Проверка корректности А/Б тестов
Время на прочтение
8 мин
Количество просмотров 10K
Хабр, привет! Сегодня поговорим о том, что такое корректность статистических критериев в контексте А/Б тестирования. Узнаем, как проверить, является критерий корректным или нет. Разберём пример, в котором тест Стьюдента не работает.

Меня зовут Коля, я работаю аналитиком данных в X5 Tech. Мы с Сашей продолжаем писать серию статей по А/Б тестированию, это наша третья статья. Первые две можно посмотреть тут:
-
Стратификация. Как разбиение выборки повышает чувствительность A/Б теста
-
Бутстреп и А/Б тестирование
Корректный статистический критерий
В А/Б тестировании при проверке гипотез с помощью статистических критериев можно совершить одну из двух ошибок:
-
ошибку первого рода – отклонить нулевую гипотезу, когда на самом деле она верна. То есть сказать, что эффект есть, хотя на самом деле его нет;
-
ошибку второго рода – не отклонить нулевую гипотезу, когда на самом деле она неверна. То есть сказать, что эффекта нет, хотя на самом деле он есть.
Совсем не ошибаться нельзя. Чтобы получить на 100% достоверные результаты, нужно бесконечно много данных. На практике получить столько данных затруднительно. Если совсем не ошибаться нельзя, то хотелось бы ошибаться не слишком часто и контролировать вероятности ошибок.
В статистике ошибка первого рода считается более важной. Поэтому обычно фиксируют допустимую вероятность ошибки первого рода, а затем пытаются минимизировать вероятность ошибки второго рода.
Предположим, мы решили, что допустимые вероятности ошибок первого и второго рода равны 0.1 и 0.2 соответственно. Будем называть статистический критерий корректным, если его вероятности ошибок первого и второго рода равны допустимым вероятностям ошибок первого и второго рода соответственно.
Как сделать критерий, в котором вероятности ошибок будут равны допустимым вероятностям ошибок?
Вероятность ошибки первого рода по определению равна уровню значимости критерия. Если уровень значимости положить равным допустимой вероятности ошибки первого рода, то вероятность ошибки первого рода должна стать равной допустимой вероятности ошибки первого рода.
Вероятность ошибки второго рода можно подогнать под желаемое значение, меняя размер групп или снижая дисперсию в данных. Чем больше размер групп и чем ниже дисперсия, тем меньше вероятность ошибки второго рода. Для некоторых гипотез есть готовые формулы оценки размера групп, при которых достигаются заданные вероятности ошибок.
Например, формула оценки необходимого размера групп для гипотезы о равенстве средних:
![n > \frac{\left[ \Phi^{-1} \left( 1-\alpha / 2 \right) + \Phi^{-1} \left( 1-\beta \right) \right]^2 (\sigma_A^2 + \sigma_B^2)}{\varepsilon^2}](https://habrastorage.org/getpro/habr/upload_files/5d2/f18/735/5d2f18735269b594598add742c905d53.svg)
где ![]() и
и ![]() – допустимые вероятности ошибок первого и второго рода,
– допустимые вероятности ошибок первого и второго рода, ![]() – ожидаемый эффект (на сколько изменится среднее),
– ожидаемый эффект (на сколько изменится среднее), ![]() и
и ![]() – стандартные отклонения случайных величин в контрольной и экспериментальной группах.
– стандартные отклонения случайных величин в контрольной и экспериментальной группах.
Проверка корректности
Допустим, мы работаем в онлайн-магазине с доставкой. Хотим исследовать, как новый алгоритм ранжирования товаров на сайте влияет на среднюю выручку с покупателя за неделю. Продолжительность эксперимента – одна неделя. Ожидаемый эффект равен +100 рублей. Допустимая вероятность ошибки первого рода равна 0.1, второго рода – 0.2.
Оценим необходимый размер групп по формуле:
import numpy as np
from scipy import stats
alpha = 0.1 # допустимая вероятность ошибки I рода
beta = 0.2 # допустимая вероятность ошибки II рода
mu_control = 2500 # средняя выручка с пользователя в контрольной группе
effect = 100 # ожидаемый размер эффекта
mu_pilot = mu_control + effect # средняя выручка с пользователя в экспериментальной группе
std = 800 # стандартное отклонение
# исторические данные выручки для 10000 клиентов
values = np.random.normal(mu_control, std, 10000)
def estimate_sample_size(effect, std, alpha, beta):
"""Оценка необходимого размер групп."""
t_alpha = stats.norm.ppf(1 - alpha / 2, loc=0, scale=1)
t_beta = stats.norm.ppf(1 - beta, loc=0, scale=1)
var = 2 * std ** 2
sample_size = int((t_alpha + t_beta) ** 2 * var / (effect ** 2))
return sample_size
estimated_std = np.std(values)
sample_size = estimate_sample_size(effect, estimated_std, alpha, beta)
print(f'оценка необходимого размера групп = {sample_size}')оценка необходимого размера групп = 784Чтобы проверить корректность, нужно знать природу случайных величин, с которыми мы работаем. В этом нам помогут исторические данные. Представьте, что мы перенеслись в прошлое на несколько недель назад и запустили эксперимент с таким же дизайном, как мы планировали запустить его сейчас. Дизайн – это совокупность параметров эксперимента, таких как: целевая метрика, допустимые вероятности ошибок первого и второго рода, размеры групп и продолжительность эксперимента, техники снижения дисперсии и т.д.
Так как это было в прошлом, мы знаем, какие покупки совершили пользователи, можем вычислить метрики и оценить значимость отличий. Кроме того, мы знаем, что эффекта на самом деле не было, так как в то время эксперимент на самом деле не запускался. Если значимые отличия были найдены, то мы совершили ошибку первого рода. Иначе получили правильный результат.
Далее нужно повторить эту процедуру с мысленным запуском эксперимента в прошлом на разных группах и временных интервалах много раз, например, 1000.
После этого можно посчитать долю экспериментов, в которых была совершена ошибка. Это будет точечная оценка вероятности ошибки первого рода.
Оценку вероятности ошибки второго рода можно получить аналогичным способом. Единственное отличие состоит в том, что каждый раз нужно искусственно добавлять ожидаемый эффект в данные экспериментальной группы. В этих экспериментах эффект на самом деле есть, так как мы сами его добавили. Если значимых отличий не будет найдено – это ошибка второго рода. Проведя 1000 экспериментов и посчитав долю ошибок второго рода, получим точечную оценку вероятности ошибки второго рода.
Посмотрим, как оценить вероятности ошибок в коде. С помощью численных синтетических А/А и А/Б экспериментов оценим вероятности ошибок и построим доверительные интервалы:
def run_synthetic_experiments(values, sample_size, effect=0, n_iter=10000):
"""Проводим синтетические эксперименты, возвращаем список p-value."""
pvalues = []
for _ in range(n_iter):
a, b = np.random.choice(values, size=(2, sample_size,), replace=False)
b += effect
pvalue = stats.ttest_ind(a, b).pvalue
pvalues.append(pvalue)
return np.array(pvalues)
def print_estimated_errors(pvalues_aa, pvalues_ab, alpha):
"""Оценивает вероятности ошибок."""
estimated_first_type_error = np.mean(pvalues_aa < alpha)
estimated_second_type_error = np.mean(pvalues_ab >= alpha)
ci_first = estimate_ci_bernoulli(estimated_first_type_error, len(pvalues_aa))
ci_second = estimate_ci_bernoulli(estimated_second_type_error, len(pvalues_ab))
print(f'оценка вероятности ошибки I рода = {estimated_first_type_error:0.4f}')
print(f' доверительный интервал = [{ci_first[0]:0.4f}, {ci_first[1]:0.4f}]')
print(f'оценка вероятности ошибки II рода = {estimated_second_type_error:0.4f}')
print(f' доверительный интервал = [{ci_second[0]:0.4f}, {ci_second[1]:0.4f}]')
def estimate_ci_bernoulli(p, n, alpha=0.05):
"""Доверительный интервал для Бернуллиевской случайной величины."""
t = stats.norm.ppf(1 - alpha / 2, loc=0, scale=1)
std_n = np.sqrt(p * (1 - p) / n)
return p - t * std_n, p + t * std_n
pvalues_aa = run_synthetic_experiments(values, sample_size, effect=0)
pvalues_ab = run_synthetic_experiments(values, sample_size, effect=effect)
print_estimated_errors(pvalues_aa, pvalues_ab, alpha)оценка вероятности ошибки I рода = 0.0991
доверительный интервал = [0.0932, 0.1050]
оценка вероятности ошибки II рода = 0.1978
доверительный интервал = [0.1900, 0.2056]Оценки вероятностей ошибок примерно равны 0.1 и 0.2, как и должно быть. Всё верно, тест Стьюдента на этих данных работает корректно.
Распределение p-value
Выше рассмотрели случай, когда тест контролирует вероятность ошибки первого рода при фиксированном уровне значимости. Если решим изменить уровень значимости с 0.1 на 0.01, будет ли тест контролировать вероятность ошибки первого рода? Было бы хорошо, если тест контролировал вероятность ошибки первого рода при любом заданном уровне значимости. Формально это можно записать так:
Для любого ![]() выполняется
выполняется ![]() .
.
Заметим, что в левой части равенства записано выражение для функции распределения p-value. Из равенства следует, что функция распределения p-value в точке X равна X для любого X от 0 до 1. Эта функция распределения является функцией распределения равномерного распределения от 0 до 1. Мы только что показали, что статистический критерий контролирует вероятность ошибки первого рода на заданном уровне для любого уровня значимости тогда и только тогда, когда при верности нулевой гипотезы p-value распределено равномерно от 0 до 1.
При верности нулевой гипотезы p-value должно быть распределено равномерно. А как должно быть распределено p-value при верности альтернативной гипотезы? Из условия для вероятности ошибки второго рода ![]() следует, что
следует, что ![]() .
.
Получается, график функции распределения p-value при верности альтернативной гипотезы должен проходить через точку ![]() , где
, где ![]() и
и ![]() – допустимые вероятности ошибок конкретного эксперимента.
– допустимые вероятности ошибок конкретного эксперимента.
Проверим, как распределено p-value в численном эксперименте. Построим эмпирические функции распределения p-value:
import matplotlib.pyplot as plt
def plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, beta):
"""Рисует графики распределения p-value."""
estimated_first_type_error = np.mean(pvalues_aa < alpha)
estimated_second_type_error = np.mean(pvalues_ab >= alpha)
y_one = estimated_first_type_error
y_two = 1 - estimated_second_type_error
X = np.linspace(0, 1, 1000)
Y_aa = [np.mean(pvalues_aa < x) for x in X]
Y_ab = [np.mean(pvalues_ab < x) for x in X]
plt.plot(X, Y_aa, label='A/A')
plt.plot(X, Y_ab, label='A/B')
plt.plot([alpha, alpha], [0, 1], '--k', alpha=0.8)
plt.plot([0, alpha], [y_one, y_one], '--k', alpha=0.8)
plt.plot([0, alpha], [y_two, y_two], '--k', alpha=0.8)
plt.plot([0, 1], [0, 1], '--k', alpha=0.8)
plt.title('Оценка распределения p-value', size=16)
plt.xlabel('p-value', size=12)
plt.legend(fontsize=12)
plt.grid()
plt.show()
plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, beta)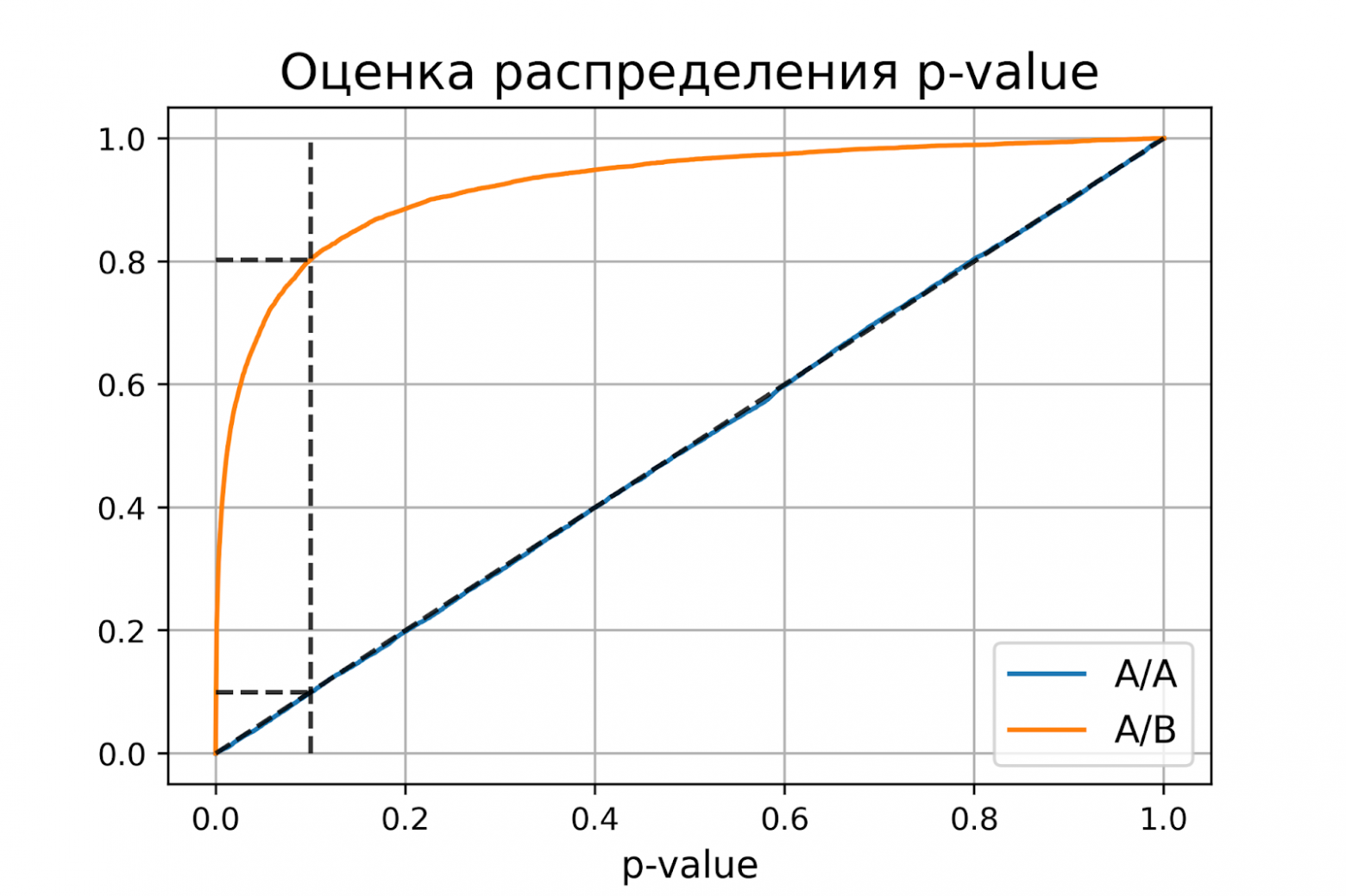
P-value для синтетических А/А тестах действительно оказалось распределено равномерно от 0 до 1, а для синтетических А/Б тестов проходит через точку ![]() .
.
Кроме оценок распределений на графике дополнительно построены четыре пунктирные линии:
-
диагональная из точки [0, 0] в точку [1, 1] – это функция распределения равномерного распределения на отрезке от 0 до 1, по ней можно визуально оценивать равномерность распределения p-value;
-
вертикальная линия с
 – пороговое значение p-value, по которому определяем отвергать нулевую гипотезу или нет. Проекция на ось ординат точки пересечения вертикальной линии с функцией распределения p-value для А/А тестов – это вероятность ошибки первого рода. Проекция точки пересечения вертикальной линии с функцией распределения p-value для А/Б тестов – это мощность теста (мощность = 1 —
– пороговое значение p-value, по которому определяем отвергать нулевую гипотезу или нет. Проекция на ось ординат точки пересечения вертикальной линии с функцией распределения p-value для А/А тестов – это вероятность ошибки первого рода. Проекция точки пересечения вертикальной линии с функцией распределения p-value для А/Б тестов – это мощность теста (мощность = 1 —  ).
). -
две горизонтальные линии – проекции на ось ординат точки пересечения вертикальной линии с функцией распределения p-value для А/А и А/Б тестов.
График с оценками распределения p-value для синтетических А/А и А/Б тестов позволяет проверить корректность теста для любого значения уровня значимости.
Некорректный критерий
Выше рассмотрели пример, когда тест Стьюдента оказался корректным критерием для случайных данных из нормального распределения. Может быть, все критерии всегда работаю корректно, и нет смысла каждый раз проверять вероятности ошибок?
Покажем, что это не так. Немного изменим рассмотренный ранее пример, чтобы продемонстрировать некорректную работу критерия. Допустим, мы решили увеличить продолжительность эксперимента до 2-х недель. Для каждого пользователя будем вычислять стоимость покупок за первую неделю и стоимость покупок за второю неделю. Полученные стоимости будем передавать в тест Стьюдента для проверки значимости отличий. Положим, что поведение пользователей повторяется от недели к неделе, и стоимости покупок одного пользователя совпадают.
def run_synthetic_experiments_two(values, sample_size, effect=0, n_iter=10000):
"""Проводим синтетические эксперименты на двух неделях."""
pvalues = []
for _ in range(n_iter):
a, b = np.random.choice(values, size=(2, sample_size,), replace=False)
b += effect
# дублируем данные
a = np.hstack((a, a,))
b = np.hstack((b, b,))
pvalue = stats.ttest_ind(a, b).pvalue
pvalues.append(pvalue)
return np.array(pvalues)
pvalues_aa = run_synthetic_experiments_two(values, sample_size)
pvalues_ab = run_synthetic_experiments_two(values, sample_size, effect=effect)
print_estimated_errors(pvalues_aa, pvalues_ab, alpha)
plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, beta)оценка вероятности ошибки I рода = 0.2451
доверительный интервал = [0.2367, 0.2535]
оценка вероятности ошибки II рода = 0.0894
доверительный интервал = [0.0838, 0.0950]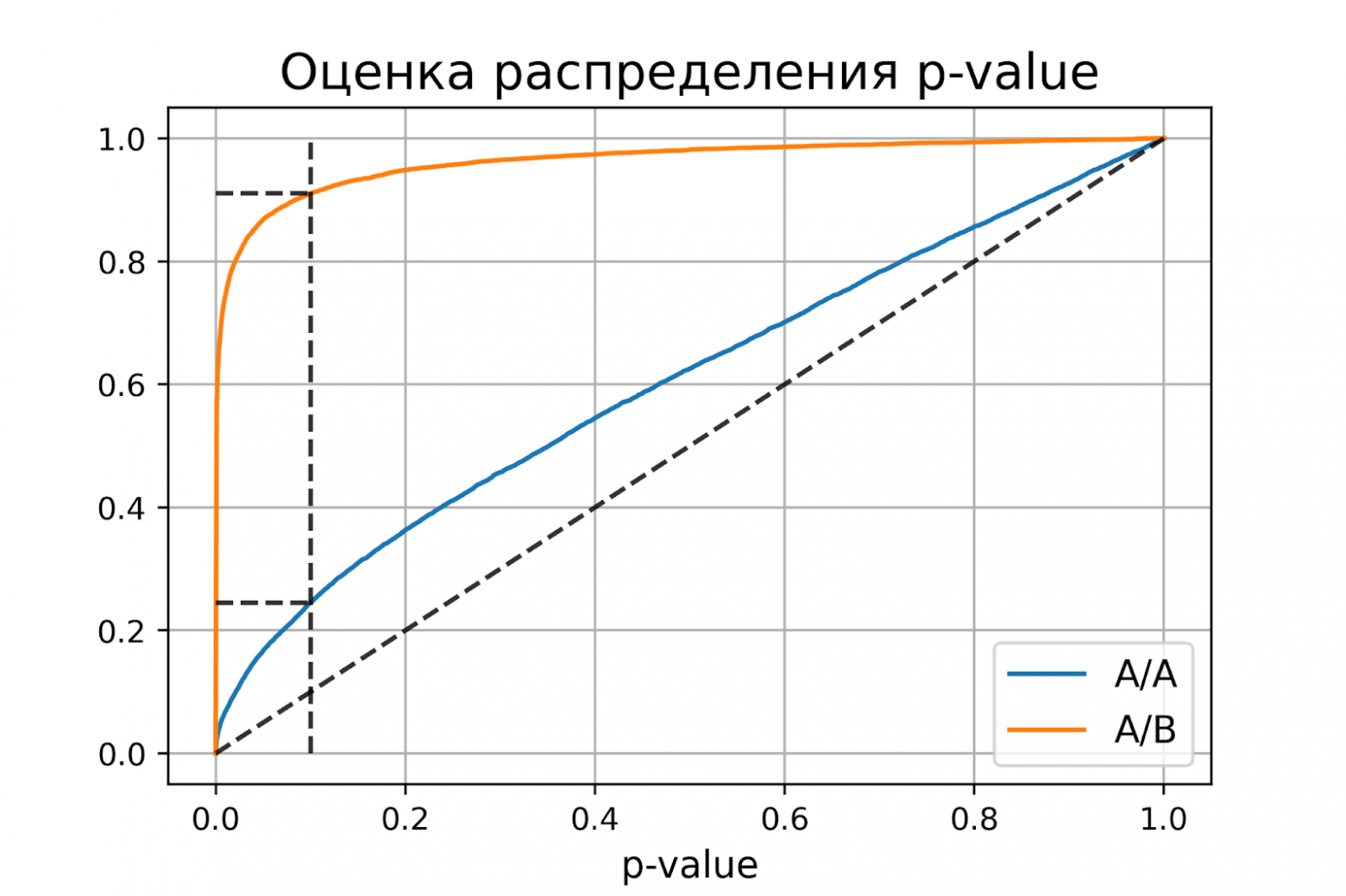
Получили оценку вероятности ошибки первого рода около 0.25, что сильно больше уровня значимости 0.1. На графике видно, что распределение p-value для синтетических А/А тестов не равномерно, оно отклоняется от диагонали. В этом примере тест Стьюдента работает некорректно, так как данные зависимые (стоимости покупок одного человека зависимы). Если бы мы сразу не догадались про зависимость данных, то оценка вероятностей ошибок помогла бы нам понять, что такой тест некорректен.
Итоги
Мы обсудили, что такое корректность статистического теста, посмотрели, как оценить вероятности ошибок на исторических данных и привели пример некорректной работы критерия.
Таким образом:
-
корректный критерий – это критерий, у которого вероятности ошибок первого и второго рода равны допустимым вероятностям ошибок первого и второго рода соответственно;
-
чтобы критерий контролировал вероятность ошибки первого рода для любого уровня значимости, необходимо и достаточно, чтобы p-value при верности нулевой гипотезы было распределено равномерно от 0 до 1.
Ошибки I и II рода при проверке гипотез, мощность
Общий обзор
Принятие неправильного решения
Мощность и связанные факторы
Проверка множественных гипотез
Общий обзор
Большинство проверяемых гипотез сравнивают между собой группы объектов, которые испытывают влияние различных факторов.
Например, можно сравнить эффективность двух видов лечения, чтобы сократить 5-летнюю смертность от рака молочной железы. Для данного исхода (например, смерть) сравнение, представляющее интерес (например, различные показатели смертности через 5 лет), называют эффектом или, если уместно, эффектом лечения.
Нулевую гипотезу выражают как отсутствие эффекта (например 5-летняя смертность от рака молочной железы одинаковая в двух группах, получающих разное лечение); двусторонняя альтернативная гипотеза будет означать, что различие эффектов не равно нулю.
Критериальная проверка гипотезы дает возможность определить, достаточно ли аргументов, чтобы отвергнуть нулевую гипотезу. Можно принять только одно из двух решений:
- отвергнуть нулевую гипотезу и принять альтернативную гипотезу
- остаться в рамках нулевой гипотезы
Важно: В литературе достаточно часто встречается понятие «принять нулевую гипотезу». Хотелось бы внести ясность, что со статистической точки зрения принять нулевую гипотезу невозможно, т.к. нулевая гипотеза представляет собой достаточно строгое утверждение (например, средние значения в сравниваемых группах равны ![]() ).
).
Поэтому фразу о принятии нулевой гипотезы следует понимать как то, что мы просто остаемся в рамках гипотезы.
Принятие неправильного решения
Возможно неправильное решение, когда отвергают/не отвергают нулевую гипотезу, потому что есть только выборочная информация.
| |
Верная гипотеза | ||
|---|---|---|---|
| H0 | H1 | ||
| Результат применения критерия |
H0 | H0 верно принята | H0 неверно принята (Ошибка второго рода) |
| H1 | H0 неверно отвергнута (Ошибка первого рода) |
H0 верно отвергнута |
Ошибка 1-го рода: нулевую гипотезу отвергают, когда она истинна, и делают вывод, что имеется эффект, когда в действительности его нет. Максимальный шанс (вероятность) допустить ошибку 1-го рода обозначается α (альфа). Это уровень значимости критерия; нулевую гипотезу отвергают, если наше значение p ниже уровня значимости, т. е., если p < α.
Следует принять решение относительно значения а прежде, чем будут собраны данные; обычно назначают условное значение 0,05, хотя можно выбрать более ограничивающее значение, например 0,01.
Шанс допустить ошибку 1-го рода никогда не превысит выбранного уровня значимости, скажем α = 0,05, так как нулевую гипотезу отвергают только тогда, когда p< 0,05. Если обнаружено, что p > 0,05, то нулевую гипотезу не отвергнут и, следовательно, не допустят ошибки 1-го рода.
Ошибка 2-го рода: не отвергают нулевую гипотезу, когда она ложна, и делают вывод, что нет эффекта, тогда как в действительности он существует. Шанс возникновения ошибки 2-го рода обозначается β (бета); а величина (1-β) называется мощностью критерия.
Следовательно, мощность — это вероятность отклонения нулевой гипотезы, когда она ложна, т.е. это шанс (обычно выраженный в процентах) обнаружить реальный эффект лечения в выборке данного объема как статистически значимый.
В идеале хотелось бы, чтобы мощность критерия составляла 100%; однако это невозможно, так как всегда остается шанс, хотя и незначительный, допустить ошибку 2-го рода.
К счастью, известно, какие факторы влияют на мощность и, таким образом, можно контролировать мощность критерия, рассматривая их.
Мощность и связанные факторы
Планируя исследование, необходимо знать мощность предложенного критерия. Очевидно, можно начинать исследование, если есть «хороший» шанс обнаружить уместный эффект, если таковой существует (под «хорошим» мы подразумеваем, что мощность должна быть по крайней мере 70-80%).
Этически безответственно начинать исследование, у которого, скажем, только 40% вероятности обнаружить реальный эффект лечения; это бесполезная трата времени и денежных средств.
Ряд факторов имеют прямое отношение к мощности критерия.
Объем выборки: мощность критерия увеличивается по мере увеличения объема выборки. Это означает, что у большей выборки больше возможностей, чем у незначительной, обнаружить важный эффект, если он существует.
Когда объем выборки небольшой, у критерия может быть недостаточно мощности, чтобы обнаружить отдельный эффект. Эти методы также можно использовать для оценки мощности критерия для точно установленного объема выборки.
Вариабельность наблюдений: мощность увеличивается по мере того, как вариабельность наблюдений уменьшается.
Интересующий исследователя эффект: мощность критерия больше для более высоких эффектов. Критерий проверки гипотез имеет больше шансов обнаружить значительный реальный эффект, чем незначительный.
Уровень значимости: мощность будет больше, если уровень значимости выше (это эквивалентно увеличению допущения ошибки 1-го рода, α, а допущение ошибки 2-го рода, β, уменьшается).
Таким образом, вероятнее всего, исследователь обнаружит реальный эффект, если на стадии планирования решит, что будет рассматривать значение р как значимое, если оно скорее будет меньше 0,05, чем меньше 0,01.
Обратите внимание, что проверка ДИ для интересующего эффекта указывает на то, была ли мощность адекватной. Большой доверительный интервал следует из небольшой выборки и/или набора данных с существенной вариабельностью и указывает на недостаточную мощность.
Проверка множественных гипотез
Часто нужно выполнить критериальную проверку значимости множественных гипотез на наборе данных с многими переменными или существует более двух видов лечения.
Ошибка 1-го рода драматически увеличивается по мере увеличения числа сравнений, что приводит к ложным выводам относительно гипотез. Следовательно, следует проверить только небольшое число гипотез, выбранных для достижения первоначальной цели исследования и точно установленных априорно.
Можно использовать какую-нибудь форму апостериорного уточнения значения р, принимая во внимание число выполненных проверок гипотез.
Например, при подходе Бонферрони (его часто считают довольно консервативным) умножают каждое значение р на число выполненных проверок; тогда любые решения относительно значимости будут основываться на этом уточненном значении р.
Связанные определения:
p-уровень
Альтернативная гипотеза, альтернатива
Альфа-уровень
Бета-уровень
Гипотеза
Двусторонний критерий
Критерий для проверки гипотезы
Критическая область проверки гипотезы
Мощность
Мощность исследования
Мощность статистического критерия
Нулевая гипотеза
Односторонний критерий
Ошибка I рода
Ошибка II рода
Статистика критерия
Эквивалентные статистические критерии
В начало
Содержание портала
Вероятность того, что, отвергая нулевую гипотезу, мы совершаем ошибку (первого рода), которая численно равна уровню значимости а, задаваемому при проверке гипотезы. [c.205]
Случай, когда РН, п> РНО,П определены, называется случаем двух простых гипотез. В [12] показано, что для данного случая существует наилучший критерий, т. е. что всегда можно определить с как функцию ошибки первого рода и что [c.89]
Очевидно, что уровень значимости q — это вероятность ошибки первого рода. Если он чрезмерно велик, то в основном ущерб будет связан с ошибочным отклонением верной гипотезы Н0, если же он чрезмерно мал, то ущерб будет возникать от ошибочного принятия ложной гипотезы Н0. На практике в качестве [c.70]
Ошибки первого рода определяются на уровне менеджмента, реально сложившемся на [c.37]
Если qn > q, то возникает ошибка первого рода и, наоборот. [c.155]
Вероятность совершить ошибку первого рода принято обозна- [c.63]
Ошибка первого рода возникает, когда процесс находится в [c.149]
При проверке гипотезы Я0 против Я, возможны два рода ошибок. Ошибки первого рода — это ошибка, когда принимается не- [c.58]
Все выборочные методы контроля качества связаны с риском ошибок. Существует риск ошибочного отклонения годной партии (в терминах статистики ошибка первого рода) и риск ошибочного принятия негодной партии (ошибка второго рода). Поскольку в первом случае дополнительные расходы несет производитель, риск называется риском производителя. Принятие бракованной партии имеет те же последствия для другой стороны, поэтому риск второго рода называют риском покупателя. [c.250]
Ошибка первого рода 256 [c.480]
Ошибки первого рода должны предотвращаться агентствами-исполнителями с ошибками второго рода сложнее, так как исполнителю их трудно об- [c.31]
Задача правильного выбора плана статистического контроля состоит в том, чтобы сделать ошибки первого и второго рода маловероятными. Напомним, что ошибки первого рода связаны с возможностью ошибочно забраковать партию изделий, ошибки второго рода связаны с возможностью ошибочно пропустить бракованную партию. [c.225]
При использовании критерия К. Пирсона, как и в случае применения других критериев, возможны два рода ошибок. Ошибка первого рода состоит в отклонении верной гипотезы, а ошибка второго рода — в принятии неправильной. Для иллюстрации на рис. 43 показаны кривые плотности распределения вероятности величины х2 в случаях, когда проверяемая гипотеза верна — кривая 1, и когда неверна — кривая 2. Если вероятности, с которой выносится решение, соответствует значение х20 ю при всех Х < х о гипотеза будет приниматься, а при всех х2 > х.2, — отклоняться. Вероятности ошибок первого и второго родов при этом [c.108]
Мы проанализируем АЩ1)-разности логарифмических прибылей для рынков капитала. АК(1)-разности используются для устранения — или, по крайней мере, для сведения к минимуму — линейной зависимости. Как мы видели в Главе 5, линейная зависимость может сместить показатель Херста (и может заставить его выглядеть значимым, когда нет процесса с долговременной памятью) т.е. вызвать ошибку первого рода. Используя АК(1)-разности, мы сводим смещение к минимуму, и, будем надеяться, делаем результаты незначительными. Такой процесс часто называют, предварительным отбеливанием или удалением трендов. Мы будем использовать последний термин. Удаление трендов не подходит для всех статистических испытаний, хотя кажется, что оно используется почти волей-неволей. Для некоторых испытаний удаление трендов может скрыть значимую информацию. Однако в случае R/S-анализа удаление трендов устранит сериальную корреляцию, или кратковременную память, а также инфляционный рост. Сериальная корреляция представляет проблему для очень высокочастотных данных, таких как пятиминутные прибыли. Инфляционный рост является проблемой для низкочастотных данных, таких как 60 лет месячных прибылей. Однако, как мы увидим, для R/S-анализа процесс с кратковременной памятью представляет гораздо большую проблему, чем проблема инфляционного роста. Мы начинаем с ряда логарифмической доходности [c.110]
Как видно по таблице, для реально встречающихся на практике распределений (см. [14, п. 6.1.11]) истинная ошибка первого рода может быть очень большой, в несколько раз превышая нормальную ошибку в 5%. [c.397]
Применительно к задаче статистического регулирования ошибка первого рода состоит в том, что налаженный процесс будет принят за разлаженный и он будет необоснованно остановлен для корректировки, когда в этом нет необходимости. Ошибка второго рода в этой задаче состоит в том, что разлаженный процесс будет принят за налаженный, что приведет к выпуску бракованной продукции. [c.25]
Вероятность совершить ошибку первого рода принято обозначать через а, а вероятность совершить ошибку второго рода — через р. Для задачи статистического регулирования а называется риском излишней наладки, ар — риском незамеченной разладки. Критическими точками (границами) называют точки, отделяющие критическую область от интервала — области принятия гипотезы. Различают одностороннюю (правостороннюю или левостороннюю) и двустороннюю критические области. Правосторонней называют критическую область, определяемую неравенством К>Ккр, где К — статистика критерия, Кщ, — положительное число (рис. 2.3). [c.25]
С этой целью задаются достаточной малой вероятностью — уровнем значимости а (это то же, что и вероятность совершения ошибки первого рода). Затем ищут критическую точку Ккр, исходя из требования, чтобы при условии справедливости нулевой гипотезы вероятность того, что критерий К примет значение большее /СкР, была бы равна принятому уровню значимости [c.26]
Как следует из неравенства (3.89) и (3.93), события Л и S не являются независимыми (поскольку в указанные неравенства входит одна и та же величина Дт). Поэтому на основании выражений (3.90) и (3.93) вероятность ошибки первого рода определится как [c.161]
Поэтому, несмотря на отсутствие отклонений в технологическом процессе, границы регулирования на контрольной карте могут быть нарушены вследствие ошибочной оценки ( риск излишней наладки ). Это называется ошибкой первого рода. Поскольку расстояние между средней линией и границами регулирования обычно составляет 3 сигмы (три средних квадратических отклонения), вероятность риска ошибки первого рода составляет 0,3%. [c.74]
Если сузить диапазон границ регулирования, то ошибки второго рода сократятся, однако ошибки первого рода увеличатся. Если же расширить границы регулирования, то ошибки первого рода уменьшатся, тогда как ошибки второго рода возрастут. Отсюда вытекает, что рациональное и экономичное сочетание этих двух аспектов является сущностью установления границ регулирования. [c.74]
Последствия ошибок первого и второго рода весьма различны. Ошибка первого рода требует от аудитора или экономического субъекта дополнительной работы по уточнению факта и характера обнаруженных недостатков бухгалтерского учета или системы внутреннего контроля. После дополнительных исследований истина обычно устанавливается. [c.216]
Ошибка первого рода — ошибка биометрической системы, принявшей зарегистрированного легального пользователя за злоумышленника. [c.449]
Ошибка первого рода состоит в том, что будет отвергнута правильная нулевая гипотеза. [c.71]
Гипотеза Но отклоняется Ошибка первого рода Правильный вывод [c.72]
В большинстве случаев последствия указанных ошибок неравнозначны. Первая приводит к более осторожному, консервативному решению, вторая — к неоправданному риску. Что лучше или хуже — зависит от конкретной постановки задачи и содержания нулевой гипотезы. Например, если Н0 состоит в признании продукции предприятия качественной, и допущена ошибка первого рода, то будет забракована годная продукция. Допустив ошибку второго рода, мы отправим потребителю брак. Очевидно, последствия второй ошибки более серьезны с точки зрения имиджа фирмы и ее долгосрочных перспектив. [c.72]
Вероятность совершить ошибку первого рода принято обозначать буквой а, и ее называют уровнем значимости. Вероятность совершить ошибку второго рода обозначают / . Тогда вероятность несовершения ошибки второго рода (1 — р) называется мощностью критерия. [c.72]
Обычно значения а задают заранее круглыми числами (например, 0.1 0.05 0.01 и т. п.), а затем стремятся построить критерий наибольшей мощности. Таким образом, если а = 0.05, то это означает, что исследователь не хочет совершить ошибку первого рода более чем в 5 случаях из 100. [c.72]
На практике для построения тестов часто используют следующий подход. Предположим, что можно найти такую статистику tn = tn(Xi,…, Хп), что если гипотеза Щ верна, то распределение случайной величины tn известно (например, табулировано). Тогда для заданного значения а ошибки первого рода можно найти такую область Ка, что P(in Ка] = 1 — а (подчеркнем, что вероятность вычисляется в предположении, что верна нулевая гипотеза). Тогда тест определяется следующим образом [c.540]
При желании можно повысить «подозрительность» нейросети, обеспечив точность выявления банкротов вплоть до 99% — за счет снижения требований к ошибкам второго рода (класификации нормальной фирмы как банкрота). Это достигается путем увеличения веса ошибки первого рода (класификации банкрота как нормальной фирмы). В зависимости от конкретной практической задачи «подозрительность» сети можно произвольно регулировать. [c.188]
Вероятность ошибки первого рода, т.е. вероятность попада- [c.65]
Ошибки первого и второго рода. Понятие о статистических критериях
Проверить статистическую гипотезу – значит проверить, согласуются ли данные, полученные из выборки с этой гипотезой. При этом проверяемая гипотеза может подтвердиться, а может и не подтвердиться. Проверка статистических гипотез сопряжена с возможностью допустить ошибку.
Ошибка первого рода состоит в том, что будет отвергнута верная гипотеза.
Ошибка второго рода состоит в том, что будет принята ложная гипотеза.
Вероятность совершения ошибки первого рода обозначается 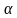 и называется уровнем значимости. Уровень значимости обычно задается близким к нулю (например, 0,05; 0,01; 0,02 и т.д.). Чем меньше уровень значимости , тем меньше вероятность отвергнуть проверяемую гипотезу
и называется уровнем значимости. Уровень значимости обычно задается близким к нулю (например, 0,05; 0,01; 0,02 и т.д.). Чем меньше уровень значимости , тем меньше вероятность отвергнуть проверяемую гипотезу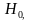 когда она верна, т.е. совершить ошибку первого рода.
когда она верна, т.е. совершить ошибку первого рода.
Вероятность не отклонить ложную гипотезу обозначается 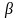 .
.
При проверке нулевой гипотезы могут возникнуть следующие ситуации (табл.):
|
|
верная |
ложная |
|
отклоняется |
Ошибка второго рода |
Решение верное |
|
не отклоняется |
Решение верное |
Ошибка второго рода |
Проверка любой статистической гипотезы осуществляется с помощью статистического критерия.
Статистический критерий – это случайная величина [статистика], которая используется с целью проверки нулевой гипотезы.
В дальнейшем статистический критерий непараметрических гипотез будем обозначать, как правило, буквой .
.
Статистические критерии носят название соответственно распределению: 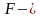 критерий,
критерий, 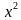 — критерий, t-критерий и т.д.
— критерий, t-критерий и т.д.
Наблюдаемое значение статистического критерия – это значение критерия, которое рассчитано по выборке с определенным законом распределения.
Множество всех возможных значений выбранного статистического критерия разделяется на два непересекающихся подмножества. Первое из этих подмножеств включает в себя значения критерия, при которых нулевая гипотеза отвергается, а второе – те значения критерия, при которых нулевая гипотеза принимается.
Критическая область – это множество возможных значений статистического критерия, при которых нулевая гипотеза отвергается.
Область принятия гипотезы [область допустимых значений] – это множество возможных значений статистического критерия, при которых нулевая гипотеза принимается.
В том случае, если наблюдаемое значение статистического критерия (рассчитанное по выборочной совокупности) принадлежит критической области, нулевую гипотезу отвергают. Если же наблюдаемое значение статистического критерия принадлежит области принятия гипотезы, то нулевая гипотеза принимается.
Критические точки [квантили] – это точки, которые разграничивают критическую область и область принятия гипотезы.
Выделяют одностороннюю и двустороннюю критические области. Дадим определения данных критических областей на примере условного статистического критерия .
Правосторонняя критическая область определяется неравенством 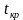 , где
, где 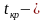 это положительное значение статистического критерия, определяемое по таблице распределения данного критерия.
это положительное значение статистического критерия, определяемое по таблице распределения данного критерия.
Левосторонняя критическая область определяется неравенством , где — это отрицательное значение статистического критерия. определяемое по таблице распределения данного критерия.
Двусторонняя критическая область определяется неравенствами 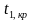 , ,
, , 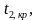 где — отрицательное значение и
где — отрицательное значение и 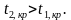
Материал из MachineLearning.
Перейти к: навигация, поиск
Содержание
- 1 Методика проверки статистических гипотез
- 2 Альтернативная методика на основе достигаемого уровня значимости
- 3 Типы критической области
- 4 Ошибки первого и второго рода
- 5 Свойства статистических критериев
- 6 Типы статистических гипотез
- 7 Типы статистических критериев
- 7.1 Критерии согласия
- 7.2 Критерии сдвига
- 7.3 Критерии нормальности
- 7.4 Критерии однородности
- 7.5 Критерии симметричности
- 7.6 Критерии тренда, стационарности и случайности
- 7.7 Критерии выбросов
- 7.8 Критерии дисперсионного анализа
- 7.9 Критерии корреляционного анализа
- 7.10 Критерии регрессионного анализа
- 8 Литература
- 9 Ссылки
Статистическая гипотеза (statistical hypothesys) — это определённое предположение о распределении вероятностей, лежащем в основе наблюдаемой выборки данных.
Проверка статистической гипотезы (testing statistical hypotheses) — это процесс принятия решения о том, противоречит ли рассматриваемая статистическая гипотеза наблюдаемой выборке данных.
Статистический тест или статистический критерий — строгое математическое правило, по которому принимается или отвергается статистическая гипотеза.
Методика проверки статистических гипотез
Пусть задана случайная выборка  — последовательность объектов из множества .
— последовательность объектов из множества .
Предполагается, что на множестве существует некоторая неизвестная вероятностная мера .
Методика состоит в следующем.
- Формулируется нулевая гипотеза о распределении вероятностей на множестве . Гипотеза формулируется исходя из требований прикладной задачи. Чаще всего рассматриваются две гипотезы — основная или нулевая и альтернативная . Иногда альтернатива не формулируется в явном виде; тогда предполагается, что означает «не ». Иногда рассматривается сразу несколько альтернатив. В математической статистике хорошо изучено несколько десятков «наиболее часто встречающихся» типов гипотез, и известны ещё сотни специальных вариантов и разновидностей. Примеры приводятся ниже.
- Задаётся некоторая статистика (функция выборки) , для которой в условиях справедливости гипотезы выводится функция распределения и/или плотность распределения . Вопрос о том, какую статистику надо взять для проверки той или иной гипотезы, часто не имеет однозначного ответа. Есть целый ряд требований, которым должна удовлетворять «хорошая» статистика . Вывод функции распределения при заданных и является строгой математической задачей, которая решается методами теории вероятностей; в справочниках приводятся готовые формулы для ; в статистических пакетах имеются готовые вычислительные процедуры.
- Фиксируется уровень значимости — допустимая для данной задачи вероятность ошибки первого рода, то есть того, что гипотеза на самом деле верна, но будет отвергнута процедурой проверки. Это должно быть достаточно малое число . На практике часто полагают .
- На множестве допустимых значений статистики выделяется критическое множество наименее вероятных значений статистики , такое, что . Вычисление границ критического множества как функции от уровня значимости является строгой математической задачей, которая в большинстве практических случаев имеет готовое простое решение.
- Собственно статистический тест (статистический критерий) заключается в проверке условия:
Итак, статистический критерий определяется статистикой
и критическим множеством , которое зависит от уровня значимости .
Замечание.
Если данные не противоречат нулевой гипотезе, это ещё не значит, что гипотеза верна.
Тому есть две причины.
Альтернативная методика на основе достигаемого уровня значимости
Широкое распространение методики фиксированного уровня значимости было вызвано сложностью вычисления многих статистических критериев в докомпьютерную эпоху. Чаще всего использовались таблицы, в которых для некоторых априорных уровней значимости были выписаны критические значения. В настоящее время результаты проверки гипотез чаще представляют с помощью достигаемого уровня значимости.
Достигаемый уровень значимости (пи-величина, англ. p-value) — это наименьшая величина уровня значимости,
при которой нулевая гипотеза отвергается для данного значения статистики критерия
где
— критическая область критерия.
Другая интерпретация:
достигаемый уровень значимости — это вероятность при справедливости нулевой гипотезы получить значение статистики, такое же или ещё более экстремальное, чем
Если достигаемый уровень значимости достаточно мал (близок к нулю), то нулевая гипотеза отвергается.
В частности, его можно сравнивать с фиксированным уровнем значимости;
тогда альтернативная методика будет эквивалентна классической.
Типы критической области
Обозначим через значение, которое находится из уравнения , где — функция распределения статистики .
Если функция распределения непрерывная строго монотонная,
то есть обратная к ней функция:
-
- .
Значение называется также —квантилем распределения .
На практике, как правило, используются статистики с унимодальной (имеющей форму пика) плотностью распределения.
Критические области (наименее вероятные значения статистики) соответствуют «хвостам» этого распределения.
Поэтому чаще всего возникают критические области одного из трёх типов:
- Левосторонняя критическая область:
-
- определяется интервалом .
- пи-величина:
- определяется интервалом
- Правосторонняя критическая область:
-
- определяется интервалом .
- пи-величина:
- определяется интервалом
- Двусторонняя критическая область:
-
- определяется двумя интервалами
- пи-величина:
- определяется двумя интервалами
Ошибки первого и второго рода
- Ошибка первого рода или «ложная тревога» (англ. type I error, error, false positive) — когда нулевая гипотеза отвергается, хотя на самом деле она верна. Вероятность ошибки первого рода:
- Ошибка второго рода или «пропуск цели» (англ. type II error, error, false negative) — когда нулевая гипотеза принимается, хотя на самом деле она не верна. Вероятность ошибки второго рода:
| Верная гипотеза | |||
|---|---|---|---|
|
|
|
||
| Результат применения критерия |
|
верно принята
|
неверно принята (Ошибка второго рода) |
|
|
неверно отвергнута (Ошибка первого рода) |
верно отвергнута
|
Свойства статистических критериев
Мощность критерия:
— вероятность отклонить гипотезу , если на самом деле верна альтернативная гипотеза .
Мощность критерия является числовой функцией от альтернативной гипотезы .
Несмещённый критерий:
для всех альтернатив
или, что то же самое,
для всех альтернатив .
Состоятельный критерий:
при для всех альтернатив .
Равномерно более мощный критерий.
Говорят, что критерий с мощностью является равномерно более мощным, чем критерий с мощностью , если выполняются два условия:
- ;
- для всех рассматриваемых альтернатив , причём хотя бы для одной альтернативы неравенство строгое.
Типы статистических гипотез
- Простая гипотеза однозначно определяет функцию распределения на множестве . Простые гипотезы имеют узкую область применения, ограниченную критериями согласия (см. ниже). Для простых гипотез известен общий вид равномерно более мощного критерия (Теорема Неймана-Пирсона).
- Сложная гипотеза утверждает принадлежность распределения к некоторому множеству распределений на . Для сложных гипотез вывести равномерно более мощный критерий удаётся лишь в некоторых специальных случаях.
Типы статистических критериев
В зависимости от проверяемой нулевой гипотезы статистические критерии делятся на группы, перечисленные ниже по разделам.
Наряду с нулевой гипотезой, которая принимается или отвергается по результату анализа выборки, статистические критерии могут опираться на дополнительные предположения, которые априори предпологаются выполненными.
- Параметрические критерии предполагают, что выборка порождена распределением из заданного параметрического семейства. В частности, существует много критериев, предназначенных для анализа выборок из нормального распределения. Преимущество этих критериев в том, что они более мощные. Если выборка действительно удовлетворяет дополнительным предположениям, то параметрические критерии дают более точные результаты. Однако если выборка им не удовлетворяет, то вероятность ошибок (как I, так и II рода) может резко возрасти. Прежде чем применять такие критерии, необходимо убедиться, что выборка удовлетворяет дополнительным предположениям. Гипотезы о виде распределения проверяются с помощью критериев согласия.
- Непараметрические критерии не опираются на дополнительные предположения о распределении. В частности, к этому типу критериев относится большинство ранговых критериев.
Критерии согласия
Критерии согласия проверяют, согласуется ли заданная выборка с заданным фиксированным распределением, с заданным параметрическим семейством распределений, или с другой выборкой.
- Критерий Колмогорова-Смирнова
- Критерий хи-квадрат (Пирсона)
- Критерий омега-квадрат (фон Мизеса)
Критерии сдвига
Специальный случай двухвыборочных критериев согласия.
Проверяется гипотеза сдвига, согласно которой распределения двух выборок имеют одинаковую форму и отличаются только сдвигом на константу.
- Критерий Стьюдента
- Критерий Уилкоксона-Манна-Уитни
Критерии нормальности
Критерии нормальности — это выделенный частный случай критериев согласия.
Нормально распределённые величины часто встречаются в прикладных задачах, что обусловлено действием закона больших чисел.
Если про выборки заранее известно, что они подчиняются нормальному распределению, то к ним становится возможно применять более мощные параметрические критерии.
Проверка нормальность часто выполняется на первом шаге анализа выборки, чтобы решить, использовать далее параметрические методы или непараметрические.
В справочнике А. И. Кобзаря приведена сравнительная таблица мощности для 21 критерия нормальности.
- Критерий Шапиро-Уилка
- Критерий асимметрии и эксцесса
Критерии однородности
Критерии однородности предназначены для проверки нулевой гипотезы о том, что
две выборки (или несколько) взяты из одного распределения,
либо их распределения имеют одинаковые значения математического ожидания, дисперсии, или других параметров.
Критерии симметричности
Критерии симметричности позволяют проверить симметричность распределения.
- Одновыборочный критерий Уилкоксона и его модификации: критерий Антилла-Кёрстинга-Цуккини, критерий Бхаттачария-Гаствирса-Райта
- Критерий знаков
- Коэффициент асимметрии
Критерии тренда, стационарности и случайности
Критерии тренда и случайности предназначены для проверки нулевой гипотезы об
отсутствии зависимости между выборочными данными и номером наблюдения в выборке.
Они часто применяются в анализе временных рядов, в частности, при анализе регрессионных остатков.
Критерии выбросов
Критерии дисперсионного анализа
Критерии корреляционного анализа
Критерии регрессионного анализа
Литература
- Вероятность и математическая статистика: Энциклопедия / Под ред. Ю.В.Прохорова. — М.: Большая российская энциклопедия, 2003. — 912 с.
- Кобзарь А. И. Прикладная математическая статистика. Справочник для инженеров и научных работников. — М.: Физматлит, 2006. — 816 с.
Ссылки
- Statistical hypothesis testing — статья в англоязычной Википедии.