По сравнению с ранее разработанными системами 3G радиоинтерфейс LTE обеспечит улучшенные технические характеристики. В частности, в LTE ширина полосы пропускания может варьироваться от 1,4 до 20 МГц (по более ранним источникам – от 1,25 МГц), что позволит удовлетворить потребностям разных операторов связи, обладающих различными полосами пропускания. При этом оборудование LTE должно одновременно поддерживать не менее 200 активных соединений (т.е. 200 телефонных звонков) на каждую 5 МГц ячейку. Также ожидается, что LTE улучшит эффективность использования радиочастотного спектра, т.е. возрастет объем данных, передаваемых в заданном диапазоне частот. LTE позволит достичь внушительных агрегатных скоростей передачи данных – до 50 Мбит/с для восходящего соединения (от абонента до базовой станции) и до 100 Мбит/с для нисходящего соединения (от базовой станции к абоненту) в полосе 20 МГц. При этом должна обеспечиваться поддержка соединений для абонентов, движущихся со скоростью до 350 км/ч. Зона покрытия одной базовой станции – до 30 км в штатном режиме, но возможна работа с ячейками радиусом более 100 км. Поддерживаются многоантенные системы MIMO.
Радиоинтерфейс LTE позиционируется в качестве решения, на которое операторы будут постепенно переходить с нынешних систем стандартов 3GPP и 3GPP2, а его разработка является важным этапом в процессе перехода к сетям четвертого поколения 4G. Фактически спецификация LTE уже содержит большую часть функций, изначально предназначавшихся для систем 4G, поэтому ее иногда именуют «технологией 3,9G».
Но развитие технологии LTE продолжается. Уже разрабатываются спецификации следующего поколения 3GPP Release 10, так называемые LTE-Advanced. На сегодня уже сформулированы основные требования, которым должен будет удовлетворять LTE Advanced. По сути, это требования к стандарту мобильных сетей четвертого поколения (4G):
∙максимальная скорость передачи данных в нисходящем радиоканале до 1 Гбит/с, в восходящем – до 500Мбит/с (средняя пропускная способность на одного абонента – втри раза выше, чем в LTE);
∙полоса пропускания в нисходящем радиоканале – 70 МГц, в восходящем – 40 МГц;
∙максимальная эффективность использования спектра в нисходящем радиоканале – 30 бит/c/Гц, в восходящем – 15 бит/c/Гц (втрое выше, чем в LTE);
∙полная совместимость и взаимодействие с LTE и другими 3GPP системами.
Для решения этих задач предполагается использовать более широкие радиоканалы (до 100 МГц), ассиметричное разделение полос пропускания между восходящим и нисходящим каналом в случае частотного дуплекса; более совершенные системы кодирования и исправления ошибок;
91
гибридную технологию OFDMA и SС-FDMA для восходящего канала, а также передовые решения в области антенных систем (MIMO).
Технология LTE сегодня находится в стадии бурного развития, ежемесячно происходят изменения, в том числе – и в самих стандартах. В самих спецификациях LTE еще хватает незаполненных мест, явных ошибок, неточностей и неопределенностей. Очевидно, следует ожидать появления новых документов в области сетевой архитектуры. Но явное достоинство технологии LTE – ее открытость.
92

Раздел 3. Задачи и методы исследования беспроводных сетей связи
3.1. Постановка задачи исследования беспроводных сетей
Исследование беспроводных сетей, характеризующихся стохастическим характером функционирования, осуществляется с использованием различных моделей и методов в зависимости от класса исследуемой сети, ее особенностей и требований, предъявляемых к качеству ее функционирования. В процессе исследования сети решаются две основные задачи:
∙анализ свойств системы и формирование рекомендаций для проектирования;
∙синтез системы с заданными свойствами и разработка проекта беспроводной сети связи.
Основной целью исследования любых систем является проектирование системы с заданными характеристиками функционирования. Для достижения указанной цели решается множество частных задач с использованием математических моделей разных классов.
На системотехническом уровне можно выделить следующие виды проектирования:
1)функциональное проектирование, заключающееся в определении стратегии управления потоками данных в беспроводной сети;
2)структурное проектирование, заключающееся в определении состава и требований к параметрам оборудования и топологии сети;
3)структурно-функциональное проектирование.
Решение перечисленных задач осуществляется с учетом вида ограничений, налагаемых на показатели эффективности системы беспроводной связи, основными среди которых являются время задержки передачи пакетов и вероятность потери пакетов. В системе, в общем случае, может циркулировать несколько классов пакетов (аудио, видео, компьютерные данные), к которым могут предъявляться различные требования в виде ограничений разных видов.
В общем случае ограничения налагаются на средние значения uk
времени задержки (доставки) в сети пакетов класса k = 1, H в виде:
|
uk ≤ uk* , |
(3.1) |
|
где uk* — заданное ограничение; H – |
количество классов пакетов, |
передаваемых в беспроводной сети.
Для мультимедийного трафика важной характеристикой качества передачи аудио и видео данных является вариация или джиттер задержки σ uk , задаваемый в виде ограничения для разных типов трафика ( k = 1, H ) :
93
Кроме того, при решении задач проектировании реальных систем в качестве критерия эффективности часто используется стоимостной показатель.
Задача функционального проектирования для ограничений любого вида решается с использованием достаточно простых моделей, в частности базовых моделей с неоднородным трафиком, и состоит в определении стратегии управления неоднородным потоком данных. Задачи структурного и структурно-функционального проектирования предполагают, в общем случае, использование более сложных – сетевых моделей, причем при структурном проектировании предполагается, что стратегия управления трафиком либо задана, либо используется бесприоритетная стратегия FIFO.
При решении задач структурного и структурно-функционального проектирования можно выделить два основных этапа:
∙определение параметров минимальной конфигурации беспроводной сети, обеспечивающих функционирование сети минимальной стоимости без учета ограничений на время задержки пакетов;
∙определение оптимальных параметров беспроводной сети, обеспечивающих заданные ограничения на время задержки пакетов при минимальной стоимости.
3.2.Общие принципы моделирования сложных систем
Моделирование представляет собой метод научного познания, при использовании которого исследуемый объект заменяется более простым объектом, называемым моделью. Основными разновидностями процесса моделирования можно считать два его вида — математическое и физическое моделирование.
При оптимизации и решении задач исследования беспроводных сетей предпочтительным оказывается использование математического моделирования.
Особым классом математических моделей являются имитационные модели, которые шаг за шагом воспроизводят события, происходящие в реальной системе. Имитационные модели беспроводных пакетных сетей воспроизводят процессы генерации сообщений приложениями, разбиение сообщений на пакеты и кадры определенных протоколов, задержки, связанные с обработкой сообщений, пакетов и кадров в сетевом оборудовании, процесс получения доступа устройств к разделяемой сетевой среде, процесс обработки поступающих пакетов маршрутизатором и т.д. При имитационном моделировании сети не требуется приобретать дорогостоящее оборудование — его работа имитируется программами, достаточно точно воспроизводящими все основные особенности и параметры такого оборудования. Результатом работы имитационной модели являются собранные в ходе наблюдения за протекающими
94
событиями статистические данные о наиболее важных характеристиках сети: временах реакции, коэффициентах использования каналов и узлов, вероятности потерь пакетов и т.п.
Существуют специальные языки имитационного моделирования, которые облегчают процесс создания программной модели по сравнению с использованием универсальных языков программирования, например
SIMULA, GPSS, SIMDIS.
Система имитационного моделирования GPSS (General Purpose System Simulator) предназначена для разработки имитационных моделей дискретных систем, например систем и сетей массового обслуживания. В системе GPSS моделируемая система представляется с помощью набора абстрактных элементов, называемых объектами, каждый из которых принадлежит к одному из типов объектов. Объект каждого типа характеризуется определенным способом поведения и набором атрибутов, отражающих его свойства. Например, прибор обслуживания имеет некоторую производительность, выражаемую числом заявок, обрабатываемых им в единицу времени. Сама заявка может иметь атрибуты, учитывающие время ее пребывания в системе, время ожидания в очереди и т.д. Характерным атрибутом очереди является ее текущая длина, наблюдая за которой в ходе работы системы (или ее имитационной модели), можно определить ее среднюю длину за время работы (или моделирования). В языке GPSS определены классы объектов, с помощью которых можно задавать приборы обслуживания, потоки заявок, очереди и т.д., а также задавать для них конкретные значения атрибутов.
Имитационная модель беспроводного транспортного сегмента корпоративной сети позволяет провести оценку вероятностно-временных характеристик (ВВХ) трафика: в частности, трафика реального времени и потокового видео с учетом предъявляемых требований.
3.3.Принципы разработки моделей беспроводных сетей
Кмоделям, используемым для исследования беспроводных сетей, предъявляются два противоречивых требования: простота модели и ее адекватность исследуемой системе.
Требование простоты модели обусловлено необходимостью построения модели, которая может быть рассчитана доступными методами. Построение сложной модели может привести к невозможности получения конечного результата имеющимися средствами в приемлемые сроки и с требуемой точностью.
Достижение разумного компромисса между простотой модели и ее адекватностью исследуемой системе является одной из сложнейших проблем моделирования.
95
3.3.1. Классификация математических моделей
При проектировании сложных технических систем наиболее широко применяются математические модели, которые строятся на основе концептуальной модели и позволяют получать конкретные значения параметров проектируемой системы.
Многообразие систем, проявляющееся в многообразии их структурно-функциональной организации, определяет использование множества разных математических моделей, которые могут быть классифицированы в зависимости от:
1)назначения – структурные, функциональные, структурнофункциональные;
2)характера функционирования исследуемой системы –
детерминированные, стохастические;
3)режима функционирования системы – стационарные,
нестационарные.
3.3.2. Параметризация моделей
Количественно любая модель, как и соответствующая ей беспроводная сеть, описывается совокупностью величин, которые могут быть разбиты на параметры и характеристики. Состав параметров и характеристик модели определяется составом параметров и характеристик исследуемой системы и может в идеальном случае совпадать с ним. В общем случае составы параметров и характеристик модели и системы различаются, т.к. в первом случае они формулируются в терминах того математического аппарата, который используется при построении модели, а параметры и характеристики системы формулируются в терминах соответствующей прикладной области, к которой принадлежит исследуемая система. В связи с тем, что, в общем случае, параметры и характеристики системы и модели различаются, их принято называть соответственно системными и модельными.
В связи с тем, что состав и номенклатура системных и модельных параметров и характеристик, в общем случае, различается, возникает необходимость установления соответствия между значениями системных и модельных параметров и характеристик, которое выполняется на этапе
параметризации модели.
Этап параметризации модели в процессе беспроводной сети имеет большое значение для получения корректных результатов. На этом этапе фактически закладывается фундамент адекватности модели исследуемой системе, поскольку именно в процессе параметризации определяются значения исходных параметров, которые будут использованы в модели и обеспечат достоверность получаемых результатов. Ошибки, заложенные при неудачной параметризации, не смогут быть компенсированы даже применением сверхточной (адекватной) модели и точных методов расчета. Более того, ошибки параметризации могут многократно увеличиться и привести к получению абсолютно неправильных значений исследуемых
96
характеристик и, следовательно, к получению некачественного проекта разрабатываемой системы.
Параметризация – это промежуточный этап установления взаимнооднозначного соответствия между концептуальной и математической моделями.
3.4. Базовые модели беспроводных сетей
При решении задач системотехнического проектирования беспроводных сетей со стохастическим характером функционирования в качестве простейших моделей могут использоваться системы и сети массового обслуживания различных классов.
3.4.1.Простейшая модель ресурса
Впростейшем случае в качестве модели некоторого ресурса (устройства) сети, обрабатывающего однородные пакеты, поступающие в сеть в случайные моменты времени, может использоваться одноканальная система массового обслуживания (СМО) с одним обслуживающим прибором (ресурсом) с однородным потоком заявок и накопителем неограниченной емкости.
Вкачестве таких ресурсов и устройств в беспроводных сетях выступают базовые и мобильные станции, маршрутизаторы и коммутаторы, радиоканалы передачи данных и т.д.
Пусть средний интервал между пакетами равен a, и средняя
ресурсоемкость, измеряемая количеством работы, которое затрачивается на обработку или передачу одного пакета, равна θ . Скорость обработки (передачи), измеряемую количеством работы, выполняемой за единицу времени, обозначим через V . В каждый момент времени ресурс может
обрабатывать или передавать только один пакет. Пакеты, заставшие ресурс занятым обработкой ранее поступившего пакета, располагаются в накопителе перед ресурсом, где ожидают его освобождения.
Положим, что пакеты, поступающие к ресурсу, образуют простейший поток с интенсивностью λ = 1/ a , а длительность обработки (передачи) одного пакета распределена по экспоненциальному закону
|
(ν b |
= 1) со средним значением b = θ . Тогда среднее время ожидания в |
|
V |
накопителе перед ресурсом и полная задержка пакета определяются как:
|
w = |
ρb |
; |
u = w + b = |
b |
. |
|
|
− ρ |
||||||
|
1 − ρ |
1 |
3.4.2. Оценка быстродействия ресурса
Рассмотренная модель может быть использована для решения задач проектирования, в частности, для оценки требуемой производительности ресурса (устройства), в частности, скорости обработки пакетов в устройстве или пропускной способности радиоканала связи. В простейшем
97

случае может быть получена нижняя оценка быстродействия устройства – быстродействие, при котором в системе отсутствуют перегрузки.
Нагрузка y и загрузка ρ устройства определяются соответственно
как:
|
y = λb = λθ ; |
ρ = min( y;1) . |
|
V |
|
|
Для того чтобы в устройстве не было перегрузок, необходимо |
|
|
выполнение условия: |
y = λθ < 1, из которого следует: V > λθ . |
|
V |
Последнее выражение можно рассматривать как ограничение, налагаемое на быстродействие ресурса (скорость работы устройства) и обеспечивающее отсутствие перегрузок в устройстве. Величина V0 = λθ представляет собой нижнее быстродействие устройства. Если быстродействие устройства будет меньше или равно V0 , то устройство будет перегружено, что приведёт к неограниченному возрастанию длины очереди пакетов перед ресурсом.
Для выбранного быстродействия V средняя задержка пакетов в устройстве:
|
u = |
b |
= |
Θ |
|
|
. |
(3.4) |
|||
|
1 − ρ |
V − λΘ |
Рассмотрим теперь задачу определения быстродействия при заданном ограничении на среднее время задержки пакетов в устройстве.
Пусть для описанной выше системы задано ограничение на среднее время задержки пакетов в устройстве в виде:
|
u < u* , |
(3.5) |
|||
|
где u – |
среднее время задержки пакетов в устройстве; u* – заданное |
|||
|
ограничение. |
||||
|
С учетом (3.4) неравенство (3.5) запишется в следующем виде: |
||||
|
θ |
< u* , |
|||
|
V − λθ |
||||
|
откуда получим выражение для оценки быстродействия устройства: |
V > λθ + θ . u*
3.4.3. Оценка ёмкости накопителя
Одной из задач проектирования систем с использованием простейших базовых моделей является оценка ёмкости накопителя (буферной памяти), обеспечивающей заданный уровень потерь поступающих пакетов из-за переполнения накопителя.
В общем случае для точного решения этой задачи необходимо знать
|
закон распределения числа |
пакетов |
в системе: pk |
= Pr(K = k ) – |
|
вероятность нахождения в |
системе |
ровно k пакетов. |
Тогда задача |
98
определения ёмкости накопителя формулируется следующим образом: определить ёмкость накопителя Е, при которой вероятность потери поступающих пакетов, то есть вероятность того, что количество пакетов К в системе окажется больше ёмкости Е накопителя, не превысит заданное
|
значение δ * : |
Pr( K |
> |
E ) ≤ δ * . |
||||||||
|
∞ |
E |
||||||||||
|
Очевидно, что Pr(K > |
E) = ∑ pk |
= 1− ∑ pk . |
|||||||||
|
k = E +1 |
k =0 |
||||||||||
|
Решая задачу на границе ограничения, получим уравнение для |
|||||||||||
|
расчёта минимального значения Е ёмкости накопителя: |
|||||||||||
|
∞ |
|||||||||||
|
∑ pk |
= δ * . |
(3.6) |
|||||||||
|
k = E +1 |
|||||||||||
|
Для простейшей модели обслуживания закон распределения числа |
|||||||||||
|
заявок в системе имеет вид: |
|||||||||||
|
pk = ρ k (1 − ρ) |
(k = 0,1, 2,…) , |
(3.7) |
|||||||||
|
где ρ = λ b < 1 — загрузка системы. |
|||||||||||
|
∞ |
|||||||||||
|
Подставляя |
(3.7) в |
(3.6), получим: (1 − ρ ) |
∑ ρ k = δ * . |
После |
|||||||
|
k = E +1 |
|||||||||||
|
некоторых преобразований окончательно получим уравнение ρ E +1 = δ * , |
|||||||||||
|
решение которого имеет вид: E = |
lgδ * |
−1. |
|||||||||
|
lg ρ |
|||||||||||
|
обычно задается в виде: δ * = 10−n , |
|||||||||||
|
Вероятностное ограничение δ * |
|||||||||||
|
где степень n принимает целочисленные значения: |
n = 2, 3,…. |
Тогда |
|||||||||
|
последнее выражение может быть представлено в виде: |
|||||||||||
|
n |
|||||||||||
|
E = − |
+1 . |
||||||||||
|
lg ρ |
Как видно из представленных зависимостей, для сохранения заданного уровня потерь заявок ёмкость накопителя существенно должна быть увеличена при увеличении загрузки, начиная со значения ρ = 0,6 . В частности, при увеличении загрузки от значения ρ = 0,8 до значения
ρ= 0,9 ёмкость накопителя должна быть увеличена примерно в 2 раза.
3.4.4.Модели систем с несколькими устройствами
Всистемах с несколькими идентичными устройствами поступающие пакеты могут обрабатываться любым свободным устройством. Если все устройства заняты, то пакеты ожидают в накопителе его освобождения. При этом могут использоваться два способа организации накопителей перед устройствами:
1) накопители формируются перед каждым устройством, при этом поступивший пакет случайным образом направляется в один из накопителей; такие системы называются системами с индивидуальными накопителями и моделируются в виде совокупности одноканальных СМО,
99

число которых равно числу устройств и, следовательно, числу накопителей;
2) перед всеми устройствами формируется один общий накопитель, в который заносятся пакеты, при этом пакеты из накопителя на обработку поступают в первое освободившееся устройство; такие системы называются системами с общим накопителем и моделируются в виде многоканальной СМО, в которой число обслуживающих приборов равно числу устройств в системе.
Расчёт характеристик системы с индивидуальными накопителями сводится к расчёту N независимых одноканальных СМО с однородным потоком пакетов, причём разные устройства могут иметь разные быстродействия.
В случае равновероятного распределения пакетов по всем N накопителям, интенсивность их поступления ко всем устройствам системы
одинакова и равна λ = λ . Если при этом все приборы идентичны, то
расчёт характеристик системы сводится к расчёту одной одноканальной СМО, поскольку характеристики всех устройств будут одинаковы. Если разные устройства имеют разные быстродействия, расчёт выполняется для всех N одноканальных СМО.
Расчёт характеристик системы с общим накопителем сводится к расчету многоканальных СМО, содержащих N идентичных обслуживающих приборов (устройств) и накопитель неограниченной ёмкости.
Рассмотрим задачу определения минимального количества устройств в системе.
Под минимальным количеством устройств в системе будем понимать такое количество, при котором в системе отсутствуют перегрузки.
|
Нагрузка y |
и загрузка ρ системы с несколькими устройствами |
||
|
определяются соответственно как: |
|||
|
y = λb = λθ ; |
ρ = min( |
y |
; 1) . |
|
V |
N |
Для того чтобы в системе с несколькими устройствами не было
перегрузок, необходимо выполнение условия: ρ = min( y ; 1) < 1, из
N
которого следует:
NV > λθ .
Полученное выражение можно рассматривать как ограничение, налагаемое на суммарное быстродействие системы, обеспечивающее существование установившегося режима в системе. Величина V0 = λθ представляет собой минимально возможную производительность (суммарное быстродействие) системы. Если суммарное быстродействие системы будет меньше или равно V0 , то в системе возникнут перегрузки,
100
Соседние файлы в папке TBS
- #
- #
- #
- #
- #
- Другие части статьи:
- 1
- 2
- вперед »
Итак, блог sqlCMD.ru продолжает цикл публикаций посвященный такой непростой теме, как параметризация запросов. В статье открывающей данный цикл, Параметризация запросов. Ваш лучший друг? мы выяснили что грамотно и к месту примененный данный механизм способен дать выигрыш в итоговой производительности решения столь значительный, что даже подтвержденный сухими цифрами «до» и «после» он все-равно продолжает выглядеть сказочно-невероятным. Были указали и причины такой «сказочности»: анализ запроса, построение нескольких альтернативных планов исполнения для него, выбор из этих возможных кандидатов «лучшего из лучших» — все это чрезвычайно ресурсоемкие задачи, и даже для современных серверов с их мультипроцессорными «фишками». А поэтому пропуск этих задач целиком дает такой прирост в скорости выполнения запроса, какой невозможно обеспечить никаким наращиванием железа (мы, разумеется, говорим о потенциальном увеличении числа/качества CPU сервера; вложения в, допустим, апгрейд дисковой подсистемы помочь именно в вопросах быстрейшей оптимизации запросов не могут никак просто по определению). Так вот чем покупать коробку новых/дополнительных CPU и загружать их работой, выгоднее (с любой точки зрения) не покупать ничего, а воспользоваться работой уже готовой, в смысле результатами такой предварительной работы. Именно так и поступает параметризация, значительно повышая наши (и наших пользователей) шансы взять «готовую работу» из кэша планов (plan cache), вместо осуществления полной и очень трудоемкой цепочки, где первым звеном является запрос на языке T-SQL, а звеном финальным — идеальный (или близкий к таковому) план исполнения, помещаемый, к слову сказать, опять же в тот же самый кэш планов.
Однако указанная статья открывающая цикл завершалась довольно интригующе. В ее заключительном абзаце было сказано, что параметризация это не только удивительно хорошо, но и в тоже самое время… плохо! ![]() Обещалось продолжение, в котором должна была проясниться такая двойственность одного и того же процесса, а так же должны были появиться пояснения, почему мы подчас захотим бороться не за параметризацию, а решительно против нее. Ну и описание методов такой «борьбы против» так же были анонсированы. Автор рад сообщить постоянным и новым своим читателям, что такое продолжение — перед вами. Оно, как представляется автору, имеет и самостоятельную ценность, однако крайне и настойчиво рекомендуется к изучению именно как продолжение упомянутой выше статьи. По крайней мере писалось продолжение с тем расчетом, что все идеи, концепции, принципы и примеры кода приведенные в статье стартовой известны читателю и поняты им в полном объеме. Приятного и познавательного чтения, не забудьте открыть в соседнем окне SQL Server Management Studio.
Обещалось продолжение, в котором должна была проясниться такая двойственность одного и того же процесса, а так же должны были появиться пояснения, почему мы подчас захотим бороться не за параметризацию, а решительно против нее. Ну и описание методов такой «борьбы против» так же были анонсированы. Автор рад сообщить постоянным и новым своим читателям, что такое продолжение — перед вами. Оно, как представляется автору, имеет и самостоятельную ценность, однако крайне и настойчиво рекомендуется к изучению именно как продолжение упомянутой выше статьи. По крайней мере писалось продолжение с тем расчетом, что все идеи, концепции, принципы и примеры кода приведенные в статье стартовой известны читателю и поняты им в полном объеме. Приятного и познавательного чтения, не забудьте открыть в соседнем окне SQL Server Management Studio. ![]()
Темная сторона параметризации.
Давайте сразу обратимся к коду и посмотрим на ситуацию, когда параметризация превращается, выражаясь языком не столь отдаленных времен отечественной истории, из вашего «верного друга и соратника» в «агента всех империалистических разведок». ![]()
|
1 |
USE master |
Что мы имеем «на входе»? Некая табличка T1 по учету компьютерной техники на складе/в офисе. Порядка 120тыс. записей сгенерированных таким образом, что фирма DELL становится нашим генеральным поставщиком (99% нашего оборудования получено от нее). С фирмой же IBM мы якобы сотрудничаем по остаточному принципу (лишь 1% записей). Для горячих поклонников оборудования последней фирмы готовых обидеться на подобный дисбаланс, автор предупреждает: все герои его повествования вымышлены, а совпадения с реально существующими фирмами/персонами случайны. ![]() Тем не менее стартовая диспозиция такова как она есть 99-к-1. Оба вендора поставляют нам и десктоп-машины, и ноутбуки, но доля последних значительно меньше первых. Так же таблица T1 имеет два индекса: кластерный по колонке первичного ключа и не кластерный по колонке как раз таки Vendor. Сама тестовая база данных переведена в режим принудительной авто-параметризации, однако мы для нашего теста выберем не ее, а параметризацию ручную, причем из трех вариантов последней остановимся на системной хранимой процедуре sp_executesql. Поскольку пользователи нашей системы обожают фильтровать свои запросы по колонке Vendor именно она становится целью нашей параметризации:
Тем не менее стартовая диспозиция такова как она есть 99-к-1. Оба вендора поставляют нам и десктоп-машины, и ноутбуки, но доля последних значительно меньше первых. Так же таблица T1 имеет два индекса: кластерный по колонке первичного ключа и не кластерный по колонке как раз таки Vendor. Сама тестовая база данных переведена в режим принудительной авто-параметризации, однако мы для нашего теста выберем не ее, а параметризацию ручную, причем из трех вариантов последней остановимся на системной хранимой процедуре sp_executesql. Поскольку пользователи нашей системы обожают фильтровать свои запросы по колонке Vendor именно она становится целью нашей параметризации:
|
1 |
USE [~DB~] |
Как обычно, для начала очищаем кэш планов — каждый наш опыт должен начинаться с «чистого листа». Далее заказываем отображение сведений о том как каждая из команд нагружает HDD, такая информация нам вскоре пригодится. Затем следует наш параметризированный запрос, причем реализовано все с помощью sp_executesql, как мы и наметили. Если опираться на информацию только из открывающей статьи цикла, то мы потрудились на славу — план будет создан (и связанные с этим процессом многочисленные ресурсы будут потрачены) лишь однажды, в момент первого обращения первого клиента предложившему серверу такой запрос. Все прочие обращения того же или последующих клиентов с тем же запросом будут пользоваться готовым планом полностью пропуская ту самую «ресурсоемкую цепочку». Причем что особенно приятно (по крайней мере это кажется нам приятным к текущей точке повествования) такой пропуск будет осуществлен вне зависимости от значения параметра для фильтрации колонки Vendor, главное что бы сам запрос оставался тем же самым.
Итак, пока мы видим сплошные плюсы от проделанной нами работы. Однако позволим пользователям поработать с нашим «идеальным» запросом. Пусть первый из них запросит оборудование поставленное нашим генеральным партнером, то есть фирмой DELL (последняя строчка последнего скрипта). Для анализа «хорошести» получившегося плана нам нужны 3 вещи:
- отчет по числу логических считываний. В условиях реального анализа вы, вполне возможно, захотите анализировать и физические чтения тоже. В нашем случае почти наверняка вся база будет в памяти вашей тест-машины после скрипта ее создающего и наполняющего данными. А поэтому для нас этот параметр ничего не даст, он (с вероятностью близкой к 100%) будет равен нулю. Но вот логические чтения — это другое дело, они действительно покажут нам степень (не)оптимальности того или иного запроса;
- сам план в графическом виде, причем мы предпочтем его актуальную, а не предполагаемую разновидность;
- так же мы захотим открыть окно свойств (клавиша F4) крайнего левого оператора плана (SELECT). А в этом окне нас будет интересовать свойство Parameter List, а более точно два его «под-свойства»:
- Parameter Compiled Value — значение параметра с которым план был создан, то есть скомпилирован;
- Parameter Runtime Value — значение параметра с которым план был исполнен;
Итак, для запроса выбирающего 99% всех строк (фирма DELL) число логических чтений составит 5833, а план/свойство Parameter List будут такими:

Быстрая «прикидка в уме» говорит нам что оптимизатор повел себя зело разумно, не захотев заморочиться с индексом по колонке Vendor. И то сказать: извлеки сначала значения первичных ключей для каждой строки удовлетворяющей фильтру, потом с этими ключами «сгоняй» в кластерный индекс и извлеки значения всех прочих столбцов кроме Vendor и ColID… И это зная, что вернуть нужно весь кластерный индекс за вычетом 1%! Ну так не проще просто отбросить из последнего лишние строки и вернуть оставшиеся? Так и сделано, мы видим полный скан по индексу PK_id (кластерный), что в данном случае, пожалуй, оптимально. Что же до параметра (точнее — до его значения) то пока все очевидно — с DELL план создался, с ним же и исполнился.
Теперь, на сервер заходит второй пользователь, и разбираемый нами запрос уже находится в кэше (и чистить его мы, разумеется, не хотим — иначе зачем нужна параметризация вообще?). Этому пользователю нужен фильтр прямо противоположный, по фирме IBM (1% всех записей), и он так и пишет:
|
1 |
set statistics io ON |
На этот раз мы имеем все те же 5833 логических чтений, а так же:

Тут нас уже могут начать терзать смутные подозрения… С учетом, что нам нужно-то всего 1% строк — не разумнее ли зайти именно со стороны индекса по колонке Vendor? Это, конечно, потребует дополнительного обращения к кластерному индексу, но зато «база» для финального резалт-сета будет извлечена практически мгновенно. А так мы пробегаем по всем строкам 99% которых нам просто не нужны… Впрочем, параметризация затевается что бы использовать тот же самый план, из кэша. Мы получили то к чему стремились, не так ли? Значения свойства Parameter List лишь подчеркивают этот факт: запрос был скомпилирован для/под параметр DELL, а исполнен для параметра IBM. Самое главное, мы миновали «ресурсоемкую цепочку», а число логических чтений даже если оно и является суб-оптимальным все еще находится в границах вменяемых значений для запроса подобного толка.
Теперь повторим эксперимент с нуля (то есть начнем вновь с чистого кэша), но только два пользователя посетят наш сервер в обратном порядке. Как ни удивительно, но порядок их посещения имеет колоссальное и даже катастрофическое (для пользователя номер 2) значение. Итак, в этот раз на сервер первым успевает «любитель IBM»:
|
1 |
USE [~DB~] |
В этом случае с планом/Parameter List-ом у нас дела такие:

Так мы и предполагали — для столь незначительного числа извлекаемых строк выгоднее «заход» со стороны IDX_Vendor плюс «добор» информации из кластерного индекса. Число логических чтений так же понижается до 3750 — это, конечно, не на порядок меньше, но и раза в полтора тоже неплохо…
Далее приходит опоздавший «поклонник DELL»:
|
1 |
set statistics io ON |
Вы уже догадываетесь что его ждет:

Однако мало кто может предположить всего масштаба постигшей нашего бедолагу катастрофы: вместо 5833 логических чтений его запрос теперь требует… 370124!! ![]() Это настолько «круто», что разница во времени фильтрации по параметру DELL в первом эксперименте и сейчас видна на достаточно мощной тестовой машине просто визуально! И это при том, что наша тест-таблица содержит 120тыс. строк (что в масштабах SQL Server еще даже не есть «много»), а запрос ими оперирующий является «мега-элементарным». Можете легко себе домыслить как это все безобразие будет смотреться на таблице из 50 млн. строк с запросом на десяток-другой джойнов.
Это настолько «круто», что разница во времени фильтрации по параметру DELL в первом эксперименте и сейчас видна на достаточно мощной тестовой машине просто визуально! И это при том, что наша тест-таблица содержит 120тыс. строк (что в масштабах SQL Server еще даже не есть «много»), а запрос ими оперирующий является «мега-элементарным». Можете легко себе домыслить как это все безобразие будет смотреться на таблице из 50 млн. строк с запросом на десяток-другой джойнов.
Теперь понимаете где столь дружелюбная (на первый взгляд) параметризация раскладывает «грабли» с очень даже жестким «черенком»? Правильно, в том самом месте, где один и тот же запрос (более точно — план такого запроса) идеально работающий с одним набором данных страшно «лажает» с другим. Кстати говоря, «вьювер» графических планов исполнения студии несколько усугубляет эти самые «грабли», и вместо того что бы помочь вам разобраться с ними успешно «затуманивает» картину. Для рассеивания этого «тумана» исполним две команды второго эксперимента в той же последовательности, но одним пакетом (batch):
|
1 |
USE [~DB~] |
Мы уже знаем, что вторая команда при таком раскладе будет столь чудовищно неэффективна, что говорить о каком-то равенстве по этому показателю с командой первой просто смешно. Это даже не учитывая того простого факта, что первая команда извлекает ~1тыс. строк, а вторая ~120тыс, что само по себе исключает любые рассуждения о равенстве, а тут еще сверх того план «заточенный» под IBM… Тем не менее студия бодро рапортует:

То есть вроде как цена/время исполнения двух показанных команд будут приблизительно равны, в то время как на самом деле если вам нужен пример двух команд не имеющих ничего общего по таким показателям, то вы их нашли. Это все проистекает из того, что цифры подчеркнутые на последней иллюстрации вычисляются очень просто. У каждого оператора плана каждой команды входящей в пакет есть показатель Estimated Subtree Cost — сколько «стоит» выполнение этого оператора плюс всех прочих операторов расположенных правее данного в графическом представлении плана. Если мы возьмем указанный показатель для оператора SELECT (самого левого на плане) то это и будет итоговая «стоимость» данной команды пакета. Если команд в пакете всего две (как в нашем случае), то показатель для оператора SELECT первой можно обозначить как ESC1, а для того же оператора второй — ESC2. Тогда первая подчеркнутая на иллюстрации цифра вычисляется так: ESC1*100%/(ESC1+ESC2). А вторая, соответственно, ESC2*100%/(ESC1+ESC2). В данном случае оптимизатор (и студия вслед за ним) «думают», что ESC1=ESC2.
Проверьте свое понимание материала: Пояснить, почему оптимизатор делает такое совершенно ошибочное предположение.
Смотреть ответ
Потому, что реальный расчет и оценка производятся только для первой команды (ESC1). При выполнении второй команды (ESC2) этап оценки данных/построения плана полностью пропускается (вы же помните нашу и оптимизатора «мета-задачу»?), а план просто берется из кэша «as is», со всеми своими «потрохами», в том числе и оценочными!
И, соответственно, все честно рассчитав по формуле «выкатывают» нам показанные выше цифры — 50% там, и столько же здесь. Ага, мы «верим»… Отсюда — вывод:
При задействованной для данного запроса параметризации относительный Query cost показываемый в заголовке графического плана может не иметь ничего общего с действительностью. Более-менее адекватную оценку относительных ожидаемых затрат на выполнение запроса можно получить из анализа информации возвращаемой командой SET STATISTICS IO ON.
Проверьте свое понимание материала: Параметризация, как известно из статьи предыдущей, бывает двух классов(автоматическая/ручная), а каждый класс еще дополнительно делится на под-классы в зависимости от конкретной реализации данного механизма (простая/принудительная и sp_executesql/хранимая процедура/на стороне клиента соответственно). «Большая проблема» параметризации описанная в данном разделе статьи имеет универсальную природу или от нее страдают лишь некоторые классы/под-классы? Если вы считаете, что верен второй вариант составьте два списка: механизмов параметризации не подверженных указанной проблеме и механизмов попадающих в зависимость от нее.
Смотреть ответ
«Большая проблема» имеет абсолютно универсальную природу и от нее страдает (и будет продолжать) любой механизм пытающийся воспользоваться планом созданным ранее. Корни проблемы гнездятся исключительно в распределении данных и от конкретной реализации механизма не зависят. Если такое распределение в колонке фильтрации [более-менее] равномерное — все отлично, параметризация ваш лучший друг. Как только распределение имеет «перекос» превышающий определенный порог, а особенно когда неравномерность распределения достигает экстремальных величин (как в нашей таблице T1) — параметризация начинает активно работать не на вас, а против. Интересно отметить, что генеральный подход применяемый SQL Server — по умолчанию все планы кэшируются, а если нам это не нужно надо произвести дополнительные «телодвижения» (о чем, кстати, речь впереди) —говорит нам лишь о том, что с точки зрения создателей движка значительно большее число реальных данных имеют нормальное распределение либо незначительный перекос. Если бы победила та точка зрения, что большинство данных имеет хороший такой перекос в своем распределении — мы бы имели прямо противоположную картину: по умолчанию ничего бы не кэшировалось, а включение плана в кэш было бы опцией, которую следовало бы указывать особо в каждом отдельном случае.
Итак, что мы с вами установили доподлинно к текущей точке материала? А то, что значение параметра передаваемого при первом выполнении параметризированного запроса имеет решающее влияние на дальнейшую судьбу этого запроса, а так же на состояние нервной системы пользователя/пользователей обращающихся с тем же запросом (но с иным значением параметра) во второй, третий и все последующие разы. И это все потому, что оптимизатор не просто строит план запроса, а «затачивает» его под это самое конкретное «первое значение». То есть оптимизатору не просто интересно это самое первое значение, а это именно то чем оптимизатор интересуется чуть ли не в первые микросекунды после получения команды от клиента. То есть это попросту одна из важнейших характеристик всего запроса! И вот такая «замороченность» оптимизатора «первым значением» получила отдельное название — «вынюхивание параметра», это если в дословном переводе (на языке оригинала это будет parameter sniffing). Название довольно точно и емко отразило существующее положение дел в буквально паре слов. Действительно, движок (а точнее один из главных его компонентов — оптимизатор) «набрасывается» на каждый новый запрос «аки гончая» и начинает «обнюхивать» его со всех сторон (и особенно со стороны параметров) пытаясь сообразить «как бы нам с ним, с запросом вашим, половчее тут…».
Теперь слова статьи открывающий данный цикл о том, что иногда вы захотите предпринимать «контр-параметризационные» меры с целью недопущения последней, не должны представляться вам нонсенсом. Если подобных мер не предпринимать, то мы попадаем в зависимость от порядка запросов, как в нашем примере с таблицей T1. Причем даже не важно какой из запросов будет выполнен первым. Или, иначе говоря, не важно какое значение параметра запроса будет предложено на «обнюхивание» серверу первым. Факт в том, что как минимум часть последующих идентичных запросов имеющих иное значение параметра будут исполнены неоптимальным образом, может отличаться лишь степень этой неоптимальности, начиная от «не айс, но сойдет» и заканчивая «это просто ужас».
Давайте резюмируем полученные знания. Мы поняли и осознали:
- почему мы можем захотеть бороться с параметризацией. Потому что план очень хорошо работающий для значения ‘ab’ параметра @p может быть никуда не годным при смене значения того же параметра на ‘cd’;
- когда мы можем захотеть бороться с параметризацией. Когда селективность одного значения в колонке фильтрации резко отличается (причем не важно в большую или меньшую сторону) от селективности иных значений в той же колонке. Формальное определение селективности можно найти в части 3-й статьи Density, Selectivity, Cardinality или о чем «думает» оптимизатор. А если сказать тоже самое без «большой науки», то мы можем ожидать проблем когда у нас в целевой таблице строк со значением ‘ab’ в колонке Col1 две штуки, а со значением ‘cd’ в той же колонке много и много больше. Обратите внимание, что если перекос в распределении данных присутствует, но «перекошенная» колонка не участвует в фильтрации запросов пользователей — все отлично, нет причин для беспокойства. Однако нам несомненно будут встречаться колонки типа Vendor из нашей тестовой таблицы и прилагающиеся к ней соответствующие запросы.
Осталось «немного» — узнать как именно осуществлять эту самую «борьбу против». А это, на самом деле, вопрос преизрядный. Сервер очень хорошо усвоил аксиому «параметризация — наше все» и делает все возможное что бы она таки имела место. Однако «поправить» наш сервер с его излишним рвением все же возможно, и в заключительной части текущей статьи мы только этим и будем заниматься, причем снова несколькими способами.
- Другие части статьи:
- 1
- 2
- вперед »
1. Прежде чем говорить о параметризации, давайте поговорим о простом скрипте оптимизации.
а. Запрос на удаление нецелевых веб-сайтов
б. Некоторые ненужные ресурсы могут быть удалены: js, png, jpeg, css и т. д.
в. Удалите повторяющиеся запросы
г. Время на размышления может быть временно заблокировано
2. Параметризация скрипта
А. Предполагается, что подготовьте тестовые данные, просто используйте для тестирования веб-сайт бронирования авиабилетов, который поставляется с lr. Я зарегистрировал несколько учетных записей заранее: hyp01,123456; hyp02,123456; hyp03,123456, пароли этих учетных записей.
b、Два способа параметризации:
(1) Здесь мы параметризуем учетную запись и пароль системы входа. После выбора поля, которое необходимо параметризовать, щелкните правой кнопкой мыши кнопку «Заменить параметром», чтобы запустить интерфейс параметризации.


(2) Второй метод заключается в следующем:

c. Отредактируйте данные, то есть добавьте только что зарегистрированного пользователя, и пароль будет таким же, как в следующих шагах.


г. В следующей таблице показаны несколько конфигураций параметризации скрипта:
| Метод значения | Стратегия обновления | результат |
| последовательный | each iteration | Обновляйте значение один раз за итерацию, чтобы |
| each occurrence | Значение необходимо обновлять каждый раз, когда оно встречается. | |
| once | Всегда используйте только первые полученные данные | |
| случайный | each iteration | То же, что и выше |
| each occurrence | То же, что и выше | |
| once | Какое значение выбирается случайным образом, но каждое значение может использоваться только один раз | |
| уникальный | each iteration | Обновляйте значение один раз за итерацию, но каждое значение можно использовать только один раз |
| each occurrence | Значение обновляется один раз за запрос, но каждое значение может использоваться только один раз. | |
| once | Всегда используйте только одно значение, последнее имеет преимущественную силу. |
Конфигурация значения устанавливается в следующем месте, какой метод используется для установки значения, может быть установлен в соответствии с реальной ситуацией.

д. После установки метода значения нам также нужно установить количество итераций. Здесь у нас есть четыре пользовательских данных, поэтому мы устанавливаем 4 раза


е. После добавления данных, как мы можем проверить успешность параметризации? Мы можем использовать функцию lr_output_message для печати и попробовать
Как показано ниже,

Результаты операции следующие:


Проблемы с Параметрическим Представлением
Ck
непрерывность
кажется удобным инструментом для
проверки на гладкость соединения кривых.
Но и тут есть проблема. Пусть даны
следующие отрезки кривых:
f(u)
= A
+ u(B
— A)
g(v)
= B
+ v(C
— B)
,
где
A,
B
и C
— три коллинеарные (лежащие на одной
прямой) точки, как показано на рисунке.

Когда
u
(соотв.,
v)
изменяется от 0 до 1, f(u)
(соотв.,
g(v))
пробегает от A
до B
(соотв.,
от B
до C).
Отрезки f(u)
и g(v),
очевидно, C0
непрерывны
в точке соединения B.
А C1
непрерывны
ли они?
f‘(u)
= B
— A
g‘(v)
= C
— B
Таким
образом, f‘(u)
= B
— A
в общем случае не равно g‘(v)
= C
— B
и, следовательно, два этих отрезка не
C1
непрерывны
в точке соединения B!
Странно?
Это все из-за параметризации. Если
заменить направляющие векторы B
— A
и C
— B
на единичные векторы и изменить интервалы
параметров u
и v,
проблема пропадет. Таким образом,
уравнения нужно изменить на следующие:
F(u)
= A
+ u(B
— A)/
| B
— A
|
G(v)
= B
+ v(C
— B)/
| C
— B
| ,
где
u
в пределах от 0 до | B
— A
| , а v
в пределах от 0 до | C
— B
|. Теперь, так как мы имеем F‘(u)
= G‘(v)
= единичному вектору в направлении от
A
до C,
отрезки C1
непрерывны.
То есть, параметризация отрезков кривых
— хорошая вещь 8).
Вот
еще один пример, здесь PI
равно 3.1415926, u
и v
в границах [0,1].
f(u)
= ( -cos(u2
PI/2), sin(u2
PI/2), 0 )
g(v)
= ( sin(v2
PI/2), cos(v2
PI/2), 0 )

Когда
u
изменяется от 0 до 1, f(u)
проходит левую часть полукруга. Аналогично
с правой частью. Они соединяются в точке,
показаной красным, (0,1,0) = f(1)
= g(0).
Имеем следующее:
f‘(u)
= ( PI
u
sin(u2
PI/2),
PI
u
cos(u2
PI/2),
0 )
f»(u)
= ( PI2
u2
cos(u2
PI/2),
-PI2
u2
sin(u2
PI/2),
0 )
f‘(u)
× f»(u)
= ( 0, 0, -PI3
u3
)
| f‘(u)
| = PI
u
| f‘(u)
× f»(u)
| = PI3
u3
k(u)
= 1
g‘(v)
= ( PI
v
cos(v2
PI/2),
-PI
v
sin(v2
PI/2),
0 )
g»(v)
= ( -PI2
v2
cos(v2
PI/2),
-PI2
v2
cos(v2
PI/2),
0 )
g‘(v)
× g»(v)
= ( 0, 0, -PI3
u3
)
| g‘(v)
| = PI
v
| g‘(v)
× g»(v)
| = PI3
v3
k(v)
= 1
Заметьте,
что и g‘(0),
и g»(0)
— вектора нулевой длины, и поэтому
неопределены. В итоге мы вообще не можем
ничего сказать о непрерывности; но по
рисунку «кажется», что они непрерывны,
хотя бы потому, что у них общая касательная
в точке соединения.
Как
вы уже, наверное, догадались, щас будем
опять все это дело перепараметризовывать.
( Жуткое слово, согласен. —
прим. перев.)
Заменим u2
на p
в f(u)
и v2
на q
в g(v).
Получим такие уравнения:
f(p)
= ( -cos(p
PI/2),
sin(p
PI/2),
0 )
g(q)
= ( sin(q
PI/2),
cos(q
PI/2),
0)
Их
производные:
f‘(p)
= ( (PI/2)
sin(p
PI/2),
(PI/2)
cos(p
PI/2),
0 )
f»(p)
= ( (PI/2)2
cos(p
PI/2),
-(PI/2)2
sin(p
PI/2),
0 )
g‘(q)
= ( (PI/2)
cos(q
PI/2),
-(PI/2)
sin(q
PI/2),
0 )
g»(q)
= ( -(PI/2)2
sin(q
PI/2),
-(PI/2)2
cos(q
PI/2),
0 )
f‘(p)
× f»(p)
= g‘(q)
× g»(q)
= ( 0, 0, -(PI/2)3
)
| f‘(p)
× f»(p)
| = | g‘(q)
× g»(q)
| = (PI/2)3
| f‘(p)
| = | g‘(q)
| = PI/2
k(p)
= k(q)
= 1
Следовательно,
после замены переменных и f‘(1)
и g‘(0)
равны ( PI/2,
0, 0 ) и поэтому они являются C1
непрерывными.
Более того, и f»(1)
и g»(0)
равны ( 0, -(PI/2)2,
0 ), и поэтому они C2
непрерывны!
Они также непрерывны
по кривизне,
так как их кривизна везде равна 1 (это
окружности). Вот она какая, эта
перепараметризация. 
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Одно из самых важных решений, которое мы принимаем, когда сталкиваемся с любой проблемой машинного обучения, — какую модель использовать. После выбора типа модели (линейная/нелинейная, CNN/RNN/Трансформаторы) необходимо определить мощность модели, а проще говоря, количество параметров, которые можно использовать. Наряду с очевидными техническими последствиями количество параметров также влияет на выразительную силу модели, то есть на ее способность изучать сложные функции. Мы ожидаем, что тренировочный набор будет легче «обучить» на более крупных моделях (меньшая ошибка обучения). Однако наша главная цель всегда состоит в том, чтобы иметь модель, которая хорошо обобщает и поддерживает низкую ошибку теста (т. емкость надо брать. На рисунке ниже показан компромисс емкости модели с точки зрения ошибок обучения и обобщения. Это одна из наиболее распространенных цифр в книгах по машинному обучению, также известная как компромисс между смещением и дисперсией. Чтобы получить низкую ошибку обучения и низкую ошибку обобщения, нам нужно быть в выигрышном положении с точки зрения размера модели.

Мы?
Недавняя бумага продемонстрировала, что это не обязательно так, когда мы используем модели глубокого обучения. На рисунке ниже показано, что по мере увеличения модели ошибка теста следует ожидаемому шаблону до определенной точки (ширина 10 на рисунке), но затем снова уменьшается! Это явление получило название Двойной спуск.

Так почему бы нам не использовать все более и более крупные модели?
Хотя это текущая тенденция в некоторых областях, таких как НЛП (где последняя модель мозга Google составляет 1,6 триллиона параметров!), мы должны осознавать последствия. этого дрейфа.
С большим размером модели возникает большая наихудшая групповая ошибка
Когда мы используем все более и более крупные модели, мы ожидаем, что средняя ошибка теста будет снижаться. Несмотря на уменьшение средней ошибки теста, работы показали, что ошибка модели на некоторых группах меньшинств значительно возрастает. Это означает, что даже если модель работает в целом лучше (или в среднем), ее производительность значительно ухудшается для некоторых групп меньшинств данных. Это может быть опасно, особенно когда мы не можем допустить низкой производительности системы на меньшинствах, как в случае жизненно важных систем. Например, автономный автомобиль не может наехать на Хэллоуин на старика с рюкзаком или человека, одетого как зомби, только потому, что это редкое событие (группа меньшинства в данных).

График выше показывает схематическую иллюстрацию наблюдаемых результатов, которые будут обсуждаться далее в этом посте. Чтобы добиться низкой наихудшей ошибки группового теста, нам нужно использовать емкость модели, которая не является ни слишком большой, ни слишком маленькой. Использование модели со слишком большим количеством параметров приведет к высокой ошибке наихудшего группового теста.
В этом блоге мы представим наихудшую групповую ошибку, используя чрезмерно параметризованные модели глубокого обучения на реалистичных наборах данных. Используя синтетические данные и более простую модель, мы продолжим изучение этого явления и его причин. В центре внимания этого блога находятся недавно опубликованные статьи:Исследование того, почему чрезмерная параметризация усугубляет ложные корреляции» (что будет основной темой этого блога) и Понимание неудачи режимы внераспределительного обобщения».
Темная сторона Луны — ложные черты
Чтобы понять, почему чрезмерно параметризованные модели демонстрируют высокую наихудшую групповую ошибку, мы определим два типа функций: основные функции и ложные функции.
Представьте, что вы пытаетесь классифицировать верблюдов и коров. Вы получили набор данных и готовы обучить классификатор для этой задачи. Естественно, большинство наших коров в наборе данных будут представлены на фоне травы, а верблюды будут представлены на фоне песка.

Мы будем различать два типа признаков: признаки самой коровы/верблюда (например, форма или текстура животного), которые полностью информируют о правильном ярлыке, и признаки фона, которые в лучшем случае коррелируют, но не в сочетании с правильной этикеткой. Мы будем называть первый тип признаков «основными признаками», а второй тип — «ложными признаками». Классификатор, использующий ложные признаки, более подвержен ошибкам на изображениях верблюдов на травянистых полях или коров на песчаном фоне. Итак, мы бы предпочли, чтобы наша классификация игнорировала такие ложные функции.

Подводя итог, мы можем неформально определить:
Фальшивые особенности —функции, которые могут быть ложно связаны с меткой только во время обучения (например, фон), но не связаны с ней.
Основные функции — функции, которые полностью зависят от ярлыка, который мы пытаемся предсказать.
Эти два варианта фона (трава/песок) и два варианта животных (корова/верблюд) дают четыре возможные группы:
- Верблюд с песочным фоном — основная группа.
- Коровы на фоне травы — большинство.
- Верблюд на фоне травы — группа меньшинства.
- Коровы с песочным фоном — меньшинство.
Поскольку две первые группы более распространены в нашем наборе данных (и в дикой природе), мы будем рассматривать их как группы большинства. Последние две группы, которые встречаются реже, составляют меньшинство набора данных. Используя эти группы, мы определяем:
Наихудшая групповая ошибка —максимальное значение ошибки (% примеров с неправильными метками) во всех группах.
Более формально мы можем определить:

Где G — все возможные группы, а L₀₋₁ — стандартная потеря нуля или единицы. На практике мы рассчитаем ошибку модели для каждой группы и сообщим о наихудшей наблюдаемой ошибке.
Важно понимать, что модель, в которой используются только ложные признаки, по-прежнему будет иметь низкую среднюю ошибку, поскольку она по-прежнему будет правильной для обеих основных групп (а это большая часть набора данных). Однако, поскольку модель неправильно классифицирует выборки из двух групп меньшинств, ее наихудшая групповая ошибка будет высокой.
Мы хотели бы, чтобы модель использовала только основные функции и полностью игнорировала ложные функции. В результате должна быть достигнута как низкая средняя ошибка теста, так и низкая наихудшая групповая ошибка.
Более крупные модели больше используют ложные признаки
Мы покажем эмпирические результаты, демонстрирующие, что более крупные модели больше полагаются на ложные признаки, что приводит к высокой ошибке наихудшего группового теста. Последует анализ SVM, чтобы объяснить причины этого явления. Результаты и анализ в основном взяты из статьи Исследование того, почему чрезмерная параметризация усугубляет ложные корреляции.
Чтобы продемонстрировать, что более крупные модели больше полагаются на ложные признаки и, следовательно, с большей вероятностью неправильно классифицируют меньшинства, в этой статье используются два набора данных.
Первый набор данных содержит изображения водоплавающих и наземных птиц. Большинство наземных птиц в наборе данных были показаны на фоне земли, а водоплавающие — на фоне воды (например, реки/моря). Водоплавающие птицы с наземным фоном и наземные птицы с водным фоном составляют меньшинство в этом наборе данных. Основные черты — это черты самой птицы, а ложные — черты фона.
Второй набор данных взят из набора данных CelebA. Авторы включили в этот набор данных мужчин и женщин с черными и светлыми волосами. Они выбрали изображения таким образом, чтобы большинство светловолосых людей были женщинами, а большинство черноволосых — мужчинами. Основными признаками здесь являются признаки цвета волос, а ложные признаки – признаки пола. Хотя это может немного сбивать с толку, исходная задача состоит в том, чтобы определить цвет волос человека, а не его пол.

Авторы обучают модель ResNet10 на наборе данных CelebA с различными размерами модели, увеличивая ширину сети с 1 до 96. Для классификации водоплавающих и наземных птиц они использовали замороженный предварительно обученный ResNet18 для извлечения признаков. Затем авторы использовали случайную проекцию этих вложений ResNet на m-мерный вектор, варьируя m от 1 до 10 000. Авторы обучили логистическую регрессию по этим m векторам измерений. Важно отметить, что количество параметров в модели определяется шириной ResNet в наборе данных Celeb и параметром m в набор данных о птицах.
Эмпирические результаты

Глядя на приведенные выше графики, мы видим, что в обоих экспериментах средняя ошибка поезда и теста уменьшается по мере увеличения емкости модели (черная и серая линии). С другой стороны, наихудшая ошибка теста группы увеличивается по мере увеличения емкости модели, демонстрируя представленное явление. Но как мы узнаем, что это из-за использования ложных признаков?
Синтетический эксперимент
Чтобы ответить на этот вопрос и дополнительно проанализировать это тревожное явление, авторы создали синтетический набор данных.
Рассмотрим метку y∈{-1,1} и ложный атрибут a∈{-1,1}.
Мы создаем четыре группы:
•Две основные группы с a=y, каждая размером nₘₐⱼ/2.
•Две группы меньшинств, где a=-y, каждая размером nₘᵢₙ/2.
где общий размер набора данных равен n=nₘₐⱼ+nₘᵢₙ, а nₘₐⱼ ≥ nₘᵢₙ.
Важным определением является Pₘₐⱼ= nₘₐⱼ/n, которое представляет собой процент большинства групп в данных.
Мы определяем три разных распределения:

Первые два распределения являются простыми гауссовыми (одномерными), а последнее — многомерным гауссовым размерностью N. Каждая выборка состоит из трех типов объектов x=[ x𝒸ₒᵣₑ, xₛₚᵤ, xₙₒᵢₛₑ], взятые из приведенных выше дистрибутивов. Обратите внимание, что каждая из четырех возможных групп имеет свое собственное распределение по функциям, в зависимости от ее y и значений.
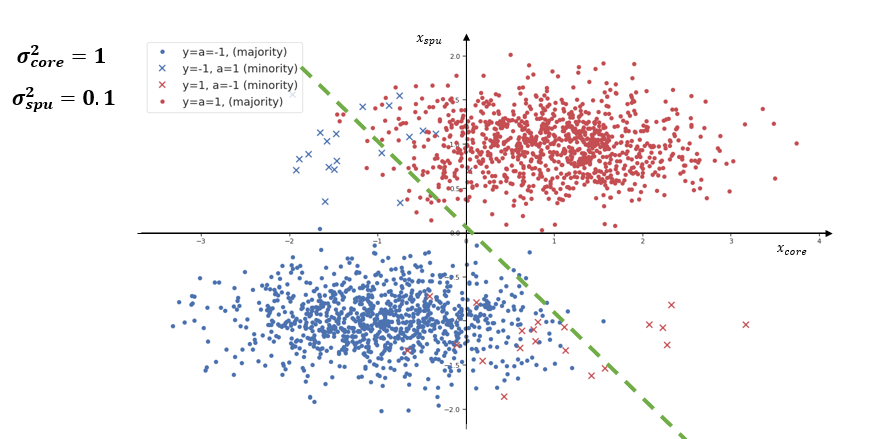
Прежде чем вы запутаетесь во всех этих определениях, давайте взглянем на эти сгенерированные сэмплы без признаков шума. Это означает, что каждая точка на графике ниже является двумерной x = [x𝒸ₒᵣₑ, xₛₚᵤ].

Мы можем видеть выборки, которые были сгенерированы из четырех различных распределений (которые попадают в каждый из квадрантов), которые зависят от их y и значений. Ось X — это основной признак, а ось Y — ложный признак. Все красные образцы — это образцы с меткой y=1, а синие — с меткой y=-1. Точки — это выборки, где a = y (группы большинства), а крестики — это выборки, где a ≠ y (группы меньшинства). Мы видим, что мы используем одну и ту же дисперсию 0,1 в распределениях основных и ложных признаков. Это приведет к следующему определению соотношения ложной и базовой информации:

Чем он выше, тем больше сигнала о ложном признаке в xₛₚᵤ относительно сигнала об истинной метке в x𝒸ₒᵣₑ. В приведенном выше примере Rs:c = 0,1/0,1 = 1.
Важно отметить, что классификатор, который мы хотим использовать, — это классификатор x=0 (зеленая линия, ось Y), поскольку этот классификатор вообще не использует ложные признаки. Здесь этот желательный классификатор достигнет высокой производительности благодаря относительно низкому соотношению паразитной информации к основной информации. Что произойдет, если в основном признаке больше шума, чем в ложном признаке (больше Rs:c)?

Теперь дисперсия основного признака равна 1, а дисперсия ложного признака по-прежнему равна 0,1. Как видно, желаемый классификатор (зеленая линия) не будет работать хорошо, и модель, вероятно, будет охватывать классификатор, который использует основные функции и ложные функции (оранжевая линия). У нас уже есть некоторая интуиция, почему модель может «захотеть» использовать ложные признаки в этой ситуации.
Используя этот синтетический набор данных (где каждая выборка равна xⁱ=[xⁱ𝒸ₒᵣₑ, xⁱₛₚᵤ, xⁱₙₒᵢₛₑ]), авторы обучили логистическую регрессию на представлении случайных признаков с размерностью m (аналогично преобразованию, сделанному в эксперименте с птицами):

Обратите внимание, что m управляет количеством параметров модели.
Авторы обучили модель с использованием ERM с подходом перевзвешивания: выборки групп меньшинств взвешиваются, а выборки групп большинства занижаются.
Неудивительно, что результаты были аналогичны тем, что мы наблюдали в экспериментах с водоплавающими птицами и CelebA:

Перепараметризованные модели плохо работают с меньшинствами, а их наихудшая ошибка группового теста высока (сильная синяя линия).
Затем авторы продемонстрировали, что чрезмерная параметризация сама по себе не обязательно приводит к высокой ошибке худшей группы (зеленая линия, левый рисунок), а скорее наличие ложных признаков, ухудшающих производительность модели (синяя линия, левый рисунок). фигура):

Следуя яркой зеленой линии, мы видим, что даже перепараметризованная модель обеспечивает низкую наихудшую ошибку группового теста. Таким образом, оказывается, что высокая ошибка наихудшего группового теста вызвана использованием ложных признаков.
Так почему же это происходит?
Мы проанализируем эту модель логистической регрессии, чтобы понять, почему в модели используются эти ложные функции, которые вызывают наблюдаемую высокую ошибку наихудшего группового теста. Авторы использовали регуляризованную логистическую регрессию, показанную Rosset et al. сходиться к решению SVM в перепараметризованном режиме. Таким образом, в дальнейшем он будет анализироваться как классификатор SVM.
Чтобы понять причины этого явления, нам нужно показать две вещи:
- Перепараметризованная модель может классифицировать выборки с помощью x𝒸ₒᵣₑ или xₛₚᵤ и запоминать выборки, противоречащие этой политике.
- Эти модели имеют индуктивный уклон, чтобы запомнить как можно меньше образцов.
Поскольку для этого блога это немного математически сложно, доказательство этих двух утверждений SVM оставлено для дальнейшего чтения статьи. Как правило, сверхпараметризованная модель может запоминать выборки из-за особенностей шума x. SVM имеет индуктивный уклон к минимальной норме весов SVM. В работе видно, как индикативное смещение к минимальной норме приводит к индуктивному смещению против запоминания образцов. Обратите внимание, что этот математический анализ касается только SVM/регуляризованной логистической регрессии, а не глубоких нейронных сетей. Таким образом, несмотря на то, что это явление также происходит с моделями глубокого обучения, которые обычно чрезмерно параметризованы,в статье не дается полного объяснения этого явления в этом контексте.
Поскольку приведенные выше утверждения считаются действительными, давайте рассмотрим две крайние возможные альтернативы: использование только основной функции или использование только ложной функции. Используя только основную функцию, модель сойдется к зеленой линии (ось Y) и должна будет запомнить 256 выборок.

С другой стороны, используя только ложный признак, модель сойдется к новой зеленой линии (ось x) и должна будет запомнить только 41 выборку (группы меньшинств).

Меньше запоминать!
Что произойдет, если мы разрешим использовать обе функции?
Тем более запоминать! Следовательно, мы ожидаем, что в результате процесса оптимизации будет создана модель, в которой используются как ложные, так и основные функции.
Понимание причин, по которым модель использует ложные признаки, может помочь нам предсказать, когда наихудшая ошибка группового теста будет высокой, а когда — низкой.
Количество выборок, которые модель должна запомнить, зависит от двух факторов: отношения ложной основной информации (Rs:c) и относительного количества группы большинства (Pₘₐⱼ = nₘₐⱼ/n).
Мы уже видели, что когда дисперсия основных признаков становится больше, чем дисперсия ложных признаков (что означает увеличение Rs:c), надежному классификатору «только основные признаки» необходимо запоминать больше выборок, чем классификатору «основных и ложных признаков». .

В результате с увеличением Rs:c стоимость запоминания надежного классификатора также увеличивается, что вынуждает процесс оптимизации сходиться к классификатору, который использует ложные признаки.
Pₘₐⱼ также влияет на количество выборок, которые должны запоминаться надежными и ложными классификаторами. По мере того, как Pₘₐⱼ=nₘₐⱼ/n уменьшается, что означает размер групп меньшинств увеличивается, классификаторы, использующие ложный признак (который не указывает на правильную маркировку в группах меньшинств) пришлось бы запоминать все больше и больше образцов. Мы продемонстрируем это, используя Pₘₐⱼ=0,5 и два экстремальных классификатора, один из которых использует только основной признак («надежный классификатор»), а другой использует только ложный признак («ложный классификатор»):

Когда Pₘₐⱼ=0,5, надежный классификатор должен запоминать меньше выборок, чем ложный классификатор. При более низком Pₘₐⱼ процесс оптимизации «подталкивается» к сходимости обратно к надежному классификатору.
Следовательно, можно было бы ожидать, что чрезмерно параметризованные модели будут плохо работать с меньшинствами, когда Rs:c и Pₘₐⱼ достаточно велики. Действительно, авторы провели этот эксперимент и получили ожидаемые результаты:

Мы видим, что чрезмерно параметризованные модели плохо работают с меньшинствами только тогда, когда Pₘₐⱼ ≥ 0,7 и Rs:c≥1.
Подвыборка против. Переоценка
Эти результаты подчеркивают важную роль основной фракции Pₘₐⱼ. Когда Pₘₐⱼ велико, индуктивное смещение благоприятствует использованию ложных признаков, поскольку это влечет за собой запоминание лишь относительно небольшого числа выборок меньшинства. С другой стороны, альтернатива использованию основных функций требует запоминания большого количества основных моментов. Это говорит о том, что мы можем снизить затраты на запоминание при использовании основных функций, напрямую удалив некоторые точки большинства.
Использование подвыборки дает следующие результаты:

Во всех трех наборах данных подвыборка обеспечивает низкое среднее значение и наибольшую ошибку группового теста. Модели с чрезмерным параметрированием, обученные на данных подвыборки, сравнимы или даже лучше, чем лучшие модели, обученные на полном наборе данных!
Как подвыборка, так и повторное взвешивание искусственно уравновешивают группы в обучающих данных. Мы видели, что увеличение чрезмерной параметризации с повторным взвешиванием увеличивает наихудшую групповую ошибку, а субдискретизация уменьшает ее. Повторное взвешивание не изменяет изученную модель, которая является классификатором максимальной маржи. Причина в том, что SVM не зависит от веса выборкии максимизирует только маржу. Поскольку маржа одинакова, если она измерена на образце с малым весом или на образце с большим весом, это не влияет на охват этой модели. Подвыборка снижает Pₘₐⱼ, что, в свою очередь, снижает затраты на запоминание моделей, которые используют в основном (или только) основные функции, что приводит к более надежному классификатору. Я думаю, что это классное наблюдение, хотя подвыборка обычно кажется выбрасыванием данных, на самом деле это оказывается разумным ходом.
Нет шума — нет проблем, верно?
На данный момент мы используем зашумленные основные функции, которые вынуждают модель использовать ложные функции. Возникает вопрос, сойдемся ли мы к модели, использующей ложный признак, если основные признаки не содержат шума? Из того, что мы видели до сих пор, мы ожидаем, что ответ будет отрицательным, модель должна использовать только основные функции. Так что, к сожалению, в модели по-прежнему будут использоваться ложные функции. Нагараджан и др. показали, что даже если мы используем основные функции без шума, использование градиентного спуска создаст модель логистической регрессии, которая использует ложные функции. Этот результат еще более удивителен, поскольку мы знаем, что с помощью SGD мы в конечном итоге придем к решению SVM, которое в этой настройке вообще не использует ложные функции.

На приведенном выше схематическом рисунке две метки y представлены фигурами: кругами и звездами. Ось X — это значение основного признака, а ось Y — значение ложного признака. Большинство групп представлено непрозрачными формами, а меньшинство — полупрозрачными формами.
Когда мы используем функции без шума, такие как точки и звезды выше, классификатор SVM представляет собой просто ось Y. Обратите внимание, что это решение SVM вообще не использует ложные функции. В этой статье показано, что, хотя решение SVM является надежным классификатором, использование SGD для конечного числа шагов приведет к классификатору, который использует ложные функции. Причина связана с Pₘₐⱼ и начальными шагами SGD. Поскольку этот блог стал слишком длинным, я оставлю все подробности и эксперименты в своем следующем блоге.
Краткое содержание
Итак, в этом блоге мы увидели одну из проблем использования чрезмерно параметризованных моделей, которая является наихудшей ошибкой группового теста. Следуя статье Сагавы и др., мы увидели, что это явление происходит как в глубоких нейронных сетях, так и в классических моделях машинного обучения (SVM). В документе проводится дальнейший анализ этого явления и его причин в настройках SVM, которые мы также интуитивно объясняем здесь. Мы увидели, что на серьезность наихудшей ошибки группового теста влияют два фактора: Pₘₐⱼ и Rs:c. Мы упоминаем последующую статью, в которой утверждается, что даже если Rs:c низкий (меньше шума в основные функции), модель логистической регрессии будет сходиться к модели, которая использует ложные функции. Это еще более удивительно, учитывая, что мы знаем, что если мы будем обучать эту модель в течение бесконечного периода времени, она в конечном итоге сойдется к решению SVM, которое не использует ложные функции.
Анализ обеих статей касается оптимизации SVM, а не более интересного случая использования глубоких нейронных сетей. Кроме того, предполагается, что мы знаем разные группы в наборе данных. Без этого предположения мы не можем даже измерить наихудшую групповую ошибку модели. Это предположение не является тривиальным в сценариях реальной жизни. Однако, на мой взгляд, в этих двух статьях обсуждалось одно из самых интересных ограничений использования перепараметризованной модели — наихудшая групповая ошибка. Они проанализировали это в настройках SVM и показали, что это также происходит с использованием глубоких нейронных сетей. Учитывая недавний успех чрезмерно параметризованных нейронных сетей, крайне важно глубже изучить причины этого явления с использованием глубоких нейронных сетей.
Обновлено: 2 авг. 2021 г.

Думаю, я не очень ошибаюсь, если скажу, что 95% программ для моделирования и сглаживания поверхности корпуса используют математику NURBS. Если 20 лет назад результатом был просто теоретический чертеж, представленный в виде линий и использовавшийся в основном для гидростатических расчетов, то теперь полученная поверхность передается во множество различных программ расчета и моделирования. Важно помнить, что поверхность передается с математической точностью, не меняя формы.
Таким образом, созданная вами модель будет использоваться во многих различных программах расчета и системах геометрического моделирования. Результат всех этих программ будет напрямую зависеть от качества поступающей модели поверхности. Модель поверхности для большинства этих программ используется как есть, без дополнительных проверок. Поэтому все проблемы и подводные камни, возникающие при моделировании поверхности, невозможно обнаружить сразу. Все это накладывает дополнительную ответственность на проектировщика, занимающегося моделированием поверхности корпуса.
Уже много лет я занимаюсь окончательным сглаживанием поверхностей корпуса судна в Shape Maker. В качестве исходной информации для сглаживания часто необходимо использовать предварительные модели поверхности, сделанные в других системах, иногда даже совсем не адаптированные для моделирования поверхности корпуса. И каждый раз я вижу одни и те же повторяющиеся ошибки, сделанные во время моделирования. Надеюсь, что эта статья хотя бы частично позволит избежать этих ошибок в будущем или позволит пользователям более осознанно выбирать инструмент для сглаживания корпуса.
Разбиение поверхности на участки.
Прежде чем приступить к моделированию поверхности, спланируйте, как ваша поверхность будет разделена на отдельные участки. Рациональное разделение на участки позволяет добиться лучшего качества сглаженной поверхности и минимальных трудозатрат. При непродуманном разбиении поверхности количество участков поверхности и соответственно сложность работы растет как снежный ком. Иногда на моделях можно увидеть панику и отчаяние дизайнера, который закрывает одну дыру на поверхности другой, и тем самым, создает себе еще больше проблем, а срок выполнения работ неумолимо приближается.

Пример неудачного разбиения на участки поверхности.Добиться плавного сопряжения участков поверхности очень сложно. Носовая и кормовая границы поверхности расположены близко друг к другу. Это не позволяет добиться необходимой плавности.

Проблема стыковки двух участков поверхности по общей границе. Очень важно правильно задать форму общей граничной кривой.

Пример неудачного разбиения кормовой оконечности на участки поверхности. Ватерлинии сжаты по продольной оси. Насколько я понимаю, изначально идея заключалась в том, чтобы сделать гладкую кормовую поверхность.

Пример неудачной общей точки для трех участков поверхности. Видны поперечные сломы на сечениях. Чтобы избежать локальной негладкости поверхностей, необходимо, чтобы все граничные линии в этой точке принадлежали одной плоскости.

Проблемы сглаживания поверхностей, состоящих из большого количества участков. Помимо сглаживания фактических участков поверхности, необходимо выполнить плавное сопряжение с соседними участками. Если граничные линии не определены точно, это может создать проблему для всей поверхности. Я предпочитаю избегать разделения поверхности на участки, где это возможно, и моделировать криволинейные поверхности одним участком. Это дает более качественную и гладкую поверхность.

Трудности с контролем формы поверхности на участке, близком к плоскому борту. Такое разделение поверхности на участки практически не дает возможности построить на этом участке ровную поверхность. Об этом можно судить по форме сечений вблизи плоского борта.
Неправильная или неконтролируемая параметризация участков поверхности.
Особенности поверхностей NURBS заключаются в том, что обычно используются треугольные или четырехугольные участки поверхностей. Поверхность представлена линиями равного параметра в двух направлениях в пространстве параметров. Правильное распределение параметрических кривых и, соответственно, контрольных точек поверхности очень важно для правильного сглаживания поверхностей. В некоторых случаях получить правильный результат просто невозможно. Поэтому правильное разделение поверхности на участки — путь к успешному сглаживанию.

Неравномерная параметризация поверхности приводит к затруднениям при ее сглаживании.

Пример успешной и неудачной параметризации поверхностей, заданных на одних и тех же граничных линиях. Левая часть поверхности представляет собой цилиндрическую поверхность.Правая часть поверхности, скорее всего, будет напоминать форму паруса, и никакая модификация контрольных точек этой поверхности не позволяет сделать ее цилиндрической. Другой практический пример неправильной параметризации площади поверхности уже был описан здесь ранее.
Выделение плоских участков боковой и нижней и линейчатой поверхностей отдельными участками поверхности.
Конечно, гораздо проще описать всю поверхность корпуса используя один участок полверхности, но недостатки такой модели перевешивают ее достоинства: линии алоского борта и плоского днища хорошо контролируют форму поверхности а их отсутствие приводит к следующим результатам:

Вид сверху. Плоское днище не выделено в отдельный участок поверхности. Изображение ватерлинии сжато по длине.

Вид на плоский борт. Изображение сжато по длине. Форма линии плоского борта явно не та, которую хотел бы видеть констрктор.
Ошибки сглаживания корпуса, вероятно, связаны с недостатком инструментов контроля качества поверхности.

Ватерлинии в корме. Изображение сжато по продольной оси. Вряд ли конструктор хотел иметь такие волны на ватерлиниях.

Ватерлинии в кормовой части скега. Изображение сжато по продольной оси. Видно, что граница двух участков поверхности слишком широкая в области плоского дна или задний участок поверхности должен быть более широким.

Неправильная форма линии границ двух участков поверхности. Видны сломы на границе соединения участков поверхности. Подобрать правильную форму пространственной линии стыковки двух участков поверхности — задача не из легких.

Распределение линий перегиба на поверхности показывает нежелательные перегибы, возникающие на участках поверхности корпуса, и недостаточно гладкое соединение участков поверхности.
Чрезмерное количество контрольных точек участков поверхности.

Поверхность, показанная выше, не закрашена. Визуализируются только контрольные точки участка поверхности. Трудно понять, чем руководствовался автор этой модели. Возможно, просто он не понимает математическую природу поверхностей NURBS или программу, которая использовалась для моделирования. Визуально поверхность получилась гладкой, но использовать ее в дальнейшем для расчетов или моделирования очень сложно. Начиная с того, что даже визуализация такой поверхности (350×350 контрольных точек) требует много времени, не говоря уже о других, более сложных вычислениях.Например, расчет развертки одного листа на этой поверхности занимает более одного часа.
Щели между участками поверхностей.

Это самая частая проблема. Щели образуются, если геометрия границ соседних участков поверхности не совпадает. Щелей можно избежать только в том случае, если граничные кривые геометрически идентичны. Во всех остальных случаях размеры щелей можно только уменьшить, но не избежать полностью. Любые методы приближения граничных кривых друг к другу, такие как интерполяция или аппроксимация, увеличивают количество контрольных точек и, соответственно, количество контрольных точек на смежных поверхностях. Это, в свою очередь, увеличивает сложность изменения формы участков поверхности.
Щели между участками поверхности — одна из самых больших проблем при переносе модели поверхности в другие системы. Зазоры создают проблемы для многих программ проектирования и программ для моделирования конструкций корпуса. Более того, не все эти программы определяют допустимые зазоры между поверхностями еще на этапе импорта. Часто проблемы, вызванные наличием зазоров, возникают позже. Например, в расчетах CFD судно тонет, когда вода поступает через открытые отверстия в модели поверхности корпуса. Получение неправильной геометрии деталей корпуса и разверток обшивки в этом случае наиболее опасно, так как это может быть обнаружено только на этапе производства. Исправление этих ошибок потребует дополнительных финансовых и временных затрат при строительстве корпуса.
Также отмечу, что некоторые системы моделирования корпуса крайне требовательны к зазорам между поверхностями, поэтому Aveva проверяет зазоры с точностью до микрон. Как я уже сказал выше, отсутствие зазоров гарантируется только геометрически идентичными границами соседних участков, но на таких кривых можно иметь разное количество контрольных точек. Это позволяет избежать промежутков между областями поверхности и, в то же время, имеет разное количество контрольных точек. Таким образом, участки поверхностей будут иметь меньше точек, а сложные разделы будут иметь больше, но без зазоров на общих границах.

Некоторые программы моделирования поверхностей делают это автоматически. Проверьте наличие такой функции в программе, которую вы используете. Еще больше возможностей появляется, если программа поддерживает T-соединение.

Т — соединение позволяет стыковать на одной границе разное количество участков поверхности с разных сторон, при этом не возникает зазоров между поверхностями.
Модель поверхности корпуса — одна из важнейших составляющих проекта в целом, с которой работает множество разных отделов. Результат работы большого коллектива может напрямую зависеть от того, насколько качественно выполнены работы по выравниванию поверхности. Конечно, нет ничего идеального, и на каждой поверхности можно найти определенные ошибки. Задача конструктора — попытаться минимизировать их, чтобы получить лучший результат.
Параметрическое моделирование (параметризация) — моделирование (проектирование) с использованием параметров элементов модели и соотношений между этими параметрами. Параметризация позволяет за короткое время «проиграть» (с помощью изменения параметров или геометрических соотношений) различные конструктивные схемы и избежать принципиальных ошибок.
Параметрическое моделирование существенно отличается от обычного двухмерного черчения или трёхмерного моделирования. Конструктор в случае параметрического проектирования создаёт математическую модель объектов с параметрами, при изменении которых происходят изменения конфигурации детали, взаимные перемещения деталей в сборке и т. п.
Идея параметрического моделирования появилась ещё на ранних этапах развития САПР, но долгое время не могла быть осуществлена по причине недостаточной компьютерной производительности. История параметрического моделирования собственно началась в 1989 году, когда вышли первые САПР с возможностью параметризации. Первопроходцами были Pro/Engineer (трёхмерное твердотельное параметрическое моделирование) фирмы Parametric Technology Corporation и T-FLEX CAD (двухмерное параметрическое моделирование) фирмы Топ Системы[1][2]
Содержание
- 1 Двухмерное параметрическое черчение и моделирование
- 2 Трёхмерное твердотельное параметрическое моделирование
- 3 Типы параметризации
- 3.1 Табличная параметризация
- 3.2 Иерархическая параметризация
- 3.3 Вариационная (размерная) параметризация
- 3.4 Геометрическая параметризация
- 4 Примечания
- 5 См. также
- 6 Ссылки
Двухмерное параметрическое черчение и моделирование[править | править исходный текст]
Параметризация двухмерных чертежей обычно доступна в CAD-системах среднего и тяжёлого классов[неизвестный термин]. Однако ставка в этих системах сделана на трёхмерную технологию проектирования и возможности параметризации двухмерных чертежей практически не используются. Параметрические CAD-системы, ориентированные на двухмерное черчение (лёгкий класс) зачастую являются «урезанными» версиями более продвинутых САПР.
Трёхмерное твердотельное параметрическое моделирование[править | править исходный текст]
Трёхмерное параметрическое моделирование является гораздо более эффективным (но и более сложным) инструментом, нежели двухмерное параметрическое моделирование. В современных САПР среднего и тяжёлого классов наличие параметрической модели заложено в идеологию самих САПР. Существование параметрического описания объекта является базой для всего процесса проектирования.
Типы параметризации[править | править исходный текст]
Табличная параметризация[править | править исходный текст]
Табличная параметризация заключается в создании таблицы параметров типовых деталей. Создание нового экземпляра детали производится путём выбора из таблицы типоразмеров. Возможности табличной параметризации весьма ограничены, поскольку задание произвольных новых значений параметров и геометрических отношений обычно невозможно.
Однако табличная параметризация находит широкое применение во всех параметрических САПР, поскольку позволяет существенно упростить и ускорить создание библиотек стандартных и типовых деталей, а также их применение в процессе конструкторского проектирования.
Иерархическая параметризация[править | править исходный текст]
Иерархическая параметризация (параметризация на основе истории построений) заключается в том, что в ходе построения модели вся последовательность построения отображается в отдельном окне в виде «древа построения». В нем перечислены все существующие в модели вспомогательные элементы, эскизы и выполненные операции в порядке их создания.
Помимо «древа построения» модели, система запоминает не только порядок её формирования, но и иерархию её элементов (отношения между элементами). Пример: сборки → подсборки → детали.
Параметризация на основе истории построений присутствует во всех САПР использующих трёхмерное твердотельное параметрическое моделирование. Обычно такой тип параметрического моделирования сочетается с вариационной и/или геометрической параметризацией.
Вариационная (размерная) параметризация[править | править исходный текст]
Вариационная или размерная параметризация основана на построении эскизов (с наложением на объекты эскиза различных параметрических связей) и наложении пользователем ограничений в виде системы уравнений, определяющих зависимости между параметрами.
Процесс создания параметрической модели с использованием вариационной параметризации выглядит следующим образом:
- На первом этапе создаётся эскиз (профиль) для трёхмерной операции. На эскиз накладываются необходимые параметрические связи.
- Затем эскиз «образмеривается». Уточняются отдельные размеры профиля. На этом этапе отдельные размеры можно обозначить как переменные (например, присвоить имя «Length») и задать зависимости других размеров от этих переменных в виде формул (например, «Length/2»)
- Затем производится трёхмерная операция (например, выдавливание), значение атрибутов операции тоже служит параметром (например, величина выдавливания).
- В случае необходимости создания сборки, взаимное положение компонентов сборки задаётся путём указания сопряжений между ними (совпадение, параллельность или перпендикулярность граней и рёбер, расположение объектов на расстоянии или под углом друг к другу и т. п.).
Вариационная параметризация позволяет легко изменять форму эскиза или величину параметров операций, что позволяет удобно модифицировать трёхмерную модель.
Геометрическая параметризация[править | править исходный текст]
Геометрической параметризацией называется параметрическое моделирование, при котором геометрия каждого параметрического объекта пересчитывается в зависимости от положения родительских объектов, его параметров и переменных.
Параметрическая модель, в случае геометрической параметризации, состоит из элементов построения и элементов изображения. Элементы построения (конструкторские линии) задают параметрические связи. К элементам изображения относятся линии изображения (которыми обводятся конструкторские линии), а также элементы оформления (размеры, надписи, штриховки и т. п.).
Одни элементы построения могут зависеть от других элементов построения. Элементы построения могут содержать и параметры (например, радиус окружности или угол наклона прямой). При изменении одного из элементов модели все зависящие от него элементы перестраиваются в соответствии со своими параметрами и способами их задания.
Процесс создания параметрической модели методом геометрической параметризации выглядит следующим образом:
- На первом этапе конструктор задаёт геометрию профиля конструкторскими линиями, отмечает ключевые точки.
- Затем проставляет размеры между конструкторскими линиями. На этом этапе можно задать зависимость размеров друг от друга.
- Затем обводит конструкторские линии линиями изображения — получается профиль, с которым можно осуществлять различные трёхмерные операции.
Последующие этапы в целом аналогичны процессу моделирования с использованием метода вариационной параметризации.
Геометрическая параметризация даёт возможность более гибкого редактирования модели. В случае необходимости внесения незапланированного изменения в геометрию модели не обязательно удалять исходные линии построения (это может привести к потере ассоциативных взаимосвязей между элементами модели), можно провести новую линию построения и перенести на неё линию изображения.
Примечания[править | править исходный текст]
- ↑ История CAD от Marian Bozdoc (перевод на русский)
- ↑ История CAD от Marian Bozdoc (на англ языке)
См. также[править | править исходный текст]
- Геометрический решатель САПР
- Трехмерная графика
Ссылки[править | править исходный текст]
- Подборка статей, посвящённых параметризации
- Параметризация в КОМПАС 3D
- Параметризация в T-Flex CAD
- Параметризация в SolidWorks
- Проблемы параметризации