Всем привет!
Сегодня мы детально обсудим очень важный класс моделей машинного обучения – линейных. Ключевое отличие нашей подачи материала от аналогичной в курсах эконометрики и статистики – это акцент на практическом применении линейных моделей в реальных задачах (хотя и математики тоже будет немало).
Пример такой задачи – это соревнование Kaggle Inclass по идентификации пользователя в Интернете по его последовательности переходов по сайтам.
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.
Все материалы доступны на GitHub.
А вот видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017). В ней, в частности, рассмотрены два бенчмарка соревнования, полученные с помощью логистической регрессии.
План этой статьи:
- Линейная регрессия
- Метод наименьших квадратов
- Метод максимального правдоподобия
- Разложение ошибки на смещение и разброс (Bias-variance decomposition)
- Регуляризация линейной регрессии
- Логистическая регрессия
- Линейный классификатор
- Логистическая регрессия как линейный классификатор
- Принцип максимального правдоподобия и логистическая регрессия
- L2-регуляризация логистической функции потерь
- Наглядный пример регуляризации логистической регрессии
- Где логистическая регрессия хороша и где не очень
-Анализ отзывов IMDB к фильмам
-XOR-проблема - Кривые валидации и обучения
- Плюсы и минусы линейных моделей в задачах машинного обучения
- Домашнее задание №4
- Полезные ресурсы
1. Линейная регрессия
Метод наименьших квадратов
Рассказ про линейные модели мы начнем с линейной регрессии. В первую очередь, необходимо задать модель зависимости объясняемой переменной  от объясняющих ее факторов, функция зависимости будет линейной:
от объясняющих ее факторов, функция зависимости будет линейной:  . Если мы добавим фиктивную размерность
. Если мы добавим фиктивную размерность  для каждого наблюдения, тогда линейную форму можно переписать чуть более компактно, записав свободный член
для каждого наблюдения, тогда линейную форму можно переписать чуть более компактно, записав свободный член  под сумму:
под сумму:  . Если рассматривать матрицу наблюдения-признаки, у которой в строках находятся примеры из набора данных, то нам необходимо добавить единичную колонку слева. Зададим модель следующим образом:
. Если рассматривать матрицу наблюдения-признаки, у которой в строках находятся примеры из набора данных, то нам необходимо добавить единичную колонку слева. Зададим модель следующим образом:

где
Можем выписать выражение для каждого конкретного наблюдения

Также на модель накладываются следующие ограничения (иначе это будет какая то другая регрессия, но точно не линейная):
Оценка  весов
весов  называется линейной, если
называется линейной, если

где  зависит только от наблюдаемых данных
зависит только от наблюдаемых данных  и почти наверняка нелинейно. Так как решением задачи поиска оптимальных весов будет именно линейная оценка, то и модель называется линейной регрессией. Введем еще одно определение. Оценка называется несмещенной тогда, когда матожидание оценки равно реальному, но неизвестному значению оцениваемого параметра:
и почти наверняка нелинейно. Так как решением задачи поиска оптимальных весов будет именно линейная оценка, то и модель называется линейной регрессией. Введем еще одно определение. Оценка называется несмещенной тогда, когда матожидание оценки равно реальному, но неизвестному значению оцениваемого параметра:
![$\large \mathbb{E}\left[\hat{w}_i\right] = w_i$](https://habrastorage.org/getpro/habr/formulas/603/883/07e/60388307e5ba9158e21e82d1dc39b5d5.svg)
Один из способов вычислить значения параметров модели является метод наименьших квадратов (МНК), который минимизирует среднеквадратичную ошибку между реальным значением зависимой переменной и прогнозом, выданным моделью:

Для решения данной оптимизационной задачи необходимо вычислить производные по параметрам модели, приравнять их к нулю и решить полученные уравнения относительно  (матричное дифференцирование неподготовленному читателю может показаться затруднительным, попробуйте расписать все через суммы, чтобы убедиться в ответе):
(матричное дифференцирование неподготовленному читателю может показаться затруднительным, попробуйте расписать все через суммы, чтобы убедиться в ответе):
Шпаргалка по матричным производным



Итак, имея в виду все определения и условия описанные выше, мы можем утверждать, опираясь на теорему Маркова-Гаусса, что оценка МНК является лучшей оценкой параметров модели, среди всех линейных и несмещенных оценок, то есть обладающей наименьшей дисперсией.
Метод максимального правдоподобия
У читателя вполне резонно могли возникнуть вопросы: например, почему мы минимизируем среднеквадратичную ошибку, а не что-то другое. Ведь можно минимизировать среднее абсолютное значение невязки или еще что-то. Единственное, что произойдёт в случае изменения минимизируемого значения, так это то, что мы выйдем из условий теоремы Маркова-Гаусса, и наши оценки перестанут быть лучшими среди линейных и несмещенных.
Давайте перед тем как продолжить, сделаем лирическое отступление, чтобы проиллюстрировать метод максимального правдоподобия на простом примере.
Как-то после школы я заметил, что все помнят формулу этилового спирта. Тогда я решил провести эксперимент: помнят ли люди более простую формулу метилового спирта:  . Мы опросили 400 человек и оказалось, что формулу помнят всего 117 человек. Разумно предположить, что вероятность того, что следующий опрошенный знает формулу метилового спирта –
. Мы опросили 400 человек и оказалось, что формулу помнят всего 117 человек. Разумно предположить, что вероятность того, что следующий опрошенный знает формулу метилового спирта –  . Покажем, что такая интуитивно понятная оценка не просто хороша, а еще и является оценкой максимального правдоподобия.
. Покажем, что такая интуитивно понятная оценка не просто хороша, а еще и является оценкой максимального правдоподобия.
Разберемся, откуда берется эта оценка, а для этого вспомним определение распределения Бернулли: случайная величина имеет распределение Бернулли, если она принимает всего два значения ( и
и  с вероятностями
с вероятностями  и
и  соответственно) и имеет следующую функцию распределения вероятности:
соответственно) и имеет следующую функцию распределения вероятности:

Похоже, это распределение – то, что нам нужно, а параметр распределения и есть та оценка вероятности того, что человек знает формулу метилового спирта. Мы проделали  независимых экспериментов, обозначим их исходы как
независимых экспериментов, обозначим их исходы как  . Запишем правдоподобие наших данных (наблюдений), то есть вероятность наблюдать 117 реализаций случайной величины
. Запишем правдоподобие наших данных (наблюдений), то есть вероятность наблюдать 117 реализаций случайной величины  и 283 реализации
и 283 реализации  :
:

Далее будем максимизировать это выражение по , и чаще всего это делают не с правдоподобием  , а с его логарифмом (применение монотонного преобразования не изменит решение, но упростит вычисления):
, а с его логарифмом (применение монотонного преобразования не изменит решение, но упростит вычисления):


Теперь мы хотим найти такое значение , которое максимизирует правдоподобие, для этого мы возьмем производную по , приравняем к нулю и решим полученное уравнение:


Получается, что наша интуитивная оценка – это и есть оценка максимального правдоподобия. Применим теперь те же рассуждения для задачи линейной регрессии и попробуем выяснить, что лежит за среднеквадратичной ошибкой. Для этого нам придется посмотреть на линейную регрессию с вероятностной точки зрения. Модель, естественно, остается такой же:
но будем теперь считать, что случайные ошибки берутся из центрированного нормального распределения:

Перепишем модель в новом свете:

Так как примеры берутся независимо (ошибки не скоррелированы – одно из условий теоремы Маркова-Гаусса), то полное правдоподобие данных будет выглядеть как произведение функций плотности  . Рассмотрим логарифм правдоподобия, что позволит нам перейти от произведения к сумме:
. Рассмотрим логарифм правдоподобия, что позволит нам перейти от произведения к сумме:

Мы хотим найти гипотезу максимального правдоподобия, т.е. нам нужно максимизировать выражение  , а это то же самое, что и максимизация его логарифма. Обратите внимание, что при максимизации функции по какому-то параметру можно выкинуть все члены, не зависящие от этого параметра:
, а это то же самое, что и максимизация его логарифма. Обратите внимание, что при максимизации функции по какому-то параметру можно выкинуть все члены, не зависящие от этого параметра:

Таким образом, мы увидели, что максимизация правдоподобия данных – это то же самое, что и минимизация среднеквадратичной ошибки (при справедливости указанных выше предположений). Получается, что именно такая функция стоимости является следствием того, что ошибка распределена нормально, а не как-то по-другому.
Разложение ошибки на смещение и разброс (Bias-variance decomposition)
Поговорим немного о свойствах ошибки прогноза линейной регрессии (в принципе эти рассуждения верны для всех алгоритмов машинного обучения). В свете предыдущего пункта мы выяснили, что:
Тогда ошибка в точке  раскладывается следующим образом:
раскладывается следующим образом:
![$\large \begin{array}{rcl} \text{Err}\left(\vec{x}\right) &=& \mathbb{E}\left[\left(y - \hat{f}\left(\vec{x}\right)\right)^2\right] \\ &=& \mathbb{E}\left[y^2\right] + \mathbb{E}\left[\left(\hat{f}\left(\vec{x}\right)\right)^2\right] - 2\mathbb{E}\left[y\hat{f}\left(\vec{x}\right)\right] \\ &=& \mathbb{E}\left[y^2\right] + \mathbb{E}\left[\hat{f}^2\right] - 2\mathbb{E}\left[y\hat{f}\right] \\ \end{array}$](https://habrastorage.org/getpro/habr/formulas/711/6be/458/7116be45859e8d6a0de7b6786aa07401.svg)
Для наглядности опустим обозначение аргумента функций. Рассмотрим каждый член в отдельности, первые два расписываются легко по формуле ![$\text{Var}\left(z\right) = \mathbb{E}\left[z^2\right] - \mathbb{E}\left[z\right]^2$](https://habrastorage.org/getpro/habr/formulas/fcd/2c9/e48/fcd2c9e48eddd600743a2bf7b08e3679.svg) :
:
![$\large \begin{array}{rcl} \mathbb{E}\left[y^2\right] &=& \text{Var}\left(y\right) + \mathbb{E}\left[y\right]^2 = \sigma^2 + f^2\\ \mathbb{E}\left[\hat{f}^2\right] &=& \text{Var}\left(\hat{f}\right) + \mathbb{E}\left[\hat{f}\right]^2 \\ \end{array}$](https://habrastorage.org/getpro/habr/formulas/b2d/193/0c7/b2d1930c72caf4e3f84184579c145226.svg)
Пояснения:
![$\large \begin{array}{rcl} \text{Var}\left(y\right) &=& \mathbb{E}\left[\left(y - \mathbb{E}\left[y\right]\right)^2\right] \\ &=& \mathbb{E}\left[\left(y - f\right)^2\right] \\ &=& \mathbb{E}\left[\left(f + \epsilon - f\right)^2\right] \\ &=& \mathbb{E}\left[\epsilon^2\right] = \sigma^2 \end{array}$](https://habrastorage.org/getpro/habr/formulas/e94/34d/b2d/e9434db2dd384a8e7e9add9c41d4b9df.svg)
![$\large \mathbb{E}[y] = \mathbb{E}[f + \epsilon] = \mathbb{E}[f] + \mathbb{E}[\epsilon] = f$](https://habrastorage.org/getpro/habr/formulas/14f/db4/0f4/14fdb40f4d963c43963f992e8c5de74f.svg)
И теперь последний член суммы. Мы помним, что ошибка и целевая переменная независимы друг от друга:
![$\large \begin{array}{rcl} \mathbb{E}\left[y\hat{f}\right] &=& \mathbb{E}\left[\left(f + \epsilon\right)\hat{f}\right] \\ &=& \mathbb{E}\left[f\hat{f}\right] + \mathbb{E}\left[\epsilon\hat{f}\right] \\ &=& f\mathbb{E}\left[\hat{f}\right] + \mathbb{E}\left[\epsilon\right] \mathbb{E}\left[\hat{f}\right] = f\mathbb{E}\left[\hat{f}\right] \end{array}$](https://habrastorage.org/getpro/habr/formulas/86c/e8f/e19/86ce8fe19fb9eb4742a609eaa59d8535.svg)
Наконец, собираем все вместе:
![$\large \begin{array}{rcl} \text{Err}\left(\vec{x}\right) &=& \mathbb{E}\left[\left(y - \hat{f}\left(\vec{x}\right)\right)^2\right] \\ &=& \sigma^2 + f^2 + \text{Var}\left(\hat{f}\right) + \mathbb{E}\left[\hat{f}\right]^2 - 2f\mathbb{E}\left[\hat{f}\right] \\ &=& \left(f - \mathbb{E}\left[\hat{f}\right]\right)^2 + \text{Var}\left(\hat{f}\right) + \sigma^2 \\ &=& \text{Bias}\left(\hat{f}\right)^2 + \text{Var}\left(\hat{f}\right) + \sigma^2 \end{array}$](https://habrastorage.org/getpro/habr/formulas/b1e/53a/017/b1e53a017320aaaeefc61ef8abb6db0e.svg)
Итак, мы достигли цели всех вычислений, описанных выше, последняя формула говорит нам, что ошибка прогноза любой модели вида  складывается из:
складывается из:
Если с последней мы ничего сделать не можем, то на первые два слагаемых мы можем как-то влиять. В идеале, конечно же, хотелось бы свести на нет оба этих слагаемых (левый верхний квадрат рисунка), но на практике часто приходится балансировать между смещенными и нестабильными оценками (высокая дисперсия).
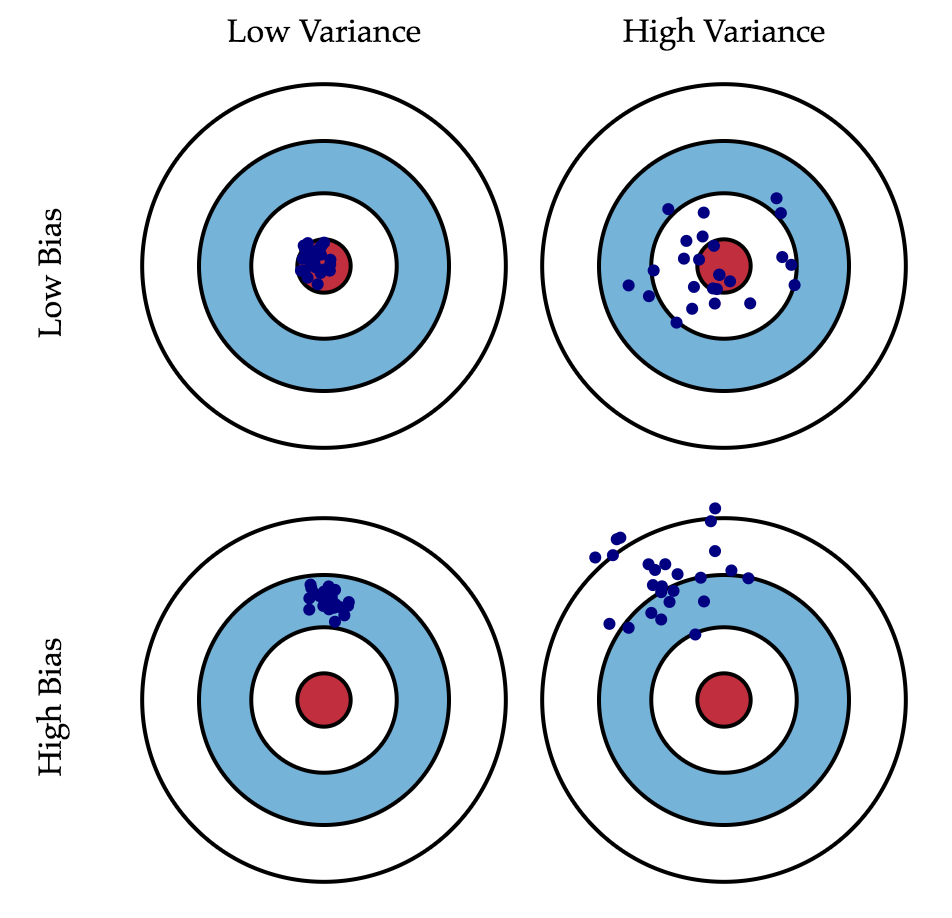
Как правило, при увеличении сложности модели (например, при увеличении количества свободных параметров) увеличивается дисперсия (разброс) оценки, но уменьшается смещение. Из-за того что тренировочный набор данных полностью запоминается вместо обобщения, небольшие изменения приводят к неожиданным результатам (переобучение). Если же модель слабая, то она не в состоянии выучить закономерность, в результате выучивается что-то другое, смещенное относительно правильного решения.
Теорема Маркова-Гаусса как раз утверждает, что МНК-оценка параметров линейной модели является самой лучшей в классе несмещенных линейных оценок, то есть с наименьшей дисперсией. Это значит, что если существует какая-либо другая несмещенная модель  тоже из класса линейных моделей, то мы можем быть уверены, что
тоже из класса линейных моделей, то мы можем быть уверены, что  .
.
Регуляризация линейной регрессии
Иногда бывают ситуации, когда мы намеренно увеличиваем смещенность модели ради ее стабильности, т.е. ради уменьшения дисперсии модели  . Одним из условий теоремы Маркова-Гаусса является полный столбцовый ранг матрицы . В противном случае решение МНК
. Одним из условий теоремы Маркова-Гаусса является полный столбцовый ранг матрицы . В противном случае решение МНК  не существует, т.к. не будет существовать обратная матрица
не существует, т.к. не будет существовать обратная матрица  Другими словами, матрица
Другими словами, матрица  будет сингулярна, или вырожденна. Такая задача называется некорректно поставленной. Задачу нужно скорректировать, а именно, сделать матрицу невырожденной, или регулярной (именно поэтому этот процесс называется регуляризацией). Чаще в данных мы можем наблюдать так называемую мультиколлинеарность — когда два или несколько признаков сильно коррелированы, в матрице это проявляется в виде «почти» линейной зависимости столбцов. Например, в задаче прогнозирования цены квартиры по ее параметрам «почти» линейная зависимость будет у признаков «площадь с учетом балкона» и «площадь без учета балкона». Формально для таких данных матрица будет обратима, но из-за мультиколлинеарности у матрицы некоторые собственные значения будут близки к нулю, а в обратной матрице
будет сингулярна, или вырожденна. Такая задача называется некорректно поставленной. Задачу нужно скорректировать, а именно, сделать матрицу невырожденной, или регулярной (именно поэтому этот процесс называется регуляризацией). Чаще в данных мы можем наблюдать так называемую мультиколлинеарность — когда два или несколько признаков сильно коррелированы, в матрице это проявляется в виде «почти» линейной зависимости столбцов. Например, в задаче прогнозирования цены квартиры по ее параметрам «почти» линейная зависимость будет у признаков «площадь с учетом балкона» и «площадь без учета балкона». Формально для таких данных матрица будет обратима, но из-за мультиколлинеарности у матрицы некоторые собственные значения будут близки к нулю, а в обратной матрице  появятся экстремально большие собственные значения, т.к. собственные значения обратной матрицы – это
появятся экстремально большие собственные значения, т.к. собственные значения обратной матрицы – это  . Итогом такого шатания собственных значений станет нестабильная оценка параметров модели, т.е. добавление нового наблюдения в набор тренировочных данных приведёт к совершенно другому решению. Иллюстрации роста коэффициентов вы найдете в одном из наших прошлых постов. Одним из способов регуляризации является регуляризация Тихонова, которая в общем виде выглядит как добавление нового члена к среднеквадратичной ошибке:
. Итогом такого шатания собственных значений станет нестабильная оценка параметров модели, т.е. добавление нового наблюдения в набор тренировочных данных приведёт к совершенно другому решению. Иллюстрации роста коэффициентов вы найдете в одном из наших прошлых постов. Одним из способов регуляризации является регуляризация Тихонова, которая в общем виде выглядит как добавление нового члена к среднеквадратичной ошибке:

Часто матрица Тихонова выражается как произведение некоторого числа на единичную матрицу:  . В этом случае задача минимизации среднеквадратичной ошибки становится задачей с ограничением на
. В этом случае задача минимизации среднеквадратичной ошибки становится задачей с ограничением на  норму. Если продифференцировать новую функцию стоимости по параметрам модели, приравнять полученную функцию к нулю и выразить , то мы получим точное решение задачи.
норму. Если продифференцировать новую функцию стоимости по параметрам модели, приравнять полученную функцию к нулю и выразить , то мы получим точное решение задачи.

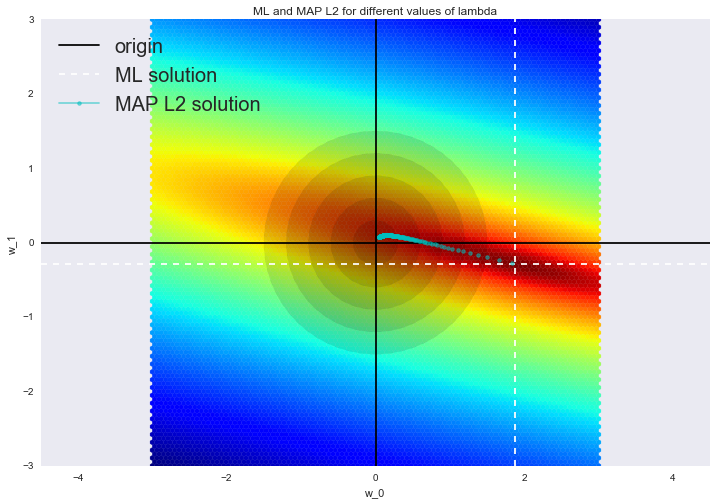
Такая регрессия называется гребневой регрессией (ridge regression). А гребнем является как раз диагональная матрица, которую мы прибавляем к матрице , в результате получается гарантированно регулярная матрица.

Такое решение уменьшает дисперсию, но становится смещенным, т.к. минимизируется также и норма вектора параметров, что заставляет решение сдвигаться в сторону нуля. На рисунке ниже на пересечении белых пунктирных линий находится МНК-решение. Голубыми точками обозначены различные решения гребневой регрессии. Видно, что при увеличении параметра регуляризации  решение сдвигается в сторону нуля.
решение сдвигается в сторону нуля.
Советуем обратиться в наш прошлый пост за примером того, как регуляризация справляется с проблемой мультиколлинеарности, а также чтобы освежить в памяти еще несколько интерпретаций регуляризации.
2. Логистическая регрессия
Линейный классификатор
Основная идея линейного классификатора заключается в том, что признаковое пространство может быть разделено гиперплоскостью на два полупространства, в каждом из которых прогнозируется одно из двух значений целевого класса.
Если это можно сделать без ошибок, то обучающая выборка называется линейно разделимой.
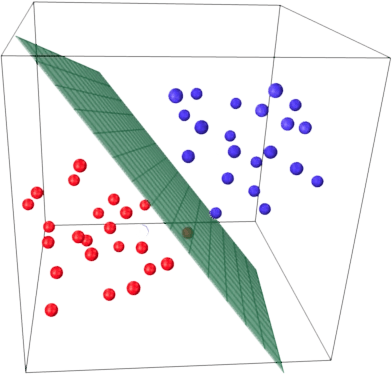
Мы уже знакомы с линейной регрессией и методом наименьших квадратов. Рассмотрим задачу бинарной классификации, причем метки целевого класса обозначим «+1» (положительные примеры) и «-1» (отрицательные примеры).
Один из самых простых линейных классификаторов получается на основе регрессии вот таким образом:

где
Логистическая регрессия как линейный классификатор
Логистическая регрессия является частным случаем линейного классификатора, но она обладает хорошим «умением» – прогнозировать вероятность  отнесения примера
отнесения примера  к классу «+»:
к классу «+»:

Прогнозирование не просто ответа («+1» или «-1»), а именно вероятности отнесения к классу «+1» во многих задачах является очень важным бизнес-требованием. Например, в задаче кредитного скоринга, где традиционно применяется логистическая регрессия, часто прогнозируют вероятность невозврата кредита (). Клиентов, обратившихся за кредитом, сортируют по этой предсказанной вероятности (по убыванию), и получается скоркарта — по сути, рейтинг клиентов от плохих к хорошим. Ниже приведен игрушечный пример такой скоркарты.
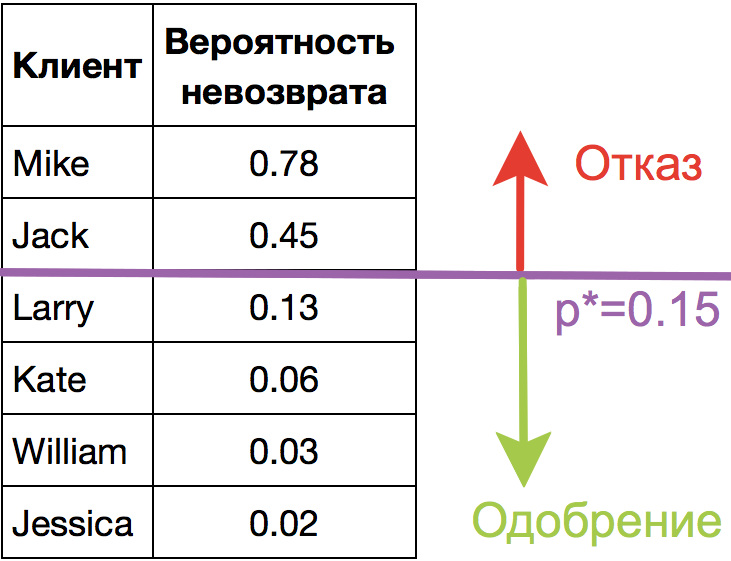
Банк выбирает для себя порог  предсказанной вероятности невозврата кредита (на картинке –
предсказанной вероятности невозврата кредита (на картинке –  ) и начиная с этого значения уже не выдает кредит. Более того, можно умножить предсказанную вероятность на выданную сумму и получить матожидание потерь с клиента, что тоже будет хорошей бизнес-метрикой (Далее в комментариях специалисты по скорингу могут поправить, но главная суть примерно такая).
) и начиная с этого значения уже не выдает кредит. Более того, можно умножить предсказанную вероятность на выданную сумму и получить матожидание потерь с клиента, что тоже будет хорошей бизнес-метрикой (Далее в комментариях специалисты по скорингу могут поправить, но главная суть примерно такая).
Итак, мы хотим прогнозировать вероятность ![$p_+ \in [0,1]$](https://habrastorage.org/getpro/habr/formulas/9be/30b/a3f/9be30ba3feda478246a6a5bc34ef6f3c.svg) , а пока умеем строить линейный прогноз с помощью МНК:
, а пока умеем строить линейный прогноз с помощью МНК:  . Каким образом преобразовать полученное значение в вероятность, пределы которой – [0, 1]? Очевидно, для этого нужна некоторая функция
. Каким образом преобразовать полученное значение в вероятность, пределы которой – [0, 1]? Очевидно, для этого нужна некоторая функция ![$f: \mathbb{R} \rightarrow [0,1].$](https://habrastorage.org/getpro/habr/formulas/375/c58/fb1/375c58fb1e953dff289609c8fc90ac8d.svg) В модели логистической регрессии для этого берется конкретная функция:
В модели логистической регрессии для этого берется конкретная функция:  . И сейчас разберемся, каковы для этого предпосылки.
. И сейчас разберемся, каковы для этого предпосылки.
Обозначим  вероятностью происходящего события . Тогда отношение вероятностей
вероятностью происходящего события . Тогда отношение вероятностей  определяется из
определяется из  , а это — отношение вероятностей того, произойдет ли событие или не произойдет. Очевидно, что вероятность и отношение шансов содержат одинаковую информацию. Но в то время как находится в пределах от 0 до 1, находится в пределах от 0 до
, а это — отношение вероятностей того, произойдет ли событие или не произойдет. Очевидно, что вероятность и отношение шансов содержат одинаковую информацию. Но в то время как находится в пределах от 0 до 1, находится в пределах от 0 до  .
.
Если вычислить логарифм (то есть называется логарифм шансов, или логарифм отношения вероятностей), то легко заметить, что  . Его-то мы и будем прогнозировать с помощью МНК.
. Его-то мы и будем прогнозировать с помощью МНК.
Посмотрим, как логистическая регрессия будет делать прогноз  (пока считаем, что веса мы как-то получили (т.е. обучили модель), далее разберемся, как именно).
(пока считаем, что веса мы как-то получили (т.е. обучили модель), далее разберемся, как именно).
-
Шаг 1. Вычислить значение
 . (уравнение задает гиперплоскость, разделяющую примеры на 2 класса);
. (уравнение задает гиперплоскость, разделяющую примеры на 2 класса); -
Шаг 2. Вычислить логарифм отношения шансов:
. -
Шаг 3. Имея прогноз шансов на отнесение к классу «+» –
, вычислить с помощью простой зависимости:
 . (уравнение
. (уравнение  задает гиперплоскость, разделяющую примеры на 2 класса);
задает гиперплоскость, разделяющую примеры на 2 класса); .
. , вычислить
, вычислить 
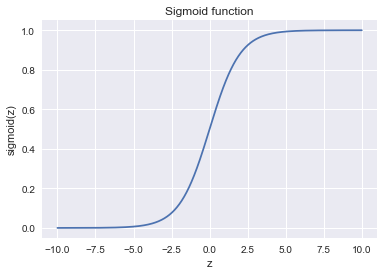
В правой части мы получили как раз сигмоид-функцию.
Итак, логистическая регрессия прогнозирует вероятность отнесения примера к классу «+» (при условии, что мы знаем его признаки и веса модели) как сигмоид-преобразование линейной комбинации вектора весов модели и вектора признаков примера:

Следующий вопрос: как модель обучается? Тут мы опять обращаемся к принципу максимального правдоподобия.
Принцип максимального правдоподобия и логистическая регрессия
Теперь посмотрим, как из принципа максимального правдоподобия получается оптимизационная задача, которую решает логистическая регрессия, а именно, – минимизация логистической функции потерь.
Только что мы увидели, что логистическая регрессия моделирует вероятность отнесения примера к классу «+» как

Тогда для класса «-» аналогичная вероятность:

Оба этих выражения можно ловко объединить в одно (следите за моими руками – не обманывают ли вас):

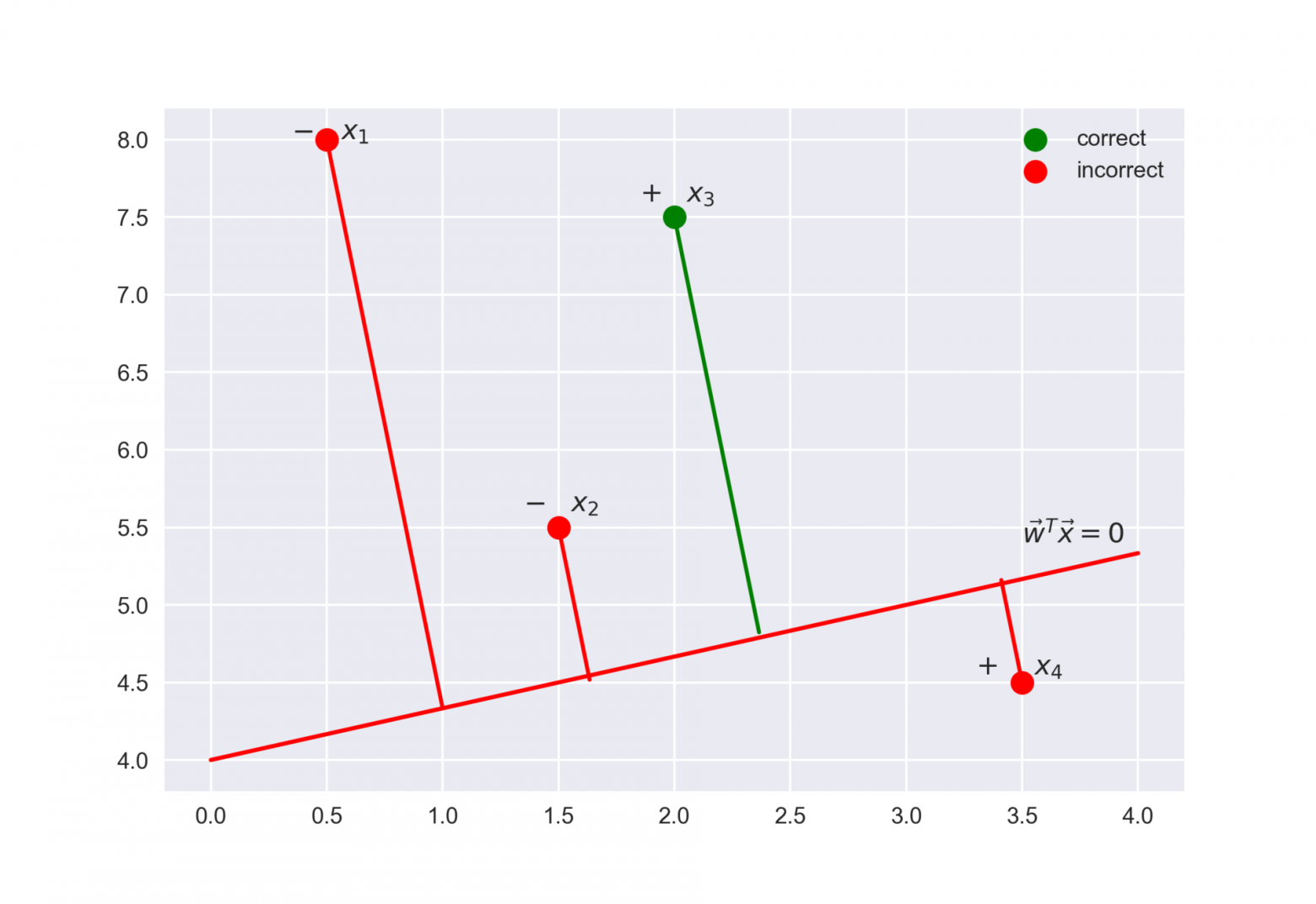
Выражение  называется отступом (margin) классификации на объекте (не путать с зазором (тоже margin), про который чаще всего говорят в контексте SVM). Если он неотрицателен, модель не ошибается на объекте , если же отрицателен – значит, класс для спрогнозирован неправильно.
называется отступом (margin) классификации на объекте (не путать с зазором (тоже margin), про который чаще всего говорят в контексте SVM). Если он неотрицателен, модель не ошибается на объекте , если же отрицателен – значит, класс для спрогнозирован неправильно.
Заметим, что отступ определен для объектов именно обучающей выборки, для которых известны реальные метки целевого класса  .
.
Чтобы понять, почему это мы сделали такие выводы, обратимся к геометрической интерпретации линейного классификатора. Подробно про это можно почитать в материалах Евгения Соколова.
Рекомендую решить почти классическую задачу из начального курса линейной алгебры: найти расстояние от точки с радиус-вектором  до плоскости, которая задается уравнением
до плоскости, которая задается уравнением 
Ответ

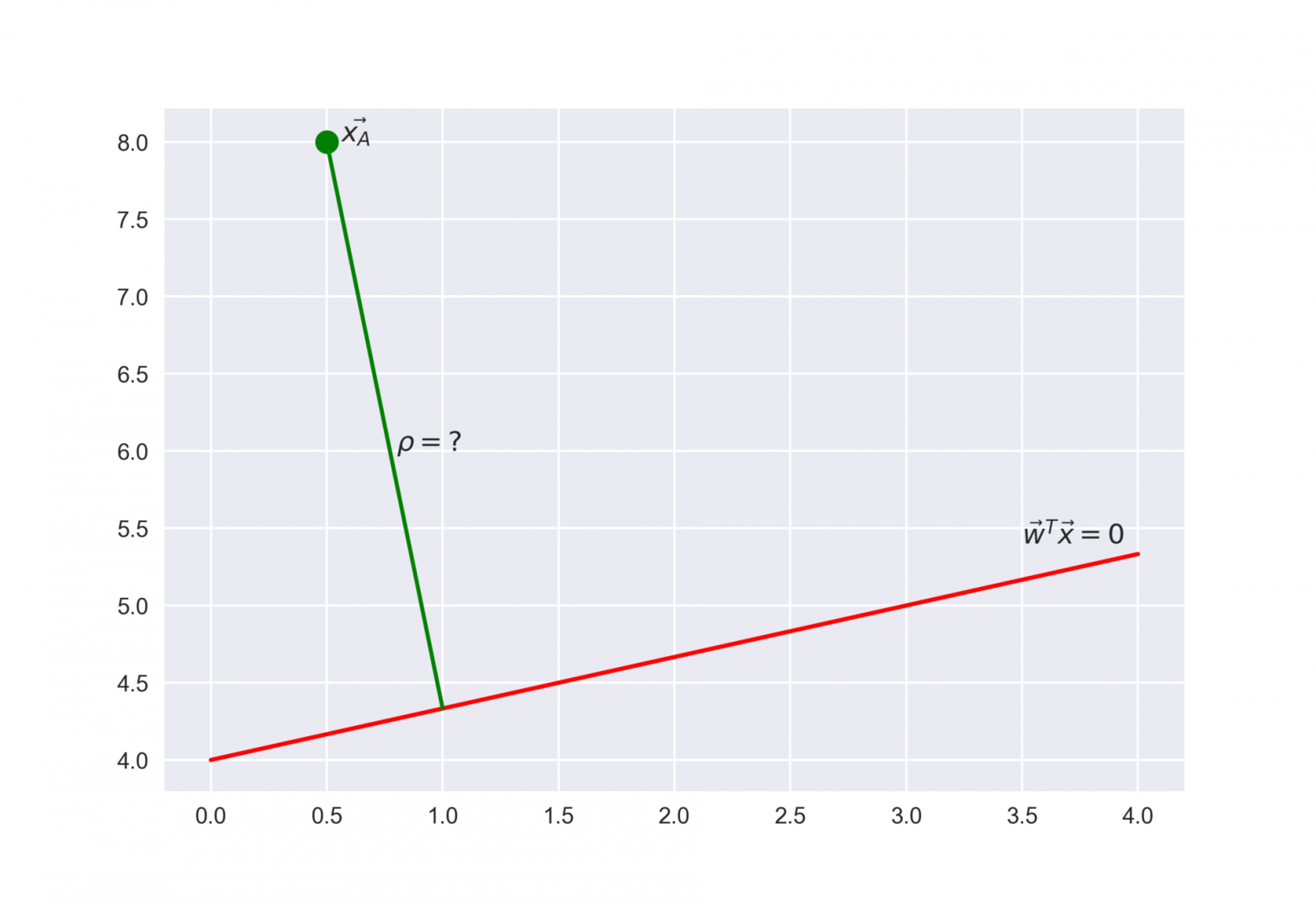
Когда получим (или посмотрим) ответ, то поймем, что чем больше по модулю выражение  , тем дальше точка находится от плоскости
, тем дальше точка находится от плоскости
Значит, выражение – это своего рода «уверенность» модели в классификации объекта :
- если отступ большой (по модулю) и положительный, это значит, что метка класса поставлена правильно, а объект находится далеко от разделяющей гиперплоскости (такой объект классифицируется уверенно). На рисунке – .
- если отступ большой (по модулю) и отрицательный, значит метка класса поставлена неправильно, а объект находится далеко от разделяющей гиперплоскости (скорее всего такой объект – аномалия, например, его метка в обучающей выборке поставлена неправильно). На рисунке – .
- если отступ малый (по модулю), то объект находится близко к разделяющей гиперплоскости, а знак отступа определяет, правильно ли объект классифицирован. На рисунке – и .
 .
. .
.
Теперь распишем правдоподобие выборки, а именно, вероятность наблюдать данный вектор  у выборки . Делаем сильное предположение: объекты приходят независимо, из одного распределения (i.i.d.). Тогда
у выборки . Делаем сильное предположение: объекты приходят независимо, из одного распределения (i.i.d.). Тогда

где  – длина выборки (число строк).
– длина выборки (число строк).
Как водится, возьмем логарифм данного выражения (сумму оптимизировать намного проще, чем произведение):

То есть в даном случае принцип максимизации правдоподобия приводит к минимизации выражения

Это логистическая функция потерь, просуммированная по всем объектам обучающей выборки.
Посмотрим на новую фунцию как на функцию от отступа:  . Нарисуем ее график, а также график 1/0 функциий потерь (zero-one loss), которая просто штрафует модель на 1 за ошибку на каждом объекте (отступ отрицательный):
. Нарисуем ее график, а также график 1/0 функциий потерь (zero-one loss), которая просто штрафует модель на 1 за ошибку на каждом объекте (отступ отрицательный): ![$L_{1/0}(M) = [M < 0]$](https://habrastorage.org/getpro/habr/formulas/279/e2d/d4f/279e2dd4f16fba5aaba3bb74abc2ca6a.svg) .
.
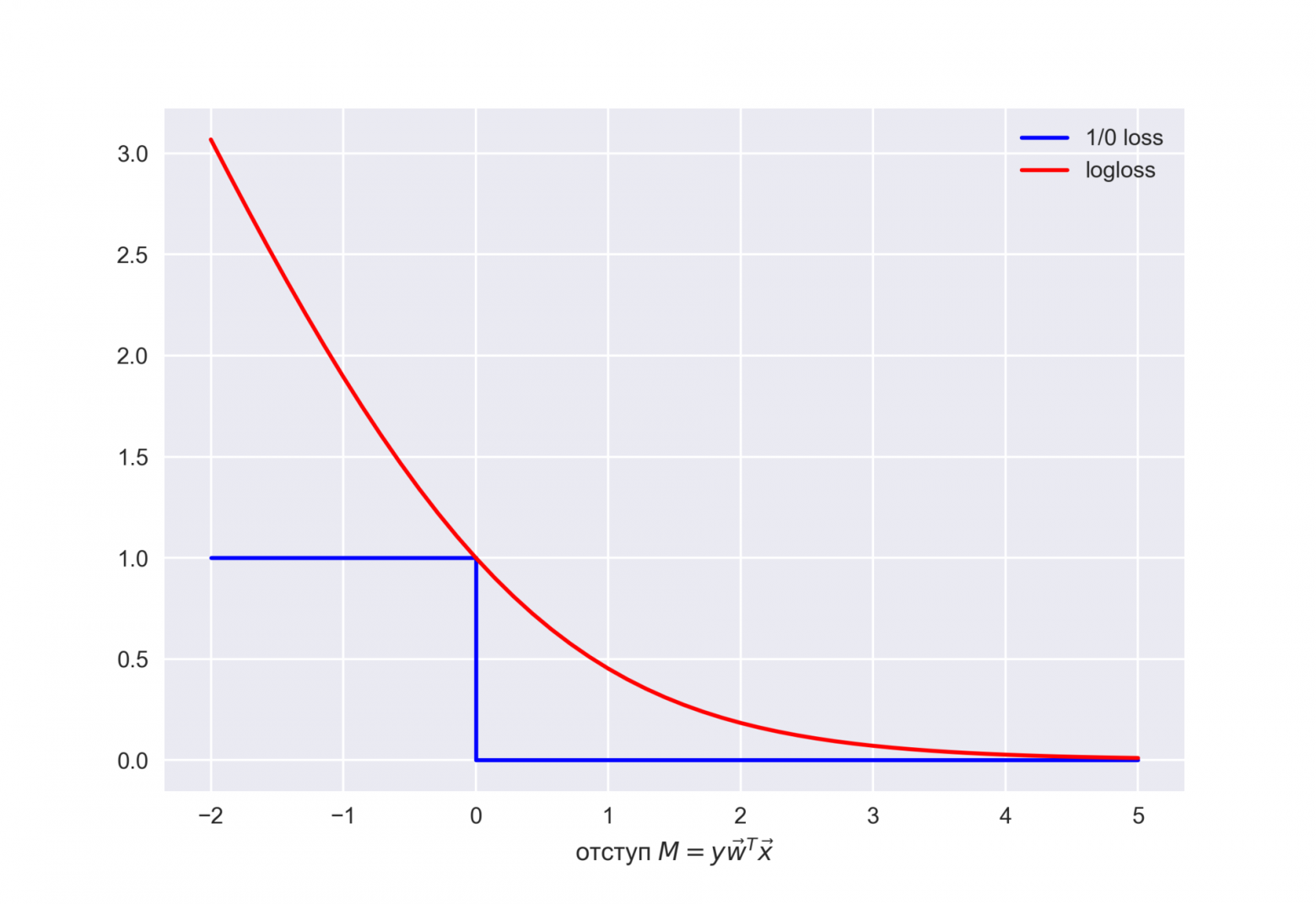
Картинка отражает общую идею, что в задаче классификации, не умея напрямую минимизировать число ошибок (по крайней мере, градиентными методами это не сделать – производная 1/0 функциий потерь в нуле обращается в бесконечность), мы минимизируем некоторую ее верхнюю оценку. В данном случае это логистическая функция потерь (где логарифм двоичный, но это не принципиально), и справедливо
![$\large \begin{array}{rcl} \mathcal{L_{1/0}} (X, \vec{y}, \vec{w}) &=& \sum_{i=1}^{\ell} [M(\vec{x_i}) < 0] \\ &\leq& \sum_{i=1}^{\ell} \log (1 + \exp^{-y_i\vec{w}^T\vec{x_i}}) \\ &=& \mathcal{L_{log}} (X, \vec{y}, \vec{w}) \end{array}$](https://habrastorage.org/getpro/habr/formulas/6f7/6f6/465/6f76f64653b4699ea79de2f9844a8d76.svg)
где  – попросту число ошибок логистической регрессии с весами на выборке
– попросту число ошибок логистической регрессии с весами на выборке  .
.
То есть уменьшая верхнюю оценку  на число ошибок классификации, мы таким образом надеемся уменьшить и само число ошибок.
на число ошибок классификации, мы таким образом надеемся уменьшить и само число ошибок.
-регуляризация логистических потерь
L2-регуляризация логистической регрессии устроена почти так же, как и в случае с гребневой (Ridge регрессией). Вместо функционала  минимизируется следующий:
минимизируется следующий:

В случае логистической регрессии принято введение обратного коэффициента регуляризации  . И тогда решением задачи будет
. И тогда решением задачи будет

Далее рассмотрим пример, позволяющий интуитивно понять один из смыслов регуляризации.
3. Наглядный пример регуляризации логистической регрессии
В 1 статье уже приводился пример того, как полиномиальные признаки позволяют линейным моделям строить нелинейные разделяющие поверхности. Покажем это в картинках.
Посмотрим, как регуляризация влияет на качество классификации на наборе данных по тестированию микрочипов из курса Andrew Ng по машинному обучению.
Будем использовать логистическую регрессию с полиномиальными признаками и варьировать параметр регуляризации C.
Сначала посмотрим, как регуляризация влияет на разделяющую границу классификатора, интуитивно распознаем переобучение и недообучение.
Потом численно установим близкий к оптимальному параметр регуляризации с помощью кросс-валидации (cross-validation) и перебора по сетке (GridSearch).
Подключение библиотек
from __future__ import division, print_function
# отключим всякие предупреждения Anaconda
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
from matplotlib import pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LogisticRegression, LogisticRegressionCV
from sklearn.model_selection import cross_val_score, StratifiedKFold
from sklearn.model_selection import GridSearchCVЗагружаем данные с помощью метода read_csv библиотеки pandas. В этом наборе данных для 118 микрочипов (объекты) указаны результаты двух тестов по контролю качества (два числовых признака) и сказано, пустили ли микрочип в производство. Признаки уже центрированы, то есть из всех значений вычтены средние по столбцам. Таким образом, «среднему» микрочипу соответствуют нулевые значения результатов тестов.
Загрузка данных
data = pd.read_csv('../../data/microchip_tests.txt',
header=None, names = ('test1','test2','released'))
# информация о наборе данных
data.info()<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 118 entries, 0 to 117
Data columns (total 3 columns):
test1 118 non-null float64
test2 118 non-null float64
released 118 non-null int64
dtypes: float64(2), int64(1)
memory usage: 2.8 KB
Посмотрим на первые и последние 5 строк.
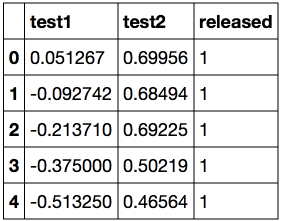
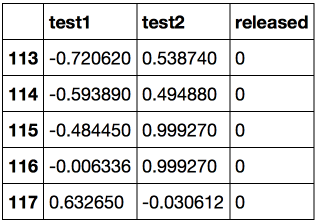
Сохраним обучающую выборку и метки целевого класса в отдельных массивах NumPy. Отобразим данные. Красный цвет соответствует бракованным чипам, зеленый – нормальным.
Код
X = data.ix[:,:2].values
y = data.ix[:,2].valuesplt.scatter(X[y == 1, 0], X[y == 1, 1], c='green', label='Выпущен')
plt.scatter(X[y == 0, 0], X[y == 0, 1], c='red', label='Бракован')
plt.xlabel("Тест 1")
plt.ylabel("Тест 2")
plt.title('2 теста микрочипов')
plt.legend();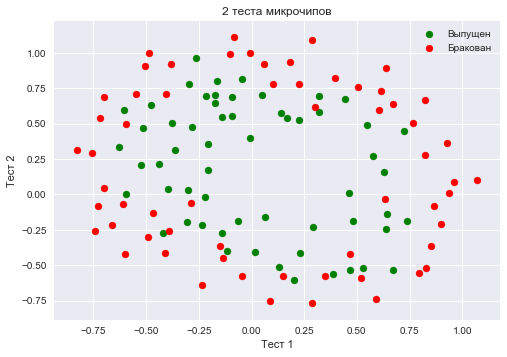
Определяем функцию для отображения разделяющей кривой классификатора
Код
def plot_boundary(clf, X, y, grid_step=.01, poly_featurizer=None):
x_min, x_max = X[:, 0].min() - .1, X[:, 0].max() + .1
y_min, y_max = X[:, 1].min() - .1, X[:, 1].max() + .1
xx, yy = np.meshgrid(np.arange(x_min, x_max, grid_step),
np.arange(y_min, y_max, grid_step))
# каждой точке в сетке [x_min, m_max]x[y_min, y_max]
# ставим в соответствие свой цвет
Z = clf.predict(poly_featurizer.transform(np.c_[xx.ravel(), yy.ravel()]))
Z = Z.reshape(xx.shape)
plt.contour(xx, yy, Z, cmap=plt.cm.Paired)Полиномиальными признаками до степени  для двух переменных
для двух переменных  и
и  мы называем следующие:
мы называем следующие:

Например, для  это будут следующие признаки:
это будут следующие признаки:

Нарисовав треугольник Пифагора, Вы сообразите, сколько таких признаков будет для  и вообще для любого .
и вообще для любого .
Попросту говоря, таких признаков экспоненциально много, и строить, скажем, для 100 признаков полиномиальные степени 10 может оказаться затратно (а более того, и не нужно).
Создадим объект sklearn, который добавит в матрицу полиномиальные признаки вплоть до степени 7 и обучим логистическую регрессию с параметром регуляризации  . Изобразим разделяющую границу.
. Изобразим разделяющую границу.
Также проверим долю правильных ответов классификатора на обучающей выборке. Видим, что регуляризация оказалась слишком сильной, и модель «недообучилась». Доля правильных ответов классификатора на обучающей выборке оказалась равной 0.627.
Код
poly = PolynomialFeatures(degree=7)
X_poly = poly.fit_transform(X)C = 1e-2
logit = LogisticRegression(C=C, n_jobs=-1, random_state=17)
logit.fit(X_poly, y)
plot_boundary(logit, X, y, grid_step=.01, poly_featurizer=poly)
plt.scatter(X[y == 1, 0], X[y == 1, 1], c='green', label='Выпущен')
plt.scatter(X[y == 0, 0], X[y == 0, 1], c='red', label='Бракован')
plt.xlabel("Тест 1")
plt.ylabel("Тест 2")
plt.title('2 теста микрочипов. Логит с C=0.01')
plt.legend();
print("Доля правильных ответов классификатора на обучающей выборке:",
round(logit.score(X_poly, y), 3))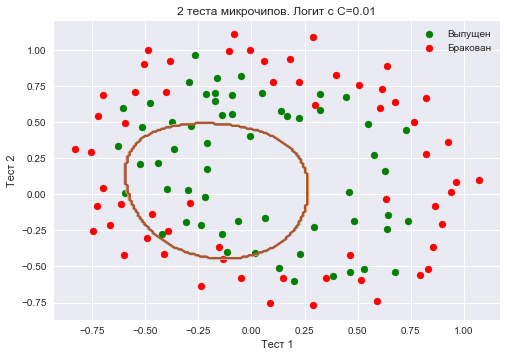
Увеличим  до 1. Тем самым мы ослабляем регуляризацию, теперь в решении значения весов логистической регрессии могут оказаться больше (по модулю), чем в прошлом случае. Теперь доля правильных ответов классификатора на обучающей выборке – 0.831.
до 1. Тем самым мы ослабляем регуляризацию, теперь в решении значения весов логистической регрессии могут оказаться больше (по модулю), чем в прошлом случае. Теперь доля правильных ответов классификатора на обучающей выборке – 0.831.
Код
C = 1
logit = LogisticRegression(C=C, n_jobs=-1, random_state=17)
logit.fit(X_poly, y)
plot_boundary(logit, X, y, grid_step=.005, poly_featurizer=poly)
plt.scatter(X[y == 1, 0], X[y == 1, 1], c='green', label='Выпущен')
plt.scatter(X[y == 0, 0], X[y == 0, 1], c='red', label='Бракован')
plt.xlabel("Тест 1")
plt.ylabel("Тест 2")
plt.title('2 теста микрочипов. Логит с C=1')
plt.legend();
print("Доля правильных ответов классификатора на обучающей выборке:",
round(logit.score(X_poly, y), 3))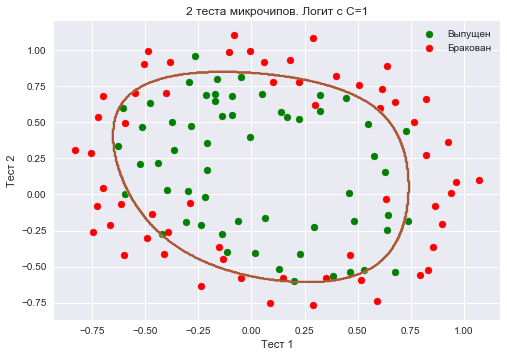
Еще увеличим – до 10 тысяч. Теперь регуляризации явно недостаточно, и мы наблюдаем переобучение. Можно заметить, что в прошлом случае (при =1 и «гладкой» границе) доля правильных ответов модели на обучающей выборке не намного ниже, чем в 3 случае, зато на новой выборке, можно себе представить, 2 модель сработает намного лучше.
Доля правильных ответов классификатора на обучающей выборке – 0.873.
Код
C = 1e4
logit = LogisticRegression(C=C, n_jobs=-1, random_state=17)
logit.fit(X_poly, y)
plot_boundary(logit, X, y, grid_step=.005, poly_featurizer=poly)
plt.scatter(X[y == 1, 0], X[y == 1, 1], c='green', label='Выпущен')
plt.scatter(X[y == 0, 0], X[y == 0, 1], c='red', label='Бракован')
plt.xlabel("Тест 1")
plt.ylabel("Тест 2")
plt.title('2 теста микрочипов. Логит с C=10k')
plt.legend();
print("Доля правильных ответов классификатора на обучающей выборке:",
round(logit.score(X_poly, y), 3))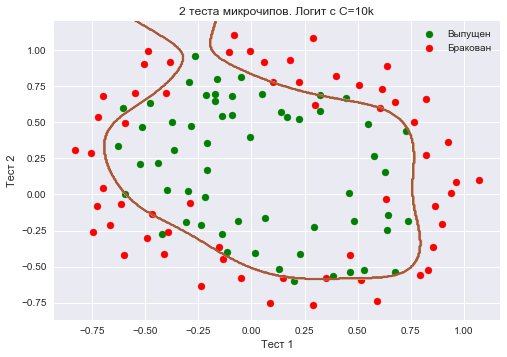
Чтоб обсудить результаты, перепишем формулу для функционала, который оптимизируется в логистической регрессии, в таком виде:

где
Промежуточные выводы:
- чем больше параметр , тем более сложные зависимости в данных может восстанавливать модель (интуитивно соответствует «сложности» модели (model capacity))
- если регуляризация слишком сильная (малые значения ), то решением задачи минимизации логистической функции потерь может оказаться то, когда многие веса занулились или стали слишком малыми. Еще говорят, что модель недостаточно «штрафуется» за ошибки (то есть в функционале «перевешивает» сумма квадратов весов, а ошибка может быть относительно большой). В таком случае модель окажется недообученной (1 случай)
- наоборот, если регуляризация слишком слабая (большие значения ), то решением задачи оптимизации может стать вектор с большими по модулю компонентами. В таком случае больший вклад в оптимизируемый функционал имеет и, вольно выражаясь, модель слишком «боится» ошибиться на объектах обучающей выборки, поэтому окажется переобученной (3 случай)
- то, какое значение выбрать, сама логистическая регрессия «не поймет» (или еще говорят «не выучит»), то есть это не может быть определено решением оптимизационной задачи, которой является логистическая регрессия (в отличие от весов ). Так же точно, дерево решений не может «само понять», какое ограничение на глубину выбрать (за один процесс обучения). Поэтому – это гиперпараметр модели, который настраивается на кросс-валидации, как и max_depth для дерева.
 «перевешивает» сумма квадратов весов, а ошибка
«перевешивает» сумма квадратов весов, а ошибка  может быть относительно большой). В таком случае модель окажется недообученной (1 случай)
может быть относительно большой). В таком случае модель окажется недообученной (1 случай) с большими по модулю компонентами. В таком случае больший вклад в оптимизируемый функционал
с большими по модулю компонентами. В таком случае больший вклад в оптимизируемый функционал Настройка параметра регуляризации
Теперь найдем оптимальное (в данном примере) значение параметра регуляризации . Сделать это можно с помощью LogisticRegressionCV – перебора параметров по сетке с последующей кросс-валидацией. Этот класс создан специально для логистической регрессии (для нее известны эффективные алгоритмы перебора параметров), для произвольной модели мы бы использовали GridSearchCV, RandomizedSearchCV или, например, специальные алгоритмы оптимизации гиперпараметров, реализованные в hyperopt.
Код
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=17)
c_values = np.logspace(-2, 3, 500)
logit_searcher = LogisticRegressionCV(Cs=c_values, cv=skf, verbose=1, n_jobs=-1)
logit_searcher.fit(X_poly, y)Посмотрим, как качество модели (доля правильных ответов на обучающей и валидационной выборках) меняется при изменении гиперпараметра .
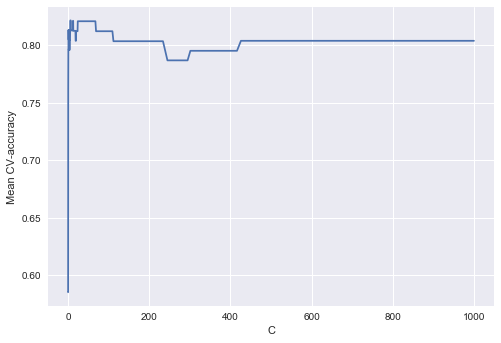
Выделим участок с «лучшими» значениями C.
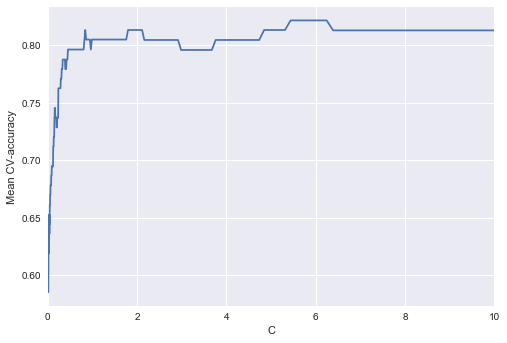
Как мы помним, такие кривые называются валидационными, раньше мы их строили вручную, но в sklearn для них их построения есть специальные методы, которые мы тоже сейчас будем использовать.
4. Где логистическая регрессия хороша и где не очень
Анализ отзывов IMDB к фильмам
Будем решать задачу бинарной классификации отзывов IMDB к фильмам. Имеется обучающая выборка с размеченными отзывами, по 12500 отзывов известно, что они хорошие, еще про 12500 – что они плохие. Здесь уже не так просто сразу приступить к машинному обучению, потому что готовой матрицы нет – ее надо приготовить. Будем использовать самый простой подход – мешок слов («Bag of words»). При таком подходе признаками отзыва будут индикаторы наличия в нем каждого слова из всего корпуса, где корпус – это множество всех отзывов. Идея иллюстрируется картинкой

Импорт библиотек и загрузка данных
from __future__ import division, print_function
# отключим всякие предупреждения Anaconda
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import numpy as np
from sklearn.datasets import load_files
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer, TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVCЗагрузим данные отсюда (краткое описание — тут). В обучающей и тестовой выборках по 12500 тысяч хороших и плохих отзывов к фильмам.
reviews_train = load_files("YOUR PATH")
text_train, y_train = reviews_train.data, reviews_train.targetprint("Number of documents in training data: %d" % len(text_train))
print(np.bincount(y_train))# поменяйте путь к файлу
reviews_test = load_files("YOUR PATH")
text_test, y_test = reviews_test.data, reviews_test.target
print("Number of documents in test data: %d" % len(text_test))
print(np.bincount(y_test))Пример плохого отзыва:
‘Words can\’t describe how bad this movie is. I can\’t explain it by writing only. You have too see it for yourself to get at grip of how horrible a movie really can be. Not that I recommend you to do that. There are so many clich\xc3\xa9s, mistakes (and all other negative things you can imagine) here that will just make you cry. To start with the technical first, there are a LOT of mistakes regarding the airplane. I won\’t list them here, but just mention the coloring of the plane. They didn\’t even manage to show an airliner in the colors of a fictional airline, but instead used a 747 painted in the original Boeing livery. Very bad. The plot is stupid and has been done many times before, only much, much better. There are so many ridiculous moments here that i lost count of it really early. Also, I was on the bad guys\’ side all the time in the movie, because the good guys were so stupid. «Executive Decision» should without a doubt be you\’re choice over this one, even the «Turbulence»-movies are better. In fact, every other movie in the world is better than this one.’
Пример хорошего отзыва:
‘Everyone plays their part pretty well in this «little nice movie». Belushi gets the chance to live part of his life differently, but ends up realizing that what he had was going to be just as good or maybe even better. The movie shows us that we ought to take advantage of the opportunities we have, not the ones we do not or cannot have. If U can get this movie on video for around $10, it\xc2\xb4d be an investment!’
Простой подсчет слов
Составим словарь всех слов с помощью CountVectorizer. Всего в выборке 74849 уникальных слов. Если посмотреть на примеры полученных «слов» (лучше их называть токенами), то можно увидеть, что многие важные этапы обработки текста мы тут пропустили (автоматическая обработка текстов – это могло бы быть темой отдельной серии статей).
Код
cv = CountVectorizer()
cv.fit(text_train)
print(len(cv.vocabulary_)) #74849print(cv.get_feature_names()[:50])
print(cv.get_feature_names()[50000:50050])[’00’, ‘000’, ‘0000000000001’, ‘00001’, ‘00015’, ‘000s’, ‘001’, ‘003830’, ‘006’, ‘007’, ‘0079’, ‘0080’, ‘0083’, ‘0093638’, ’00am’, ’00pm’, ’00s’, ’01’, ’01pm’, ’02’, ‘020410’, ‘029’, ’03’, ’04’, ‘041’, ’05’, ‘050’, ’06’, ’06th’, ’07’, ’08’, ‘087’, ‘089’, ’08th’, ’09’, ‘0f’, ‘0ne’, ‘0r’, ‘0s’, ’10’, ‘100’, ‘1000’, ‘1000000’, ‘10000000000000’, ‘1000lb’, ‘1000s’, ‘1001’, ‘100b’, ‘100k’, ‘100m’]
[‘pincher’, ‘pinchers’, ‘pinches’, ‘pinching’, ‘pinchot’, ‘pinciotti’, ‘pine’, ‘pineal’, ‘pineapple’, ‘pineapples’, ‘pines’, ‘pinet’, ‘pinetrees’, ‘pineyro’, ‘pinfall’, ‘pinfold’, ‘ping’, ‘pingo’, ‘pinhead’, ‘pinheads’, ‘pinho’, ‘pining’, ‘pinjar’, ‘pink’, ‘pinkerton’, ‘pinkett’, ‘pinkie’, ‘pinkins’, ‘pinkish’, ‘pinko’, ‘pinks’, ‘pinku’, ‘pinkus’, ‘pinky’, ‘pinnacle’, ‘pinnacles’, ‘pinned’, ‘pinning’, ‘pinnings’, ‘pinnochio’, ‘pinnocioesque’, ‘pino’, ‘pinocchio’, ‘pinochet’, ‘pinochets’, ‘pinoy’, ‘pinpoint’, ‘pinpoints’, ‘pins’, ‘pinsent’]
Закодируем предложения из текстов обучающей выборки индексами входящих слов. Используем разреженный формат. Преобразуем так же тестовую выборку.
X_train = cv.transform(text_train)
X_test = cv.transform(text_test)Обучим логистическую регрессию и посмотрим на доли правильных ответов на обучающей и тестовой выборках. Получается, на тестовой выборке мы правильно угадываем тональность примерно 86.7% отзывов.
Код
%%time
logit = LogisticRegression(n_jobs=-1, random_state=7)
logit.fit(X_train, y_train)
print(round(logit.score(X_train, y_train), 3), round(logit.score(X_test, y_test), 3))Коэффициенты модели можно красиво отобразить.
Код визуализации коэффициентов модели
def visualize_coefficients(classifier, feature_names, n_top_features=25):
# get coefficients with large absolute values
coef = classifier.coef_.ravel()
positive_coefficients = np.argsort(coef)[-n_top_features:]
negative_coefficients = np.argsort(coef)[:n_top_features]
interesting_coefficients = np.hstack([negative_coefficients, positive_coefficients])
# plot them
plt.figure(figsize=(15, 5))
colors = ["red" if c < 0 else "blue" for c in coef[interesting_coefficients]]
plt.bar(np.arange(2 * n_top_features), coef[interesting_coefficients], color=colors)
feature_names = np.array(feature_names)
plt.xticks(np.arange(1, 1 + 2 * n_top_features), feature_names[interesting_coefficients], rotation=60, ha="right");
def plot_grid_scores(grid, param_name):
plt.plot(grid.param_grid[param_name], grid.cv_results_['mean_train_score'],
color='green', label='train')
plt.plot(grid.param_grid[param_name], grid.cv_results_['mean_test_score'],
color='red', label='test')
plt.legend();
visualize_coefficients(logit, cv.get_feature_names())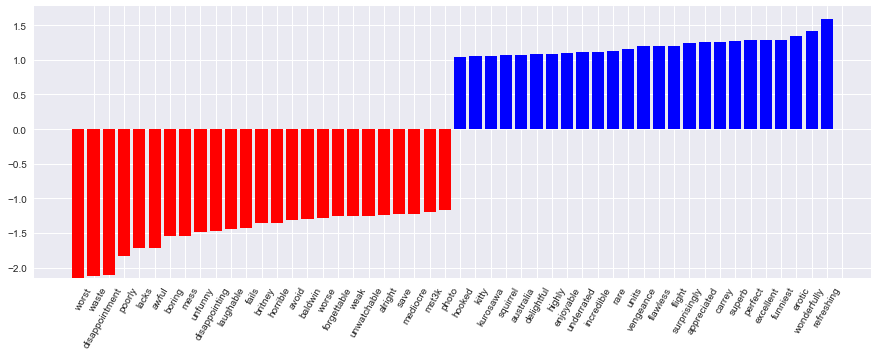
Подберем коэффициент регуляризации для логистической регрессии. Используем sklearn.pipeline, поскольку CountVectorizer правильно применять только на тех данных, на которых в текущий момент обучается модель (чтоб не «подсматривать» в тестовую выборку и не считать по ней частоты вхождения слов). В данном случае pipeline задает последовательность действий: применить CountVectorizer, затем обучить логистическую регрессию. Так мы поднимаем долю правильных ответов до 88.5% на кросс-валидации и 87.9% – на отложенной выборке.
Код
from sklearn.pipeline import make_pipeline
text_pipe_logit = make_pipeline(CountVectorizer(),
LogisticRegression(n_jobs=-1, random_state=7))
text_pipe_logit.fit(text_train, y_train)
print(text_pipe_logit.score(text_test, y_test))
from sklearn.model_selection import GridSearchCV
param_grid_logit = {'logisticregression__C': np.logspace(-5, 0, 6)}
grid_logit = GridSearchCV(text_pipe_logit, param_grid_logit, cv=3, n_jobs=-1)
grid_logit.fit(text_train, y_train)
grid_logit.best_params_, grid_logit.best_score_
plot_grid_scores(grid_logit, 'logisticregression__C')
grid_logit.score(text_test, y_test)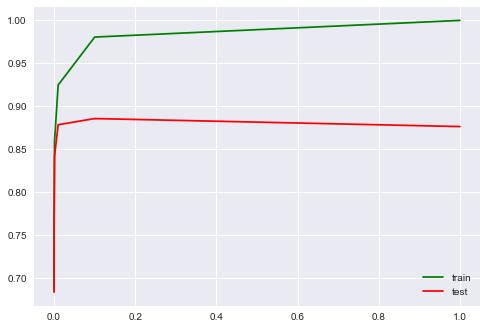
Теперь то же самое, но со случайным лесом. Видим, что с логистической регрессией мы достигаем большей доли правильных ответов меньшими усилиями. Лес работает дольше, на отложенной выборке 85.5% правильных ответов.
Код для обучения случайного леса
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators=200, n_jobs=-1, random_state=17)
forest.fit(X_train, y_train)
print(round(forest.score(X_test, y_test), 3))XOR-проблема
Теперь рассмотрим пример, где линейные модели справляются хуже.
Линейные методы классификации строят все же очень простую разделяющую поверхность – гиперплоскость. Самый известный игрушечный пример, в котором классы нельзя без ошибок поделить гиперплоскостью (то есть прямой, если это 2D), получил имя «the XOR problem».
XOR – это «исключающее ИЛИ», булева функция со следующей таблицей истинности:
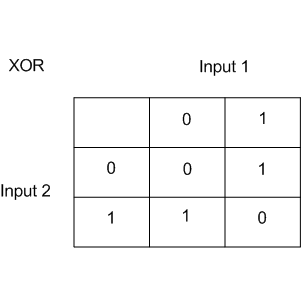
XOR дал имя простой задаче бинарной классификации, в которой классы представлены вытянутыми по диагоналям и пересекающимися облаками точек.
Код, рисующий следующие 3 картинки
# порождаем данные
rng = np.random.RandomState(0)
X = rng.randn(200, 2)
y = np.logical_xor(X[:, 0] > 0, X[:, 1] > 0)plt.scatter(X[:, 0], X[:, 1], s=30, c=y, cmap=plt.cm.Paired);def plot_boundary(clf, X, y, plot_title):
xx, yy = np.meshgrid(np.linspace(-3, 3, 50),
np.linspace(-3, 3, 50))
clf.fit(X, y)
# plot the decision function for each datapoint on the grid
Z = clf.predict_proba(np.vstack((xx.ravel(), yy.ravel())).T)[:, 1]
Z = Z.reshape(xx.shape)
image = plt.imshow(Z, interpolation='nearest',
extent=(xx.min(), xx.max(), yy.min(), yy.max()),
aspect='auto', origin='lower', cmap=plt.cm.PuOr_r)
contours = plt.contour(xx, yy, Z, levels=[0], linewidths=2,
linetypes='--')
plt.scatter(X[:, 0], X[:, 1], s=30, c=y, cmap=plt.cm.Paired)
plt.xticks(())
plt.yticks(())
plt.xlabel(r'$<!-- math>$inline$x_1$inline$</math -->$')
plt.ylabel(r'$<!-- math>$inline$x_2$inline$</math -->$')
plt.axis([-3, 3, -3, 3])
plt.colorbar(image)
plt.title(plot_title, fontsize=12);plot_boundary(LogisticRegression(), X, y,
"Logistic Regression, XOR problem")from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipelinelogit_pipe = Pipeline([('poly', PolynomialFeatures(degree=2)),
('logit', LogisticRegression())])plot_boundary(logit_pipe, X, y,
"Logistic Regression + quadratic features. XOR problem")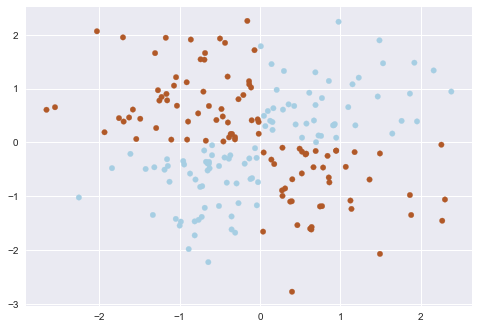
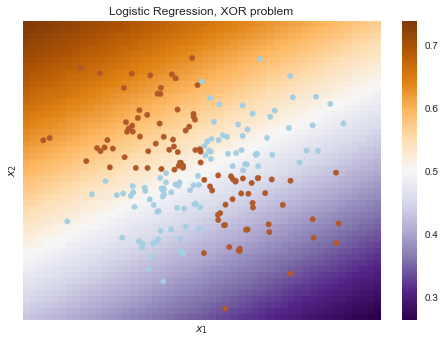
Очевидно, нельзя провести прямую так, чтобы без ошибок отделить один класс от другого. Поэтому логистическая регрессия плохо справляется с такой задачей.
А вот если на вход подать полиномиальные признаки, в данном случае до 2 степени, то проблема решается.
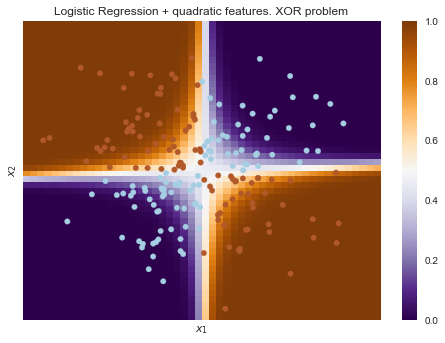
Здесь логистическая регрессия все равно строила гиперплоскость, но в 6-мерном пространстве признаков  и
и  . В проекции на исходное пространство признаков
. В проекции на исходное пространство признаков  граница получилась нелинейной.
граница получилась нелинейной.
На практике полиномиальные признаки действительно помогают, но строить их явно – вычислительно неэффективно. Гораздо быстрее работает SVM с ядровым трюком. При таком подходе в пространстве высокой размерности считается только расстояние между объектами (задаваемое функцией-ядром), а явно плодить комбинаторно большое число признаков не приходится. Про это подробно можно почитать в курсе Евгения Соколова (математика уже серьезная).
5. Кривые валидации и обучения
Мы уже получили представление о проверке модели, кросс-валидации и регуляризации.
Теперь рассмотрим главный вопрос:
Если качество модели нас не устраивает, что делать?
- Сделать модель сложнее или упростить?
- Добавить больше признаков?
- Или нам просто нужно больше данных для обучения?
Ответы на данные вопросы не всегда лежат на поверхности. В частности, иногда использование более сложной модели приведет к ухудшению показателей. Либо добавление наблюдений не приведет к ощутимым изменениям. Способность принять правильное решение и выбрать правильный способ улучшения модели, собственно говоря, и отличает хорошего специалиста от плохого.
Будем работать со знакомыми данными по оттоку клиентов телеком-оператора.
Импорт библиотек и чтение данных
from __future__ import division, print_function
# отключим всякие предупреждения Anaconda
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
from matplotlib import pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression, LogisticRegressionCV, SGDClassifier
from sklearn.model_selection import validation_curve
data = pd.read_csv('../../data/telecom_churn.csv').drop('State', axis=1)
data['International plan'] = data['International plan'].map({'Yes': 1, 'No': 0})
data['Voice mail plan'] = data['Voice mail plan'].map({'Yes': 1, 'No': 0})
y = data['Churn'].astype('int').values
X = data.drop('Churn', axis=1).valuesЛогистическую регрессию будем обучать стохастическим градиентным спуском. Пока объясним это тем, что так быстрее, но далее в программе у нас отдельная статья про это дело. Построим валидационные кривые, показывающие, как качество (ROC AUC) на обучающей и проверочной выборке меняется с изменением параметра регуляризации.
Код
alphas = np.logspace(-2, 0, 20)
sgd_logit = SGDClassifier(loss='log', n_jobs=-1, random_state=17)
logit_pipe = Pipeline([('scaler', StandardScaler()), ('poly', PolynomialFeatures(degree=2)),
('sgd_logit', sgd_logit)])
val_train, val_test = validation_curve(logit_pipe, X, y,
'sgd_logit__alpha', alphas, cv=5,
scoring='roc_auc')
def plot_with_err(x, data, **kwargs):
mu, std = data.mean(1), data.std(1)
lines = plt.plot(x, mu, '-', **kwargs)
plt.fill_between(x, mu - std, mu + std, edgecolor='none',
facecolor=lines[0].get_color(), alpha=0.2)
plot_with_err(alphas, val_train, label='training scores')
plot_with_err(alphas, val_test, label='validation scores')
plt.xlabel(r'$\alpha$'); plt.ylabel('ROC AUC')
plt.legend();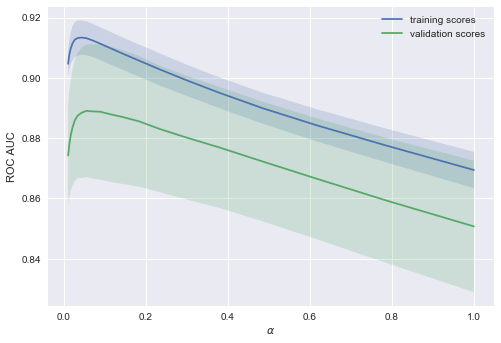
Тенденция видна сразу, и она очень часто встречается.
-
Для простых моделей тренировочная и валидационная ошибка находятся где-то рядом, и они велики. Это говорит о том, что модель недообучилась: то есть она не имеет достаточное кол-во параметров.
-
Для сильно усложненных моделей тренировочная и валидационная ошибки значительно отличаются. Это можно объяснить переобучением: когда параметров слишком много либо не хватает регуляризации, алгоритм может «отвлекаться» на шум в данных и упускать основной тренд.
Сколько нужно данных?
Известно, что чем больше данных использует модель, тем лучше. Но как нам понять в конкретной ситуации, помогут ли новые данные? Скажем, целесообразно ли нам потратить N\$ на труд асессоров, чтобы увеличить выборку вдвое?
Поскольку новых данных пока может и не быть, разумно поварьировать размер имеющейся обучающей выборки и посмотреть, как качество решения задачи зависит от объема данных, на котором мы обучали модель. Так получаются кривые обучения (learning curves).
Идея простая: мы отображаем ошибку как функцию от количества примеров, используемых для обучения. При этом параметры модели фиксируются заранее.
Давайте посмотрим, что мы получим для линейной модели. Коэффициент регуляризации выставим большим.
Код
from sklearn.model_selection import learning_curve
def plot_learning_curve(degree=2, alpha=0.01):
train_sizes = np.linspace(0.05, 1, 20)
logit_pipe = Pipeline([('scaler', StandardScaler()), ('poly', PolynomialFeatures(degree=degree)),
('sgd_logit', SGDClassifier(n_jobs=-1, random_state=17, alpha=alpha))])
N_train, val_train, val_test = learning_curve(logit_pipe,
X, y, train_sizes=train_sizes, cv=5,
scoring='roc_auc')
plot_with_err(N_train, val_train, label='training scores')
plot_with_err(N_train, val_test, label='validation scores')
plt.xlabel('Training Set Size'); plt.ylabel('AUC')
plt.legend()
plot_learning_curve(degree=2, alpha=10)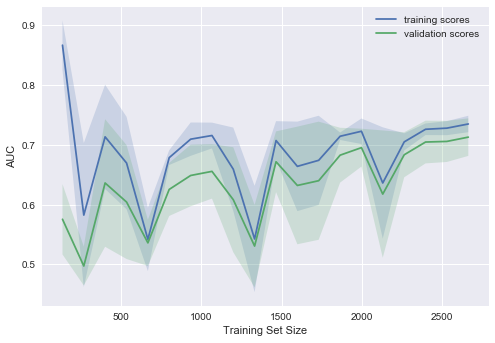
Типичная ситуация: для небольшого объема данных ошибки на обучающей выборке и в процессе кросс-валидации довольно сильно отличаются, что указывает на переобучение. Для той же модели, но с большим объемом данных ошибки «сходятся», что указывается на недообучение.
Если добавить еще данные, ошибка на обучающей выборке не будет расти, но с другой стороны, ошибка на тестовых данных не будет уменьшаться.
Получается, ошибки «сошлись», и добавление новых данных не поможет. Собственно, это случай – самый интересный для бизнеса. Возможна ситуация, когда мы увеличиваем выборку в 10 раз. Но если не менять сложность модели, это может и не помочь. То есть стратегия «настроил один раз – дальше использую 10 раз» может и не работать.
Что будет, если изменить коэффициент регуляризации (уменьшить до 0.05)?
Видим хорошую тенденцию – кривые постепенно сходятся, и если дальше двигаться направо (добавлять в модель данные), можно еще повысить качество на валидации.
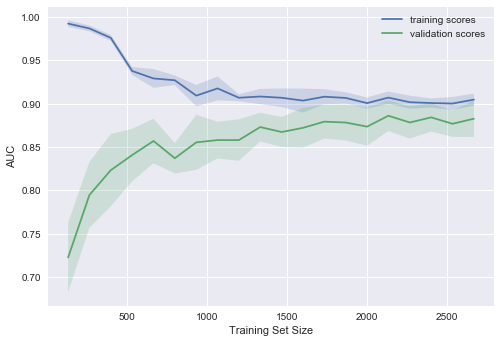
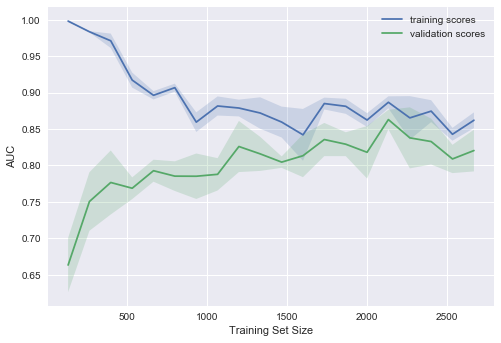
А если усложнить модель ещё больше ( )?
)?
Проявляется переобучение – AUC падает как на обучении, так и на валидации.
Строя подобные кривые, можно понять, в какую сторону двигаться, и как правильно настроить сложность модели на новых данных.
Выводы по кривым валидации и обучения
- Ошибка на обучающей выборке сама по себе ничего не говорит о качестве модели
- Кросс-валидационная ошибка показывает, насколько хорошо модель подстраивается под данные (имеющийся тренд в данных), сохраняя при этом способность обобщения на новые данные
- Валидационная кривая представляет собой график, показывающий результат на тренировочной и валидационной выборке в зависимости от сложности модели:
- если две кривые распологаются близко, и обе ошибки велики, — это признак недообучения
- если две кривые далеко друг от друга, — это показатель переобучения
- Кривая обучения — это график, показывающий результаты на валидации и тренировочной подвыборке в зависимости от количества наблюдений:
- если кривые сошлись друг к другу, добавление новых данных не поможет – надо менять сложность модели
- если кривые еще не сошлись, добавление новых данных может улучшить результат.
6. Плюсы и минусы линейных моделей в задачах машинного обучения
Плюсы:
Минусы:
- Плохо работают в задачах, в которых зависимость ответов от признаков сложная, нелинейная
- На практике предположения теоремы Маркова-Гаусса почти никогда не выполняются, поэтому чаще линейные методы работают хуже, чем, например, SVM и ансамбли (по качеству решения задачи классификации/регрессии)
7. Домашнее задание № 4
В качестве закрепления изученного материала предлагаем следующее задание: разобраться с тем, как работает TfidfVectorizer и DictVectorizer, обучить и настроить модель линейной регрессии Ridge на данных о публикациях на Хабрахабре и воспроизвести бенчмарк в соревновании. Проверить себя можно отправив ответы в веб-форме (там же найдете и решение).
Актуальные и обновляемые версии демо-заданий – на английском на сайте курса. Также по подписке на Patreon («Bonus Assignments» tier) доступны расширенные домашние задания по каждой теме (только на англ.)
8. Полезные ресурсы
- Перевод материала этой статьи на английский – Jupyter notebooks в репозитории курса
- Видеозаписи лекций по мотивам этой статьи: классификация, регрессия
- Основательный обзор классики машинного обучения и, конечно же, линейных моделей сделан в книге «Deep Learning» (I. Goodfellow, Y. Bengio, A. Courville, 2016);
- Реализация многих алгоритмов машинного обучения с нуля – репозиторий rushter. Рекомендуем изучить реализацию логистической регрессии;
- Курс Евгения Соколова по машинному обучению (материалы на GitHub). Хорошая теория, нужна неплохая математическая подготовка;
- Курс Дмитрия Ефимова на GitHub (англ.). Тоже очень качественные материалы.
Статья написана в соавторстве с mephistopheies (Павлом Нестеровым). Он же – автор домашнего задания. Авторы домашнего задания в первой сессии курса (февраль-май 2017)– aiho (Ольга Дайховская) и das19 (Юрий Исаков). Благодарю bauchgefuehl (Анастасию Манохину) за редактирование.
В данной главе мы изучим инструмент, который позволяет анализировать ошибку алгоритма в зависимости от некоторого набора факторов, влияющих на итоговое качество его работы. Этот инструмент в литературе называется bias-variance decomposition — разложение ошибки на смещение и разброс. В разложении, на самом деле, есть и третья компонента — случайный шум в данных, но ему не посчастливилось оказаться в названии. Данное разложение оказывается полезным в некоторых теоретических исследованиях работы моделей машинного обучения, в частности, при анализе свойств ансамблевых моделей.
Некоторые картинки в тексте кликабельны. Это означает, что они были заимствованы из какого-то источника и при клике вы сможете перейти к этому источнику.
Вывод разложения bias-variance для MSE
Рассмотрим задачу регрессии с квадратичной функцией потерь. Представим также для простоты, что целевая переменная $y$ — одномерная и выражается через переменную $x$ как:
$$
y = f(x) + \varepsilon,
$$
где $f$ — некоторая детерминированная функция, а $\varepsilon$ — случайный шум со следующими свойствами:
$$
\mathbb{E} \varepsilon = 0, , \mathbb{V}\text{ar} \varepsilon = \mathbb{E} \varepsilon^2 = \sigma^2.
$$
В зависимости от природы данных, которые описывает эта зависимость, её представление в виде точной $f(x)$ и случайной $\varepsilon$ может быть продиктовано тем, что:
-
данные на самом деле имеют случайный характер;
-
измерительный прибор не может зафиксировать целевую переменную абсолютно точно;
-
имеющихся признаков недостаточно, чтобы исчерпывающим образом описать объект, пользователя или событие.
Функция потерь на одном объекте $x$ равна
$$
MSE = (y(x) — a(x))^2
$$
Однако знание значения MSE только на одном объекте не может дать нам общего понимания того, насколько хорошо работает наш алгоритм. Какие факторы мы бы хотели учесть при оценке качества алгоритма? Например, то, что выход алгоритма на объекте $x$ зависит не только от самого этого объекта, но и от выборки $X$, на которой алгоритм обучался:
$$
X = ((x_1, y_1), \ldots, (x_\ell, y_\ell))
$$
$$
a(x) = a(x, X)
$$
Кроме того, значение $y$ на объекте $x$ зависит не только от $x$, но и от реализации шума в этой точке:
$$
y(x) = y(x, \varepsilon)
$$
Наконец, измерять качество мы бы хотели на тестовых объектах $x$ — тех, которые не встречались в обучающей выборке, а тестовых объектов у нас в большинстве случаев более одного. При включении всех вышеперечисленных источников случайности в рассмотрение логичной оценкой качества алгоритма $a$ кажется следующая величина:
$$
Q(a) = \mathbb{E}_x \mathbb{E}_{X, \varepsilon} [y(x, \varepsilon) — a(x, X)]^2
$$
Внутреннее матожидание позволяет оценить качество работы алгоритма в одной тестовой точке $x$ в зависимости от всевозможных реализаций $X$ и $\varepsilon$, а внешнее матожидание усредняет это качество по всем тестовым точкам.
Замечание. Запись $\mathbb{E}_{X, \varepsilon}$ в общем случае обозначает взятие матожидания по совместному распределению $X$ и $\varepsilon$. Однако, поскольку $X$ и $\varepsilon$ независимы, она равносильна последовательному взятию матожиданий по каждой из переменных: $\mathbb{E}_{X, \varepsilon} = \mathbb{E}_{X} \mathbb{E}_{\varepsilon}$, но последний вариант выглядит несколько более громоздко.
Попробуем представить выражение для $Q(a)$ в более удобном для анализа виде. Начнём с внутреннего матожидания:
$$
\mathbb{E}_{X, \varepsilon} [y(x, \varepsilon) — a(x, X)]^2 = \mathbb{E}_{X, \varepsilon}[f(x) + \varepsilon — a(x, X)]^2 =
$$
$$
= \mathbb{E}_{X, \varepsilon} [ \underbrace{(f(x) — a(x, X))^2}_{\text{не зависит от $\varepsilon$}} +
\underbrace{2 \varepsilon \cdot (f(x) — a(x, X))}_{\text{множители независимы}} + \varepsilon^2 ] =
$$
$$
= \mathbb{E}_X \left[
(f(x) — a(x, X))^2
\right] + 2 \underbrace{\mathbb{E}_\varepsilon[\varepsilon]}_{=0} \cdot \mathbb{E}_X (f(x) — a(x, X)) + \mathbb{E}_\varepsilon \varepsilon^2 =
$$
$$
= \mathbb{E}_X \left[ (f(x) — a(x, X))^2 \right] + \sigma^2
$$
Из общего выражения для $Q(a)$ выделилась шумовая компонента $\sigma^2$. Продолжим преобразования:
$$
\mathbb{E}_X \left[ (f(x) — a(x, X))^2 \right] = \mathbb{E}_X \left[
(f(x) — \mathbb{E}_X[a(x, X)] + \mathbb{E}_X[a(x, X)] — a(x, X))^2
\right] =
$$
$$
= \mathbb{E}_X\underbrace{\left[
(f(x) — \mathbb{E}_X[a(x, X)])^2
\right]}_{\text{не зависит от $X$}} + \underbrace{\mathbb{E}_X \left[ (a(x, X) — \mathbb{E}_X[a(x, X)])^2 \right]}_{\text{$=\mathbb{V}\text{ar}_X[a(x, X)]$}} +
$$
$$
+ 2 \mathbb{E}_X[\underbrace{(f(x) — \mathbb{E}_X[a(x, X)])}_{\text{не зависит от $X$}} \cdot (\mathbb{E}_X[a(x, X)] — a(x, X))] =
$$
$$
= (\underbrace{f(x) — \mathbb{E}_X[a(x, X)]}_{\text{bias}_X a(x, X)})^2 + \mathbb{V}\text{ar}_X[a(x, X)] + 2 (f(x) — \mathbb{E}_X[a(x, X)]) \cdot \underbrace{(\mathbb{E}_X[a(x, X)] — \mathbb{E}_X [a(x, X)])}_{=0} =
$$
$$
= \text{bias}_X^2 a(x, X)+ \mathbb{V}\text{ar}_X[a(x, X)]
$$
Таким образом, итоговое выражение для $Q(a)$ примет вид
$$
Q(a) = \mathbb{E}_x \mathbb{E}_{X, \varepsilon} [y(x, \varepsilon) — a(x, X)]^2 = \mathbb{E}_x \text{bias}_X^2 a(x, X) + \mathbb{E}_x \mathbb{V}\text{ar}_X[a(x, X)] + \sigma^2,
$$
где
$$
\text{bias}_X a(x, X) = f(x) — \mathbb{E}_X[a(x, X)]
$$
— смещение предсказания алгоритма в точке $x$, усреднённого по всем возможным обучающим выборкам, относительно истинной зависимости $f$;
$$
\mathbb{V}\text{ar}_X[a(x, X)] = \mathbb{E}_X \left[ a(x, X) — \mathbb{E}_X[a(x, X)] \right]^2
$$
— дисперсия (разброс) предсказаний алгоритма в зависимости от обучающей выборки $X$;
$$
\sigma^2 = \mathbb{E}_x \mathbb{E}_\varepsilon[y(x, \varepsilon) — f(x)]^2
$$
— неустранимый шум в данных.
Смещение показывает, насколько хорошо с помощью данного алгоритма можно приблизить истинную зависимость $f$, а разброс характеризует чувствительность алгоритма к изменениям в обучающей выборке. Например, деревья маленькой глубины будут в большинстве случаев иметь высокое смещение и низкий разброс предсказаний, так как они не могут слишком хорошо запомнить обучающую выборку. А глубокие деревья, наоборот, могут безошибочно выучить обучающую выборку и потому будут иметь высокий разброс в зависимости от выборки, однако их предсказания в среднем будут точнее. На рисунке ниже приведены возможные случаи сочетания смещения и разброса для разных моделей:
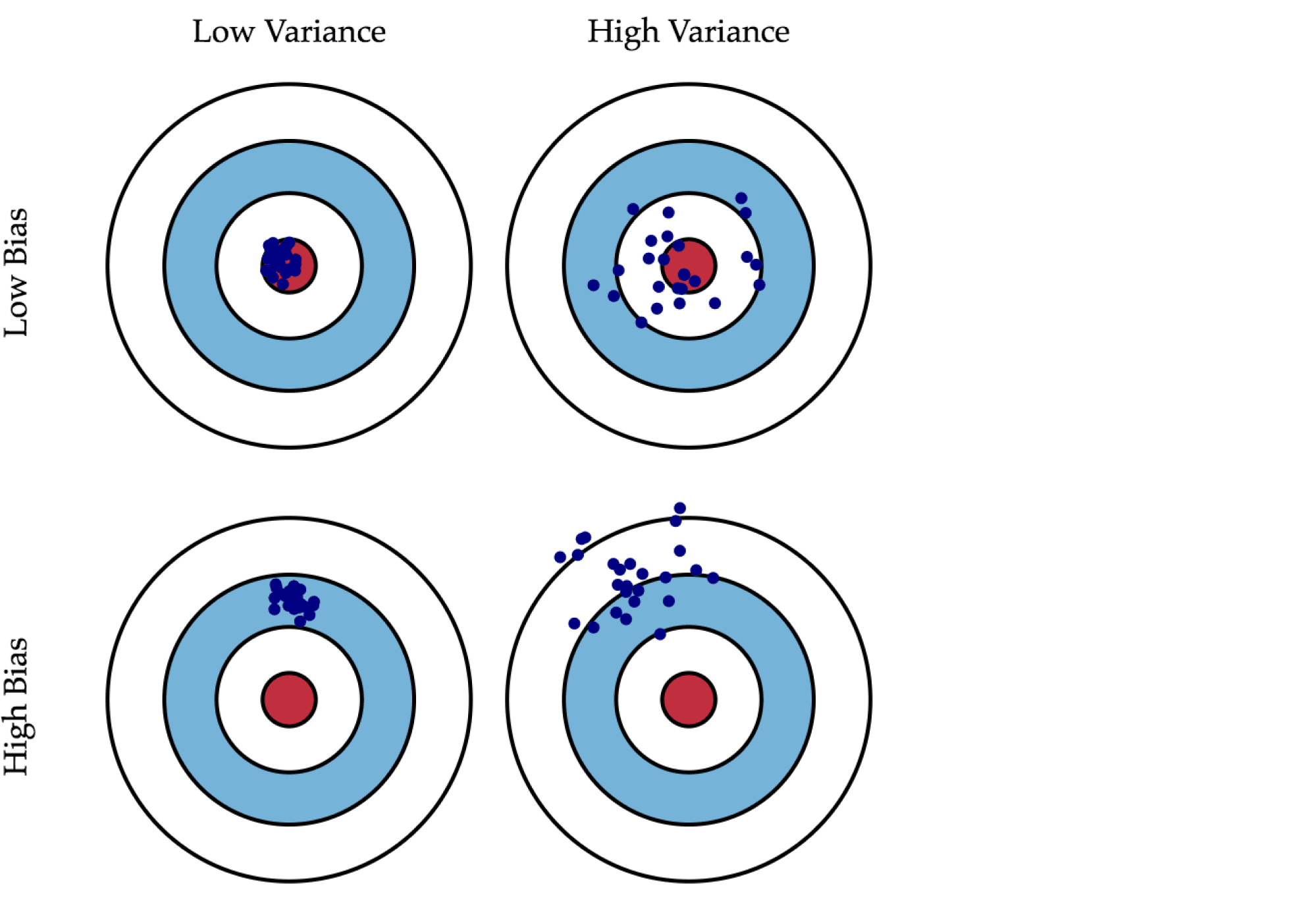
Синяя точка соответствует модели, обученной на некоторой обучающей выборке, а всего синих точек столько, сколько было обучающих выборок. Красный круг в центре области представляет ближайшую окрестность целевого значения. Большое смещение соответствует тому, что модели в среднем не попадают в цель, а при большом разбросе модели могут как делать точные предсказания, так и довольно сильно ошибаться.
Полученное нами разложение ошибки на три компоненты верно только для квадратичной функции потерь. Для других функций потерь существуют более общие формы этого разложения (Domigos, 2000, James, 2003) с похожими по смыслу компонентами. Это позволяет предполагать, что для большинства основных функций потерь имеется некоторое представление в виде смещения, разброса и шума (хоть и, возможно, не в столь простой аддитивной форме).
Пример расчёта оценок bias и variance
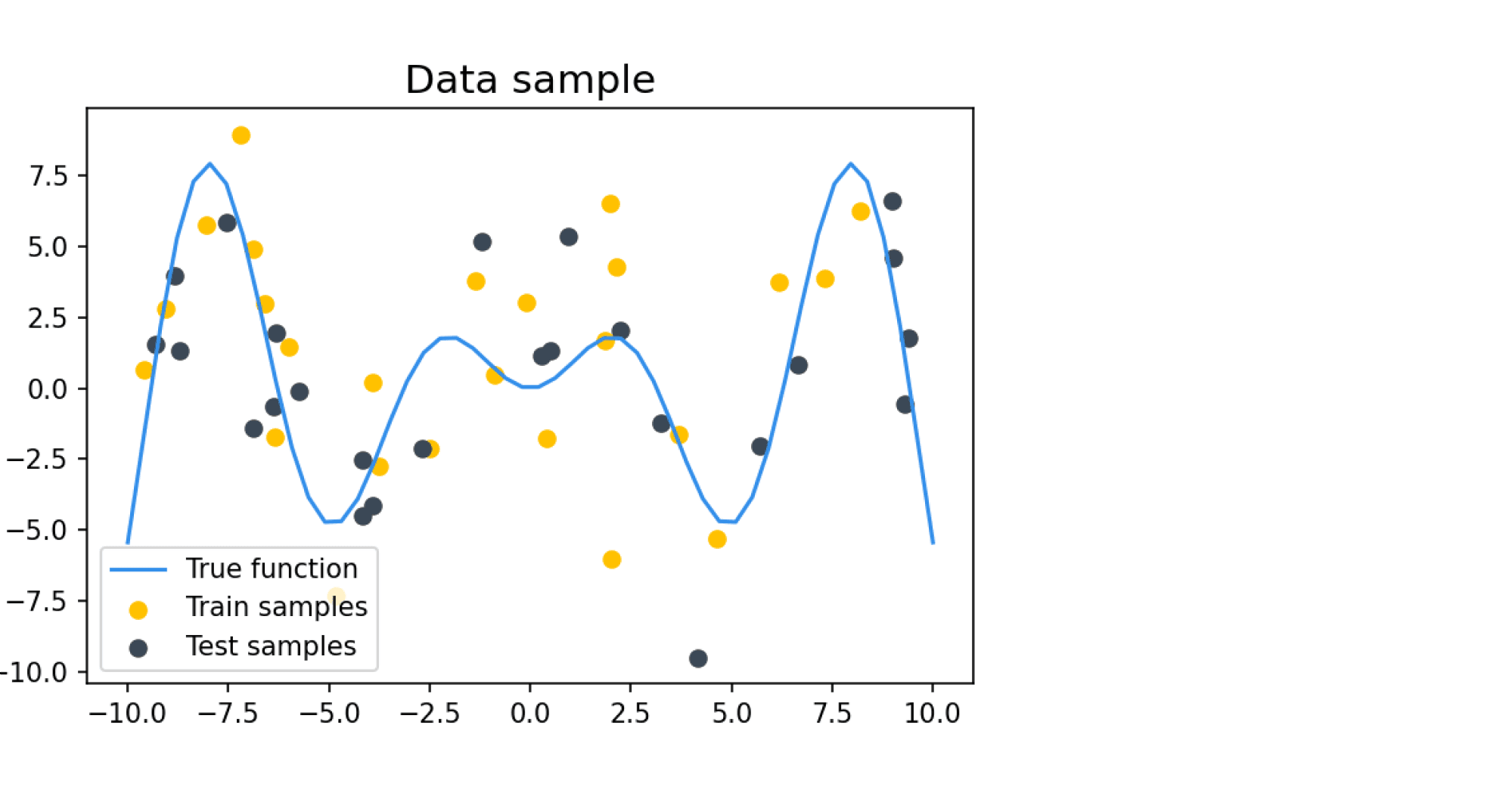
Попробуем вычислить разложение на смещение и разброс на каком-нибудь практическом примере. Наши обучающие и тестовые примеры будут состоять из зашумлённых значений целевой функции $f(x)$, где $f(x)$ определяется как
$$
f(x) = x \sin x
$$
В качестве шума добавляется нормальный шум с нулевым средним и дисперсией $\sigma^2$, равной во всех дальнейших примерах 9. Такое большое значение шума задано для того, чтобы задача была достаточно сложной для классификатора, который будет на этих данных учиться и тестироваться. Пример семпла из таких данных:
Посмотрим на то, как предсказания деревьев зависят от обучающих подмножеств и максимальной глубины дерева. На рисунке ниже изображены предсказания деревьев разной глубины, обученных на трёх независимых подвыборках размера 20 (каждая колонка соответствует одному подмножеству):
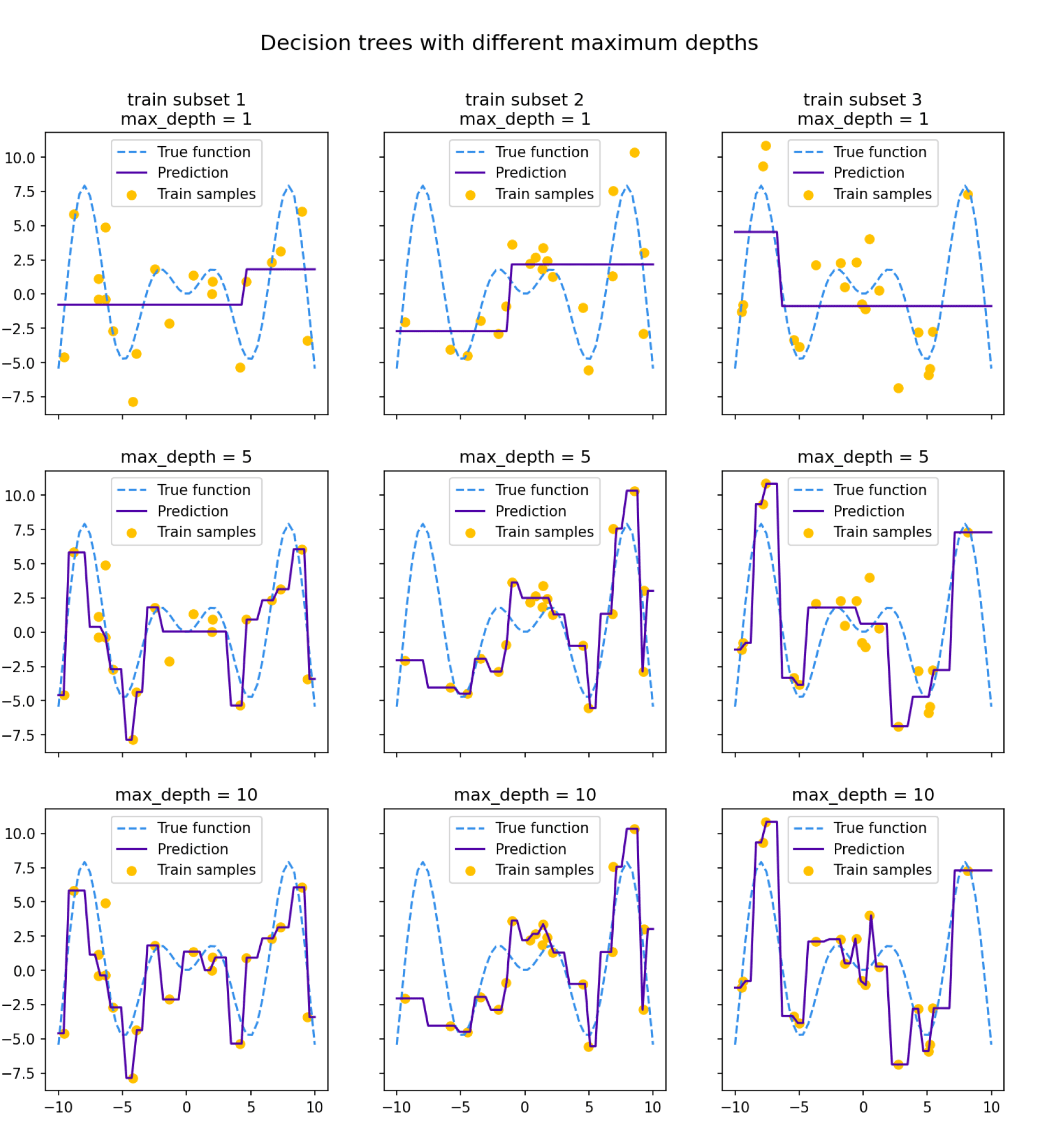
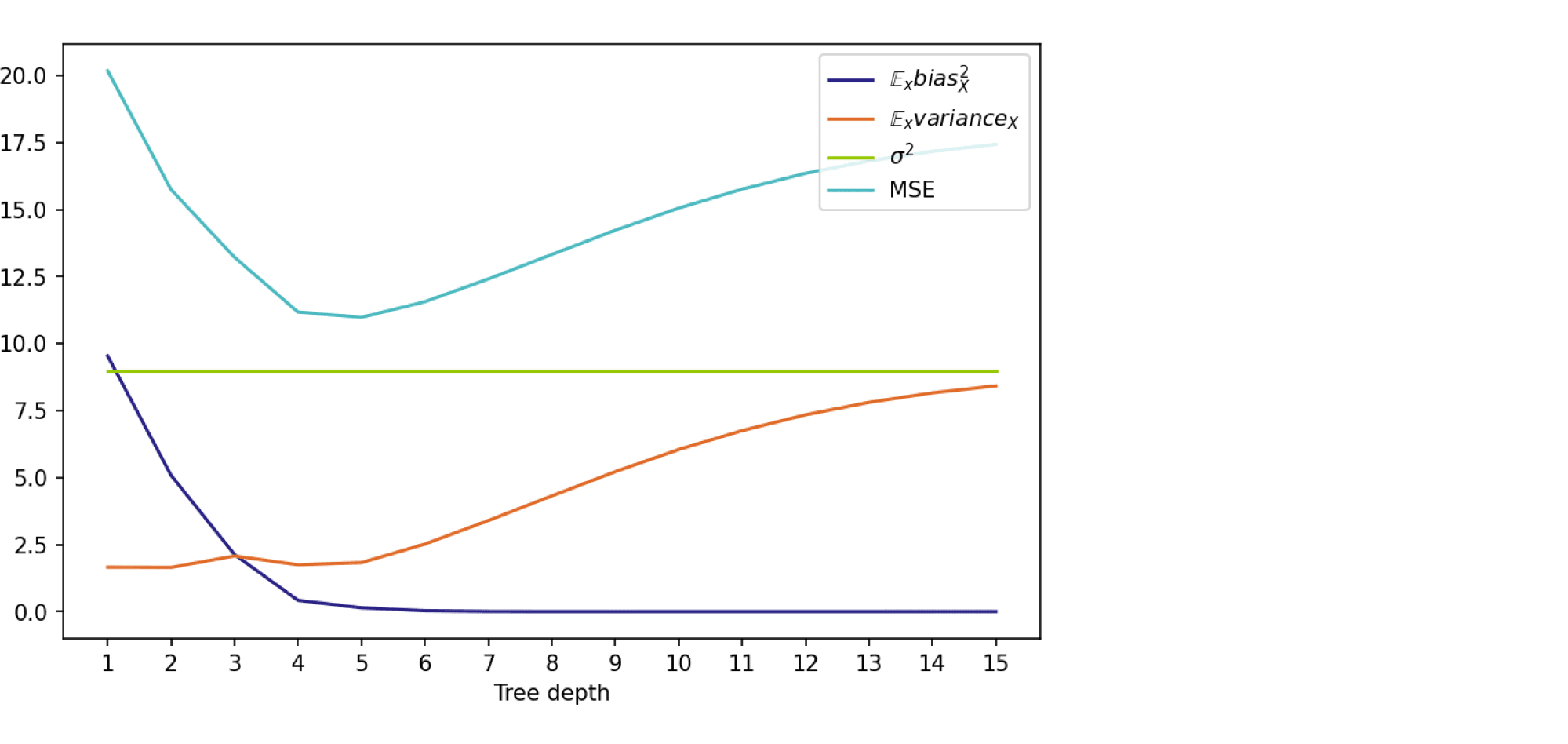
Глядя на эти рисунки, можно выдвинуть гипотезу о том, что с увеличением глубины дерева смещение алгоритма падает, а разброс в зависимости от выборки растёт. Проверим, так ли это, вычислив компоненты разложения для деревьев со значениями глубины от 1 до 15.
Для обучения деревьев насемплируем 1000 случайных подмножеств $X_{train} = (x_{train}, y_{train})$ размера 500, а для тестирования зафиксируем случайное тестовое подмножество точек $x_{test}$ также размера 500. Чтобы вычислить матожидание по $\varepsilon$, нам нужно несколько экземпляров шума $\varepsilon$ для тестовых лейблов:
$$
y_{test} = y(x_{test}, \hat \varepsilon) = f(x_{test}) + \hat \varepsilon
$$
Положим количество семплов случайного шума равным 300. Для фиксированных $X_{train} = (x_{train}, y_{train})$ и $X_{test} = (x_{test}, y_{test})$ квадратичная ошибка вычисляется как
$$
MSE = (y_{test} — a(x_{test}, X_{train}))^2
$$
Взяв среднее от $MSE$ по $X_{train}$, $x_{test}$ и $\varepsilon$, мы получим оценку для $Q(a)$, а оценки для компонент ошибки мы можем вычислить по ранее выведенным формулам.
На графике ниже изображены компоненты ошибки и она сама в зависимости от глубины дерева:
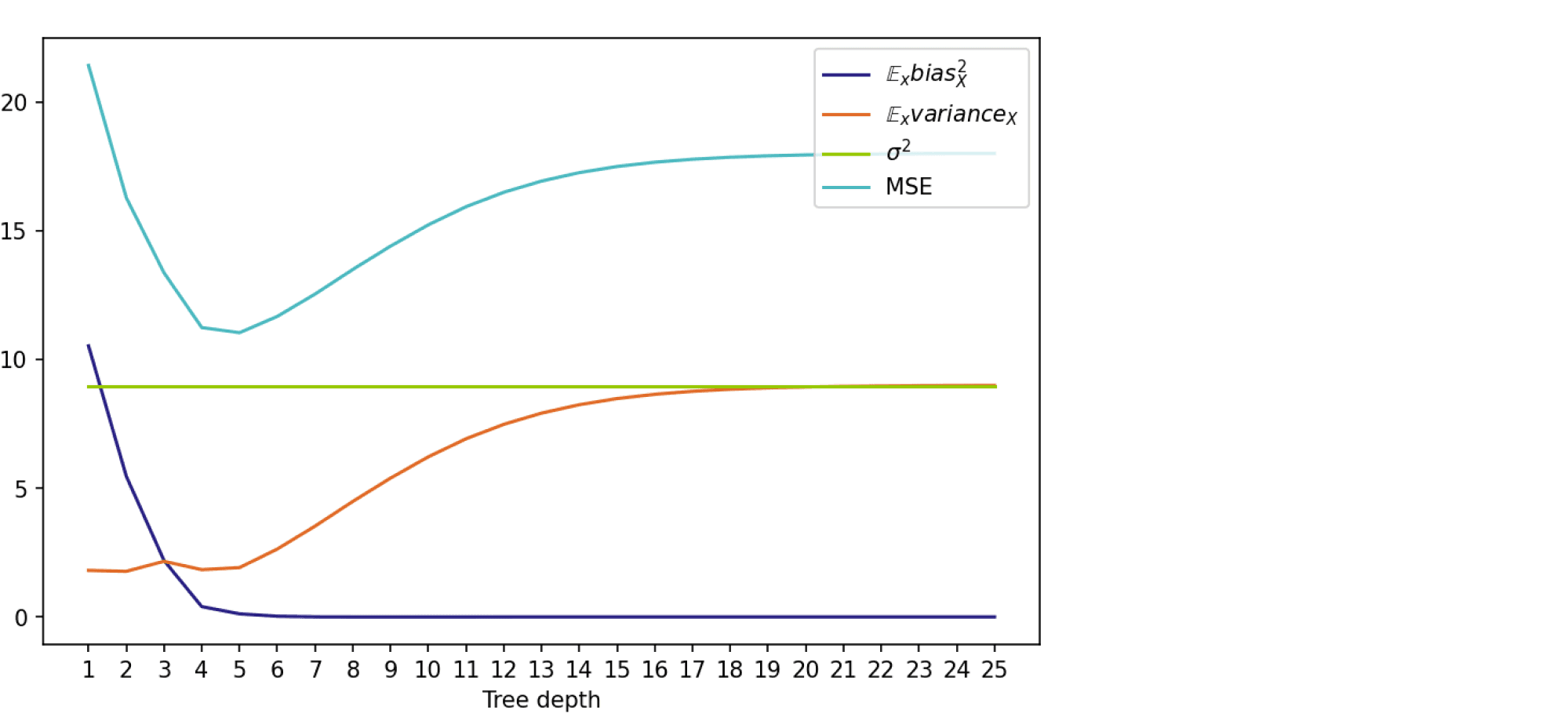
По графику видно, что гипотеза о падении смещения и росте разброса при увеличении глубины подтверждается для рассматриваемого отрезка возможных значений глубины дерева. Правда, если нарисовать график до глубины 25, можно увидеть, что разброс становится равен дисперсии случайного шума. То есть деревья слишком большой глубины начинают идеально подстраиваться под зашумлённую обучающую выборку и теряют способность к обобщению:
Код для подсчёта разложения на смещение и разброс, а также код отрисовки картинок можно найти в данном ноутбуке.
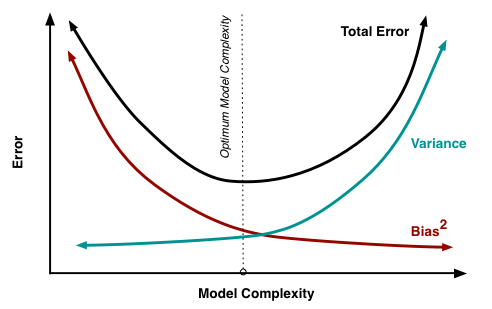
Bias-variance trade-off: в каких ситуациях он применим
В книжках и различных интернет-ресурсах часто можно увидеть следующую картинку:
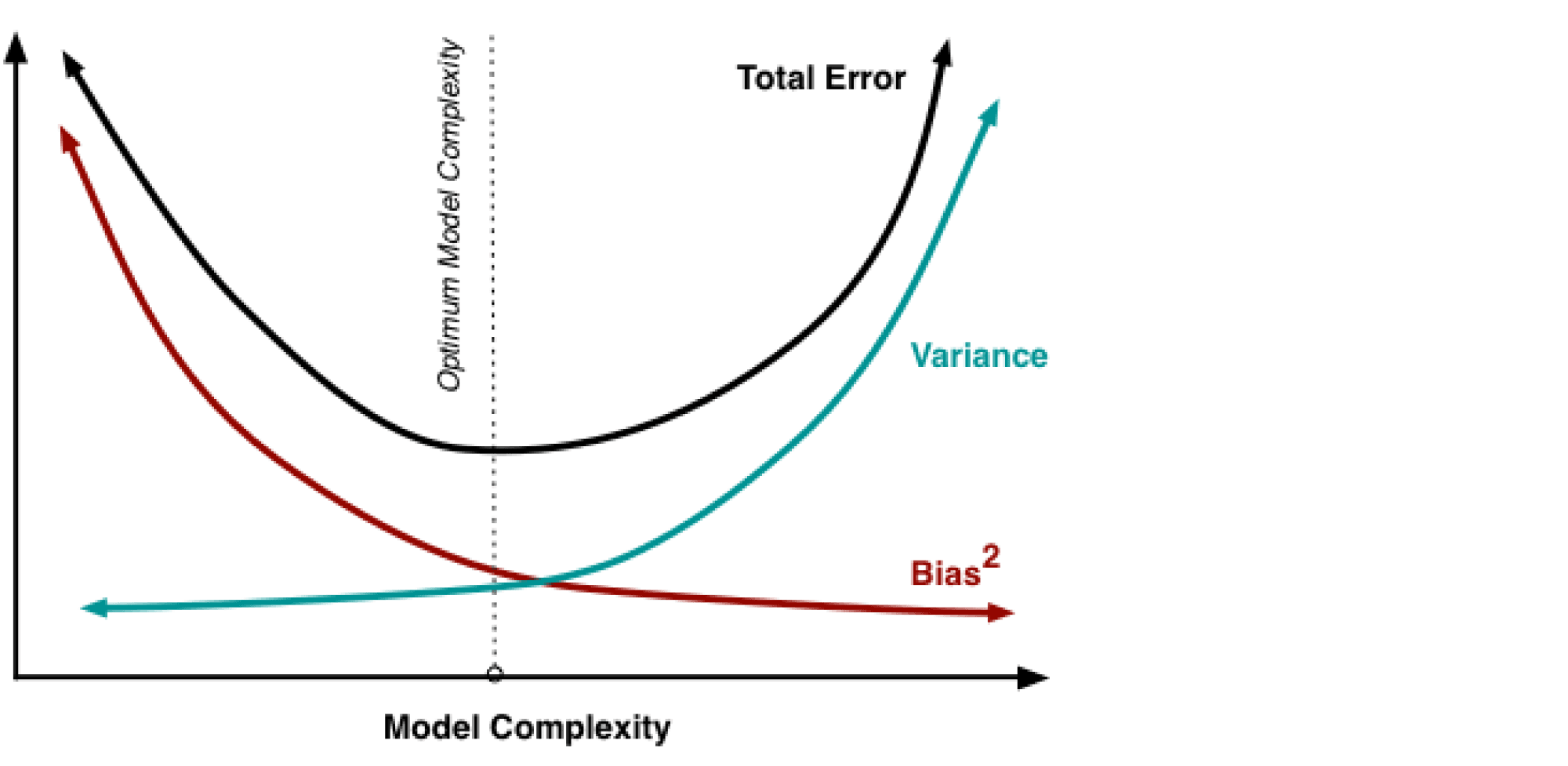
Она иллюстрирует утверждение, которое в литературе называется bias-variance trade-off: чем выше сложность обучаемой модели, тем меньше её смещение и тем больше разброс, и поэтому общая ошибка на тестовой выборке имеет вид $U$-образной кривой. С падением смещения модель всё лучше запоминает обучающую выборку, поэтому слишком сложная модель будет иметь нулевую ошибку на тренировочных данных и большую ошибку на тесте. Этот график призван показать, что существует оптимальная сложность модели, при которой соблюдается баланс между переобучением и недообучением и ошибка при этом минимальна.
Существует достаточное количество подтверждений bias-variance trade-off для непараметрических моделей. Например, его можно наблюдать для метода $k$ ближайших соседей при росте $k$ и для ядерной регрессии при увеличении ширины окна $\sigma$ (Geman et al., 1992):
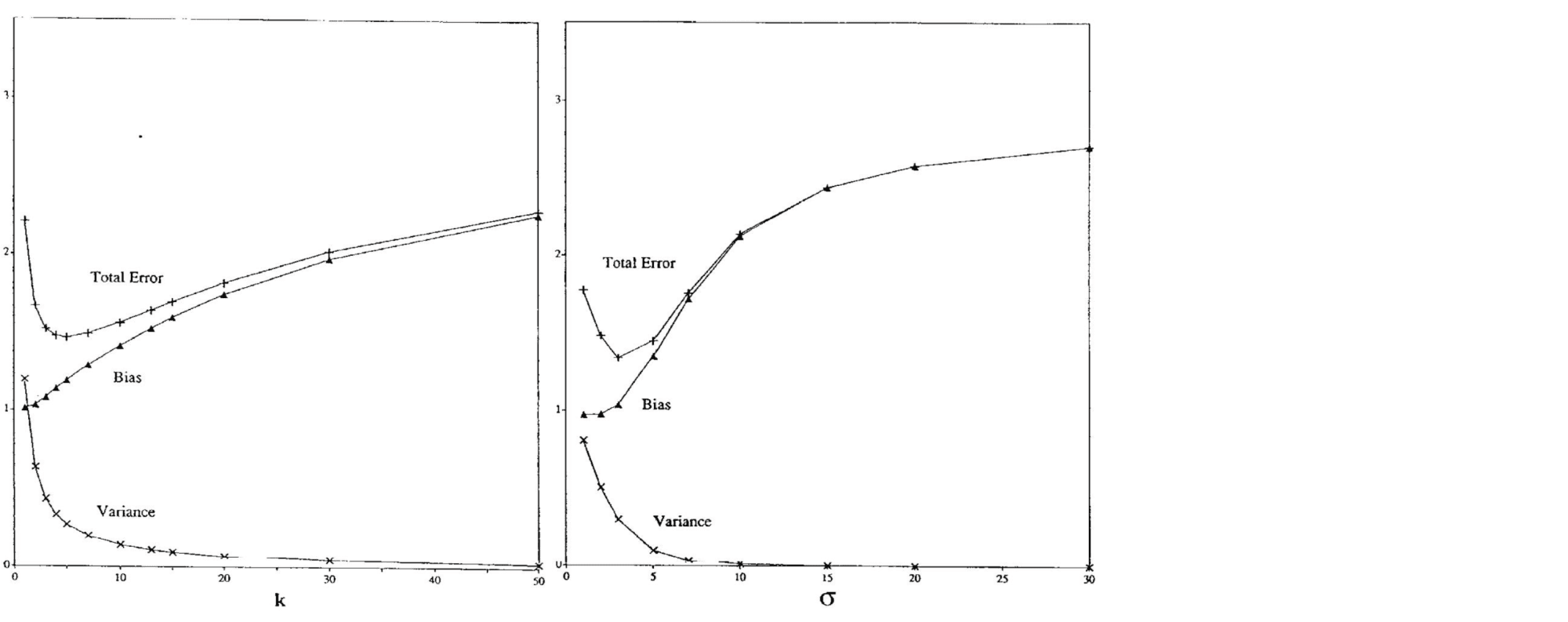
Чем больше соседей учитывает $k$-NN, тем менее изменчивым становится его предсказание, и аналогично для ядерной регрессии, из-за чего сложность этих моделей в некотором смысле убывает с ростом $k$ и $\sigma$. Поэтому традиционный график bias-variance trade-off здесь симметрично отражён по оси $x$.
Однако, как показывают последние исследования, непременное возрастание разброса при убывании смещения не является абсолютно истинным предположением. Например, для нейронных сетей с ростом их сложности может происходить снижение и разброса, и смещения. Одна из наиболее известных статей на эту тему — статья Белкина и др. (Belkin et al., 2019), в которой, в частности, была предложена следующая иллюстрация:

Слева — классический bias-variance trade-off: убывающая часть кривой соответствует недообученной модели, а возрастающая — переобученной. А на правой картинке — график, называемый в статье double descent risk curve. На нём изображена эмпирически наблюдаемая авторами зависимость тестовой ошибки нейросетей от мощности множества входящих в них параметров ($\mathcal H$). Этот график разделён на две части пунктирной линией, которую авторы называют interpolation threshold. Эта линия соответствует точке, в которой в нейросети стало достаточно параметров, чтобы без особых усилий почти идеально запомнить всю обучающую выборку. Часть до достижения interpolation threshold соответствует «классическому» режиму обучения моделей: когда у модели недостаточно параметров, чтобы сохранить обобщающую способность при почти полном запоминании обучающей выборки. А часть после достижения interpolation threshold соответствует «современным» возможностям обучения моделей с огромным числом параметров. На этой части графика ошибка монотонно убывает с ростом количества параметров у нейросети. Авторы также наблюдают похожее поведение и для «древесных» моделей: Random Forest и бустинга над решающими деревьями. Для них эффект проявляется при одновременном росте глубины и числа входящих в ансамбль деревьев.
В качестве вывода к этому разделу хочется сформулировать два основных тезиса:
- Bias-variance trade-off нельзя считать непреложной истиной, выполняющейся для всех моделей и обучающих данных.
- Разложение на смещение и разброс не влечёт немедленного выполнения bias-variance trade-off и остаётся верным и для случая, когда все компоненты ошибки (кроме неустранимого шума) убывают одновременно. Этот факт может оказаться незамеченным из-за того, что в учебных пособиях часто разговор о разложении дополняется иллюстрацией с $U$-образной кривой, благодаря чему в сознании эти два факта могут слиться в один.
Список литературы
- Блог-пост про bias-variance от Йоргоса Папахристудиса
- Блог-пост про bias-variance от Скотта Фортмана-Роу
- Статьи от Домингоса (2000) и Джеймса (2003) про обобщённые формы bias-variance decomposition
- Блог-пост от Брейди Нила про необходимость пересмотра традиционного взгляда на bias-variance trade-off
- Статья Гемана и др. (1992), в которой была впервые предложена концепция bias-variance trade-off
- Статья Белкина и др. (2019), в которой был предложен double-descent curve
Сегодня дадим немного объяснений стандартных для машинного обучения понятий: смещение, разброс, переобучение и недообучение. Как всегда, всё объясним просто (но нужна будет математическая подготовка), на картинках, с примерами (в данном случае на модельных задачах). Все рисунки и эксперименты авторские, в конце, по традиции, изюминка – в чём при объяснении этих понятий Вас обманывают на курсах по ML и в учебниках;)

Ниже обсудим несколько фундаментальных понятий машинного обучения. Первое – переобучение (overfitting) – явление, когда ошибка на тестовой выборке заметно больше ошибки на обучающей. Это главная проблема машинного обучения: если бы такого эффекта не было (ошибка на тесте примерно совпадала с ошибкой на обучении), то всё обучение сводилось бы к минимизации ошибки на тесте (т.н. эмпирическому риску).
Второе – недообучение (underfitting) – явление, когда ошибка на обучающей выборке достаточно большая, часто говорят «не удаётся настроиться на выборку». Такой странный термин объясняется тем, что недообучение при настройке алгоритмов итерационными методами (например, нейронных сетей методом обратного распространения) можно наблюдать, когда сделано слишком маленькое число итераций, т.е. «не успели обучиться».
Третье – сложность (complexity) модели алгоритмов (допускает множество формализаций) – оценивает, насколько разнообразно семейство алгоритмов в модели с точки зрения их функциональных свойств (например, способности настраиваться на выборки). Повышение сложности (т.е. использование более сложных моделей) решает проблему недообучения и вызывает переобучение.
Сначала опишем на примере, как проявляется проблема выбора сложности и почему возникает переобучение. Для начала рассмотрим задачу регрессии. Для простоты будем считать, что это регрессия от одного признака x. Целевая зависимость y(x) известна в конечном наборе точек. На рис. 1 показана выборка для зависимости вида y = sin(4x) + шум, на рис. 2 для зашумлённой пороговой зависимости.


На рисунках показаны также решения указанных задач полиномиальной регрессией с разными степенями полиномов. Видно, что в обеих задачах полином первой степени явно плохо подходит для описания целевой зависимости, второй – достаточно хорошо её описывает, хотя ошибки есть и на обучающей выборке, седьмой – идеально проходит через точки обучающей выборки, но совсем не похож на «естественную функцию» и существенно отклоняется от целевой зависимости в остальных точках.
Если попробовать решить задачу полиномами различной степени, то мы получим рис. 3 (он построен для первой задачи, но во второй картина аналогичная). Видно, что с увеличением степени ошибка на обучающей выборке падает, а на тестовой (мы взяли очень мелкую сетку отрезка [0, 1]) – сначала падает, потом возрастает.

Попробуем разобраться, в чём дело с теоретической точки зрения (сейчас немного математики). Наша целевая зависимость имеет вид

Мы строим алгоритм (в нашем случае полином фиксированной степени) a=a(x), посмотрим чему равно математическое ожидание квадрата отклонения ответа алгоритма от истинного значения:

Здесь важно понимать, как берутся матожидания (т.е., по сути, интегрирования) в приведённых выше формулах. Мы считаем, что обучающая выборка выбирается случайно из некоторого распределения, настроенный алгоритм тоже случаен, поскольку зависит от выборки, настройка алгоритма также может быть стохастической. Таким образом, матожидание берётся по всем данным (обучающим выборкам) и настройкам алгоритма, а сами формулы записываются в конкретной точке x:

При желании, можно проинтегрировать полученные формулы и по всем объектам (точнее, по какому-то распределению всех объектов) и получить уже смещение и разброс модели алгоритмов как таковой.
Разбросом (variance) мы назвали дисперсию ответов алгоритмов Da, а смещением (bias) – матожидание разности между истинным ответом и выданным алгоритмом: E(f – a). Мы получили, что ошибка раскладывается на три составляющие. Первая связана с шумом в самих данных, а вот две остальные связаны с используемой моделью алгоритмов. Понятно, что разброс характеризует разнообразие алгоритмов (из-за случайности обучающей выборки, в том числе шума, и стохастической природы настройки), а смещение – способность модели алгоритмов настраиваться на целевую зависимость. Проиллюстрируем это. На рис. 4-5 – показаны различные полиномы первой степени, они настроены на разных обучающих выборках. В точке x=0.5 ответы алгоритмов являются случайными величинами, они немного «разбросаны» (есть variance), а также они сильно смещены (есть bias) относительно правильного ответа (который, кстати, даже если нам и известен, то с точностью до шума).


На рис. 6-7 изображены уже полиномы второй степени (настроенные на тех же выборках). В точке x=0.5 у них сильно меньше смещение и чуть меньше разброс. Видно, что они совсем неплохо описывают целевую зависимость во всех точках.


Часто разброс и смещение иллюстрируют такими картинками – рис. 8. Если провести аналогию, что алгоритм – это игрок в дартс, то самый лучший игрок будет иметь небольшое смещение и разброс – его дротики ложатся кучно «в яблочко», если у игрока большое смешение, то они сгруппированы около другой точки, а если большой разброс, то они ложатся совсем не кучно. Эта аналогия понятна, но может сбить с толку. Например, известно, что спортсменов учат стрелять кучно, поскольку нужного смещения легко добиться (например, целясь повыше). С алгоритмами машинного обучения всё сложнее. Смещение нельзя просто «подвинуть», приходится переходить к другой (например, более сложной модели), а у неё может быть уже другой разброс.

Ещё важный момент: спортсмен может повысить точность целясь выше/ниже/правее/левее, а для алгоритма нет таких понятий. Напомним, что разброс и смещение мы вводили в конкретной точке. Если изменить смещение в этой точке, то модель будет по-новому вести себя и в остальных. Если же усреднить смещение, точнее его квадрат, по всем точкам, то мы получим просто число (оно не указывает, как менять модель, чтобы уменьшить ошибку).
Теперь рассмотрим самую частую иллюстрацию, которую приводят при объяснении разброса и смещения, см. рис. 9. Она полностью согласуется с рис. 3. При увеличении сложности модели (например, степени полинома) ошибка на независимом контроле сначала падает, потом начинает увеличиваться. Обычно это связывают с уменьшением смещения (в сложных моделях очень много алгоритмов, поэтому наверняка найдутся те, которые хорошо описывают целевую зависимость) и увеличением разброса (в сложных моделях больше алгоритмов, а следовательно, и больше разброс).

Для простых моделей характерно недообучение (они слишком простые, не могут описать целевую зависимость и имеют большое смещение), для сложных – переобучение (алгоритмов в модели слишком много, при настройке мы выбираем ту, которая хорошо описывает обучающую выборку, но из-за сильного разброса она может допускать большую ошибку на тесте).
Теперь рассмотрим задачу классификации. Отметим, что для неё тоже есть результат о разложении ошибки на шум, разброс и смещение. На рис. 10-12 показаны результаты экспериментов в задаче с двумя классами (стандартная задача «два полумесяца») и моделью k ближайших соседей (kNN) при разных k. Результат также согласуется с рис. 9, если учесть, что изображена точность, а не ошибка, и сложность алгоритма ~ 1/k. Возникает вопрос, а почему так вводится сложность для kNN? Ведь при разных k эти алгоритмы
- имеют одинаковые параметры (что бы не понималось под этим…),
- требуют хранения всей обучающей выборки (являются «ленивыми» – lazy algorithms),
- 9NN даже «чуть сложнее в реализации» 1NN (требует поиска большего числа соседей).
Всё очень просто: часто сложность как раз и логично формализовать как 1/variance. На рис. 11 показаны разделяющие поверхности метода 1NN для разных выборок, которые описывают одну и ту же целевую зависимость. Они очень сильно отличаются друг от друга. А разделяющие поверхности kNN при больших k, см. рис 12, различаются существенно меньше. И чем выше k, тем стабильней результат. В этом смысле это очень простые алгоритмы: то, как они разделяют классы, меньше зависит от исходных данных, т.е. по определению ответ алгоритма 9NN в каждой точке зависит от 9и ближайших соседей, а по факту он практически не меняется от выборки к выборке (при варьировании обучения).



Теперь покажем, в чём не правы стандартные учебники и учебные курсы по машинному обучению. Проведём эксперименты по оцениванию разброса и смещения в модельных задачах. На рис. 13-14 приведены результаты для задачи с целевой зависимостью «ступенька», а на рис. 15-16 для задачи с целевой зависимостью «sin(4x)».




Очевидно, что степень полинома – очень естественная мера сложности для полиномиальной регрессии. Но полученные рисунки немного отличаются от рис. 9:
- общая ошибка может быть не совсем унимодальна от сложности,
- смещение и разброс могут не быть строго монотонными,
- смещение может возрастать при увеличении сложности.
Почему так происходит? Одна их причин в том, что «сложность модели», если мы хотим видеть красивые графики монотонных и унимодальных функций, правильнее определять для конкретных данных! Например, ступенчатая функция нечётная (с точностью до смещения) и для восстановления такой целевой зависимости лучше подходят полиномы с нечётной старшей степенью.
Кстати, если использовать полиномиальную регрессию с L2-регуляризацией, то на рис. 16 смещение начинает вести себя «по классике»: убывать при увеличении степени полинома.
П.С. Дальше возникают естественные вопросы: как найти оптимальную сложность модели, как решать задачу сложными моделями и не переобучаться (используют же нейросети). Но это тема для отдельного поста… Просьба к читателям – давать отклики в комментариях. Этот материал будет использован, в том числе, в рамках нового курса на ВМК МГУ, а также в книжке, которую автор уже и не надеется закончить… Поэтому любые замечания по формулировкам, корректности выводов и т.п. будут полезны. Удачи!
Пусть  и производится обучение алгоритма
и производится обучение алгоритма  на некоторой выборке
на некоторой выборке  . Тогда среднеквадратичный риск
. Тогда среднеквадратичный риск  можно выразить, как:
можно выразить, как:

- — квадрат смещения.

- — разброс.

- — неустранимый шум.

Более короткая запись:

Доказательство[]
Подробно доказательство проводится тут
Bias-Variance decomposition c усреднением по всем объектам[]
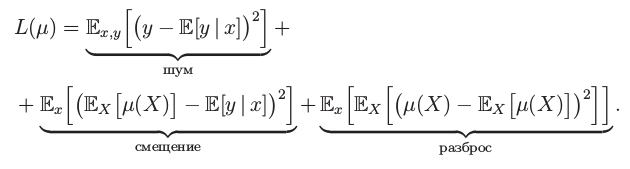
Более подробно почитать про это можно тут
Связь Bias-Variance decomposition и алгоритмов обучения[]
Смещение алгоритма показывает, насколько хорошо алгоритм приближает реальную зависимость между данными и откликами. Разбор показывает, насколько сильно может меняться ответ в зависимости от выборки, то есть насколько сильно изменится алгоритм при изменениях в выборке.
Алгоритмы с маленьким смещением — как правило, сложные алгоритмы, например, решающее дерево.
Алгоритмы с большим смещением — как правило, простые алгоритмы, например, линейные классификаторы.
Алгоритмы с маленькой дисперсией — как правило, простые алгоритмы.
Алгоритмы с большой дисперсией — как правило, сложные алгоритмы.
Также, высокая дисперсия показывает то, что алгоритм, скорее всего переобучен, а высокое смещение — что недообучен.
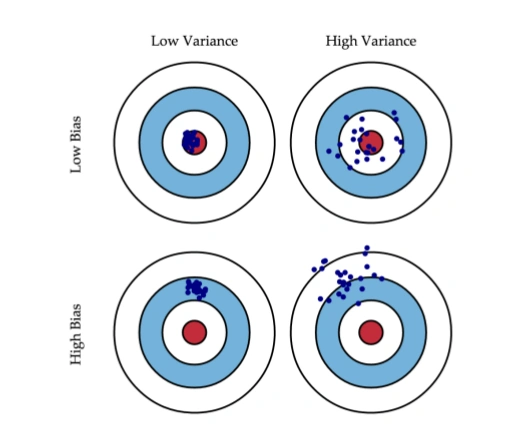
Все курсы > Оптимизация > Занятие 7
В рамках вводного курса мы подробно обсудили вопрос разделения выборки на обучающую и тестовую части, а также затронули проблему переобучения и недообучения модели. Рассмотрим этот вопрос более подробно.
Переобучение и недообучение модели
Переобучение (overfitting) случается, когда модель показывает хороший результат на обучающей выборке и сильно «проседает» на тестовых данных. При недообучении (underfitting) наоборот у алгоритма не получается уловить зависимость на обучающих данных.
Вспомним график из вводного курса.
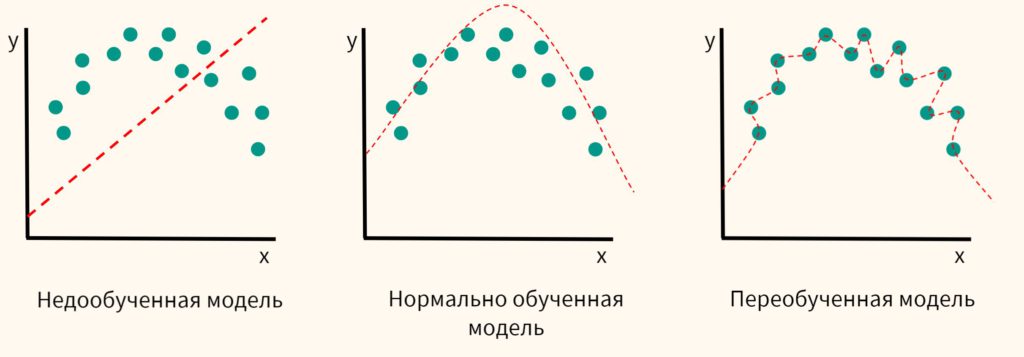
Дополним его для наглядности иллюстрацией того, как может повести себя переобученная модель на тестовых данных.

Также рассмотрим пример переобучения и недообучения в задаче классификации.

С точки зрения уровня ошибки на обучающих и тестовых данных можно привести следующий график. Предположим, что мы взяли полиномиальную регрессию и смотрим на значение функции потерь на обучающих и тестовых данных для различных степеней регрессии.

Как вы видите, после определенной границы сложности модели ошибка на тестовых данных начала расти. Рассмотрим этот вопрос под разными углами и введем несколько новых терминов.
Сложность модели
Причиной пере- и недообучения может быть степень сложности используемой модели (model complexity). Под сложностью в данном случае понимается тип или типы используемых алгоритмов, способность к выявлению линейных или нелинейных зависимостей, количество рассматриваемых признаков и другие факторы.
В целом, можно сказать, что более простая модель склонна к недообучению, более сложная — к переобучению.
Например, полиномиальная модель (особенно с полиномом высокой степени) зачастую способна уловить более сложную зависимость, чем модель линейной регрессии. Если модель хорошо описывает исходные данные, говорят, что у нее низкое смещение.
Смещение
Cмещение (bias) означает матожидание разности между истинным и прогнозным значением.
$$ Bias = E [\hat{y}-y] $$
Другими словами, смещение показывает, насколько хорошо модель обучилась на имеющихся данных (настроилась на выборку). Впрочем, как мы уже сказали в самом начале, идеально обученная (переобученная) модель может иметь минимальное смещение и при этом показать слабые результаты на тестовых данных. В этом случае говорят о большом разбросе.
Разброс
Разброс (variance) показывает насколько результат модели на обучающей выборке отличается от результата модели на тестовой выборке. То есть предсказания на тесте (например, на нескольких выборках) имеют разброс, и нам важно чтобы эти результаты не слишком отличались (тогда можно сказать, что у модели хорошая обобщающая способность).
Компромисс смещения и разброса
На практике стремление к снижению смещения может привести к увеличению разброса, т.е. переобучению, и, наоборот, высокое смещение модели может способствовать низкому разбросу, но смысла в этом не будет, потому что модель будет недообучена.
Эту проблему принято называть компромиссом или дилеммой смещения и разброса (bias-variance tradeoff). Посмотрим на рисунок ниже.
Рассмотрим еще одну полезную для понимания смещения и разброса иллюстрацию. На левом графике изобразим модели (каждая точка на графике — это прогноз одной модели), которые не очень хорошо описывают данные. Например, представим, что мы пытаемся описать полиномом первой степени зависимость, которая гораздо лучше описывается с помощью квадратичной функции.
Оценим прогнозы этих моделей в условной точке x = 5.

Коричневым цветом обозначены те «правильные» ответы, которые мы хотели бы получить. Свести их в одну точку мы не можем, потому что даже в идеальном случае мы можем получить прогноз с точностью до шума (случайных колебаний). Bias (фиолетовая стрелка) отражает ошибку, связанную с тем, что мы ошиблись с выбором модели (степень полинома). Разброс (зеленый цвет) — прогнозы моделей на нескольких обучающих выборках.
На правом графике, благодаря правильно подобранным (например, полином второй степени, снижает bias) и хорошо настроенным (снижает variance) моделям мы смогли существенно улучшить качество ответов.
Математика
Выразим три упомянутых компонента (смещение, разброс/дисперсия, шум) математически. Изначально мы хотим предсказать следующую зависимость.
$$ \hat{f}(X) = f(X) + \varepsilon, \varepsilon \sim N(0, \sigma_{\varepsilon}) $$
Ошибка в точке x равна
$$ Err(x) = E[(Y-\hat{f}(x))^2] $$
Ошибку можно разложить на
$$ Err(x) = \left( E[\hat{f}(x)]-f(x) \right)^2 + E \left[ \left( \hat{f}(x)-E[\hat{f}(x)] \right)^2 \right] + \sigma^2_{\varepsilon} $$
Что представляет собой
$$ Err(x) = Bias^2 + Variance + Noise $$
В случае дисперсии мы находим матожидание прогнозных значений различных моделей $E[\hat{f}(x)]$, вычитаем его из прогнозов моделей $\hat{f}(x)$, возводим в квадрат и находим матожидание отклонений.
Приведем разложение (здесь полезно вспомнить, что дисперсия равна матожиданию квадрата минус квадрат матожидания). Для простоты обозначим истинные значения как $y,$ прогнозные как $\hat{y}$.
$$ E(y-\hat{y})^2 = E(y^2 + \hat{y}^2-2y\hat{y}) = $$
$$ E(y^2)-(Ey)^2+(Ey)^2 + $$
$$ E(\hat{y}^2)-(E\hat{y})^2+(E\hat{y})^2-2(Ey\hat{y}) = $$
$$ Dy + D\hat{y} + (Ey)^2 +(E\hat{y})^2-2(Ey\hat{y}) = $$
$$ Dy + D\hat{y} + E(y-\hat{y})^2 $$
Как бороться с переобучением?
Сложная, переобученная модель может иметь очень много признаков (особенно если речь идёт о полиноме).
Очевидно, в большинстве случае визуальный подбор степени полинома (как мы это делали ранее для линейной и логистической полиномиальных регрессий) не представляется возможным. Более того, модели с таким количеством признаков в силу их высокой сложности (complexity) склонны к переобучению.
Бороться с этим можно тремя способами:
Первый вариант. Увеличить размер обучающей выборки. Маленькая выборка снижает обобщающую способность модели, а значит повышает разброс.
Второй вариант. Уменьшить количество признаков (вручную или через алгоритм, кроме того вводить наказание за новые признаки, как например, скорректированный коэффициент детерминации, adjusted R-square). Опасность здесь — выбросить нужные признаки.
Третий вариант. Использовать регуляризацию, которая позволяет снижать параметр (вес, коэффициент) признака и, таким образом, снижать его значимость. Предположим, что мы хотим уменьшить влияние второго признака в модели ниже.
$$ y = 15x_1 + 10x_2 + 5 \rightarrow y = 15x_1 + 5x_2 + 5 $$
Подобное изменение, как правило, приводит к тому, что модель меньше настраивается на шум (излишнюю вариативность) в обучающих данных и, как следствие, показывает лучшие результаты на тестовой выборке.
Другими словами, по сравнению с обычной линейной регрессией, у нее немного большее смещение (bias), но зато заметно меньший разброс (variance).
Три дополнительных соображения:
- Очевидно, что если мы снизим параметр признака до нуля, то этот признак будет удален из модели.
- Как правило, не имеет смысла применять регуляризацию к свободному коэффициенту $ \theta_0 $.
- Очень маленькие значения $\theta$ также могут повышать ошибку
Откроем ноутбук к этому занятию⧉
Регуляризация линейной регрессии
Рассмотрим несколько вариантов регуляризации линейной регрессии: Ridge, Lasso и Elastic Net.
Подготовка данных
Подгрузим данные о недвижимости в Бостоне, разделим на обучающую и тестовую части и выполним стандартизацию.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
boston = pd.read_csv(‘/content/boston.csv’) X = boston[[‘LSTAT’, ‘RM’, ‘PTRATIO’, ‘INDUS’]] y = boston.MEDV from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42) from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) |
Ordinary Least Squares
Построим регрессию без регуляризации методом наименьших квадратов и выведем RMSE на обучающей и тестовой выборках.
|
from sklearn.linear_model import LinearRegression ols = LinearRegression() ols.fit(X_train, y_train) y_pred_train = ols.predict(X_train) y_pred_test = ols.predict(X_test) from sklearn.metrics import mean_squared_error print(‘train: ‘ + str(mean_squared_error(y_train, y_pred_train, squared = False))) print(‘test: ‘ + str(mean_squared_error(y_test, y_pred_test, squared = False))) |
|
train: 5.255700309296848 test: 5.127682560624116 |
Ridge Regression
Функция потерь
Ридж-регрессия (ridge regression, гребневая регрессия) вводит наказание (penalty) за слишком большие коэффициенты. Это наказание представляет собой сумму коэффициентов $ \theta $, возведенных в квадрат (чтобы положительные и отрицательные значения не взаимоудалялись).
$$ J_{Ridge}(\theta) = MSE + \sum{\theta_i^2} $$
Опять же $\theta_0$ здесь не учитывается. В векторизованной форме,
$$ J_{Ridge}(\theta) = MSE + \theta^T \theta $$
Корень из скалярного произведения вектора на самого себя есть его длина. Так как в данном случае мы корень не извлекаем, то можем записать слагаемое регуляризации (regularization term) как
$$ J_{Ridge}(\theta) = MSE + || \theta ||^2_2 $$
Наконец, введем еще одно дополнение, параметр $\lambda$, который позволит нам контролировать силу воздействия этого слагаемого на уровень ошибки.
$$ J_{Ridge}(\theta) = MSE + \alpha \cdot || \theta ||^2_2 $$
Замечу также, что Ridge Regression также называют L2-регуляризацией, потому что она использует L2-норму в качестве соответствующего слагаемого. Посмотрим на иллюстрацию регуляризации.

При регуляризации у нас появляется, по сути, две функции ошибки: основная (синяя), наказывающая за отклонение истинных значений от прогнозных. и дополнительная (оранжевая), наказывающая за отклонение коэффициентов от нуля. Их сумму и будет пытаться минимизировать алгоритм.
Источник картинки и подробности здесь⧉.
Нормальные уравнения
Вспомним аналитическое решение задачи линейной регрессии.
$$ \theta = (X^TX)^{-1}X^Ty $$
В случае нормальных уравнений с L2-регуляризацией оптимальное решение можно найти через
$$ \theta = (X^TX + \alpha I)^{-1}X^Ty $$
$I$ представляет собой единичную матрицу размером $ (j+1) \times (j+1) $ с нулевым значением первого столбца первой строки (сдвиг), где $j$ — количество признаков.
Что интересно, регуляризация решает проблему вырожденных или необратимых матриц. Матрица будет вырожденной в случае, если количество признаков больше количества объектов и может быть необратима, если оно равно количеству объектов. Выражение $X^TX + \alpha I $ решает эту проблему.
Напишем собственный класс.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
class RidgeReg(): def __init__(self, alpha = 1.0): self.alpha = alpha self.thetas = None def fit(self, x, y): x = x.copy() x = self.add_ones(x) I = np.identity(x.shape[1]) I[0][0] = 0 self.thetas = np.linalg.inv(x.T.dot(x) + self.alpha * I).dot(x.T).dot(y) def predict(self, x): x = x.copy() x = self.add_ones(x) return np.dot(x, self.thetas) def add_ones(self, x): return np.c_[np.ones((len(x), 1)), x] |
|
ridge = RidgeReg(alpha = 10) ridge.fit(X_train, y_train) y_pred_train = ridge.predict(X_train) y_pred_test = ridge.predict(X_test) print(‘train: ‘ + str(mean_squared_error(y_train, y_pred_train, squared = False))) print(‘test: ‘ + str(mean_squared_error(y_test, y_pred_test, squared = False))) |
|
train: 5.258077962476522 test: 5.104623428412015 |
Ошибка на обучающей выборке немного выросла, на тесте немного уменьшилась. Сравним с sklearn.
|
from sklearn.linear_model import Ridge ridge = Ridge(alpha = 10) ridge.fit(X_train, y_train) y_pred_train = ridge.predict(X_train) y_pred_test = ridge.predict(X_test) print(‘train: ‘ + str(mean_squared_error(y_train, y_pred_train, squared = False))) print(‘test: ‘ + str(mean_squared_error(y_test, y_pred_test, squared = False))) |
|
train: 5.258077962476521 test: 5.104623428412015 |
Выведем изменение коэффициентов на графике.
|
features = X.columns plt.figure(figsize = (5, 5)) plt.plot(features, ridge.coef_, alpha=0.7, linestyle=‘none’ , marker=‘*’, markersize=5, color=‘red’, label=r‘Ridge; $\alpha = 10$’, zorder = 7) plt.plot(features, ols.coef_, alpha=0.4, linestyle=‘none’, marker=‘o’, markersize=7, color=‘green’,label=‘Linear Regression’) plt.xticks(rotation = 0) plt.legend() plt.show() |

Метод градиентного спуска
Эту же задачу можно решить методом градиентного спуска. Функция потерь в этом случае будет иметь вид
$$ J({\theta_j}) = \frac{1}{2n} \sum (y-\theta X)^2 + \frac{1}{2n} \lambda \theta^T \theta $$
Для градиентного спуска, чтобы не запутаться, обозначим коэффициент скорости обучения через $\alpha$, а параметр регуляризации через $\lambda$. При этом градиент будет равен
$$ \frac{\partial}{\partial \theta_j} J(\theta) = \left( -x_j(y-X\theta) + \lambda \theta \right) \times \frac{1}{n} $$
Нормализовывать сдвиг не обязательно (в первую очередь имеют значения наклоны). Здесь мы это делаем, чтобы упростить код. Перейдем к практике. Начнем с собственного класса.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
class RidgeGD(): def __init__(self, alpha = 0.0001): self.thetas = None self.loss_history = [] self.alpha = alpha def add_ones(self, x): return np.c_[np.ones((len(x), 1)), x] def objective(self, x, y, thetas, n): return (np.sum((y — self.h(x, thetas)) ** 2) + self.alpha * np.dot(thetas, thetas)) / (2 * n) def h(self, x, thetas): return np.dot(x, thetas) def gradient(self, x, y, thetas, n): return (np.dot(—x.T, (y — self.h(x, thetas))) + (self.alpha * thetas)) / n def fit(self, x, y, iter = 20000, learning_rate = 0.05): x, y = x.copy(), y.copy() x = self.add_ones(x) thetas, n = np.zeros(x.shape[1]), x.shape[0] loss_history = [] for i in range(iter): loss_history.append(self.objective(x, y, thetas, n)) grad = self.gradient(x, y, thetas, n) thetas -= learning_rate * grad self.thetas = thetas self.loss_history = loss_history def predict(self, x): x = x.copy() x = self.add_ones(x) return np.dot(x, self.thetas) |
|
ridge_gd = RidgeGD(alpha = 0.0001) ridge_gd.fit(X_train, y_train, iter = 50000, learning_rate = 0.01) y_pred_train = ridge_gd.predict(X_train) y_pred_test = ridge_gd.predict(X_test) print(‘train: ‘ + str(mean_squared_error(y_train, y_pred_train, squared = False))) print(‘test: ‘ + str(mean_squared_error(y_test, y_pred_test, squared = False))) |
|
train: 5.255700309301131 test: 5.127682311863072 |
Сравним с sklearn. Для того чтобы оптимизировать Ridge регрессию методом градиентного спуска, используем класс SGDRegressor с параметром penalty = ‘l2’. Кроме того, укажем другие параметры для того, чтобы применяемый алгоритм был максимально близок к написанному вручную.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from sklearn.linear_model import SGDRegressor ridge_gd = SGDRegressor(loss = ‘squared_error’, penalty = ‘l2’, alpha = 0.0001, max_iter = 50000, learning_rate = ‘constant’, eta0 = 0.001, random_state = 42) ridge_gd.fit(X_train, y_train) y_pred_train = ridge_gd.predict(X_train) y_pred_test = ridge_gd.predict(X_test) print(‘train: ‘ + str(mean_squared_error(y_train, y_pred_train, squared = False))) print(‘test: ‘ + str(mean_squared_error(y_test, y_pred_test, squared = False))) |
|
train: 5.25595467395471 test: 5.120506389637218 |
Выбор $\alpha$
Подобрать оптимальный гиперпараметр регуляризации можно, в частности, с помощью класса RidgeCV, который одновременно выполним оценку качества модели с помощью перекрестной валидации.
Темы перекрестной валидации и настройки гиперпараметров будут рассмотрены в курсе ML для продолжающих.
Приведем пример.
|
from sklearn.linear_model import RidgeCV # укажем параметры регуляризации alpha, которые хотим протестировать # дополнительно укажем количество частей (folds), параметр cv, # на которое нужно разбить данные при оценке качества модели ridge_cv = RidgeCV(alphas = [0.1, 1.0, 10], cv = 10) ridge_cv.fit(X_train, y_train) # выведем оптимальный параметр и достигнутое качество ridge_cv.alpha_, ridge_cv.best_score_ |
|
(10.0, 0.6482859868459572) |
Lasso Regression
Регрессия Lasso для регуляризации использует сумму весов по модулю, то есть L1-норму.
Сравнение L1 и L2 регуляризации
$$ J_{Lasso}(\theta) = MSE + \alpha \cdot || \theta ||_1 $$
Отличие заключается в том, что Ridge-регрессия при возведении $\theta$ в квадрат сильнее «наказывает» за большие коэффициенты, Lasso «наказывает» все коэффициенты одинаково. Например, если $\theta$ равен $ \begin{bmatrix} 10 \\ 5 \end{bmatrix} $, то в первом случае L2-регрессии penalty составит $ 10^2 + 5^2 = 125 $, в случае L1, только 15. При увеличении первого коэффициента на единицу L2-penalty составит $ 11^2 + 5^2 = 146 $, L1 увеличится до 16.
Одновременно этот пример показывает особую важность масштабирования признаков при использовании алгоритма с регуляризацией.
Обнуление коэффициентов
L1 регуляризация может полностью обнулить часть коэффициентов и, таким образом, исключить соответствующие признаки из модели. Эта особенность Lasso регрессии называется parameter sparcity.
Математика
Вначале рассмотрим модель с L2-регуляризацией с одним признаком и одним коэффициентом $\theta$.
$$ L_2 = (y-x\theta)^2+\alpha\theta^2 = y^2-2xy\theta+x^2\theta^2+\alpha\theta^2 $$
Найдем производную относительно $\theta$, приравняем ее к нулю и решим для $\theta$.
$$ \frac{\partial L_2}{\partial \theta} = -2xy + 2x^2\theta + 2\alpha\theta $$
$$ -2xy + 2x^2\theta + 2\alpha\theta = 0 $$
$$ \theta(x^2 + \alpha ) = xy $$
$$ \theta = \frac{xy}{(x^2 + \alpha)} $$
Коэффициент $\theta$ превратится в ноль для ненулевых значений x и y при $\alpha \rightarrow \inf$. Сравним с L1-регуляризацией. Найдем производную относительно $\theta,$ приравняем к нулю и решим для $\theta$ для случаев $\theta > 0$ (в точке ноль производная функции не определена).
$$ \frac{\partial L_1}{\partial \theta} = -2xy + 2x^2\theta + \alpha $$
$$ -2xy + 2x^2\theta + \alpha = 0 $$
$$ 2x^2\theta = 2xy-\alpha $$
$$ \theta = \frac{2xy-\alpha}{2x^2} $$
Сдалаем то же самое для случая, когда $\theta < 0$.
$$ \frac{\partial L_1}{\partial \theta} = -2xy + 2x^2\theta-\alpha $$
$$ -2xy + 2x^2\theta-\alpha = 0 $$
$$ 2x^2\theta = (\alpha + 2xy) $$
$$ \theta = \frac{\alpha + 2xy}{2x^2} $$
В обоих случаях при определенных x, y и $\alpha$ параметр $\theta$ может быть равен нулю.
Дополнительно сравним L2 и L1 нормы двух векторов $ \begin{bmatrix} 1 \\ 0 \end{bmatrix} $ и $ \begin{bmatrix} \frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} \end{bmatrix} $.
В случае L2-нормы, их длина будет равна единице. В случае L1-нормы длина первого вектора будет равна единце, а второго $\sqrt{2} \approx 1,41$. Таким образом, L1 регуляризация не только допускает, но и способствует обнулению коэффициентов.
Визуализация
Приведем классическую визуализацию границ двух видов регуляризации из книги T. Hastie The Elements of Statistical Learning⧉ (страница 71).

Изолинии отображают уровни ошибки при определенных параметрах $\theta$. Синий ромб и круг задают соответственно границу L1 и L2 регуляризации.
Координатный спуск
Как уже было замечено, производная функции абсолютной величины не определена в точке $x = 0$ и, как следствие, мы не можем использовать обычный алгоритм градиентного спуска.
При этом мы можем двигаться вниз на каждой итерации лишь вдоль одной из координат и остановиться, если этот шаг окажется меньше, чем некоторое заданное нами пороговое значение. Такой метод называется методом координатного спуска (coordinate descent).
Приведем иллюстрацию из Википедии⧉.

Выбрать, по какой координате спускаться можно разными способами, в частности, можно:
- выбирать признак (координату) случайным образом или
- просто идти от признака 0 до j (далее признаки мы будем обозначать так)
Рассмотрим как координатный спуск выглядит с точки зрения математики.
Математика
Итак, напомню, функция потерь будет иметь вид
$$ J_{Lasso}(\theta) = MSE + \alpha \cdot || \theta ||_1 $$
Вначале обратимся к первому компоненту, а именно MSE. Вспомним, чему равен градиент MSE.
$$ \frac{\partial J}{\partial \theta_j} = \frac{1}{n} \times -x_j(y-X\theta) $$
Перепишем $y-X\theta$ как $y-(\theta_kX_k+\theta_jx_j)$.
$$ \frac{1}{n} \times -x_j(y-(\theta_kX_k+\theta_jx_j)) $$
Другими словами, выделим ту координату j (признак), по которой мы будем спускаться в этот раз. $\theta_kX_k$ — это прогноз модели без коордианты j. Раскроем, а затем реорганизуем скобки.
$$ \frac{1}{n} \times -x_j((y-\theta_kX_k)-\theta_jx_j)$$
Умножим $-x_j$ на каждое из слагаемых.
$$ \frac{1}{n} \times -x_j((y-\theta_kX_k) + \theta_j x_j^2 $$
Обозначим компоненты через новые переменные $\rho$ («ро») и $z$.
$$ \rho_j = x_j((y-\theta_kX_k) $$
Примечание. Минус перед $x_j$ появится в окончательной формуле ниже.
$$ z_j = x_j^2 $$
Переменная $\rho$ по сути показывает насколько признак $x_j$ коррелирует с остатками модели $y-\theta_kX_k$, построенной без j. Если $\rho$ (т.е. корреляция) растет, значит этот признак важен для модели и его вес стоит увеличить.
Тогда выражение будет иметь вид
$$ \frac{\partial L}{\partial \theta_j} = -\frac{1}{n}\rho_j + \frac{1}{n} \theta_jz_j $$
Приравняв производную к нулю, найдем решение относительно $\theta_j$.
$$ \theta_j = \frac{\rho_j}{z_j} $$
Замечу, что $z_j$, то есть скалярное произведение вектора признака $x_j$ самого на себя, будет равно единице, если признаки будут предварительно нормализованы (приведены к единичной L2 норме).
Обратимся ко второму компоненту, слагаемому регуляризации. Так как производная в точке $|\theta_j| = 0$ не определена, воспользуемся таким понятием как субградиент (subgradient). По сути, субградиентом является множество возможных градиентов в определенной точке. Приведем иллюстрацию для субградиентов в точке $|\theta_j| = 0$.

Как видно, субградиенты могут принимать значения $[-1, 1]$ (градиенты функции абсолютного значения) или вернее от $[-\alpha, \alpha]$, то есть параметра, на который мы умножаем слагаемое регуляризации.
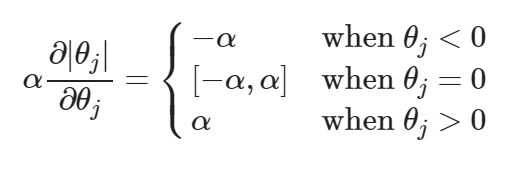
Объединим две производных.

Рассмотрим каждый из трех случаев по отдельности.
Вариант 1. $\theta_j < 0$
$$ -\frac{1}{n}\rho_j + \frac{1}{n} \theta_jz_j-\alpha = 0 $$
$$ \theta_j = \frac{\rho_j + n\alpha}{z_j} $$
Для того чтобы $\theta_j < 0$, необходимо чтобы $\rho_j < n\alpha $
Вариант 2. $\theta_j = 0$
$$ -\frac{1}{n}\rho_j + \frac{1}{n} \theta_jz_j + [-\alpha, \alpha] = 0 $$
$$ \theta_j = \left[ \frac{\rho_j-n\alpha}{z_j}, \frac{\rho_j + n\alpha}{z_j} \right] $$
Для того чтобы $ \theta_j = 0 $, $ -n\alpha\ \leq \rho_j \leq n\alpha $.
Вариант 3. $\theta_j > 0$
$$ -\frac{1}{n}\rho_j + \frac{1}{n} \theta_jz_j + \alpha = 0 $$
$$ \theta_j = \frac{\rho_j-n\alpha}{z_j} $$
Для того чтобы $\theta_j > 0$, $\rho_j > n\alpha $
Сдвиг $\theta_0$ не регуляризуется и изменяется с помощью частной производной MSE (первое слагаемое).
$$ \theta_0 = \frac{\rho_0}{z_0} $$
Таким образом, шаги алгоритма координатного спуска будут следующими:
Шаг 1. Добавить первый (!) столбец из единиц для коэффициента $\theta_0$. Инициализировать веса $\theta$.
Шаг 2. Рассчитать $z_j$.
$$ z_j = \sum x_j^2 $$
Шаг 3. Задать начальный максимальный размер шага (max_step) и пороговое значение (tolerance)
Шаг 4. Пока максимальный размер шага больше порогового значения проходиться в цикле по каждой из координат (признаку), рассчитать $ \rho_j = \sum x_j((y-\theta_kX_k) $ и обновлять вес $\theta$ этого признака в соответствии со следующими правилами:
Если j = 0, то есть первого по счету коэффициента $\theta_0$, то $\theta_j = \frac{ρ_j}{z_j}$.
В остальных случаях
$$ \theta_j = \left\{ \begin{matrix} \frac{\rho_j + n \alpha}{z_j} & if & \rho_j < -n \alpha \\ 0 & if & -n \alpha ≤ \rho_j ≤ n \alpha \\ \frac{\rho_j-n \alpha}{z_j} & if & \rho_j > n \alpha \end{matrix} \right. $$
Обратите внимание, если $ -n\alpha\ \leq \rho_j \leq n\alpha $ (то есть корреляция признака очень мала по модулю), то коэффициент будет обнулен и исключен из модели. В двух других случаях (варианты 1 и 3), мы будем увеличивать коэффициент при большом отрицательном $\rho_j$ и уменьшать при большом положительном (т.е. выполнять регуляризацию). Посмотрим на график ниже.

Такое ограничение называется мягким порогом (soft thresholding). Приведем для сравнения Ridge регрессию, которая сокращает коэффициенты на всем диапазоне $\theta$, но не приводит их к нулевым значениям.
Реализация на Питоне
Объявим вспомогательные функции.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# добавим столбец из единиц в матрицу признаков def add_ones(x): return np.c_[np.ones((len(x), 1)), x] # объявим функцию гипотезы def h(x, theta): # 506 х (4 + 1) на (4 + 1) х 1 return np.matmul(x, theta) # 506 x 1 # рассчитаем rho_j def rho(y, x, theta, j): # удалим признак (координату) j из матрицы признаков и вектора весов x_k = np.delete(x, j, 1) theta_k = np.delete(theta ,j) # сделаем прогноз без j y_pred_k = h(x_k, theta_k) # найдем остатки при прогнозе без j residuals_k = y — y_pred_k # вычислим rho_j rho_j = np.sum(x[:,j] * residuals_k) return rho_j # рассчитаем z def compute_z(x): # рассчитаем z (т.е. L2 норму) для каждого столбца (axis = 0) z_vector = np.sum(x * x, axis = 0) return z_vector |
Объявим функцию координатного спуска.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
def coordinate_descent(x, y, alpha = 0.1, tolerance = 0.0001): x = add_ones(x) theta = np.zeros(x.shape[1], dtype = float) z = compute_z(x) max_step = 100. iterations = 0 # tolerance — пороговое значение, если шаг меньше, остановимся while(max_step > tolerance): iterations += 1 old_theta = np.copy(theta) # поочередно выберем каждый из признаков for j in range(len(theta)): # рассчитаем rho_j rho_j = rho(y, x, theta, j) # пропишем обновление для сдвига (первый по счету коэффициент) if j == 0: theta[j] = rho_j / z[j] # пропишем обновления для остальных признаков elif rho_j < —alpha * len(y): theta[j] = (rho_j + (alpha * len(y))) / z[j] elif rho_j > —alpha * len(y) and rho_j < alpha * len(y): theta[j] = 0. elif rho_j > alpha * len(y): theta[j] = (rho_j — (alpha*len(y))) / z[j] # запишем текущий максимальный для всех координат (!!!) размер шага # (обратите внимание, код ниже выполняется после цикла for) step_sizes = abs(old_theta — theta) max_step = step_sizes.max() return theta, iterations, max_step |
Протестируем алгоритм.
|
theta_opt, iterations, max_step = coordinate_descent(X_train, y_train, alpha = 0.2, tolerance = 0.0001) np.set_printoptions(precision = 3, suppress = True) print(«Intercept is:»,theta_opt[0]) print(«\nCoefficients are:\n»,theta_opt[1:]) print(«\nNumber of iterations is:», iterations) |
|
Intercept is: 23.01581920903955 Coefficients are: [-4.228 3.107 -1.811 0. ] Number of iterations is: 11 |
Мы видим, что модель сочла признак INDUS не имеющим значения для данной модели и обнулила соответствующий коэффициент. Сравним с классом Lasso библиотеки sklearn.
|
from sklearn.linear_model import Lasso lasso = Lasso(alpha = 0.2, tol = 0.0001) lasso.fit(X_train, y_train) print(«sklearn Lasso intercept :»,lasso.intercept_) print(«\nsklearn Lasso coefficients :\n»,lasso.coef_) print(«\nsklearn Lasso number of iterations :»,lasso.n_iter_) |
|
sklearn Lasso intercept : 23.01581920903955 sklearn Lasso coefficients : [-4.228 3.107 -1.811 0. ] sklearn Lasso number of iterations : 10 |
Elastic Net Regression
Регрессия Elastic Net использует как L1, так и L2 регуляризацию.
$$ J_{ElasticNet}(\theta) = MSE + \alpha_1 \cdot || \theta ||_1 + \alpha_2 \cdot || \theta ||_2^2 $$
Так как в этой модели есть компонент L-1, для которого в точке $|\theta_j| = 0$ производная не определена, используем один из возможных субградиентов, а именно нулевой субградиент (красная пунктирная линия $g_3$ на рисунке выше).
Другими словами, субградиент для компонента будет выглядеть следующим образом
$$ \frac{\partial J_{L1}}{\partial_{sub} \theta} = \left\{ \begin{matrix} 1 & if & \theta > 0 \\ 0 & if & \theta = 0 \\ -1 & if & \theta < 0 \end{matrix} \right. $$
Это условие соответствует сигнум-функции или функции знака (sign function⧉). На Питоне можно использовать np.sign().
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
class ElasticNet(): def __init__(self, a1 = 0.1, a2 = 0.1): self.thetas = None self.loss_history = [] self.a1 = a1 self.a2 = a2 def add_ones(self, x): return np.c_[np.ones((len(x), 1)), x] def objective(self, x, y, thetas, n): return (np.sum((y — self.h(x, thetas)) ** 2) + self.a1 * np.sum(np.abs(thetas)) + self.a2 * np.dot(thetas, thetas)) / (2 * n) def h(self, x, thetas): return np.dot(x, thetas) def gradient(self, x, y, thetas, n): return (np.dot(—x.T, (y — self.h(x, thetas))) + (self.a1 * np.sign(thetas)) + (self.a2 * thetas)) / n def fit(self, x, y, iter = 20000, learning_rate = 0.05): x, y = x.copy(), y.copy() x = self.add_ones(x) thetas, n = np.zeros(x.shape[1]), x.shape[0] loss_history = [] for i in range(iter): loss_history.append(self.objective(x, y, thetas, n)) grad = self.gradient(x, y, thetas, n) thetas -= learning_rate * grad self.thetas = thetas self.loss_history = loss_history def predict(self, x): x = x.copy() x = self.add_ones(x) return np.dot(x, self.thetas) |
|
elastic = ElasticNet() elastic.fit(X_train, y_train, iter = 50000, learning_rate = 0.01) y_pred_train = elastic.predict(X_train) y_pred_test = elastic.predict(X_test) print(‘train: ‘ + str(mean_squared_error(y_train, y_pred_train, squared = False))) print(‘test: ‘ + str(mean_squared_error(y_test, y_pred_test, squared = False))) |
|
train: 5.255705191138267 test: 5.127348870379186 |
|
array([23.009, -4.473, 3.219, -1.998, 0.317]) |
Сравним с классом ElasticNet библиотеки sklearn.
|
from sklearn.linear_model import ElasticNet elastic = ElasticNet(alpha = 0.05) elastic.fit(X_train, y_train) elastic.fit(X_train, y_train) y_pred_train = elastic.predict(X_train) y_pred_test = elastic.predict(X_test) print(‘train: ‘ + str(mean_squared_error(y_train, y_pred_train, squared = False))) print(‘test: ‘ + str(mean_squared_error(y_test, y_pred_test, squared = False))) |
|
train: 5.259317264886122 test: 5.100827371724984 |
|
elastic.intercept_, elastic.coef_ |
|
(23.01581920903955, array([-4.287, 3.179, -1.944, 0.146])) |
Замечу, что класс ElasticNet библиотеки sklearn использует координатный спуск для минимизации функции потерь. Кроме того, в документации можно посмотреть, как единственный параметр $\alpha$ регулирует значимость L1 и L2 компонентов.
Регуляризация нейросети
В качестве иллюстрации приведем примеры L2 регуляризации нейронной сети.
Функция потерь с регуляризацией
Посмотрим на функцию потерь с учетом регуляризации (бинарная классификация)
$$ J_{reg}(W) = -\frac{1}{n} \sum y \cdot log(a^{(L)}) + (1-y) \cdot log(1-a^{(L)}) + $$
$$ + \frac{\alpha}{2n} \sum_l \sum_k \sum_j W^{(l)}_{k,j} $$
Уточним нотацию, мы находим уровень ошибки на основе значений выходного слоя $a^{(L)}$. Кроме того, мы добавляем значение регуляризации, которое рассчитывается как сумма $\sum_l$ сумм весов слоев $k$ и $j$ ($\sum_k$ и $\sum_j$). Приведем код.
|
def objective(y, y_pred, n, alpha): y_one_loss = y * np.log(y_pred + 1e—9) y_zero_loss = (1 — y) * np.log(1 — y_pred + 1e—9) log_loss = — np.sum(y_zero_loss + y_one_loss) / n # по умолчанию np.sum() складывает по всем измерениям reg_loss = (np.sum(W1**2) + np.sum(W2**2)) * alpha / (2 * n) return log_loss + reg_loss |
Реализуем модель с регуляризацией на Питоне на основе уже созданного алгоритма бинарной классификации со смещением с двумя признаками и одним скрытым слоем (три нейрона) и сравним результаты обучения.
Подготовка данных
|
from sklearn import datasets data = datasets.load_wine() df = pd.DataFrame(data.data, columns = data.feature_names) df[‘target’] = data.target df = df[df.target != 2] X = df[[‘alcohol’, ‘proline’]] y = df[‘target’] X = (X — X.mean()) / X.std() X = X.to_numpy().T y = y.to_numpy().reshape(1, —1) |
Обучение модели
Обучим модель.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
def sigmoid(z): s = 1 / (1 + np.exp(—z)) return s np.random.seed(33) W1 = np.random.randn(3, 2) b1 = np.random.randn(3, 1) W2 = np.random.randn(1, 3) b2 = np.random.randn(1, 1) n = X.shape[1] epochs = 100000 learning_rate = 1 alpha = 0.1 A1 = X for i in range(epochs): # 3 х 2 на 2 х 130 Z1 = np.dot(W1, A1) + b1 A2 = sigmoid(Z1) # (3 x 130) # 1 х 3 на 3 х 130 Z2 = np.dot(W2, A2) + b2 A3 = sigmoid(Z2) # (1 x 130) loss = objective(A3, y, n, alpha) W2_delta = A3 — y # (1 x 130) W1_delta = np.dot(W2.T, W2_delta) * A2 * (1 — A2) # (3 x 130) # 1 х 130 на 130 х 3 W2_derivative = (np.dot(W2_delta, A2.T) + alpha * W2) / n # (1 x 3) b2_derivative = np.sum(W2_delta, keepdims = True) / n # (1 x 1) # 3 х 130 на 130 х 2 W1_derivative = (np.dot(W1_delta, A1.T) + alpha * W1) / n # (3 x 2) b1_derivative = np.sum(W1_delta, keepdims = True) / n # (1 x 1) W2 = W2 — learning_rate * W2_derivative b2 = b2 — learning_rate * b2_derivative W1 = W1 — learning_rate * W1_derivative b1 = b1 — learning_rate * b1_derivative if i % (epochs / 5) == 0: print(‘Эпоха:’, i) print(‘Ошибка:’, loss) print(‘————————‘) time.sleep(0.5) print(‘Итоговая ошибка’, loss) print(‘Нейросеть успешно обучена’) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
Эпоха: 0 Ошибка: 10.082518872092187 ———————— Эпоха: 20000 Ошибка: 1.1736216908788164 ———————— Эпоха: 40000 Ошибка: 1.1736172913272431 ———————— Эпоха: 60000 Ошибка: 1.173617288499269 ———————— Эпоха: 80000 Ошибка: 1.1736172884974607 ———————— Итоговая ошибка 1.1736172884974607 Нейросеть успешно обучена |
Сделаем прогноз.
|
from sklearn.metrics import accuracy_score Z1 = np.matmul(W1, A1) + b1 A2 = sigmoid(Z1) Z2 = np.matmul(W2, A2) + b2 A3 = sigmoid(Z2) y_pred, y_true = A3.flatten() > 0.5, y.flatten() accuracy_score(y_true, y_pred) |
Выведем веса.
|
(array([[-1.757, -2.494], [-1.525, -1.663], [ 1.479, 1.653]]), array([[ 4.543, 3.227, -3.486]])) |
По сравнению с моделью без регуляризаци, точность на обучающей выборке, а также веса модели снизились.
Регуляризация в библиотеке Keras
Приведем регуляризацию модели в библиотеки Keras.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
np.random.seed(42) tf.random.set_seed(42) model = tf.keras.models.Sequential([ tf.keras.layers.Dense(3, activation = ‘sigmoid’, use_bias = True, kernel_regularizer = tf.keras.regularizers.l2(0.01)), tf.keras.layers.Dense(1, activation = ‘sigmoid’, use_bias = True, kernel_regularizer = tf.keras.regularizers.l2(0.01)) ]) sgd = tf.keras.optimizers.SGD(learning_rate = 1, momentum = 0, nesterov = False) model.compile(optimizer = sgd, loss = ‘binary_crossentropy’, metrics = [‘accuracy’]) model.fit(X.T, y.T, epochs = 10000, batch_size = 130, verbose = 0) model.summary() |
|
Model: «sequential_2» _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_4 (Dense) (130, 3) 9 dense_5 (Dense) (130, 1) 4 ================================================================= Total params: 13 Trainable params: 13 Non-trainable params: 0 _________________________________________________________________ |
|
model.history.history[‘accuracy’][—1] |
В целом регуляризаторы в Keras можно задавать следующим образом.
|
# l1, l2 и ElasticNet tf.keras.regularizers.l1(0.) tf.keras.regularizers.l2(0.) tf.keras.regularizers.l1_l2(l1 = 0.01, l2 = 0.01) |
Подведем итог
На сегодняшнем занятии мы изучили концепции смещения и разброса модели, рассмотрели принцип L1 и L2 регуляризации и протестировали регуляризацию на линейной регрессии и нейросети. Также мы познакомились с алгоритмами координатного и субградиентного спуска.
В заключение, приведем советы Эндрю Ына по тому, что делать, если модель не показывает нужные результаты (то есть имеет высокое смещение или разброс):
- увеличить обучающую выборку
- уменьшить количество признаков
- найти или создать новые признаки
- использовать полиномиальные признаки или увеличить количество слоев/нейронов в нейросети
- уменьшить или увеличить параметр регуляризации $ \alpha $
Дополнительные материалы
Бэггинг для снижения разброса
Нам не обязательно использовать прогноз только одной модели. Можно взять группу или ансамбль (от франц. ensemble — «вместе») моделей.
На курсе «ML для продолжающих» мы поговорим про техники ансамблирования (ensemble methods) или объединения алгоритмов.
Сейчас же давайте рассмотрим один из этих способов, а именно бэггинг (bagging) и постараемся с его помощью снизить разброс модели.
Про бэггинг
Бэггинг (bagging) или bootstrap aggregating предполагает три основных шага:
- Bootstrapping. За счет случайных выборок с возвращением (random samples with replacement) создается несколько датасетов на основе исходных данных (subsets). Это означает, что в каждом датасете могут быть как повторяющиеся объекты, так и объекты из других датасетов.
- Parallel training. Затем модели (их называют базовыми моделями, base estimators, или weak learners) обучаются параллельно и независимо друг от друга.
- Aggregation. Наконец, в зависимости от типа задачи, т.е. регрессии или классификации, рассчитывается, соответственно, среднее значение (soft voting) или класс, предсказанный большинством (hard/majority voting).
Алгоритм решающего дерева
Рассмотрение решающих деревьев (decision trees), алгоритма, который мы будем использовать внутри бэггинга, выходит за рамки сегодняшнего занятия. Мы начали знакомиться с этой темой на занятии работе с выбросами и более детально изучим на последующих курсах.
При этом будет важно сказать, что одним из недостатков этого алгоритма (когда используется только одно дерево) как раз является склонность к переобучению и высокий разброс модели. Посмотрим, сможет ли бэггинг исправить ситуацию.
Подготовка данных
Используем данные о пациентах с диабетом.
|
diabetes = pd.read_csv(‘/content/diabetes.csv’) diabetes.head() |
|
X = diabetes.drop(columns = ‘Outcome’) y = diabetes.Outcome X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42) |
|
from sklearn.tree import DecisionTreeClassifier model = DecisionTreeClassifier(max_depth = 10, random_state = 42) model.fit(X_train, y_train) y_pred_train = model.predict(X_train) y_pred_test = model.predict(X_test) print(‘train: ‘ + str(accuracy_score(y_train, y_pred_train))) print(‘test: ‘ + str(accuracy_score(y_test, y_pred_test))) |
|
train: 0.9795158286778398 test: 0.696969696969697 |
|
from sklearn.ensemble import BaggingClassifier # в версии sklearn 1.2 параметр называет estimator bag_model = BaggingClassifier(base_estimator = model, n_estimators = 100, bootstrap = True, # выборка с возвращением random_state = 42) bag_model.fit(X_train, y_train) y_pred_train = bag_model.predict(X_train) y_pred_test = bag_model.predict(X_test) print(‘train: ‘ + str(accuracy_score(y_train, y_pred_train))) print(‘test: ‘ + str(accuracy_score(y_test, y_pred_test))) |
|
train: 1.0 test: 0.7532467532467533 |
Полезные ссылки
Bias-variance decomposition⧉
Ансамбли в машинном обучении⧉
Перейдем к теме градиентного спуска.