Критерий Стьюдента применяется для проверки равенства средних значений двух выборок, сравнение количественных значений только двух выборок с нормальным распределением случайной величины.
Критерий Стьюдента определяется по формуле:
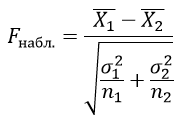
$bar{X_1}$ – выборочные средние значения первой выборки;
$bar{X_2}$ – выборочные средние значения второй выборки;
n1 – объем первой выборки;
n2 – объем второй выборки;
σ1 и σ2 – среднее квадратическое отклонение в соответствующих выборках и находятся из формулы:
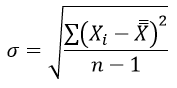
Число степеней свободы определяется по формуле:
k=n1+n2−2
Fкр(α, k) определяется по таблице
При Fнабл<Fкр нулевая гипотеза принимается.
Формула критерия Стьюдента для несвязанных независимых выборок:
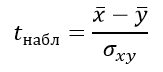
Формула для определения стандартной ошибки разности средних арифметических σxy:
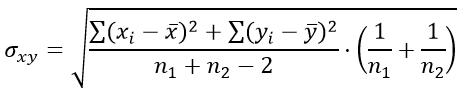
Число степеней свободы определяется выражением:
k=n1+n2–2
При n1=n2 число степеней свободы находится по формуле:
k=2n-2
а стандартная ошибка разности средних арифметических σxy задаётся выражением:
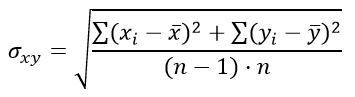
Пример
Даны две выборки.
В первой выборки продажа товара со скидкой, а во второй без скидки.
| № п/п | X | Y |
| 1 | 25 | 19 |
| 2 | 34 | 31 |
| 3 | 23 | 17 |
| 4 | 35 | 24 |
| 5 | 33 | 28 |
| 6 | 25 | 31 |
| 7 | 45 | 39 |
| 8 | 41 | 32 |
| 9 | 27 | 38 |
| 10 | 54 | 43 |
| 11 | 32 | 21 |
| 12 | 32 |
По критерию Стьюдента определить зависит ли спрос на товар от скидок на него при p=0.99?
Решение
В соответствии с таблицей n1=12, n2=11
Вычислим дисперсии D(X), D(Y)
| № п/п | X | Y | D(X) | D(Y) |
| 1 | 25 | 19 | 78,028 | 107,4 |
| 2 | 34 | 31 | 0,0278 | 2,6777 |
| 3 | 23 | 17 | 117,36 | 152,86 |
| 4 | 35 | 24 | 1,3611 | 28,769 |
| 5 | 33 | 28 | 0,6944 | 1,8595 |
| 6 | 25 | 31 | 78,028 | 2,6777 |
| 7 | 45 | 39 | 124,69 | 92,86 |
| 8 | 41 | 32 | 51,361 | 6,9504 |
| 9 | 27 | 38 | 46,694 | 74,587 |
| 10 | 54 | 43 | 406,69 | 185,95 |
| 11 | 32 | 21 | 3,3611 | 69,95 |
| 12 | 32 | 3,3611 | ||
| Сумма | 406 | 323 | 911,67 | 726,55 |
| Среднее | 33,833 | 29,364 |
Подставим значения в формулу стандартной ошибки разности средних арифметических σxy:
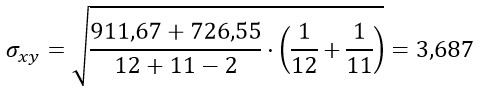
Вычисляем критерий Стьюдента:
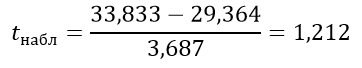
Число степеней свободы равно:
k=12+11–2=21
По таблице Стьюдента находим критическое значение:
tкрит=2,8310
Отсюда tкрит> tнабл, следовательно, зависит.
![]() 18953
18953
Условное обозначение средней ошибки среднего арифметического — т. Следует помнить, что под «ошибкой» в статистике понимается не ошибка исследования, а мера представительства данной величины, т. е. мера, которой средняя арифметическая величина, полученная на выборочной совокупности (в нашем примере — на 125 детях), отличается от истинной средней арифметической величины, которая была бы получена на генеральной совокупности (в нашем примере это были бы все дети аналогичного возраста, уровня подготовленности и т. д.). Например, в приведенном ранее примере определялась точность попадания малым мячом в цель у 125 детей и была получена средняя арифметическая величина примерно равная 5,6 см. Теперь надо установить, в какой мере эта величина будет характерна, если взять для исследования 200, 300, 500 и больше аналогичных детей. Ответ на этот вопрос и даст вычисление средней ошибки среднего арифметического, которое производится по формуле:
Для приведенного примера величина средней ошибки среднего арифметического будет равна:
Следовательно, M±m = 5,6±0,38. Это означает, что полученная средняя арифметическая величина (M = 5,6) может иметь в других аналогичных исследованиях значения от 5,22 (5,6 — 0,38 = 5,22) до 5,98 (5,6+0,38 = 5,98).
4. Вычисление средней ошибки разности
Условное обозначение средней ошибки разности — t. Таким образом, установлены основные статистические параметры, характеризующие количественную сторону эффективности одной из методик обучения метанию малых мячей в цель. Но в приведенном примере речь шла о сравнительном эксперименте, в котором сопоставлялись две методики обучения. Предположим, что вычисленные параметры характеризуют методику «А». Тогда для методики «Б» также необходимо вычислить аналогичные статистические параметры. Допустим, они будут равны:
МБ 4,7; σБ ± 3,67 mБ ± 0,33
Теперь есть числовые характеристики двух разных методик обучения. Необходимо установить, насколько эти характеристики достоверно различны, т. е. установить статистически реальную значимость разницы между ними. Условно принято считать, что если разница равна трем своим ошибкам или больше, то она является достоверной:
В приведенном примере:
0,9<1,5
Следовательно, найденные количественные характеристики двух методик обучения не имеют достоверных различий и объясняются не закономерными, а случайными факторами. Поэтому можно сделать следующий педагогический вывод: обе методики обучения равноценны по своей эффективности; новая методика расширяет существующие способы решения данной педагогической задачи.
Подобное вычисление средней ошибки разности применяется в тех случаях, когда имеются количественно значительные показатели п (т. е. при большом числе вариант). Если же в распоряжении экспериментатора имеется небольшое число наблюдений (менее 20), то целесообразно вычислять среднюю ошибку разности по формулам:
где С — число степеней свободы вариаций от 1 до ∞, которые равны числу наблюдений без единицы (С = п — 1).
В виде примера можно привести исследование, в котором оценивалась разница в величине становой динамометрии боксеров двух весовых категорий (А. Г. Жданова, 1961). Были получены следующие исходные данные: тяжелый вес — п1 = 12 человек, легкий вес — п2 = 15человек.
М1 = 139,2 кг M2 = 135,0 кг
σ1 = ± 4,2 кг σ2 = ±4,0 кг
m1 = ± 1,23 кг m2 = ± 1,69 кг
Если подставить эти значения в формулы, то получится:
Далее достоверность различия определяют по таблице вероятностей P/t/≥/t1/ по распределению Стьюдента (t — критерий Стьюдента).
В данной таблице столбец t является нормированным отклонением и содержит числа, которые показывают, во сколько раз разница больше средней ошибки. По вычисленным показателям t и С в таблице определяется число Р, которое показывает вероятность разницы между М1 и М2. Чем больше Р, тем менее существенна разница, тем меньше достоверность различий.
В приведенном примере при значении t 2,0 и С = 25 число Р будет равняться 0,0455 (в таблице оно расположено на пересечении строки, соответствующей t 2,0, и столбца, соответствующего С = ∞). Это свидетельствует о том, что реальная разница весьма вероятна.
В тех случаях, когда расчеты показывают отсутствие достоверности различия, преждевременно считать, что между изучаемыми явлениями вообще не может быть различия. Можно лишь утверждать, что нет различия при данных условиях исследования. При увеличении объема выборки достоверность в различии может появиться. Это положение является главным доказательством важности правильного определения необходимого числа исследований до начала эксперимента.
СПИСОК ЛИТЕРАТУРЫ
-
Масальгин Н.А. Математико-статистические методы в спорте. М., ФиС, 1974.
-
Методика и техника статистической обработки первичной социологической информации. Отв. ред. Г.В. Осипов. М., «Наука», 1968.
-
Начинская С.В. Основы спортивной статистики. — К.: Вища шк., 1987. — 189 с.
-
Толоконцев Н.А. Вычисление среднего квадратичного отклонения по размаху. Сравнение с общепринятым методом. Тезисы докладов третьего совещания по применению математических методов в биологии. ЛГУ, 1961, стр. 83 — 85.
-
Фаламеев А.И., Выдрин В.М. Научно-исследовательская работа в тяжелой атлетике. ГДОИФК им. П. Ф. Лесгафта, 1974.
Оценка разности двух показателей
При оценке
существенности разности двух показателей
вначале находят разность
двух показателей
α
по формуле:
![]()
После этого
вычисляют среднюю
ошибку разности Sα
и
коэффициент доверительности tα
по формулам:
![]()
,
![]()
Пример:
Из 125 студентов у 43 (pЭГ
= 34,40%) выявлен высокий уровень личностной
тревожности в экспериментальной группе
(ЭГ). В контрольной группе (КГ) из 125
студентов – высокий уровень личностной
тревожности у 59 (pКГ
= 47,20%). Необходимо определить, имеются
ли существенные различия между
показателями экспериментальной (pЭГ)
и контрольной (pКГ)
групп.
В нашем примере α
= 12,80, Sα
= 6,16, tα
= 2,08. Разность показателей α
превышает
свою ошибку Sα
более, чем в 2 раза (tα
= 2,08).
По таблице Стьюдента
находим, что эмпирическое значение tα
(2,08) превышает табличное для вероятности
ошибки P
= 0,05 (5%). Значение коэффициента Стьюдента
зависит не только от вероятности P
, но и от объема выборки. Число
степеней свободы n‘
при оценке
одного показателя равняется n
– 1, при
оценке достоверности разности двух
показателей n‘
= n1
+ n2
– 2. Так как
эмпирическое значение tα
(2,08) превышает табличное для вероятности
ошибки P
= 0,05 (5%), следовательно, имеются существенные
различия в показателях высоких уровней
личностной тревожности среди студентов
экспериментальной и контрольной групп.
Таблица 2 – Значения
критерия t
(по Стьюденту)
|
Число степеней |
Вероятность |
|||
|
0,05 = 5% |
0,02 = 2% |
0,01 = 1% |
0,001 = 0,1% |
|
|
30 |
2,042 |
2,457 |
2,750 |
3,64 |
|
∞ |
1,957 |
2,326 |
2,575 |
3,29 |
Определение средней ошибки показателей равных или близких к нулю или 100%
Величина средней
ошибки рассчитывается по формуле:
![]()
где
Sp
– величина
средней ошибки;
t
– доверительный
коэффициент;
n
– число
наблюдений (объем выборки).
Пример:
По данным минутной пробы Н.И Моисеевой
– В.М. Сысуева у всех 35 студентов
зарегистрирован средний уровень
способности к адаптации и ориентации
во времени (p
= 100%). Значит ли это, что в данной группе
отсутствуют студенты, имеющие высокие
или низкие способности к адаптации?
Принимаем
доверительный коэффициент t
= 2, что соответствует вероятности ошибки
меньше 5% (0,05), тогда средняя ошибка
показателя Sp
= 10,3%.
Следовательно,
при последующих испытаниях число лиц,
имеющих средние способности к адаптации
и ориентации во времени, может быть p
= 100% –
10,3% = 89,7%.
Если необходимо
увеличить надежность вывода, можно
принять t
= 3.
Критерий х2
Часто возникает
задача сравнения частных (например,
процентных) распределений
данных. В этом случае можно воспользоваться
статистикой, именуемой х2-критерий:
![]()
где
Pk
–
частоты
результатов наблюдений до эксперимента;
Vk
–
частоты результатов наблюдений после
эксперимента;
S
–
общее
число групп, на которые разделились
результаты наблюдений.
Полученное
расчетным путем значение х2
сопоставляется
с табличным и в случае его превышения
или равенства делается вывод о значимости
различий с определенной вероятностью
допустимой
ошибки.
Таблица 3 – Граничные
(критические)
значения х2-критерия
|
Число |
Вероятность |
||
|
0,05 |
0,01 |
0,001 |
|
|
1 |
3,84 |
6,64 |
10,83 |
|
2 |
5,99 |
9,21 |
13,82 |
|
3 |
7,81 |
11,34 |
16,27 |
|
4 |
9,49 |
13,23 |
18,46 |
|
5 |
11,07 |
15,09 |
20,52 |
|
6 |
12,59 |
16,81 |
22,46 |
|
7 |
14,07 |
18,48 |
24,32 |
|
8 |
15,51 |
20,09 |
26,12 |
|
9 |
16,92 |
21,67 |
27,88 |
|
10 |
18,31 |
23,21 |
29,59 |
Например,
из 100 испытуемых до
начала эксперимента 30 человек показали
результаты
ниже средних, 50 –
средние
и 20 –
выше средних.
После проведения формирующего эксперимента
результаты
распределились следующим образом: 20
человек
показали результаты ниже среднего, 40 –
средние и 40
–
выше среднего уровня.
Можно ли, опираясь
на эти данные, утверждать, что формирующий
эксперимент, направленный на увеличение
показателей (например, уровней самооценки)
удался?
Для
ответа на данный вопрос воспользуемся
формулой.
В данном примере переменная Pk
принимает
значение
30 %, 50 %, 20 %, a
Vk
–
20
%, 40 %, 40 %. Подставив
эти значения в формулу, получим
![]()
Воспользуемся
теперь таблицей «Граничные
(критические)
значения х2-критерия»,
где для заданного числа степеней
свободы (S–1=3–1=2)
можно определить степень
значимости различий показателей до и
после эксперимента. Полученное нами
значение 25,33 больше соответствующего
табличного значения
(13,82) при вероятности допустимой ошибки
меньше
0,1 % (0,001). Следовательно, эксперимент
удался, и мы можем
это утверждать, допуская ошибку, не
превышающую
0,1 %.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Оценка разности двух показателей
При оценке
существенности разности двух показателей
вначале находят разность
двух показателей
α
по формуле:
![]()
После этого
вычисляют среднюю
ошибку разности Sα
и
коэффициент доверительности tα
по формулам:
![]()
,
![]()
Пример:
Из 125 студентов у 43 (pЭГ
= 34,40%) выявлен высокий уровень личностной
тревожности в экспериментальной группе
(ЭГ). В контрольной группе (КГ) из 125
студентов – высокий уровень личностной
тревожности у 59 (pКГ
= 47,20%). Необходимо определить, имеются
ли существенные различия между
показателями экспериментальной (pЭГ)
и контрольной (pКГ)
групп.
В нашем примере α
= 12,80, Sα
= 6,16, tα
= 2,08. Разность показателей α
превышает
свою ошибку Sα
более, чем в 2 раза (tα
= 2,08).
По таблице Стьюдента
находим, что эмпирическое значение tα
(2,08) превышает табличное для вероятности
ошибки P
= 0,05 (5%). Значение коэффициента Стьюдента
зависит не только от вероятности P
, но и от объема выборки. Число
степеней свободы n‘
при оценке
одного показателя равняется n
– 1, при
оценке достоверности разности двух
показателей n‘
= n1
+ n2
– 2. Так как
эмпирическое значение tα
(2,08) превышает табличное для вероятности
ошибки P
= 0,05 (5%), следовательно, имеются существенные
различия в показателях высоких уровней
личностной тревожности среди студентов
экспериментальной и контрольной групп.
Таблица 2 – Значения
критерия t
(по Стьюденту)
|
Число степеней |
Вероятность |
|||
|
0,05 = 5% |
0,02 = 2% |
0,01 = 1% |
0,001 = 0,1% |
|
|
30 |
2,042 |
2,457 |
2,750 |
3,64 |
|
∞ |
1,957 |
2,326 |
2,575 |
3,29 |
Определение средней ошибки показателей равных или близких к нулю или 100%
Величина средней
ошибки рассчитывается по формуле:
![]()
где
Sp
– величина
средней ошибки;
t
– доверительный
коэффициент;
n
– число
наблюдений (объем выборки).
Пример:
По данным минутной пробы Н.И Моисеевой
– В.М. Сысуева у всех 35 студентов
зарегистрирован средний уровень
способности к адаптации и ориентации
во времени (p
= 100%). Значит ли это, что в данной группе
отсутствуют студенты, имеющие высокие
или низкие способности к адаптации?
Принимаем
доверительный коэффициент t
= 2, что соответствует вероятности ошибки
меньше 5% (0,05), тогда средняя ошибка
показателя Sp
= 10,3%.
Следовательно,
при последующих испытаниях число лиц,
имеющих средние способности к адаптации
и ориентации во времени, может быть p
= 100% –
10,3% = 89,7%.
Если необходимо
увеличить надежность вывода, можно
принять t
= 3.
Критерий х2
Часто возникает
задача сравнения частных (например,
процентных) распределений
данных. В этом случае можно воспользоваться
статистикой, именуемой х2-критерий:
![]()
где
Pk
–
частоты
результатов наблюдений до эксперимента;
Vk
–
частоты результатов наблюдений после
эксперимента;
S
–
общее
число групп, на которые разделились
результаты наблюдений.
Полученное
расчетным путем значение х2
сопоставляется
с табличным и в случае его превышения
или равенства делается вывод о значимости
различий с определенной вероятностью
допустимой
ошибки.
Таблица 3 – Граничные
(критические)
значения х2-критерия
|
Число |
Вероятность |
||
|
0,05 |
0,01 |
0,001 |
|
|
1 |
3,84 |
6,64 |
10,83 |
|
2 |
5,99 |
9,21 |
13,82 |
|
3 |
7,81 |
11,34 |
16,27 |
|
4 |
9,49 |
13,23 |
18,46 |
|
5 |
11,07 |
15,09 |
20,52 |
|
6 |
12,59 |
16,81 |
22,46 |
|
7 |
14,07 |
18,48 |
24,32 |
|
8 |
15,51 |
20,09 |
26,12 |
|
9 |
16,92 |
21,67 |
27,88 |
|
10 |
18,31 |
23,21 |
29,59 |
Например,
из 100 испытуемых до
начала эксперимента 30 человек показали
результаты
ниже средних, 50 –
средние
и 20 –
выше средних.
После проведения формирующего эксперимента
результаты
распределились следующим образом: 20
человек
показали результаты ниже среднего, 40 –
средние и 40
–
выше среднего уровня.
Можно ли, опираясь
на эти данные, утверждать, что формирующий
эксперимент, направленный на увеличение
показателей (например, уровней самооценки)
удался?
Для
ответа на данный вопрос воспользуемся
формулой.
В данном примере переменная Pk
принимает
значение
30 %, 50 %, 20 %, a
Vk
–
20
%, 40 %, 40 %. Подставив
эти значения в формулу, получим
![]()
Воспользуемся
теперь таблицей «Граничные
(критические)
значения х2-критерия»,
где для заданного числа степеней
свободы (S–1=3–1=2)
можно определить степень
значимости различий показателей до и
после эксперимента. Полученное нами
значение 25,33 больше соответствующего
табличного значения
(13,82) при вероятности допустимой ошибки
меньше
0,1 % (0,001). Следовательно, эксперимент
удался, и мы можем
это утверждать, допуская ошибку, не
превышающую
0,1 %.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Оценка разности двух показателей
При оценке
существенности разности двух показателей
вначале находят разность
двух показателей
α
по формуле:
![]()
После этого
вычисляют среднюю
ошибку разности Sα
и
коэффициент доверительности tα
по формулам:
![]()
,
![]()
Пример:
Из 125 студентов у 43 (pЭГ
= 34,40%) выявлен высокий уровень личностной
тревожности в экспериментальной группе
(ЭГ). В контрольной группе (КГ) из 125
студентов – высокий уровень личностной
тревожности у 59 (pКГ
= 47,20%). Необходимо определить, имеются
ли существенные различия между
показателями экспериментальной (pЭГ)
и контрольной (pКГ)
групп.
В нашем примере α
= 12,80, Sα
= 6,16, tα
= 2,08. Разность показателей α
превышает
свою ошибку Sα
более, чем в 2 раза (tα
= 2,08).
По таблице Стьюдента
находим, что эмпирическое значение tα
(2,08) превышает табличное для вероятности
ошибки P
= 0,05 (5%). Значение коэффициента Стьюдента
зависит не только от вероятности P
, но и от объема выборки. Число
степеней свободы n‘
при оценке
одного показателя равняется n
– 1, при
оценке достоверности разности двух
показателей n‘
= n1
+ n2
– 2. Так как
эмпирическое значение tα
(2,08) превышает табличное для вероятности
ошибки P
= 0,05 (5%), следовательно, имеются существенные
различия в показателях высоких уровней
личностной тревожности среди студентов
экспериментальной и контрольной групп.
Таблица 2 – Значения
критерия t
(по Стьюденту)
|
Число степеней |
Вероятность |
|||
|
0,05 = 5% |
0,02 = 2% |
0,01 = 1% |
0,001 = 0,1% |
|
|
30 |
2,042 |
2,457 |
2,750 |
3,64 |
|
∞ |
1,957 |
2,326 |
2,575 |
3,29 |
Определение средней ошибки показателей равных или близких к нулю или 100%
Величина средней
ошибки рассчитывается по формуле:
![]()
где
Sp
– величина
средней ошибки;
t
– доверительный
коэффициент;
n
– число
наблюдений (объем выборки).
Пример:
По данным минутной пробы Н.И Моисеевой
– В.М. Сысуева у всех 35 студентов
зарегистрирован средний уровень
способности к адаптации и ориентации
во времени (p
= 100%). Значит ли это, что в данной группе
отсутствуют студенты, имеющие высокие
или низкие способности к адаптации?
Принимаем
доверительный коэффициент t
= 2, что соответствует вероятности ошибки
меньше 5% (0,05), тогда средняя ошибка
показателя Sp
= 10,3%.
Следовательно,
при последующих испытаниях число лиц,
имеющих средние способности к адаптации
и ориентации во времени, может быть p
= 100% –
10,3% = 89,7%.
Если необходимо
увеличить надежность вывода, можно
принять t
= 3.
Критерий х2
Часто возникает
задача сравнения частных (например,
процентных) распределений
данных. В этом случае можно воспользоваться
статистикой, именуемой х2-критерий:
![]()
где
Pk
–
частоты
результатов наблюдений до эксперимента;
Vk
–
частоты результатов наблюдений после
эксперимента;
S
–
общее
число групп, на которые разделились
результаты наблюдений.
Полученное
расчетным путем значение х2
сопоставляется
с табличным и в случае его превышения
или равенства делается вывод о значимости
различий с определенной вероятностью
допустимой
ошибки.
Таблица 3 – Граничные
(критические)
значения х2-критерия
|
Число |
Вероятность |
||
|
0,05 |
0,01 |
0,001 |
|
|
1 |
3,84 |
6,64 |
10,83 |
|
2 |
5,99 |
9,21 |
13,82 |
|
3 |
7,81 |
11,34 |
16,27 |
|
4 |
9,49 |
13,23 |
18,46 |
|
5 |
11,07 |
15,09 |
20,52 |
|
6 |
12,59 |
16,81 |
22,46 |
|
7 |
14,07 |
18,48 |
24,32 |
|
8 |
15,51 |
20,09 |
26,12 |
|
9 |
16,92 |
21,67 |
27,88 |
|
10 |
18,31 |
23,21 |
29,59 |
Например,
из 100 испытуемых до
начала эксперимента 30 человек показали
результаты
ниже средних, 50 –
средние
и 20 –
выше средних.
После проведения формирующего эксперимента
результаты
распределились следующим образом: 20
человек
показали результаты ниже среднего, 40 –
средние и 40
–
выше среднего уровня.
Можно ли, опираясь
на эти данные, утверждать, что формирующий
эксперимент, направленный на увеличение
показателей (например, уровней самооценки)
удался?
Для
ответа на данный вопрос воспользуемся
формулой.
В данном примере переменная Pk
принимает
значение
30 %, 50 %, 20 %, a
Vk
–
20
%, 40 %, 40 %. Подставив
эти значения в формулу, получим
![]()
Воспользуемся
теперь таблицей «Граничные
(критические)
значения х2-критерия»,
где для заданного числа степеней
свободы (S–1=3–1=2)
можно определить степень
значимости различий показателей до и
после эксперимента. Полученное нами
значение 25,33 больше соответствующего
табличного значения
(13,82) при вероятности допустимой ошибки
меньше
0,1 % (0,001). Следовательно, эксперимент
удался, и мы можем
это утверждать, допуская ошибку, не
превышающую
0,1 %.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Критерий Стьюдента применяется для проверки равенства средних значений двух выборок, сравнение количественных значений только двух выборок с нормальным распределением случайной величины.
Критерий Стьюдента определяется по формуле:
$bar{X_1}$ – выборочные средние значения первой выборки;
$bar{X_2}$ – выборочные средние значения второй выборки;
n1 – объем первой выборки;
n2 – объем второй выборки;
σ1 и σ2 – среднее квадратическое отклонение в соответствующих выборках и находятся из формулы:
Число степеней свободы определяется по формуле:
k=n1+n2−2
Fкр(α, k) определяется по таблице
При Fнабл<Fкр нулевая гипотеза принимается.
Формула критерия Стьюдента для несвязанных независимых выборок:
Формула для определения стандартной ошибки разности средних арифметических σxy:
Число степеней свободы определяется выражением:
k=n1+n2–2
При n1=n2 число степеней свободы находится по формуле:
k=2n-2
а стандартная ошибка разности средних арифметических σxy задаётся выражением:
Пример
Даны две выборки.
В первой выборки продажа товара со скидкой, а во второй без скидки.
| № п/п | X | Y |
| 1 | 25 | 19 |
| 2 | 34 | 31 |
| 3 | 23 | 17 |
| 4 | 35 | 24 |
| 5 | 33 | 28 |
| 6 | 25 | 31 |
| 7 | 45 | 39 |
| 8 | 41 | 32 |
| 9 | 27 | 38 |
| 10 | 54 | 43 |
| 11 | 32 | 21 |
| 12 | 32 |
По критерию Стьюдента определить зависит ли спрос на товар от скидок на него при p=0.99?
Решение
В соответствии с таблицей n1=12, n2=11
Вычислим дисперсии D(X), D(Y)
| № п/п | X | Y | D(X) | D(Y) |
| 1 | 25 | 19 | 78,028 | 107,4 |
| 2 | 34 | 31 | 0,0278 | 2,6777 |
| 3 | 23 | 17 | 117,36 | 152,86 |
| 4 | 35 | 24 | 1,3611 | 28,769 |
| 5 | 33 | 28 | 0,6944 | 1,8595 |
| 6 | 25 | 31 | 78,028 | 2,6777 |
| 7 | 45 | 39 | 124,69 | 92,86 |
| 8 | 41 | 32 | 51,361 | 6,9504 |
| 9 | 27 | 38 | 46,694 | 74,587 |
| 10 | 54 | 43 | 406,69 | 185,95 |
| 11 | 32 | 21 | 3,3611 | 69,95 |
| 12 | 32 | 3,3611 | ||
| Сумма | 406 | 323 | 911,67 | 726,55 |
| Среднее | 33,833 | 29,364 |
Подставим значения в формулу стандартной ошибки разности средних арифметических σxy:
Вычисляем критерий Стьюдента:
Число степеней свободы равно:
k=12+11–2=21
По таблице Стьюдента находим критическое значение:
tкрит=2,8310
Отсюда tкрит> tнабл, следовательно, зависит.
![]() 16992
16992
В предыдущем разделе мы использовали два t-теста, чтобы разобраться в различиях между средними значениями по совокупности. Эти тесты были основаны на двух выборках.
Предположение о допустимости использования этих тестов для проверки гипотезы было основано на том, что выборки были независимыми — т.е., не связанными друг с другом.
Когда мы хотим проверить гипотезу для двух средних значений, основанных на выборках, которые, по нашему мнению, зависят друг от друга, мы применяем методы, представленные в данном разделе.
t-тест, описанный в этом разделе, основан на данных, расположенных попарно, т.е. в виде парных наблюдений, а сам этот тест иногда называют тестом парного (т.е. попарного) сравнения.
Парные наблюдения (англ. ‘paired observations’) — это наблюдения, которые зависят друг от друга, потому что у них есть нечто общее.
Тест парного сравнения (парный тест или парный двухвыборочный t-тест для средних, англ. ‘paired comparisons test’) представляет собой статистическую проверку различий между зависимыми элементами.
Например, нас может интересовать разница в дивидендной политике компании до и после изменения в налоговом законодательстве, регулирующем налогообложение дивидендов.
В этом случае, мы имеем пару наблюдений «до» и «после» для одних и тех же компаний. Мы можем проверить гипотезу о среднем значении различий (среднее разности, англ. ‘mean differences’), которые мы наблюдаем в разных компаниях.
В других случаях, парные наблюдения могут быть основаны на разных группах наблюдений.
Например, мы можем проверить, были ли средняя доходность двух инвестиционных стратегий равна в течение рассматриваемого периода. Здесь наблюдения связаны друг с другом в том смысле, что есть только одно наблюдение для каждой стратегии в каждом месяце, и оба наблюдения зависят от основных факторов рыночного риска.
Поскольку доходность обеих стратегий может быть связана с некоторыми общими факторами риска, такими, как рыночная доходность, эти выборки зависят друг от друга.
Благодаря расчету стандартной ошибки, основанному на различиях, t-тест, представленный ниже, учитывает корреляцию между наблюдениями.
Пусть (A) обозначает «после», а (B) — «до». Предположим, что у нас есть наблюдения для случайных величин (X_A) и (X_B) и что выборки зависимы. Мы располагаем наблюдения попарно.
Пусть (d_i) обозначает разность между двумя парными наблюдениями. Мы можем использовать обозначение (d_i = x_{Ai} — x_{Bi}), где (x_{Ai}) и (x_{Bi}) являются (i)-й парой наблюдений, где (i = 1,2, ldots, n).
Пусть (mu_d) обозначает разность средних по совокупности, а (mu_{d0}) обозначает гипотетическое значение разности средних по совокупности.
Мы можем сформулировать следующие пары гипотез для (mu_{d0}):
- (H_0: mu_d = mu_{d0}) против (H_a:mu_d neq mu_{d0})
- (H_0: mu_d leq mu_{d0}) против (H_a:mu_d > mu_{d0})
- (H_0: mu_d geq mu_{d0}) против (H_a:mu_d < mu_{d0})
На практике, наиболее часто используемым значением для (mu_{d0}) является 0.
Как обычно, мы имеем дело со случаем нормально распределенными совокупностями с неизвестными дисперсиями совокупности, мы будем выполнять t-тест.
Для вычисления t-статистики, мы сначала должны найти выборочную среднюю разность:
(Large { overline d = {1 over n} dsum^n_{i=1} d_i }) (Формула 10)
где (n) — число пар наблюдений.
Выборочная дисперсия, обозначенная как (s^2_d), рассчитывается по формуле:
(Large { s^2_d = {dsum^n_{i=1} (d_i — overline d)^2 over n-1 } }) (Формула 11)
Найдя квадратный корень из этой величины, мы получим стандартное отклонение выборки (s_d), который позволяет нам рассчитать стандартную ошибку средней разности следующим образом:
(Large dst { s_{overline d} = {s_d over sqrt n} }) (Формула 12)
Мы можем также использовать следующее эквивалентное выражение, которое использует корреляцию между двумя переменными величинами:
( dst s_{overline d} = sqrt {s^2_A + s^2_B — 2r(X_A, X_B)s_A s_B} Big / sqrt n )
где
- (s^2_A) является выборочной дисперсией (X_A),
- (s^2_B) является выборочной дисперсией (X_B), а
- (r(X_A, X_B) ) является выборочной корреляцией между (X_A) и (X_B).
Тестовая статистика для проверки средней разности (нормально распределенные совокупности, неизвестные дисперсии совокупности).
Когда у нас есть данные, состоящие из парных наблюдений из выборок, отобранных из нормально распределенных совокупностей с неизвестными дисперсиями, t-тест рассчитывается следующим образом:
(large dst t = {overline d — mu_{d0} over s_{overline d}} ) (Формула 13)
с (n — 1) степенями свободы, где
- (n) — число парных наблюдений,
- (overline d ) — выборочная средняя разность (определяемая по Формуле 10) и
- (s_{overline d} ) — стандартная ошибка (overline d ) (определяемая по Формуле 12).
В Таблице 7 представлена ежеквартальная доходность за 6 лет для двух управляемых портфелей, специализирующихся на драгоценных металлах. Эти два портфеля подвержены схожим рискам (по оценке с помощью стандартного отклонения доходности и других показателям) и имеют почти одинаковые доли расходов.
Инвестиционная компания присвоила Портфелю B более высокий рейтинг, чем Портфелю A. Мы исследуем относительную эффективность портфелей, и предположим, что мы хотим проверить гипотезу о том, что средняя квартальная доходность Портфеля A равна средней квартальной доходности Портфеля B в течение шестилетнего периода.
Поскольку два портфеля подвержены по существу одному и тому же набору факторов риска, их доходность зависима друг от друга, поэтому целесообразно выполнить тест парного сравнения.
Пусть (mu_d) обозначает среднее по совокупности значение разности между доходностью двух портфелей за этот период.
Мы проверяем нулевую гипотезу (H_0: mu_d = 0) против альтернативной гипотезы (H_a:mu_d neq 0) на уровне значимости 0.05.
Таблица 7. Квартальная доходность двух управляемых портфелей.
|
Квартал |
Портфель A (%) |
Портфель B (%) |
Разность |
|---|---|---|---|
|
4КВ:Год 6 |
11.40 |
14.64 |
-3.24 |
|
3КВ:Год 6 |
-2.17 |
0.44 |
-2.61 |
|
2КВ:Год 6 |
10.72 |
19.51 |
-8.79 |
|
1КВ:Год 6 |
38.91 |
50.40 |
-11.49 |
|
4КВ:Год 5 |
4.36 |
1.01 |
3.35 |
|
3КВ:Год 5 |
5.13 |
10.18 |
-5.05 |
|
2КВ:Год 5 |
26.36 |
17.77 |
8.59 |
|
1КВ:Год 5 |
-5.53 |
4.76 |
-10.29 |
|
4КВ:Год 4 |
5.27 |
-5.36 |
10.63 |
|
3КВ:Год 4 |
-7.82 |
-1.54 |
-6.28 |
|
2КВ:Год 4 |
2.34 |
0.19 |
2.15 |
|
1КВ:Год 4 |
-14.38 |
-12.07 |
-2.31 |
|
4КВ:Год 3 |
-9.80 |
-9.98 |
0.18 |
|
3КВ:Год 3 |
19.03 |
26.18 |
-7.15 |
|
2КВ:Год 3 |
4.11 |
-2.39 |
6.50 |
|
1КВ:Год 3 |
-4.12 |
-2.51 |
-1.61 |
|
4КВ:Год 2 |
-0.53 |
-11.32 |
10.79 |
|
3КВ:Год 2 |
5.06 |
0.46 |
4.60 |
|
2КВ:Год 2 |
-14.01 |
-11.56 |
-2.45 |
|
1КВ:Год 2 |
12.50 |
3.52 |
8.98 |
|
4КВ:Год 1 |
-29.05 |
-22.45 |
-6.60 |
|
3КВ:Год 1 |
3.60 |
0.10 |
3.50 |
|
2КВ:Год 1 |
-7.97 |
-8.96 |
0.99 |
|
1КВ:Год 1 |
-8.62 |
-0.66 |
-7.96 |
|
Среднее |
1.87 |
2.52 |
-0.65 |
Выборочное стандартное отклонение разностей = 6.71.
Выборочное среднее разности (overline d), между Портфелем A и Портфелем B составляет -0.65% в квартал. Стандартная ошибка выборочного среднего разности равна:
( s_{overline d} = 6.71 big / sqrt{24} = 1.369673)
Тестовая статистика равна (t = (-0.65 — 0)/1.369673 = -0.475) при (n — 1 = 24 — 1 = 23) степенях свободы.
На уровне значимости 0.05, мы отвергаем нулевую гипотезу, если (t> 2.069) или если (t < -2.069).
Поскольку -0.475 не меньше, чем -2.069, мы не отвергаем нуль. На уровне значимости 0.10 значимости мы отвергаем нулевую гипотезу, если (t> 1.714) или если (t < -1.714).
Таким образом, разница в средней квартальной доходности не является значимой при любом обычном уровне значимости.
Следующий пример иллюстрирует применение этого теста для оценки двух конкурирующих инвестиционных стратегий.
Пример (6) сравнения двух портфелей.
Вы выясняете, отличается ли эффективность портфеля акций компаний со всего мира от эффективности портфеля только акций американских компаний.
Для анализа всемирного портфеля, вы решили сосредоточиться на индексе биржевого инвестиционного фонда Vanguard Total World Index Stock ETF.
Фонд ETF (биржевой инвестиционный фонд, от англ. ‘exchange-traded fund’) стремится отслеживать эффективность индекса FTSE Global All Cap Index, который является взвешенным индексом рыночной капитализации, предназначенным для оценки рыночной эффективности акций компаний из развитых и развивающихся рынков.
Для анализа портфеля США, вы решили сосредоточиться на SPDR S&P 500, фонда ETF, который стремится отслеживать эффективность индекса S&P 500.
Вы проанализировали месячные данные по обоим ETF с августа 2013 года по июль 2018 года и подготовили следующую сводную таблицу.
Таблица 8. Месячная общая доходность для фондов Vanguard Total World Index Stock ETF и
|
Стратегия |
Средняя доходность |
Стандартное |
|---|---|---|
|
Мировая |
0.79% |
2.93% |
|
США |
1.06 |
2.81 |
|
Разность |
-0.27 |
1.00 * |
SPDR S&P 500 ETF:
с августа 2013 года по июль 2018 года ((n = 60)).
* Выборочное стандартное отклонение разности.
Источник данных о доходности: finance.yahoo.com, по состоянию на 18 августа 2018 г.
В Таблице 8 мы имеем (overline d) = -0.27% и (s_d) = 1.00%.
- Сформулируйте нулевую и альтернативную гипотезы для двухсторонней проверки того, средняя разность между мировой стратегией и стратегией акций США равна 0.
- Определите тестовую статистику для проведения проверки гипотез из части 1.
- Определите критическое значение или значения для проверенных гипотез из части 1 на уровне значимости 0.01.
- Определите, отвергается или нет нулевая гипотеза на уровне значимости 0.01. (используйте таблицы t-распределения)
- Обоснуйте выбор теста парного сравнения.
Решение для части 1:
Приняв (mu_d) в качестве средней разности между стратегиями, мы имеем пару гипотез:
(H_0: mu_d = 0) против (H_a:mu_d neq 0)
Решение для части 2:
Поскольку дисперсия генеральной совокупности неизвестна, тестовой статистикой является t-тест с 60 — 1 = 59 степенями свободы.
Решение для части 3:
В таблице t-распределения, ближайшим значением к df = 59 будет df = 60. Критическим значением, при 60 степенях свободы и уровне значимости 0.005, будет 2.66. Мы отвергаем нуль, если находим, что (t> 2.66) или (t <-2.66).
Решение для части 4:
( dst t_{59} = {-0.27 over 1.00 big / sqrt{60}} = {-0.27 over 0.129099} = -2.09)
Поскольку (-2.09 > -2.66), мы не можем отвергнуть нулевую гипотезу. Соответственно, мы приходим к выводу, что разница в средней доходности двух стратегий не является статистически значимой.
Решение для части 5:
Несколько американских акций, которые являются частью индекса S&P 500, также включены в ETF Vanguard Total World Index Stock. Профиль мирового фонда ETF показывает, что девять из десяти крупнейших холдингов в ETF являются американскими акциями.
В результате, выборки двух портфелей не являются независимыми. В целом, корреляция доходности фондов Vanguard Total World Index Stock ETF и SPDR S&P 500 ETF должна быть положительной.
Поскольку выборки зависимые, парный тест был обоснованным.
Критерий Стьюдента применяется для проверки равенства средних значений двух выборок, сравнение количественных значений только двух выборок с нормальным распределением случайной величины.
Критерий Стьюдента определяется по формуле:
$\bar{X_1}$ – выборочные средние значения первой выборки;
$\bar{X_2}$ – выборочные средние значения второй выборки;
n1 – объем первой выборки;
n2 – объем второй выборки;
σ1 и σ2 – среднее квадратическое отклонение в соответствующих выборках и находятся из формулы:
Число степеней свободы определяется по формуле:
k=n1+n2−2
Fкр(α, k) определяется по таблице
При Fнабл<Fкр нулевая гипотеза принимается.
Формула критерия Стьюдента для несвязанных независимых выборок:
Формула для определения стандартной ошибки разности средних арифметических σxy:
Число степеней свободы определяется выражением:
k=n1+n2–2
При n1=n2 число степеней свободы находится по формуле:
k=2n-2
а стандартная ошибка разности средних арифметических σxy задаётся выражением:
Пример
Даны две выборки.
В первой выборки продажа товара со скидкой, а во второй без скидки.
| № п/п | X | Y |
| 1 | 25 | 19 |
| 2 | 34 | 31 |
| 3 | 23 | 17 |
| 4 | 35 | 24 |
| 5 | 33 | 28 |
| 6 | 25 | 31 |
| 7 | 45 | 39 |
| 8 | 41 | 32 |
| 9 | 27 | 38 |
| 10 | 54 | 43 |
| 11 | 32 | 21 |
| 12 | 32 |
По критерию Стьюдента определить зависит ли спрос на товар от скидок на него при p=0.99?
Решение
В соответствии с таблицей n1=12, n2=11
Вычислим дисперсии D(X), D(Y)
| № п/п | X | Y | D(X) | D(Y) |
| 1 | 25 | 19 | 78,028 | 107,4 |
| 2 | 34 | 31 | 0,0278 | 2,6777 |
| 3 | 23 | 17 | 117,36 | 152,86 |
| 4 | 35 | 24 | 1,3611 | 28,769 |
| 5 | 33 | 28 | 0,6944 | 1,8595 |
| 6 | 25 | 31 | 78,028 | 2,6777 |
| 7 | 45 | 39 | 124,69 | 92,86 |
| 8 | 41 | 32 | 51,361 | 6,9504 |
| 9 | 27 | 38 | 46,694 | 74,587 |
| 10 | 54 | 43 | 406,69 | 185,95 |
| 11 | 32 | 21 | 3,3611 | 69,95 |
| 12 | 32 | 3,3611 | ||
| Сумма | 406 | 323 | 911,67 | 726,55 |
| Среднее | 33,833 | 29,364 |
Подставим значения в формулу стандартной ошибки разности средних арифметических σxy:
Вычисляем критерий Стьюдента:
Число степеней свободы равно:
k=12+11–2=21
По таблице Стьюдента находим критическое значение:
tкрит=2,8310
Отсюда tкрит> tнабл, следовательно, зависит.
![]() 19847
19847