KEDB, или база данных известных ошибок, — важный компонент базы знаний, который ускоряет решение проблем. В общем виде KEDB содержит:
- Описание проблемы, как, когда и почему она возникает, как проявляется с точки зрения пользователя.
- Скриншоты — например, с текстом сообщения об ошибке.
- Описание решения проблемы либо обходного пути (временного решения) — в идеале пошаговая инструкция, в которой, где это нужно, используются скриншоты и видео.
Основное назначение KEDB — помочь специалисту Service Desk быстро решить проблему, чтобы минимизировать простой клиентского сервиса. Чем больше известных ошибок в KEDB, тем она полезнее и эффективнее как инструмент поддержки.
KEDB, как правило, не смешивают с общей базой знаний и выделяют в отдельную подбазу. KEDB — более динамичная структура, которая больше подходит для описания временных проблем. Такие проблемы архивируются или удаляются из базы по мере устранения ошибок.
Различают тестирование по типам:
- черный ящик (без просмотра исходного текста);
- белый ящик (с изучением исходного текста);
и по объему:
- маленький тест, типа печати «hello, world», чтобы понять, есть ли вообще о чем говорить;
- получаcовое тестирование (американцы говорят «Тест на одну сигарету»), обычно проверяют по одному тесту на каждую функцию программы перед серьезным тестированием;
- модульное тестирование;
- комплексное тестирование.
Особого упоминания заслуживают тестирование граничных значений входных данных, тесты на максимальный объем счета, проверка предположений об ошибках («Я бы сделал ошибку здесь»).
Иногда применяется перекрестное чтение особо ответственных участков программы, когда одна группа разработчиков читает программы другой группы (insрection peer review). В США очень популярны Bugs festivals, когда незадолго перед выпуском системы фирма платит определенную сумму за каждую найденную ошибку. Список таких приемов можно расширить, но вряд ли их можно считать общеупотребительными.
В зрелых программистских компаниях для каждого проекта ведется своя база данных ошибок, в которую вносится:
- кто нашел ошибку, дата;
- описание ошибки;
- модуль, в котором ошибка обнаружилась (возможно, это наведенная ошибка, может быть, она вызвана ошибкой в совсем другом модуле);
- версия продукта;
-
статус ошибки:
- open: найдена
- fixed: исправлена
- can’t reproduce: невозможно воспроизвести
- by design: ошибка проектировщиков
- wont fix: это не ошибка (тестеру показалось)
- postponed: сейчас исправить трудно, исправим в следующей версии
- regression: исправленная ошибка появилась вновь
- Важность (severity) ошибки:
- сrash: все падает, полная потеря данных
- major problem: падает частично, частичная потеря данных
- minor problem: что-то не то, но данные не теряются
- trivial: сейчас не стоит исправлять
- Приоритет ошибки:
- highest: невозможно поставить продукт с такой ошибкой, не можем перейти к следующей версии
- high: поставить не можем, но можем перейти к следующей версии
- medium: можем и исправим
- low: косметические улучшения – оставим на следующую версию.
Особенно заметна ценность базы данных ошибок для больших и длительных проектов. Если идентификатор одной ошибки встречается десятки раз в различных письмах, недельных отчетах – это верный признак того, что требуется вмешательство руководства. Все руководители разных рангов знают на память записи из этой базы данных о текущих ошибках с высшей важностью и приоритетом. По завершении каждого проекта база данных ошибок внимательно анализируется. Интересно распределение ошибок по тому, кто их совершил, по времени исправления, кто чаще ошибки находит и т.д. Если в одну неделю разработчик 1 сделал 10 ошибок, а разработчик 2 – только 2, это еще ни о чем не говорит. Но если же за весь период разработки разработчик 1 сделал 100 ошибок, а разработчик 2 – только 10, то по этим цифрам можно уже судить об их квалификации. Можно также оценивать целые группы или, скажем, качество проектирования, а можно сделать какие-то выводы по мощности и надежности используемых инструментальных средств.
На основе изучения записей в базе данных ошибок руководство проектом принимает решение о возможности выпуска продукта, например, продукт нельзя выпускать, если есть хотя бы одна ошибка с важностью «crash» или с приоритетом «highest/high». Возможна и такая стратегия, когда продукт выпустить обязательно надо, но времени на исправление основных ошибок нет (нужно помнить, что даже небольшие исправления могут повлечь за собой новые ошибки), тогда из продукта просто удаляют часть функций, в которых есть ошибки.
Мы говорили о тестировании, только отдавая дань многолетней традиции. На самом деле, любая зрелая программистская компания имеет большую независимую группу оценки качества ПО (Quality Assurance или просто QA), функции которой намного шире, чем просто тестирование. Для каждого продукта проверяется:
- полнота и корректность документации;
- корректность процедур установки и запуска;
- эргономичность использования;
- полнота тестирования.
QA должна играть роль придирчивого пользователя, но внутри компании. В США разработчики и QA сидят в разных концах коридора, не поощряется даже неформальное общение. В западных компаниях довольно существенную часть зарплаты (примерно 20-30%) составляет бонус, выплачиваемый в конце проекта и только в случае его успешного завершения. Так вот, если QA найдет слишком много ошибок разработчиков, те остаются без бонуса, но если QA принял разработку, а затем пользователи начнут жаловаться, то QA остается без бонуса, хотя жалобы связаны с ошибками разработчиков. Таким искусственным разделением ответственности и непоощрением дружеских отношений между разработчиками и QA владельцы компаний пытаются застраховаться от неудачи на рынке. В США говорят, что каждому продукту дается только одна попытка выхода на рынок. Если пользователям по разным причинам продукт не понравился, репутация теряется навсегда. Поэтому ошибки так дорого стоят.
О чём могут рассказать логи: важный инструмент в работе тестировщика
Уровень сложности
Средний
Время на прочтение
6 мин
Количество просмотров 8.3K
Привет, Хабр! Меня зовут Анфиса Одинцова, я — наставница в Яндекс Практикуме на курсе «Инженер по тестированию». Сейчас работаю в JoomPay, а раньше — в Яндекс Дзен и ВК. В этой статье расскажу о важном аспекте тестирования — работе с логами. Ведь в мире разработки программного обеспечения логирование играет ключевую роль в обеспечении качества и отладке приложений. Для тестировщиков логи — ценный инструмент, который помогает нам понять работу приложения, обнаружить потенциальные проблемы и сделать наше тестирование более эффективным.
Мы рассмотрим, зачем в работе могут понадобиться логи, какие виды логирования существуют и что внутри лога может быть нам полезным.
Что такое логи и когда в них смотреть
Логи — это записи событий и сообщений, создаваемые программой или системой во время ее работы. Они представляют собой источник информации о том, что происходит внутри приложения в определённый момент времени. Логи содержат различные данные, такие как сообщения об ошибках, предупреждения, информацию о выполнении определённых действий и многое другое.
Когда тестировщик смотрит в логи
В зависимости от вида проводимого тестирования тестировщик может воспользоваться информацией из логов.
-
При тестировании новой фичи. Стоит держать логи открытыми, они помогут отследить правильность выполнения определенных операций, последовательность событий и другие аспекты функциональности приложения.
К примеру, если упадет ошибка (ERROR) или предупреждение (WARN) — о них мы подробнее поговорим дальше, — мы всегда могли сообщить разработчику и быстро нейтрализовать проблему. -
При релизе приложения и проведении регрессионного тестирования нужно проверять логи, часто в командах это делают разработчики.
-
При проверке взаимодействия с внешними системами, такими как базы данных, API или другие службы. Логи могут содержать информацию о запросах и ответах, передаваемых данным, кодах состояния и других деталях взаимодействия.
-
Для более точного определения причины бага и отладки ошибки. В логах может содержаться необходимая информация для идентификации бага, логи могут содержать полезную информацию о возникших исключениях, трассировке стека, сообщениях об ошибках или недостаточных данных, которые могут помочь воспроизвести и понять причину ошибки. А чем больше информации мы принесём разработчику, тем быстрее он починит баг.
-
Для оценки производительности приложения. Логи могут содержать информацию о времени выполнения определенных операций, использовании ресурсов (например, процессора, памяти) и других показателях производительности. Тестировщик может использовать эти данные для определения узких мест в приложении и предложения улучшений.
-
При работе с событиями системы. Вас могут попросить разработчики или вам самим потребуется более детальная информация для понимания работы системы.
Типы и уровни логов
Для начала разберёмся в категориях логов. Логи бывают разных типов и уровней детализации и критичности.
Уровни логирования
Уровни логирования определяют, насколько важная информация будет записываться в лог-файлы или выводиться при выполнении программы. На верхнем уровне находятся самые важные сообщения. На них стоит обращать внимание в первую очередь. Чем ниже уровень логирования, тем менее критичная, но более подробная информация содержится в логе.
Тестировщику они нужны для понимания того, есть ли ошибка / насколько она серьёзная и нужно ли заводить баг и отнести баг-репорт.
Уровни логирования бывают:
-
FATAL: является наивысшим уровнем критичности логов и указывает на самые критические ошибки и проблемы, которые могут привести к немедленному завершению программы или системы. Логи с уровнем FATAL обычно означают серьезные сбои, которые требуют немедленного вмешательства и исправления.
-
ERROR: этот уровень используется для записи ошибок и проблем, которые могут привести к некорректной работе приложения. Логи с уровнем ERROR указывают на проблемы, которые требуют вмешательства и исправления.
-
WARN: уровень WARN указывает на предупреждения и потенциальные проблемы, которые не являются критическими ошибками. Логи с уровнем WARN могут включать сообщения о неправильном использовании приложения, некорректных данных или других ситуациях, требующих внимания.
-
INFO: этот уровень предоставляет информацию о ходе работы приложения и важных событиях. Логи с уровнем INFO содержат сообщения, которые помогают отслеживать основные операции и состояние приложения. Например, они могут сообщать о начале и окончании определенных операций, загрузке ресурсов, отправке и получении запросов, изменении состояния приложения и других событиях, которые могут быть полезны для отслеживания хода выполнения программы.
-
DEBUG: содержат подробности о ходе выполнения приложения, значимые переменные и другие данные, которые могут быть полезными при обнаружении и исправлении ошибок.
-
TRACE: это наиболее подробный уровень логирования. Логи с уровнем TRACE содержат очень подробную информацию о состоянии приложения, включая значения переменных, шаги выполнения и другие детали. Они обычно используются во время отладки и разработки для более глубокого анализа приложения.
Уровни детализации, с которыми чаще всего сталкивается тестировщик
Тестировщик чаще всего работает с ошибками (ERROR, реже FATAL) и c предупреждениями (WARN). Но для получения информации иногда, бывает, обращается к информационным логам (INFO).
Уровень логирования может быть настроен в зависимости от потребностей разработчика или тестировщика.
Обычно в продакшене уровень детализации не устанавливается на самый высокий, чтобы не перегружать логи большим объёмом информации. В то время как во время разработки или отладки можно использовать такие уровни детализации, как DEBUG или TRACE, для более глубокого анализа и отслеживания проблем.
Визуально уровни логирования можно представить таким образом:

Какие виды логов бывают и зачем их знать тестировщику
Существует несколько различных видов логов, которые широко используются в программировании и системном администрировании.
Зачем их знать тестировщику? Чтобы понимать, к какому типу логов обратиться для проверки и дебага сервера или клиента, например при тестировании бэкенда, нам скорее всего понадобятся логи сервера.
Тестировщик чаще всего работает с логами приложения, логами сервера и системными логами. Разберёмся, что значит каждый из видов:
-
Логи приложений (Application logs). Это логи, создаваемые самим приложением в процессе его работы. Это может быть веб, десктоп и мобильное приложение. Они содержат информацию о выполнении операций, событиях, ошибочных ситуациях, запросах, ответах и других событиях, внутри приложения.
-
Логи сервера (Server logs). Это логи, генерируемые серверами и веб-серверами. Они содержат информацию о работе сервера, запросах, ошибочных ситуациях, подключениях и других событиях, происходящих на сервере. Логи сервера помогают администраторам серверов и разработчикам отслеживать состояние сервера, обнаруживать проблемы с производительностью, безопасностью и настраивать серверное окружение.
Логи сервера часто делятся на два типа:
-
Error logs (это информация об ошибках)
-
Access Logs (общая информация о запросах и ответах к серверу)
-
Системные логи (System logs): Это логи, записываемые операционной системой. Они содержат информацию о работе операционной системы, событиях, ошибках, состоянии системы, процессах, сетевых подключениях и других системных событиях.
Это основные виды логов, с которыми обычно приходится сталкиваться тестировщику. Также существуют и другие виды, но чаще всего в работе тестировщик к ним не обращается.

Что хранится в логах
Разные виды и логи разной детализации содержат в себе информацию разного вида. Информация в логах также зависит от того, что туда решил положить разработчик, также от решения разработки зависит, какие уровни детализации и критичности логов будут использованы.
Большинство разработчиков стараются придерживаться общих правил написания логов. К примеру, практически любой лог имеет:
-
системную информацию (время и дата события, ID события и другая служебная информация);
-
уровень лога;
-
текст сообщения (например, сообщения об ошибке);
-
контекст (дополнительная информация).
Разберем, как это выглядит, на сообщении об ошибке:

Дата и время: 2023-05-18 10:23:45 — указывает точное время, когда произошла ошибка.
Уровень лога: [ERROR] — указывает на уровень ошибки.
Контекст: [Server] — указывает на компонент или модуль системы, в котором произошла ошибка.
Сообщение об ошибке: Exception occurred while processing request — описание самой ошибки.
Стек вызовов: Последующие строки показывают стек вызовов и указывают на классы и методы, в которых произошла ошибка. В данном примере указывается, что ошибка возникла в методе handleRequest класса MyController (строка 32), затем в методе processRequest класса Server (строка 87) и так далее.

Заключение
Обладая знаниями о логировании системы, тестировщик может легко понять, что происходит во время его работы с приложением, быстро отследить ошибки и лучше описывать ошибки внутри своих репортов. Это серьёзно ускорит процесс исправления бага, а значит, и скорость разработки новых фич и релиза.
Блоги, форумы, посадочные страницы и другие интернет-ресурсы представляют собой совокупность графического, текстового, аудио- и видео-контента, размещенного на веб-страницах в виде кода. Чтобы обеспечить к ним доступ пользователей через интернет, файлы размещают на серверах. Это аппаратное обеспечение (персональный компьютер или рабочая станция), на жестком диске которого и хранится код. Ключевые функции выполняются без участия человека, что актуально для всех типов оборудования, включая виртуальный выделенный сервер. Но это не означает, что контроль не осуществляется. Большинство событий, которые происходят при участии оборудования, пользователей и софта, включая ошибки, логи сервера фиксируют и сохраняют. Из этой статьи вы узнаете, что они собой представляют, зачем нужны, и как их читать.

Что такое логи
Это текстовые файлы, которые хранятся на жестком диске сервера. Создаются и заполняются в автоматическом режиме, в хронологическом порядке. В них записываются:
- системная информация о переданных пользователю данных;
- сообщения о сбоях и ошибках;
- протоколирующие данные о посетителях платформы.
Посмотреть логи сервера может каждый, у кого есть к ним доступ, но непосвященному обывателю этот набор символов может показаться бессмысленным. Интерпретировать записи и получить пользу после прочтения проще профессионалу.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Классификация логов
Для каждой разновидности софта предусмотрены соответствующие файлы. Все логи сервера могут храниться на одном диске или даже на отдельном сервере. Существует довольно много разновидностей логов, вот наиболее распространенные:
- доступа (access_log) — записывают IP-адрес, время запроса, другую информацию о пользователях;
- ошибок (error_log) — показывают файлы, в которых выявлены ошибки и классифицируют сбои;
- FTP-авторизаций — отображают данные о попытках входа по FTP-соединению;
- загрузки системы — с его помощью выполняется отладка при появлении проблем, в файл записываются основные системные события, включая сбои;
- основной — содержит информацию о действиях с файерволом, DNS-сервером, ядром системы, FTP-сервисом;
- планировщика задач — в нем выполняется протоколирование задач, отображаются ошибки при запуске cron;
- баз данных — хранит подробности о запросах, сбоях, ошибки в логах сервера отображаются наравне с другой важной информацией;
- хостинговой панели — включает статистику использования ресурсов сервера, время и количество входов в панель, обновление лицензии;
- веб-сервера — содержит информацию о возникавших ошибках, обращениях;
- почтового сервера — в нем ведутся записи о входящих и исходящих сообщениях, отклонениях писем.
Записи в системные журналы выполняет установленный софт.
Зачем нужны логи
Анализ логов сервера — неотъемлемая часть работы системного администратора или веб-разработчика. Обрабатывая их, специалисты получают массу полезных сведений. Используются в следующих целях:
- поиск ошибок и сбоев в работе системы;
- выявление вредоносной активности;
- сбор статистики посещения веб-ресурса.
После изучения информации можно получить точную статистику в виде сводных цифр, информацию о юзерах, выявить поведенческие закономерности пользовательских групп.
Читайте также

Где посмотреть логи
Расположение определяется хостинг-провайдером или настройками установленного софта. На виртуальном хостинге доступ к лог-файлам предоставляется из панели управления хостингом. Если администратор не открыл его для владельца сайта, получить информацию не получится. Но большинство провайдеров разрешают свободно пользоваться журналами и проводить анализ логов сервера. Независимо от разновидности сервера лог-файлы хранятся в текстовом документе. По умолчанию он называется access.log, но настройки позволяют переименовать файл. Это актуально для Nginx, Apache, прокси-разновидностей squid, других типов. Для просмотра их надо скачать и открыть в текстовом редакторе. В качестве альтернативы можно использовать Grep и схожие утилиты. Они позволяют открыть и отфильтровать логи прямо на сервере.

Как читать логи. Пример
Существует довольно много форматов записи, combined — один из наиболее распространенных. В нем строчка кода может выглядеть так:
%h %l %u %t \»%r\» %>s %b \»%{Referer}i\» \»%{User-Agent}i\»
Директивы имеют следующее значение:
- %h — IP-адрес, с которого был сделан запрос;
- %l — длинное имя удаленного хоста;
- %u — удаленный пользователь, если запрос был сделан аутентифицированным юзером;
- %t — время запроса к серверу и его часовой пояс;
- %r — тип и содержимое запроса;
- %s — код состояния HTTP;
- %b — количество байт информации, отданных сервером;
- %{Referer} — URL-источник запроса;
- %{User-Agent} — HTTP-заголовок.
Еще один пример чтения логов можно посмотреть в статье «Как читать логи сервера».
Опытные веб-мастера для сбора и чтения лог-файлов используют программы-анализаторы. Они позволяют читать логи сервера без значительных временных затрат. Вот некоторые из наиболее востребованных:
- Analog. Один из самых популярных анализаторов, что во многом объясняется высокой скоростью обработки данных и экономным расходованием системных ресурсов. Хорошо справляется с объемными записями, совместим с любыми ОС.
- Weblog Expert. Программа доступна в трех вариациях: Lite (бесплатная версия), Professional и Standard (платные релизы). Версии отличаются функциональными возможностями, но каждая позволяет анализировать лог-файлы и создает отчеты в PDF и HTML.
- SpyLOG Flexolyzer. Простой аналитический инструмент, позволяющий получать отчеты с высокой степенью детализации. Интегрируется c системой статистики SpyLOG, позволяет решать задачи любой сложности.
Логи сервера с ошибками error.log
Это журнал с информацией об ошибках на сайте. В нем можно посмотреть, какие страницы отсутствуют, откуда пришел пользователь с конкретным запросом, имеются ли «битые» ссылки, другие недочеты, включая те, которые не удалось классифицировать. Используется для выявления багов и погрешностей в коде.
Каждая ошибка в логе сервера error.log отображается с новой строки. Идентифицировав и устранив ее, программист сможет наладить работу сайта. Используя журнал, можно выявить и слабые места веб-платформы. Это простой и удобный инструмент анализа, которым должен уметь пользоваться каждый веб-мастер, системный администратор и программист.
#статьи
-

0
База данных: что это такое и зачем она нужна
Рассказываем, как работают базы данных, почему их используют, какие они бывают и чем отличаются от СУБД.
Иллюстрация: Shutterstock / imgix / jms / Arina Bondar / Unsplash / Polina Vari для Skillbox Media

Любитель научной фантастики и технологического прогресса. Хорошо сочетает в себе заумного технаря и утончённого гуманитария. Пишет про IT и радуется этому.
Если вы захотите написать приложение, которое будет использовать данные пользователей, — например, интернет-магазин или игру, вам точно понадобится база данных. Как раз чтобы работать с этими данными.
В информатике базой данных называют совокупность данных, организованных по определённым правилам. Но мы дадим более простое определение.
База данных (БД) — это набор данных, который как-то структурирован. Например, можно взять сто картинок с котами и отсортировать их по цвету или по позе.

Иллюстрация: Polina Vari для Skillbox Media
Обычно данные в БД записывают в виде таблицы — строк и столбцов. В такой архитектуре каждая строка — это новый элемент, у которого есть некоторые свойства — столбцы. Тех же котов можно отсортировать по множеству параметров — например, цвету, позе и весу.
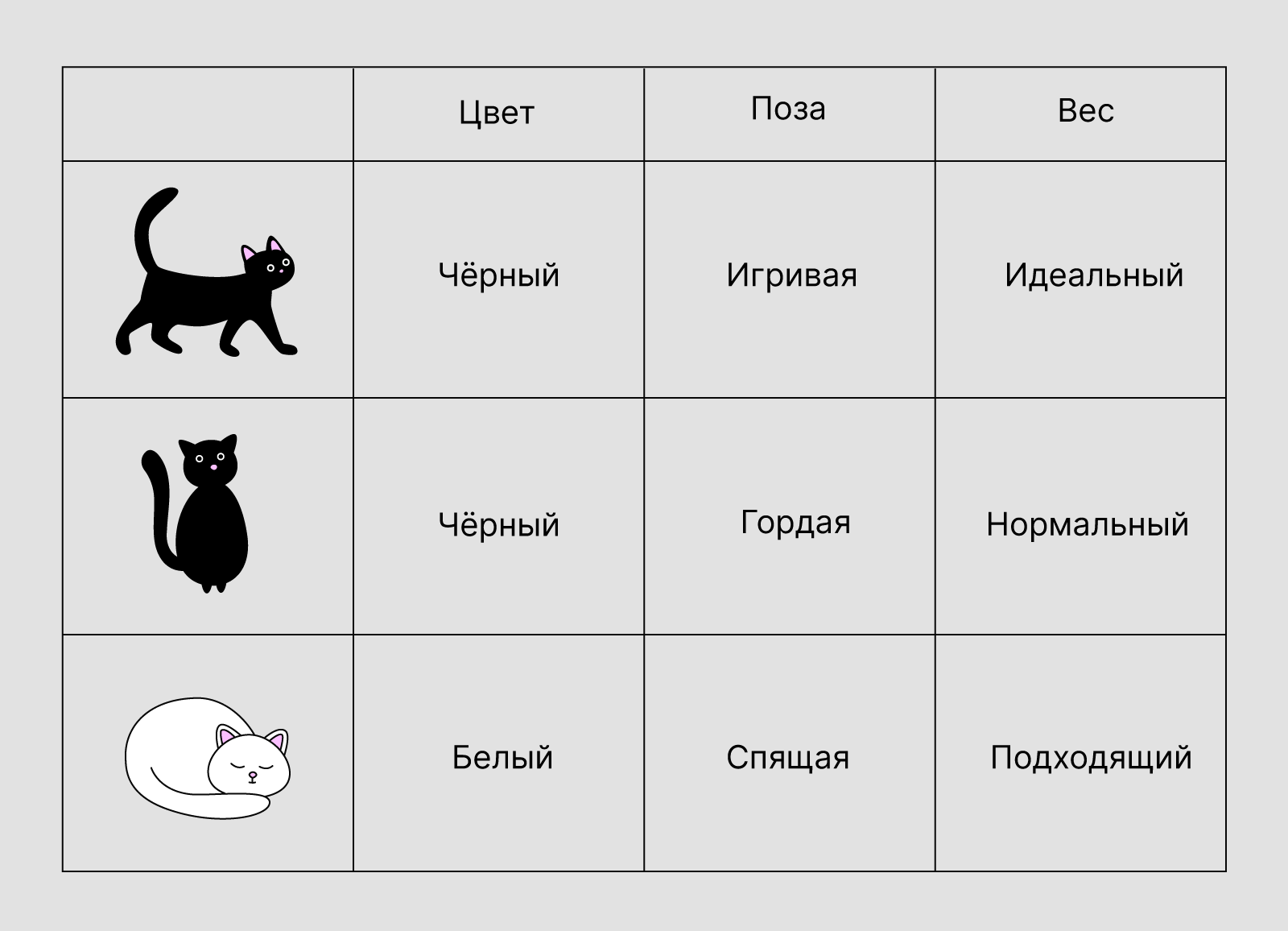
Иллюстрация: Polina Vari для Skillbox Media
Базу данных нельзя назвать программой в полном смысле этого слова. Это скорее просто файлик, в котором записаны данные. А чтобы достать из этого файла данные, сначала нужно написать программу, которая будет всё это делать, то есть управлять базой данных.
Например, вы хотите найти элемент по индексу и решили написать программу, которая умеет это делать. А затем вам вдруг понадобилось отсортировать записи в БД по каким-то параметрам. И вы пишете ещё один скрипт, который уже умеет сортировать таблицы. Так вы продолжаете создавать всё новые и новые мини-программы для разных мини-задач.
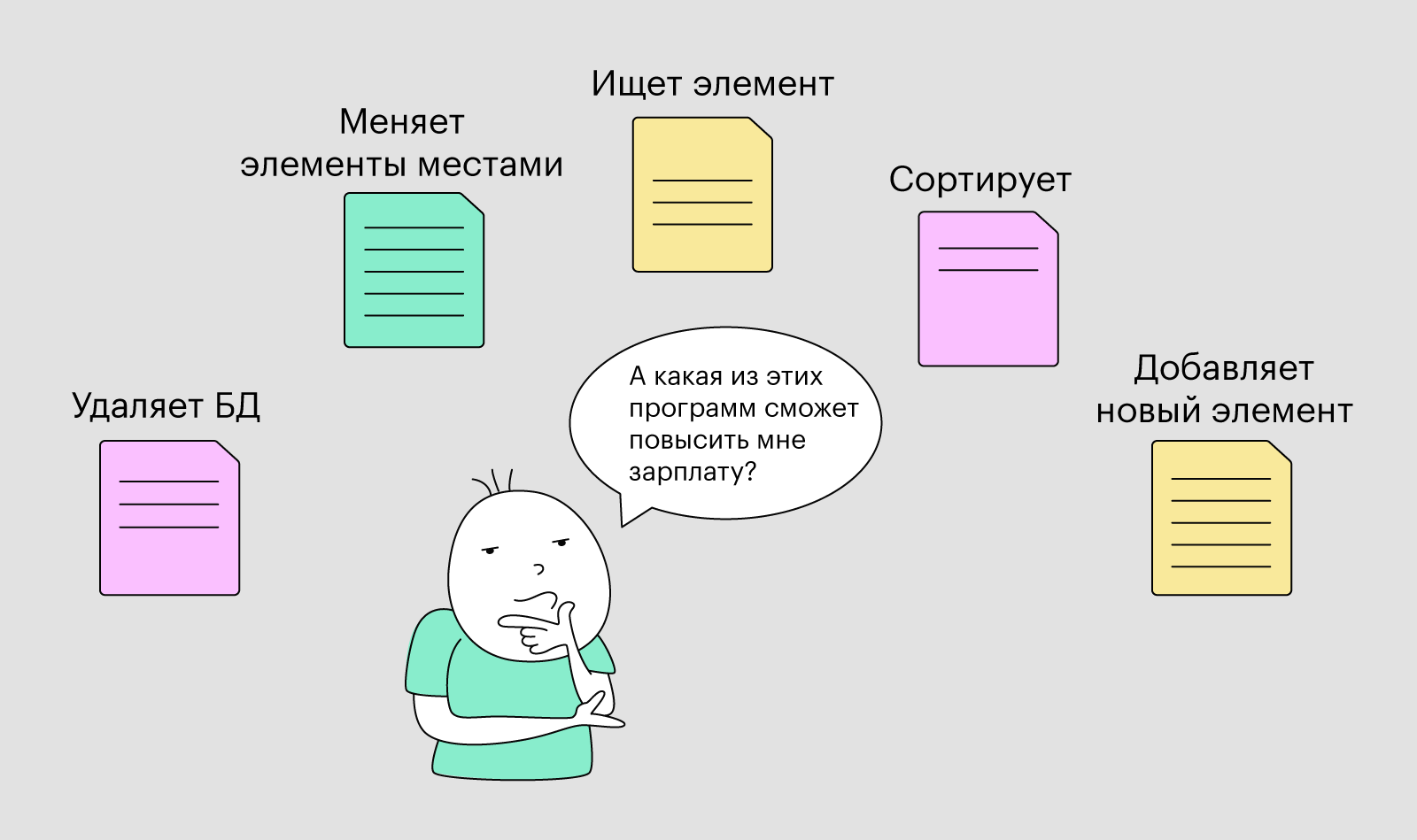
Иллюстрация: Polina Vari для Skillbox Media
В итоге у вас копится куча полезных скриптов на все случаи жизни и вы понимаете: «А зачем каждый раз писать что-то новое, объединю-ка я эти скрипты в одну программу и назову её системой управления базами данных, или СУБД». Так что СУБД позволяют просто манипулировать данными в БД — например, доставать элементы, добавлять новые и удалять ненужные, не отвлекаясь на код.
Получается, что база данных — это просто файл на диске компьютера, а СУБД — это инструменты, которые помогают управлять базами данных. Кстати, нередко базами данных называют именно СУБД, такая вот терминологическая путаница и ад для душнилы-перфекциониста.
Давайте на примере рассмотрим, зачем люди используют базы данных.
Допустим, мы открыли магазин музыкальных инструментов. Теперь нам нужно создать сайт, чтобы продавать товары в онлайне. На сайте должен находиться весь ассортимент магазина, при этом информация о наличии инструментов всегда должна поддерживаться в актуальном состоянии.
Для этого мы создадим базу данных и добавим в неё наши музыкальные инструменты. В итоге получится большая таблица, каждая строка которой — отдельный инструмент, а каждый столбец — его свойство. Среди свойств мы пока остановимся на трёх: цена, количество товара на складе и тип инструмента.
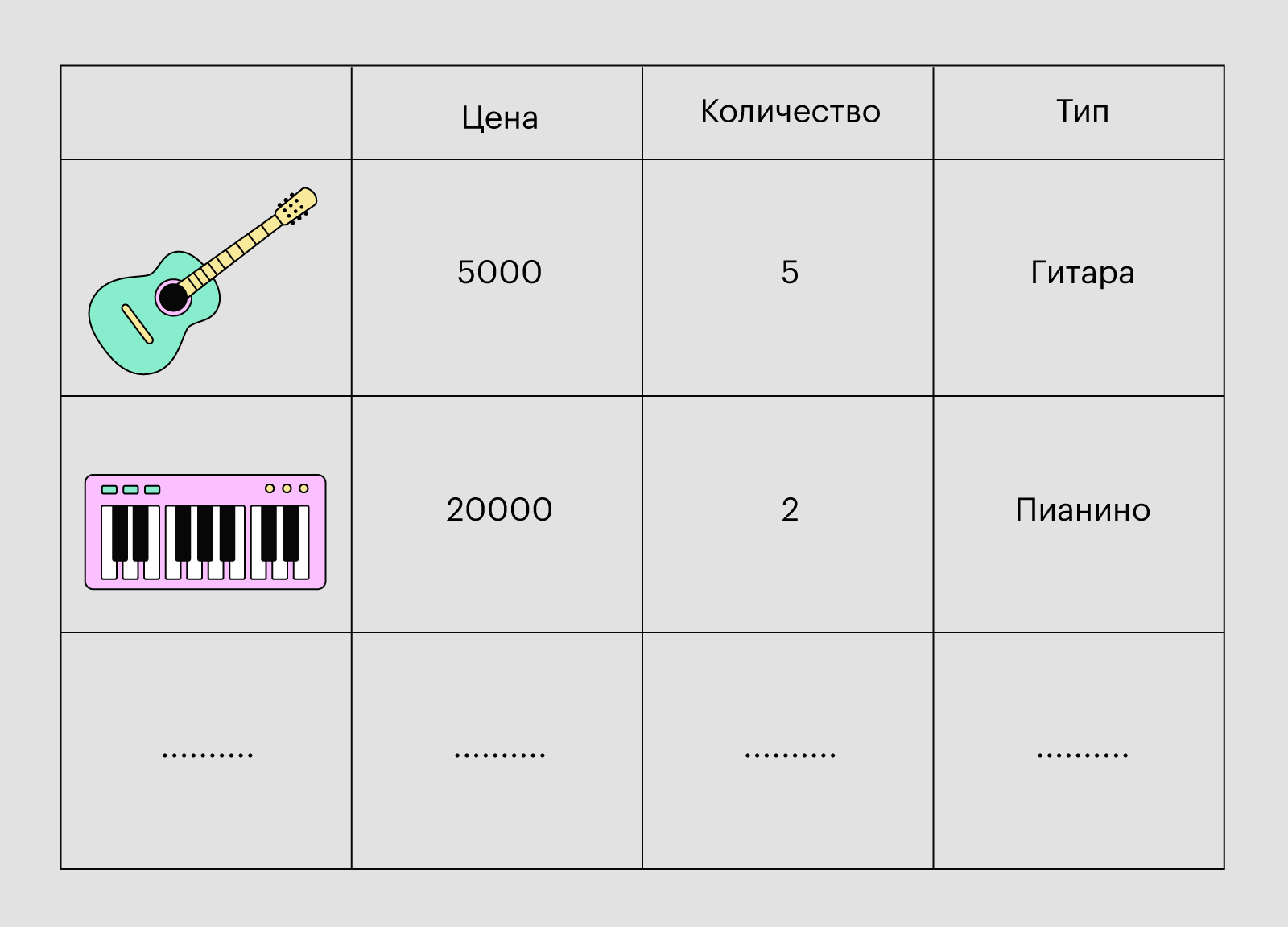
Иллюстрация: Polina Vari для Skillbox Media
Теперь, когда у нас есть база данных со всеми товарами, мы должны понять, что именно мы будем с этими данными делать. Вот основные операции, которые пригодятся интернет-магазину:
- Записать новые данные. Чтобы мы могли добавить новый инструмент, когда он приедет на склад.
- Изменить старые данные. Чтобы изменить цену товара или его количество на складе.
- Найти данные. Чтобы найти, например, все синтезаторы и показать клиенту.
- Позволить читать данные только работникам, а всем остальным закрыть доступ. Чтобы клиенты сами не меняли цены товаров и не получали их бесплатно.
- Поддерживать данные в порядке. Чтобы быть уверенным: в категории «Гитары» будут лежать именно гитары, а не барабаны.
- Масштабировать базу данных. Чтобы добавлять новые данные и не переживать об ограничениях по объёму.
- Ничего не потерять. Чтобы, даже если магазин сгорит, мы всегда могли восстановить базу данных.
Эти принципы применимы к любой базе данных, а не только к нашему примеру.
Если бегло посмотреть на базу данных и электронную таблицу, можно не увидеть разницы. Но она есть — и сейчас мы о ней расскажем.
Представим, что у нас есть Excel-таблица, в которой мы ведём учёт всех клиентов нашей компании — отмечаем, как их зовут, где они работают, зачем к нам обращались и когда в последний раз мы с ними общались. Этот Excel-файл единый для всей компании, и каждый день им пользуются десятки человек.
Вот вы садитесь за работу, открываете эту таблицу и вносите в неё какие-то изменения. Параллельно с этим ваш коллега тоже открыл её и начал вносить изменения — причём в те же колонки или строки, в которых работаете вы. Вы доделали работу, сохранили файл и закрыли его. Данные перезаписались в таблицу. Но ваш коллега не увидит эти изменения, потому что он открыл файл раньше. Поэтому когда он сохранит свой файл, то перезапишет ваши данные своими, а ваши изменения пропадут.
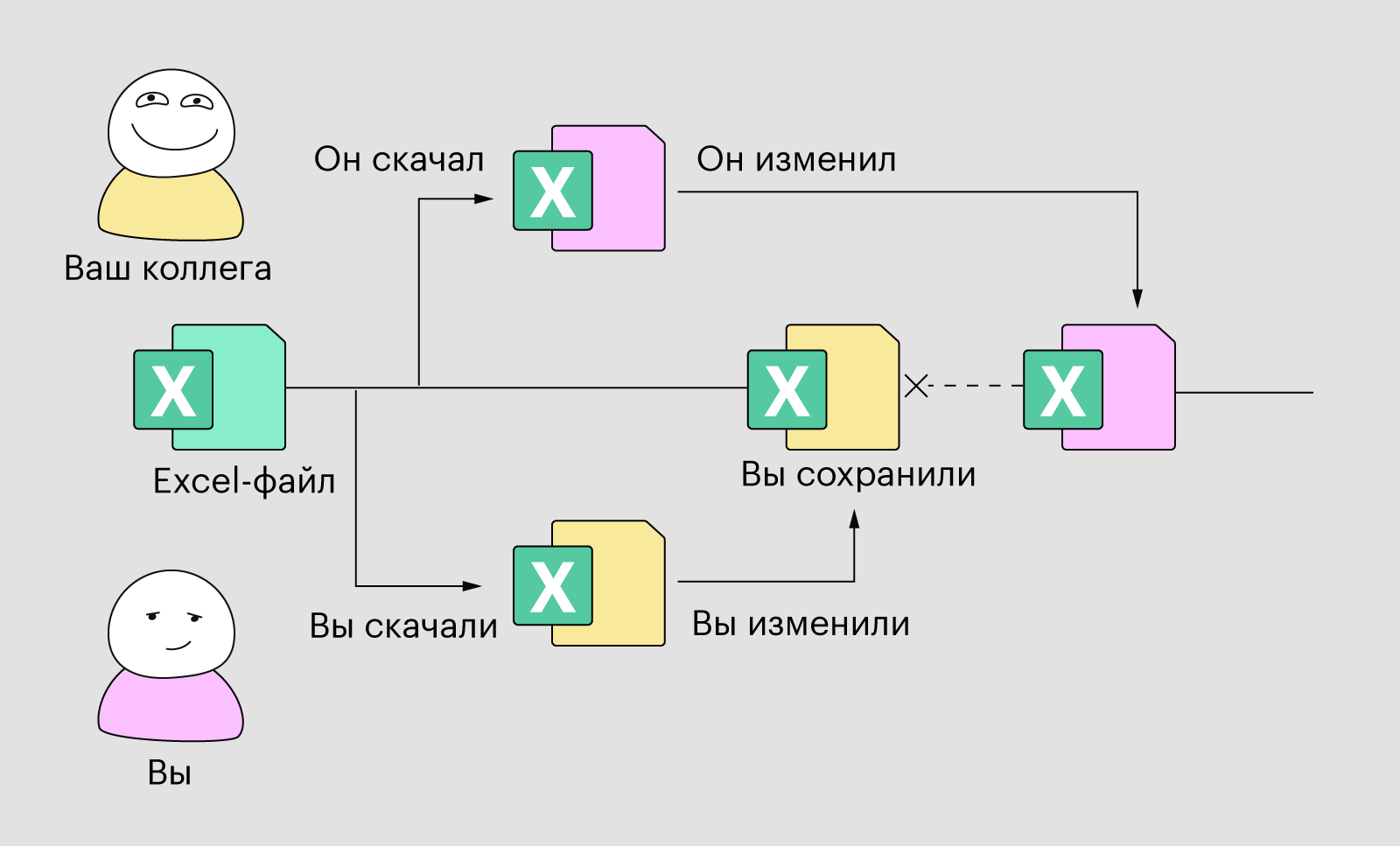
Иллюстрация: Polina Vari для Skillbox Media
С базой данных такой ситуации не произойдёт. Пусть у нас та же ситуация, но таблица — это база данных, которая управляется с помощью какой-то СУБД. Теперь каждый раз, когда вы вносите изменения, они отправляются в виде запросов в СУБД. И даже если ваш коллега будет работать с вами одновременно и тоже отправит запрос, то он встанет в очередь и будет ждать, пока не обработается предыдущий.
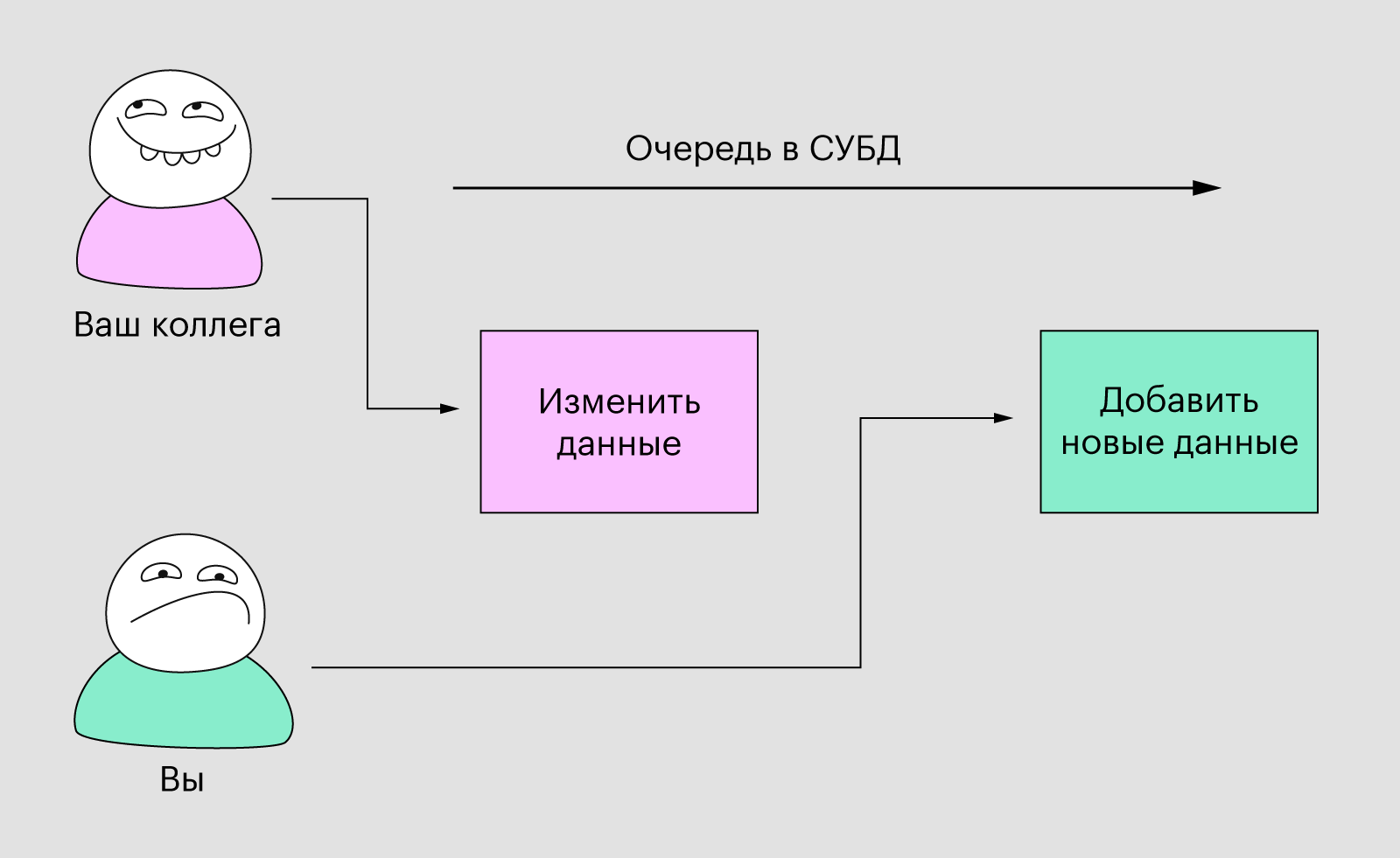
Иллюстрация: Polina Vari для Skillbox Media
Базы данных и СУБД обеспечивают надёжность и помогают избежать ситуаций, когда ваши изменения могут быть утрачены. Это называется разрешением коллизий.
Базы данных разделяют на два основных типа: реляционные и нереляционные. Последние делятся ещё на два: сетевые и иерархические. Получается, существует три главных типа баз данных — реляционные, сетевые и иерархические.
Ещё их называют табличными — из-за того, что все данные они хранят в виде таблиц. Эти таблицы внутри связаны друг с другом, поэтому получается такая связная структура:
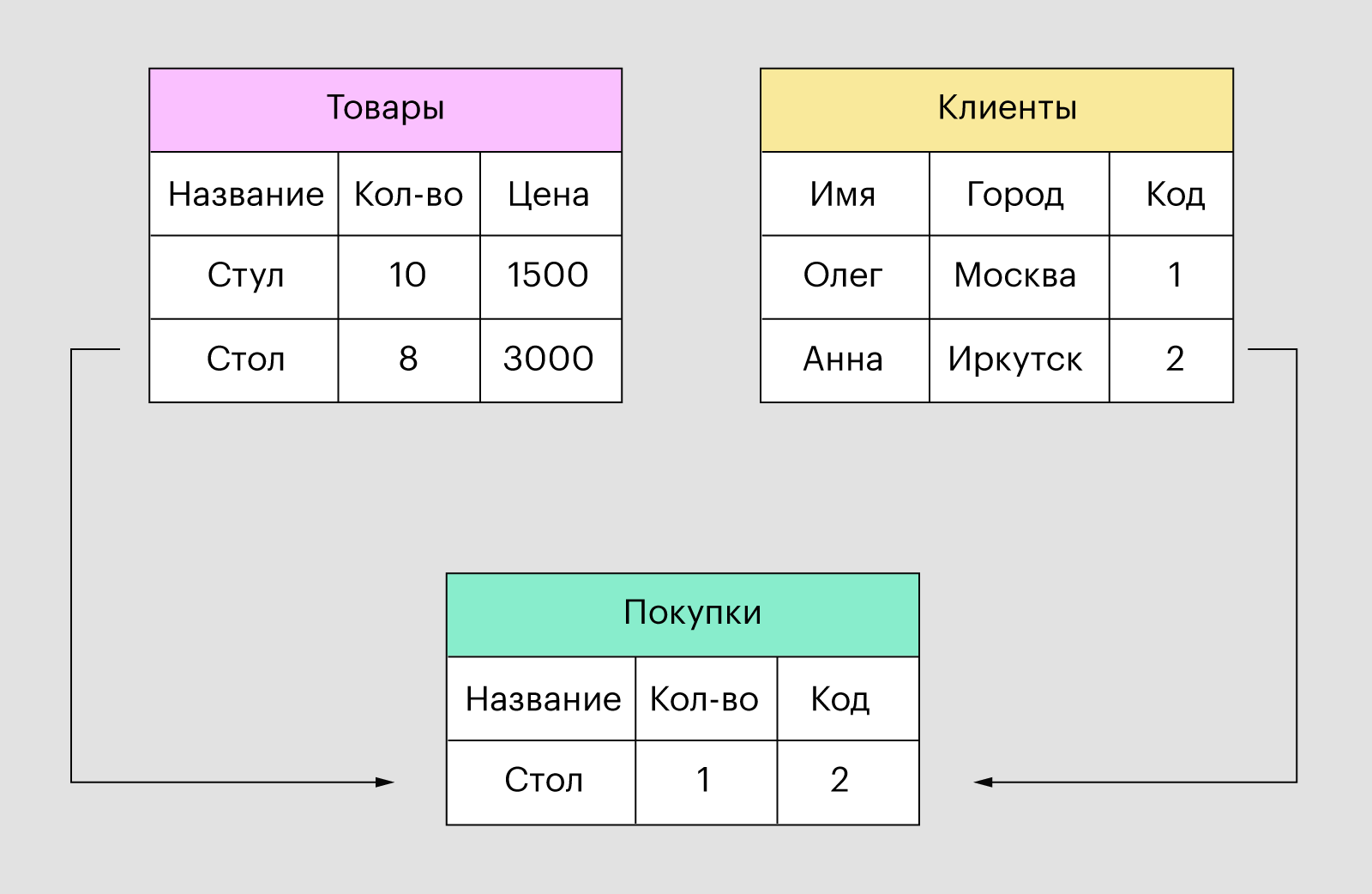
Иллюстрация: Polina Vari для Skillbox Media
У нас есть две таблицы — с покупателями и товарами. Когда покупатель что-то покупает, данные добавляются в третью таблицу. Там находится информация о купленных товарах и ссылки на них.
Такая структура хороша тем, что если поменяются какие-то данные — например, адрес покупателя, то нам нужно будет всего лишь изменить значения в одной таблице, а остальные таблицы трогать не придётся.
Их отличие от реляционных в том, что между таблицами и их записями может быть несколько разных связей. Каждая такая связь отвечает за что-то своё.
Сетевые базы данных применяют, например, в соцсетях:
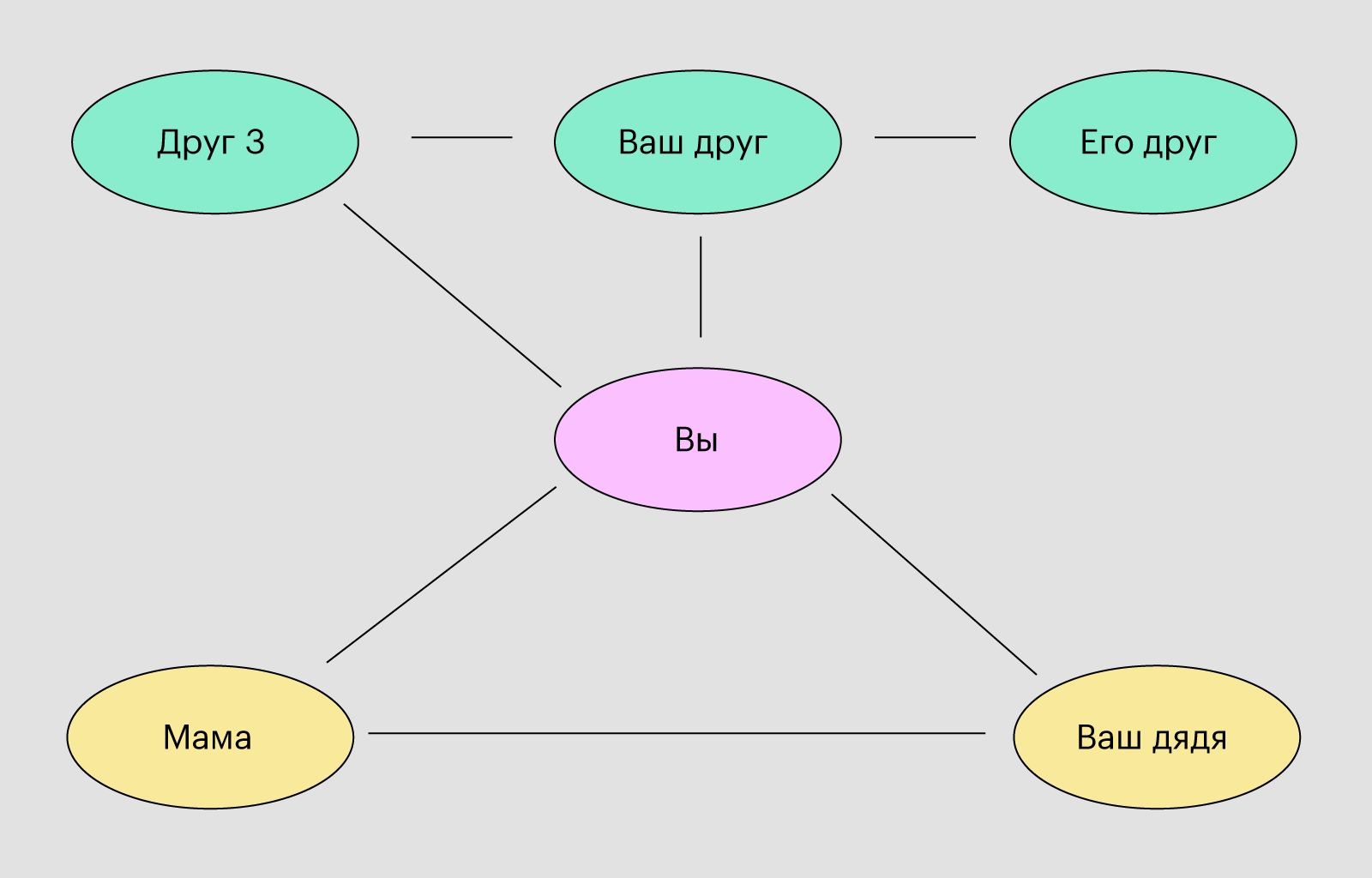
Иллюстрация: Polina Vari для Skillbox Media
Вся информация в сетевой базе данных хранится в отдельных файлах. Она содержит в них сами данные и связи между ними. Базе не приходится тратить время на поиск данных, ведь вся информация уже есть в специальных файлах. В них находятся все связи, позволяющие быстро выдать результат.
Такая структура похожа на файловую систему в Windows. У каждого элемента есть вышестоящий элемент, а есть и подчинённый элемент — тот, что ниже. Поэтому по этой структуре легко перемещаться снизу вверх и сверху вниз.
Изображение: Microsoft Corporation
Иерархическая база данных знает, кто кому подчиняется, а значит, быстро находит информацию. Однако такие базы можно организовать только в том случае, если у вас есть чёткое разделение в данных и вы точно понимаете, какой элемент главный, а какой ему подчиняется.
Базы данных особо не отличаются друг от друга. Они просто хранят информацию в файле. А вот то, что отличается, — это СУБД. И обычно, когда говорят про базы данных, имеют в виду СУБД. Давайте посмотрим, какие из них популярны. Если хотите подробнее прочитать о них — смотрите нашу статью о СУБД.
СУБД имеет большую функциональность и высокую производительность — например, она без проблем может работать с большими данными под высокой нагрузкой.
Язык запросов — SQL, но его можно поменять через расширения на PL/Python, PL/Java и PL/Perl. И ещё одно преимущество PostgreSQL — в ней нет лимита по размеру баз данных и числу записей в таблицах.
Посмотреть можно на официальном сайте.
Скриншот: PostgreSQL
Интерфейс программы позволяет работать с таблицами разных форматов. MySQL работает онлайн и вмещает до 50 миллионов элементов. По функциональности она уступает PostgreSQL. При этом её можно интегрировать с другими СУБД.
MySQL использовали для сайтов и интернет-магазинов такие компании, как Twitter, Alibaba, Meta, Wikipedia.
После того как MySQL купила компания Oracle, пользователи стали немного переживать, что в скором времени база данных может стать платной. Но пока она остаётся бесплатной.
Скачать эту СУБД можно на официальном сайте.
Изображение: MySQL
Эта СУБД добавляет автоматизацию задач — например, можно задать скрипт, который будет управлять памятью. Ещё Microsoft SQL Server позволяет удобно хранить сложные структуры данных и быстро искать их.
СУБД совместима с другими программами Microsoft — например, Excel и Access. С ними можно сделать интеграцию и выгружать данные оттуда, а также изменять их онлайн.
В качестве языка запросов Microsoft SQL Server использует язык SQL.
Посмотреть можно на официальном сайте.
Изображение: Microsoft
SQLite очень компактная СУБД, которая не использует серверы и другие утилиты. Все данные хранятся на одном устройстве.
На SQLite можно написать простой сайт или приложение, у которого будет ограничен трафик и объём данных. СУБД работает на любых устройствах — смартфонах, компьютерах, ТВ и других, куда можно загрузить библиотеку. Она не нуждается в администрировании, а её язык запросов — C.
Посмотреть можно на официальном сайте.
Скриншот: sqliteexpert.com
Главная особенность этой СУБД — данные представлены в виде текстовых документов, которые записаны в формате JSON. MongoDB — NoSQL-СУБД.
Вместо таблиц здесь данные в виде коллекций — групп документов. СУБД оптимизирована для распределённой работы, но также поддерживает локальное хранение данных.
MongoDB используют такие компании, как Meta, Google, Twitter, Forbes, IBM, а также многие интернет-магазины.
Посмотреть можно на официальном сайте.
Скриншот: studio3t.com
Redis можно использовать в облаке — полностью готовую к работе и оптимально настроенную. Она легко масштабируется и управляется.
В Redis можно перенести данные из другой базы данных с помощью автоматизированного сервиса.
Посмотреть можно на официальном сайте.
Скриншот: Hector Hernandez / stackoverflow.com

Oracle DB работает как клиент-сервер. Это значит, что она располагается на сервере вместе с базой данных. Поэтому, чтобы работать с ней, нужен специальный интерфейс приложения-клиента. Пользователь управляет пересылкой и получением данных от сервиса.
Oracle DB обеспечивает высокую безопасность и лёгкий доступ для пользователей. Ещё она позволяет снизить нагрузку на клиентские компьютеры. При этом сервер для СУБД должен быть помощнее.
Посмотреть можно на официальном сайте.
Скриншот: sqlmanager.net
- База данных — это набор элементов, которые сгруппированы по определённым правилам. Они бывают реляционными, графовыми и иерархическими.
- СУБД — это инструменты, которые помогают управлять базами данных. Например, с их помощью можно удалять, изменять и находить элементы.
- Популярные СУБД — PostgreSQL, MySQL, Microsoft SQL Server, SQLite, MongoDB, Redis, Oracle Database.
- Базы данных отличаются от СУБД тем, что сами по себе представляют лишь файл на компьютере. Базы данных не умеют ничего делать с этими данными — только хранить. А вот СУБД уже предоставляют возможности по манипуляции ими.
- Электронные таблицы очень похожи на базы данных, но имеют большой недостаток: если несколько пользователей будут использовать одну таблицу одновременно, есть риск перезаписать данные друг поверх друга и потерять их. С базами данных такого не случится, потому что они обрабатывают запросы по очереди.
* Решением суда запрещена «деятельность компании Meta Platforms Inc. по реализации продуктов — социальных сетей Facebook и Instagram на территории Российской Федерации по основаниям осуществления экстремистской деятельности».

Как зарабатывать больше с помощью нейросетей?
Бесплатный вебинар: 15 экспертов, 7 топ-нейросетей. Научитесь использовать ИИ в своей работе и увеличьте доход.
Узнать больше