2.4. Точность статистического наблюдения
Под точностью статистического наблюдения понимают степень соответствия значения наблюдаемого показателя, вычисленного по материалам обследования, его действительной величине. Расхождение, или разница, между ними называется ошибкой статистического наблюдения.
Различают две группы ошибок:
- ошибки регистрации;
- ошибки репрезентативности.
Ошибки регистрации присущи любому статистическому наблюдению, как сплошному, так и несплошному. Они делятся на случайные ошибки регистрации и систематические ошибки регистрации.
Случайными ошибками регистрации называют ошибки, возникающие вследствие действия случайных факторов. К ним можно отнести различного рода непреднамеренные описки: например, вместо возраста человека «15 лет» указано «5 лет», у Ивановой Марии Петровны в графе пол отмечен «Мужской» и т. п. Такие ошибки легко выявляются методом логического анализа, например, если человеку 8 лет, но имеется высшее образование, а в графе «Семейное положение» указано «Состоит в браке», то, естественно, следует исправить возраст. Если объем исследуемой совокупности велик или велика доля отбора при выборочном наблюдении, случайные ошибки регистрации имеют тенденцию взаимопогашаться вследствие действия закона больших чисел, поскольку ошибки, как правило, разнонаправлены и искажают статистический показатель как в большую, так и в меньшую сторону. При небольшом объеме наблюдения требуется тщательная выверка его результатов — логический анализ данных.
Систематические ошибки регистрации чаще всего имеют однонаправленные искажения: они либо увеличивают, либо уменьшают статистический показатель, и, что характерно, подобная ситуация повторяется от обследования к обследованию. Так, по результатам переписей (практически всех!) число замужних женщин превышает число женатых мужчин — мужчинам приятнее ощущать себя неженатыми, а для женщины как бы «стыдно» быть не замужем. Другой пример, когда человек округляет свой возраст — вместо 32 лет говорит 30, вместо 79-80 и т. п. (это явление широко известно и даже получило свое название — «аккумуляция возрастов»). Систематические ошибки регистрации могут возникать и из-за неточностей измерительных приборов, если сбор информации проводят путем непосредственного наблюдения.
Ошибки репрезентативности присущи только несплошному обследованию. Они также делятся на случайные и систематические ошибки.
Случайные ошибки репрезентативности возникают из-за того, что обследованию подвергается не вся совокупность в целом, а только ее часть, и, следовательно, при несплошном наблюдении они присутствуют всегда. В теории статистики разработаны специальные методы для оценки величин таких ошибок, на их основе для наблюдаемых показателей строят доверительные интервалы, т.д. эти ошибки вычисляются и находятся как бы «под контролем».
Хуже обстоит дело, если наряду со случайными ошибками имеются и ошибки систематические.
Систематические ошибки репрезентативности возникают, если при несплошном наблюдении кардинально нарушаются технологии отбора единиц из генеральной совокупности объектов, но чаще — если в ходе обследования не удается получить информацию обо всех отобранных для наблюдения единицах, например, вследствие отказа отвечать на вопросы анкеты, или если человека не удалось застать дома и т. п.
Ошибки статистического наблюдения для наглядности можно изобразить в виде схемы (рис. 2.1).
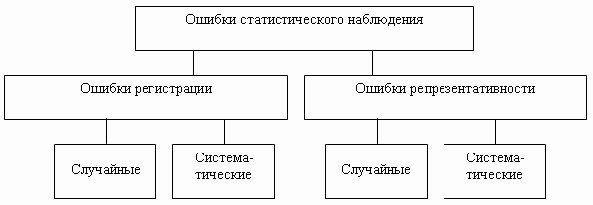
Рис.
2.1.
Виды ошибок статистического наблюдения
Для повышения точности наблюдения необходимо:
- правильно разработать формуляр статистического наблюдения: вопросы должны быть четкими, однозначными, не допускающими двойного толкования;
- иметь хорошо обученный персонал для проведения обследования;
- строго придерживаться выбранной технологии обследования (если проводится несплошное наблюдение) и помнить, что если не удается опросить какую-то конкретную единицу, отобранную для наблюдения, замена ее на другую единицу может привести к возникновению систематической ошибки репрезентативности;
- провести логический анализ данных, основанный на логических взаимосвязях показателей, после сбора всей совокупности анкет или формуляров;
- целесообразно провести и арифметический контроль данных, т.д. заново пересчитать расчетные величины, если какие-либо показатели получаются в результате определенных арифметических действий;
- предпринять определенные меры по восстановлению данных при наличии незаполненных анкет или формуляров либо при получении результатов обследования сделать поправку на неответы респондентов.
Расхождения
между величиной какого-либо показателя,
найденного посредством статистического
наблюдения, и действительными его
размерами называются ошибками
наблюдения.В зависимости от
причин возникновения различают ошибки
регистрации и ошибки репрезентативности.
Ошибки
регистрациивозникают в результате
неправильного установления фактов или
ошибочной записи в процессе наблюдения
или опроса. Они бывают случайными или
систематическими. Случайные ошибки
регистрации могут быть допущены как
опрашиваемыми в их ответах, так и
регистраторами. Систематические ошибки
могут быть и преднамеренными, и
непреднамеренными. Преднамеренные –
сознательные, тенденциозные искажения
действительного положения дела.
Непреднамеренные вызываются различными
случайными причинами (небрежность,
невнимательность).
Ошибки
репрезентативности(представительности)
возникают в результате неполного
обследования и в случае, если обследуемая
совокупность недостаточно полно
воспроизводит генеральную совокупность.
Они могут быть случайными и систематическими.
Случайные ошибки репрезентативности
– это отклонения, возникающие при
несплошном наблюдении из-за того, что
совокупность отобранных единиц наблюдения
(выборка) неполно воспроизводит всю
совокупность в целом. Систематические
ошибки репрезентативности – это
отклонения, возникающие вследствие
нарушения принципов случайного отбора
единиц. Ошибки репрезентативности
органически присущи выборочному
наблюдению и возникают в силу того, что
выборочная совокупность не полностью
воспроизводит генеральную. Избежать
ошибок репрезентативности нельзя,
однако, пользуясь методами теории
вероятностей, основанными на использовании
предельных теорем закона больших чисел,
эти ошибки можно свести к минимальным
значениям, границы которых устанавливаются
с достаточно большой точностью.
Ошибки
выборки –разность между
характеристиками выборочной и генеральной
совокупности. Для среднего значения
ошибка будет определяться по формуле
![]()
(7.1)
где
![]()
Величина
![]() называетсяпредельной ошибкойвыборки.
называетсяпредельной ошибкойвыборки.
Предельная
ошибка выборки – величина случайная.
Исследованию закономерностей случайных
ошибок выборки посвящены предельные
теоремы закона больших чисел. Наиболее
полно эти закономерности раскрыты в
теоремах П. Л. Чебышева и А. М. Ляпунова.
Теорему П.
Л. Чебышева применительно к
рассматриваемому методу можно
сформулировать следующим образом: при
достаточно большом числе независимых
наблюдений можно с вероятностью, близкой
к единице (т. е. почти с достоверностью),
утверждать, что отклонение выборочной
средней от генеральной будет сколько
угодно малым. В теореме П. Л. Чебышева
доказано, что величина ошибки не должна
превышать![]() .
.
В свою очередь величина![]() ,
,
выражающая среднее квадратическое
отклонение выборочной средней от
генеральной средней, зависит от
колеблемости признака в генеральной
совокупности![]() и числа отобранных единицn. Эта
и числа отобранных единицn. Эта
зависимость выражается формулой
![]() ,
,
(7.2)
где
![]() зависит также от способа производства
зависит также от способа производства
выборки.
Величину
![]() =
=![]() называютсредней ошибкой выборки. В
называютсредней ошибкой выборки. В
этом выражении![]() – генеральная дисперсия,n– объем
– генеральная дисперсия,n– объем
выборочной совокупности.
Рассмотрим, как
влияет на величину средней ошибки число
отбираемых единиц n. Логически
нетрудно убедиться, что при отборе
большого числа единиц расхождения между
средними будут меньше, т. е. существует
обратная связь между средней ошибкой
выборки и числом отобранных единиц. При
этом здесь образуется не просто обратная
математическая зависимость, а такая
зависимость, которая показывает, что
квадрат расхождения между средними
обратно пропорционален числу отобранных
единиц.
Увеличение
колеблемости признака влечет за собой
увеличение среднего квадратического
отклонения, а следовательно, и ошибки.
Если предположить, что все единицы будут
иметь одинаковую величину признака, то
среднее квадратическое отклонение
станет равно нулю и ошибка выборки
также исчезнет. Тогда нет необходимости
применять выборку. Однако следует иметь
в виду, что величина колеблемости
признака в генеральной совокупности
неизвестна, поскольку неизвестны размеры
единиц в ней. Можно рассчитать лишь
колеблемость признака в выборочной
совокупности. Соотношение между
дисперсиями генеральной и выборочной
совокупности выражается формулой
![]()
Поскольку
величина
![]() при достаточно большихnблизка к
при достаточно большихnблизка к
единице, можно приближенно считать, что
выборочная дисперсия равна генеральной
дисперсии, т. е.![]()
Следовательно,
средняя ошибка выборки показывает,
какие возможны отклонения характеристик
выборочной совокупности от соответствующих
характеристик генеральной совокупности.
Однако о величине этой ошибки можно
судить с определенной вероятностью. На
величину вероятности указывает множитель
![]()
Теорема А.
М. Ляпунова. А. М. Ляпунов доказал,
что распределение выборочных средних
(следовательно, и их отклонений от
генеральной средней) при достаточно
большом числе независимых наблюдений
приближенно нормально при условии, что
генеральная совокупность обладает
конечной средней и ограниченной
дисперсией.
Математически
теорему Ляпуноваможно записать
так:
 (7.3)
(7.3)
где
![]() ,
,
(7.4)
где ![]() – математическая постоянная;
– математическая постоянная;
![]() –предельная ошибка выборки,которая дает возможность выяснить, в
–предельная ошибка выборки,которая дает возможность выяснить, в
каких пределах находится величина
генеральной средней.
Значения этого
интеграла для различных значений
коэффициента доверия tвычислены и
приводятся в специальных математических
таблицах. В частности, при:

Поскольку tуказывает на вероятность расхождения![]() ,
,
т. е. на вероятность того, на какую
величину генеральная средняя будет
отличаться от выборочной средней, то
это может быть прочитано так: с вероятностью
0,683 можно утверждать, что разность между
выборочной и генеральной средними не
превышает одной величины средней ошибки
выборки. Другими словами, в 68,3 % случаев
ошибка репрезентативности не выйдет
за пределы![]() С вероятностью 0,954 можно утверждать,
С вероятностью 0,954 можно утверждать,
что ошибка репрезентативности не
превышает![]() (т. е. в 95 % случаев). С вероятностью
(т. е. в 95 % случаев). С вероятностью
0,997, т. е. довольно близкой к единице,
можно ожидать, что разность между
выборочной и генеральной средней не
превзойдет трехкратной средней ошибки
выборки и т. д.
Логически связь
здесь выглядит довольно ясно: чем больше
пределы, в которых допускается
возможная ошибка, тем с большей
вероятностью судят о ее величине.
Зная выборочную
среднюю величину признака
![]() и предельную ошибку выборки
и предельную ошибку выборки![]() ,
,
можно определить границы (пределы),
в которых заключена генеральная
средняя
![]() (7.5)
(7.5)
1.
Собственно-случайная выборка–
этот способ ориентирован на выборку
единиц из генеральной совокупности без
всякого расчленения на части или группы.
При этом для соблюдения основного
принципа выборки – равной возможности
всем единицам генеральной совокупности
быть отобранным – используются схема
случайного извлечения единиц путем
жеребьевки (лотереи) или таблицы случайных
чисел. Возможен повторный и бесповторный
отбор единиц
Средняя ошибка
собственно-случайной выборки
представляет собой среднеквадратическое
отклонение возможных значений выборочной
средней от генеральной средней. Средние
ошибки выборки при собственно-случайном
методе отбора представлены в табл. 7.2.
Таблица 7.2
|
Средняя ошибка |
При отборе |
|
|
повторном |
бесповторном |
|
|
Для средней |
|
|
|
Для доли |
|
|

В таблице
использованы следующие обозначения:
![]() – дисперсия выборочной совокупности;
– дисперсия выборочной совокупности;
![]() – численность выборки;
– численность выборки;
![]() – численность генеральной совокупности;
– численность генеральной совокупности;
![]() – выборочная доля единиц, обладающих
– выборочная доля единиц, обладающих
изучаемым признаком;
![]() – число единиц, обладающих изучаемым
– число единиц, обладающих изучаемым
признаком;
![]() – численность выборки.
– численность выборки.
Для увеличения
точности вместо множителя
![]() следует
следует
брать множитель
![]() ,
,
но при большой численностиNразличие
между этими выражениями практического
значения не имеет.
Предельная
ошибка собственно-случайной выборки
![]() рассчитывается по формуле
рассчитывается по формуле
![]() ,
,
(7.6)
где t
– коэффициент доверия зависит от
значения вероятности.
Пример.При
обследовании ста образцов изделий,
отобранных из партии в случайном порядке,
20 оказалось нестандартными. С вероятностью
0,954 определите пределы, в которых
находится доля нестандартной продукции
в партии.
Решение.
Вычислим генеральную долю (Р):
![]() .
.
Доля нестандартной
продукции:
 .
.
Предельная
ошибка выборочной доли с вероятностью
0,954 рассчитывается по формуле (7.6) с
применением формулы табл. 7.2 для доли:

![]()
С вероятностью
0,954 можно утверждать, что доля нестандартной
продукции в партии товара находится в
пределах 12 % ≤ P≤ 28 %.
В практике
проектирования выборочного наблюдения
возникает потребность определения
численности выборки, которая необходима
для обеспечения определенной точности
расчета генеральных средних. Предельная
ошибка выборки и ее вероятность при
этом являются заданными. Из формулы
![]() и формул средних ошибок выборки
и формул средних ошибок выборки
устанавливается необходимая численность
выборки. Формулы для определения
численности выборки (n) зависят от
способа отбора. Расчет численности
выборки для собственно-случайной выборки
приведен в табл. 7.3.
Таблица 7.3
|
Предполагаемый |
Формулы |
|
|
для средней |
для доли |
|
|
Повторный |
|
|
|
Бесповторный |
|
|



2.
Механическая выборка– при этом
методе исходят из учета некоторых
особенностей расположения объектов в
генеральной совокупности, их упорядоченности
(по списку, номеру, алфавиту). Механическая
выборка осуществляется путем отбора
отдельных объектов генеральной
совокупности через определенный интервал
(каждый 10-й или 20-й). Интервал рассчитывается
по отношению![]() ,
,
гдеn– численность выборки,N–
численность генеральной совокупности.
Так, если из совокупности в 500 000 единиц
предполагается получить 2 %-ную выборку,
т. е. отобрать 10 000
единиц, то пропорция отбора составит![]() Отбор
Отбор
единиц осуществляется в соответствии
с установленной пропорцией через равные
интервалы. Если расположение объектов
в генеральной совокупности носит
случайный характер, то механическая
выборка по содержанию аналогична
случайному отбору. При механическом
отборе применяется только бесповторная
выборка [1, 5–10].
Средняя ошибка
и численность выборки при механическом
отборе подсчитывается по формулам
собственно-случайной выборки (см.
табл. 7.2 и 7.3).
3.
Типическая выборка, при котрой
генеральная совокупность делится по
некоторым существенным признакам на
типические группы; отбор единиц
производится из типических групп. При
этом способе отбора генеральная
совокупность расчленяется на однородные
в некотором отношении группы, которые
имеют свои характеристики, и вопрос
сводится к определению объема выборок
из каждой группы. Может бытьравномерная
выборка– при этом способе из каждой
типической группы отбирается одинаковое
число единиц![]() Такой подход оправдан лишь при равенстве
Такой подход оправдан лишь при равенстве
численностей исходных типических групп.
При типическом отборе, непропорциональном
объему групп, общее число отбираемых
единиц делится на число типических
групп, полученная величина дает
численность отбора из каждой типической
группы.
Более совершенной
формой отбора является пропорциональная
выборка. Пропорциональной называется
такая схема формирования выборочной
совокупности, когда численность выборок,
взятых из каждой типической группы в
генеральной совокупности, пропорциональна
численностям, дисперсиям (или комбинированно
и численностям, и дисперсиям). Условно
определяем численность выборки в 100
единиц и отбираем единицы из групп:
– пропорционально
численности их генеральной совокупности
(табл. 7.4). В таблице
обозначено:
Ni– численность типической группы;
dj
– доля (Ni/N);
N– численность
генеральной совокупности;
ni– численность выборки из типической
группы вычисляется:
![]() , (7.7)
, (7.7)
n – численность выборки из генеральной
совокупности.
Таблица
7.4
-
Группы
Ni
dj
ni
1
300
0,3
30
2
500
0,5
50
3
200
0,2
20
1000
1,0
100
–
пропорционально среднему квадратическому
отклонению(табл. 7.5).
здесь
i– среднее
квадратическое отклонение типических
групп;
ni
– численность выборки из типической
группы вычисляется по формуле

(7.8)
Таблица
7.5
-
Ni
i

ni
300
5
0,25
25
500
7
0,35
35
200
8
0,40
40
1000
20
1,0
100
–
комбинированно (табл. 7.6).
Численность
выборки вычисляется по формуле
![]() . (7.9)
. (7.9)
Таблица 7.6
-

i
iNi


300
5
1500
0,23
23
500
7
2100
0,53
53
200
8
1600
0.24
24
1000
20
6600
1,0
100
При проведении
типической выборки непосредственный
отбор из каждой группы проводится
методом случайного отбора.
Средние ошибки
выборки рассчитываются по формулам
табл. 7.7 в зависимости от способа отбора
из типических групп.
Таблица 7.7
|
Способ |
Повторный |
Бесповторный |
||
|
для |
для |
для |
для |
|
|
Непропорциональный |
|
|
|
|
|
Пропорциональный объему групп |
|
|
|
|
|
Пропорциональный |
|
|
|
|





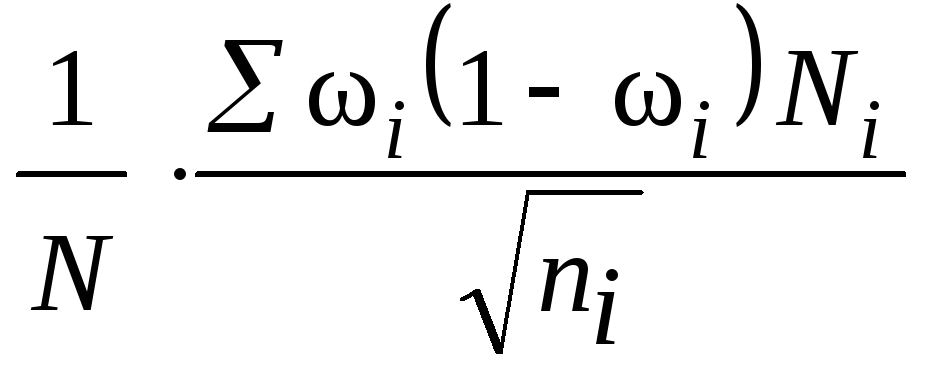


здесь
![]() – средняя из внутригрупповых дисперсий
– средняя из внутригрупповых дисперсий
типических групп;
![]() – доля единиц, обладающих изучаемым
– доля единиц, обладающих изучаемым
признаком;
![]() – средняя из внутригрупповых дисперсий
– средняя из внутригрупповых дисперсий
для доли;
![]() – среднее квадратическое отклонение
– среднее квадратическое отклонение
в выборке изi-й типической группы;
![]() – объем выборки из типической группы;
– объем выборки из типической группы;
![]() – общий объем выборки;
– общий объем выборки;
![]() –
–
объем типической группы;
![]() – объем генеральной совокупности.
– объем генеральной совокупности.
Численность
выборки из каждой типической группы
должна быть пропорциональна среднему
квадратическому отклонению в этой
группе
![]() .Расчет численности
.Расчет численности
![]() производится по формулам, приведенным
производится по формулам, приведенным
в табл. 7.8.
Таблица 7.8
|
Повторный |
Бесповторный |
|
|
Для определения |
|
|
|
Для определения |
|
|
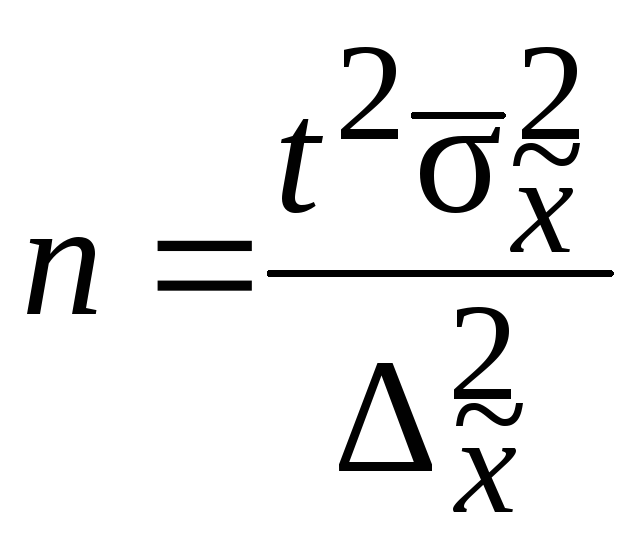

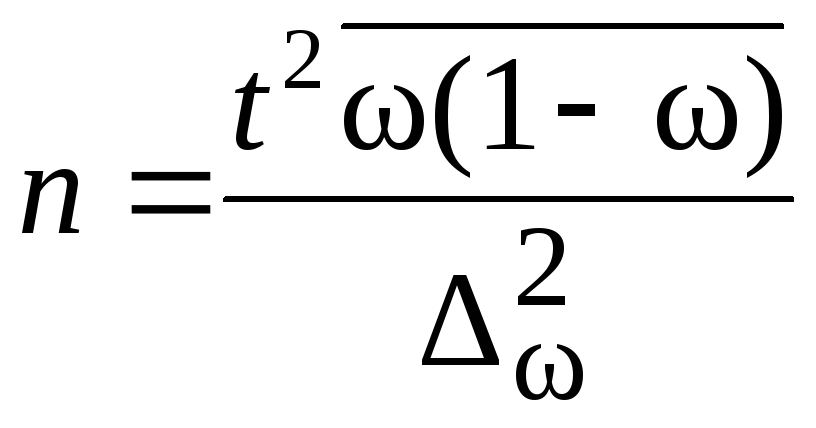

4. Серийная
выборка– удобена в тех случаях,
когда единицы совокупности объединены
в небольшие группы или серии. При серийной
выборке генеральную совокупность делят
на одинаковые по объему группы – серии.
В выборочную совокупность отбираются
серии. Сущность серийной выборки
заключается в случайном или механическом
отборе серий, внутри которых производится
сплошное обследование единиц. Средняя
ошибка серийной выборки с равновеликими
сериями зависит от величины только
межгрупповой дисперсии. Средние ошибки
сведены в табл. 7.9.
Таблица 7.9
|
Способ |
Формулы |
|
|
для |
для |
|
|
Повторный |
|
|
|
Бесповторный |
|
|


Здесь
R– число серий в генеральной
совокупности;
r – число
отобранных серий;
![]() – межсерийная (межгрупповая) дисперсия
– межсерийная (межгрупповая) дисперсия
средних;
![]() – межсерийная (межгрупповая) дисперсия
– межсерийная (межгрупповая) дисперсия
доли.
При серийном
отборе необходимую численность отбираемых
серий определяют так же, как и при
собственно-случайном методе отбора.
Расчет численности
серийной выборки производится по
формулам, приведенным в табл. 7.10.
Таблица 7.10
|
Повторный |
Бесповторный |
|
|
Для |
|
|
|
Для |
|
|
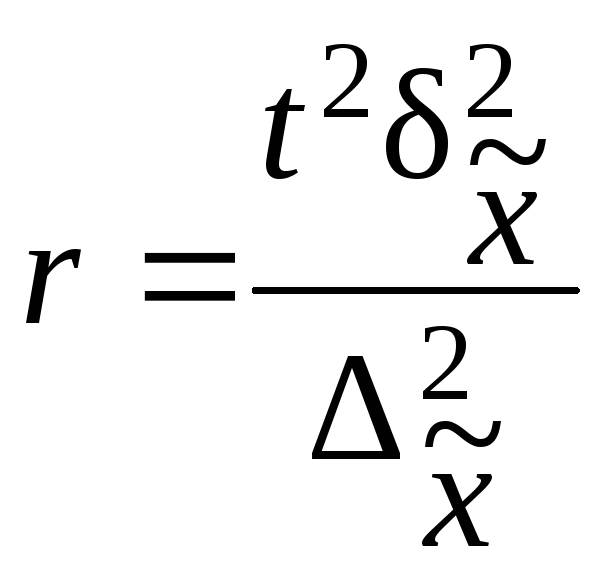

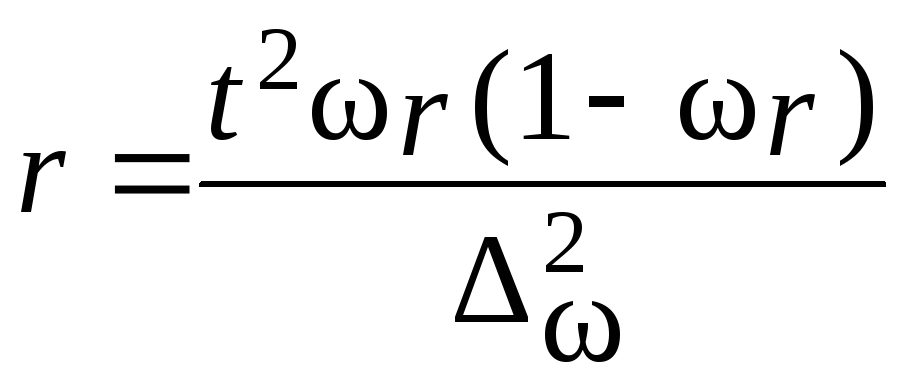

Пример.В
механическом цехе завода в десяти
бригадах работает 100 рабочих. В целях
изучения квалификации рабочих была
произведена 20 %-ная серийная бесповторная
выборка, в которую вошли две бригады.
Получено следующее распределение
обследованных рабочих по разрядам:
|
Рабочие |
Разряды рабочих |
Разряды рабочих |
Рабочие |
Разряды |
Разряды |
|
1 2 3 4 5 |
2 4 5 2 5 |
3 6 1 5 3 |
6 7 8 9 10 |
6 5 8 4 5 |
4 2 1 3 2 |
Необходимо
определить с вероятностью 0,997 пределы,
в которых находится средний разряд
рабочих механического цеха.
Решение.
Определим выборочные средние по
бригадам и общую среднюю как среднюю
взвешенную из групповых средних:

Определим
межсерийную дисперсию по формулам
(5.25):
![]()
Рассчитаем
среднюю ошибку выборки по формуле табл.
7.9:
![]()
Вычислим
предельную ошибку выборки с вероятностью
0,997:
![]()
С вероятностью
0,997 можно утверждать, что средний разряд
рабочих механического цеха находится
в пределах
![]()
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Ошибка
репрезентативности
— расхождение между выборочной
характеристикой и характеристикой
генеральной совокупности.
Ошибки
репрезентативности
-
Систематические
— возникают в результате нарушения
научных принципов отбора единиц
совокупности (преднамеренные и
непреднамеренные). -
Случайные
возникают в результате несплошного
характера наблюдения (средняя и
предельная ошибки выбора).
Случайные
ошибки могут быть доведены до незначительных
размеров, а главное, их размеры и пределы
можно определить с достаточной точностью
на основании закона больших чисел.
Средняя
ошибка выборки
— такое расхождение между средними
выборочной и генеральной совокупностями,
которое не превышает ±.
В
математической статистике доказывается,
что значения средней ошибки выборки
определяются по формулам:
Формула
для определения величины средней ошибки
выборки для количественного признака:
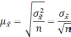
Формула
для определения величины средней ошибки
выборки для альтернативного признака:

Полученное
значение средней ошибки необходимо для
установления возможного значения 
 .
.
Которое определяется по формуле:
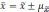
Но
такое суждение можно гарантировать не
с абсолютной
достоверностью, а лишь с определенной
степенью
вероятности.
В
математической статистике доказывается,
что пределы значений характеристик
генеральной совокупности отличаются
от характеристик выборочной совокупности
лишь с вероятностью, которая определена
числом 0,683.
Это
означает, что в 683 случаях из 1000 генеральная
средняя будет находиться в установленных
пределах, т.е. отклонение ГС от ВС не
превысит однократной средней ошибки
выборки. В остальных 317 случаях они могут
выйти за эти пределы. Вероятность можно
повысить, если расширить пределы
отклонений. Так, при удвоенном значении

 ,
,
вероятность достигает 0,954 (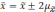
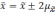 ).
).
Если утроить значение то вероятность
увеличится до 0,997 (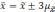
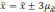 ).
).
|
Возможное |
Вероятность |
|
|
0,683 |
|
|
0,954 |
|
|
0,997 |
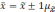
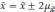
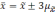
Если
обозначить значение увеличения 

за
t,
то можно записать в общем виде:
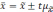
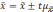
Множитель
t
называется коэффициентом
доверия.
Известный русский математик А.М.Ляпунов
дал выражение конкретных значений
множителя t
для различных степеней вероятности в
виде функции:
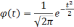
На
практике пользуются готовыми таблицами
этой функции.
|
t |
0 |
0,1 |
0,5 |
1 |
1,5 |
2 |
2,5 |
2,6 |
3 |
4 |
|
(t) |
0,1 |
0,0797 |
0,3829 |
0,6827 |
0,8664 |
0,9545 |
0,9876 |
0,9907 |
0,9973 |
0,99994 |
Из
вышесказанного следует, что лишь с
определенной степенью вероятности
можно утверждать, что показатели
генеральной совокупности и их отклонения
не превысят величину 
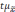 .
.
Полученную величину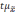
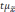 называетсяпредельной
называетсяпредельной
ошибкой выборки.
Предельная
ошибка выборки
—
максимально
возможное расхождение выборочной и
генеральной средних,
т.е.
максимум ошибки при заданной вероятности
ее появления.
Предельная
ошибка выборки для количественного
признака:
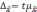
Предельная
ошибка выборки для альтернативного
признака:
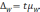
В
связи с тем, что существуют различные
методы, виды и способы отбора единиц из
генеральной совокупности формулы для
расчета средней ошибки выборки также
будут различаться:
|
Способ |
Оцениваемый |
Повторный |
Бесповторный |
|
Собственно случайный механический |
Средняя |
|
|
|
Доля |
|
|
|
|
Типический |
Средняя |
|
|
|
Доля |
|
|
|
|
Серийный |
Средняя |
|
|
|
Доля |
|
|
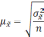
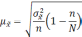
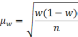
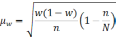
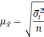
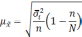
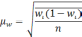
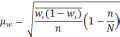
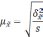
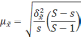

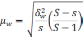
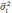
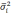
— средняя из групповых дисперсий;
wi
— доля
единиц совокупности, обладающих изучаемым
признаком в i-й
типической
группе;
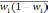
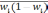
— средняя из групповых дисперсий для
доли. В табл. 6.6 представлены формулы
для исчисления средней ошибки выборки
при типическом отборе;
S
– общее число серий;
s
– число отобранных серий;

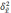 —
—
межгрупповая дисперсия средних,
определяемая по формуле:
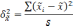
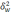
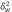 —
—
межгрупповая дисперсия доли, определяемая
по формуле:
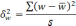
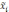
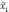
— средняя
i-й
серии;


—
средняя по всей выборочной совокупности;
w
— доля признака i-й
серии;


— общая доля признака во всей выборочной
совокупности.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Ошибки в статистике
Ошибки в статистике (сплошных и выборочных) могут возникнуть ошибки двух видов: репрезентативности и регистрации.
Ошибки репрезентативности характерны только для выборочного наблюдения и возникают в результате того, что выборочная совокупность не полностью воспроизводит генеральную. Они определяются как расхождение между значениями показателей, полученных по выборке, и значениями показателей этих же величин, которые были бы получены при проведенном сплошном наблюдении с одинаковой степенью точности.
Ошибки регистрации могут иметь случайный, систематический и непреднамеренный характер.
Случайные ошибки часто уравновешивают друг друга, так как они не имеют преимущественного направления в сторону преувеличения (преуменьшении) значения изучаемого показателя. Данные ошибки имеют объективный характер и возникают в следствии случайных различий между единицами, попавшими в выборку, и единицами генеральной совокупности. В результате и структуры этих совокупностей чаще всего не совпадают. Научным обоснованием случайных ошибок являются теория вероятностей и ее предельные теоремы.
Систематические ошибки направлены в одну сторону в результате предумышленного нарушения правил отбора. Их можно избежать при правильной организации и проведении наблюдения.
Ошибка выборки в статистике
Ошибка выборки или ошибка репрезентативности определяется как разница между значением показателя, который был получен по выборке, и генеральным параметром. Она характерна только для выборочных наблюдений. Чем больше значение этой ошибки, тем в большей степени выборочные показатели отличаются от соответствующих им генеральных показателей.
Ошибку выборки часто определяют по формулам:
1. Для среднего количественного признака:

где первое — среднее значение признака в генеральной совокупности или генеральная средняя;
второе — выборочная средняя.
2. Для доли (альтернативного признака):

где w — выборочная доля;
р — генеральная доля, или доля единиц, обладающих данным значением признака в общем числе единиц генеральной совокупности.
Ошибки выборки возникают вследствие двух причин из-за нарушения принципа случайности как основного принципа выборки (систематические ошибки) и в результате случайного отбора (случайные ошибки). Выборки являются случайными величинами и могут принимать разные значения.
Источник: Балинова B.C. Статистика в вопросах и ответах: Учеб. пособие. — М.: ТК. Велби, Изд-во Проспект, 2004. — 344 с.
2.4. Точность статистического наблюдения
Под точностью статистического наблюдения понимают степень соответствия значения наблюдаемого показателя, вычисленного по материалам обследования, его действительной величине. Расхождение, или разница, между ними называется ошибкой статистического наблюдения.
Различают две группы ошибок:
- ошибки регистрации;
- ошибки репрезентативности.
Ошибки регистрации присущи любому статистическому наблюдению, как сплошному, так и несплошному. Они делятся на случайные ошибки регистрации и систематические ошибки регистрации.
Случайными ошибками регистрации называют ошибки, возникающие вследствие действия случайных факторов. К ним можно отнести различного рода непреднамеренные описки: например, вместо возраста человека «15 лет» указано «5 лет», у Ивановой Марии Петровны в графе пол отмечен «Мужской» и т. п. Такие ошибки легко выявляются методом логического анализа, например, если человеку 8 лет, но имеется высшее образование, а в графе «Семейное положение» указано «Состоит в браке», то, естественно, следует исправить возраст. Если объем исследуемой совокупности велик или велика доля отбора при выборочном наблюдении, случайные ошибки регистрации имеют тенденцию взаимопогашаться вследствие действия закона больших чисел, поскольку ошибки, как правило, разнонаправлены и искажают статистический показатель как в большую, так и в меньшую сторону. При небольшом объеме наблюдения требуется тщательная выверка его результатов — логический анализ данных.
Систематические ошибки регистрации чаще всего имеют однонаправленные искажения: они либо увеличивают, либо уменьшают статистический показатель, и, что характерно, подобная ситуация повторяется от обследования к обследованию. Так, по результатам переписей (практически всех!) число замужних женщин превышает число женатых мужчин — мужчинам приятнее ощущать себя неженатыми, а для женщины как бы «стыдно» быть не замужем. Другой пример, когда человек округляет свой возраст — вместо 32 лет говорит 30, вместо 79-80 и т. п. (это явление широко известно и даже получило свое название — «аккумуляция возрастов»). Систематические ошибки регистрации могут возникать и из-за неточностей измерительных приборов, если сбор информации проводят путем непосредственного наблюдения.
Ошибки репрезентативности присущи только несплошному обследованию. Они также делятся на случайные и систематические ошибки.
Случайные ошибки репрезентативности возникают из-за того, что обследованию подвергается не вся совокупность в целом, а только ее часть, и, следовательно, при несплошном наблюдении они присутствуют всегда. В теории статистики разработаны специальные методы для оценки величин таких ошибок, на их основе для наблюдаемых показателей строят доверительные интервалы, т.д. эти ошибки вычисляются и находятся как бы «под контролем».
Хуже обстоит дело, если наряду со случайными ошибками имеются и ошибки систематические.
Систематические ошибки репрезентативности возникают, если при несплошном наблюдении кардинально нарушаются технологии отбора единиц из генеральной совокупности объектов, но чаще — если в ходе обследования не удается получить информацию обо всех отобранных для наблюдения единицах, например, вследствие отказа отвечать на вопросы анкеты, или если человека не удалось застать дома и т. п.
Ошибки статистического наблюдения для наглядности можно изобразить в виде схемы (рис. 2.1).
Рис.
2.1.
Виды ошибок статистического наблюдения
Для повышения точности наблюдения необходимо:
- правильно разработать формуляр статистического наблюдения: вопросы должны быть четкими, однозначными, не допускающими двойного толкования;
- иметь хорошо обученный персонал для проведения обследования;
- строго придерживаться выбранной технологии обследования (если проводится несплошное наблюдение) и помнить, что если не удается опросить какую-то конкретную единицу, отобранную для наблюдения, замена ее на другую единицу может привести к возникновению систематической ошибки репрезентативности;
- провести логический анализ данных, основанный на логических взаимосвязях показателей, после сбора всей совокупности анкет или формуляров;
- целесообразно провести и арифметический контроль данных, т.д. заново пересчитать расчетные величины, если какие-либо показатели получаются в результате определенных арифметических действий;
- предпринять определенные меры по восстановлению данных при наличии незаполненных анкет или формуляров либо при получении результатов обследования сделать поправку на неответы респондентов.
Социально-экономическая статистика
Ошибки статистического наблюдения
Расхождение между расчетным и действительным значением изучаемых величин называется ошибкой наблюдения. В зависимости от причин возникновения различают ошибки регистрации и ошибки репрезентативности.
Ошибки регистрации — это отклонения между значением показателя, полученного в ходе статистического наблюдения, и фактическим, действительным его значением. Такой вид ошибок имеет место и при сплошном, и при несплошном наблюдениях. Ошибки регистрации бывают случайными и систематическими. Случайные ошибки — это результат действия различных случайных факторов (например, цифры переставлены местами, перепутаны соседние строки или графы при заполнении статистического формуляра). Систематические ошибки регистрации всегда имеют одинаковую тенденцию либо к увеличению, либо к уменьшению значения показателей по каждой единице наблюдения, и поэтому величина показателя по совокупности в целом будет включать в себя накопленную ошибку. Примером статистической ошибки регистрации при проведении социологических опросов может служить округление возраста населения, как правило, на цифрах, оканчивающихся на 5 и 0. Многие опрашиваемые, например, вместо 48—49 лет и 51—52 года говорят, что им 50 лет.
В отличие от ошибок регистрации ошибки репрезентативности характерны только для несплошного наблюдения. Они возникают потому, что отобранная и обследованная совокупность недостаточно точно воспроизводит генеральную совокупность в целом.
Отклонение значения показателя обследованной совокупности от его величины в генеральной совокупности называется ошибкой репрезентативности.
Ошибки репрезентативности также бывают случайными и систематическими. Случайные ошибки репрезентативности возникают, если отобранная совокупность неполно воспроизводит совокупность в целом. Величина этих ошибок может быть оценена.
Систематические ошибки репрезентативности появляются вследствие нарушения принципов отбора единиц из исходной совокупности, которые должны бьггь подвергнуты наблюдению. Для устранения ошибок наблюдения необходимо осуществить контроль полученной информации.
После получения статистических формуляров следует провести проверку полноты собранных данных, т. е. определить, все ли отчетные единицы заполнили статистические формуляры и значения всех ли показателей отражены в них. Следующим этапом контроля точности информации является арифметический контроль. Он основывается на использовании количественных связей между значениями различных показателей. Например, сумма значений компонентов не может быть больше итогового показателя.
Если арифметический контроль покажет, что данная зависимость не выполняется, то это будет свидетельствовать о недостоверности собранных данных. Поэтому в программу статистического наблюдения целесообразно включать показатели, дающие возможность провести арифметический контроль.
Логический контроль, так же как и арифметический, основывается на знании взаимосвязей между показателями, но не количественных, а логических. Например, человек в возрасте шести лет не может состоять в браке, поэтому, если в бланке переписи имеются одновременно обе записи, то это показывает, что одна из них не соответствует действительности.
Обычно для исправления ошибок, выявленных в ходе логического контроля, требуется повторно обратиться к источнику сведений.
- Статистическая сводка и группировка
- Программно-методологические вопросы статистического наблюдения
- Рекомендации по выбору бизнеса
- Строительное оборудование МСД
- Тепловые насосы
Социально-экономическая статистика
Личные и бизнес аккаунты в социальных сетях
Существует много путаницы в том, как отделить личные данные от бизнес-аккаунтов в социальных сетях. Большая часть неопределенности связана с созданием страниц Facebook, но многие люди также используют социальные сети, такие …
Глоссарий
Баланс народного хозяйства (balance of economy national) — взаимосвязанная система балансовых таблиц, которую составляло ЦСУ СССР вплоть до конца 80-х годов XX столетия. БНХ характеризовал процесс воспроизводства совокупного общественного продукта …
Статистические показатели условий жизни, труда и отдыха
Наряду с показателями материального благосостояния жизненный уровень населения характеризуют показатели, отражающие общую ситуацию, обусловливающую уровень жизни. К ним относятся показатели: • состояния окружающей среды; • криминогенной обстановки; • условий труда; …
Слайд 1Ошибки репрезентативности и факторы, определяющие ее величину
МВД России
Санкт-Петербургский университет
53

Слайд 2
Ошибки репрезентативности
— это расхождение между двумя
совокупностями генеральной, на которую направлен теоретический интерес социолога и представление
о свойствах которой он хочет получить в конечном итоге, и выборочной, на которую направлен практический интерес социолога, которая выступает одновременно как объект обследования и средство получить информацию о генеральной совокупности
Санкт-Петербургский университет МВД России

Слайд 3Ошибки репрезентативности
Систематические ошибки
репрезентативности-
возникают из-за нарушения
научного принципа
отбора
единиц в выборочную
совокупность
Случайные ошибки
репрезентативности-
возникают из-за того,
что выборочная
совокупность не совсем
правильно отражает
средние величины и
величины доли признака
генеральной совокупности
Санкт-Петербургский университет МВД России

Слайд 4
каждый элемент генеральной
совокупности должен иметь
одинаковую вероятность попасть
в выборочную
совокупность
необходимо иметь сведения о
структуре генеральной
совокупности и её характерные
черты
генеральная совокупность должна
быть желательно однородной
при составлении выборочной
совокупности заранее учесть
случайные и систематические
ошибки
Способы, позволяющие избежать ошибки репрезентативности
Санкт-Петербургский университет МВД России

Слайд 5
неудачно выбран
способ отбора
единиц
наблюдения
в ходе исследования
была не
правильно
составлена основа
выборки (использова-
лись устаревшие,
неполные данные либо
отсутствовала статистика
по некоторым важным
для формирования
выборки признакам)
часть респондентов
по разным причинам
«выпала»
из опроса
(отсутствовала,
отказалась отвечать)
и так далее
Причины возникновения
систематических ошибок наблюдения
Санкт-Петербургский университет МВД России

Слайд 6
Ошибки репрезентативности свойственны только выборочному наблюдению. Они не могут быть
полностью устранены, но они могут быть доведены до незначительных размеров,
если соответствующим образом организовать отбор единиц в выборочную совокупность.
Пределы ошибок репрезентативности можно определить с достаточной степенью точности на основании ряда теорем в теории вероятности и математической статистике.
Санкт-Петербургский университет МВД России
