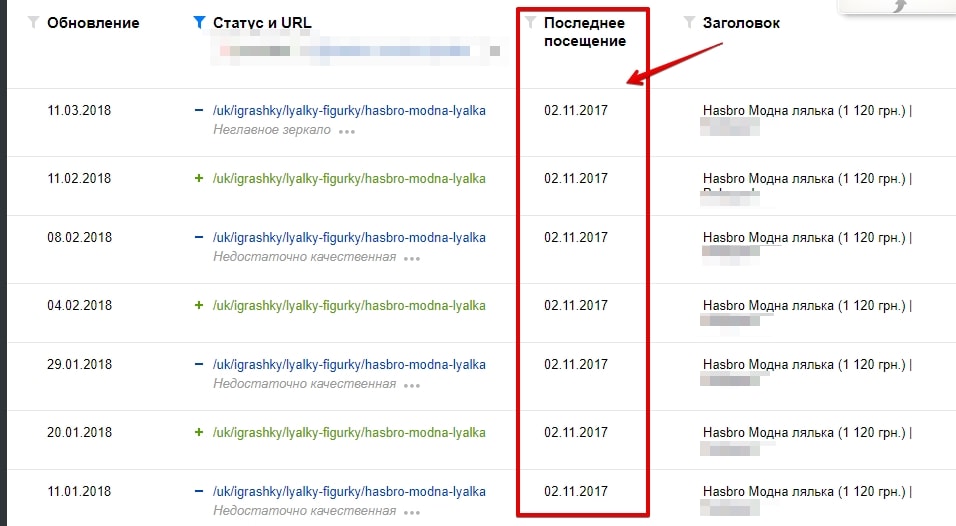
1.3. Неглавное зеркало
Сайт переехал на защищённый протокол. Долгое время робот Яндекса не знал, что делать со старой страницей на HTTP и, то удалял её как некачественную, то добавлял обратно в поиск. По итогу, спустя несколько месяцев, он удалил страницу как неглавное зеркало.
1.4. Страницы, закрытые в файле robots.txt
Директивы в файле robots.txt не являются прямыми указаниями для поисковых роботов, а служат больше рекомендациями. Исходя из практики, бот Яндекса больше придерживается установок, прописанных в файле, чем Google. Но не в этот раз. Как и в прошлом примере, «помучив» несколько раз страницу, он всё-таки «снизошёл» и удалил её из поиска как запрещённую в файле robots.txt.
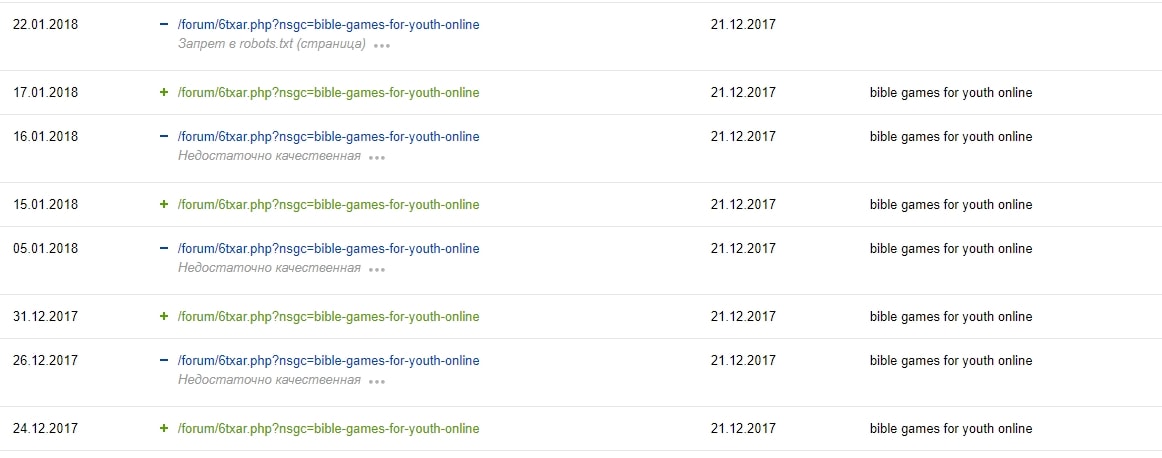
2. Действительные недостаточно качественные страницы
В эту группу «я плох, бесполезен и никому не нужен» попадают страницы низкого качества, которые действительно являются таковыми.
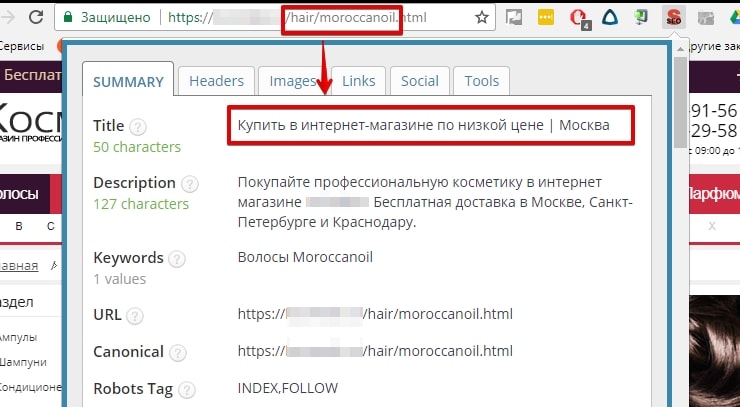
2.1. Шаблонная генерация страниц
Часто шаблонное заполнение и генерация страниц влечёт за собой ошибки внутренней оптимизации: неуникальные Title, отсутствует Description, с H1 что-то не так и т. д.
Тут важно сказать, что пользователь без проблем поймёт разницу в страницах и для него они могут быть даже полезными, но он о них не узнает, так как роботы стоят на страже порядка не допустят попадания данных страниц в поиск.

Увидев Title на странице, долго не пришлось гадать, что с ней не так.
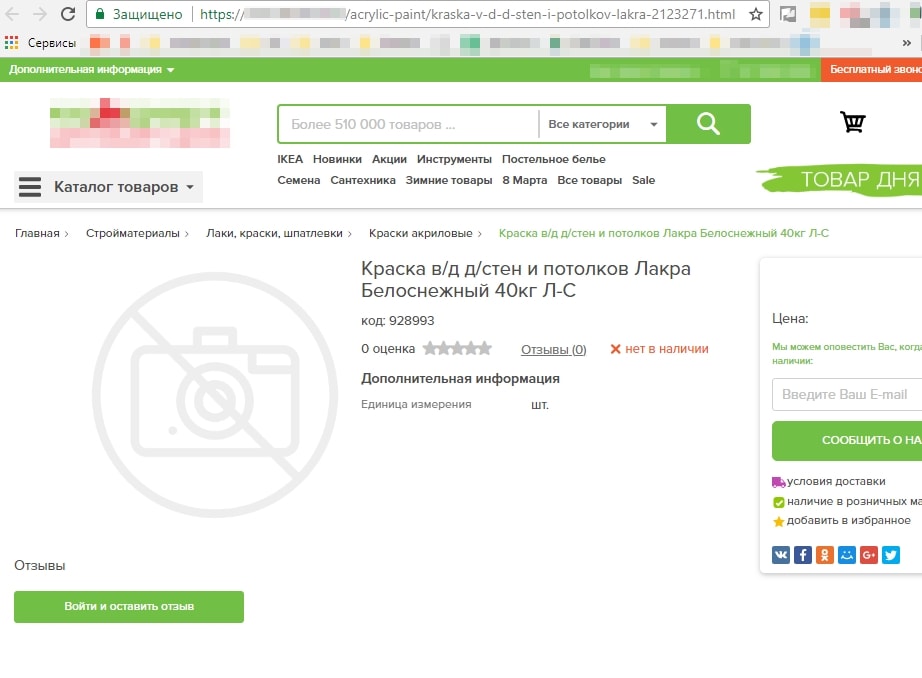
2.2. Плохое заполнение карточек товара
Создать карточку товара просто, а вот наполнить её качественным контентом, описанием товара, изображениями – не каждому под силу.

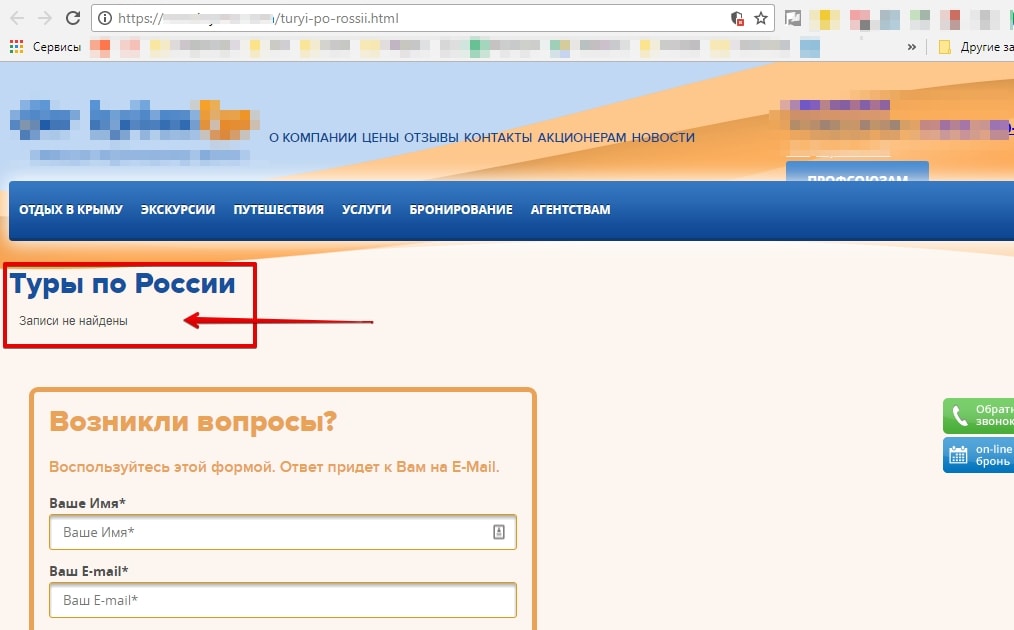
2.3. Листинг без листинга
Создавать страницы категорий/подкатегорий без товара – лишено смысла, так как:
- вряд ли такая страница попадёт в ТОП;
- вероятнее всего, показатель отказов на такой странице будет максимальный.
Об этом скажет и сам Яндекс, исключив страницу из поиска как недостаточно качественную.

2.4. Страницы с малым количеством контента
Несмотря на слова поддержки Яндекса, что важно не количество контента, а качество, его отсутствие – не очень хорошая идея.
Например, на этой странице, кроме шаблонной части и двух изображений, ничего нет.

2.5. Страницы, не предназначенные для поиска
В эту группу относятся страницы robots.txt, Sitemap, RSS-ленты.
Чуть ли не в каждом проекте можно встретить файл robots.txt, удалённый из поиска как недостаточно качественная страница.

Не стоит паниковать, робот о нём знает и помнит. Страница просто не будет отображаться в поисковой выдаче – ну а зачем она там нужна?
XML- и HTML-карты сайта также исключаются. Особенно если у вас многостраничная карта сайта – какая польза от неё в поиске?

Яндекс считает, что RSS-лентам в поиске тоже нет места.

2.6. Страницы с некорректным ответом сервера
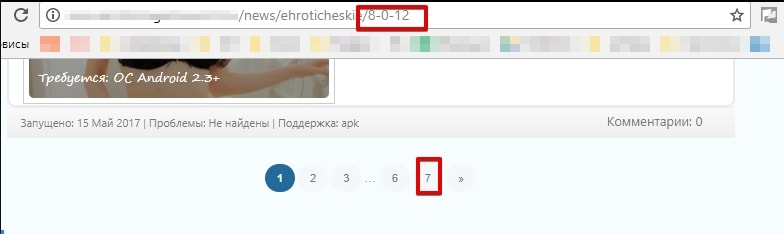
В эту группу мы отнесём страницы, которые должны выдавать 404 ответ сервера, а вместо этого отвечают 200 ОК.
Например, это могут быть несуществующие страницы пагинации. Яндекс исключил восьмую страницу пагинации, при имеющихся семи.

Также это могут быть пустые страницы. В таком случае нужно анализировать и принимать решение: настраивать 404 ответ сервера или 301 редирект.
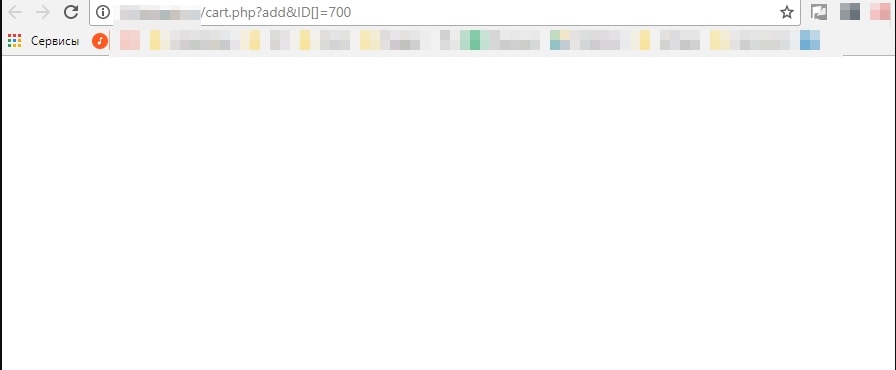
Google может удалить такие страницы, как SOFT 404, но об этом чуть позже.
2.7. «Нужно больше страниц»
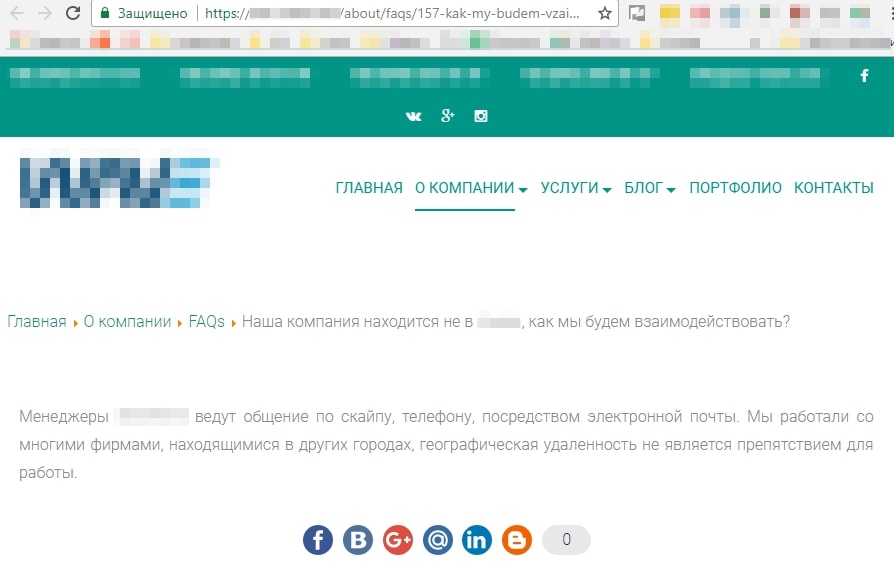
Этим часто грешат агрегаторы и интернет-магазины, считая, что чем больше страниц, тем больше видимость и трафик. Страницы создают, не беря во внимание их качество и надобность.
Например, низкокачественными являются страницы, созданные под каждый вопрос из FAQ.

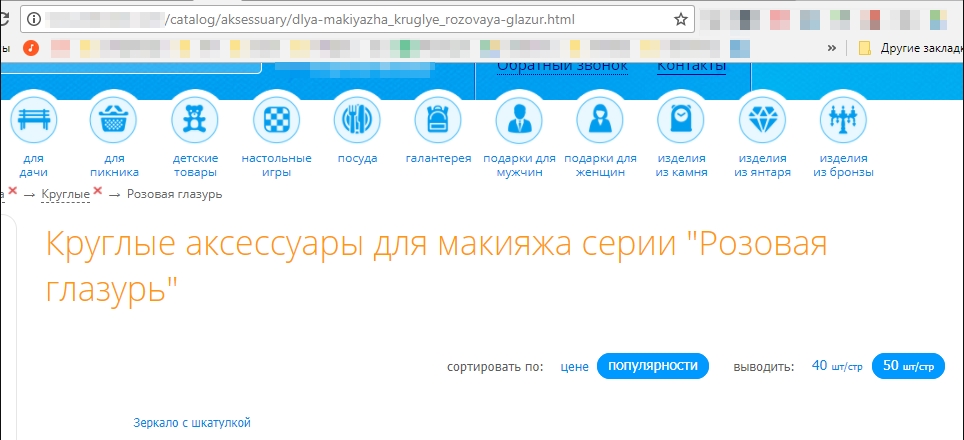
Часто бесполезные страницы создаются с помощью применения всех фильтров. Я соглашусь, что нужно думать о посетителях и удобстве пользования сайтом. Если у интернет-магазина большой ассортимент, то структура сайта должна состоять из множества категорий и подкатегорий, а также иметь различные фильтры. Но, во-первых, нужно ли создавать страницу для «Фарфоровых кукол 20 см с голубыми глазами в розовом платье с корзинкой» и, во-вторых, нужны ли такие страницы в поиске?
2.8. Технические ошибки
Яндекс не жалует страницы с pop-upом, который перекрывает текст без возможности его закрыть, или случайно созданные страницы под изображения.
Как должно быть и как реализовано на сайте:
Случайно созданная страница:
2.9. SOFT 404
Как мы уже говорили, Google прикрепляет страницам именно такой ярлык. Это могут быть пустые страницы или же страницы с очень малым количеством контента.
Влияние низкокачественных страниц на ранжирование
Сколько бы страниц ни было исключено из поиска по этой причине, на ранжировании остальных страниц сайта это никак не отразится.
Этот алгоритм удаления страниц анализирует каждую страницу отдельно, пытаясь ответить на вопрос: «Если страница будет в поиске, даст ли она релевантный ответ на вопрос пользователя?».
Как говорит Яндекс, страница может быть исключена из поиска даже в том случае, если отсутствуют запросы. Робот может вернуть её, если количество запросов, которым будет релевантна страница, увеличится.

Что же делать со страницами низкого качества
Принимать меры можно только после того, как вы определили причину исключения страницы из поиска. Без выяснения обстоятельств не стоит паниковать, сразу удалять страницы, настраивать 301 редирект.
Алгоритм действий после определения причины удаления страницы:
Дубли страниц: 301 редирект или rel=“canonical”.
Страницы сортировки, пагинации и GET-параметры: настраиваем rel=“canonical”/уникализируем страницы пагинации.
Неглавное зеркало: проверяем 301 редирект, отправляем на переиндексацию.
Страницы, закрытые в файле robots.txt: если страница не нужна в поиске, настраиваем метатег noindex.
Шаблонная генерация страниц: если страница нужна в поиске – уникализируем её, работаем над качеством.
Плохое заполнение карточек товара: добавляем описание товара, изображения и т. д.
Листинг без листинга:
- проверяем, приносили ли такие страницы трафик;
- определяем, нужны ли они пользователям;
- временно ли на них отсутствует товар или его не было и не будет.
Принимаем действия исходя из результата. Например, если страница приносила трафик и на ней временно отсутствует товар, можно вывести ленту с похожими товарами или со смежных категорий.
Страницы с малым количеством контента: определяем необходимость таких страниц в поиске, если они нужны – наполняем качественным контентом; не нужны – настраиваем метатег noindex.
Страницы, не предназначенные для поиска: тут всё просто – ничего не делаем, просто живём с этим.
Страницы с некорректным ответом сервера и SOFT 404: как бы ни логично это прозвучит, настраиваем корректный ответ сервера.
«Нужно больше страниц»: проверяем, приносили ли такие страницы трафик, определяем, нужны ли они пользователям в поиске, частотны ли запросы – принимаем действия исходя из результата.
Страницы с техническими ошибками: исправляем недочёты/если страницы не нужны – закрываем noindex/настраиваем 404 ответ сервера.
ВАЖНО: выше перечислены общие рекомендации, которые чаще всего предпринимаются в той или иной ситуации. Каждый случай нужно рассматривать в индивидуальном порядке, находить оптимальное решение проблемы.
Заключение
К сожалению, выдача поисковых систем переполнена мусором, некачественным контентом и бессмысленными сгенерированными страницами. Яндекс и Google активно борются с такими страницами, исключая их из поиска. Мы за качественный контент. Поэтому, если у вас возникли трудности, вы наблюдаете, как поисковики удаляют страницы, ссылаясь на недостаточное качество, мы можем провести технический аудит вашего сайта и написать инструкции по решению проблемы.
Еще по теме:
- Безопасный переезд сайта с http на https в Яндексе и Google
- Что влияет на частоту индексации и как заставить поискового робота посещать ваш сайт чаще
- Гайд по robots.txt: создаём, настраиваем, проверяем
- Да будет SEO: 4 плагина для оптимизации сайта на WordPress
- Обзор CMS-систем — какой движок выбрать? Часть 1
В последние время всё больше владельцев проектов задумываются о переводе сайтов на защищённый протокол. Не перестают напоминать об этом и представители поисковых систем. Яндекс пока…
От чего зависит скорость индексации сайта, как на нее можно повлиять и как сообщить роботу Яндекса и Google об изменениях на сайте. Читайте о том,…
В этой статье мы рассмотрим: Что такое robots.txt? Все директивы файла: Disallow и Allow Sitemap Host Crawl-delay Clean-param Использование спецсимволов Как проверить корректную работу файла…
Рассмотрим SEO-плагины для CMS WordPress, которые позволяют провести внутреннюю оптимизацию сайта. О некоторых плагинах я уже писала ранее. У плагинов, о которых расскажу в этой…
При создании сайта мы часто делаем выбор в пользу CMS. Давай попробуем разобраться, чем же обусловлен наш выбор, и как определиться с подходящим инструментом. Предисловие…

SEO-TeamLead
За два года от стажера до тимлида.
Google меня любит.
Множко катаю на сапборде.
Девиз: Либо делай качественно, либо делай качественно.
Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.
This page describes how different
HTTP status codes,
network errors, and DNS errors affect Google Search. We cover the top 20 status codes that
Googlebot
encountered on the web, and the most prominent network and DNS errors. More exotic status
codes, such as
418 (I'm a teapot),
aren’t covered. All issues mentioned on this page generate a corresponding error or warning in
Search Console’s
Page Indexing report.
HTTP status codes
HTTP status codes are generated by the server that’s hosting the site when it responds to a
request made by a client, for example a browser or a crawler. Every HTTP status code has a
different meaning, but often the outcome of the request is the same. For example, there are
multiple status codes that signal redirection, but their outcome is the same.
Search Console generates error messages for status codes in the 4xx–5xx range,
and for failed redirections (3xx). If the server responded with a
2xx status code, the content received in the response may be considered for
indexing.
The following table contains the most encountered HTTP status codes by Googlebot and an
explanation how Google handles each status code.
| HTTP status codes | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Google considers the content for indexing. If the content suggests an error, for example
|
|||||||||||
|
Googlebot follows up to 10 redirect hops. If the crawler doesn’t receive content within
In case of robots.txt, Googlebot follows at least five redirect hops as defined by
Any content Googlebot received from the redirecting URL is ignored, and the final target
|
|||||||||||
|
Google’s indexing pipeline doesn’t consider URLs that return a
Any content Googlebot received from URLs that return a
|
|||||||||||
|
If the robots.txt file returns a server error status code for more than 30 days, Google
Any content Googlebot received from URLs that return a
|
soft 404 errors
A soft 404 error is when a URL that returns a page telling the user that the page does
not exist and also a
200 (success)
status code. In some cases, it might be a page with no main content or empty page.
Such pages may be generated for various reasons by your website’s web server or content
management system, or the user’s browser. For example:
- A missing server-side include file.
- A broken connection to the database.
- An empty internal search result page.
- An unloaded or otherwise missing JavaScript file.
It’s a bad user experience to return a 200 (success) status code, but then
display or suggest an error message or some kind of error on the page. Users may think the
page is a live working page, but then are presented with some kind of error. Such pages are
excluded from Search.
When Google’s algorithms detect that the page is actually an error page based on its content,
Search Console will show a soft 404 error in the site’s
Page Indexing report.
Fix soft 404 errors
Depending on the state of the page and the desired outcome, you can solve soft 404
errors in multiple ways:
- The page and content are no longer available.
- The page or content is now somewhere else.
- The page and content still exist.
Try to determine which solution would be the best for your users.
The page and content are no longer available
If you removed the page and there’s no replacement page on your site with similar content,
return a
404 (not found) or 410 (gone)
response (status) code for the page. These status codes indicate to search engines that the
page doesn’t exist and the content should not be indexed.
If you have access to your server’s configuration files, you can make these error pages useful
to users by customizing them. A good custom 404 page helps people find the
information they’re looking for, and also provides other helpful content that encourages
people to explore your site further. Here are some tips for designing a useful custom
404 page:
-
Tell visitors clearly that the page they’re looking for can’t be found. Use language that is
friendly and inviting. -
Make sure your
404page has the same look and feel (including navigation) as
the rest of your site. -
Consider adding links to your most popular articles or posts, as well as a link to your
site’s home page. - Think about providing a way for users to report a broken link.
Custom 404 pages are created solely for users. Since these pages are useless from
a search engine’s perspective, make sure the server returns a 404 HTTP status
code to prevent having the pages indexed.
The page or content is now somewhere else
If your page has moved or has a clear replacement on your site, return a
301 (permanent redirect)
to redirect the user. This will not interrupt their browsing experience and it’s also a great
way to tell search engines about the new location of the page. Use the
URL Inspection tool
to verify whether your URL is actually returning the correct code.
The page and content still exist
If an otherwise good page was flagged with a soft 404 error, it’s likely it
didn’t load properly for Googlebot, it was missing critical resources, or it displayed a
prominent error message during rendering. Use the
URL Inspection tool
to examine the rendered content and the returned HTTP code. If the rendered page is blank,
nearly blank, or the content has an error message, it could be that your page references many
resources that can’t be loaded (images, scripts, and other non-textual elements), which can be
interpreted as a soft 404.
Reasons that resources can’t be loaded include blocked resources (blocked by
robots.txt), having too many
resources on a page, various server errors, or slow loading or very large resources.
Network and DNS errors
Network and DNS errors have quick, negative effects on a URL’s presence in Google Search.
Googlebot treats network timeouts, connection reset, and DNS errors similarly to
5xx server errors. In case of network errors, crawling immediately starts
slowing down, as a network error is a sign that the server may not be able to handle the
serving load. Since Googlebot couldn’t reach the server hosting the site, Google also hasn’t
received any content from the server. The lack of content means that Google can’t index the
crawled URLs, and already indexed URLs that are unreachable will be removed from Google’s
index within days. Search Console may generate errors for each respective error.
Debug network errors
These errors happen before Google starts crawling a URL or while Google is crawling the URL.
Since the errors may occur before the server can respond and so there’s no status code that
can hint at issues, diagnosing these errors can be more challenging. To debug timeout and
connection reset errors:
-
Look at your firewall settings and logs. There may be an overly-broad
blocking rule set. Make sure that
Googlebot IP addresses
are not blocked by any firewall rule. -
Look at the network traffic. Use tools like
tcpdump and
Wireshark to capture and analyze
TCP packets, and look for anomalies that point to a specific network component or server
module. - If you can’t find anything suspicious, contact your hosting company.
The error may be in any server component that handles network traffic. For example, overloaded
network interfaces may drop packets leading to timeouts (inability to establish a connection)
and reset connections (RST packet sent because a port was mistakenly closed).
Debug DNS errors
DNS errors are most commonly caused by misconfiguration, but they may be also caused by a
firewall rule that’s blocking Googlebot DNS queries. To debug DNS errors, do the following:
-
Inspect your firewall rules. Make sure that
none of Google’s IPs
are blocked by any firewall rule, and that bothUDPandTCP
requests are allowed. -
Look at your DNS records. Double check that your
Aand
CNAMErecords are pointing to the right IP addresses and hostname,
respectively. For example:dig +nocmd example.com a +noall +answer
dig +nocmd www.example.com cname +noall +answer
-
Check that all your name servers are pointing to the correct IP addresses of your
site. For example:dig +nocmd example.com ns +noall +answerexample.com. 86400 IN NS a.iana-servers.net. example.com. 86400 IN NS b.iana-servers.net.dig +nocmd @a.iana-servers.net example.com +noall +answerexample.com. 86400 IN A 93.184.216.34dig +nocmd @b.iana-servers.net example.com +noall +answer... -
If you’ve made changes to your DNS configuration within the last 72 hours,
you may need to wait for your changes to propagate across the global DNS network. To speed up propagation, you can
flush Google’s Public DNS cache. -
If you’re running your own DNS server, make sure it’s healthy and that it’s
not overloaded.
Мы должны убедиться, что не существующие страницы возвращают код 404. Для этого необходимо проанализировать следующие ошибки в панелях вебмастеров:
в Яндекс Вебмастере:
- Некорректно настроено отображение несуществующих файлов и страниц;
- Ошибка HTTP.
в Google Search Console:
- Отправленный URL возвращает ложную ошибку 404;
- Отправленный URL возвращает ошибку 401 (неавторизованный запрос) ;
- Отправленный URL не найден (ошибка 404);
- Страница не проиндексирована вследствие ошибки 401 (неавторизованный запрос) ;
- Ложная ошибка 404.
Для проведения анализа необходимо в Яндекс Вебмастере перейти в раздел «Диагностика сайта»:
и убедиться, что ошибка:
- Некорректно настроено отображение несуществующих файлов и страниц;
отсутствует в проблемах сайта.
Если ошибка присутствует, то готовим ТЗ для программиста.
2. Также смотрим, чтобы в проблемах сайта не было ошибки «Большое количество страниц-дублей». Но в любом случае переходим в Яндекс Вебмастере в раздел Индексирование -> Страницы в поиске:
3. Нажимаем на вкладку «Исключенные страницы” и кликаем на фильтр “Статус”, где выбираем статус «Ошибка HTTP 404»:
Скачиваем страницы с ошибкой 404 в формате Excel и проверяем через бесплатный сервис https://coolakov. ru/tools/ping/, чтобы страницы действительно отдавали код 404.
Заходим на эти страницы и проверяем наличие шаблона для обработки 404 ошибки. Пользователь должен увидеть сообщение о том, что запрашиваемая страница не найдена и предложения о других возможных вариантах перехода, например:
Если страница не существует и не возвращает код 404, необходимо в ТЗ программисту указать, что нужно настроить корректную обработку 404 ошибки на страницах сайта в соответствующем разделе и реализовать шаблон 404 ошибки с необходимой информацией.
Наличие шаблона 404-ой страницы не является достаточным подтверждением корректности кода ответа. Поэтому код ответа необходимо всегда проверять через сервис проверки HTTP.
4. В этом же разделе выбираем статус «Дубль»:
Необходимо убедиться, что наличие дублирующихся страниц не связано с некорректной обработкой несуществующих страниц. Для этого следует перейти на дублирующийся URL и проверить, что страница отображается корректно.
Если Яндекс Вебмастер определил страницу как дубль и она не возвращает код 404, необходимо визуально проверить, как отображаются несколько похожих страниц. Затем необходимо добавить любое количество символов после последнего «/» в URL этих страниц, чтобы получилась несуществующая страница и проверить полученный URL на код ответа. Если есть проблемы, то код ответа будет 200 ОК. Тогда делаем ТЗ программисту.
5. Для Google Search Console анализ будет немного проще. Следует перейти в раздел «Покрытие», выбрать вкладку »Ошибки, Предупреждения и Исключения”, и изучить отчет под графиком на ошибки:
- Отправленный URL возвращает ложную ошибку 404;
- Отправленный URL возвращает ошибку 401 (неавторизованный запрос) ;
- Отправленный URL не найден (ошибка 404);
- Страница не проиндексирована вследствие ошибки 401 (неавторизованный запрос) ;
- Ложная ошибка 404.
В случае обнаружения, алгоритм исправления ошибок должен быть аналогичным алгоритму работы с Я. Вебмастером.